
面向小目标检测的并行高分辨率网络设计
2022-09-21 05:37郑乐辉魏建国
计算机工程与应用 2022年18期
牛 润,曲 毅,郑乐辉,魏建国
1.武警工程大学 研究生大队,西安710086
2.武警工程大学 信息工程学院,西安710086
目标检测是识别图像中感兴趣的目标以及确定位置,在日常生活各个领域中,如智能安防、自动驾驶、工业生产等场景下被广泛应用。在实际应用中,大量目标由于自身大小或者距离等因素被定义为小目标。随着深度学习的广泛应用,目标检测的精度被不断提升,但针对小目标的检测一直是难点。小目标覆盖的像素区域小、分辨率低、特征不够明显且表达能力弱,在当前通过深度换精度的模型中,特征极易丢失,导致小目标检测难于常规目标的检测[1]。
在解决小目标检测方面,研究人员做了大量探索,主要包括Anchor box 优化、引入注意力机制、特征融合、特征增强、改进网络、改进损失函数等研究[2]。针对特征信息在网络中易丢失的问题,人们利用特征金字塔进行多尺度特征图处理,Liu等[3]提出SSD网络,应用特征金字塔思想,通过主干网络不同层的特征图实现多尺度检测,有效利用了浅层特征信息,但不同尺度特征图信息没有有效结合。Lin 等[4]提出特征金字塔网络(feature pyramid networks,FPN),通过融合邻近层特征图实现了深层特征信息反向传输来增强浅层特征,但FPN结构虽然增强了较浅特征图的语义信息,但深层特征图依然会失去许多位置信息,Liu 等[5]通过在FPN 上添加一条从下往上的通路,缩短了位置信息向上传输的距离,实现了位置信息向深层特征图的有效传递。
由于小目标所占像素过少,可直接利用的信息不丰富,研究人员通过上下文信息来强化模型检测能力,Fu等[6]在SSD模型的基础上加入反卷积层获取上下文信息,生成了一种“宽-窄-宽”的沙漏结构。李青援[7]在SSD模型中引入一条自深向浅的递归反向路径,通过特征增强模块将深层包含上下文信息的语义特征增强到浅层。梁延禹等[8]使用特征图的空间和通道间全局信息来增强浅层特征图中小目标的上下文信息。Yu 等[9]提出空洞卷积来扩大感受野,Li等[10]利用空洞卷积设计了一种三叉戟网络(TridentNet)以利用目标上下文语义信息。
本文从多尺度信息融合和上下文信息的利用两个角度出发,采用HRNet[11]和HRDNet[12]能够保留丰富小目标特征信息的优势网络结构,构建一种多分辨率子网并行连接的特征提取网络结构,该网络具有以下6个特点:
(1)具有多分辨率网络并行连接结构,并且将不同分辨率特征图多次进行融合,使每个分辨率特征图都能多次接受其他分辨率特征图的信息,可得到既包含高分辨率位置信息又包含低分辨率语义信息的输出特征图。
