
面向时钟领域的BERT-LCRF命名实体识别方法
2022-09-21 05:38唐焕玲赵红磊窦全胜鲁明羽
计算机工程与应用 2022年18期
唐焕玲,王 慧,隗 昊,赵红磊,窦全胜,鲁明羽
1.山东工商学院 计算机科学与技术学院,山东 烟台264005
2.山东工商学院 信息与电子工程学院,山东 烟台264005
3.山东省高等学校协同创新中心:未来智能计算,山东 烟台264005
4.山东省高校智能信息处理重点实验室(山东工商学院),山东 烟台264005
5.大连海事大学 信息科学技术学院,辽宁 大连116026
知识图谱(knowledge graph,KG)是一种用图模型来描述知识和建模世间万物之间关联关系的技术方法,可分为通用知识图谱和领域知识图谱两种。通用知识图谱主要应用于语义搜索、推荐系统、智能问答等业务场景,并发挥着越来越重要的作用。而领域知识图谱是基于行业数据构建,由于知识来源多、知识结构复杂、知识质量要求更高等特点,在解决行业痛点时,存在对知识图谱利用不明晰、知识图谱技术与行业难融合等问题。如面向时钟领域,用户越来越复杂,用户无法将自己的需求用专业术语表达,进而导致需求频繁更改、项目延期。同时,传统售后服务不能快速识别、理解和解决用户的售后问题。因此,迫切需要面向时钟领域构建垂直知识图谱,辅助语言理解和数据分析。而命名实体识别是时钟领域知识图谱构建过程中的基础和关键环节,其目标是从海量的文本中识别出具有特定意义的实体。
主流的命名实体识别方法是基于深度学习的方法,通常是将实体识别任务转化为序列标注任务。而目前没有针对时钟领域命名实体识别的研究,由于时钟领域的标签数据匮乏,现有的方法直接应用于时钟领域,存在实体识别精度不高的问题。
本文针对时钟领域实体识别中的问题,提出一种新的命名实体识别模型BERT-LCRF,该模型利用预训练语言模型BERT能够提取时钟领域的文本特征,利用线性链条件随机场(Linear-CRF)进一步提高实体识别的精度。在时钟行业数据集上的实验结果表明,该模型在各项指标上显著优于其他命名实体识别方法。BERTLCRF 命名实体识别方法,能够更好地获取句子间的语义关系,并且能够提高序列标注任务的精度,对构建时钟领域知识图谱有着积极的促进作用。
1 相关工作
命名实体识别发展至今,主要有基于规则和词典的方法、基于统计的方法和基于深度学习的方法,其中基于深度学习的方法可以自动学习适合领域的特征,获取多层次的表达,因此在命名实体识别方向有着广泛的使用。
1.1 基于规则和字典的方法
基于规则和字典的方法主要是采用模式字符串匹配的实现方式,使用人手工构造的特征模版。该方法的不足之处在于模型的可移植性差,单一语料训练好的特征模板不适用于任意语料;其次,构建模板时花费的时间成本较大,它依赖语言学专家书写规则,或者需要收集整理相关词典等资源。因此,该方法存在系统可移植性不好,代价大,系统建设周期长等问题。
1.2 基于统计的方法
基于统计的方法依赖于特征选择,对实体识别结果有影响的各种特征需要从文本中选取,用统计的模型对选出的特征进行训练,从而得到各模型的参数,进而对实体进行识别。有学者采用基于词汇资源、模板的统计信息等进行上下文聚类的方式[1-3];也有学者使用少量标注的种子数据作为开始,再去无监督语料中进行训练,迭代后发现符合规则的实体[4-7]。基于统计的方法主要是在标注训练数据集上,利用模型来抽取数据集中的特征,对训练数据集以外的数据进行实体抽取。常用的识别模型有马尔可夫模型(hidden Markov model,HMM)[8]、支持向量机(support vector machine,SVM)[9]、条件随机场(CRF)[10]等。有监督学习虽然有优势并且能够有效处理海量的数据,但是其不足之处在于,第一,模型的训练需要大量的人工标注语料、代价高;第二,有监督学习的识别效果依赖特征工程选取的特征,因此如何选取反映实体特性的特征集合,对于模型来说至关重要。
