
弱监督学习下的三维点云模型簇协同分割
2022-09-15 10:27雷喜文
计算机与生活 2022年9期
杨 军,雷喜文
1.兰州交通大学 电子与信息工程学院,兰州 730070
2.兰州交通大学 测绘与地理信息学院,兰州 730070
三维模型成为继音频数据、二维图像及视频之后的新一代的数字多媒体。与传统的多媒体数据相比,三维模型以其强烈的真实感更符合人们对自然界的直观认识而受到了工业界和学术界的广泛关注。随着信息技术产业、数据驱动和深度学习等技术在计算机视觉和计算机图形学中的广泛应用,三维模型分割取得了显著的进展。三维模型的分割问题是三维模型分析领域的一个基础性问题,它是根据三维模型的几何及拓扑特征,将三维模型分割为若干具有意义、各自连通且相互独立的语义部件,以帮助三维模型的理解和分析,是计算机图形学研究的重要问题。
近年来,随着激光扫描和类似的三维传感技术的广泛应用,三维点云成为三维几何数据表示的基本格式,并广泛应用于许多领域,如自动驾驶汽车、虚拟现实、三维城市建模等。一些深度学习方法开始尝试对点云数据进行分析和处理。文献[3]提出PointCNN 网络模型可以直接将卷积神经网络结构作用于无序的点云数据,避免了特征随输入点顺序的变化而改变,增强了网络对模型的处理能力。文献[4]提出了可以直接对点云进行分类和分割的深度学习网络框架PointNet。考虑到点云的稀疏性,未将点云转换为多视图或体素网格,从而能保留更多的三维特征信息,取得了较好的分割结果。文献[5]提出一种多特征融合的三维点云模型分割方法,通过构建注意力融合层学习全局单点特征和局部几何特征隐含关系来充分挖掘模型的细粒度几何特征,以得到更好的模型分割结果。目前,基于深度学习的三维点云模型分割方法大都依赖于带标记的训练数据集,使得此类方法推广受限。
最近,研究者发现三维模型簇的协同分割(cosegmentation)相比单个三维模型可以提供更多的有效信息,可以取得比单个模型更好的分割结果,并且可以同时对不同姿态的同类模型或者拓扑结构相似的不同类模型进行协同一致分割。因此,近期关于三维模型分割问题的研究主要集中于对三维模型簇进行协同分割。文献[6]从有标签的数据集中学习模型潜在的共有特征,以此进行模型的协同分析。因此,若带有标签的数据集数量足够多,有监督的算法就能取得理想的分割结果。然而,获取高质量的标签数据费时费力,成本高昂。相反,文献[7]提出一种无监督的协同分割方法,将输入模型分割成面片,然后通过子空间聚类对相似面片进行分类。虽然无监督三维模型分割算法能利用无标签的数据实现三维模型的协同分割,但这种分割算法以降低分割准确率为代价。结合点云数据的特点,本文提出了一种基于弱监督学习的三维点云模型簇协同分割网络。在特征提取过程中,利用局部卷积操作能更好地关联点与点之间的特征信息,提高网络对点云模型的识别分割能力。由于同类模型具有相似的特征信息,用相似部件矩阵就可表示同类部件特征,网络在学习时,可以对同类型的多个模型协同进行学习。此外,深度学习网络以能量函数为引导,通过反向传播优化网络参数,从而实现对点云模型簇的一致性分割。算法的主要创新点和贡献有:(1)对原始点云数据进行采样时,为了弥补采样损失,采样之前在被采样点集中选择子集的邻域,能够将丢弃点的信息嵌入在关联点的邻域中,在降低网络计算复杂度的同时保留更多点的特征信息。(2)将弱监督学习方法用于三维点云模型分割,能降低网络训练阶段对高质量带标签数据集的依赖性,该方法只需要在训练阶段标记一小部分点就能实现与有监督方法相媲美的分割结果。
1 相关研究工作
三维模型的分割有助于模型的后续分析、处理和应用。目前,三维模型的分割形式主要有两类:单体三维模型分割和三维模型簇协同分割。