(2)缩短了高分辨率分支子网的深度,使其保持更加丰富的细节信息和位置信息,同时加深低分辨率分支子网深度,使其获得更抽象的语义信息。
(3)使用了扩大感受野的模块,使得模型可以获得丰富的目标上下文语义信息,增强检测能力。
(4)使用了融合因子来调节低分辨率特征信息到高分辨率特征信息的流通,强化模型对小目标检测的针对性。
(5)在下采样时使用Focus 模块实现不丢失信息的分辨率降低;在相邻特征图融合时,使用亚像素卷积[13]实现不丢失信息的分辨率提升。
(6)采用注意力机制来进一步提高小目标检测能力。
1 相关工作介绍
1.1 高分辨率网络
在卷积神经网络中,高分辨率的图像包含更丰富的细节信息,对于小目标检测至关重要,但高分辨率特征图也产生了较多的运算量,增大了计算成本。此外,位于模型深层的低分辨率特征图包含丰富的语义信息,可以用来提高模型对目标的识别能力。基于以上考虑,Sun等[11]设计了用于关键点检测的高分辨率网络HRNet。
HRNet结构如图1所示,通过将不同分辨率网络并行连接,将低分辨率特征图与高分辨率特征图进行融合,使特征提取网络可以输出包含丰富语义信息的高分辨率特征图。图像经过不同分支可以得到分辨率大小不一的特征图,且输入进每一分支的特征图都融合了前一阶段所有尺度的特征图,使得每一分支的特征图都兼顾高分辨率与低分辨率的特征信息,保留更多小目标特征信息。
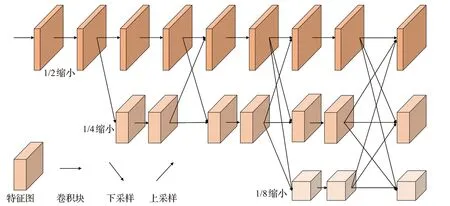
图1 HRNet网络结构Fig.1 HRNet network structure
HRNet的核心思想在于图像在模型中进行处理时,全程都保持了较高的分辨率,同时生成多个低分辨率的特征图,利用其增强高分辨率特征图的特征信息。
Liu等[12]同样利用这种思想设计了针对小目标检测的网络HRDNet,其结构如图2所示,首先构建图像金字塔,得到不同分辨率的图像,针对高分辨率的图像使用较浅的特征提取网络处理,对低分辨率网络则使用较深的网络,然后使用多尺度特征金字塔实现浅层到深层、高分辨率到低分辨率的特征信息流通,增强对多尺度目标的语义表征能力。
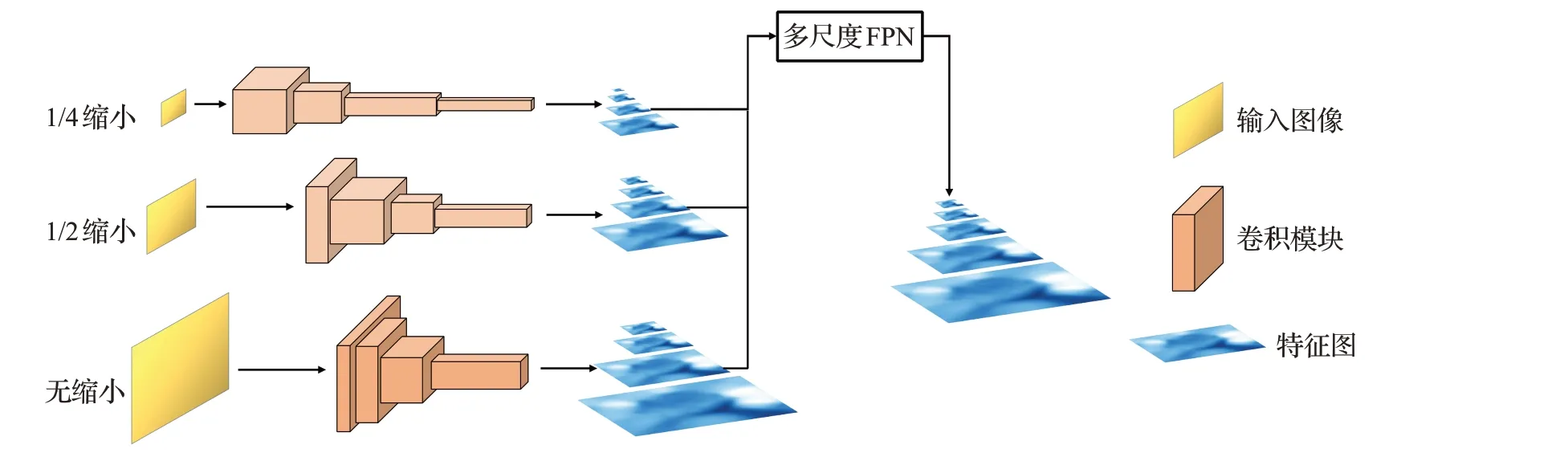
图2 HRDNet网络结构Fig.2 HRDNet network structure
HRDNet 通过使用较浅的网络处理高分辨率图像,既可以节省计算资源,同时可以保留图像的细节信息;用较深的网络处理低分辨率图像可以获得特征高度凝练的语义信息。
1.2 RFB模块
