
生成式对抗网络研究综述
2022-09-21 05:37孙书魁曲金帅路佩东
计算机工程与应用 2022年18期
孙书魁,范 菁,曲金帅,路佩东
1.云南民族大学 电气信息工程学院,昆明650000
2.云南民族大学 云南省高校信息与通信安全灾备重点实验室,昆明650000
近年来,随着不同行业领域海量数据的涌现以及硬件设备的算力不断增强,人工智能的身影开始出现在各个领域。其中机器学习是人工智能的核心应用,它关注的是计算机学习能力所依据的程序和算法的改进与优化。根据有无监督,机器学习[1]分为监督学习和非监督学习。在监督学习中,人工标记的数据即昂贵又耗时;另外,自动收集数据也较繁杂。在深度学习中,解决这个问题的关键技术之一是数据扩充,将这种方法应用于模型可以提高模型的能力,并减少泛化误差。通过对图像进行旋转、裁剪、缩放和其他简单变换等操作,创造出新的、可接受训练的样本集,从而实现数据扩充。然而,使用这种方法获得的数据是有限的。最先进的数据扩充方式是通过生成模型生成高质量的样本。考虑到生成模型具有生成大规模数据的能力,标签数据短缺的问题将得到大幅度缓解。
生成模型通常基于马尔科夫链、最大似然估计和近似推理。受限玻尔兹曼机[2]及其开发模型、深度信念网络[3]以及深度玻尔兹曼机[4]都是基于最大似然估计的,这些模型存在一些严重的缺陷,泛化能力不强。为解决这些缺陷,Goodfellow等人在2004年提出生成式对抗网络(generative adversarial networks,GAN)[5]。自首次提出,GAN就被研究学者誉为“深度学习中最重要的创新之一”。作为深度学习领域领军人物的LeCun 曾表示,GAN 及其变体是“过去20 年来深度学习中最酷的想法”。
如今,GAN 已经渗透到各个领域,例如视频语音、计算机视觉以及诸如医学物理等学科领域。图1 显示了Scoups 上至2021 年以来GAN 在不同学科领域所发表论文数量。图2表示近年来Scoups上GAN论文的数量变化趋势。从这些数据可以得知GAN是人工智能中不可多得的技术,并且有非常大的应用前景等待人们去发掘。
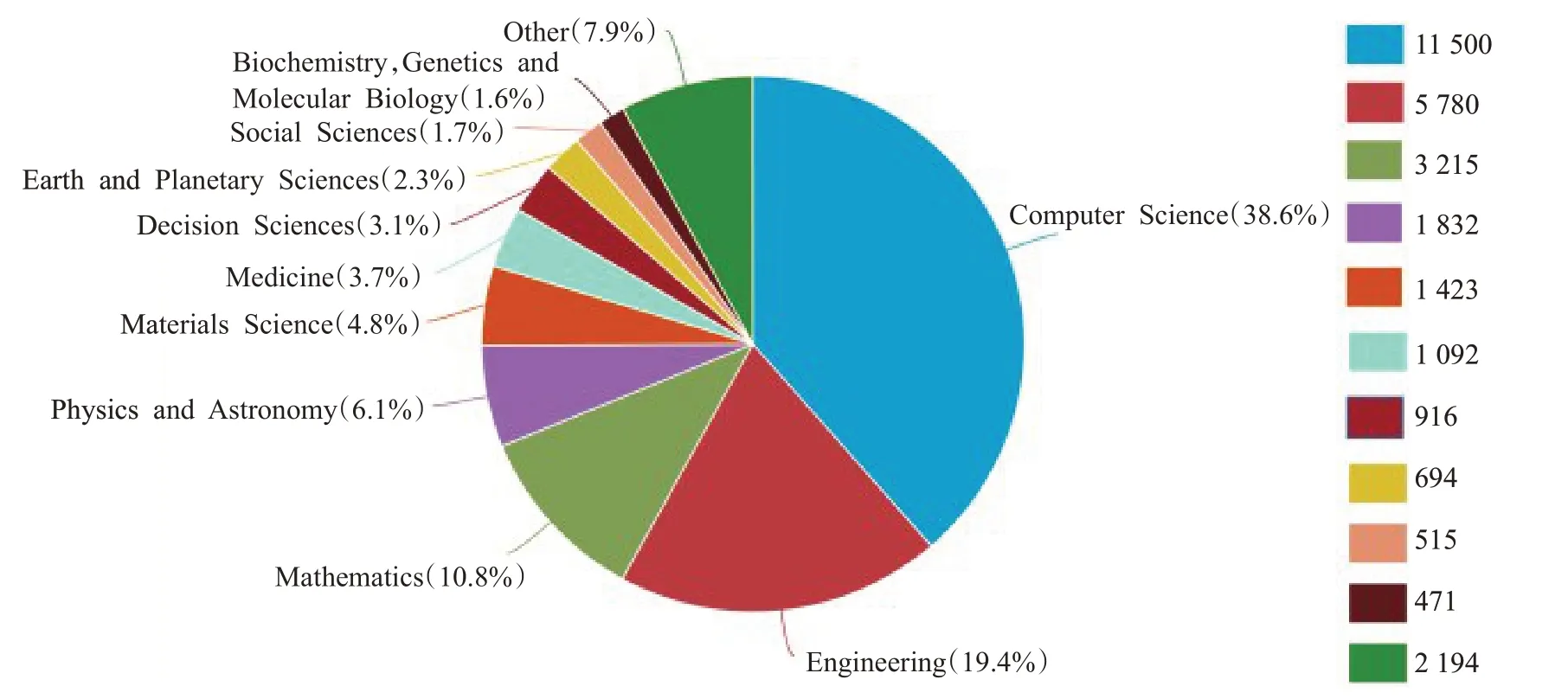
图1 Scopus上GAN论文所属Top 10学科领域Fig.1 Top 10 disciplines of GAN papers on Scopus
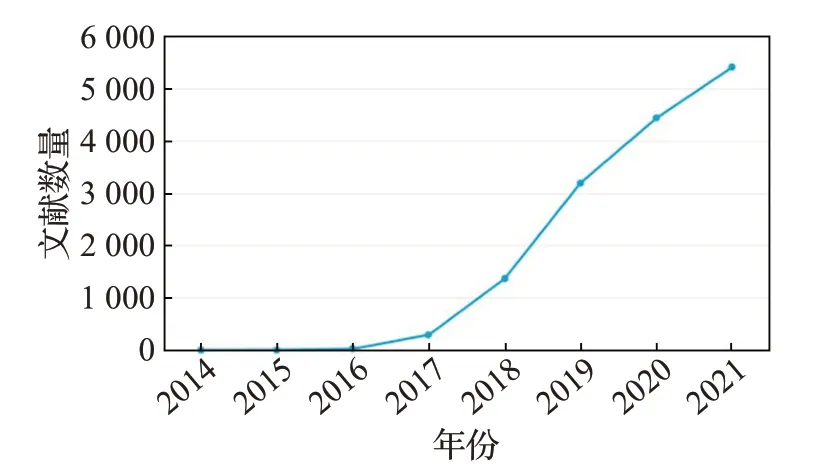
图2 Scopus上GAN论文数量的变化趋势Fig.2 Change trend of GAN papers on Scopus
本文阐述了GAN 在架构、训练、目标函数、面临挑战和评估指标等方面的最新研究进展,然后对GAN 在图像、序列数据和半监督学习等领域中的应用进行了梳理,最后进行了总结并对其下一步研究方向进行展望。
1 生成式对抗网络
主要介绍了GAN 的网络架构、训练过程以及目标函数,并且讨论了GAN如今所面临的挑战。
1.1 GAN网络架构
GAN 是一种类似于二人博弈的网络模型,该模型由生成网络G和判别网络D组成。GAN的架构如图3所示。Xdata和G(z)分别表示真实数据样本和生成器G生成的伪数据样本,判别器D判断输入数据的真伪。在GAN中,生成器G以固定长度的随机噪声向量z(均匀分布或高斯分布)作为输入,生成器的目的是尽量使生成数据分布近似于真实数据分布。鉴别器D的输入有两部分:Xdata和G(z),其输出为概率值,表示D认为输入数据是真实样本的概率,同时输出会反馈给G,用于指导G的训练。理想情况下D无法判别输入数据是来自真实数据还是生成数据,即D每次的输出概率值都是1/2,此时模型达到最优[6]。
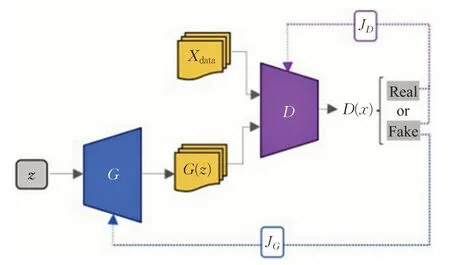
图3 GAN架构Fig.3 Architecture of GAN
1.2 GAN训练过程
GAN 是一组非常复杂且富有挑战性的网络,因为生成和判别网络是以对抗方式同时进行训练。GAN的核心是两个网络之间的平衡。图4显示了GAN的训练过程。在图4(a)中,通过更新判别分布(蓝色虚线)使其能够区分输入是来自真实分布(黑色虚线)还是生成数据分布(绿色实线)。在图4(b)中,判别器经过训练可以区分真假数据,并且很容易完成任务。在图4(c)中,固定判别器,只训练生成器,使其生成假数据的分布更接近真实数据分布。更新一直持续到判别器无法区分为止(图4(d))[7]。值得注意的是,训练过程并不像图4 所示的这么简单。理想情况下,假数据分布与真实的数据分布完全重叠,但实践中存在各种挑战[8]。
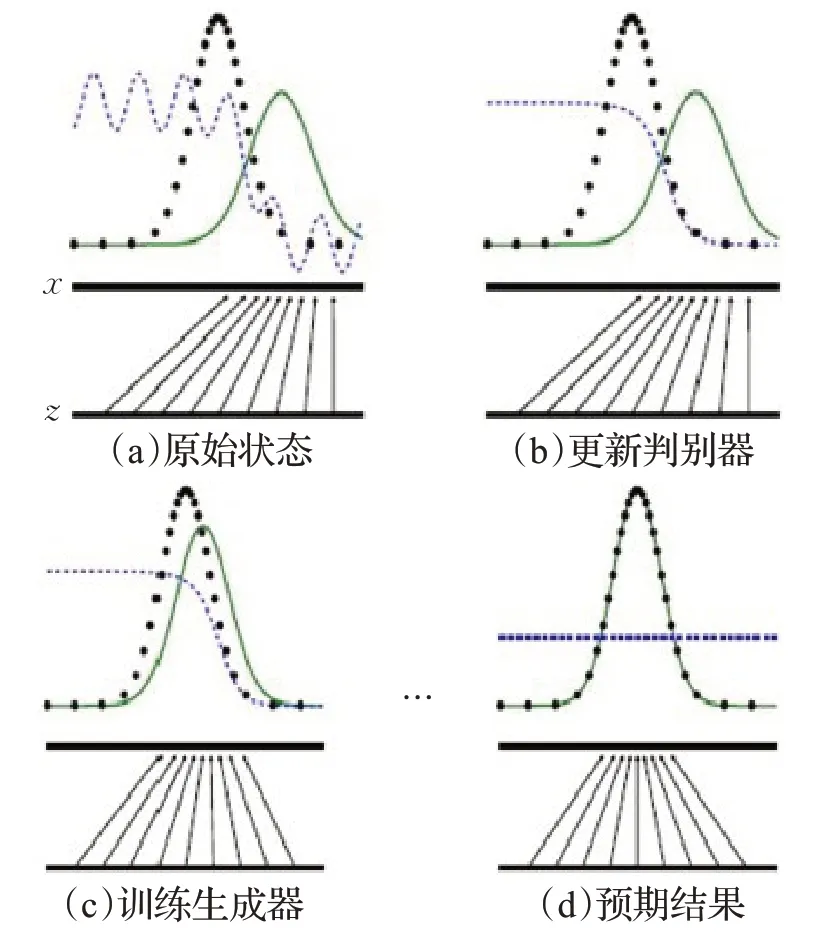
图4 GAN训练过程Fig.4 Training process of GAN
1.3 目标函数
原始GAN 使用两个目标函数:(1)D最小化二元分类的负对数似然;(2)G最大化生成样本为真实的概率。D参数为θD,G参数为θG,θG和θD分别最小化和最大化目标函数,因此这是一场零和博弈。等式(1)中的pdata(x)和pz(z)分别表示数据空间x中定义的真实数据概率和隐藏空间定义的z的概率分布。
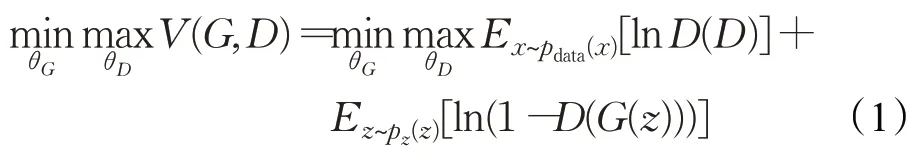
