
机器学习解构区域金融风险防控研究进展
2022-09-15 10:27张立华张顺顺
计算机与生活 2022年9期
张立华,张顺顺
1.温州商学院 金融贸易学院,浙江 温州 325000
2.伦敦大学国王学院 国王商学院,伦敦WC2B 4BG
在大数据、云计算、元宇宙、人工智能等新技术革命的推动下,机器学习(machine learning,ML)诞生了自然语言处理(natural language processing,NLP)、计算机视觉(computer vision)和机器人(robotics)技术发展的一座座里程碑。伴随着海量数据的挖掘过程,区域金融风险防控面临着数据稀疏性和复杂性的挑战。区域金融风险的量化和防控非常重要。当金融机构愈来愈强大和业务更加综合,准确量化和减轻风险的综合统计模型变得比过往任何时候更加复杂多变。当需要准确评估大金融机构的投资组合风险敞口,运用传统的统计或模拟方法将变得越来越无所适从。为克服传统方法的缺陷不足,研究者开始关注ML 方法在应对区域金融风险防控中的应用。
理论学术界相关的研究工作已经逐渐展开,不断研发的ML 防控区域金融风险研究方法主要表现为两方面:一是,从传统金融风险管控ML 视角看,2016 年Cavalcante 等人介绍了2009—2015 年的主要研究文献,综述了计算智能方法的金融市场动态预测,全文着重于金融数据的预处理和聚类、未来市场走势的预测、金融文本信息挖掘技术等。随后,De Spiegeleer 等人描述了传统高斯回归的加速多个数量级的机器学习技术,拟合了复杂的希腊值风险并总结了隐含波动率,减少了模型的普通期权价值测算、美式期权定价和超越Black-Scholes 模型奇异期权定价的计算次数。2020 年Mashrur 等人介绍了一个传统金融风险管理ML 分类法,详述了其过去十年中的重要出版文献,梳理了研究人员面临的主要困惑,指出了传统金融风险管理机器学习的未来研究方向。二是,从金融系统风险管控ML 视角看,Helbing强调了当今全球网络具有广泛且相互依存的系统,当网络世界的复杂性和交互作用增加时,这些系统可能对社会造成严重的破坏。之后,2019 年Kuo对现有的利用大数据分析、网络分析和情感分析等ML技术评估衡量金融系统风险的研究方法进行了综述,梳理了当前金融系统风险ML 的研究方法和未来工作方向。2020年Giudici等人描述了多元网络结构的关联网络模型(correlation network models,CNM),注重系统风险、间接风险敞口,将其关联于直接风险敞口,捕捉和度量金融网络中的系统风险。RFRP(regional financial risks prevention)防控模拟的优化路径如图1 所示,ML 模型求解过程是对传统统计计量方法的一种优化策略。
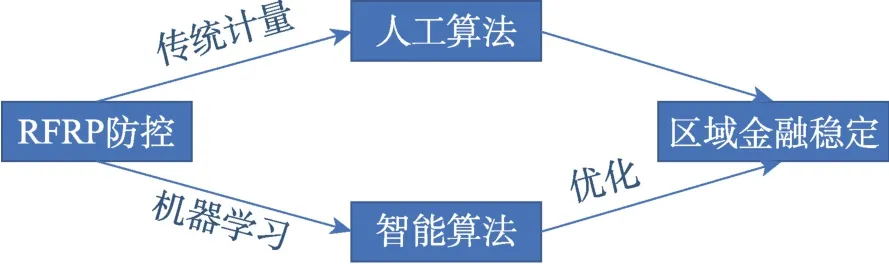
图1 RFRP 防控模拟的优化路径Fig.1 Optimal path to simulate RFRP prevention
综合来看,以往研究文献分别关注传统金融风险管理或者金融系统风险管控,然而,缺乏对区域金融风险管控的科学化分类法和区域金融风险管控框架中优化ML 方法。本文的研究扩展有以下几个方面:首先提出了区域金融风险防控的科学分类,在ML 的简要概述上描述了ML 的关联性,这有助于研究者在复杂多变的区域金融风险领域中确定正确的研究方向;其次综述了传统金融风险防控ML 的主要方法和技术,并基于不同的方法和技术,梳理了传统金融风险防控ML 的国内外研究进展,揭示了传统金融风险防控ML 应用的实践路径;再次梳理了区域金融系统风险防控ML 的主要模型和技术,着重于金融系统风险防控ML 的最新进展,以便驾驭ML 目前在区域金融系统风险防控领域中的研究方向和重点领域;最后对区域金融风险防控机器学习新兴方向和前景技术进行了展望,希望有助于国内外研究者和从业者,进一步研发出更适合的ML 方法与技术,有效应对区域金融风险。
1 区域金融风险防控和机器学习简要概述