小目标在图像中占用的像素少,特征信息不够充分,一种优化的思路是利用目标周围环境的信息来辅助识别,这些信息被称作目标上下文语义信息。通常图像中的物体不是独立存在,其必然与周围环境存在一定联系,利用好目标的上下文语义信息可以丰富目标特征。常用的优化方法为利用空洞卷积扩大神经网络的感受野,Liu 等[14]利用空洞卷积设计了RFB 模块(receptive field block)。
RFB 模块借鉴人类视觉的感受野结构Receptive Fields(RFs),使用多尺寸、多离心率的空洞卷积核构建了多分支结构。RFB 模块对输入的图像首先使用3 种不同尺寸(1×1、3×3、5×5)的普通卷积核进行处理,然后使用不同离心率的空洞卷积得到3 个不同感受野的特征图,将其融合可以得到特征增强的特征图。RFB-s是RFB模块的变体,通过用3×3卷积层代替5×5卷积层,用1×3和3×1卷积层代替3x3卷积层来减少计算量。
与传统卷积模块,RFB模块较低离心率的分支得到的特征图中,每个像素可以凝练包含部分或者目标整体的特征信息,较高离心率的分支能够凝练包括目标本身与周围环境在内的特征信息,将多分支融合的优势在于:高离心率分支可以为低离心率分支扩充上下文语义信息;低离心率分支则可以弥补高离心率分支卷积核扩散造成的细节信息丢失。
1.3 特征融合因子
Gong 等[15]指出,在应用FPN 进行小目标检测时,FPN 中相邻层之间的信息传递会给小目标的检测带来负面影响,由于要检测的目标很小,每一层的学习能力不足,深层网络难以学习到足够有用的特征信息,不能对浅层进行指导,每一层更应关注本层的学习,减少对其他层的影响。因而Gong等提出特征融合因子来调整信息的流通性。
通过计算FPN 中每层特征图捕获的目标正样本数量,从而得到不同分辨率下的特征图对小尺度目标的“关注度”,用相邻两层正样本数量的比值作为特征融合因子,在特征图融合时使用,可以有效引导不同层更加关注本层目标特征,减小其他层带来的负面影响。计算特征融合因子的公式为:

1.4 Focus结构和亚像素卷积
Focus 结构在YOLOv5 模型(UltralyticsLLC 公司于2020年5月提出的一种单阶段目标检测网络)中首次出现,如图3(a)中所示,它将输入的图像进行切片操作,减小图像分辨率的同时同比例扩大了通道数,然后应用普通卷积进行特征整合,对比传统下采样方法,Focus结构有效利用了所有图像数据,没有丢失图像信息。亚像素卷积如图3(b)所示,其处理图像的方法与Focus结构类似,首先利用普通的卷积将图像的通道数扩大n2倍,然后对生成的特征图进行尺寸重塑(reshape 操作),使其分辨率扩大为原来的n倍、通道数保持不变,亚像素卷积区别于传统的补零、插值的上采样方法,扩大分辨率用的是图像特征信息,没有引入无用数据,实现了无失真的上采样。