基于几何的分割方法利用特定的描述符提取三维模型的几何特征,通过分解和聚类技术完成三维模型分割。随机游走(random walk,RW)算法和分水岭(watershed segmentation,WS)算法是二维图像分割中常见的算法,研究者将其扩展用于三维模型分割。Shlafman 等人提出将均值聚类应用于三维模型分割,通过聚类相似面片得到分割结果,该方法的分割面片数目可以预先设定,从而避免了过分割。Liu 等人提出谱聚类算法,将三维模型分割问题转化为图的切割问题,通过图构建一个相似矩阵并结合均值聚类算法得到模型的分割结果。然而,这些方法依赖于特征描述符提取的几何层面的低层次特征,无法提取具有语义性质的高层次特征,而且若输入的是同一类的若干三维模型,利用单一的特征描述符分割的结果往往会存在较大的差异。
近年来,随着深度学习技术的发展,研究者开始将其应用于三维模型的分析领域,形成了基于数据驱动的模型分析方法。深度学习尽管在二维图像数据分析方面取得了巨大成功,但由于三维模型具有复杂的特征和拓扑结构,无法像二维图像一样直接将原始数据输入到学习算法中,因此许多学者致力于采用卷积神经网络(convolutional neural network,CNN)分析三维模型。文献[12]提出了基于多视图的卷积神经网络(multi-view convolutional neural network,MVCNN)。其思想是首先将三维模型投影为多个视角下的二维图像,得到不同视角下该模型的多视角姿态图像;然后通过CNN 对每个视图提取特征,将不同视角下提取的特征通过图池化层进行聚合;最后将聚合后的特征再输入到CNN 中,从而获得三维模型的分割结果。文献[13]提出一种基于体素的卷积神经网络(deep voxel convolutional neural network,DVCNN)的方法。首先利用体素化技术将三维多边形网格模型转化为二值的三维体素矩阵,然后通过深度体素卷积神经网络获取模型的深层特征。然而,多视图和体素化方法在处理三维模型过程中都要将原始数据转化为卷积神经网络可以处理的数据形式,这一过程会丢失三维模型的信息,例如体素化会损失空间分辨率,多视图会丢失三维模型的部分几何信息。
以上这些方法都是针对单体三维模型的分割,在有监督的分割方法中,单个模型无法提供足够的几何信息,且需要人工设计大量的标注数据,即使在大数据时代,获取大批高质量的标注数据往往成本高昂,限制了此类方法的发展。
近年来,研究者开始关注三维模型簇的协同一致分割。协同分割旨在对一组拓扑结构相似的同类或不同种类的模型进行一致分割,其利用模型排列方式和共同特征,在模型间建立对应关系传播相关性信息以实现协同分割。Golovinskiy 等人首次提出协同分割方法,将三维模型协同分割问题转化为图分割问题,通过对齐所有模型并聚类其图元来获得模型簇的一致性分割。Sidi 等人引入了一种基于描述符的模型分割方法,该方法依靠多个特征描述符来表征原始面片之间的特征,将协同分割问题看成特征空间的聚类问题。文献[18]提出了一种基于深度学习的无监督三维模型分割方法,利用深度神经网络从低级特征中提取若干同一类模型的高级特征,并将这些高级特征进行聚类运算得到模型的一致性分割结果。然而,由于低级特征描述符提取的特征容易受到三维模型的几何形状和拓扑结构的影响而改变,为了解决这一问题,研究者提出了有监督的方法,将分割视为一个标记问题。Kalogerakis等人利用机器学习技术,构造分类器来预测类标签。Guo 等人引入了使用卷积神经网络预测标签的深度学习框架。这两种方法都是基于几何特征和人工标记的训练数据。文献[21]提出的PointNet++网络架构直接作用于点云数据,将点作为输入并输出类标签,能进一步提升模型分割效果。