
利用深度学习进行目标检测
2022-09-21 07:55史宇
电脑知识与技术 2022年24期
史宇
(合肥工业大学,安徽合肥 230009)
1 引言
1.1 目标检测
目标检测的目的是在图像中寻找特定的目标(物体),并确定它们的位置和大小。首先,我们来看看如何理解一张图片?根据任务需要,可以分为三个阶段:一是分类,即图像以特定的信息类别结构化,并且使用预定义的类别(string)或存在标识符来描述图像。二是检测,分类功能负责整体并描述整个图像的内容,抓取可深入了解图像的前景和背景。三是分割,涉及语义分割和事件分割,以解决“每个像素属于什么目标或场景”的问题[1]。
1.2 深度学习
深度学习是一种人工智能技术或想法。麻省理工科技评论(深度学习#1)认为它是2013 年十大重要技术之一。深度学习在计算机视野中成长速度快,有很多趋势。它从图像排序开始,逐渐扩展到图像搜索、图像分割等。
本文展示了如何利用深度学习进行目标检测。可以通过目标检测解决三个主要问题:目标可以显示在图像的任何部分;有不同类型的目标;有不同形状的目标。如果使用长方块来表示目标,则矩形比率会有所不同。由于目标条件不同,使用滑动窗口来捕捉图像质量和解决视觉问题的成本是巨大的。
2 目标检测的应用
目标检测可以使用在很多地方,主要应用在以下领域:
2.1 人脸检测
人脸检测是解决“人脸在哪里”的问题,从图像中识别实际人脸区域,利于对面部进行诊断和识别。在图片上先进行一次目标检测可以去除图片上非人脸部分的影响,提高人脸识别的准确率,也可以在图片上找到人脸进行美颜等功能。
2.2 行人检测
行人检测包括智能驾驶辅助、智能监控、行人检测和智能机器人。在交通统计、自主驾驶等方面也发挥着重要作用。动作提取、变形处理、闭合和排序是四个行人检测中的重要部分。
2.3 车辆检测
识别交通信号灯、道路标志等交通标志对于自动驾驶也非常重要。有必要根据交通灯的状况来评估车辆左转或右转、掉头的运行情况。告诉驾驶员前面多远有行人或者车辆,车辆有哪些种类,多久有红绿灯。使人们的驾驶更安全。
2.4 遥感图像中的目标检测
高分辨率数据驱动的图像目标检测是目前遥感图像处理的一个重要研究领域。传统的目标跟踪识别方法难以适应海量数据。它们所基于的实际表示是手工制作的、耗时的,取决于数据本身的专业知识和属性,并且难以从大量数据中学习一个高效的分类系统可以完全分析数据相关性。复杂动作的强大表达(更抽象和有意义的含义)和深度学习的学习能力可以为在图像中绘制目标提供有效的框架。相关研究包括车辆检验、船舶检验、作物检验和建筑检验。除了传统的CNN 之外,诊断模型有基于超像素划分和弱监督学习。我们可以基于谷歌影像进行训练,生成想要检测的物体在地图上的坐标点,然后就可以在地图上可视化显示出物体的位置[2]。
在高分图像中分析深度学习目标的模型由两个主要部分组成。首先是通过深度学习引入目标特征。从图像像素入手,创建深度图像学习网络,通过为学习来实现图像呈现。深度网络的每一层都有特殊的意义,可以更有效地表达其目标。另一个是使用上下文信息定制深度网络。图像分析完成后,利用目标标记、目标框架和站点框架信息来调整深度网络的权重,与环境的交互提高了深度网络的可见性,提高了目标检测的性能。
3 利用深度学习进行目标检测
有两种深度学习的目标检测算法:一是两阶段(2-stage)检测模型,例如有R-CNN 算法和FastR-CNN 算法等。二是单阶段(1-stage)检测模型,例如YOLO、SSD 等算法[3]。目标检测模型成功的关键是分析的准确性和速度。具体来说,集中分析不仅要评估分类的准确性,还要评估对象放置的准确性。以下是使用每种经典算法的过程和算法。
3.1 两阶段(2-stage)检测模型
3.1.1 R-CNN
R-CNN 使用供应链方法生成大约2000 个ROI。把区域变成固定长宽的图片,并相应地添加到神经系统中(原始图像依据ROI 进行裁剪,修改,然后发送到神经网络进行训练)[4]。网络后面是几个完全互连的层,得到一个目标分类并设置一个约束框。使用候选站点、CNN、相关点来确定目标。利用始终如一的高质量ROI,R-CNN 比弹出式方法更加迅速正确。
(1)算法:R-CNN 首先搜索区域,然后对候选区域进行排名。R-CNN 使用selective search 办法生成候选区域。首先通过简单的区域算法将图像分成几个较小的区域,然后通过层次分组的方法将它们按照某种约定进行组合,最后剩下的区域为候选区域[3]。它是一个区域并且可以包含对象。