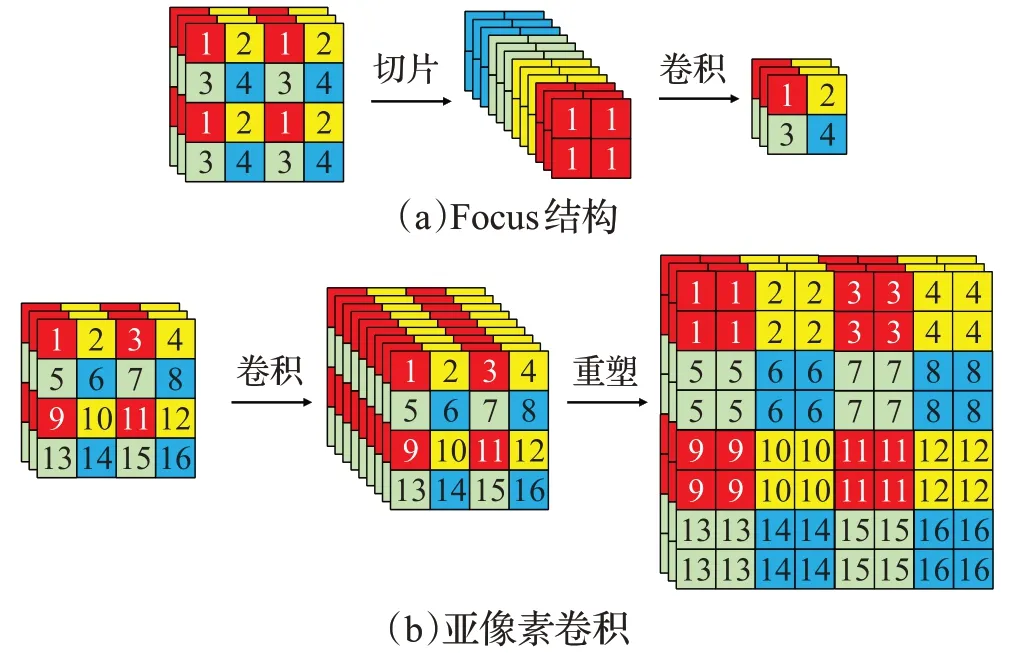
图3 Focus结构和亚像素卷积Fig.3 Focus structure and subpixel convolution
1.5 注意力机制
模型在处理小目标图像时会混入大量不包含目标信息的“无意义”区域,这些信息会对有效目标的特征提取造成影响,研究人员提出了注意力机制来引导模型关注目标区域,提高特征提取能力。注意力机制借鉴了人类视觉特有的脑信号处理机制,在人眼视觉神经扫描图像时会产生注意力焦点,重点关注某几个关键区域以排除无关信息的干扰,提高对信息处理的精度和效率。
神经网络中的注意力机制是一种即插即用的可学习模块,工作原理是对特征图张量中的数值分配权重系数,强化重点区域的信息。注意力机制主要包括通道注意力机制和空间注意力机制,通道注意力机制是对特征图的通道维度进行权重分配,动态强化各通道的特征,代表模型是SENet[16];空间注意力机制在空间维度上进行权重分配,学习图像上不同位置的依赖关系,动态强化空间维度的特征,代表模型有SAM[17]等;还有结合两种机制的结构如BAM[18]、CBAM[19]等。自注意力机制是从自然语言处理领域发展而来的注意力机制的分支,它不依赖外部信息的引导,依靠自身输入建立全局依赖关系生成权重系数,常用的是transformer[20]模块,代表模型有ViT[21]、DETR[22]等。
2 提出的模型
2.1 模型基本结构
为了有效整合高分辨率浅层特征信息与低分辨率深层特征信息,本文基于HRNet和HRDNet设计了一种多分辨率子网并行连接的网络结构。该模型结构如图4所示,首先对输入的图片应用Focus结构进行处理,通过对图像进行切片和卷积,实现不丢失图像信息的尺寸缩减,构建输入图像金字塔;将不同尺寸的特征图输入到不同深度的网络分支中提取特征,各网络分支使用不同数量的RFB 模块搭建,将尺寸缩小1/4、1/8 和1/16 的特征图分别输入到包含1 个、2 个和3 个RFB 模块的分支中,低深度分支只处理大分辨率特征图,高深度分支只处理小分辨率特征图,三个分支并行连接同步运行,在三个分支中间位置进行两次多尺度特征图融合,充分结合高分辨率浅层定位信息和低分辨率深层语义信息。所提的网络结构命名为PHRNet(parallel high-resolution net)。
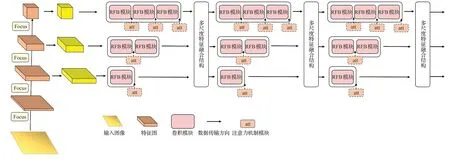
图4 本文所设计的网络结构Fig.4 Network structure designed in this paper
2.2 多尺度特征融合结构