但是此方法对带标签的数据集依然有较强的依赖性,数据集的质量影响网络的性能。此外,为了实现模型簇的协同分析,需要在整个模型簇中逐点分析各个模型的共有潜在特征,将这些特征进行协同分析难度较大。目前,弱监督学习是一种能降低网络对带标签数据集依赖性的方法,文献[22]提出一种胶囊网络能以小部分标注的数据实现三维点云模型分割任务,但网络中的动态路由机制需要耗费大量的存储空间,并且在模型重构过程中存在一定的误差。文献[23]构建了一种基于分支式自动编码器的协同分割网络架构,其中每个分支分别学习输入模型的一个部件特征。该网络能以弱监督学习方式实现模型分割任务,但缺乏模型簇的一致性优化且对输入集较小的模型簇分割效果不佳。文献[24]提出一种利用云级弱标签来训练语义分割网络的方法。该方法可以显著降低标注数据集的人工和时间成本,且一定程度上解决了类标签数据不均衡的问题,使得网络提高了对小对象的分割精度,但该网络设计的多路径注意力模块可能会导致网络复杂度较高。文献[25]提出一种作用于点云数据的自适应协同分割网络架构,将三维模型分割转化为点标记问题。该方法通过迭代最小化组一致性损失来生成模型部件标签以实现同类模型间的协同分析,但当不同类别模型混合在一起时,网络便很难学习到其所有部件特征,且学习的权值不能随着新模型的出现而不断更新,使得跨类别学习受限。
综上所述,虽然无监督和有监督三维模型协同分割方法在一些场景下取得了比较好的结果,但无监督方法过度依赖人工设计的描述符,有监督的方法又依赖于大量人工标注的数据集,这两种方法都费时费力,增加了网络的学习成本。而弱监督学习(weakly supervised learning,WSL)方法可以看作上述两种方法的混合,并且弱监督学习技术作为一种可以同时有效利用有标签数据和无标签数据的学习范式,大大降低监督任务对于标签数据的需求。因此,本文在文献[4]的基础上,提出一种基于弱监督学习的卷积神经网络架构,实现对三维模型簇的协同一致分割。
2 三维点云模型分割及特征提取
三维点云模型由一系列具有几何信息的点集构成,其分割的实质是对点集进行逐点分类,旨在将同一类别的点分类到所属的部件中得到模型分割结果。因此,本文提出利用局部卷积方法并构建局部邻域图来解决上述问题,并通过弱监督方法采用少量标注的数据进行训练,提高了网络架构的普适性和分割效果。
2.1 构建点云模型局部邻域图
三维点云模型是一组无序点的三维坐标信息集合,然而每个点也不是独立存在的,相邻点之间有相似的几何信息,因此,建立点与点之间的关联性可以更好地表征三维模型的局部特征信息,图1 为点的邻域图构建过程。定义一个点集为{p=(x,y,z)|=1,2,…,},其中p为点云中任意一点,由该点对应的坐标(x,y,z) 表示,以p为中心点利用K 近邻(Knearest neighbour,KNN)方法建立局部有向图,由顶点集和边集构成,定义如下:

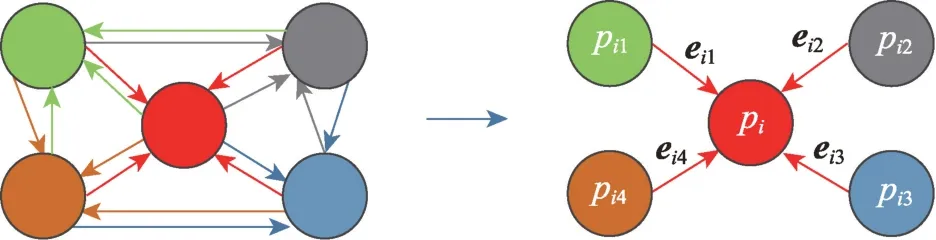
图1 邻域图构建过程Fig.1 Construction process of neighborhood graph
式中,e为第个有向边集合,e表示相邻点p到中心点p的有向边。
2.2 局部卷积操作提取特征
局部卷积操作用于提取中心点的特征和中心点与K 近邻域点的边缘向量。由于点云模型是一组无序的点集,采用最大池化操作,该方法不受邻域点顺序的影响,可以提取所有边向量中最主要的特征。对所有的点定义一个相同的特征提取函数f,则输入一个中心点是p的局部邻域图可以得到输出局部特征l,公式如下:
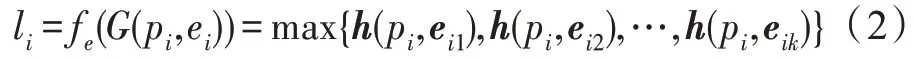
式中,(p,e)是中心点p和一个边向量e之间的隐藏特征向量。输出的局部特征l取隐藏特征向量的最大值max{}。