V(G,D)为二元交叉熵函数,常用于二元分类问题,可以注意到G将z从Z中映射到X的元素中,而D接收输入X,并判断X是真实数据还是由G生成的假数据。为了更新各自的模型,G和D的训练是通过它们各自的模型执行反向传播来实现的。从D的角度来看,如果样本来自真实数据样本,D将其最大化,若样本来自生成器生成的样本数据,D则将其最小化输出。与此同时,G试图欺骗D,所以当一个假样本输入D时,它试图最大化D的输出[9]。因此,D试图最大化V(G,D),而G试图最小化V(G,D),从而形成了等式(1)的极大极小关系。等式(1)是通过交替执行两个梯度更新来求解的:
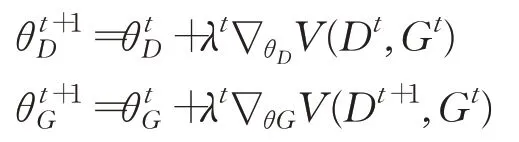
λ是学习率,t是迭代次数。实际上,在等式(1)的第二项ln(1-D(G(z))梯度饱和并使梯度不饱和的流向G时,即梯度变小,停止学习。为了克服梯度消失,可以将等式(1)的目标函数分解成等式(2):
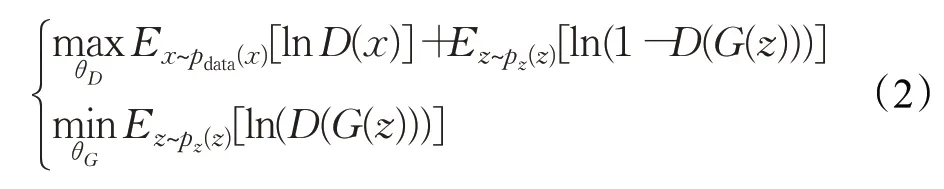
这两个单独目标函数的G梯度具有相同的固定点,且总是在相同的方向上训练。在等式(2)中的损失计算出来后,利用反向传播更新参数。若有充足训练,G能够将简单的隐式分布pg转换为更复杂的分布,即pg收敛于pdata。
1.4 GAN面临的挑战
原始GAN 生成的样本缺乏多样性,生成器在存在多个可能输出类别的情况下,却一直生成单一类别输出[10],即模式崩溃。模式崩溃是GAN 训练过程中常见的问题,其原因和解决方法尚未被完全理解。GAN 在训练过程中G和D也会发生振荡,而不是固定点收敛。当一个玩家比另一个玩家强大的时候,网络可能无法学习并受梯度消失影响。在本节中,将讨论GAN 训练过程中所面临的挑战。
1.4.1 模式崩塌

通常来说,模式崩溃[11]是泛化能力差的结果,这类崩溃大致可以分为两种:(1)输入数据中的大部分模式在生成的数据中不存在;(2)G只学到了特定模式的子集,对于一些修改D的目标函数[12-13]和修改G的目标函数[14]的GAN 的变体而言,不合适的目标函数也可能会导致模式崩溃。在这些变体中,G处于平衡状并且能够学习整个数据分布,但在实际中收敛常是难以捉摸的。为了解决这个问题,最近几项研究引入了具有新目标函数或替代训练方案的新型网络架构。图5 显示了GAN 在玩具集上的模式崩溃,其中目标分布是二维空间中的高斯分布。

图5 2D玩具数据集上的模式崩溃示例Fig.5 Example for mode collapse problem on 2D toy dataset
1.4.2 非收敛性和不稳定性
在原始GAN 中,G使用的两个损失函数是Ez[lnD(G(z))]和Ez[ln(1-D(G(z)))]。当D可以轻松区分真假样本时,前一个损失函数Ez[lnD(G(z))]可能是梯度消失问题的原因。对于最优D,G损失最小化类似于真实图像分布和生成图像分布之间的JSD(Jensen-Shannon divergency,JSD)最小化。在这种情况下,JSD将是2ln2。这允许最优D将概率0 分配给假样本,将1分配给真实样本,并导致G损失函数梯度接近于0,这称为G上的梯度消失。图6显示,随着D的优化,G的梯度逐渐消失[15]。
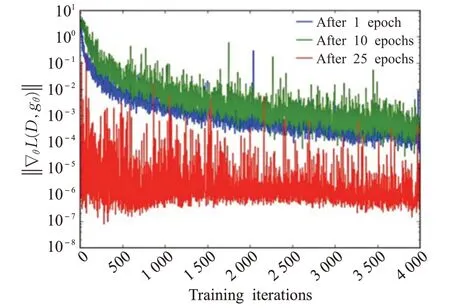
图6 原始代价函数的梯度Fig.6 Gradient of original cost function
在GAN 中,D试图最小化交叉熵,而G则尝试最大化。当D的置信度很高时,D拒绝G生成的样本,然后G的梯度消失。缓解此问题的第一种方案是反转用于构建交叉熵成本的目标。第二个被认为-lnD方式。G的损失函数Ez[ln(1-D(G(z)))]的最小化等于最小化DKL(pg||pdata)-2(DJS(pdata||pg)),这会导致梯度不稳定,因为它会同时最小化KL 散度(Kullback-Leibler divergence)和最大化JSD。这种情况称为G的梯度更新不稳定。图7 显示了G的梯度正在快速增长。且还显示了梯度的方差在增长,更新梯度将导致产生低质量样本[15]。
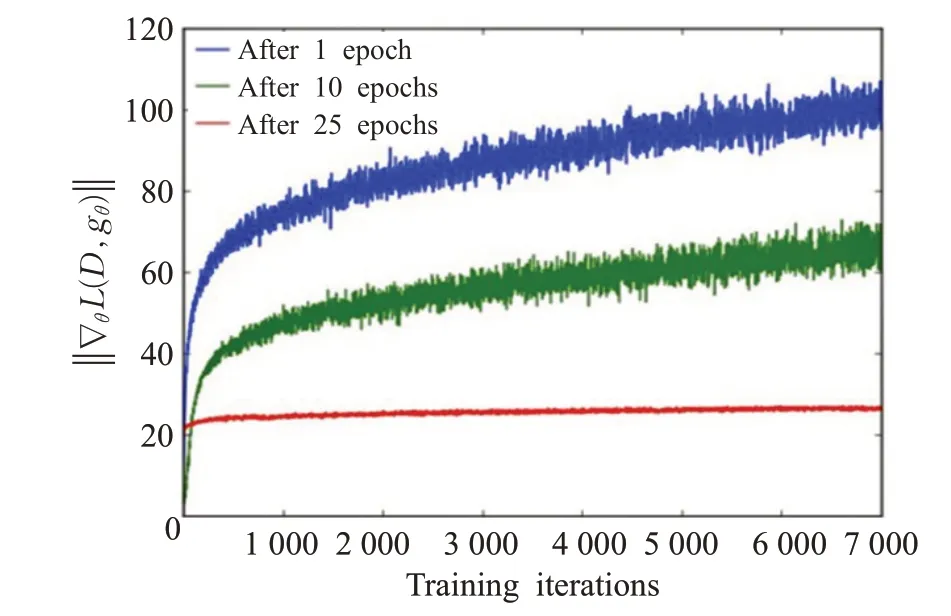
图7 -lnD 代价函数的梯度Fig.7 Gradient of-lnD cost function
如上所述,为了应对GAN 所面临的挑战,文献[16]提出一种新的、鲁棒性更强的算法去寻找二人博弈的纳什均衡,该方法能够在各种结构和散度度量上稳定地训练GAN,并能够达到局部收敛,但全局收敛性还有待研究。文献[17]对如今的训练方法进行分析比较,并指出通过添加一致优化正则项和zero centered gradient可以较好地实现收敛,这为以后的研究指明了方向。
1.4.3 评估指标
GAN 模型已被广泛应用于很多的领域,且衍生出较多的变体。但不同模型的评估仍存在大量的分歧。目前虽然已经有评估GAN 的性能的措施和方案,但这些评估方案是定性的,而且这些评估耗时、主观且无法捕获分布特征。由于选择合适的模型对于获得良好的应用性能至关重要,因此选择合适的评价指标对于得出正确的结论也至关重要。为了设计更好的GAN 模型,需要通过开发或使用适当的定量度量来克服定性度量的局限性。
2 GAN的发展及其衍生模型
2.1 GAN的分类