1.3 基于深度学习的方法
目前,深度学习算法在自然语言处理领域已经得到了大规模的应用,在命名实体识别领域,基于深度学习的方法已经成为主流。循环神经网络(recurrent neural networks,RNN)等时序网络模型,在文本序列标注中表现出良好的效果,神经网络模型的输入分为字粒度、词粒度和句子粒度,通过学习嵌入模型以向量的形式表示,输入到神经网络中进行编码,然后通过条件随机场模型对编码的数据进行解码,得到全局最优的标注序列。为了解决RNN 中梯度消失和梯度爆炸问题,研究学者又提出了一种长短期记忆网络模型(long shortterm memory,LSTM)[11],这种改进的时序网络模型适用于命名实体识别任务,具有较大的优势。Huang 等人[12]提出了双向长短期记忆网络(bidirectional long shortterm memory,BiLSTM)和条件随机场(CRF)架构用于自然语言处理序列标注任务,将拼写特征、内容特征、词向量作为神经网络的输入,该论文将模型用于命名实体识别任务中获得了先进水平。2018 年,由Google 的研究人员Devlin等人[13]提出的BERT模型采用Transformer编码和自注意力机制对大规模语料进行训练,得到了表征能力强的预训练字向量。李明扬等人[14]在BiLSTMCRF模型的基础上引入自注意力机制,丰富了文本的特征,在微博语料库中达到58.76%的效果。李博等人[15]针对中文电子病历命名实体识别传统模型识别效果不佳的问题,提出一种完全基于注意力机制的神经网络模型,对Transformer模型进行训练优化以提取文本特征;利用条件随机场对提取到的文本特征进行分类识别,具有较好的识别效果。
杨培等人[16]利用BiLSTM 学习字符向量,随后将词向量和字符向量再经过另一个BiLSTM 以获得词的上下文表示,然后再利用Attention机制获得词在全文范围下的上下文表示,最后利用CRF层得到整篇文章的标签序列。Kuru 等人[17]提出的一种基于字符级别的命名实体识别标注模型及标注模式,该方法能更好地捕获词组的形态学特征,同时又可以避免出现未登陆的词(OOV)情况。Zhang 等人[18]采用Lattice LSTM 模型进行实体识别,该模型对输入字符序列以及与词典匹配的所有潜在单词进行编码,供模型自动取用,相比于字符级的编码,Lattice LSTM 能够获取更丰富的语义;相比于词序列的编码,Lattice LSTM能够避免分词错误带来的影响。
但在特定的时钟领域的实体识别方法还存在一些难点问题:(1)时钟行业内数据类型众多,存储格式不统一,并且信息实体之间大部分不是直接连接的。信息实体与通用的命名实体也是不一致的,需要对概念实体进行重新定义。(2)时钟领域缺乏足够多的标注数据,人工标注的成本很高,需要耗费大量的时间以及精力,并且实体标注难度大。目前并无学者对时钟领域的命名实体识别进行探索,时钟领域也没有公开的大规模的带标签的数据集。因此,本文针对时钟领域的命名实体识别问题,提出了一种结合BERT和Linear-CRF的时钟领域命名实体识别模型,记作BERT-LCRF。
2 BERT-LCRF时钟领域命名实体识别模型
2.1 问题描述
面向时钟领域的命名实体识别方法,其目标是从时钟行业的文档中识别出与时钟行业相关的实体,并将他们归类到预先定义好的实体类别中。
首先根据收集的时钟领域的各种文档,分析时钟领域的专业术语和概念,预先定义时钟领域的实体类别集合C={c1,c2,…,cm}。根据时钟领域的文本特点和实体类别集合C,采用BIO 标注策略,定义实体标签集合L。令B代表Beginning,标注实体的起始部分,I代表Inside,标注实体的中间部分,O 代表Outside,标注与实体无关的信息,实体标签集合L={l1,l2,…,lk}。面向时钟领域的命名实体识别问题可以转换为序列标注问题,输入句子的字序列,预测输出其实体标签序列。