将三个分支输出的三个不同分辨率大小的特征图传入多尺度特征融合结构进行信息融合。本文结合在现有的多尺度特征融合网络FPN和PAN的基础上进行改进,构建了对小目标检测针对性的网络结构。本文设计的结构如图5所示。
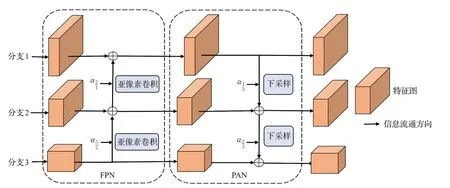
图5 多尺度特征融合结构Fig.5 Multi-scale feature fusion structure
为了加强定位信息的流通,在FPN 结构后补充了PAN 结构,在对低分辨率特征图进行上采样时,使用了亚像素卷积对原特征图扩充通道再重组为更高分辨率的特征图,以此实现不丢失信息的尺寸放大。在对特征图上采样和下采样时应用特征融合因子来调整信息的流通,引导模型更加关注小目标。
2.3 注意力机制
本文所提模型采用了轻量级注意力机制CBAM(convolutional block attention module)模块,插入到指定RFB模块后。CBAM模块结合了空间注意力机制和通道注意力机制,从空间和通道两个维度上强化特征图中的目标信息,引导模型增强对关键信息的注意力。CBAM模块结构如图6所示。
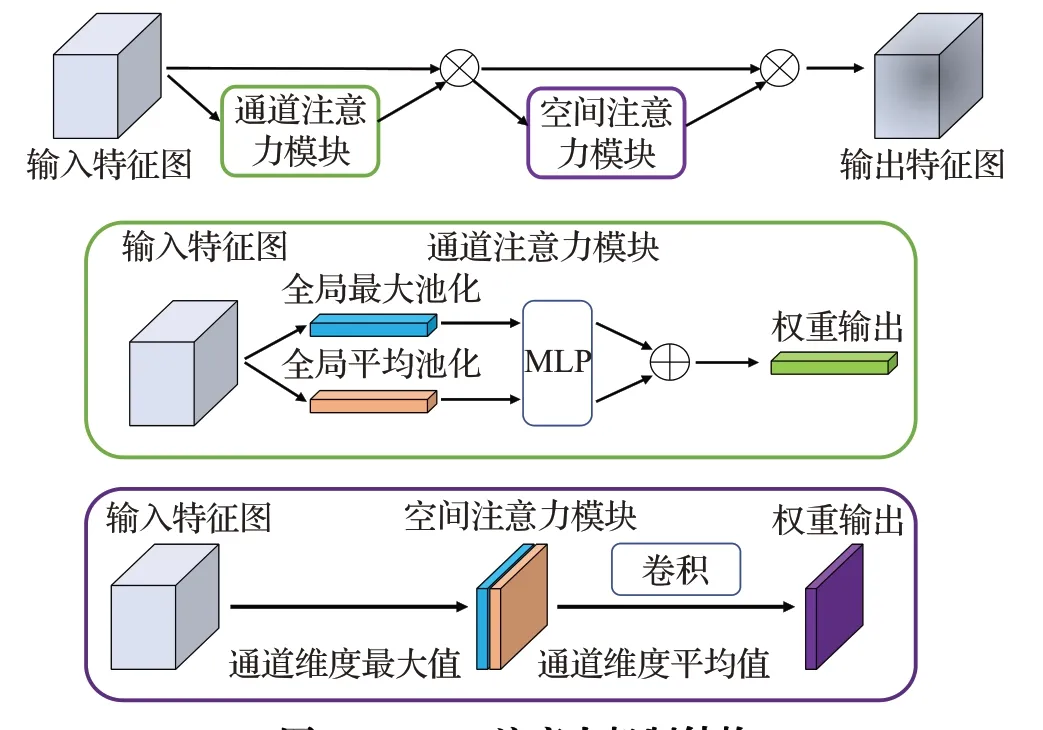
图6 CBAM注意力机制结构Fig.6 Structure of CBAM attention mechanism
通道注意力机制的工作流程为:特征图输入后分别进行全局最大池化和全局平均池化,经过两层共用的全连接层后相加输出通道权重。空间注意力机制的工作流程为:对特征图进行通道维度的最大池化和平均池化,输出结果拼接后经过一次卷积得到空间维度权重。
为了进一步提高模型对小目标的检测能力,在模型中加入了自注意力机制transformer模块,其核心机制是全局关联的建立,公式为:
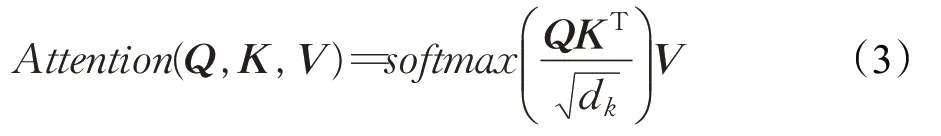
式中,Q代表Query向量,K代表Key向量,V代表Value向量,它们是通过对展平分割后的特征图进行全连接操作得到的,以四维张量的形式表现。dk表示向量的长度,存在的目的是使得训练过程中具有更稳定的梯度。因此在进行向量运算时,特征图中的每个像素都参与了与其他所有像素的计算,所以transformer模块可以构建全局的关联,具有很强的通用建模能力,可以用来获取更丰富的特征信息,但因其较大的参数量和运算量不利于后期的优化部署,本模型仅在处理低分辨率的分支网络中使用,加入的位置为第3、6、9个RFB模块后。加入注意力机制后的模型命名为PHRNet-A,结构如图4所示。
3 实验
3.1 数据集与评价指标
