
脸由音生:语音驱动的静动态人脸生成方法
2022-09-21 05:37赵璐璐陈雁翔赵鹏铖朱玉鹏盛振涛
计算机工程与应用 2022年18期
赵璐璐,陈雁翔,赵鹏铖,朱玉鹏,盛振涛
合肥工业大学 计算机与信息学院,合肥230009
人类所发出的声音总是与其本身的诸多特性相关联,例如性别、年龄以及嘴唇开合等,而最能反映这些特性的就是人的脸部。因此,语音驱动人脸生成逐渐成为一个热门的研究课题,其研究目的是挖掘语音与人脸之间的关联性,进而能够由给定的任意语音片段生成相对应的人脸图像。然而语音和人脸之间存在着多维复杂关联,其与单张静态人脸图像之间存在着多重属性关联(性别、年龄等),同时与多张动态人脸序列之间又存在嘴唇同步关联。因此语音驱动人脸生成模型需要综合考虑这两方面的因素,从而能够更好地将其应用于实际生产生活中。
无论是生成静态人脸图像,还是生成动态人脸序列,都面临着巨大的挑战。首先,由于语音信号和人脸图像在数据特征层面存在异质性,因此在没有确切先验信息的前提下,模型需要捕捉到特定的语音特征来编码得到与之对应的人脸图像。其次,动态人脸序列的生成要在时间维度上保持人脸属性特征的不变性,同时所生成的人脸序列应保证语音片段和嘴唇运动之间的同步性。
目前大多数工作在研究这种语音驱动的跨模态人脸生成时,都只考虑了其中一种的关联性来生成相对应的人脸图像,缺乏对语音和人脸图像对应关系的综合研究。例如,Speech2Face[1]通过利用视频中人脸图像和声音在时间和语义这两个维度上的双重相关性,将语音声谱图的特征与预训练的真实人脸的特征在高维空间中相对齐,进而实现由语音生成静态人脸图像。但该模型依赖语音和人脸图像之间严格时序对齐的数据集进行训练,而在实际中由于时间维度的影响,只有很少的数据集标记了这种时间对齐信息,进而导致模型不具有广泛应用性。而本文考虑使用属性对齐(性别、年龄)的语音-人脸图像数据集对模型进行训练,以此来生成属性对应的静态人脸图像。对于语音驱动动态人脸序列生成的研究,Jamaludin等人[2]设计了一种基于编码器-解码器结构的卷积神经网络模型Speech2Vid,该模型以一种自监督的方式使用静态人脸图像和语音片段的联合嵌入来合成说话者的人脸视频帧,但是其将序列生成变换成与时间无关的图像生成,因此容易造成像素抖动。Suwajanakorn等人[3]通过循环神经网络学习原始语音特征到嘴唇区域的映射,进而定位到匹配度最佳的嘴唇区域图像,并将检索出的嘴唇区域图像与原始的人脸图像进行合成以得到最终的目标视频。虽然此方法可以获得高真实感的生成效果,但是其只适用于特定身份的人,缺乏泛化能力。
本文所提出的方法与之前的语音驱动人脸生成模型不同,其综合研究了语音驱动的静态人脸图像生成和动态人脸序列生成,并基于条件生成对抗网络构建了系统模型SDVF-GAN。为了更好地依托该模型生成属性对齐的静态人脸图像,依据现有数据集建立了一个涵盖性别和年龄两种属性的Voice-Face数据集,实现语音与静态人脸之间属性信息的精准对应。同时该模型还利用注意力思想定位到人脸图像中的嘴唇区域,以此细节信息为条件,进一步从给定的语音和身份人脸图像中生成嘴唇同步的动态人脸序列。为了验证本文所提出方法的有效性,对其进行了一系列针对性实验。实验结果表明,SDVF-GAN 不仅可以生成属性对应的高质量静态人脸图像,同时还可生成嘴唇运动与输入语音同步的动态人脸序列。综上所述,本文的主要贡献如下:
(1)本文提出了一种基于条件生成对抗网络的语音驱动静动态人脸生成模型SDVF-GAN,该模型能由给定的语音信号生成属性一致(年龄、性别)的静态人脸图像并在身份人脸图像的条件下生成嘴唇同步的动态人脸序列。
(2)本文基于现有数据构建了一个新的包含语音和人脸图像的数据集Voice-Face,其中语音和人脸图像在性别和年龄上具有属性一致性。
(3)本文在动态人脸生成模型中设计了一个基于注意力思想的嘴唇判别器,通过将嘴唇区域信息与身份相关信息分离,来降低不准确的嘴唇运动所造成的影响,实现在生成高质量的人脸序列的同时进一步提高嘴唇同步的准确性。
1 相关工作
1.1 视听觉跨模态生成
视听觉数据是现实世界中自然共存的两种信号,并且二者都可为对方提供丰富的监督信息,利用视听觉数据进行跨模态学习的研究也因此而取得了很多突破性的成就。Aytar 等人[4]利用视频中音频数据和视觉数据自然同步的特性,通过已建立的视觉识别网络和未标记的视频数据对音频特征提取网络进行训练,进而学习到音频的有效表示。Chen 等人[5]使用条件生成对抗网络来实现视听觉跨模态双向生成,并在多模态数据集Sub-URMP 上实现面向乐器类别和面向演奏姿势这两种不同的训练场景下的视听觉跨模态生成。Hu 等人[6]提出了两种分别针对不同情况盲人的视听跨模态生成模型,实现从编码后的声音生成相应的视觉图像,其目的是验证机器模型可快速高效地评估为帮助盲人而构建的视觉到听觉编码方案的性能与质量。文献[7-8]进一步实现了基于GAN 的语音到人脸图像的跨模态生成,也即在给定语音波形的情况下生成相对应的人脸图像,并保留说话者的身份信息。而本文提出的静态人脸生成模型研究的是如何生成与输入语音信号属性关联(年龄、性别)的静态人脸图像,可使用属性对齐的数据集对模型进行训练,其在实际中的应用范围更加广泛。
1.2 动态人脸生成
动态人脸生成研究在给定目标人脸图像和语音片段的情况下,生成嘴唇运动与输入语音准确同步的说话者人脸序列。近年来,随着生成式模型的不断发展,对于任意人脸序列的生成涌现出众多优秀的模型。X2Face[9]提出一种能够控制给定人脸的姿态和表情的深度神经网络,它是以语音信号(或是另一张人脸图像)作为条件实现任意说话者对应的人脸生成,但是该方法以不受身份信息约束的形式对网络进行训练,使得模型无法针对身份信息生成相应的人脸,并且基于语音生成的人脸图像质量相对不高。Zhou 等人[10]利用对抗训练的思想,通过解耦一张人脸图像中的主体相关信息和语言相关信息来实现任意主体说话者对应的人脸生成,然而该方法主要关注图像在模态内部的一致性,缺乏对跨模态一致性的探索,从而导致生成人脸序列的嘴唇运动与输入语音之间的同步性不够准确。Chen 等人[11]利用面部标志作为中间信息来拉近两种不同模态数据之间的距离,从而实现了说话者对应的人脸序列生成,但是该方法缺乏对视听跨模态的同步性进行建模,因此会出现嘴唇运动不同步的现象。
1.3 注意力机制
