
基于生成对抗网络的图像动漫风格化
2022-09-21 05:37王一凡赵乐义
计算机工程与应用 2022年18期
王一凡,赵乐义,李 毅
四川大学 计算机学院,成都610065
近年来,动画电影的受众逐渐扩大,越来越多的人开始喜欢具有卡通效果的图片,但是,不是所有的图片都能转换为动漫风格且融合得很好,也不是所有人都能达到相应的画图水平可以自由作画,再者,手工作图也是费时费力的,目前也没有一款工具可以让人们进行便捷操作就能够得到动漫风格的图片,而漫画场景的应用其实是很广泛的,如儿童图书、书本插画等等。生成对抗网络一直以来都是研究热门,近年来也有多种GAN网络被提出,在各个方面都得到了很大的优化和利用,也有很多突破性的成果。在生成对抗网络中也有许多分支,风格迁移一直都是热门研究之一,如CycleGAN[1]、MUNIT[2]、DualGAN[3]等。大部分的风格迁移模型相对来说都是广泛的,并没有针对各种风格进行单独的适配,所以在不同风格的应用效果上就存在一定的差异,也并不是所有图片和风格都能达到想象中的效果。动漫图片的色彩、线条和边缘等等与现实图片本就具有较大的差别,所以结合生成对抗网络进行这方面的研究就很有意义,同时针对动漫化的风格,还需要对网络结构等进行单独适配和调整,为了达到良好效果还需要进行较多的实验和改进。
本文针对上述问题,提出了以下几个方面的改进:
(1)在GAN 网络的生成器中引入多层感知机模块(multi-layer perceptron,MLP),加入噪声的输入。
(2)引入自适应实例归一化层(AdaIN[4]),修改网络结构,使得内容特征能够很好地转变为样式特征。
(3)将损失函数分为两个部分,对网络和内容分开进行损失计算。
(4)增加图片数据集,对动漫图片和现实图片集进行扩充,完善训练效果。
1 相关工作
1.1 GAN
生成对抗网络一直以来都受到了大家的广泛关注,它具有强大的功能,可以应用到任何类型的数据中,例如图像生成、图像修复等。
生成对抗网络的思想源于二人博弈理论。生成器G生成可以骗过判别器D的样本,而判别器D找出生成器G生成的“假数据”。假设用1 来代表真实数据,0代表生成的数据。对于判别器来说,如果是真实的数据,它要尽可能地判别并输出1,在这个过程中,生成器也会随机生成假数据来输入给判别器,判别器对这部分数据要尽可能地判别并输出0。生成器和判别器是两个相互独立的模型,没有联系,好比两个独立的神经网络模型,利用的是单独交替迭代训练的方法对这两个模型进行训练。通过不断地循环,两边的能力都越来越强。
在Goodfellow 等人[5]的论文中,有几个重要的数学公式描述,如下列式子。