区域金融风险无论在管理区域TFR 还是坚守不发生区域FSR 中都要进行识别、评测和预防,但以往文献对区域金融风险存在着模糊不全面的理解和应用,其中涉及“地区”和“区域”这对词语。查证调研了该对词语历史发展过程,发现“地区”与“区域”的内涵是基本一致的。本文认为区域金融风险一般呈现出五种表现形式:(1)跨国层面的金融风险;(2)国内层面的金融风险;(3)跨省层面的金融风险;(4)省内层面的金融风险;(5)跨市层面的金融风险。本文将区域金融风险分为区域传统金融风险和区域金融系统风险两大类型。这种金融风险分类视角不同于传统的风险划分方法,既有助于机器学习模拟区域传统金融风险,也有利于机器学习量化区域金融系统风险。
1.1 金融风险简单概述与分类
金融行业的繁荣发展伴随着承担、预防和化解金融风险。金融事件可能造成不利的金融市场波动、贷款违约、金融机构倒闭、欺诈活动、客户损失。根据金融风险因素的来源,本文拓展了2017年Silva等人研究脉络,在传统的金融信用风险、市场风险、操作风险、保险风险基础上,引入“系统风险(systemic risk)”。
(1)信用风险是指债权人履行贷款违约或破产合同义务能力的不确定性。信用风险主要呈现为零售贷方风险和企业贷方风险。
(2)市场风险是指高度流动性的金融市场风险敞口导致公司标的资产、债务或收入价值的不确定性。市场风险主要表现为利率风险、汇率风险、大宗商品价格风险等。
(3)操作风险是指金融业务操作的不可预测性致使亏损风险或错误欺诈行为造成绩效损失。操作风险一般可分为业务风险和事件风险。业务风险表现为经营业绩的不确定性,事件风险呈现出业务操作产生不利影响事件的不确定性。
(4)保险是一种保险人事先约定,承诺在一定时期内发生意外事故并造成损失的情况下,对被保险人进行赔偿或提供保险服务的金融系统,也是一种应对风险的方法。保险风险主要特征表现在保险损失或死亡事件中的不确定性。
(5)系统风险是指由金融机构崩溃等影响的广泛事件引发的金融系统严重衰退的概率,事件对金融市场以及整个经济带来负面冲击。
图2 汇总了不同来源的金融风险种类及范围,有助于及时运用各种区域金融风险防控策略测度和化解金融复杂体系的风险。这种新的分类视角有助于对区域金融风险开展重点研究和应对未来金融系统所面临的风险挑战。
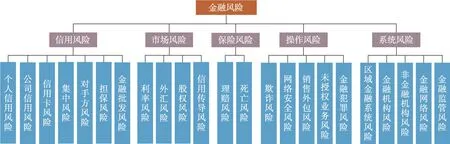
图2 金融风险分类Fig.2 Taxonomy of financial risks
1.2 机器学习简单概述
机器学习是一种利用以往数据或经验提高绩效或准确预测的计算机算法,其学习具有优化损失或回报函数的性能。基于学习方式的机器学习主要分类为:
(1)监督学习(supervised learning,SL)
SL 又称为有导师学习,是利用标签(labelled)的样本数据进行训练,其算法中训练模型可用于对未标签(unlabelled)的数据做出预测。监督学习主要包括回归和分类。图3 给出了SL 的流程框架。
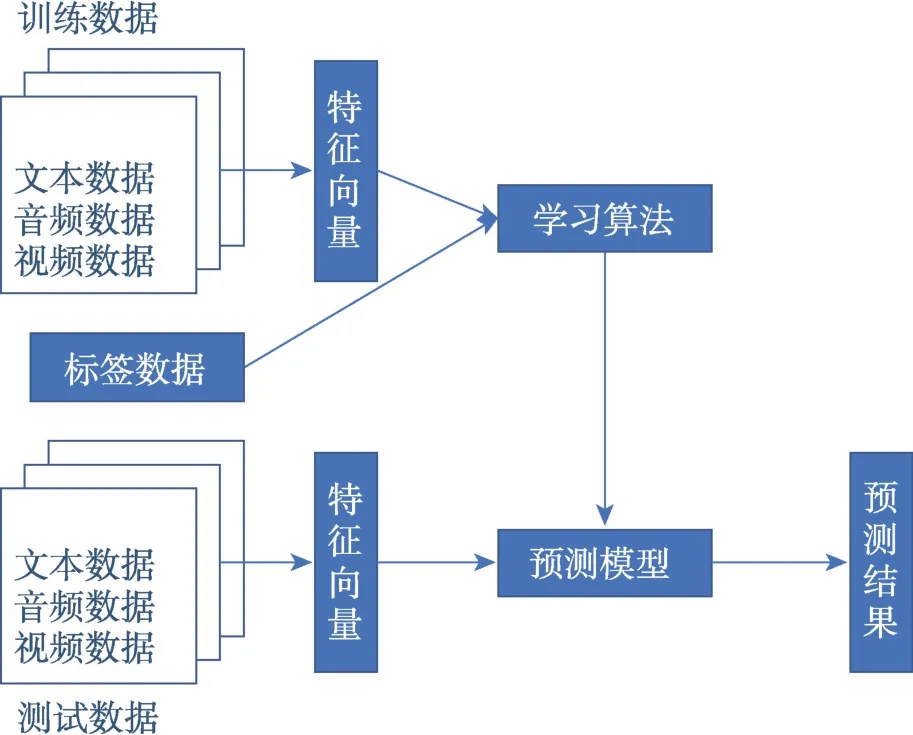
图3 监督学习的流程框架Fig.3 Progress framework of supervised learning
(2)无监督学习(unsupervised learning,UL)
UL也称为无导师学习,是指利用没有被标签的数据探测模式识别的机器学习任务。该算法中没有可用的标签数据。无监督学习算法旨在解决未标签数据的聚类(clustering)、异常检测(anomaly detection)、降维(dimensionality reduction)等特定问题。从图4 可以理解UL 的决策系统。
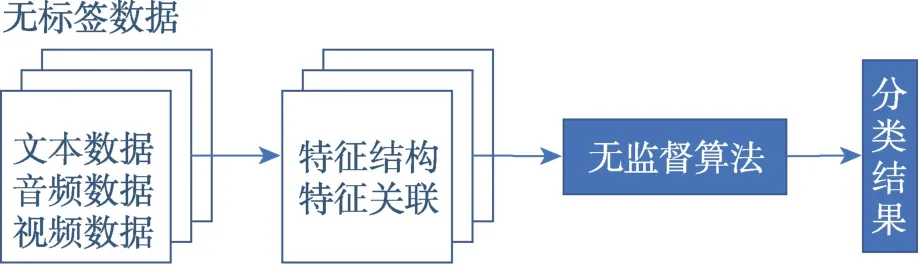
图4 无监督学习的流程框架Fig.4 Progress framework of unsupervised learning
(3)半监督学习(semi-supervised learning,SSL)
SSL在实际应用中很常见,其利用大量的未标签数据以及标签数据进行模式识别研究。SSL 的具体流程框架如图5 所示。从学习算法看,SSL 可以分类为生成模型(generative models)、自训练算法(selftraining)、协同训练算法(co-training)、半监督支持向量机(semi-supervised supported vector machines,S3VM)、图论算法(graph-based algorithms)。