对于分割任务,需将全局特征与提取的局部特征逐点进行拼接,并采用多层感知机(multilayer perceptron,MLP)对每个点输出一个预测分数。因此,局部卷积操作方法公式定义如下:
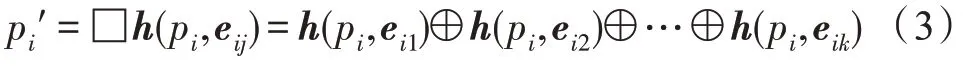
式中,p′表示更新后的点特征,它将每个点的自身特征与对应的邻点相关联,□表示一种通用的对称函数,如池化操作或者求和。总之,局部卷积将多层感知机应用于每个点和相应的邻域以捕获局部感受野,然后用最大池化运算生成与局部特征相关联的新维度特征的新点集。局部卷积过程如图2 所示。
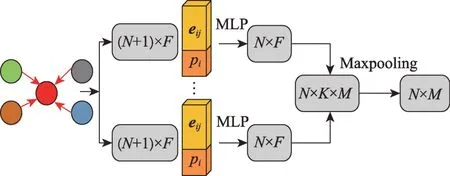
图2 局部卷积过程Fig.2 Local convolution process
局部卷积操作的最主要作用就是生成边特征,其用于表征每个点与其邻域点之间的关系。这种卷积方法有两个优点:(1)通过KNN Graph 能够在保持排列不变性的同时,可以更好地提取点局部信息,提高点云模型的分割效果;(2)在经过多层迭代之后能够更好地捕捉到潜在的远距离相似特征。
3 协同分割网络
每一个三维点云模型都是三维空间中逐点坐标构成的集合,为了建立多个同类模型之间的关联性实现协同分析,根据三维点云模型的特性,本文提出了基于局部卷积操作部件分割网络。首先将点集输入到网络并建立关于点的局部邻域图,以每个点为顶点,相邻点之间的有向边表示相邻点对之间的关联性;然后利用局部卷积操作提取点云模型特征,得到各类部件的分割结果;最后利用相似部件矩阵分析模型之间的协同性。
本研究中构建的深度学习网络结合了弱监督学习方法,旨在对同类模型的若干少量标注的样本同时进行学习,因此网络在提取模型特征之后,将同类部件特征描述符堆叠于相似部件矩阵,然后用一个能量函数在反向传播中不断优化网络参数,从而实现对同一类模型的多个样本的一致性分割,网络的协同分析特性也由此体现。
3.1 局部卷积网络
设三维点云模型为点集{p=(x,y,z)|=1,2,…,},其中表示点的数目,网络将点云数据作为输入,直接对原始点集进行采样。为了减少采样损失,本文提出在采样前从被采样点中选择子集的邻域,这样就能将丢弃的点的信息嵌入在邻域中。如图3 所示,使用迭代最远点采样(iterative farthest point sampling,FPS)策略选择个点作为子集。首先,从原始点集中取出一个点p作为起始点,并写入子集中,然后迭代地将与上一个选取点的距离最远的点添加至子集中,直到取够个点。与随机采样相比,FPS 策略对整个点集有更好的覆盖率。
三维点云模型分割的实质是对点的逐点分类,即为点集中的每个点预测一个部件类别标签,因此需要提取所有点的特征。常用的策略有两种:一种是文献[4]和文献[26]采用的将所有点作为质心来进行采样的方法,即将整体和局部特征连接在一起输出每个点的预测分数。然而,这种方法会导致较高的计算成本。另一种是文献[21]采用的基于距离插值的分层传播策略和跨层跳跃链接方式。本文基于第二种策略,结合KNN 算法和局部卷积方法进行上采样,为了从给定的子采样点集及其对应特征中生成插值点,插值策略基于个近邻点的欧式距离平方倒数值的加权平均值,其值由式(4)计算可得。

式中,w()=1/(-p)是和p之间的欧式距离平方的倒数。将插值后的点特征与相对应层点特征拼接在一起,并通过局部卷积将它们融合。
基于局部卷积的部件分割网络的基本架构如图3所示。首先,原始点云数据经过两层为采样层和对应的局部卷积层操作,转化为128×128 的张量。然后,使用两个上采样层和相对应的局部卷积层([256,256],[512,512,1 024])提取细粒度特征。最后,通过一个最大池化操作获取点云的全局特征,并且利用4个多层感知机(256,256,128,)将全局特征转换为个部件类别,dropout设置为0.6。