(2)流程:一是根据图像建议一系列可以包含物体的区域(即裁剪局部图像)。使用选择性搜索算法。二是在这些建议的区域中以有史以来最好的性能运行,可以获得每个区域中对象的类别。
(3)贡献:CNN 可用于按区域放置和分割对象。如果监督下的训练样本数量很少,则带有附加数据的预训练模型在分配点后可以得到很好的结果。
(4)缺点:必须训练三个不同的模型,性能问题。
3.1.2 Fast R-CNN
R-CNN 使用多个可用区域来提高正确率,但实际上大部分区域是重复的,使得R-CNN 的使用和实现非常缓慢。比如有2000个候选页面,并且需要将每个页面分别发送到CNN,则需要为每个ROI多次解压2000个特征[5](R-CNN 上需要多次合并重复)。
特征图可以直接用来识别物体而不是需要利用原始图像吗?Fast R-CNN 不是从一开始就重复检查每个图像块,而是使用属性选择器(CNN)来提取整个图像的属性。因此可以使用应用程序区域办法直接在提取器上创造它。比如,Fast RCNN 使用从VGG16的转换图来生成ROI。然后将这些范围组合成匹配的动作地图,将它们切割成动作框并使用它们来寻找目标。ROI 组允许将动作框的大小调整为固定的,并将它们移动到完美统一的层中以进行评估和放置。Fast R-CNN 不会多次检查属性,可以缩短处理时间[6]。
下面是Fast R-CNN 的过程图:
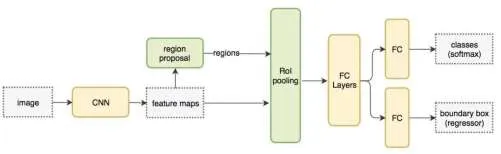
在下面的伪代码中,因为计算机密集型挖掘过程已从For Loop 站点中删除。Fast R-CNN 的计算速度比R-CNN 快10倍,最终速度比R-CNN快150倍。
Fast R-CNN 的关键在于可以训练整个网络,包括从端到端的多任务处理中选择特征、评级和盒对盒反馈[7]。这种多任务损失是估值和投资损失的组合,很大程度上提高了模型的正确性。
(1)算法:Fast R-CNN(Fast Region-based Convolutional Network)旨在缩短候选区域计算向量所使用的时间。R-CNN 要求将每个候选站点单独发送到CNN 模型中来计算向量,这需要很长时间。RoI pooling 原理是根据供应区域找到CNN 属性图对应的属性区域,将其分成若干子集(根据创建的属性图的大小),并使用每个子集的max pooling得到活动图的大小,这个过程是可控的。
(2)步骤:首先拿到feature map,同时找到ROI并分配到feature map上。然后对每个RoI 执行RoI Pooling得到一个具有相同长度属性的向量,正负样本同时处理进行分拣和返回,并统一损失。
3.1.3 Faster R-CNN
Fast R-CNN 凭借于替代的候选实践。但是它在CPU 上计算非常慢。在实验时,R-CNN 做出预测的时间是2.3s,而创建2000 ROI 的时间是2s[8]。
Faster R-CNN 使用与Fast R-CNN 一样的项目,但是它用内里深度网络替换了候选段的工作。新的站点网络(RPN)可以更有效地创建ROI,并以10 毫秒的速率为每张图像执行。
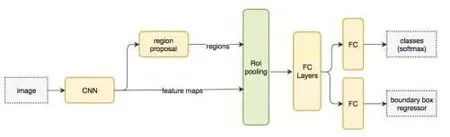
Faster R-CNN 的流程图与Fast R-CNN 相同。
候选域(RPN)从第一个聊天网络的端口管理器获取映射。使用模型卡3x3校正核心使用旋转系统构建独立的候选控制系统。可以使用其他高级系统(例如VGG 和ResNet)完成功能的完整转换,但是速度会变慢。ZF 系统将256 个值传输并传输到两个与预测目标框和两个对象编号密切相关的独立矩阵,以测量目标是否在目标框内。
RPN 为每个模型地图位置预测k 次,因此,RPN 为每个节点创建4×k 和2×k 节点。下图显示了8x8 模型图。为此,有一个3x3 的锥体核心,并且得出8×8×3 个ROI(k=3)。这里有三个想法。第一个选择包括所有形状和尺寸,因为只需要一个正确的选择。所以,Faster R-CNN 不会制作无限框。恰恰相反的是,它假设一些偏差(x、y 等)与原始图像有关,即左侧的“附着点”。附着点的选择是一样的,因为使用了这些偏移值。
为了预测任何地方,我们需要在各个地方的核心有一个附着点k。其中各个假设都和一个特定的附着点有联系,但不一样的位置区分同一类型的附着点。
因为这些附着点是经过细细选择的,所以是不同的,并以相同的图像大小和形状覆盖玻璃。这使得可以使用更准确的估计指导第一个实验,并将每个预测定位到更准确的方法。这种设计有利于基础训练。