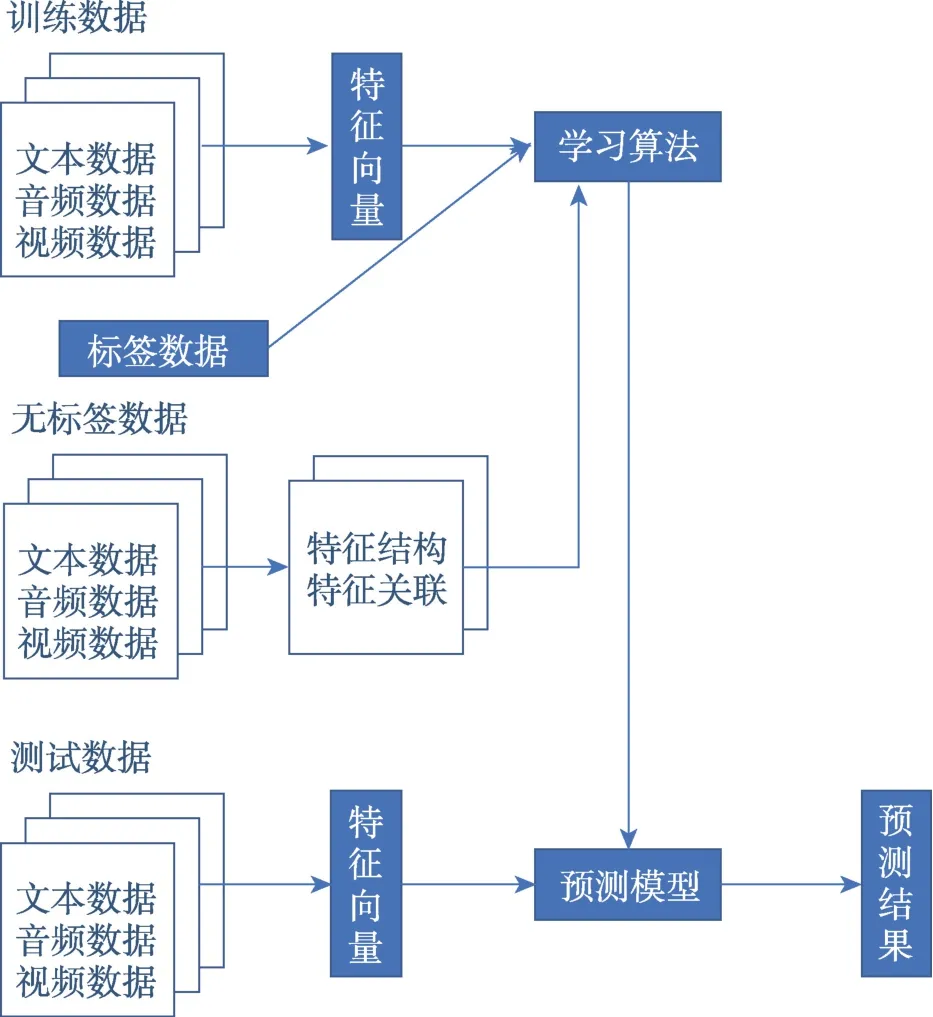
图5 半监督学习的流程框架Fig.5 Progress framework of semi-supervised learning
(4)强化学习(reinforcement learning,RL)
RL 是指不确定性下实现在环境交互过程中最大化回报或完成特定目标的序列决策。强化学习方法主要包括时序差分学习(temporal-difference learning,TD)、状态-动作-回报-状态-动作(state action reward state action,SARSA)算法、异步优势行动者评价者算法(asynchronous advantage actor-critic,A3C)、深度Q网络(deep Q-network,DQN)、深度确定性策略梯度(deep deterministic policy gradient,DDPG)等。图6表明智能体与环境的交互过程是一个试错策略,以最大化奖励累计值。
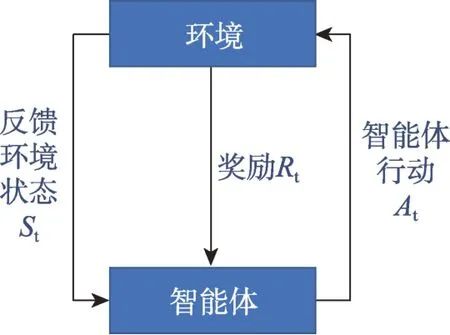
图6 强化学习的流程框架Fig.6 Progress framework of reinforcement learning
(5)深度学习(deep learning,DL)
深度学习是一种提取特征的多层表示的、拟合特征到标签的层级转换的非线性复合函数的机器学习形式。这种学习方法非常适合复杂非线性数据相互作用的识别模式。随后,深度学习方法发展了卷积神经网络(convolutional neural network,CNN)、循环神经网络(recurrent neural networks,RNN)、长短期记忆网络(long short-term memory,LSTM)。近年,出现了一种融合深度学习和强化学习用于金融市场动态环境中做出决策的深度强化学习。
例如代表性RNN 模型是将输入序列映射到输出序列的非线性动态系统。如图7 显示右侧是左侧递归表示的展开表示,其中递归关系表达式如下:

随时间反向传播算法(backpropagation through time)可以直接应用于图7 右侧展开网络的计算图,以计算所有状态s和所有参数的总偏差导数。
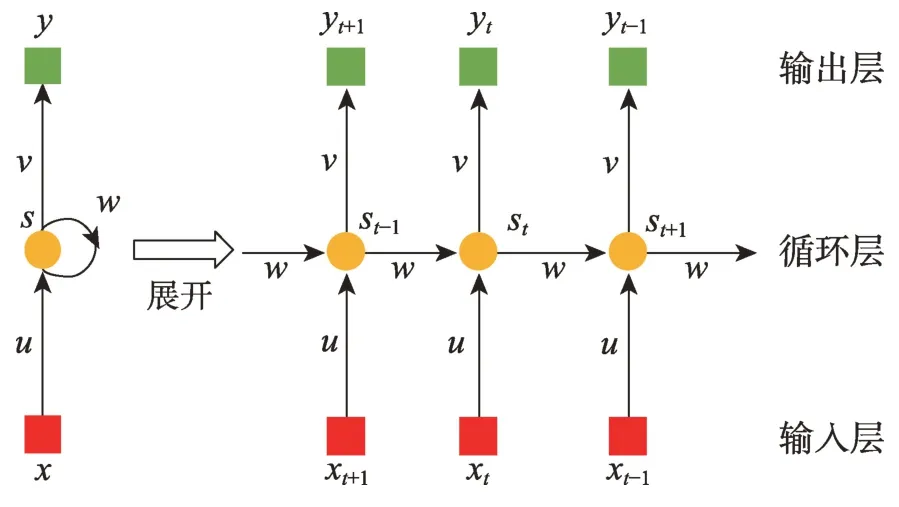
图7 循环神经网络框架Fig.7 Progress framework of RNN
目前流行的LSTM解决了RNN 无法处理长距离依赖的问题,改进了网络间的梯度流。
2 传统金融风险防控机器学习方法分析
20 世纪80 年代以来,随着区域经济一体化和金融国际化的发展,区域金融风险对区域金融稳定带来挑战。从1988 年起,巴塞尔银行业监管委员会(Basel Committee on Banking Supervision,BCBS)先后发布了巴塞尔协议I(Basel I)和巴塞尔协议Ⅱ(Basel II),Basel I、Basel Ⅱ都着重于银行不同资产的风险差异。借鉴Basel I、Basel Ⅱ对银行风险的划分,区域传统金融风险防控机器学习方法的系统性分类具体模型如图8 所示。本章分类框架综合分列了利用机器学习模拟区域传统金融风险中的信用风险、市场风险、操作风险、保险风险等方法与技术。
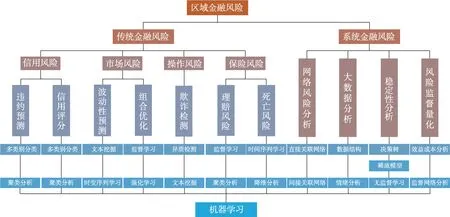
图8 区域金融风险防控机器学习方法分类框架Fig.8 Taxonomy framework of machine learning for regional financial risks prevention
鉴于以上综述的TFR 防控不同ML 方法,表1 分析了各类ML 方法的优点、局限和传统场景等。
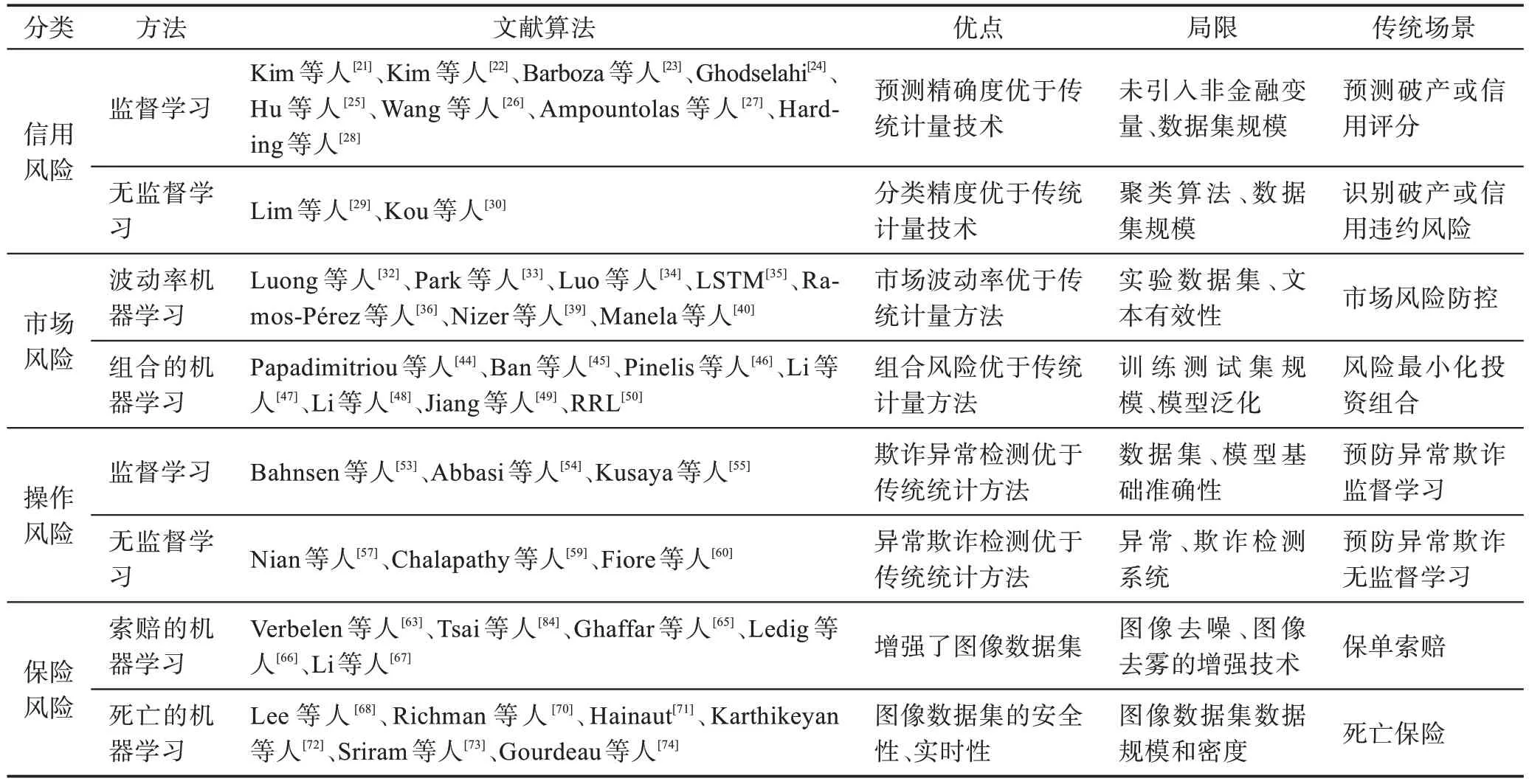
表1 TFR 防控的不同ML 方法比较Table 1 Comparison of ML methods for TFR prevention