面向时钟领域命名实体识别任务是:
训练阶段:对给定时钟领域训练样本集X和实体标签序列空间Y,训练生成:

其中,hBERT-LCRF是本文面向时钟领域提出的一种基于BERT和线性链条件随机场(Linear-CRF)的命名实体识别模型,框架如图1 所示。hBERT-LCRF的目标函数是最大化如式(2)的对数似然。
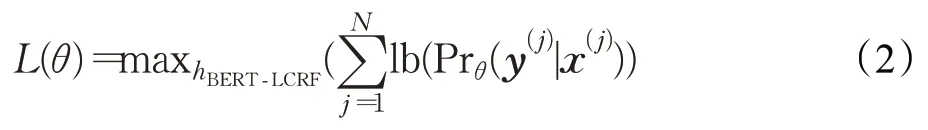
测试阶段:对任意句子x=(x1,x2,…,xn),预测实体标签序列为:

其中,hBERT-LCRF是训练好的命名实体识别训练模型。∈L,是对x预测的实体标签序列。
如图1所示,BERT-LCRF的时钟领域命名实体识别模型由BERT层、Linear-CRF层组成。其中,BERT层是特征提取层,实现特征提取的功能。Linear-CRF层是基于Linear-CRF 的序列标注层,实现序列标注的功能。BERT层和Linear-CRF层将在2.2~2.4节详细描述。

图1 BERT-LCRF的模型结构图Fig.1 BERT-LCRF model structure diagram
2.2 BERT预训练语言模型
BERT 模型[13]是从语料中学习,并充分考虑语料中句子级、词语级和字符级之间的关系特征,增强字向量的语义表示。BERT 的结构如图2 所示,其最大的特点是抛弃循环神经网络(RNN)和卷积神经网络(CNN),采用多层的Transformer结构。

图2 BERT模型结构Fig.2 BERT model structure
如图2所示,BERT的输入是n个字序列,经过BERT嵌入层(embedding),表示成字编码向量(e1,e2,…,en),输出是(t1,t2,…,tn),表示n个字的得分概率向量。
为融合字左右两侧的上下文,BERT 采用多个双向Transformer 作为编码器,即图2 中的Trm。通过Transformer 中的注意力机制将任意位置的两个单词的距离转换,反映各个字之间的相关程度,从而使输出的各个字向量都充分融合了上下文的信息,解决了一词多义的问题。BERT 模型具有很好的并行计算能力,且能够捕获长距离的特征。
2.3 Linear-CRF模型
条件随机场(condition random field,CRF)模型是一种用于标注和切分有序数据的条件概率模型,该模型结合了隐马尔可夫和最大熵模型的优点。
假设x=(x1,x2,…,xn),y=(y1,y2,…,yn)均为线性链表示的随机变量序列,如果给定随机变量序列x,随机变量序列y的条件概率分布Pr(y|x)构成条件随机场,即满足马尔可夫性:

则称Pr(y|x)为线性链条件随机场(Linear-CRF)。
序列标注问题中,x表示输入观测序列,y表示对应的输出标记序列或状态序列,且与观测序列具有相同的结构。因此,序列标注问题可以表示为如图3所示的Linear-CRF。

图3 线性链条件随机场Fig.3 Linear chain conditional random field
对序列标签的预测,通常采用softmax分类器方法,但是softmax方法没有考虑标签之间的依赖关系。
本文采用Linear-CRF 进行序列标签预测,Linear-CRF能够考虑各字标签之间的约束关系,它利用每个字标签的得分与字标签之间的转移矩阵A计算不同标签序列的出现概率Pr(y|x),从而能够从中选取出概率最大的序列y*作为所考虑句子的标签序列。
2.4 BERT-LCRF模型
本文基于BERT 和Linear-CRF 提出了面向时钟领域的BERT-LCRF命名实体识别模型。
如图1 所示,输入句子x=(x1,x2,…,xn),由BERT模型输出字序列标签的得分概率向量T=(t1,t2,…,tn),然后采用Linear-CRF 模型预测句子中的每个字xi∈x的最优标签,从而完成时钟领域的命名实体识别任务。
2.4.1 BERT嵌入层
BERT 嵌入层即图1 和图2 中的“embedding”层,由三种embedding求和而成,具体如图4所示。