数据集:本文选择用于航空图像中微小物体检测的数据集AI-TOD[23]作为模型训练和检测的基准数据集,具有车辆、船只等8 个种类,包含28 036 张图片共计70 0621 个检测实例。AI-TOD 数据集目标实际大小只有平均12.8 个像素,远小于其他数据集,适合本论文的研究。
评价指标:本文采用平均精度值(average precision,AP)作为评价指标,包括mAP、AP50、AP75、APs和APm。AP50表示目标真实框和模型预测框交并比(IOU)阈值为0.5 时的平均精度值,AP75为0.75,mAP 表示交并比阈值从0.5到0.95之间等间距取10个值,并计算这10个阈值下AP的均值;APs表示检测目标所占像素小于322个像素,APm表示检测目标所占像素在322到962之间。
3.2 实验环境与参数设置
本文实验所用配置环境如表1所示。
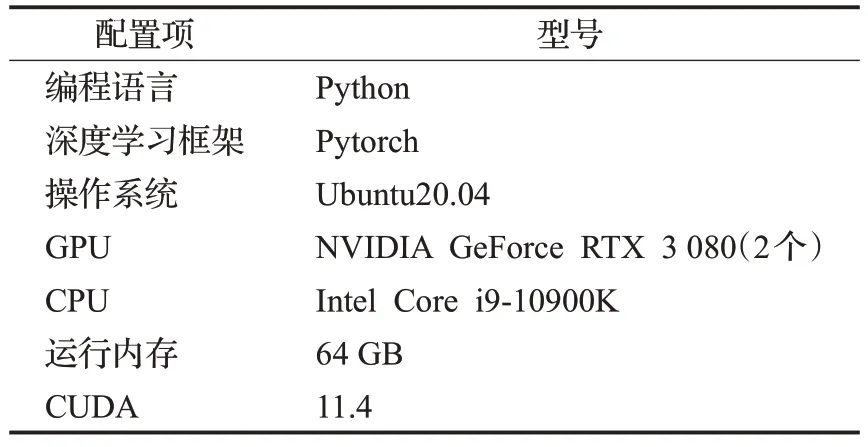
表1 实验环境配置Table 1 Experimental environment configuration
实验参数设置如下:使用AI-TOD 数据集对模型进行训练和测试,输入图片大小缩放为416×416,使用双显卡并行训练,每个显卡的batchsize设置为8;实验采用随机梯度下降算法(stochastic gradient descent,SGD),学习率初始值设为0.1,采用余弦退火算法调整学习率,共训练350 个epochs,在训练前对图像进行翻转裁剪等数据增强操作,对不同模型采用相同参数设置,对比实验结果并分析。
3.3 实验结果分析
3.3.1 不同网络结构对比实验
为了验证所提网络结构的性能,将所提特征提取网络结构与当前常用的相近深度的特征提取网络结构对比,针对不同特征提取网络,使用相同的数据增强方法,在特征提取网络后应用FPN结构,检测头和损失函数都采用Generalized Focal Loss[24],实验结果如表2所示。
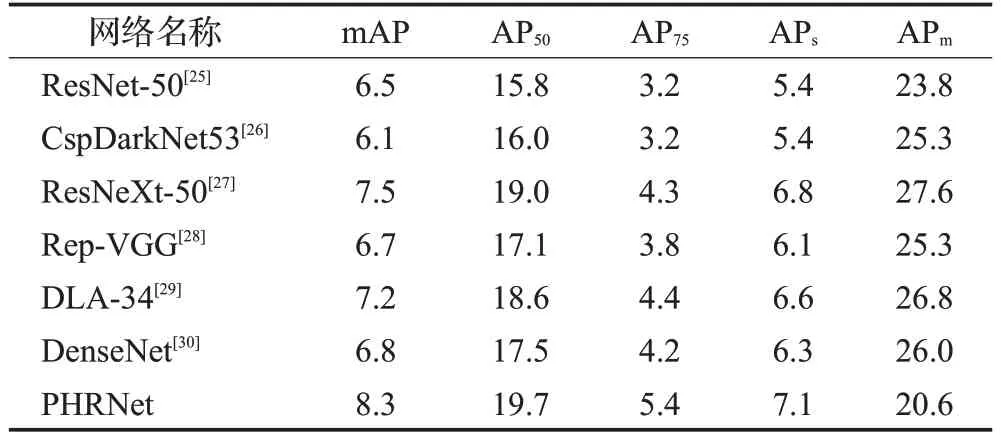
表2 不同特征提取网络在AI-TOD数据集性能对比Table 2 Performance comparison of different feature extraction networks in AI-TOD dataset %
由表2可知,所提的网络结构相较常用的其他模型效果最好,mAP 达到了8.3%。ResNeXt-50 网络具有较高的宽度,DLA-34实现了浅层信息与深层信息的融合,因而这两个模型较为出众,mAP 分别为7.5%和7.2%。本文所提PHRNet兼具以上两个特点,mAP值比DLA-34高1.1个百分点,比ResNeXt-50高0.8个百分点,其他指标表现也十分优异,但在中等目标的检测指标APm上的表现有所欠缺,仅为20.6%。经分析发现特征融合因子的使用,使模型被训练的更加关注小目标而忽视中等目标。实验结果的对比分析表明,本文所提PHRNet 网络结构在小目标检测任务中的表现优于当前主流的特征提取网络,具有良好的特征提取性能,还可以根据实际应用场景的不同调整特征融合因子以适应不同尺度目标的检测。