2.1 信用风险模拟方法
信用风险(credit risk)定义为借款人履行义务的不确定性。这包括个人贷款违约或公司破产。信用风险防控着重于信用评分和破产预测。信用评分(credit scoring)系指个人贷款的风险敞口,而破产预测是指企业借款的风险度量。从统计建模来看,破产预测和信用评分用于建模的解释变量不尽相同。前者的解释变量关注于公司资产负债表或损益表等的主要财务比率;而零售信用评分模型(retail credit scoring)的预测变量使用贷款申请人的财务和人口统计信息。
近20 年以来,机器学习预测个人或企业违约的文献不断增长。其中用于信用风险评估分为两类:
(1)监督学习预测信用风险
两个最常用的预测破产或信用评分的分类器(classifiers)是支持向量机(support vector machines,SVM)和神经网络(neural network,NN)。Kim 等人描述了一种多类SVM。新的选择特征方法改进了这些模型的有效性。与此同时,集成学习(ensemble learning)和混合模型(hybrid models)也被广泛应用。
Ghodselahi和Hu等人对自助聚合(Bagging)、提升法(Boosting)、堆叠法(stacking)等集成学习方法进行了综述。Wang 等人描述的支持向量机提高了集成模型的预测性能。随后,Ampountolas 等人和Harding 等人指出随机森林算法(random forest)优于其他单一或混合分类器模型。
(2)无监督学习模拟信用风险
聚类方法(clustering methods)适用于识别破产或信用违约风险,这些方法有助于识别申请组合贷款的个人或企业。Lim 等人分析了聚类动态评分模型(cluster-based dynamic scoring model),并指出可以通过聚类的不同分类器获取更高的评分精度。Kou等人综述比较了研究文献的不同聚类方法。
Kim等人提出了一种解决信用评级的多类SVM新方法。之后文献[22]通过决策树和AdaBoosed 决策树解决财务预警问题。文献[23-28]通过引入自助聚合、提升法、堆叠法、支持向量机、随机森林或通过神经网络、分类与回归、梯度提升法,或引入自助聚合支持向量机、自助聚合随机森林等集成算法,进行特征选择,改进了信用风险建模,提升了风险预测准确率问题。与此同时,文献[29-30]通过数据分割或聚类选择,提出了无监督学习的行为评分或验证了多准则决策的有效性。针对信用风险ML 算法选择特征、性能绩效、数据规模等问题,表2 分析了信用风险预测模型方法的局限性。

表2 信用风险预测方法的局限性Table 2 Limitation of credit risk model
2.2 市场风险模拟方法
正如Shiller所言,市场风险的主要测度是运用资产收益标准差衡量资产波动率。为了使市场风险最小化同时收益最大化,机器学习可采用动态资产配置系统。最优投资组合的机器学习模型主要有两大类型:机器学习预测波动率和机器学习优化投资组合。
波动率(volatility)被定义为未来金融市场资产价格的不确定性。较高波动率呈现出较高市场风险。市场风险防控的波动率机器学习的典型方法有:
(1)传统统计方法改进
20 多年以来,Luong 等人证明了混合机器学习(hybrid machine learning)技术可以改进传统GARCH模型和随机方法的性能。人工神经网络(artificial neural networks,ANN)可与GARCH 模型和随机波动率模型融合,做出更准确的波动率预测。利用GARCH模型输出作为多层感知机(multi-layer perceptron)模型的输入,不仅可使模型预测更加准确,而且对于不同的窗口大小(window sizes)、堆叠模型(stacked model)呈现出更好的稳健性和一致性。与此同时,Park 等人研究发现了机器学习模型,特别是支持向量回归(support vector regression)、高斯过程回归(Gaussian process regression)和神经网络模型可完全取代传统的参数模型。Luo 等人分析了循环神经网络与随机波动率模型(stochastic volatility models)相融合可以显著提升模型的预测能力。