这个公式的优势在于固定G,描述的是一个极小极大化的过程,也就是两个不断优化的过程。其中,Pdata表示的是真实图像的数据分布,用极大似然估计。V这个函数算的是Pdata(x)和PG之间的距离。训练判别器D网络,去最大化这个距离,只有得到最大化距离的结果,才表示判别器是成功的,一旦有了这个值,就可以训练生成器G,从而得到V的最小值,最小的时候说明已经找到了网络的最优解。
1.2 图像到图像转换
Isola等人[6]第一次提出了基于条件生成对抗网络的图像转换。类似于语言翻译,作者提出了图像翻译的概念,希望训练后的网络能够像翻译语言一样,完成图像转换的工作。后来,又出现了生成高分辨率图像的Wang GAN[7]。现在,已经有许多研究人员利用生成对抗网络进行这方面的研究。图像到图像的转换在很多方面都可以进行应用,其基本思想就是将输入图像转换为输出图像,例如:输入一张狗的图片,输出的是猫的图片;输入一张风景照,输出的是中国画图片等。在本文中,经过训练,能够将真实图片转换为具有动漫效果的图片,这个过程其实也是图像到图像的转换。
在之前很多的研究中,人们都是利用成对的数据集进行训练,但是其实成对的数据集并不多,收集此类数据也比较耗费时间和资金,特别是在艺术风格的迁移中就更困难了。CycleGAN[1]提出了在非成对数据下进行图片转换的思想,这一思想的提出,给图片转换带来了大大的便利,解决了需要配对训练数据的问题。如图1,CycleGAN 可以理解为两个单向的生成对抗网络,它们共享两个生成器,再各自带一个判别器,同时,在映射中加入循环稳定损失函数,就可以完成非成对的图像转换。
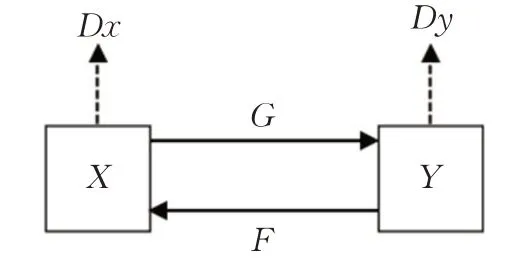
图1 CycleGAN原理Fig.1 Principle of CycleGAN
文献[2]中提出了多模态无监督的图像转换,在生成图片时可以把同一个内容和不同的样式组合,从而输出多态图片。自动编码器结构如图2,由内容、样式编码器以及联合解码器组成。样式编码器利用全局池化得到风格,解码器中使用了自适应实例归一化层将两个编码器进行整合,同时使用MLP网络生成参数,辅助残差块。本文也参考了其结构进行优化,以达到更好的效果。