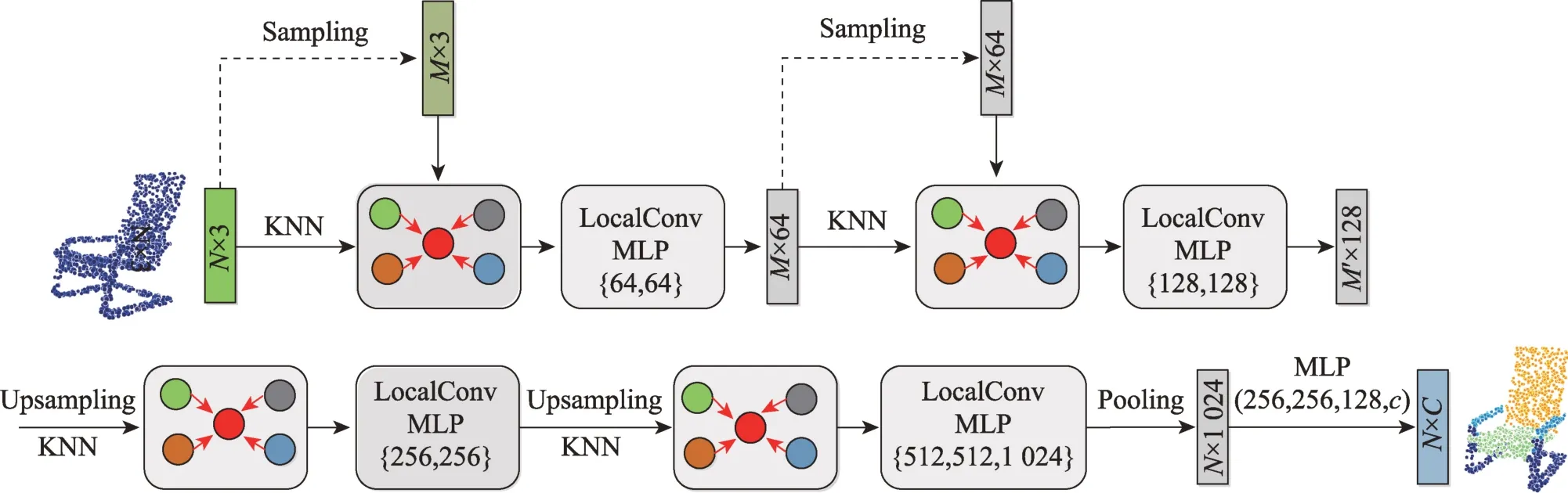
图3 局部卷积的部件分割网络Fig.3 Component segmentation network of LocalConv
3.2 协同分割网络总体架构
本文构建的协同分割网络通过反向传播学习到最优的网络权值,该方法基于部件特征上定义的能量函数,公式如下:
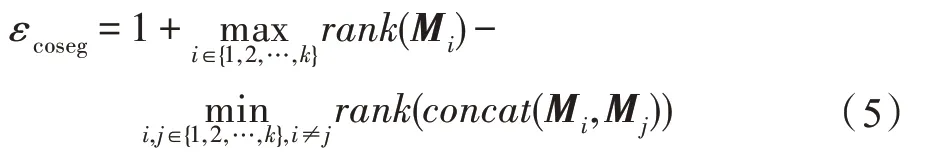
式中,M和M分别表示不同的部件特征矩阵;表示矩阵的秩大小;表示将两个不同的部件矩阵联合。
图4 为协同分割网络总体架构。网络首先对原始点云数据利用最远点采样法进行采样,经过局部卷积网络得到部件分割结果。在此过程中,网络对同一类别三维点云模型的多个样本同时进行训练,经过全连接层将点云模型逐点进行分类,使每个点得到一个预测分数,接着将个类别的抽象标签{,,…, L}分别分配于每个模型中的逐个标记点,以此判断该点属于哪一个部件,并通过权值共享和标签传播方法预测未标记点的所属部件类别,每个模型中带标签L的点集构成模型的单个部件。然后采用最大池化(max pooling)操作为每个模型的各个部件生成一个与之对应的特征描述符,且带有标签L的所有部件具有相似的特征描述符。最后,将所有带标签L的部件描述符堆叠在一个特征矩阵M中,且矩阵秩越小表示部件的特征越一致。此外,将带不同标签的特征描述符拼接在一起,构造一个新的联合矩阵(M,M)。因为带不同标签的部件具有不同特征,所以矩阵M和矩阵M的行并集的秩更大,该矩阵秩越大,表示不同部件之间的特征越不一致。因此,本文算法以最小化同类别语义标签的部件特征矩阵的秩,同时最大化不同类别语义标签的联合部件特征矩阵的秩为目标,优化协同分割网络的权重实现模型簇的一致性分割。

图4 协同分割网络架构Fig.4 Co-segmentation network framework
3.3 弱监督学习
本研究基于弱监督学习方法构建协同分割网络获得点云模型一致性分割结果,在网络训练的点云数据中只需标记很小一部分点,就可以产生接近甚至优于有监督的结果。因此,本研究的核心在于利用弱监督学习方法以少量标记的数据以实现三维点云模型簇的协同分割。
基于深度学习的弱监督学习方法一般根据其数据类型可分为三类:不完整监督学习,其数据中只有一部分有标记;不确切监督学习,其数据中标记数据粗粒度太大;不准确监督学习,其数据中标签有错误。本研究中采用不完整的弱监督学习方法,旨在使用较弱的标注数据进行实验。训练集只需要在训练阶段标记很小的一部分点,并且通过KNN 算法构建局部邻域图获得点与点之间关联特征。此时,图中的每一个节点就是一个数据点,包含已经标记和未标记的数据,并以标签传播的形式推断出未标记点的所属类别。为了实现标签传播,将构建的KNN邻域图的相应的权重矩阵∈R表示为:
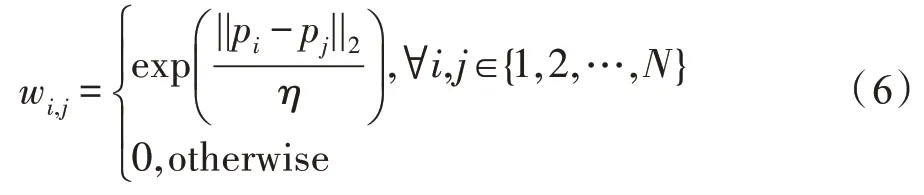
式中,||p-p||表示点对之间的距离,为超参数。利用KNN 算法只保留每个点的K 近邻权重,其他为0。然后通过节点之间的边传播标签,边的权重越大,表示两个节点越相似,使得标签容易从标记点传播到未标记点。因此,定义概率转移矩阵:

式中,t表示标签从节点转移到节点的概率。经过标签传播策略,深度神经网络便学习到了更多的带标签的数据,经过能量函数反馈使网络参数达到最优,这样网络的输出便是理想的协同分割结果。
4 实验结果与分析