Faster R-CNN 有很多附着点。分配了9 个不同大小的附着框。一个地方使用9 个附着点,则会创建2×9个对象编号和4×9个位置s[9]。
(1)算法:在fast R-CNN的情况下,需要另一种专门的搜索方法来创建耗时的候选区域。为了解决这个问题,模型Faster R-CNN 使用RPN 来创建瞬时候选站点。Fast R-CNN=RPN+fast R-CNN。
对于RPN,首先使用CNN 标准获取大图并导出属性图。然后在此图上使用N×N滑块并为滑块中的每个位置分配小功能。此功能分为两个完全相关的层。每个供应区域都包含一个对象或背景概率值,回归级别提取四个坐标值表示每个供应区域的状态。滑块窗口中的每个位置都将这两个完美互连的级别共享。
(2)流程:在滑块窗口中创建不同大小的锚框,设置IoU 阈值,并根据Ground Truth 调整这些锚框的优劣将双重分类和回归损失集成为RPN网络训练,并使用多任务处理将两种损害结合起来。
(3)算法贡献:网络RPN替代了专门搜索算法,让神经系统可以完成端到端的过程。
3.2 单阶段(1-stage)检测模型
3.2.1 YOLO
YOLO 利用DarkNet 功能来分析开发活动,并没有使用多个功能图进行独立分析。相反,它会部分展平行动卡并将其与其他一张低分辨率卡组合。比如YOLO把一个28×28×512的层转换成14×14×2048,与14×14×1024 的功能图接连起来。YOLO 使用新的14×14×3072 层中的复杂核心进行假设。
YOLO(v2)在实践时有许多变化,把mAP 值从宣布时的63.4提升至78.6。YOLO9000 能够计算9000 种元件类型s[10]。
下面是YOLO文档中mAP与FPS不同传感器的比较。YOLOv3 运用更复杂的旋转网络来利用这些特性。DarkNet-53 大概根据3×3 与1×1 可折叠内核和相应的ResNet 跳转循环组成。相较于ResNet-152,DarkNet 具有更小的BFLOP,但能够用两倍的速率实现同样的排序精度。
YOLOv3 还增加了一个特点椎体,使得更快速地识别小物体。
(1)贡献:通过将检测活动表示为一个集成的端到端回归问题,图像可以处理一次,同时重新排列和排序。
(2)问题:标线粗糙,小物体检测受限。但是,此后YOLOv2和YOLOv3将网络改进取得了更好的检测结果。
3.2.2 SSD
SSD 是根据VGG19 系统作为移除特征的关键传感器(类似于在Faster R-CNN 中的CNN)。在系统背面添加标准线圈表(蓝色)并使用线圈芯(绿色)进行假设s[5]。但是,卷积类别减小了空间的大小和精度。所以上面的例子只能识别更大的物体。根据这些问题本文使用多级模型卡进行独立研究。
以下是特征图图示。
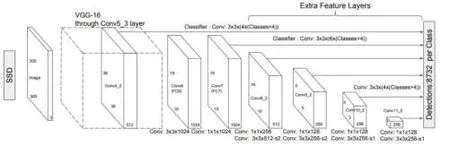
SSD 使用重复网络深层来识别对象。以几乎真实的大小重复上面的图像,会看到图片的精度明显减小,并且在低精度下难以看到的小物体不可见。此问题仍然存在则需要提高输入图片的精度s[4]。
(1)算法:SSD 网络分为两部分。一个是默认的图像评级网络,另一个是多尺度发现的映射级别,以便可以实现不同的检测。
(2)与YOLO 相比,SSD 具有以下优势:多尺度feature map:依据VGG卷积不一样的段,将feature map发送给回归器。这是提高识别小物体的正确性的。
4 总结
目标检测对人类来说并不困难。识别图像中的不同颜色单位可以更轻松地查找和排序目标,但对计算机而言,很难直接从图像中提取和定位抽象概念,而且在某些情况下还会受到更模糊的对象和背景的组合的阻碍。Faster R-CNN、R-CNN和SSD是常用的检测算法,而且利用深度学习进行目标检测的流程变得越发简单、速率也变快了。当然,对于目标检测还有很长的路要走,期待未来利用深度学习的目标检测的发展。
猜你喜欢
解放军医学院学报(2022年3期)2022-06-09
北京大学学报(医学版)(2021年6期)2021-12-13
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
中国临床医学影像杂志(2019年4期)2019-06-18
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
小学生导刊(2016年34期)2016-04-11
电测与仪表(2015年5期)2015-04-09
解放军医学院学报(2013年2期)2013-08-27