图4 BERT嵌入层的特征嵌入表示Fig.4 Feature embedding representation of BERT embedding layer
BERT 嵌入层的输入是字的线性序列,支持单句文本和句对文本,句首用符号[CLS]表示,句尾采用符号[SEP],断开输入的两个句子。
BERT嵌入层由词嵌入(token embeddings)、分割嵌入(segment embeddings)和位置嵌入(position embeddings)共同组成[13],其中词嵌入是将中文字符转为字向量,位置嵌入是指将字符的位置信息编码成特征向量,分割嵌入用于区分两个句子。其中,位置嵌入(position embeddings)用来加入位置信息,支持序列长度为512,利用正余弦函数对字进行位置编码,将字的位置信息编码成特征矩阵,其编码如式(5)和(6)[13]。
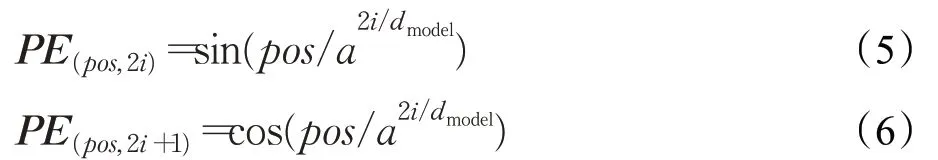
其中,PE为二维矩阵,其维度与输入embedding 的相同,这里行表示字,列表示字向量,pos表示字在句子中的位置,dmodel表示字向量的维度,i表示字向量的位置,a等于10 000。位置编码的每个维度的波长形成是从2π 到a⋅2π 的几何数,对于任何固定偏移k,PE(pos,k)可以表示为一个线性的位置编码。位置编码是通过线性变换获取后续字符相对于当前字符的位置关系,能够更好地表达语义关系。
输入句子x=(x1,x2,…,xn),由BERT嵌入层的三种embedding转换求和之后,每个字xi转换为嵌入向量ei输出,得到句子的嵌入表示E=(e1,e2,…,en),其中ei是对应xi的向量表示,是一个m维向量,E是一个n×m维的矩阵,每一行对应句子中一个字的向量表示,然后作为图2中Trm层的输入。
2.4.2 Trm层
如图2 所示,BERT 的Trm 层由多个Transformer 编码器(Encoder)组成,每个Encoder的结构如图5所示。
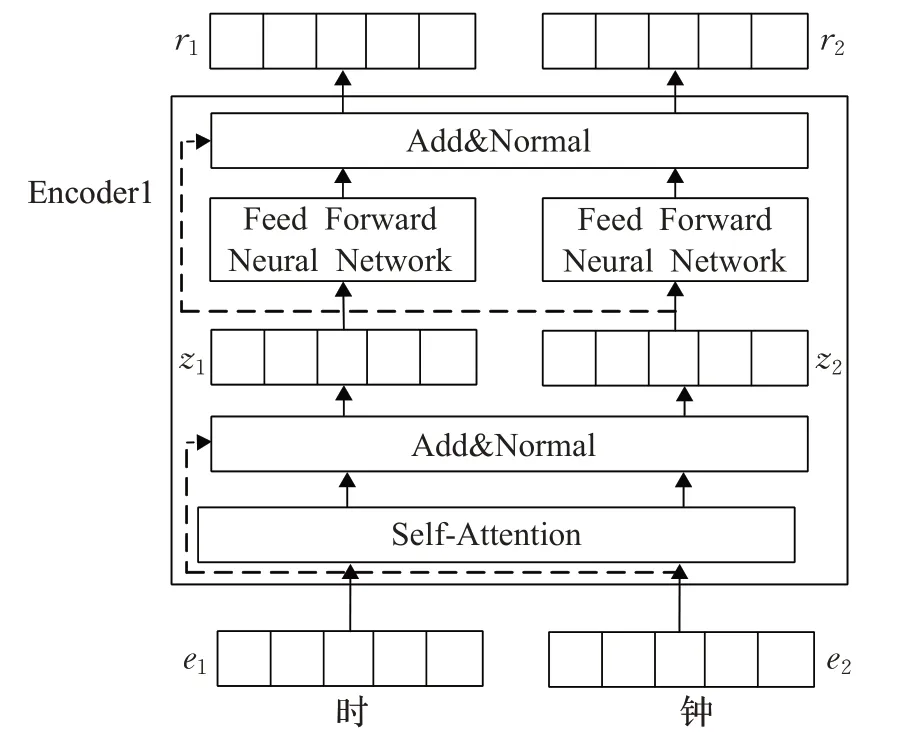
图5 Encoder详细结构Fig.5 Encoder detailed structure
每个Encoder包括多头自注意力机制层(multi-head self-attention)、全连接层(feed forward)、残差连接和归一化层(add&normal)。在Encoder 中最主要的模块为multi-head self-attention[19],其核心思想是计算句子中每个字与该句子中其他所有的字的相互关系,并调整每个字的权重,获取每个字的新的表达方式。
Encoder的输入是BERT嵌入层的输出E。将目标字的ei通过线性变换得到表示目标字的q向量、表示上下文各个字的k向量以及表示目标字与上下文各个字的原始v向量,然后计算q向量与各个k向量的相似度作为权重,加权融合目标字的v向量和各个上下文字的v向量,计算[19]如式(7):