本实验采用的实验环境为Linux Ubuntu 16.04 操作系统,硬件是Intel Core i9 9900k CPU 和NVIDIA Rtx 2080Ti GPU(11 GB 显存)处理器,采用的深度学习框架为Tensorflow,基于该框架的深度学习运算平台为CUDA 9.0,GPU 加速库为cudnn 7.0。
4.1 数据集
为了与其他算法进行比较,本文采用ShapeNet Parts数据集,该数据集包含16 881 个三维模型,16个类别,共50 个带有标签的部件,大多数模型都被标记为2 至5 个部件,且标签都被注释在三维模型的采样点上。
4.2 参数设置与性能评价
为了提高模型分割精度,从模型表面均匀采样2 048 点进行训练和测试实验。实验中采用自适应矩估计(adaptive moment estimation,Adam)对神经网络模型进行优化。初始学习率设为0.003,以便在较高的学习率下快速得到最优解。动量设置为0.8,避免网络在更新参数时陷入局部最优。为防止训练时网络中间层数据分布不一致,在网络的每个输入层前插入一个批归一化层(batch normalization),将批处理归一化的指数衰减系数设为0.5,使损失函数能够快速收敛。在本实验中,批尺寸大小设置为32 时,对网络梯度的影响最小。
4.3 评估标准
三维点云模型的分割准确率以点集上的交并比(intersection over union,IoU)来度量,IoU 主要计算两个集合的交集和并集之间的比率,用于模型分割指真实分割部件和预测部件的交集和并集之间的比率,对于点云模型分割任务,需要先计算每类模型的IoU 值,公式如下:

式中,表示真正样本数量;表示真实的真样本数量;表示预测的真样本数量。
在得到每类模型的IoU 值之后,为了评估网络对整个模型簇的分割效果,需要引入平均交并比(mean intersection over union,mIoU)来进行度量,公式如下:
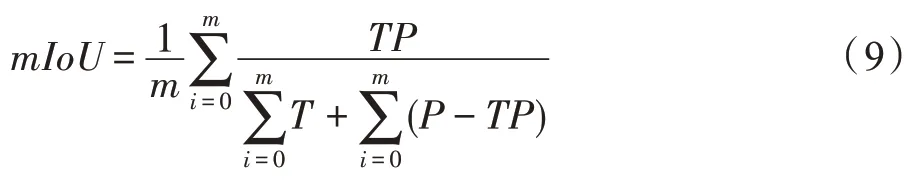
式中,表示三维模型的类别数,mIoU 的值越大表明真实值与测试值越接近,从而得到模型分割的效果也更好。在ShapeNet Parts 数据集中,由于不同类别的模型数量均不同,需要从定量的角度继续对分割准确率进行评估,故引入部件交并比(part averaged IoU,pIoU)进一步做对比,公式如下:
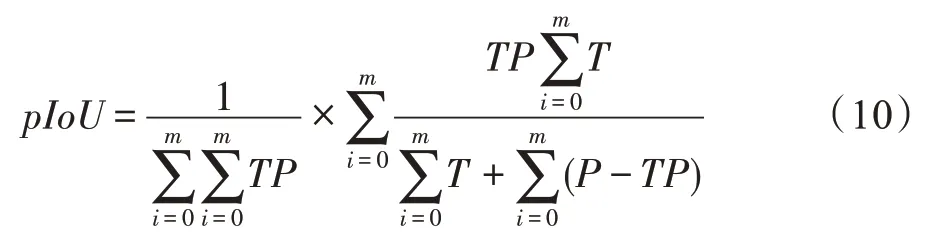
该式表示根据每一类模型出现的频率对各个类的IoU 进行加权求和,本实验中频率即每类模型的数量。pIoU 值越高,表明分割准确率越高。
4.4 实验结果分析
本文算法对三维点云模型簇的协同分割效果如图5 所示,其中不同颜色的点云表示不同的模型分割部件。可以看出,每一类模型对应的同类部件的颜色是一致的,较好地体现出了三维模型簇协同分割的一致性。
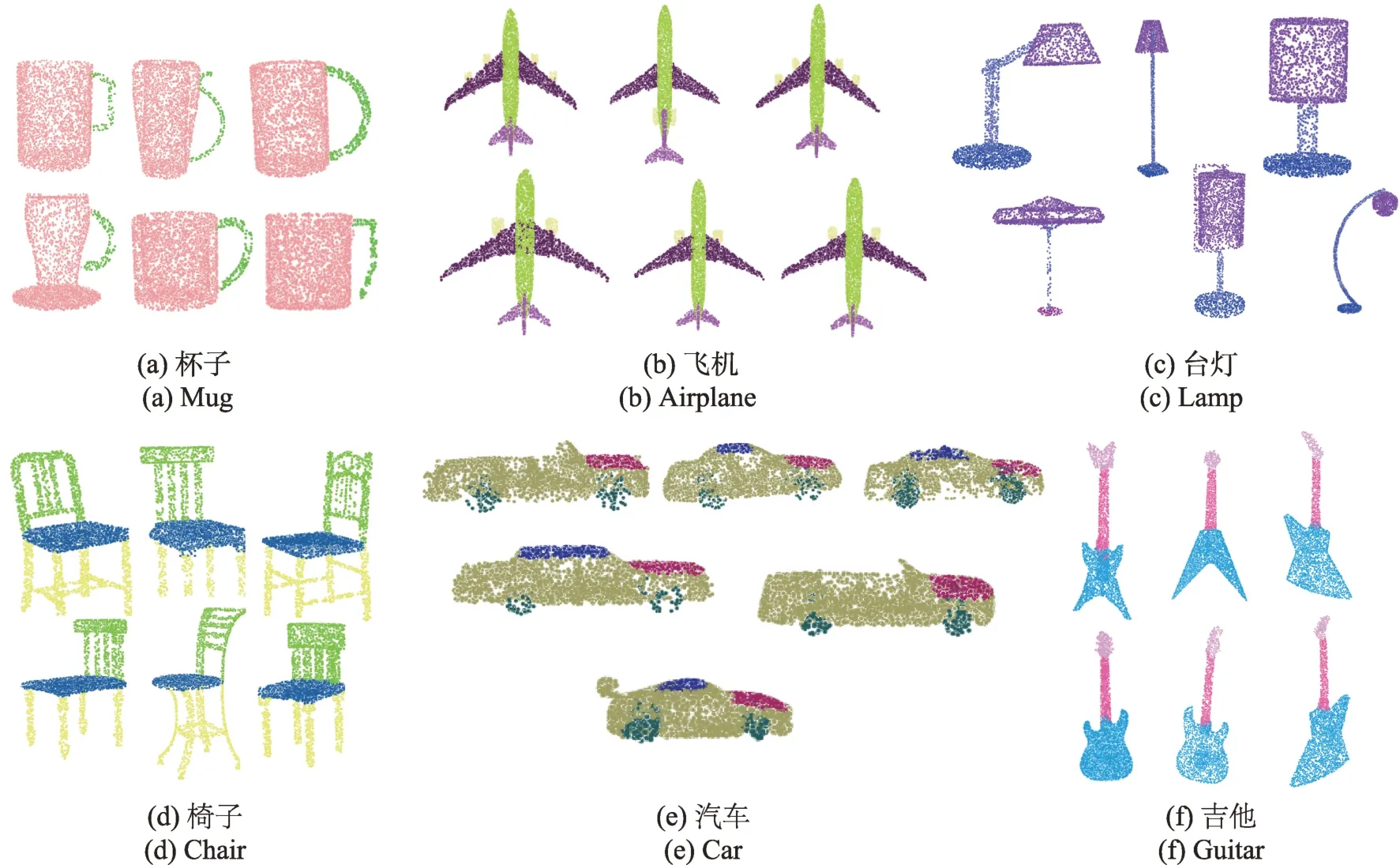
图5 点云模型协同分割结果Fig.5 Co-segmentation results of point cloud shapes
本文算法与文献[4]、文献[21,23]、文献[26]和文献[28]的算法在ShapeNet 数据集上的实验结果对比如表1 所示。本文算法采用了弱监督策略,并通过KNN 方法建立点的局部邻域图以更好地关联采样点之间的信息,当对模型中的各个部件分别只标记一个点时已经能够获得具有竞争力的结果,当标记10%的点时,相比文献[4]的算法,mIoU 值提高0.012,pIoU 值提高0.014。此外,本文算法以一个能量函数反向传播迭代产生模型的一致性分割结果,相比文献[28]采用的递归邻近搜索策略的mIoU 值提高0.042,pIoU 值提高0.027。由于本文算法采用弱监督学习策略,并且用少量标注的数据进行实验,分割准确率略低于文献[21]和文献[26]的方法。但其相比文献[22]和文献[23]所采用的弱监督策略,mIoU 值分别提高0.007 和0.017,pIoU 值分别提高0.001和0.004。