(2)神经网络序列方法
Hochreiter 等人指出了长短期记忆网络模型是序列分析的循环神经网络流行变体,长短期记忆网络模型被应用于预测波动率。最近,Ramos-Pérez 等人基于随机森林、支持向量、人工神经网络建立了混合人工神经网络,其呈现的预测绩效可靠性更高。
(3)市场文本数据方法
传统方法没有将金融、经济、流行病新闻等非结构化(unstructured)文本数据(textual data)用于预测波动率。Groth 等人总结了股票交易量和价格等结构化数据不仅用于机器学习预测投资组合波动率,而且文本数据也可作为市场波动率的重要解释变量(predictors)。从历史上看,金融市场文本数据有着不同的来源:一方面,来自资产波动舆论的公开讨论区(public discussion boards)。Antweiler 等人早先讨论了朴素贝叶斯(naive Bayes)算法根据公开讨论区留言准确预测交易量和波动率。之后,Nizer等人研究了公司新闻可作为标的资产波动率短期预测的关键解释变量指标。随后,Manela 等人分析了支持向量回归可将新闻隐含波动率以及市场崩盘等引发的不确定性作为有效解释变量预测收益的波动率。另一方面,Oliveira 等人指出了有部分文本挖掘(text-mining)预测需要使用Twitter 微博等社交媒体上的数据。此后,Xu 等人分析了“谷歌趋势”(Google trends)可作为股票市场预测波动率的有效指标。近来,自然语言处理(NLP)技术不断用于提高金融预测性能。Xu 等人指出新闻文章、微博等非结构化文本数据可包含金融决策的重要信息。
投资组合优化(portfolio optimization)是指一组特定金融合约权重的预期收益最大化或金融风险最小化资产配置过程。许多机器学习方法技术有助于构建波动率最小的投资组合。
(1)监督学习优化投资组合
Papadimitriou等人描述了支持向量预测S&P500股指极端变动的非线性关系。Ban 等人使用了新正则化(regularization)或交叉验证(cross-validation)技术,进一步提升了监督学习模型的性能。Pinelis 等人发现了随机森林模型优于传统的投资组合选择模型。
(2)在线学习优化投资组合
Li 等人分析了金融市场均值回复(mean reversion)假设下找到最优投资组合权重的在线投资组合选择策略(online portfolio selection strategy)。随后,Li 等人对使用投资组合选择的不同在线学习方法进行了文献综述。
(3)强化学习优化投资组合
Jiang 等人总结了强化学习方法可运用卷积神经网络(CNN)、循环神经网络(RNN)和长短期记忆网络(LSTM)达到策略优化。同时,Almahdi 等人分析了循环强化学习方法(recurrent reinforcement learning,RRL),在产生市场买卖信号的同时,并基于下行风险调整目标函数(downside risk-adjusted objective function)获得最优资产配置权重。
Luong等人提出了一种基于随机森林与GARCH模型随机融合的解决波动率预测的新方法。针对GARCH 方法中参数建模的路径依赖问题,文献[33-34]基于支持向量机、深度循环神经网络,分别提升了传统计量模型的预测性能,实现了基于实际场景优化预测。文献[35-36]针对金融时间序列问题,阐述了基于长短期记忆网络或混合人工神经网络的波动率预测方法。文献[39-40]从新闻文本数据测度了市场的隐含波动率,提高了市场风险的预测效应。表3给出了针对波动率预测的文献模型的局限性。

表3 预测波动率方法的局限性Table 3 Limitation of volatility prediction models
Papadimitriou 等人提出了一种基于支持向量机预测指数组合收益与风险的非线性新方法。文献[45-46]通过绩效正则化与交叉验证技术、随机森林与弹性网络等监督学习技术,预测了资产组合的收益和波动风险问题;文献[47-48]基于被动均值回归,设计了最小损失函数的新权重,优化在线学习投资组合;文献[49-50]提出的深度强化学习、循环强化学习框架,优化了传统机器学习方法,获得资产组合的优化配置。针对投资组合优化的文献算法,表4 解释了相关投资组合预测文献模型的局限性。