表1 展示一种基于GAN 设计和优化方案的新型GAN分类。近年来,基于两种主要技术:重组网络架构和新型损失函数,人们提出了很多解决方案来更好地设计和优化原始GAN 。重组网络架构侧重于对原始GAN 架构进行重新组合和创新[18-20],新型损失函数涵盖对GAN 损失函数的修改和重新设计[21-22]。对于每种技术,相关的研究从未停止且已经提出了相应的解决方案来解决上述GAN 所面临的挑战[12]。
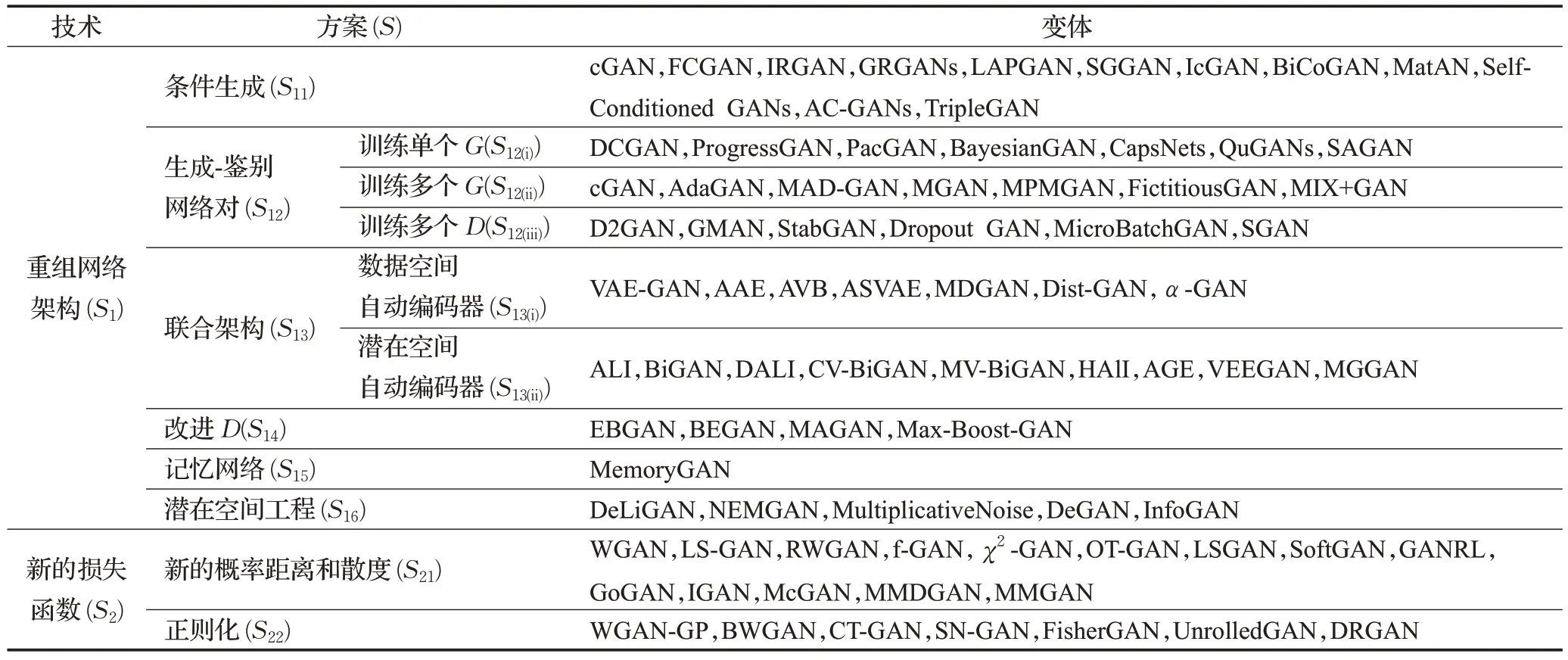
表1 GAN衍生变体分类Table 1 Classification of GAN derived variants
2.2 基于架构优化的GAN
生成和判别网络的架构会极大地影响GAN的训练稳定性。如上文讨论,目前有很多学者对架构进行分析和优化,并尝试与其他的模型结合,以结合彼此的优势。这些基于架构优化的模型大致可以分为三类:条件、卷积和自动编码器,现在的绝大多数变体都是基于以上三种经典模型进行开发的。在下文中,将详细介绍这三种经典架构。
2.2.1 基于条件优化的GAN
如上所述,在原始GAN中,把随机噪声向量z输入到G中,G从噪声z中输出一个样本。假设GAN的训练集有很多类样本,由于原始GAN 对于生成器几乎没有任何约束限制,因此无法控制生成特定类的样本,在生成内容复杂图像的情形时模型会变得更加难以控制。因此,文献[23]提出了条件生成对抗网络(conditional generative adversarial network,cGAN),在原始GAN 的基础上添加条件信息有y,通过y用户可以让G具体输出某一类别的数据样本,D则以真实图像和附加信息y作为输入。使网络朝着既定的方向生成样本[24]。cGAN的目标函数是:
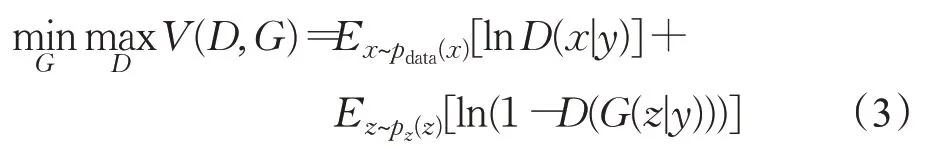
为实现等式(3),将one-hot编码y连接到x作为判别器的输入,同时将y连接到噪声z作为生成器的输入。因此,判别器和生成器的输入层被放大以接受连接的输入,这样用户就可以让生成器输出特定类别的数据[25]。
现有的研究表明,cGAN只是为了使生成的图像更具有控制性而增加了控制信息,并没有解决训练不稳定问题。因此,cGAN 不能很好地执行监督任务,如语义分割、实例分割、直线检测等。可能的原因是G通过最小化并不直接依赖于真实数据标签的损失函数来优化。为了解决上述问题,文献[26]还提出了一种类条件GAN,该GAN 不需要人工标注类标签。而标签是通过在D的特征空间中应用聚类自动导出的。聚类操作会自动发现不同的模式,并要求G明确地覆盖它们。在后面的介绍中,很多的应用都直接或间接地用到cGAN,或者是对cGAN 的进一步改进,但使控制信息应用到GAN 的思想是不变的。因此,条件生成可以说是GAN应用中极为重要的一部分。
2.2.2 基于卷积优化的GAN
卷积神经网络(convolutional neural network,CNN)[27]作为如今最有效和应用最多的学习模型,近几年在计算机视觉领域开始变得举足轻重。在原始GAN 中,多层感知机(multilayer perceptron,MLP)用于生成和鉴别网络。由于MLP 的训练不稳定且具有挑战性,并且CNN在特征提取方面比MLP 具有更好的性能,因此提出了深度卷积GAN(deep convolutional GAN,DCGAN)[28]架构。在这个体系架构中,通过对CNN 进行了一些更改以便可以将其应用于生成和判别网络。这些更改主要是通过在架构、设置和训练上的大量实验和错误中获得的。表2 显示了对CNN 所做的更改。DCGAN 可以很好地生成高分辨率图像,也可以说是设计和训练可持续GAN模型的最关键步骤之一,大多数GAN模型都是基于这种架构。

表2 在GAN中应用CNN架构Table 2 Application of CNN architecture in GAN
在DCGAN架构中,生成器捕获潜在空间中的随机点作为输入并生成图像,所提出的方法是通过使用转置卷积层来实现这一目标。换句话说,步幅为2会产生相反的效果,即在标准卷积层中将使用上采样操作而不是下采样操作。图8 显示了发生器的结构。鉴别器是一个标准的卷积网络,它捕获图像作为输入并显示二进制分类(真或假)作为输出。在标准模式下,深度卷积网络利用池化层减少深度网络的输入维数和特征图。对于DCGAN,并没有使用池化层而是使用跨步卷积降维。
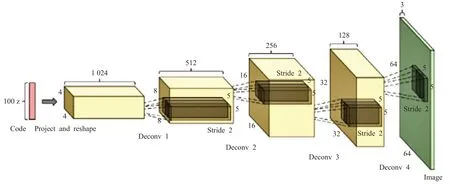
图8 DCGAN的生成器Fig.8 Generator of DCGAN
虽然实验证明DCGAN训练更加的稳定,但是伴随训练的时间延长,滤波子集有时会折叠为单一振荡模型,对于这一不稳定现象,需进一步研究。
2.2.3 基于自编码器优化的GAN
自编码神经网络是一种用于提取特征和重建操作的无监督神经网络模型。这个网络由两部分组成:编码器z=f(x)和解码器x̂=g(z)。编码器通过输入降维过程将x转换为潜层z。同时,解码器通过接收来自潜在层z的代码来重构输入x以输出。在过去的几年中,自动编码器网络已被用于深度生成模型中。自编码器网络的缺点之一就是编码器产生的潜层在指定空间上没有均匀分布,导致分布中存在大量间隙。