图2 MUNIT自动编码器结构Fig.2 Auto-encoder architecture of MUNIT
文献[8]提出了一种基于GAN 的图像卡通化方法,通过三个白盒分别对图像的结构、表面和纹理进行处理,得到了较好的图像转换方法。文献[9]也提出了基于GAN 的卡通转换图像方法,可以利用真实景物图片生成漫画,后文也会进行对比。
1.3 风格迁移
图像到图像的转换算法成功,在图像生成的领域又有了一个新观点,也就是可以从卷积神经网络中提取特征,作为目标函数的一部分,通过比较待生成图片和目标图片的特征值,令输出图片和目标图片在语义层面上更相似。
风格迁移的目的是需要保持图像的内容不变,只是转换它的风格,这一点就和图像到图像的转换紧密相关。
Gatys 等人[10]曾提出用CNN 来做风格迁移,文中发现,在卷积神经网络中内容和风格表示可以分离进行独立操作。作者利用卷积神经网络从图片中提取内容和风格信息,再分别定义内容和风格损失进行约束,从而生成指定内容和风格的图片。在卷积网络中,从越高层次中提取出的特征是更加抽象的语义信息,和图片有关的内容信息就越少,文中也进行了对比发现利用更高层次的特征来转换风格的话,图片的内容细节就容易丢失。之前,也有人提出对文献[8]的改进。Li等人[9]在深度特征空间中引入一种基于马尔可夫随机场(MRF)的框架来实现。
Ioffe 等人[11]引入一个批归一化层(BN),通过归一化特征统计,明显地简化了网络的训练。在之后,Ulyanov等人[12]又发现,利用IN层替换BN层,又可以得到显著的改善。
现在也有很多比较成功的风格迁移方法,但是这些方法都不是单独针对动漫风格进行研究的。在本文中,需要输出的图片内容和内容图片接近,输出图片的风格变为动漫风格。引入了噪声的输入,生成风格编码,同时针对内容进行单独损失计算,提高迁移的质量,在后续测试中效果表现良好。
1.4 感知损失
对于人类来说,判断两个图像之间的相似性是非常容易的。但是对于机器而言,这个过程就相对复杂了。目前也有一些感知指标被广泛使用,但是都是相对简单的函数,无法跟人类细微的感知相比较。在文献[13]中,作者利用感知损失函数的优势,训练一个前向传播的网络进行图像转换,在训练的过程中,感知误差衡量了图像之间的相似性,起到了很好的作用。网络架构同样也是他们的亮点,由图像转换网络和损失网络组成,结构与生成对抗网络较为相似,与GAN 不同的地方在于,损失网络是固定参数的,图像转换网络类似于生成器,但是它的损失为感知损失,也就是利用真实图片的卷积得到的特征和生成图片卷积得到的特征相比较,使得内容和全局结构接近,也就是感知的意思。实验结果显示速度提升了三个量级,视觉效果也更好。
Zhang 等人[14]为了衡量所谓的“感知损失”,提出了一个新的人类感知相似度判断数据集,能够评估感知距离,不仅可以度量两个图像之间的相似性,而且还符合人类的判断。越来越多的研究工作发现,利用感知损失函数可以生成高质量的图像,感知损失的出现也证明它可以作为图像生成中辅助工具。在本文中,也选择感知损失函数来计算内容损失。
2 动漫风格化编码的生成对抗网络
2.1 网络框架
本文在生成对抗网络的基础上,引入了几个新的模块。
网络结构如图3所示,由生成器和判别器组成。生成器负责生成可以以假乱真的图像混淆判别器,而判别器则需要鉴别图像是真实图像还是合成的图像。
本文在生成器的部分相比与原始GAN做了较大的优化和改进,新增部分如图3中红色虚线部分所示。生成器包括编码器、特征转换器和解码器,图片输入到编码器,经过一系列的操作之后输出风格图片,同时作为判别器的一部分输入,当然,真实图片也是判别器的一部分输入,经过下采样之后得到输出。与文献[2]的结构相比本文网络结构进行了一定的简化,文献[2]中采用了对偶学习的方式,使用两对生成对抗网络进行训练,本文只使用一对生成对抗网络,只是新增模块对网络结构进行优化,专注于动漫风格的提取。
在生成器中,包含三个上采样层和三个下采样层,还加入了特征转换器,将原始图像的特征转换为生成图像的特征,具体的结构如图3所示。一般的残差块由卷积层、BN 层和ReLU 层组成,本文中也进行了修改,引入了MLP 层、卷积层和自适应实例归一化(AdaIN)层。首先,加入随机噪声作为输入,进入MLP层转变为风格编码后,进入AdaIN层,再输入到残差模块,组成生成器的一部分。
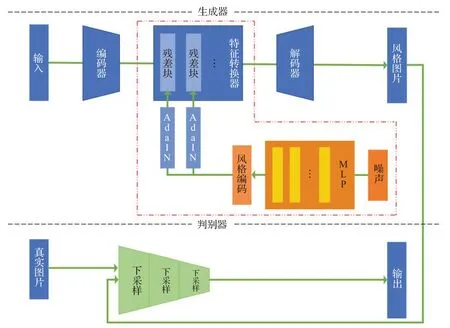
图3 本文网络结构Fig.3 Proposed network structure
在Huang 等人[4]的论文中,他们在CIN[15]的基础上提出了AdaIN,算式如下,和BN、CIN 等不同,AdaIN 没有可学习的仿射参数,它可以根据输入的风格图片,自适应地从样式输入中计算仿射参数。

其中,x代表的是原始的内容图像,y表示的是经过MLP 变换得到的风格编码,σ和μ分别代表均值和标准差。该式子先将内容图像经过归一化,均值为0,标准差为1,然后再乘以风格的标准差,加上风格的均值,也就是先将自身去风格化,然后再和风格特征进行计算,这样内容和风格图像的均值和标准差就对齐了。该方法没有引入其他的参数,自动计算出均值和方差,只需要一次前向网络就可以完成风格网络的生成,不仅节省内存同时还减少了计算时间。该方法在后来也被应用于各种网络,也证明其具有较大优势。应用于本文的网络中大大改善了实验效果。简而言之,AdaIN通过传递特征统计信息,特别是通道的平均值和方差,在特征空间中进行样式传递。
神经网络在机器学习领域中是被广泛应用的,在本文中选择了多层感知机(MLP)。MLP是一种前向结构的神经网络,它包括输入层、输出层以及若干隐藏层,层与层之间是全连接的。三层感知机的结构如图4。