注意力机制模仿了生物观察行为的内部过程,是一种将内部经验和外部感觉对齐从而增加部分区域的观察精细度的机制。注意力机制可以快速提取到稀疏数据的重要特征,其最初提出的目的是解决机器翻译研究领域中的文本序列问题。注意力机制本质上源自于人类视觉注意机制,其核心目标是从众多信息中选择出对当前任务目标更关键的信息并聚焦到这些重要信息上,因此注意力机制逐渐发展成计算机视觉领域的重要工具之一。例如Zhang 等人[12]将自注意力机制与GAN[13]相结合,提出了一种新的图像生成模型SAGAN。本文通过将自注意力机制添加到语音编码器网络中以提取出更准确的听觉特征。同时在动态人脸生成模型中,还利用注意力思想捕捉嘴唇区域的特征,进而将身份人脸图像中的身份属性信息与嘴唇运动信息进行分离,以实现在任意身份下生成嘴唇同步的动态人脸序列。
2 Voice-Face数据集
为了满足静态人脸生成网络的训练需求,本文构建了“性别+年龄”属性对齐的数据集Voice-Face。该数据集中包含大量的语音片段和人脸图像,并满足属性一致性。为了切合本次研究的目的,选择了aidatatang_1505zh数据集中的语音片段和CACD2000 数据集[14]中的人脸图像。对于这两个模态的数据,对其按年龄段(11~20、21~30、31~40、41~50)和性别(男、女)进行组合,同时清除了一些质量不佳和不符合要求的语音片段和人脸图像,使得各种组合的数量处于相对平衡状态,最终将得到的语音和人脸图像数据整合成属性关联的Voice-Face数据集。此外,为了更好地利用该数据集对静态生成模型进行训练,还将对其中的数据进行一定的预处理操作,具体步骤如下:
语音预处理:原始的语音信号是由16 kHz的单声道进行采样而得到,在本文的模型中需要将其转换成声谱图作为系统的原始输入。将语音分别转换成短时傅里叶变换(STFT)、梅尔频率倒谱系数(MFCC)和对数振幅梅尔频谱(LMS)这三种声谱图,并对比三者分别作为模型输入时的生成效果,根据模型实际的性能表现,最终选择将语音信号的MFCC特征作为语音编码器网络的输入。
人脸图像裁剪:为了去除人脸图像中多余的背景信息,采用人脸检测器[15]来检测图像中相应的人脸部分区域,进而从整幅图像中裁剪出人脸区域,最后将裁剪后的人脸图像统一缩放为相同的尺寸大小。
最终,经过上述数据预处理操作之后,得到了8 种属性组合下的48 000个语音-人脸图像对,并将其按5∶1的比率划分为训练集和测试集。
3 方法
本文综合考虑语音和人脸之间的静态属性和动态变化关系,在条件生成对抗网络的基础上构建了语音驱动的静动态人脸生成模型(SDVF-GAN)。该模型以给定的语音片段作为输入,能够生成属性一致(性别、年龄)的静态人脸图像,同时能够基于身份人脸图像生成嘴唇同步的动态人脸序列。
3.1 网络架构
SDVF-GAN模型的网络架构如图1所示,其包含编码器、生成器和判别器这三个部分。
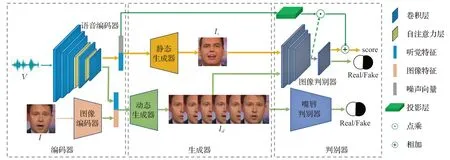
图1 语音驱动的静动态人脸生成模型(SDVF-GAN)的框架结构Fig.1 Frame structure of voice-driven static and dynamic face generation model(SDVF-GAN)
3.1.1 编码器
