
基于度量学习的步态识别比较研究
2022-09-16 07:15胡峻林
计算机技术与发展 2022年9期
刘 东,胡峻林
(1.北京化工大学 信息科学与技术学院,北京 100029;2.北京航空航天大学 软件学院,北京 100191)
0 引 言
随着计算机视觉和模式识别的快速发展,传统的生物识别技术已经取得了极大的突破,如指纹识别、面部识别、虹膜识别等,但是这些方法通常需要待识别者一定的配合,对采集的图像的质量要求也比较高,并且需要在近距离内完成识别。与传统的识别技术相比,步态识别是从行人的行走姿态中提取特征进行检测和比较,因而可以实现远距离、无接触的人体身份识别。近年来,步态识别已经广泛应用于安防、监控、医疗[1-3]等领域。
近二十年来,不断有新的步态识别方法提出,但是基于视觉的步态识别仍然面临着一些挑战:首先是拍摄角度问题[4],在实际应用中,行人通常以不同的角度出现在画面中,不同视角下行人的轮廓会存在明显的差别;其次,行人的状态如着装的变化、是否携带物体如背包等也是影响识别的重要因素;此外,一些环境因素如光线、遮挡、低分辨率等同样也会影响算法模型的性能。这些问题往往会改变行人的外观轮廓,进而干扰识别结果。因此,步态识别技术仍然需要进一步研究发展。
该文从度量学习视角来研究步态识别问题,并比较分析了几种经典的度量学习方法在步态识别上的性能表现,这些方法包括余弦相似度度量学习(Cosine Similarity Metric Learning,CSML)[5]、信息论度量学习(Information Theoretic Metric Learning,ITML)[6]、几何平均度量学习(Geometric Mean Metric Learning,GMML)[7]、KISS度量学习(KISS Metric Learning)[8]、边信息线性判别分析(Side-Information based Linear Discriminant Analysis,SILD)[9]。
1 相关工作
1.1 步态识别
现有的步态识别方法主要分为两大类:基于模板序列的和基于视频的[10]。基于模板序列的步态识别方法主要将步态序列转化为单张图像进行识别,这类方法首先从视频序列的每一帧中得到人体轮廓,然后将所有人体轮廓对齐并归一化成大小相同的步态模板。得到步态模板之后,可以通过机器学习方法或者深度学习方法从步态模板中提取步态特征,最后使用某种距离度量如欧几里得距离、余弦距离等度量图像之间的相似度并完成识别。步态模板的作用是将一个行走序列的信息压缩到一张图像中,典型的方法是步态能量图(Gait Energy Image,GEI)[11],由于行人在行走的时候动作是有周期性的,因此可以用单个二维步态模板代替视频序列来表示行走的特征信息。将一个行走周期内的人体轮廓图像累加后再求平均就得到一张GEI。使用GEI作为特征代替视频序列能够节省样本的存储空间并缩短识别的计算时间。基于视频的方法则直接将轮廓序列作为输入,从轮廓序列中提取特征,代表性的方法包括LSTM(Long-Short-Term Memory)[12]和3D-CNN[13]等基于深度学习的方法。这类方法虽然能够保留更多的时间和空间信息,但是计算量巨大,并且训练深度模型具有一定的困难。
近年来,不断有新的步态识别方法提出。为了解决在煤矿井下人脸、指纹等生物识别效果不理想的问题,刘晓阳等[14]提出一种基于双流神经网络的步态识别方法。该方法利用残差神经网络和栈式卷积自动编码器从步态中提取特征,并使用特征融合方法实现动态和静态特征的融合。受CNN在图像识别方面应用的启发,Shiraga等[12]提出GEINet,将GEI作为CNN网络的输入,经过两个连续的卷积层、池化层、归一化层,最后经过两个全连接层完成识别。Wu等[15]提出一种基于深度卷积神经网络的步态识别方法,该方法中设计了3个不同的以GEI为输入的网络结构,最后将这些网络融合得到识别的结果。相较于已有的方法,该方法在视角变化较大时具有明显的优势。Yu等[16]提出一种基于生成性对抗网络(Generative Adversarial Networks,GAN)的步态识别方法,称为GaitGANv2。在GaitGANv2中,生成器用于生成待识别者的标准步态图像,即穿着正常衣服且没有携带任何物品的侧视图,这样可以消除角度,着装等因素的干扰。与传统GAN不同的是,GaitGANv2中包含两个判别器,第一个为真假判别器,用于判别生成的步态图像的真假,第二个为身份判别器,用于保证生成步态图像的同时不丢失行人的身份信息。同时,GaitGANv2还采用多损耗策略优化网络,在增大类间距离的同时减小类内距离。Chao等[17]提出一种端到端的深度模型GaitSet。GaitSet中,步态序列不再保持特定的顺序,而是被视为一组相互独立的帧。该方法不受帧排列的影响,并且可以自然地整合不同场景下拍摄的不同视频的帧,例如不同的视角、不同的衣服等,在复杂的场景下有较好的性能。
1.2 度量学习
度量学习的思想起源于分类问题中的最近邻方法,度量样本数据间的相似性并将一个样本划分为距离其最近的类别。作为一种最常见的距离,欧氏距离在早期度量学习中有着广泛的应用,然而单一的距离度量无法应对更多复杂的问题。因此,度量学习的基本目的是学习一种合适的距离度量,使得分类问题中,同一类内样本间的距离最小化,不同类样本间的距离最大化,从而完成分类。
作为欧氏距离的一种推广,马氏距离越来越多地被应用于度量学习算法中,典型的有信息论度量学习(ITML)[6]、大边界成分分析(Large Margin Component Analysis,LMCA)[18]等。然而,单一的马氏距离只能学习到线性变换,一些非线性的问题就难以得到解决。因此,近年来一些深度度量学习方法不断被提出。Hadshell等[19]最早将深度学习引入度量学习中,他们提出一种对比损失函数用于实现最大化类间距离并最小化类内距离。在此基础上,后续不断有研究者做出改进,提出了三元组损失[20]、N元组损失[21]、中心损失[22]、代理损失[23]等方法。近年来,度量学习被广泛运用于人脸识别[24]、行人重识别[25]等领域。
鉴于度量学习在模式识别中的优势,该文从度量学习视角来研究步态识别问题,并比较分析了几种经典的度量学习方法在步态识别上的性能。
2 度量学习方法
在本节中,主要介绍几种用于步态识别的度量学习方法,这些方法包括余弦相似度度量学习(CSML)[5]、信息论度量学习(ITML)[6]、几何平均度量学习(GMML)[7]、KISS度量学习(KISSME)[8]和边信息线性判别分析(SILD)[9]。
2.1 CSML
余弦相似度度量学习的目的是学习一个线性变换W∈Rd×m,m≤d,其中d是变换前的空间维度,m是变换后的空间维度,来计算一对样本xi和xj在这个变换子空间中的余弦相似度:
(1)
为了学习出最优的变换W,CSML通过将目标函数表示为以下形式来最小化交叉验证误差:

β‖W-W0‖2
(2)
其中,lij=1表示xi和xj为一对正样本对(即来自同一类别);lij=-1表示xi和xj为一对负样本对(即来自不同的类别);W0是一个预定义的矩阵,如随机矩阵;参数α用于平衡正负样本对对目标函数的贡献;β用于控制正则化项|W-W0‖2的权重。最后采用基于梯度的策略求解出合适的W。
2.2 ITML
ITML方法采用广泛使用的马氏距离度量学习框架。马氏距离度量学习的目的是寻找一个半正定矩阵M∈Rd×d来计算两个样本xi和xj之间的马氏距离平方:

(3)
ITML的核心思想就是,在正样本对之间的马氏距离小于一个阈值τp和负样本对之间的马氏距离大于另一个阈值τn的约束条件下,τn>τp>0,通过最小化两个矩阵之间的对数离散度来寻找一个接近先验度量M0的距离度量M。具体可以表示为以下的优化问题:
(4)
其中,tr表示矩阵的迹运算,det表示矩阵的行列式运算。
通过迭代计算Bregman投影,可以将式(4)简化为以下形式:
Mt+1=Mt+βMt(xi-xj)(xi-xj)TMt
(5)
其中,投影参数β由样本对标签和学习率决定;t表示迭代次数。依照式(5)迭代直到算法满足一定收敛条件,便可获得需要的M。在测试阶段,当两个样本之间的距离小于一个给定的阈值时,即认为它们是同类的样本,当样本间的距离大于一个给定的阈值时,即认为它们是来自不同类的样本。
2.3 GMML
几何平均度量学习的目的是寻找一个矩阵M,用于减小正样本对之间的距离,但是与传统方法不同的是,对于负样本对,GMML使用M-1来度量它们之间的距离,而不是使用非对称的方法。GMML是通过使用M最小化所有正样本对之间的距离,同时用M-1最小化所有负样本对之间的距离来学习一个矩阵M。GMML的目标函数可以表示为如下的优化问题:
minJ(M)=tr(MS)+tr(M-1D)
(6)
其中,S和D分别表示:

(7)
这里,NS和ND分别表示正样本对和负样本对的总数目。
根据文献[7]中的理论3可知,GMML的目标函数是严格凸的。因此,式(6)中目标函数的全局最小值可以由下面过程求得闭式解:
(8)
M=S-1/2(S1/2DS1/2)1/2S-1/2
(9)
2.4 KISSME
KISSME方法将一对样本是否为同一类(正样本对或负样本对)考虑为两个独立的过程。从统计学的角度来看,可以通过似然比检验得到一对样本对是否为同一类的最优统计决策。检验假设H0:样本对不是同类样本;H1:样本是同一类样本,则似然比检验为:

(10)
当式(10)的值大于一个阈值时,接受H0;当式(10)的值小于阈值时,接受H1,即认为两个样本为同一类。KISSME方法假定样本对之间的差为单高斯分布,通过取对数并剥离常数项式(10)简化为:
(11)
这里,xij=xi-xj表示样本对之间的差向量;方差矩阵S和D通过式(7)计算求得。
2.5 SILD
与传统方法Fisher线性判别分析(FLDA)相似,SILD通过最大化类间散度矩阵SB的行列式与类内散度矩阵SW的行列式的比率来找到一组最具判别力的线性投影,投影矩阵可以通过求解以下的优化问题获得:
(12)
然而在FLDA中,所有样本的标签信息都必须已知,在某些类标签信息未知的情况下,SB和SW将无法求解。为了解决这一问题,SILD使用边信息计算散度矩阵。具体来说,通过式(7)计算正样本对的S作为类内散度矩阵,即SW=S;计算负样本对的D作为类间散度矩阵,即SB=D。
后续的求解方式与FLDA类似,由于正负样本对集合的大小显然会影响SB和SW的稳定性,导致类内散度矩阵会有大量较小的特征值,因此SILD中将SW对角化,只使用最大特征值对应的特征向量:
SW=HΛHT
(13)
在SILD中,定义一个由Λ的部分列组成的矩阵Λ',Λ'保留了Λ中较大的部分特征值,使用Λ'代替Λ进行后续运算可以有效地解决不稳定性的问题。
当求得变换矩阵W=Wopt之后,一对样本之间的距离可以表示为:

(xi-xj)TM(xi-xj)
(14)
其中,M=WWT。
3 实验与结果
本小节在两个大规模的步态数据集上进行了一系列实验,评估了几种度量学习方法的性能。
3.1 数据集
选择在CASIA-C[26]与CASIA-B[27]步态数据集上进行实验。CASIA-C是一个使用红外摄像机在夜间拍摄的大规模数据集,包含153个样本,每个样本共有10组步态序列,分别为4组正常行走的序列,2组快步行走的序列,2组慢步行走的序列以及2组背包行走的序列。在该数据集中不包含视角的变化,因此每一组序列中行人都以90°的视角出现。在CASIA-C中,使用前76个样本的所有数据作为训练集,测试集中,使用每个样本的前2个正常行走序列作为Gallery集(fn00-fn01),Probe集则划分了4组进行实验,分别是后2个正常行走序列(fn02-fn03),2个快步行走的序列(fq00-fq01),2个慢步行走的序列(fs00-fs01)以及2个背包行走的序列(fb00-fb01)。CASIA-B是一个大规模、多视角的步态数据集,共包含124个样本,每个样本有10种步态序列,分别为6个正常行走的序列,2个穿着长外套的行走序列和2个背包的行走序列。与CASIA-C相比,CASIA-B更关注视角的变化,因此每种行走序列下,又分为11个不同的角度(0°,18°,…,180°),所以,每个样本共包含110个步态序列。实验的设置上,选择目前比较主流的方案,使用前62个样本的所有数据作为训练集。测试集中,使用每个样本的前4个正常行走序列作为Gallery集(NM#1-4),为了研究模型在轮廓变化时的性能表现,划分了3个Probe集,分别为正常行走的后2个序列(NM#5-6),2个穿着长外套的序列(CL#1-2)和2个背包的序列(BG#1-2)。考虑到角度的影响,在实验时,对Probe集中每一个角度都单独测试了识别率。
2.高校校园文化建设物化倾向比较严重。高校物质文化环境的营造,应该充分体现学校的办学特色和人才培养宗旨,表现出办学历史的文化积淀与独特魅力。然而近年来,部分高校在校园文化建设中过分强调物质建设、崇尚现代化,气派的教学楼、奢华的装修、高档的设备等,造成了人力、物力、财力的资源浪费,这些不仅未能体现高校的文化底蕴和历史发展特点,而且与生态文明建设精髓严重背道而驰。部分高校师生没有形成保护生态、勤俭节约的理念,普遍存在办公室资源浪费、教室长明灯、食堂饭菜倾倒等现象,出现宿舍违章用电、破坏公共设施等行为。
在实验中,使用步态能量图(GEI)来表示行人的步态特征,最终每一个步态序列生成的GEI大小为64×32,如图1和图2所示。