3.3.2 不同尺度分支输出特性对比
为了进一步优化模型检测能力,通过设置消融实验,探究不同尺度分支输出的特征图对检测结果的影响。实验方法为:使用AI-TOD数据集作为验证集进行测试,每次只保留一个或两个分支输出,其余设为0,假设尺寸缩小1/4的输出特征图为F1、缩小1/8为F2、缩小1/16为F3,消融实验对比结果如表3所示。
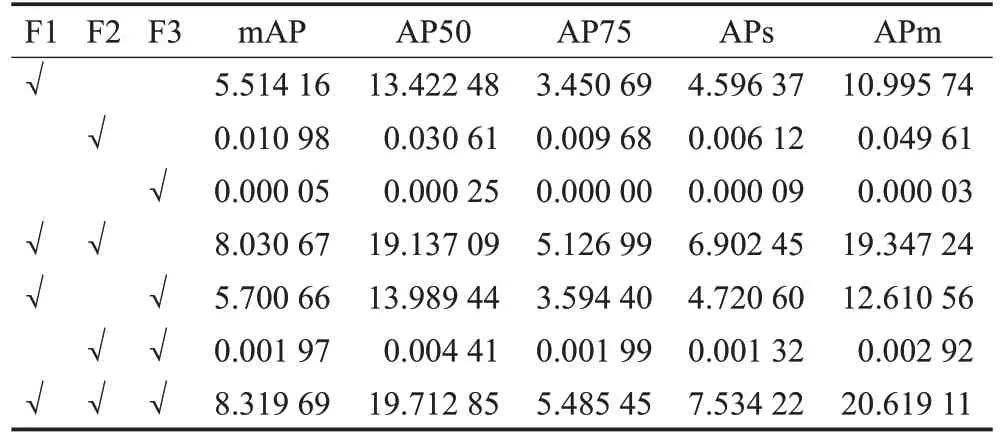
表3 消融实验结果分析Table 3 Analysis of ablation experiment results %
从实验结果可以看出,低分辨率分支的输出特征图对最终检测结果的贡献很小,在将特征图F3设为0后检测精度仅下降了0.3个百分点,而F1特征图和F3特征图同时输出的结果也仅比F1单一输出高了0.2个百分点,可见模型对小目标的检测能力主要来自高分辨率分支。通过实验为模型的进一步优化给出了思路:可以通过减少高分辨率分支的参数量,以最小的精度代价换取检测速度的提升。
3.3.3 多尺度特征融合结构验证实验
为了验证本文所提改进的多尺度特征融合结构的有效性,通过在原FPN+PAN 网络结构的基础上逐步添加亚像素卷积和特征融合因子来进行消融实验,实验结果如表4。

表4 多尺度特征融合结构消融实验Table 4 Multi-scale feature fusion structural ablation experiment
通过实验对比可以看出,改进后的多尺度特征融合结构比原结构表现更优,使用亚像素卷积后平均检测精度上升0.2个百分点,使用特征融合因子后精度上升0.9个百分点,实验结果证明了所提新结构的有效性。
3.3.4 注意力机制相关实验
本文通过加入注意力机制强化模型对小目标的“关注度”,通过将不同注意力模块加入网络进行实验对比,验证本文方法的有效性,消融实验结果如表5所示。
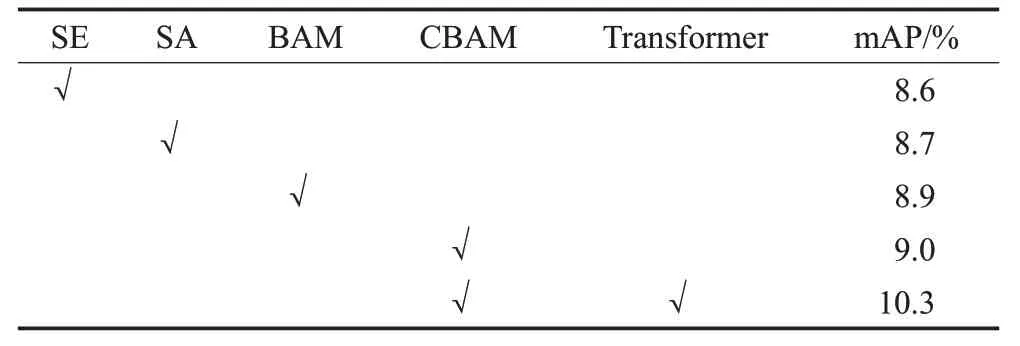
表5 注意力模块消融实验Table 5 Attention module ablation experiment
实验结果表明,BAM 和CBAM 作为兼具通道维度操作和空间维度操作的注意力模块,性能要优于单一维度操作的模块;CBAM 的表现最好,mAP 达到了9.0%,在加入自注意力机制后mAP达到最高10.3%,验证了本文所用方法的有效性。