其中,q表示查询向量,k表示键向量,v表示值向量,d为缩放因子,其目的是使模型的梯度更稳定。采用点积的计算机制,使当前节点不只关注当前的字,而是关注整个句子,从而获取到上下文的语义信息,在一定程度上反映出不同字符之间的关联性和重要程度,获得更丰富的语义特征表达。最后使用softmax进行归一化处理。
在实际应用过程中,编码器(encoder)中使用多头自注意力(multi-head self-attention),利用不同的Self-Attention 模块获得句子中每个字在不同语义空间下的增强语义向量,并将每个字的多个增强语义向量进行拼接,再进行线性变换,从而获得一个最终的与原始字向量长度相同的增强语义向量,作为Multi-Head Self-Attention层的结果,计算如式(8)和式(9)。表示第i个head的权重矩阵,WO表示附加的权重矩阵,在模型训练时不断更新。在多头注意力层通过不同的head得到多个特征表达,将所有的特征拼接到一起,作为增强语义的向量表示。

在残差链接和归一化层(add&normal)中,利用残差链接可避免在模型较深时,反向传播过程中的梯度消失问题。当网络进行前向传播时,可以按照网络层数进行逐层传播,还可以从当前层隔一层或多层向前传播。该层能对各特征之间的输入进行规范化。然后将处理后的数据zi传送给全连接层(feed forward),该层可以进行并行计算。
在全连接层(feed forward neural network),是一个两层的全连接层,第一层的激活函数为Relu,第二层不使用激活函数,对应的公式如下:
其中,
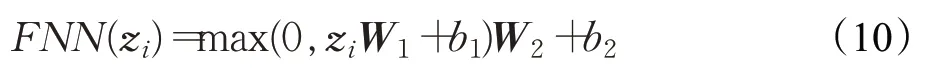
其中,zi为残差链接和归一化层的输出,W1,W2,b1,b2均为前馈网络层的权值参数。
在模型结构中,每一层都会间隔一层add&normal,这是深度残差网络的特性,将前一层的输入和输出进行求和正则,得到R=(r1,r2,…,rn),并将其作为下一个Encoder 的输入,在经过多个Encoder 编码后,最后通过softmax 归一化得到各个字的标签得分概率向量T=(t1,t2,…,tn)。
使用Transformer编码器(Encoder)能够计算句中字与字之间的关系,使得模型能够学习字之间的联系以及每个字的重要程度,获取全局特征信息。
2.4.3 基于Linear-CRF的序列标注层
给定句子x=(x1,x2,…,xn),由BERT模型得到的字序列的实体标签得分概率T=(t1,t2,…,tn),ti是字xi的实体标签得分,T是linear-CRF序列标注层的输入。
linear-CRF 层的参数是一个(n+2)×(n+2)的实体标签转移矩阵A,Aij表示是从第i个标签到第j标签的转移得分,体现的是实体标签之间的约束关系。对一个位置进行标注时,可以利用此前已经标注过的标签。n+2 是为句子首部添加一个起始状态,句子尾部添加一个终止状态。
对给定的句子x,根据每个字的实体标签的得分ti,以及字标签之间的转移矩阵A,计算对x预测为不同标签序列y的概率,取概率最大的标签序列y*,作为该句子的标签序列,具体过程如下:
对任意一个句子x=(x1,x2,…,xn),n是字序列长度,也是标签序列的长度,那么BERT-LCRF模型对x预测为标签序列y的得分计算如式(11):