本文使用基于深度卷积网络构建的语音编码器VE来提取语音信号的听觉特征向量。初始的语音信号是一维波形V,鉴于梅尔频率倒谱系数(MFCC)特征能够很好地表示语音的相关信息,因此将语音信号转换成MFCC特征M以作为语音编码器的输入。由于MFCC特征在某一维度上对应了时序信息,因此对于时间间隔较长的MFCC特征,语音编码器在特征的提取过程中要能够捕捉到它们之间的时间依赖关系。自注意力机制[16]可以模拟图像区域中长距离、多级别的依赖关系,进而可以使得远距离依赖特征之间的距离极大地缩短。因此,在语音编码器VE 中引入自注意力机制可以学习到MFCC中的时序信息,进而提取出更准确的听觉特征向量zv=VE(M)。最后将得到的听觉特征向量作为静态人脸生成网络和动态人脸生成网络的输入,以实现静态和动态的人脸生成。
在动态人脸生成网络中,是将听觉特征和图像特征相串联得到的混合特征作为网络的输入以确保生成的人脸序列中的多张人脸图像在身份信息上的一致性。基于此,构建了图像编码器IE,以提取相应的图像特征向量zI=VE(I),网络参数如表1。
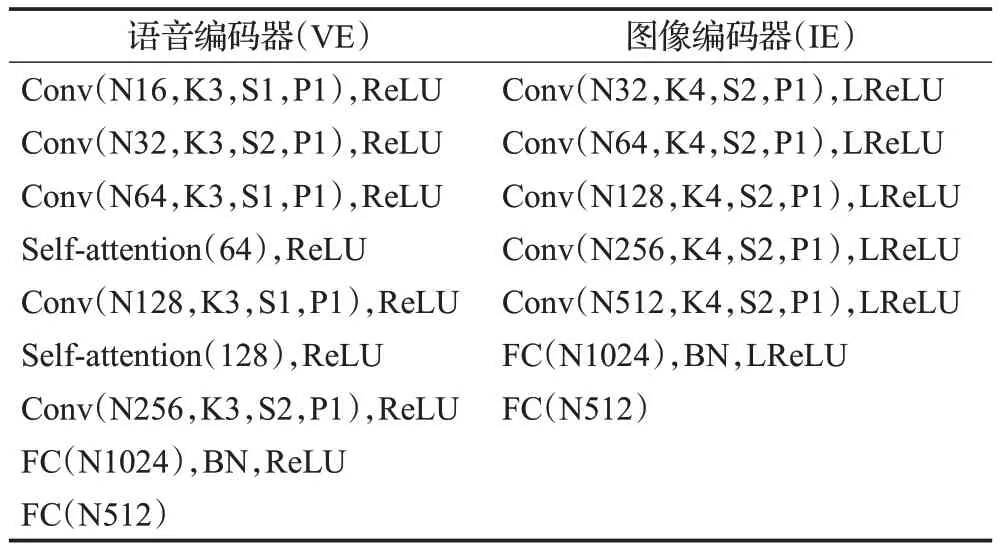
表1 编码器网络架构Table 1 Encoder network architecture
3.1.2 生成器
SDVF-GAN模型是基于条件生成对抗网络(CGANs)[17]的结构而构建。因此,在获取听觉特征向量和图像特征向量后,以听觉特征向量zv与使用标准正态分布采样的噪声向量zn~N(0,1)相串联而得到的高维特征向量作为静态人脸生成器SFG 的输入,进而合成出属性一致(年龄和性别)的静态人脸图像Is=SFG(zv,zn);以听觉特征向量zv与图像特征向量zI串联得到的混合特征向量作为动态人脸生成器DFG 的输入,通过分别考虑语音相关信息和身份相关信息来生成嘴唇同步的动态人脸序列Id=DFG(zv,zI),网络参数如表2。
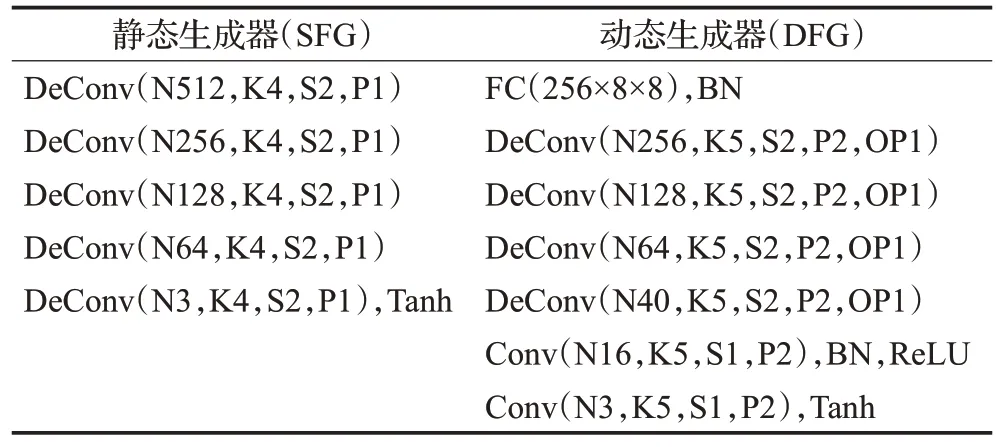
表2 生成器网络架构Table 2 Generator network architecture
3.1.3 判别器
图像判别器以真实图像或生成图像作为输入,输出相应的概率分数,以判别输入图像的真伪。静态人脸生成模型针对的是属性对齐条件下的视听觉跨模态人脸生成,需要在生成高质量的真实图像的同时确保属性的一致性。为了生成符合要求的静态人脸图像,在原始图像判别器的倒数第二层后加入投影层(Projection)[18],以获得一个表示语音片段与人脸图像属性匹配程度的概率分数。具体而言,本文使用x表示输入特征向量,y表示条件信息,同时用D(x,y)=A(f(x,y))表示CGANs的图像判别器,A表示激活函数。pt和pg分别表示真实样本分布和生成样本分布。当使用Sigmoid作为最后卷积层的激活函数时,由CGANs的损失函数可知,最优判别器:
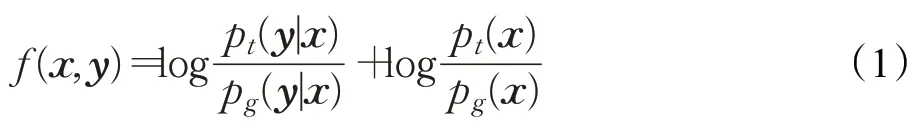
在多分类问题中,一般使用Softmax 函数来计算输入x属于某一类别y=c的概率,则有:
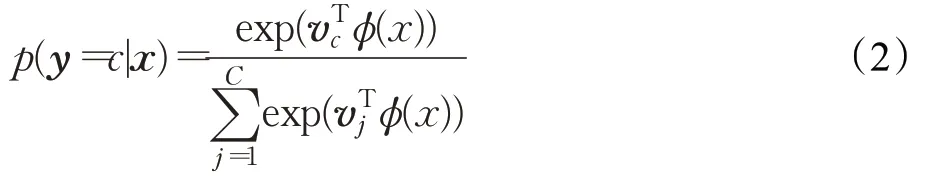
其中,(x)表示全连接层的输出,ϕ为去除最后一层的传统判别器网络。同时令矩阵V表示行向量,并将其看作条件信息y的嵌入层,ψ表示判别器的最后一层,则此时最优判别器可化简为:
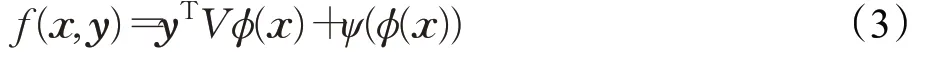