实验结果证明了自注意力机制Transformer 的应用可以进一步提升模型对小目标的特征提取能力。
3.3.5 可视化结果
为了更直观地验证本文所提模型的有效性,以未加入注意力机制的PHRNet 为特征提取网络的模型与CspDarknet53、ResNet-50、Rep-VGG、ResNeXt-50和DLA-34模型对比,检测一张包含密集小目标航拍图,图7 为模型对比的可视化结果。

图7 可视化结果对比Fig.7 Visual result comparison
从图中可以看出,本文所提模型相较其他常用模型对小目标的检测能力更强,可以检测出更多的小型目标。
为进一步验证本文所提模型的可应用价值,将所提的PHRNet-A 特征提取网络替换到不同的主流目标检测模型中进行测试,得到结果如表6。
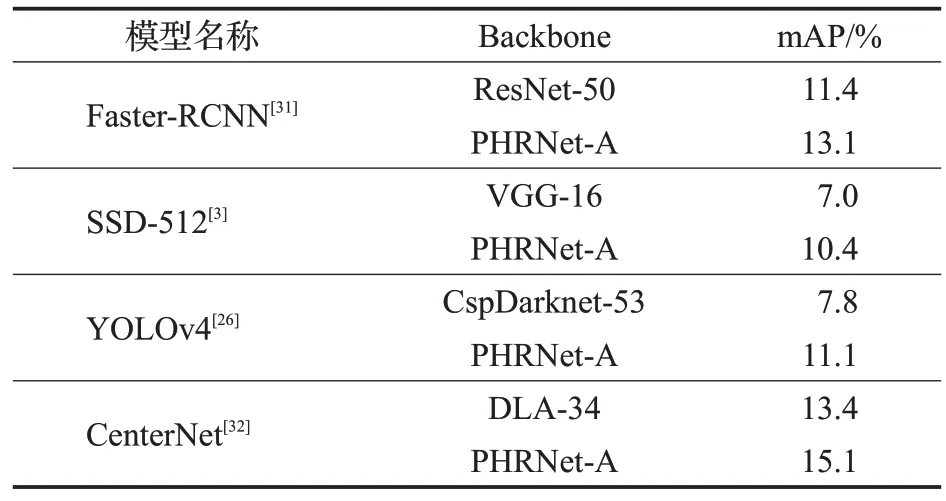
表6 所提网络应用实验Table 6 Proposed network application experiment
对比结果表明,本文所提并行高分辨率特征提取网络能够适用于不同种类的目标检测模型中,提高对小目标的检测能力。
4 结束语
针对小目标检测信息丢失、定位不准等问题,本文在参考经典高分辨率网络结构的基础上,设计了高分辨、多尺度并行的网络结构作为特征提取网络,实现了浅层与深层、多尺度的特征融合,扩宽了网络结构,增强了小目标信息的流通,强化对小目标的特征提取能力。通过引入特征融合因子和注意力机制,引导模型更加关注小目标,进一步提高对小目标的检测能力。
在小目标数据集AI-TOD 上的平均检测精度为10.4%,高于其他主流的特征提取网络,更好地解决了小目标检测困难的问题,可应用于各类目标检测模型替换原有的特征提取网络,适应小目标检测任务。
本文在实验中探究了多尺度分支对检测结果的影响,为模型进一步优化提供了思路,在未来的工作中,将以本文探究成果为指导对模型进行剪枝、压缩等操作,实现模型轻量化处理,提高检测速度和占用的参数量,使模型更易于在移动端部署。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
甘肃教育(2020年22期)2020-04-13
电子制作(2019年13期)2020-01-14
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2019年11期)2019-07-04
电子制作(2018年19期)2018-11-14
北京航空航天大学学报(2018年1期)2018-04-20