其中,表示第i个字被标记为yi的概率,A为转移矩阵,表示从yi标签转移到yi+1标签的概率,n为序列长度。因此,整个字序列的得分是每个字的分数之和,而每个字的分数由两部分组成,一部分是由上一层输出的ti决定,另一部分则由linear-CRF的转移矩阵A决定。最后利用softmax函数归一化,计算Pr(y|x)如式(12)所示:
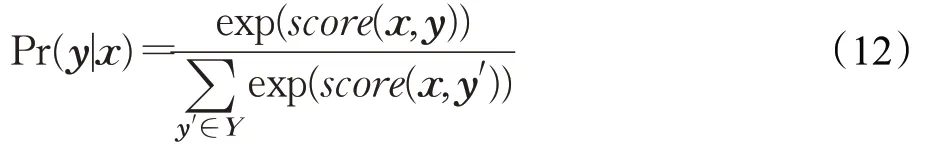
其中,y′∈Y,L是对时钟领域的字标签集合,y′是可能的字标签序列,式(12)的对数似然计算如式(13):

最后在解码阶段,使用维特比算法[20]求解最优路径,计算如式(14):

由此对于输入字序列x=(x1,x2,…,xn),经过模型BERT-LCRF预测,得到字序列标签
3 实验分析
3.1 时钟领域数据集(clock-dataset)
本文采用自建的时钟领域语料库(clock-dataset)对BERT-LCRF模型的有效性进行实验评估。
(1)时钟领域文本预处理
首先收集时钟行业的时钟系统建议书作为原始数据,由于原始文本数据的存储格式不同,包含对实体识别无用的信息,经过格式转换、过滤图片等无用信息、分段、分句等预处理,得到初始以句子为单位的时钟领域语料库。
(2)领域新词识别和自定义字典
对未分词的语料库,采用基于互信息和左右熵算法[21]进行领域新词的识别。该方法首先计算词与其右邻接字的互信息,得到候选新词,然后再采用邻接熵、过滤候选新词首尾的停用词和过滤旧词语等规则进行筛选,最终得到领域新词集,并添加领域自定义词典(clockdictionary)中。结合clock-dictionary,采用jieba 分词对初始时钟语料库中的句子进行分词,提高领域分词结果的准确性。同时将分词结果作为时钟领域的先验知识,减少人工标注审核的工作量,提高标注的效率,降低标注误差。
(3)实体类别和实体标签定义
根据时钟系统建议书的领域特性,进行概念抽取,结合对领域词汇的统计分析,定义时钟领域的实体类别集合C={c1,c2,…,cm},其中ci∈C,可以是地域(CITY)、设备(EQU)、对象(OBJ)等,具体如表1所示。

表1 时钟领域实体类别描述Table 1 Entity category description in clock domain
在定义了实体类别集合C后,根据时钟领域的文本特点,采用BIO 标注策略,令B 代表Beginning,标注实体的起始部分,I代表Inside,标注实体的中间部分,O代表Outside,标注与实体无关的信息,定义实体字标签集合L={l1,l2,…,lk},其中li∈L,具体描述如表2所示。

表2 clock-dataset的实体标签描述Table 2 Label category description of clock-dataset
(4)语料标注
在没有时钟领域的标注语料时,通过设计人机交互的辅助实体标注平台,辅助专业人士快速、高效标注高质量的训练语料,记作时钟领域数据集(clock-dataset)。在获得一定数量的人工标注数据后,可以利用BERTLCRF命名实体识别方法,结合semi-supervised learning(半监督学习)、self-learning(自学习)和active learning(主动学习)等方法进行标注数据的扩充。实验中,对标注的clock-dataset 数据集,划分成三个数据集:训练集、测试集和验证集,具体表述如表3所示。
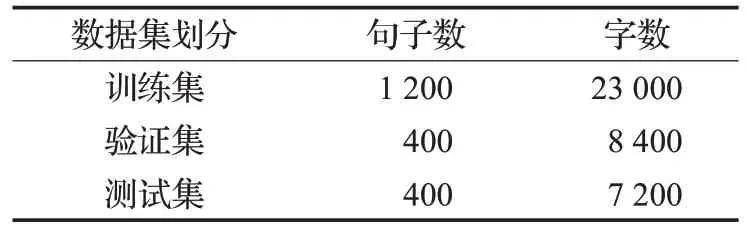
表3 clock-dataset的划分描述Table 3 Clock-dataset division
3.2 实验基本设置及参数设置
本文的实验环境设置:64 位Window10 系统,AMD Ryzen 7 2700X Eight-Core Pricessor 3.70 GHz 处理器,8 GB内存,显卡为NVIDIA GeForce GTX 1060 6 GB中进行。使用的编程语言为Python,深度学习框架Pytorch。
实验中,设置网络的损失函数为最大似然函数,采用BertAdam 优化方法不断更新参数,并使损失函数最小化。为了防止模型过拟合,提高模型的泛化能力,在网络模型中加入Dropout,将其设置为0.1。BERT 模型共12 层,768 个隐藏单元,12 个注意力头。实验参数设置如表4所示。