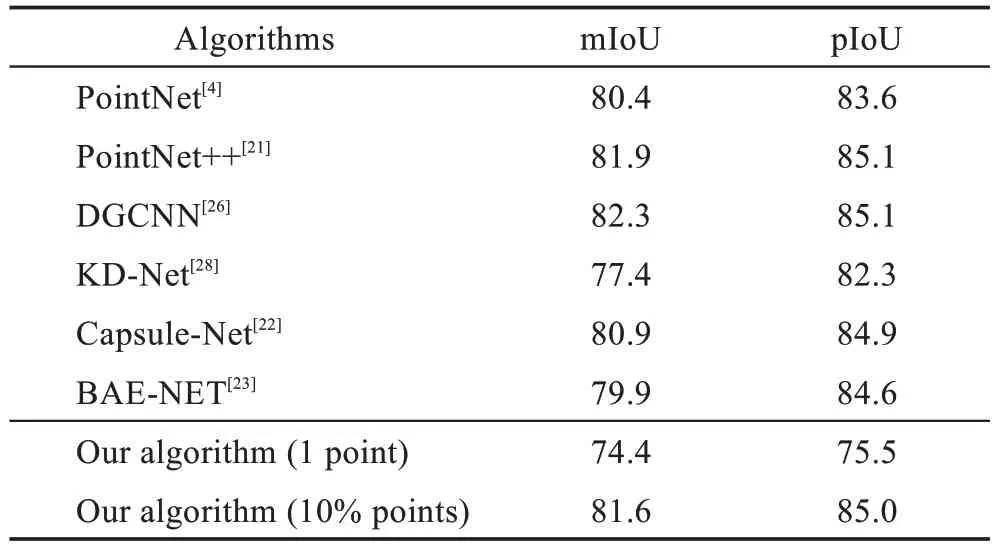
表1 不同算法的分割准确率对比Table 1 Comparison of segmentation accuracy of different algorithms 单位:%
本研究进一步对比不同算法在各类模型上的分割准确率,结果如表2 所示。文献[4]、文献[21]、文献[26]和文献[28]都采用了有监督策略,而文献[22]、文献[23]和本文算法采用了弱监督策略,当模型各部件被标记一个采样点时,本文弱监督策略与文献[28]的有监督策略相比,部分模型的分割准确率有一定的提升,其中帽子模型(cap)和杯子模型(mug)的准确率分别提高0.049 和0.036。当训练样本中被标记采样点提升至10%时,各类模型的分割准确率已能和对比文献有监督策略的分割结果相媲美,且部分模型的分割效果甚至优于有监督学习方法。对比文献[28],汽车模型(car)和火箭模型(rocket)的分割准确率提升最为明显,分别提高0.075 和0.101。文献[26]采用边缘卷积方法关联点云模型点之间的特征,当分割训练样本数目较多的模型时,分割结果优于其他算法,如飞机模型(airplane)、椅子模型(chair)和吉他模型(guitar)。对比文献[26],本文算法在飞机(airplane)、椅子(chair)和吉他(guitar)三类模型的分割准确率分别降低0.005、0.011 和0.006,但在汽车模型(car)、刀模型(knife)、火箭模型(rocket)和桌子模型(table)上的分割准确率分别高于文献[26]算法0.007、0.003、0.022 和0.009。文献[22]利用动态路由驱动的注意力机制能有效提取局部特征信息,从而对模型的细小部件具有较高的分割准确率,如对摩托车模型(motorbike)的分割准确率高于本文算法0.044。文献[23]采用分支自动编码器,每个分支分别学习输入模型的一个部件特征,没有模型簇一致性优化,对于输入集数目较少的模型类别分割准确率较低。如本文算法在包模型(bag)、耳机模型(earphone)和火箭模型(rocket)的分割准确率分别高于文献[23]算法0.099、0.069 和0.048。实验结果表明,与有监督算法相比,本文弱监督策略能够在标记点减少至10%的情况下,对各类模型分割时依然能够获得具有竞争力的结果,与采用不同策略的弱监督方法相比,本文算法的主要优势在于通过构建部件特征矩阵来约束模型分割结果的一致性,并在更弱的监督情况下以标签传播策略实现对未标记点的标签预测,能在完成协同分割任务的同时进一步提高分割准确率。因此,弱监督策略的优势在本文算法中也得以体现。
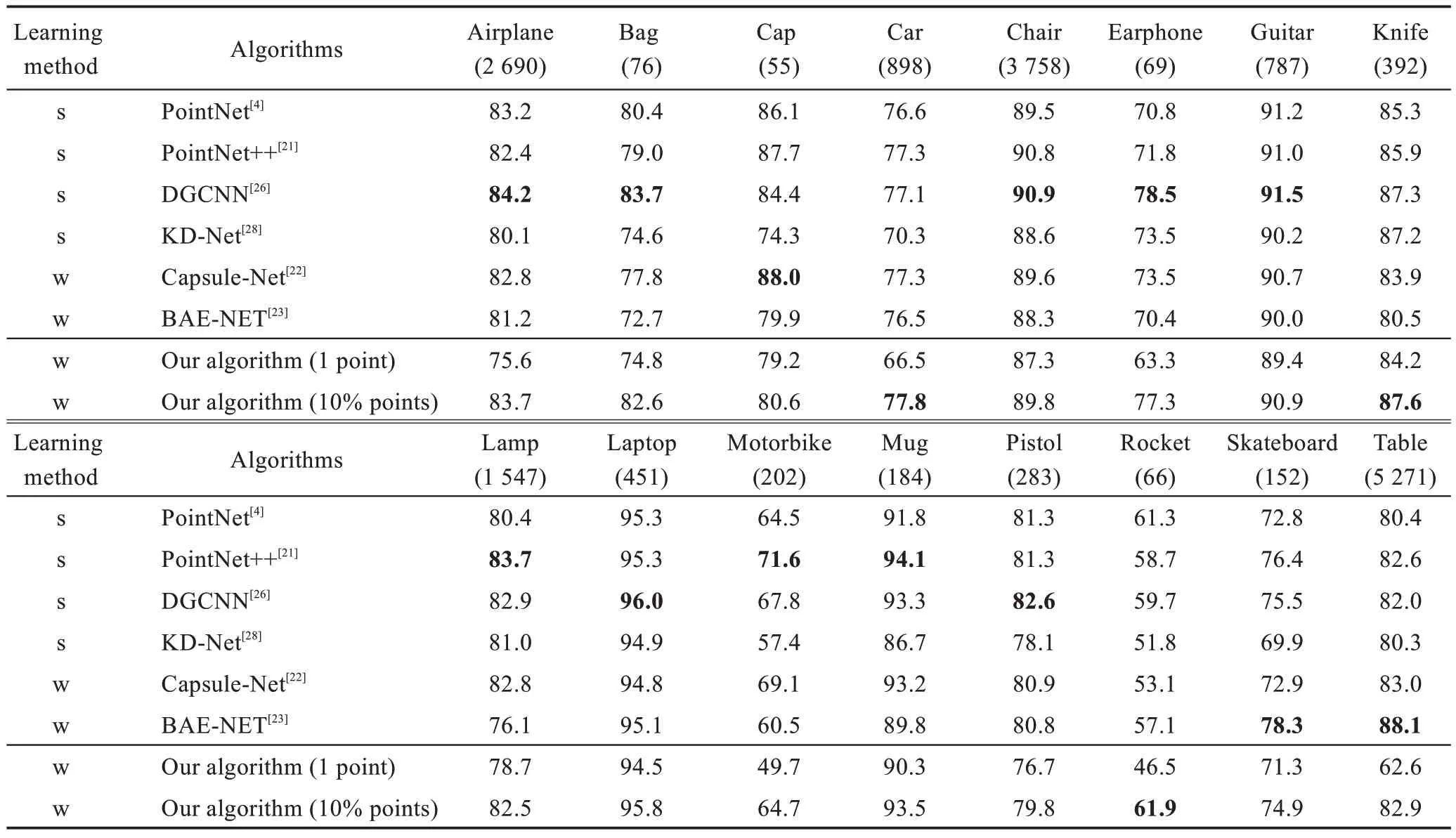
表2 不同算法在各类模型的分割准确率对比Table 2 Comparison of segmentation accuracy of different algorithms on each category of shape cluster 单位:%