图1 CASIA-C数据集生成的GEI

图2 CASIA-B数据集生成的GEI
3.2 实验结果和分析
在本节中,分别评估了几种度量学习方法在CASIA-C和CASIA-B步态数据集上的识别率,来比较几个度量学习模型在步态识别中的性能表现。首先将64×32的GEI转成64×32=2 048维的特征向量,然后通过主成分分析(PCA)方法将训练样本的特征降到500维,以加快计算速度和去除部分噪声的干扰。然后分别使用CSML、ITML、GMML、SILD、KISSME以及欧氏距离(L2)度量样本之间的距离,并对结果进行了详细的对比。
表1显示了几种方法在CASIA-C数据集上的识别准确率,其中,KISSME方法在4组实验中均取得了最好的识别精度。快步行走和慢步行走的情况下识别精度相较于正常行走略有下降,KISSME方法在这两组实验中都达到了98%以上的精度。背包的情形下,由于行人的轮廓发生较大的变化,识别精度相较于前3组实验的精度有所下降,KISSME方法在此情形下的识别精度为60.39%。

表1 CASIA-C数据集的识别准确率 %
表2至表4显示了几种方法在CASIA-B数据集上的表现。表2显示了几种方法在正常行走情形下的识别准确率,其中,SILD方法的平均识别准确率达到了99.78%,明显优于其他几种方法。CSML,GMML,L2三种方法的平均识别准确率也达到了97%以上。在正常行走的场景下,平均识别率普遍较高。表3给出了在背包情况下的识别准确率,SILD方法的平均识别准确率达到了64.26%,在90°及108°视角下的识别率都在50%以上,而其他方法的识别率在该视角下都低于40%,SILD方法明显优于其他方法。CSML,GMML,L2三种方法的平均识别率都在50%以上,而ITML的平均识别率最低,只有34.44%。同时可以观察到,背包的情形中,90°视角下的识别率普遍较低,而0°和180°视角下的识别率则相对较高,这是因为背包对行人侧面视角的轮廓影响较大,对0°和180°视角的影响相对较小。