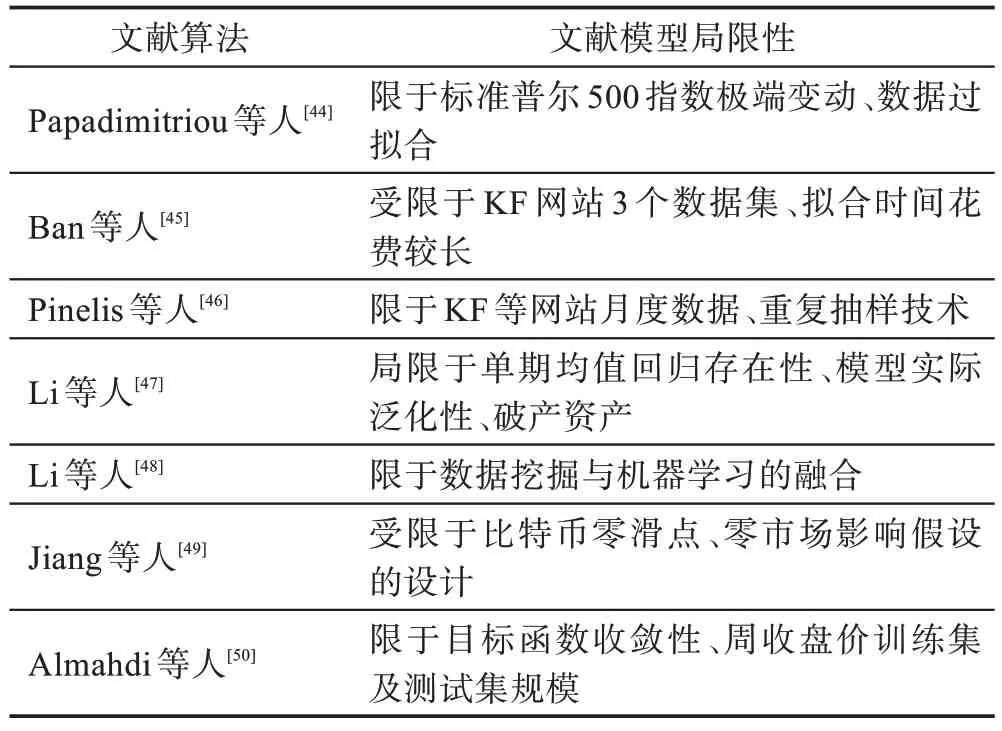
表4 优化投资组合的局限性Table 4 Limitation of portfolio optimization
2.3 操作风险模拟方法
金融欺诈活动是金融机构操作风险的主要来源之一。Ngai等人描述了金融欺诈检测系统的机器学习算法,区分了欺诈性金融数据与大数据。金融欺诈活动包括欺诈性信用卡交易和洗钱、欺诈性保险索赔、证券和大宗商品欺诈。这类操作风险防控机器学习算法可以分为监督学习方法和无监督学习方法:
(1)监督学习方法
Sahin等人总结了逻辑回归(logistic regression)、神经网络、K-最近邻(K-nearest neighbor)、决策树(decision trees)和支持向量机等二元分类器被用于欺诈检测的研究文献。Bahnsen 等人描述了特征工程方法(feature engineering methods)可以有效提高欺诈检测模型的预测性能。Abbasi 等人指出元学习(meta-learning)算法可检测欺诈。Kusaya 等人分析了人工神经网络等ML 方法也用于检测欺诈行为。当前,基于文本挖掘(text-mining)算法也被用于检测欺诈研究。
(2)无监督学习方法
Nian 等人综述了基于异常检测处理欺诈检测。Papernot 等人提出了异常检测的理论框架。2019 年Chalapathy 等人发现了深度学习模型也可用于异常检测。近年来,生成式对抗网络(generative adversarial networks,GAN)已被用于模拟和检测欺诈活动。
监督机器学习和无监督机器学习方法可以用于自然语言处理模型训练和调优。自然语言处理技术被广泛用于挖掘与欺诈检测的相关文本。近年,Purda等人基于决策树方法,在排序单词上应用支持向量机等分类器,有效提高了识别欺诈报告的准确度。Hajek 等人综述了自然语言处理模型从财务报表中检测欺诈行为。
Bahnsen 等人基于ML 和数据挖掘技术构建了一种信用卡欺诈检测的新方法。通过实际金融成本,提取交易数据的真实特征。文献[54-55,57,59-60]通过引入ML 的元学习,自适应学习、堆栈泛化,卷积神经网络、循环神经网络、长短期记忆,生成对抗网络实现了异常检测处理信用卡等金融欺诈问题。针对操作风险ML 算法提取特征、性能绩效、数据规模等问题,表5 列出了操作风险预测模型方法的局限性。
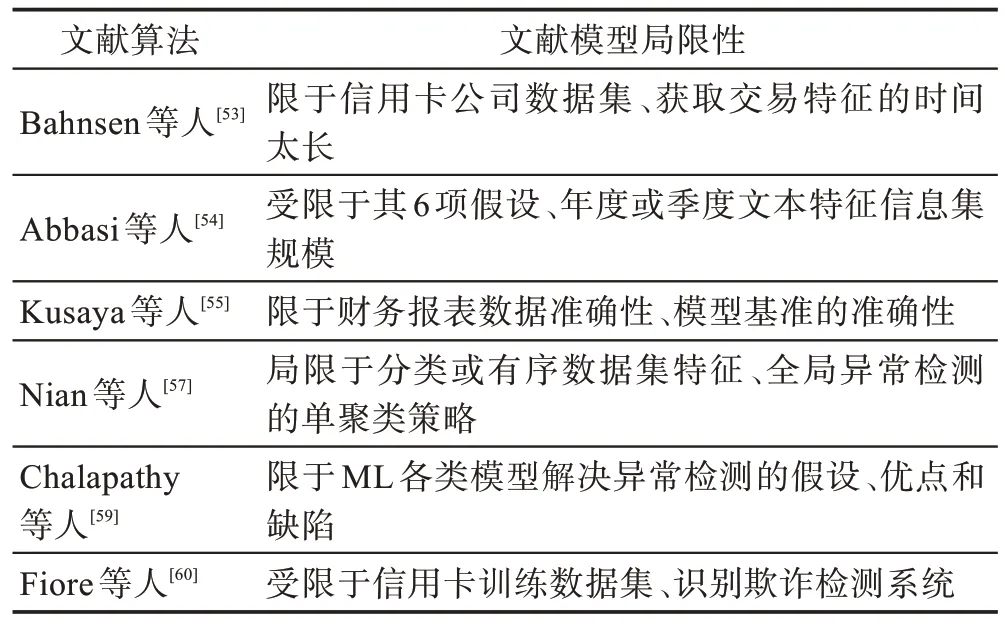
表5 操作风险预测方法的局限性Table 5 Limitation of operational risk prediction models
2.4 保险风险模拟方法
保险公司为社会提供保险服务的同时,也承担或引发金融保险的不确定性。保险风险可能呈现多种来源,每种风险都需要准确地预测。保险公司预测失误将导致保险产品定价过低,引发公司未来金融风险;人寿保险公司需要准确估计人口预期寿命。保险风险主要包括索赔风险、死亡风险等。
索赔风险(claims risk)是指与投保人(policyholders)保险索赔有关的所有未来的不确定性。索赔频率(claim frequency)和索赔额度(claim severity)是确定未来不确定性的重要指标。索赔建模的传统统计模型主要是广义线性模型(generalised linear models,GLM)。但GLM 模型的缺点是假设索赔频率和索赔额度独立,并不符合实际。集成模型(ensemble models)预测索赔频率和索赔额度的绩效优于GLM 模型。同时,神经网络可以高质量预测凭保单索赔(policylevel claim)的准确率。索赔风险建模的车载信息系统(Telematics)为保险业务提供了重要的动态数据库。当获得汽车传感器数据(Telematics data),可以捕捉到汽车司机的行为特征。这种车载信息数据库改进了索赔预测的准确性。