表4 实验参数设置Table 4 Experimental parameter settings
3.3 评价指标
实验中采用宏准确率(Macro-P),宏召回率(Macro-R)和宏F1值(Macro-F1)三个指标,对如表1所示的七类实体的识别结果进行评估,计算公式如下:
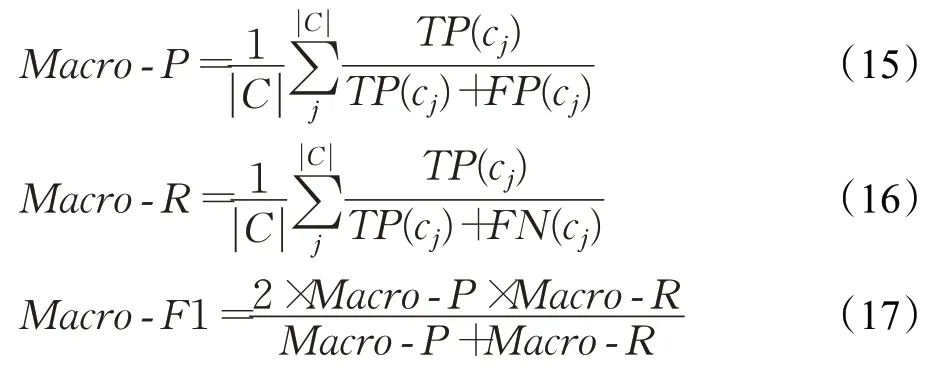
其中,TP(cj)表示属于cj实体类别,且识别正确实体数;FN(cj)表示属于cj实体类别,但识别不正确的实体数;FP(cj)表示不属于cj实体类别,但被识别为cj的实体数。
3.4 实验结果及分析
为了验证所提BERT-LCRF模型的有效性,与HMM、CRF、LSTM、BiLSTM-CRF模型进行了命名实体识别对比实验。
3.4.1 命名实体识别模型总体识别效果比较分析
在clock-dataset 上,BERT-LCRF 模型与BiLSTMCRF、LSTM、HMM、CRF模型的命名实体识别对比实验结果如表5所示。
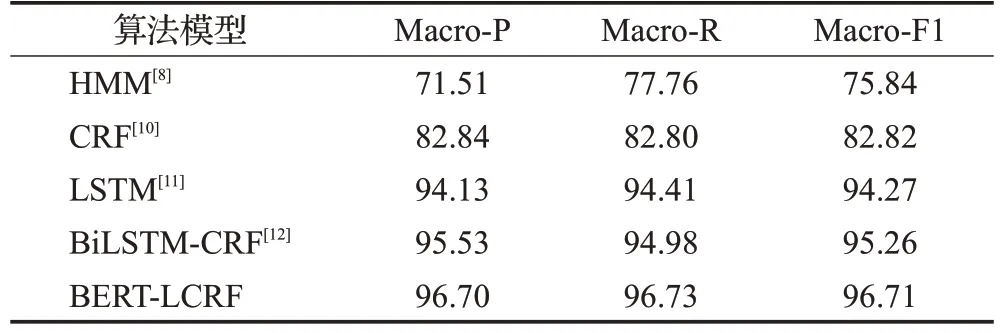
表5 不同模型的命名实体识别结果比较Table 5 Comparison of named entity recognition results of different models %
从表5 中可以看出,针对于时钟领域的语料而言,所提BERT-LCRF模型相对于其他四种算法模型取得了较为优异的结果。如表5所示,HMM、CRF、LSTM算法的Macro-P分别为71.51%、82.84%、94.13%,BiLSTM-CRF模型为95.53%,而BERT-LCRF 的准确率为96.70%,评估指标Macro-R和Macro-F1的对比也是类似的。
分析表5中不同方法的效果对比,其中HMM、CRF算法没有学习上下文的语义关系,因此识别效果不好。LSTM 只是单向的学习文本序列,没有CRF,虽然可以得到句子中每个单元的正确标签,但是不能保证标签每次都是预测正确的。BiLSTM-CRF 模型采用双向LSTM 和CRF,其结果优于LSTM 方法,其Macro-P 为95.53%、Macro-R 为94.98%、Macro-F1 为95.26%。而BERT-LCRF 模型的三种评估指标为96.70%、96.73%和96.71%,对比BiLSTM-CRF模型平均提升了0.9%。
原因在于,本文使用BERT预训练语言模型来代替BiLSTM。基于BiLSTM-CRF 命名实体识别方法不能很好地利用语料中的上下文的语义关系,而BERTLCRF 模型增加了位置编码以及注意力机制,能够很好地利用语料中的上下文语义关系,对时钟领域数据进行特征提取,能够充分学习时钟领域的特征信息,解决时钟领域的特征表示的一词多义问题,因此BERT-LCRF模型的识别效率相对最高。
3.4.2 时钟领域每类实体的识别效果比较
为进一步验证BERT-LCRF模型对每类实体的识别效果,与HMM 模型、CRF 模型和BiLSTM-CRF 模型进行了实验对比,实验结果如表6~9所示。
从表6~9 中可以看出,BERT-LCRF 模型在13 种实体类别上的宏准确率、宏召回率、宏F1值均比其他模型的高,说明BERT-LCRF 模型的每类实体识别效果要优于其他模型。
从表6~9中还可以看出,所有实体类别中,“B-OBJ”和“I-OBJ”对象类实体的宏准确率最高,HMM 模型为87.67%,CRF 模型为94.95%,BiLSTM-CRF 模型为97.46%,BERT-LCRF模型为97.49%。分析原因,时钟领域数据中的对象这类实体的数量比较多,并且实体组成较为单一,边界词明显,主要是以“系统”两个字作为结尾,并且有固定的表达格式,例如“时钟系统”“时钟同步系统”“子母钟系统”等,因此在识别过程中宏准确率高。功能、技术这类实体的宏准确率相对较低,功能(FUN)和技术(TEC)这类实体,实体数量相对其他实体来说,实体数量少,存在OOV 词,因此其宏准确率会相对较低,其余的实体类别宏准确率相对而言比较平均。