因此,提出了对抗式自动编码(adversarial autoencoder,AAE)[29],这是对抗式网络与自动编码器的组合。在这种方法中,先前的任意分布被施加在编码器获得的潜在层分布上,以确保不存在间隙,从而解码器可以从其每个部分重建有意义的样本。AEE架构如图9所示,在这种架构中,潜在代码z表示假信息,z′由指定分布的p(z)表示,两个输入都充当判别器。在完成训练过程后,编码器可以学习期望的分布,而解码器则可以生成根据所需分布重构的样本。表3 为基于架构优化的衍生体对比分析。
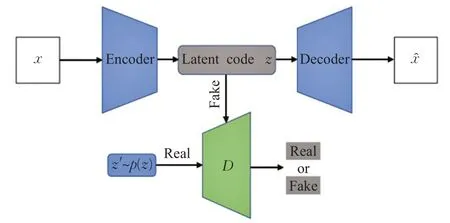
图9 自动编码器(AAE)的结构Fig.9 Structure of automatic encoder(AAE)
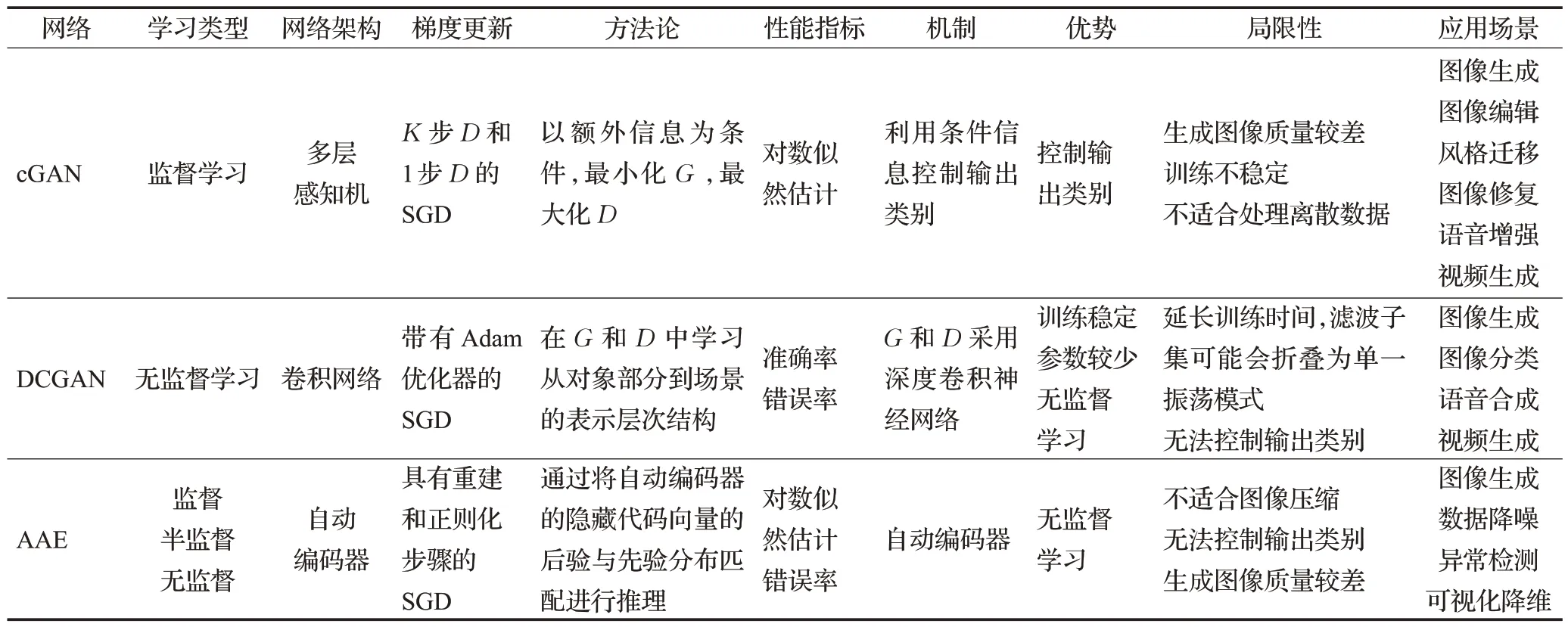
表3 cGAN、DCGAN和AAE的对比Table 3 Comparison of cGAN,DCGAN和AAE
2.3 基于目标函数优化的GAN
文献[5]提出GAN 网络时,对生成器的目标是最小化pdata和pG分布距离[30]。在本节中,将讨论如何使用各种距离和从这些距离导出的目标函数来测量pdata和pG之间的差异。
2.3.1 f-divergence
文献[5]中使用JS散度来衡量两个分布之间的差异,但是JS散度有自身的函数域,这可能会造成PG和Pdata分布的可能取值域缺乏重叠。理论上来说,真实的数据分布通常是一个低维流形,数据并不具备高维特性,而是嵌入在高维度的低维空间中,而实际当中,数据维度的空间远远不止3维,甚至上百维,这样的话,数据就更难以重合。为解决上述问题,文献[15]提出通用模式f-divergence来衡量分布之间的差异。使用两个分布的比率,Pdata和PG与函数f的f-divergence定义如下:
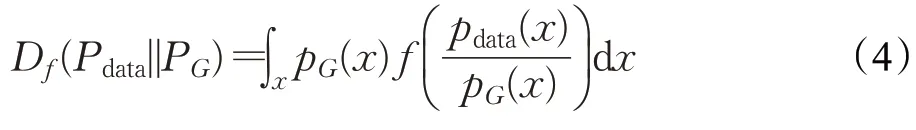
上式中,Pdata和PG是两个不同的分布;pdata(x)和pG(x)代表着分别从Pdata和PG中采样出x的概率。f可以是任意类型的收敛,只需满足它是一个凸函数同时f(1)=0。
当令f(x)=xlnx,f-divergence 转换为KL-divergence:
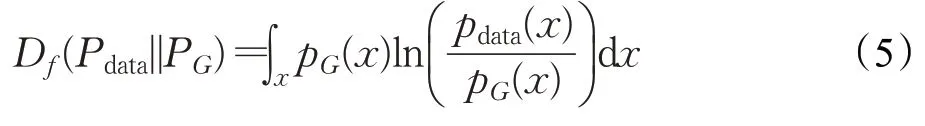
当令f(x)=-lnx,f-divergence 转换为Reverse KL Divergence:
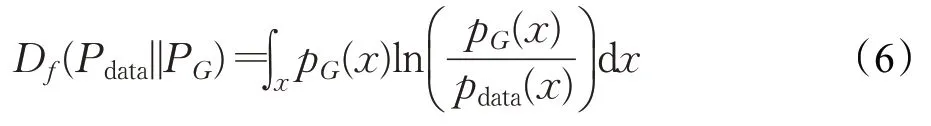
f-divergence 根据任意凸函数f下的f散度来构建目标函数。由于不知道确切的分布,方程(2)应该通过易于处理的形式来估计,例如期望形式。通过使用共轭,等式(2)可以被重新整理如下:
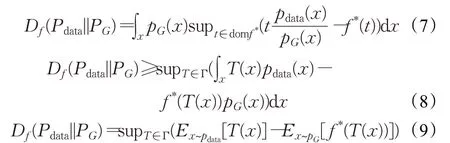
其中f*是凸函数f的Fenchel共轭,domf*表示了f*域。
等式(7)源于最大值的总和大于总和的最大值,并且Γ 是满足χ→R的任意函数类。可以注意到将方程(6)中的t替换为方程(7)中的T(x):χ→domf*使t参与到fχ。如果将T(x)表示为满足a(⋅):ℝ →domf*的T(x)=a(Dω(x))和Dω(x):χ→ℝ,可以将T(x)解释为具有特定激活函数a(⋅)的判别器。
f-divergence 统一了GAN 模型,对任何满足条件的f都有一个对应的GAN。解决训练过程中模式崩塌的问题,但是在训练的过程中,不同的f-divergence对训练结果并没有改善。
2.3.2 最小二乘GAN
如上所述,通过JS散度衡量两个分布的差异进而拉近PG(x)与Pdata(x)的距离,由于JS散度自身函数域的影响可能会导致PG与Pdata缺乏重叠。从数学的角度来看,无论两种分布多么接近,只要没有相交,那么它们的JS散度都是一个常数ln 2。因此如果生成的样本被判别器分类为真实样本,那么即使生成的样本远离真实数据分布,也没有理由更新生成器。
针对上述问题,文献[20]提出了LSGAN(least squares GAN,LSGAN)的方法。原始GAN 的鉴别器使用sigmoid 交叉熵损失去判断输入是真还是假。通过上面分析,知道sigmoid 交叉损失无法将生成的样本推向真实数据分布,因为它已经实现了分类的作用。受此启发,用更加平滑和非饱和的最小二乘损失代替了sigmoid 交叉熵损失。通过D将G生成的样本拖到真实数据流形中。与公式(1)相比,LSGAN 解决了以下问题:
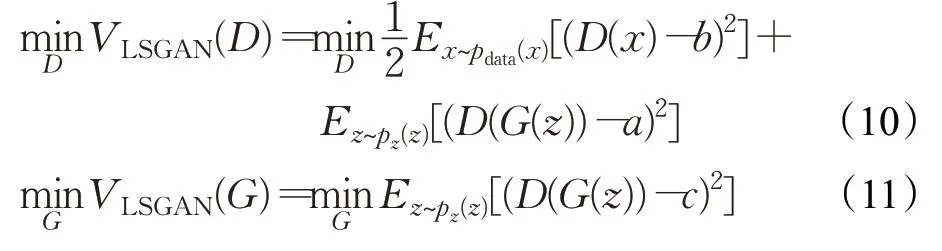
其中a、b和c是判别器的基线值。
等式(10)和(11)使用最小二乘损失,在此情形下,判别器被迫分别具有真实样本和生成样本的指定值(a、b和c),而不是真实或假样本的概率。因此最小二乘损失不仅可以对真实样本和生成样本进行分类,还可以将生成的样本拉近真实数据分布。此外,LSGAN 还可以连接到f-divergence框架。
2.3.3 Wasserstein GAN
如上所述,为了较好地测量PG和Pdata分布的差异的问题,文献[11]提出了用Wasserstein距离(也称was距离、EM距离),以便较好地测量两个分布之间的差异,从而解决JS和f-divergence散度不能充分体现两个分布之间差异的弊端。Wasserstein距离定义如下:
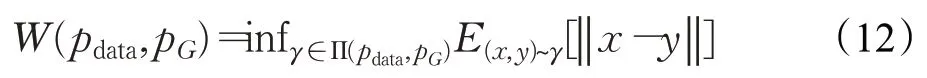
其中,Π(pdata,pG)表示联合分布的集合,γ(x,y)的边缘分布为pdata(x)和pG(x)[31]。
由于方程(12)中的inf 项是难以处理的,它通过具有Lipschita 函数类[27-28]的Kantorovich-Rubinstein 对偶性转换为易于处理的方程,即f:X→R,满足dR(f(x1),f(x2))≤1×dX(x1,x2),∀x1,x2∈X其中dX表示域X的度量距离。等式(12)的对偶性如下:
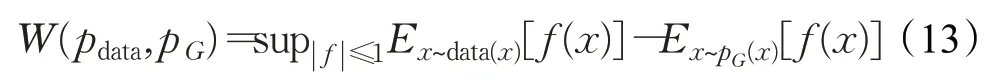
因此,如果将带有w的函数f参数化1-Lipschitz函数,则该公式变成了一个极大极小问题,因为首先通过公式(13)中的最大值来训练fw以逼近W(pdata,pG),并且通过优化生成器gθ来最小化这种近似距离。为了保证fω是Lipschitz 函数,对w的每次更新进行权重裁剪,以确保w的参数空间位于紧凑空间中。值得注意的是,在WGAN中输出的是was距离,原始GAN的输出结果在(0,1)区间之内,但是was距离是没有上下界的,意味着随着训练的进行,判别器将永远无法收敛,虽然文献[11]中做了权重裁剪处理,但是这个方法并没有让D真的限制在Lipschitz 函数内,所以WGAN 严格意义上说并没有给出was距离的计算方法。
2.3.4 Wasserstein GAN-Gradient Penalty
具有梯度惩罚的WGAN(Wasserstein GAN-Gradient Penalty,WGAN-GP)[32]指出:WGAN并未能将D限制在Lipschitz 函数内,在训练WGAN 时对判别器进行权重裁剪会导致判别器的不良行为,并建议添加梯度惩罚而不是权重裁剪。它表明,通过权重裁剪来保证判别器的Lipschitz 条件将判别器限制在所有Lipschitz 函数的一个非常有限的子集中;这使判别器偏向于简单的功能。权重裁剪还会产生梯度问题,因为它将权重推到了裁剪范围的极端。为了通过直接约束判别器的梯度来实现Lipschitz 条件,建议在方程(13)中添加一个梯度惩罚项,而不是权重裁剪[33]。
Loss sensitive GAN(LS-GAN)[33]也使用Lipschitz约束,但方法不同。它学习损失函数Lθ而不是判别器,这样真实样本的损失应该比生成样本小一个与数据相关的边距,导致关注边际高的假样本。此外,LS-GAN假设真实样本pdata(x)的密度是Lipschitz 连续的,因此附近的数据不会突然变化。采用Lipschitz 条件的原因与WGAN 的Lipschitz 条件无关。关于LS-GAN 的文献讨论了Goodfellow 等人提出的模型应该无限容量的非参数假设。文献[5]的条件过于苛刻,即使对于深度神经网络也无法满足,并导致训练中出现各种问题;因此它将模型限制在Lipschitz 连续函数空间中,而WGAN的Lipschitz 条件来自kantorovich-Rubinstein 对偶,并且只有判别器受到限制。此外,LS-GAN 使用权重衰减正则化技术将模型的权重强加在有界区域内,以确保Lipschitz函数条件。
虽然WGAN-GP 很好解决了WGAN 遗留的问题,但是WGAN-GP依然存在改进的空间,因为它并没有保证每一个x梯度的模都小于或等于1,对于这一问题,在文献[34]中通过频谱范数正则化得到了很好的解决。表4总结分析了基于损失函数优化的衍生体。
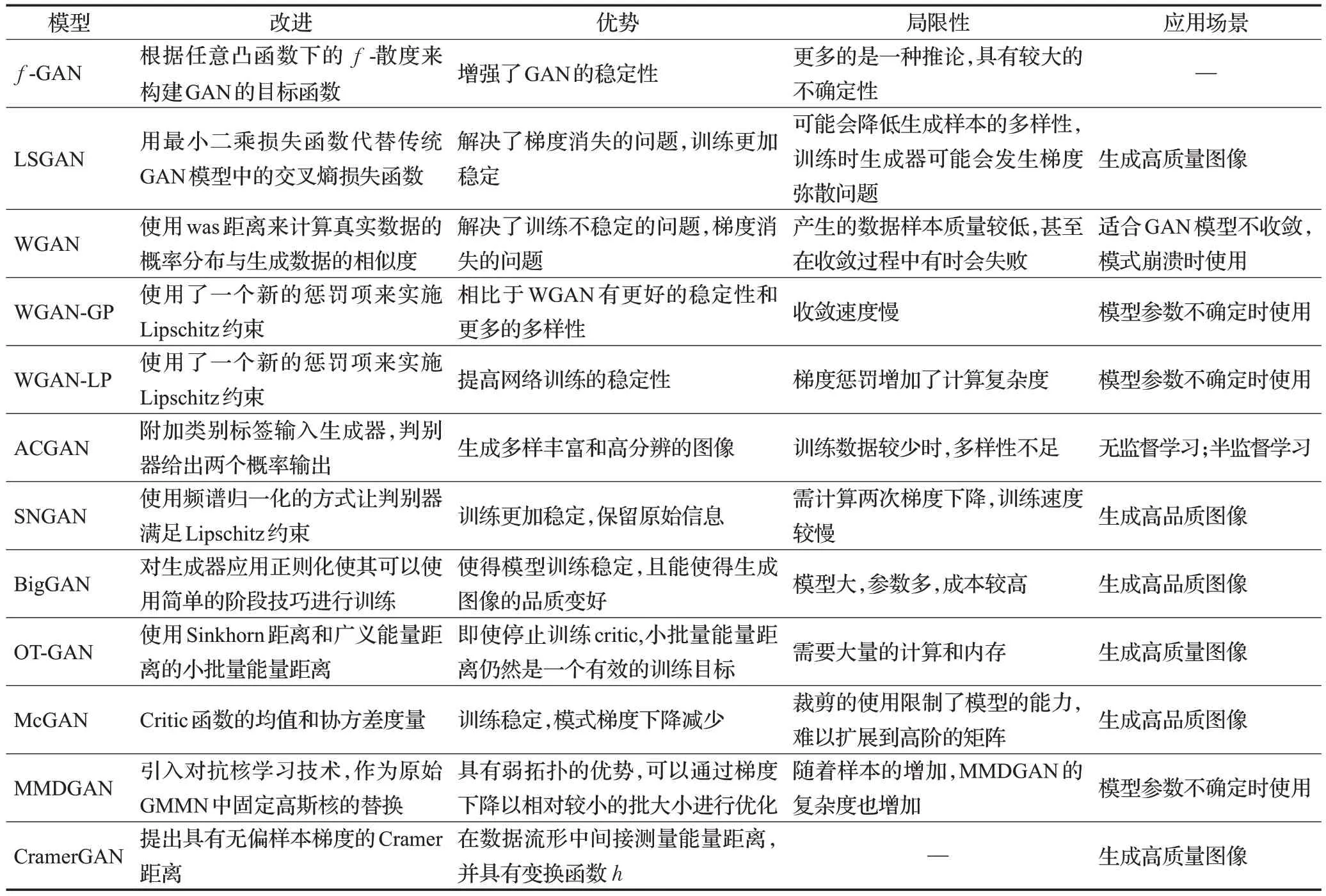
表4 基于损失函数优化的衍生体比较Table 4 Comparison of variants based on loss function optimization
3 GAN模型评价指标
GAN 衍生体目前种类繁多,如果仅仅凭借人工去评测生成样本的优劣,将会消耗大量的人力以及时间成本,并且极易受到主观因素影响。考虑到定性评估存在以上的内在缺陷,因此定量评估就显得十分重要,本节以下内容对GAN的定量评价指标进行了全面的概述。
3.1 Inception分数
文献[35]于2016 年提出Inception Score(IS),它对每个生成的图像使用Inception 模型来获得条件标签分布p(y|x)。IS指标常用来评估生成图像的质量,采用熵的形式体现了量化的概念。生成图像的多样性与熵的大小成正比,熵值越大意味着样本越丰富。鉴于考虑图像质量和多样性的情形,以互信息形式设计GAN 评价指标。为了简化计算添加了指数项,因此IS表达式如下:
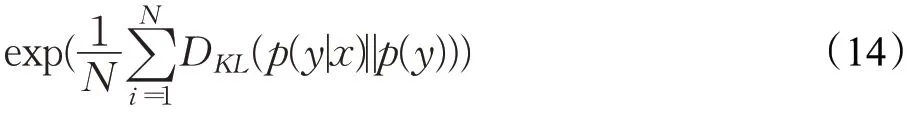
其中结果取幂是为了方便比较。较高的IS表明生成样本多样性且高质量。然而,IS 也有缺点,如果生成模型陷入模式崩溃,则IS可能仍然很好,而实际情况则非常糟糕。
3.2 FID距离
如上所述,由于IS 指标在GAN 发生模式崩溃时并不能较好的工作且只考虑生成数据的分布pg而忽略真实数据的分布pdata,于是文献[36]在2017 年提出了Fréchet Inception Distance(FID),FID 计算了在特征空间高斯分布中真实数据与生成数据的弗雷歇距离。FID需要先选取一个特征函数φ(默认是Inception网络的卷积特征)。FID 将φ(pdata)和φ(pg)建模为具有均值μr、μg和协方差Cr、Cg的高斯随机变量并计算:
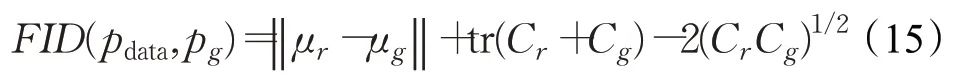
FID距离与GAN的性能成反比,且反映了两个分布之间的亲疏关系。FID 数值越大,两个分布相差越大。然而,IS和FID均不能很好地处理过拟合问题。为了缓解这个问题,文献[32]提出了内核初始距离(KID)。总的来说,FID 还是相对有效的,其不足之处是高斯分布的假设只存在于理想情况下。
3.3 最大均值差异(MMD)
MMD(maximum mean discrepancy)[37]主要用来测量两个不同但相关的分布的距离。MMD计算了在希尔伯特空间中两个分布的距离,是一种核学习方法。受到FID启发,将求解FID距离的方法替换成MMD,数据分布之间的距离可以作为GAN 性能指标。MMD 距离与GAN 的性能成反比,MMD 值越低,则两种分布越相似。实验证明MMD可以较好地识别模式崩塌,尽管是有偏的,但仍推荐使用[38]。
3.4 多尺度结构相似性(MS-SSIM)
SSIM(structural similarity)[39]主要用来度量图像之间的相似性。与单尺度相比,多尺度结构相似性(multiscale structural similarity,MS-SSIM)[40]是用来评估多尺度图像质量。它通过尝试预测人类感知相似度判断进而定量评估图像的相似度。MS-SSIM 值得范围在0 和0.1之间,较低的MS-SSIM值通常意味感知上更不相似的图像。文献[41]建议MS-SSIM 应与FID 和IS 指标一起考虑去测量样本的多样性。
3.5 1-最近邻分类器(1-NN)
1-NN(1-nearest neighbor classifier)[42]是如今评价GAN的完美指标,且具备其他指标的所有优势,其输出分数还在[0,1]区间,类似于分类问题中的准确率/误差[38]。1-NN 比较训练数据集与生成数据集的概率分布,如果两者的结果一样,则说明GAN 的性能良好,反之较差,这类的方法通常采用准确率作为评价指标。1-NN 分类器进行评估时,通过留一(leave-one-out,LOO)的准确率去评估Pr和Pg的差异。假设Tr~、Tg~分别是来自两个概率分布和的样本,同时样本的数量一样,即 |Tr|=|Tg|,如果两个分布完全匹配的话,则LOO的准确率即为50%。
上述可知,不同的GAN 评估指标侧重点不同。在ImageNet上预训练ResNet的卷积空间中,MMD和1-NN在判别力、鲁棒性和效率都是优秀的指标,而IS、FID和MMD 不适合于ImageNet 差异较大的数据集。尽管人们广泛认为GAN 对训练数据过拟合,但这只在训练样本很少的情况下才会发生[38]。考虑到应用场景多样化的情形,评价指标的设计也应该多样化,同时最大化保持模型性能。
4 GAN在不同领域的应用
如上所述,GAN是一个非常神奇的生成模型,它可以根据任意噪声向量z生成逼真的数据,且无需知道数据真实分布,也无需任何数学假设。这些特性使得GAN 身影遍布诸多领域。本章将讨论GAN 在几个领域中的应用。
4.1 图像
4.1.1 图像翻译
图像到图像的翻译是一种无监督学习,用于将图像从一种表示转换成另一种表示。传统方式是利用每个像素的分类或回归。在这些方法中,每一个输出像素都是针对整个输入图像进行预测,并独立于先前输入图像的所有像素,导致图像的大部分语义丢失。为了解决上述问题,文献[43]提出了基于cGAN 架构的像素到像素的构架(pix2pix),该体系结构可以在图像到图像翻译应用程序中生成真实的高分辨率图像。与旧的GAN模型相比,它还允许创建更高分辨率图像(256×256)。图10展示了pix2pix 的性能。在pix2pix 架构中,生成器和鉴别器分别受到U-Net[44]和PatchGAN[45]的启发。此体系结构中的两个网络使用的都是卷积神经网络。在PatchGAN中,对所有图像进行分类是一步进行的,而在pix2pix 的鉴别器中,取而代之的是每个图像首先被分成n×n个patch。然后,对于每个patch分别预测图像是真的还是假的。最终,通过平均所有响应来执行最终分类。
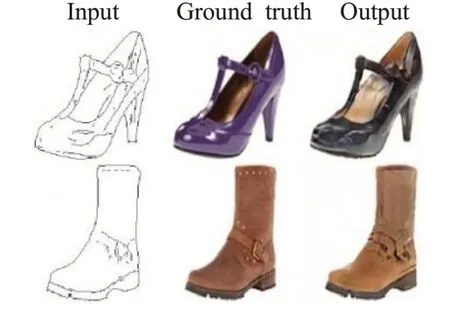
图10 pix2pix生成的图像Fig.10 Image generated by pix2pix
4.1.2 图像合成
人脸生成以及人脸识别被广泛应用,尽管已有研究提出基于数据的深度学习来达到目的,但是该领域仍然具有一定的挑战性。由于人类视觉对面部畸形和变形很敏感,因此生成逼真的面部图像并非易事。GAN 已被证明能够生成具有精致纹理的高质量人脸图像。
双路径GAN(two-pathway generative adversarial network,TP-GAN)[46]可以使用侧面轮廓图像生成高分辨的正面图像(如图11)。这种技术可以像人类一样考虑局部和全局信息,该方法生成的人脸图像很好地保留了个人身份的很多特征。它还可以处理不同模式和光照下的多幅图像并且具有双路径架构。训练全局生成器生成面部标记(标记点)周围的细节。

图11 TP-GAN基于侧面轮廓合成正面人脸图像Fig.11 TP-GAN synthesizes front face image based on side contour