对上式进行分析可知,ψ(ϕ(x))起到了原始CGANs中图像判别器的作用,用于判断输入数据x的真实性;而yTVϕ(x)表示投影层的判别结果,其相当于卷积网络的输出Vϕ(x)与条件y进行点乘得到的对应目标组合的概率值,其值越大表示属性匹配越准确。因此,添加投影模块的图像判别器的输出既表示了图像的真伪,又表示了图像与语音之间的属性匹配度,可更好地推动静态人脸生成器生成与输入语音属性一致的高质量的静态人脸图像。
动态人脸生成网络的目的是生成嘴唇同步的人脸序列。由于图像判别器以人脸图像的整个区域为判别标准来更新动态生成器网络的参数,所以仅利用图像判别器不足以在训练时捕获到精准的嘴唇运动。为了能够在人脸图像中捕获嘴唇相关的变化信息,基于注意力的思想构建了一个嘴唇判别器Dl,通过仅关注嘴唇区域的变化来去除身份相关信息及面部表情的干扰,并将其与图像判别器相结合,二者共同以对抗训练的方式更新动态人脸生成器,以生成嘴唇同步的高质量的动态人脸序列,判别器网络架构如表3。
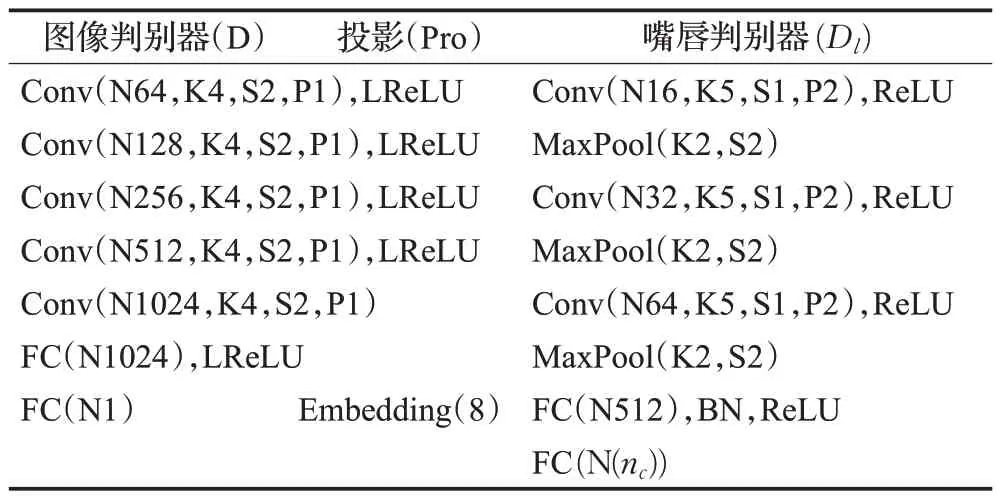
表3 判别器网络架构Table 3 Discriminator network architecture
3.2 损失函数
为防止传统GAN中出现的梯度消失和模式崩溃的问题,SDVF-GAN模型采用了WGAN-GP形式的对抗损失函数。此时,对抗损失函数如下:
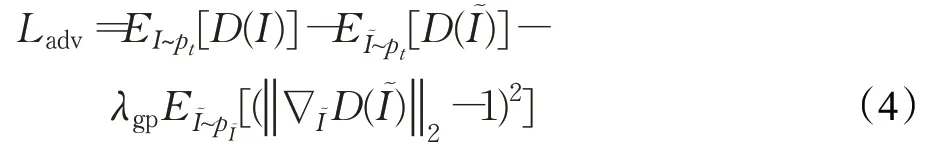
其中,I表示真实图像,I表示生成图像,其在静态人脸生成网络和动态人脸生成网络中分别表示静态人脸图像Is=SFG(zv,zn)和动态人脸图像Id=DFG(zv,zI),而I是沿真实图像和生成图像对之间的直线均匀采样得到的图像。D表示图像判别器,其在静态人脸生成网络中嵌入了投影(projection)模块。
为使得静态人脸生成模型能够生成属性一致的人脸图像,为其构建如下所示的属性损失函数:

为了在动态人脸生成过程中保持身份的不变性,将重建损失应用于动态人脸生成模型中,公式化如下:

如前所述,通过构建嘴唇判别器Dl来确保生成的动态人脸序列具有准确的嘴唇运动,其目标函数:

此时,静态人脸生成模型和动态人脸生成模型的总损失函数分别如式(8)和式(9)所示:
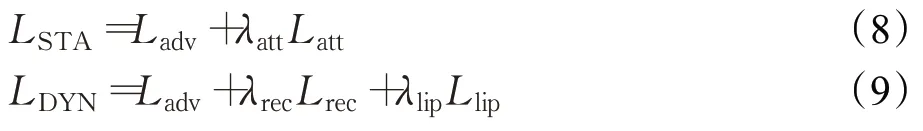
其中,λatt、λrec和λlip是模型中的超参数,它们分别控制模型的属性损失、重建损失和嘴唇损失的相对重要程度,进而更好地对网络模型进行训练。
4 实验
4.1 实验设置
4.1.1 数据集
分别利用自己构建的Voice-Face 数据集和现有的LRW 数据集[19]对静态人脸生成模型和动态人脸生成模型进行训练。对于Voice-Face 数据集,按照两种性别(男性和女性)和四个年龄段(11~20、21~30、31~40、41~50)将其组合成8 种属性类别。而LRW 数据集是目前最大规模的单词级唇读数据集,其包含数百个不同的说话者读单词的视频,每个视频的持续时间很短,只有1 s左右。从LRW 数据集中分别提取音频流和视频帧,并使两者相互匹配。对于音频流,以16 kHz 的采样率提取出(Mel frequency cepstrum coefficient)MFCC 特征;对于视频帧,使用人脸检测器裁剪出相应的人脸区域,然后将人脸区域的图像维度调整为128×128。
4.1.2 实现细节