图4 三层感知机结构Fig.4 Structure of 3-layer percetron
假设有m个样本n个特征,则输入层X∈R(m×n),设隐藏层有h个神经元,则隐藏层的权重和偏差为Wh∈R(n×h)、bh∈R(1×h)。输出的标签值有q个则输出层的权重和偏差参数分别是W0∈R(h×q)、bh∈R(1×q)。隐藏层的输出和输出层的输出通过下列式子计算,可以知道,后一层的输入就是前一层的输出。

上述两个式子是对数据进行的线性变换,同时还要引入激活函数对除去输入层的部分进行非线性变换,得到结果后再传递给输出层。
引入MLP 和AdaIN 这两个模块后,网络结构有了较大的调整,对于无监督的训练学习能够得到更好的结果。解码器根据得到的特征重建图像,从而得到效果更好的风格图片。同时,生成器和判别器交替训练、互相对抗,各自也都得到更好的结果。
2.2 损失函数
本文架构共包含两个损失函数。Lpips函数作为内容的损失函数进行计算,BCEWithLogitsLoss 函数作为对抗损失。
2.2.1 Lpips函数
在风格迁移中,选择用一个感知损失函数来训练网络。计算感知相似度需要逐层计算网络输出对应通道的余弦距离,然后计算距离在网络空间维度和层之间的平均值。在文献[16]中,作者为了验证模型是否可以学习感知,对算法提出了三种变种,统称为Lpips。Lpips的确在视觉相似性的判断上更加接近人类的感知,是很优秀的算法。
公式(5)描述的是在网络中如何计算块x和x0之间的距离。首先从L层中提取特征堆栈,在通道维度中进行单元归一化,将得到的结果记为利用向量wl∈缩放激活通道并计算l2的距离,最后在空间上算出平均值,然后基于通道求和。

感知相似性其实并不是一个特殊的功能,它是对一些结构进行预测的视觉特征的结果。例如,在语义的预测中,有效的欧几里德距离也是感知相似度判断的高度预测的表现。
2.2.2 BCEWithLogitsLoss函数
对于对抗损失采用的是BCEWithLogitsLoss函数进行计算,它将Sigmoid 和BCELoss 合为一个步骤,计算过程与BCELoss相似,只是多加了一个sigmoid层,数值也更加稳定。它们是一组常用的二元交叉熵损失函数,常用于二分类的问题中。BCELoss式子如下,其中y是target,x是模型输出的值。

BCEWithLogitsLoss函数的表示如下:
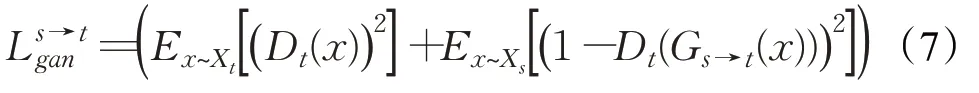
3 实验过程和分析
3.1 实验准备
为了达到更好的实验效果,动漫数据集从宫崎骏的动画电影《千与千寻》《起风了》和《龙猫》中进行截图,同时要保证每张图片内容没有重复,没有相似,扩充得到了4 427张256×256的图片。自定义现实图片集也同样通过网络搜集得到共3 700张,包括各类风景、人物以及动物等图片。
本文实验均在Windows10系统中完成,在深度学习框架pytorch+cuda10.1,NVIDIA2080下进行训练。训练分为两个过程,先是初始化预训练10 个epoch,再进入训练,epoch 为500,batch size 为4,初始学习率设置为0.000 2。
在初始化阶段,引入文献[17]的思想,对生成器网络进行预训练,重建输入图像,帮助网络在适当阶段收敛,同时也提高了样式传输的质量。
3.2 实验结果及分析
图5 为选取的部分实验结果图,第一行为现实图片,第二行为原始网络生成的动漫化图片,第三行为CycleGAN的生产结果,第四行为本文网络生成的结果。

图5 部分实验结果Fig.5 Part of experimental results
可以看出,原始的GAN 算法容易产生不稳定的效果,如第二行第四列,细节如图6,图片上方的纹理感明显,色彩变化太大;而且原始算法的整体色彩都比较暗,饱和度较低,特别是图像四周边缘的色彩不均衡,与输入图片差距过大。而CycleGAN 的生成效果也并不理想,在色彩的处理上相对来说比较不真实。本文的网络在整体的色彩、纹理以及细节的处理方面都比原始的网络有很大的提升,再现了清晰的边缘和光滑的阴影,生成的图像稳定性也较高,本文的模型结果是高质量的。