4.1.3 图像修复
图像修复试图重建图像中丢失的部分,使读者无法察觉重建的区域。这种方法通常用于从图像中删除不需要的对象或恢复图像中损坏的部分。在传统的技术中,图像中的孔洞是通过复制原始图像的像素或图像库来填补的。基于深度学习的方法在恢复图像中丢失的区域取得了良好的结果。这些方法可以创建可接受图像结构和纹理。其中一些使用卷积网络的技术,在用正确的特征填补空白方面表现不佳。因此,开发了生成模型以找到训练过程中已知的正确特征。第一种基于GAN 的图像恢复方法是上下文编码器[47]。该方法基于编码器-解码器架构进行训练,以根据图像语义推断图像中任意缺失的大区域。尽管如此,在这种方法中,全连接层无法存储准确的空间信息。上下文编码器有时会创建与孔周围区域成比例的模糊纹理。文献[48]将“风格迁移”的思想和上下文编码相结合。但是,该模型不足以用复杂的结构填充缺失的区域。图12显示了该方法和上下文编码器的示例结果。

图12 Context encoder与PatchGAN生成图像比较Fig.12 Comparison of images generated by Context encoder and PatchGAN
文献[49]提出了一种基于GAN的图像恢复方法,该方法与全局和局部环境兼容。输入是带有附加二进制掩码的图像,以显示缺失的孔。恢复图形的输出具有相同的分辨率。生成器采用编码器-解码器架构和扩展卷积层而不是标准卷积层来支持更大的空间[50]。并且由两个判别器,一个能够捕获整个图像作为输入的全局判别器和一个能够覆盖小区域的孔作为输入的局部判别器。这两个判别器网络确保生成的图像在“全局”和“局部”尺度上都是兼容的,这使它能够恢复任意孔洞的高分辨率图像。
4.2 序列数据
生成离散值的GAN变体大多借用了RL(reinforcement learning,RL)的策略梯度算法,以规避离散值的直接反向传播。为了输出离散值,生成器作为一个函数,需要将潜在变量映射到元素不连续的域中。然而,如果将反向传播作为另一个连续值的生成过程,判别器会稳定地引导生成器生成类似真实的数据,而不是突然跳到目标离散值。因此,生成器的这种微小变化不能轻易地寻找有限的真实离散数据源[51]。此外,在生成音乐或语言等序列时,需要逐步评估部分生成的序列,衡量生成器的性能,这也可以通过策略梯度算法来解决。
4.2.1 音乐
当生成音乐时,需要一步一步地生成音乐的音符和音调,而这些元素不是连续的值。一种简单而直接的办法是连续RNN-GAN(C-RNN-GAN)[52],它将生成器和判别器建模为具有长-短期记忆(long short term memory)[53]的RNN,直接提取整个音乐序列。然而,如上所述,只能评估整个序列,而不是评估部分的序列此外,它的结果不是非常令人满意,因为它不考虑音乐元素的离散属性。
相反,序列GAN(sequence generative adversarial network,SeqGAN)[51]和Lee 等人[54]使用了策略梯度算法,无需一次生成整个序列。它们将生成器的输出作为代理的策略,并将判别器的输出视为奖励。选择带有鉴别器的奖励是一种常规操作,因为生成器的作用是从判别器中获得大的奖励,类似于代理学习在强化学习中获得的较大奖励。
4.2.2 语言和语音
RankGAN(ranking generative adversarial network)[55]提出了语言(句子)生成方法和排名器而不是传统鉴别器。在自然语言处理中,除了真实性之外,还需要考虑自然语言的表达能力。因此,RankGAN 在生成句子和人工编写的参考句子之间采用了相对排名概念。生成器尝试将其生成的语言样本排名靠前,而排名器评估人类编写句子的排名分数高于机器编写的句子。由于生成器输出离散符号,它同样采用类似于SeqGAN 和ORGAN(objective reinforced generative adversarial network)[56]的策略梯度算法。在RankGAN中,生成器可以解释为预测下一步符号的策略,并且可以将等级分数视为给定过去生成序列的值函数。
可变自动编码Wasserstein-GAN(variatio-nalautoencoding Wasserstein GAN,VAW)[57]作为一种语音转换系统,结合了VAE 和GAN 框架。其编码器推断出源语音的语音内容z,解码器则根据目标说话人的信息y合成目标语音,类似于条件VAE。由于高斯分布的假设过于简单,VAE 会产生尖锐的结果。为了解决这个问题,VAW-GAN 与VAEGAN[12]合并了WGAN[11]。通过将解码器分配给生成器,它的目标是在给定说话人表示的情况下重建目标语音。
4.3 半监督学习
半监督学习在既有标签数据又有未标记数据的情况下,通常使用只有一小部分带有标签的数据集来训练模型。
基于GAN的半监督学习方法[35]演示了如何在GAN框架上使用未标记数据和生成的数据。生成的数据分配给一个K+1 类,而1至K类用于标记真实数据。对于标记的真实数据,鉴别器对其正确的标签进行分类(1到K)。对于未标记的真实数据和生成的数据,它们使用GAN极大极小游戏进行训练。它们的训练目标可以表示如下:
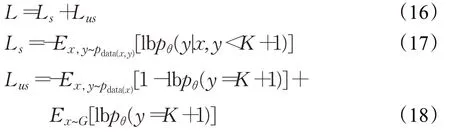