SDVF-GAN 中的语音编码器、图像编码器、生成器和判别器都是由卷积层或反卷积层搭建而成。对于语音编码器网络,在最后两个卷积层之前都添加了一个自注意力层来捕获语音中的长距离依赖信息,并在最后一层卷积层后添加了两个全连接层来得到听觉特征向量。动态人脸生成器中借鉴了U-Net[20]的思想,其将图像编码器中各卷积层的图像特征分别馈送到生成器网络中,以更好地保持生成的动态人脸序列身份信息的一致性。在实验中,使用Pytorch 框架来实现整个系统模型。训练时的参数细节如下:选用ADAM 优化器[21],其中α=0.5,β=0.999,并将学习率固定为1E-4;WGANGP 中的梯度惩罚参数λgp设置为10,同时将λatt、λrec和λlip分别设置为10、10和1。算法1和算法2分别说明了本文中所提出的静态人脸生成网络和动态人脸生成网络的优化训练过程。
算法1 静态人脸生成模型的训练流程

算法2 动态人脸生成模型的训练流程


4.2 评价标准
在实验中,选用几个常见的评价指标来定量评估SDVF-GAN 模型的生成效果。对于静态人脸生成模型,其通过跨模态准确率(cross-modal accuracy)来定量评估属性组合的跨模态人脸生成是否成功。此外,Fréchet inception distance(FID)通过计算真实图像和生成图像在特征向量上的距离来定量评估生成的静态人脸图像质量的好坏,具体公式如下:
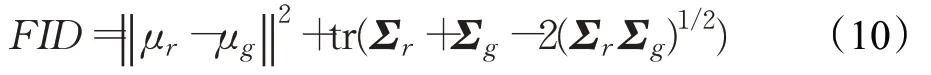
其中,μr和μg分别表示真实图像和生成图像特征的均值,Σr和Σg分别表示真实图像和生成图像特征的协方差矩阵。FID值越小,表明生成数据与真实数据之间的分布越接近,生成的静态人脸图像质量越高、多样性越丰富。
对于动态人脸生成模型,使用常用的度量指标peak signal-to-noise ratio(PSNR)和structural SIMilarity(SSIM)[22]来评估生成的视频帧质量的好坏,两者的值越大,说明生成人脸序列的质量越好。此外,采用landmarks distance(LMD)[23]来评估生成人脸序列中嘴唇同步的准确性。LMD通过计算真实序列和生成序列之间的关键点距离来度量嘴唇同步准确率,其值越小,表明合成人脸序列的嘴唇运动与输入语音片段的匹配程度越高。
4.3 静态人脸生成实验
静态人脸生成模型的目的是实现属性一致(性别、年龄)的视听觉跨模态人脸生成,因此,使用自己构建的基于性别和年龄属性对齐的Voice-Face 数据集对模型进行训练和测试。为了验证模型所生成的静态人脸图像具有一定的优越性,本文从定性和定量角度对实验结果进行分析,并将其与最近的方法进行定量对比,同时针对自身模型架构及损失函数进行了消融研究实验。
定性结果。图2显示了8种不同属性组合下的语音片段分别作为静态人脸生成模型的输入时,所生成的相应组合下的静态人脸图像。从中可以观察到,SDVFGAN 能够学习到声音和人脸之间的潜在联系,其生成的人脸图像和真实的人脸图像对应的属性信息(年龄、性别)是一致的。此外,还为每个组合选取多个不同的语音片段分别送入静态网络模型中来进行相应的实验,实验结果如图3所示,可以观察到SDVF-GAN在生成属性一致的静态人脸图像的同时还可以保持生成图像的多样性。