表4列出了穿外套情形下的识别准确率,SILD方法在各个角度下的识别准确率都优于其他方法,但平均准确率仅有26.54%。在穿外套情形中,各个方法的识别率都比较低,而且不同角度下的识别率没有明显的区别,这是因为穿外套对各个角度下的行人轮廓都有较大的影响。
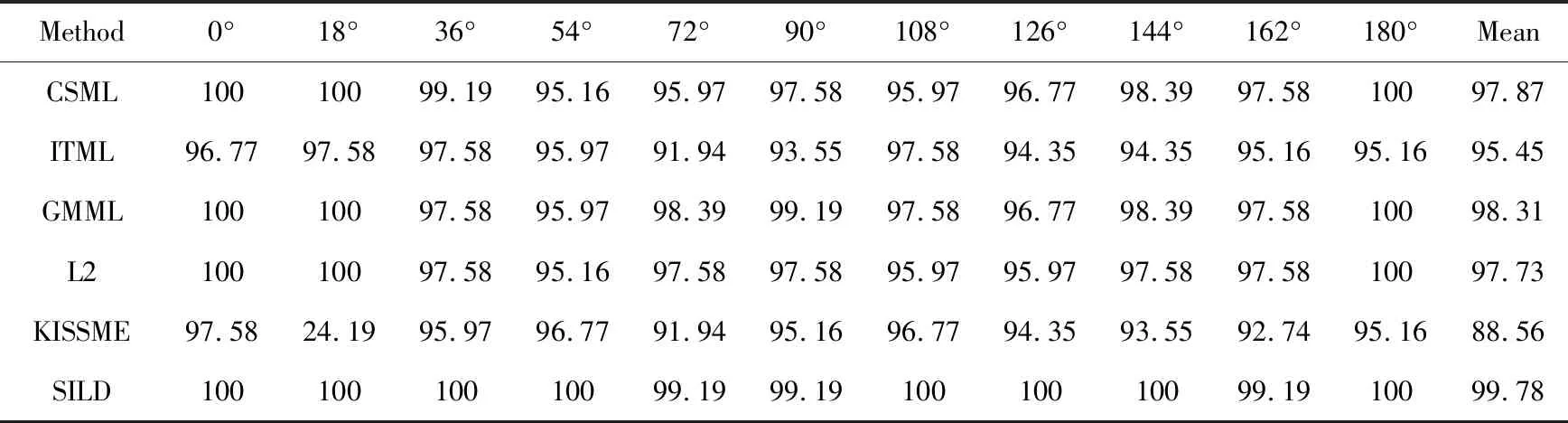
表2 CASIA-B数据集正常行走(NM#5-6)下的识别准确率 %
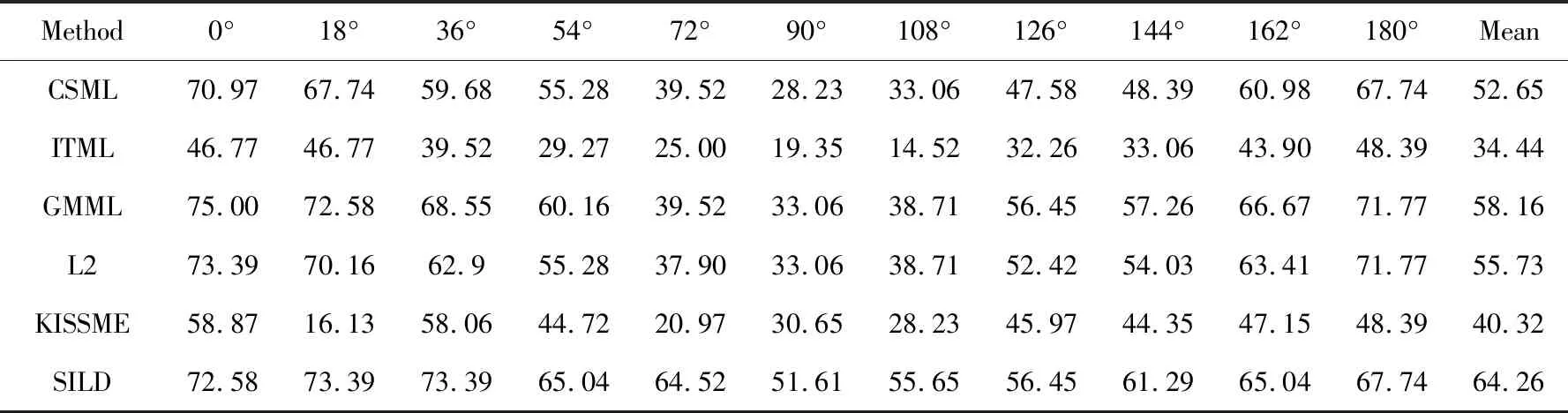
表3 CASIA-B数据集背包状态下(BG#1-2)的识别准确率 %

表4 CASIA-B数据集穿外套状态下(CL#1-2)的识别准确率 %

续表4
4 结束语
从度量学习角度研究了步态识别问题,并评估了几种度量学习方法在步态识别中的性能表现。首先使用步态能量图GEI作为行人步态特征,然后采用主成分分析方法将目标特征进行降维,最后使用几种度量学习方法在训练集上学习出数据之间的距离度量,并应用距离度量计算测试集样本之间的相似性。在CASIA-C与CASIA-B步态数据集上的实验结果展示了几种方法的识别性能,也表明了跨视角步态识别问题的挑战性,为今后的研究提供了一些基准结果。
猜你喜欢
现代仪器与医疗(2022年4期)2022-10-08
上海文化(文化研究)(2022年3期)2022-06-28
作文与考试·初中版(2019年15期)2019-04-28
江西教育B(2019年2期)2019-04-12
科学之谜(2018年4期)2018-09-17
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
中国新闻周刊(2017年20期)2017-06-15
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