其中,Ls和Lus分别代表标记数据和未标记数据的损失函数。因为只有生成的数据被归为K+1 类,所以可以将Lus视为标准的极小极大博弈。未标记的数据和生成的数据用于告知模型真实数据所在的空间。
4.4 其他应用
4.4.1 信息安全
随着互联网的大规模普及,人们在上网的同时自身的隐私数据也时刻面临巨大的威胁。近年来,由于深度学习在各个领域都取得了不俗的成绩,很多学者将GAN 应用于安全检测和系统防护之中。文献[58]基于GAN 提出一种新的数据异常检测方法,该方法不需要较多的异常样本数据,只要达到数据平衡就能很好地检测到系统中的异常数据。还有恶意代码生成器MalGAN[59]和识别恶意网页的WS-GAN[60]。MalGAN 通过模拟一种可控的透明的攻击方式进而提升自身系统的防御能力。WS-GAN可以有效地识别恶意网页,避免自身的数据泄露。
4.4.2 持续学习
深层生成重放[61]将GAN 框架扩展到持续学习领域。持续学习解决多项任务并不断积累新知识。深度神经网络中的持续学习会遭受灾难性遗忘:当新任务被学习时过去获得的知识被遗忘。受大脑机制启发,灾难性遗忘可以通过深层生成重放的GAN框架来解决。深层重放模型是一个有深层生成模型(生成器)和任务解决模型(求解器)组成的合作双模型架构。在这个架构中,该模型通过重发生成的伪数据来保留以前学习过的知识。被称为scholar模型的生成器-求解器对可以针对需求生成假数据和所需的目标对,当出现新任务时,这些目标对会与新数据共同更新生成器和求解网络。因此,scholar 模型既可以学习新任务而不忘记自己的知识,还可以在子网络配置不同的情况下用生成的输入-目标对训练其他模型。
4.4.3 疫情防控
自COVID-19大流行以来,已经对公众的健康构成严重的威胁,传统的CT 扫描虽然对于疫情防控有很好的效果,但是会花费大量的时间[62]。文献[63]提出一种新颖的算法——CCS-GAN,该算法只需要较少的样本数据就能高效快速地识别CT扫描分类,大大提高了诊断效率。类似的还有数据同化预测的GAN(DA-PredGAN)[64]和使用辅助分类器进行数据增强的GAN(CovidGAN)[65]。DA-PredGAN 利用生成模型具有的模拟时间向前和向后的能力,对COVID-19在传播预防和流控具有很好的效果。CovidGAN生成的合成图像可用于增强COVID-19的检测性能能,大大加快检测速度。
5 总结与展望
自从2014 年Goodfellow 等人把GAN 网络架构模型首次引入深度学习之中,GAN 便凭借其强大的对抗学习能力,受到广大科研人员的喜爱,GAN的应用也开始蔓延至各行各业,尤其在计算机视觉方向更是层出不穷。本文首先从架构、目标函数和面临的挑战以及应对策略等角度进行了一系列探讨,为了应对GAN 面临的挑战,从架构和目标函数两个优化角度进行讨论。然后,对目前工作中GAN 性能评估的方法做了详细的汇总和分析。最后,根据不同的应用场景对GAN 的应用做了详细介绍。尽管GAN在很多领域取得了令人鼓舞的成就,但是GAN 模型本身以及训练算法还是有很多的优化空间,实际上GAN在各领域的应用才真正开始,还有很多值得探索和深耕的未知领域。下面对于GAN的探索提出若干展望:
(1)GAN 网络轻量化。研究人员已经设计出大量优秀的大型神经网络算法模型。但这些模型都有一个共同的缺点,就是所需的计算量庞大和参数繁多,对于硬件的配置提出了极高的要求,无疑加大了GAN 的应用门槛。这时候GAN网络轻量化显得尤为重要。
(2)GAN 与其他模型相结合。随着GAN 的不断飞速发展,优点被不断扩大的同时,其弊端也变得不容忽视,如果可以把GAN 与其他模型相结合,结合二者优点,克服自身缺点,生成鲁棒性更强的模型,这将是不错的选择。例如:DCGAN是GAN和卷积神经网络结合而成的,这种模型训练更加稳定;还有GAN与ViT结合的ViTGAN[66],与NAS结合的autoGAN[67],都是未来值得关注的方向。
(3)GAN理论突破。GAN源自二人博弈理论,由于自身理论缺陷的原因,GAN 的发展一直受到模型崩溃训练不稳定的困扰,虽然学者们提出了很多方案去解决,但是依然基于这一理论,所以无法从根本上解决这一问题。这个时候思考源头本身,从理论出发做出突破或许是一个不错的解决方式,例如,文献[68]提出的三人博弈提论值得借鉴学习。
(4)GAN 伪造鉴别。随着GAN 的能力被大家所熟知,其生成的数据甚至于达到以假乱真的地步,如何能够保证GAN 技术永远用在正确的地方,而不是被别有用心的人利用,这个值得严肃对待,同时也亟需一个答案。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
数学物理学报(2022年5期)2022-10-09
网络安全与数据管理(2022年1期)2022-08-29
科学技术创新(2021年5期)2021-03-17
汽车工程(2021年12期)2021-03-08
——编码器
演艺科技(2020年7期)2020-08-13
时代人物(2019年27期)2019-10-23
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
电子制作(2018年1期)2018-04-04
北京航空航天大学学报(2017年12期)2017-04-23