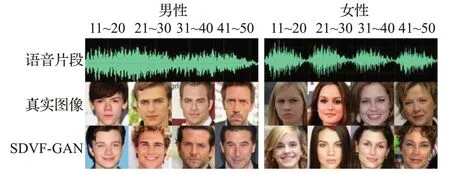
图2 静态人脸生成模型合成的静态人脸图像Fig.2 Static face image synthesized by static face generation model

图3 选取不同语音片段所生成的静态人脸图像Fig.3 Static face image generated by selecting different voices fragments
定量结果。使用Voice-Face数据集对Wen等人[7]提出的模型进行训练和测试,并将其与本文提出的静态人脸生成模型进行定量比较,具体实验结果如表4 所示。结果显示SDVF-GAN在两个常用的评价指标下均明显优于Wen 等人的方法,表明了SDVF-GAN 模型不仅可以生成高质量的静态人脸图像,而且在8种属性组合下的跨模态分类准确率也相对更高。

表4 Voice-Face数据集中不同方法的定量结果Table 4 Quantitative results of different methods in Voice-Face dataset
消融研究。为了定量评估静态人脸生成模型中各组成部分(自注意力机制(SA)、投影模块(Pro)以及属性损失Latt)对生成效果的影响,通过逐一移除模型中的某个组件来进行相应的消融研究实验,实验结果如表5所示。由表中的数据可以看出,当仅去除网络模型中的自注意力机制时,跨模态准确率下降了将近3.1 个百分点;仅去除投影模块时,FID 的值相比提高了5.2 左右,也即生成图像的质量有所下降;而当同时去除这两个组件时,跨模态准确率和FID 更是都朝着变坏的方向发展。这表明模型中加入这两种组件不仅有助于降低FID值以提升人脸图像的生成质量,同时还可使得模型生成出的人脸图像与输入语音具有更好的属性一致性。此外,表5 中的结果还反映出添加属性损失Latt可进一步提高跨模态准确率,定量表明了属性损失的添加对静态人脸生成模型的性能具有一定的提升。
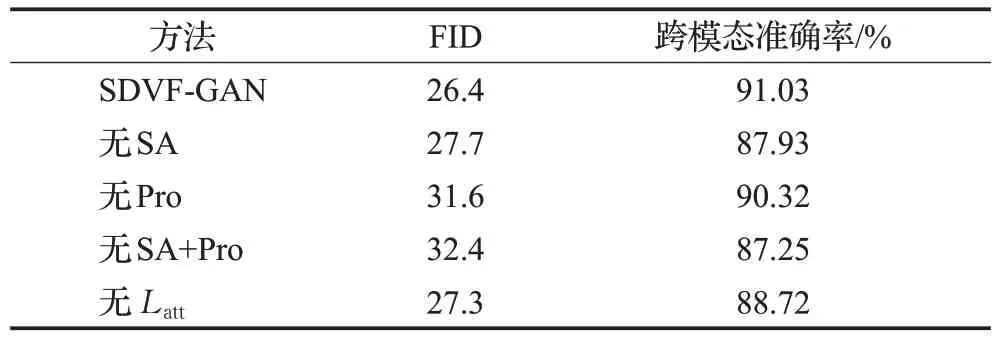
表5 静态人脸生成模型的消融研究Table 5 Ablation research of static face generation model
4.4 动态人脸生成实验
使用现有的LRW数据集来训练和测试SDVF-GAN中的动态人脸生成模型,以实现嘴唇同步的动态人脸序列生成。
定性结果。为了验证本文所提出动态人脸生成模型的先进性,在相同的实验设定下,将其与ATVGnet 模型进行定性对比,具体实验结果如图4所示。可以直观地看到,相较于ATVGnet模型来说,SDVF-GAN所生成的人脸序列与真实人脸序列在嘴唇运动方面的同步性更好,并且生成的人脸图像更加清晰。因此,无论从图像质量还是嘴唇同步来说,SDVF-GAN 模型的生成结果与先前的方法相比均有一定程度的提升。

图4 动态人脸生成模型以及ATVGnet模型的生成结果Fig.4 Synthesis result of dynamic face generation model and ATVGnet model