图6 细节对比Fig.6 Detail contrast
同时,还进行了两次对比实验,分别替换掉了两个损失函数,部分测试结果如图7。

图7 部分对比实验结果Fig.7 Part of contrast experimental results
第二行为替换掉Lpips 函数的结果,第三行为替换掉BCE函数的结果,最后一行为本文效果。可以看出,即使有相同的网络架构,如果不选用本文的两个损失函数,结果仍然有较大的偏差。比如第二行的第二张图片,颜色上有明显的偏绿,而第四张图片又明显的颜色很淡,效果不稳定;观察第三行也可以发现,整体图片的颜色饱和度过低,纹理等与真实图片没有太大的差别。而本文的效果在向动漫风格进行转变的同时又有很好的色彩还原度。
另一方面,增加了几种卡通动漫风格转换方法的对比,部分结果展示如图8,第二行为WhiteboxGAN 的生成结果,第三行为CartoonGAN的生成结果,最后一行为本文效果,可以看出在图像的还原度上本文是较为优秀的。同时细节对比如图9。可以发现,WhiteboxGAN的生成结果虽然色彩比较接近真实图像,但是纹理过于失真,生成效果不协调,而CartoonGAN色彩的处理上不够真实,同时细节部分容易产生模糊效果,生成效果不理想,而本文在细节以及色彩的处理上仍然较好。

图8 卡通风格方法对比Fig.8 Cartoon-style method contrast

图9 细节对比Fig.9 Detail contrast
通过多次实验发现,本文得到的效果还是比较令人满意的。
3.3 评价指标
对于动漫图像的评判其实没有一个准确的标准,大部分情况下人们都是通过自我感觉去衡量。选择用Fréchet inception distance(FID)[17]来评价实验结果。FID专门用于生成对抗网络性能的评估,它是合成图像和真实图像之间的特征向量距离的一种度量,距离越小,值越小,说明生成图像与真实图片的分布越接近,则实验效果越佳,模型越好。两个分布的距离公式如式(8):

x代表真实图像的分布,g代表生成图像的分布,u、C代表提取特征之后特征向量的均值和协方差,tr 代表矩阵对角线上元素的总和,也就是矩阵的迹。FID对噪声有很好的鲁棒性,用在本文中也非常合适。
由表1 中的数值可以看出本文的模型效果有了较大的提升,FID 分数明显优于原始网络、CycleGAN、CartoonGAN和WhiteboxGAN很多。

表1 FID分数Table 1 FID score
4 结束语
本文基于生成对抗网络的思想,提出了动漫风格化编码的生成对抗网络,目的是将输入的现实图片转换为宫崎骏动画电影的动漫风格输出。调整并优化网络结构,引入了AdaIN 和MLP 模块,增加噪声的输入,能更好地提取风格编码,增加内容的损失函数,调整对抗损失函数,同时扩充了实验数据集,增加了动漫图片和现实图片。实验结果说明效果良好,与原始网络相比得到了较大的提升,边缘细节也能处理到位,FID 分数有了较大进步。证明本文网络能够应用于各种图片的动漫风格输出。
图像到图像的转换目前仍然具有很大的挑战性,大多数的研究都是针对局部处理的,如人脸等。在无监督领域中,还有很多问题值得去探索。在接下来的学习中,将继续进行这方面的研究,争取继续减小FID分数,在细节上取得更好的结果,同时研究如何提高图像的分辨率和网络的稳定性、准确性,争取不仅是动漫的风格,如油画等的艺术风格迁移方面都能得到更好的效果。
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
中学生数理化·中考版(2021年3期)2021-07-22
数学小灵通·3-4年级(2021年5期)2021-07-16
新世纪智能(数学备考)(2020年9期)2021-01-04
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
今日农业(2019年15期)2019-01-03
南风窗(2016年19期)2016-09-21
看天下(2016年23期)2016-09-02
故事大王(2016年1期)2016-04-21
看天下(2016年5期)2016-03-14