本网络架构的各模块作用至关重要,为了更好地分析网络各模块对结果的影响,消融实验的分割准确率对比如表3 所示。可以看出:(1)对网络性能影响最大的是局部卷积模块,将局部卷积模块移除后分割结果mIoU 降低为56.3%,在图2 中展示了该模块的结构特点,在经最远点采样之后,局部卷积能表征每个采样点与其邻域点之间的空间关系,以弥补采样过程丢失的特征信息。(2)移除能量函数(energy function)对分割结果的影响次于(1),证明这个模块能有效实现反向传播学习,并以特征矩阵来约束分割结果的一致性。(3)利用随机采样替换最远点采样之后,分割准确率有所下降,因为该采样方法不能对采样空间有很好的覆盖率,不利于后续提取特征信息。经消融实验结果表明,本文构建的网络各组件是有效的,并且能够相互补充以达到最佳性能。

表3 验证各模型组件有效性的消融实验对比Table 3 Comparison of ablated experiments to verify effectiveness of each model component
为了验证本文算法所采取的弱监督样本标注策略具有一定的优势,实验中分别对三种标注策略进行验证,对比结果如表4 所示。标记策略由100%的训练样本(sample)和每个样本具有的标记点(Pts)所限定。实验结果表明,随着训练样本的标记点从100%降低至10%,分割结果的mIoU 值从82.19%降低到81.70%,pIoU 值从85.10%降低到85.00%,分别降低0.49个百分点和0.1个百分点。因此,从实验结果可知随着标记点数比例的减少(由100%减少到10%),本文算法的分割准确率变化并不明显,有效验证了本文算法对标记点数量的依赖性较小,对标记点的减少有很强的鲁棒性和弱监督性,节约了费时费力的人工标记成本。
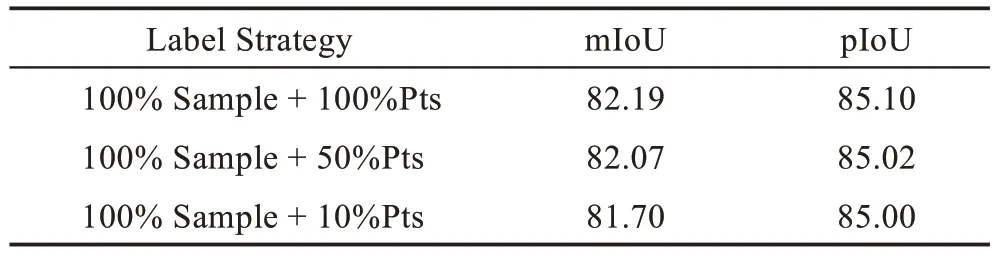
表4 不同标记策略对ShapeNet Parts分割的比较Table 4 Comparison of different labelling strategies on ShapeNet Parts segmentation 单位:%
5 结束语
本文提出了一种基于弱监督学习的协同分割网络架构,目的是以少量标记数据解决三维点云模型的协同分割问题。首先,使用最远点采样方法对原始点云进行采样,并通过KNN 算法建立点的局部邻域图关联点与点之间的信息,从而更好地表征模型局部特征。然后,利用局部卷积方法提取模型特征,以生成模型各部件对应的特征描述符。最后,通过构建部件特征矩阵,通过深度学习网络中的能量函数反向传播迭代得到模型簇的一致性分割结果。在ShapeNet Parts数据集上进行实验,与文献[4]、文献[26]等有监督方法相比较,本文提出的深度学习网络只需要少量标记点就可以有效实现点云模型分割,而且在标记点减少至10%的情况下可取得与有监督算法相媲美的结果,并与文献[22]和文献[23]弱监督方法相比,本文算法在更弱的监督情况下取得了更好的分割结果。然而,本文算法也存在局限性:一方面,算法对于每一个点在LocalConv 都有明确的近邻关系,因此网络计算复杂度更大,在处理大规模点云数据时效率会降低;另一方面,由于本文算法采用弱监督策略,在数据集需求方面具有明显优势,使得网络具有更强的普适性,但是与完全有监督算法相比,部分模型的分割结果有明显差距。这都是未来需要继续研究的问题。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
汽车维修与保养(2020年11期)2020-06-09
科学与财富(2020年6期)2020-05-19
小学语文教学·会刊(2019年2期)2019-09-10
电子制作(2019年11期)2019-07-04
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
北京航空航天大学学报(2018年1期)2018-04-20
文教资料(2017年15期)2017-09-18