定量结果。将本文的动态人脸生成模型与ATVGnet[11]和Speech2Vid[2]模型进行定量比较,具体实验结果如表6所示。结果表明SDVF-GAN模型相比于其他的方法虽然在评价指标PSNR上略低于ATVGnet模型,但其同时取得了最高的SSIM 和最低的LMD。这也定量说明了SDVF-GAN 可以在保证生成较高质量图像的同时实现嘴唇运动与输入语音片段之间的精准同步。
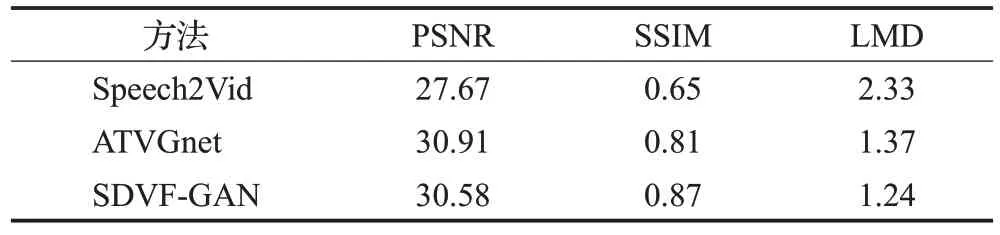
表6 LRW数据集中不同方法的定量结果Table 6 Quantitative results of different methods in LRW dataset
消融研究。为了验证动态人脸生成模型中的自注意力机制(SA)和嘴唇判别器Dl对于模型性能提升的重要性,同样进行了相应的消融研究实验来量化这两个组件对模型性能的影响,具体实验结果如表7所示。实验结果表明,SA和Dl两个组件逐一添加到模型中都可进一步提高所有评价指标的性能,两者联合作用下更是使模型达到了最优的生成效果。这也定量说明了自注意力机制和嘴唇判别器对动态人脸生成模型生成高质量的嘴唇同步的动态人脸序列有着至关重要的作用。
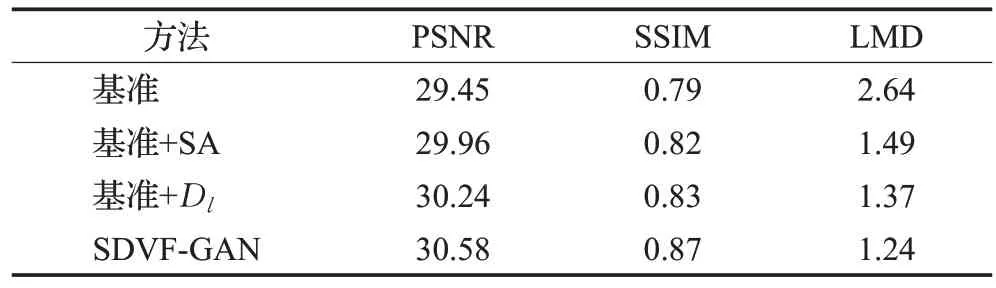
表7 动态人脸生成模型的消融研究Table 7 Ablation research of dynamic face generation model
5 结束语
本文研究了语音与人脸之间静态和动态的关联性,提出了一种可生成静态人脸图像和动态人脸序列的语音驱动人脸生成模型SDVF-GAN。模型的语音编码器在自注意力机制的作用下捕获语音数据的全局听觉特征,在静态人脸生成网络中通过将投影模块加入到图像判别器中以约束静态生成器生成出属性一致(性别、年龄)的静态人脸图像。同时,本文设计了一种基于注意力思想的嘴唇判别器,用于实现嘴唇区域与身份信息的分离,以在动态人脸生成网络中校正不准确的嘴唇运动,进一步提高生成的动态人脸序列的嘴唇运动与输入语音片段之间的同步准确率。
实验结果表明,SDVF-GAN 模型生成的静态人脸图像具有高质量、多样化以及属性一致(性别、年龄)的特点,生成的动态人脸序列的嘴唇运动与输入语音片段具有高同步性的特点。此外,与现有方法对比发现,SDVF-GAN 在跨模态准确率和嘴唇同步准确率方面均取得了更优异的表现。
在现有的工作基础之上,本文认为后续的工作可以从以下两个方面进行。首先,对于训练静态人脸生成网络的Voice-Face数据集,本文只考虑了性别和年龄两种属性,使得属性组合相对较少。未来的工作中可进一步添加人的情感属性,更深层次的挖掘语音和人脸的属性关系,提高静态人脸生成网络的应用范围。其次,未来可在动态人脸生成网络中实现生成的面部序列具有与输入语音同步的表情变化,从而获得更加逼真的视觉效果。
猜你喜欢
云南画报(2021年8期)2021-11-13
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
北京航空航天大学学报(2021年6期)2021-07-20
动漫星空(2018年9期)2018-10-26
小学生学习指导(低年级)(2018年9期)2018-09-26
延河(2017年7期)2017-07-19
专用汽车(2015年1期)2015-03-01
奇闻怪事(2014年5期)2014-05-13
阅读与作文(小学高年级版)(2006年5期)2006-05-16