表6 HMM模型实体类别识别结果Table 6 HMM model entity category recognition results %
4 结论
本文针对时钟领域的问题,定义时钟领域实体类别,选择适合时钟领域文本的标注规则,设计辅助标注平台,构建时钟领域数据集(clock-dataset),提出一种BERT-LCRF 的命名实体识别模型。该模型利用BERT结合时钟领域的先验知识,充分学习时钟领域的特征信息,而Linear-CRF 能够提高序列标注的准确度,从而BERT-LCRF模型能够提高实体识别的精度。在时钟行业数据集上的实验结果表明,该模型在各项指标上显著优于同类其他模型。BERT-LCRF模型是构建时钟领域知识图谱的基础,时钟领域的实体类别和标签还有待扩充,下一步将在此基础上结合时钟领域先验知识进行事件抽取,进一步构建面向时钟领域的知识图谱。

表7 CRF模型实体类别识别结果Table 7 CRF model entity category recognition results %

表8 BiLSTM-CRF模型实体类别识别结果Table 8 BiLSTM-CRF model entity category recognition results %

表9 BERT-LCRF模型实体类别识别结果Table 9 BERT-LCRF model entity category recognition results %
猜你喜欢
通信技术(2021年12期)2022-01-25
数学小灵通·3-4年级(2021年9期)2021-10-12
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
小学生学习指导(低年级)(2020年10期)2020-11-09
计算机应用与软件(2018年9期)2018-09-26
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
数学大王·中高年级(2017年2期)2017-02-08
学苑创造·A版(2016年4期)2016-04-16
外语教学理论与实践(2014年2期)2014-06-21