远程医疗系统(telemedicine)逐渐应用于保险领域。保险智能服务需要数据作为支撑。有效地获取高质量的数据资源成为不可或缺的重要工作。Tsai等人首次提出了一种图像超分辨率重建(image superresolution reconstruction,ISRR)算法,基于傅里叶变换(Fourier transform)的多幅图像恢复增强高频信息的超分辨率重建算法。该模型假设图像中不存在动态模糊(motion blur)和观测噪声(observation noise),忽略了光学系统的点扩散分布,仅适用于理想的图像退化模型。
针对保险理赔风险面临的数据缺失、数据稀疏、数据重建和数据安全等问题,需要增加ML 中训练样本的数量,减少模型过拟合。当前图像超分辨率重建(ISRR)算法的相关研究已经逐渐展开,如Ghaffar等人提出了一种提高卫星图像超分辨率的数据增强技术(data augmentation technique,DAT)。超分辨率卷积神经网络(super-resolution convolutional neural network,SRCNN)作为最先进的深度学习模型测试DAT。模型中超分辨率输出的重建质量使用峰值信噪比(peak signal to noise ratio,PSNR)进行定量评估,同时运用超分辨率前后测试样本的可视化进行定性评估。构建深度学习算法的卫星图像训练数据集可能会影响分类或回归的性能和速度。通常构建深度学习匹配规模的数据集很困难。实证发现数据增强缓解了数据稀缺问题,也减少了模型等的过度拟合。实验结果表明SRCNN 模型有效融合了增强方法与实际标准方法。
Ledig 等人提出了生成对抗网络的单幅图像超分辨率算法(super-resolution using a generative adversarial network,SRGAN),SRGAN 是第一个对放大四倍自然图像超分辨率的框架。模型提出了由对抗损失(adversarial loss,AL)和内容损失(content loss,CL)组成的感知损失函数(perceptual loss function)。模型通过训练比下采样(down-sampling)层更多上采样(up-sampling)层的编码器-解码器网络(encoderdecoder network),基于下采样中恢复图像详细特征,AL 使得判别器(discriminator)生成的图像更加接近自然图像。CL 促使图像的感知相似,不是像素空间相似。深度残差网络从深度下采样恢复图像逼真性。平均意见得分(mean opinion score,MOS)测试结果表明SRGAN 获得的图像MOS 值比其他方法获得图像MOS 值更加接近原始的高分辨率图像。目前SRGAN 已被应用于从低分辨率图像生成高分辨率图像的医学、保险领域。
2021 年Li 等人运用神经网络改进了ISRR 处理低分辨率图像的问题,提出了基于自注意力机制图像超分辨率重建(self-attention-based image reconstruction)方法,利用残差网络(residual network)结构和子像素卷积(sub-pixel convolution),提取图像中的详细信息;运用生成对抗(generative confrontation)和图像特征感知机(image feature perception),提高了图像重建质量,保障数据的安全传输。目前,图像超分辨率重建算法应用于金融保险的研究文献并不多见。
死亡风险(mortality risk)是金融机构提供与受益人长寿相关的人寿保险产品的未来不确定性。死亡率(mortality rate)是人寿保险的量化指标,对人寿保险产品进行估值。通常表示为特定人群组中每1 000人的预期死亡人数。以往死亡风险建模研究主要分为两方面:一是广泛应用的年度死亡率演化的离散时间模型(Lee-Carter模型等);二是刻画了瞬时死亡的连续时间随机模型。近年来,多种ML 技术已经用于死亡率建模。神经网络已被广泛用于增强预测多人口死亡率(multi-population mortality)预测的方法。比如神经网络扩展了Lee-Carter模型预测多人口死亡率同时,也可以用于多人口死亡率预测的降维分析。
目前X 光图像检测技术(X-ray image detection,XRID)是保险、医学、质量检测、安全检查等行业中最重要的诊断方法之一。主要提供形态信息,也可获取一些功能信息。X 光可以穿透普通可见光无法穿透的物质,X 光波长越短、密度越低或厚度越薄,其穿透率越高。X 光可以实现其他检测方法无法比拟的独特检测效果。就X 光的实时成像来说,通过探测器将检测数据传输至电脑显示端,经过软件同步处理,呈现出实时成像检测结果,具有操作简单、实时保存、追溯性强的特点。
冠状病毒病(COVID-19)是一种被世界卫生组织(WHO)命名为大流行病的急性呼吸道疾病,医疗卫生系统面临着感染人数突然激增和高死亡率的巨大压力。Karthikeyan 等人运用X 光图像、CT 扫描和超声波等死亡率检测技术,提出了基于检测数据的ML 方法,预测COVID-19 死亡风险,以96%准确率预测了死亡率。在整个疾病期间,对神经网络、逻辑回归、XGBoost、随机森林、SVM 和决策树等ML 模型进行了训练和性能比较。发现使用XGBoost 的重要特征提取和神经网络方法,提前16 天以90%的准确率做出了预测,有助于提高医疗保险系统的决策过程。
X 光图像检测技术等临床数据的ML已被用于预测COVID-19 患者的病情恶化导致死亡风险。Sriram等人指出COVID-19 患者数据的稀缺性,目前受到预训练数据(pretraining data)和目标COVID-19 患者数据之间差异的限制,需要补充对非COVID-19 图像的监督预训练,在预训练中使用动量对比(momentum contrast,MoCo)的自监督学习,学习更通用的图像表征(image representations)用于下步任务。提出了一种新的多图像序列预测的转换器架构(transformer-based architecture)模型,结果表明模型实现了0.848AUC 预测96 h 的死亡率。
Gourdeau 等人阐述了胸部X 光图像检测(chest X-ray detection,CXRD)结果,表明亟需从当前CXRD开展未来COVID-19 患者的病情评估(severity evaluation)。基于CheXnet 开放数据集(65 240 名患者的224 316 幅胸部X 光图像)训练了一种重新调整的深度学习算法,提取映射到放射标签的数据特征。从开源数据集(COVID-19 图像数据集)和多机构ICU数据集中收集了COVID-19 阳性患者的CXR,从图像和报告中将数据分组为成对的CXR“更差”“稳定”或“改进”三类。训练了深度学习提取的特征,实时病情评估和未来放射轨迹的预测,进行了观测者操作特性曲线(receiver operating characteristic curve,ROC)分析和曼-惠特尼检验(Mann-Whitney tests)。COVID-19 在本地图像数据收集上训练的病情评估具有良好的分布外泛化性。CXRD 深度学习表明了病情评估和轨迹进行分类的应用前景。当纳入临床数据和更大样本量的研究得到验证,可以为分诊决策(triage decisions)、保险风险预测提供有效信息。
2018 年综合汽车图像、司机行为特征的动态数据库车载信息数据库开始用于改进保险索赔风险预测的精确性。之前,Tsai 等人提出了一种完善保险索赔风险数据的图像超分辨率重建(ISRR)问题的雏形,其模型通过傅里叶变换的多幅图像恢复增强高频数据信息。文献[65-67]提出了改进ISRR 的数据增强新技术,引入卷积神经网络、生成对抗网络、自注意力机制,利用残差网络结构和子像素卷积提取图像的特征信息,将图像从低分辨率转为高分辨率,补充了图像数据库及数据稀缺问题,提高了数据的传输效率,减少了传输数据加密和密钥交换的成本,成为保障数据安全的重要环节。超分辨率医学图像(super-resolution medical images)可以帮助更准确地判断疾病,提高索赔的准确度,化解和减少索赔风险。为保险理赔风险预测做好了数据增强的准备基础。针对保险索赔风险ML 算法提取图像特征中的图像处理的问题、数据传输的安全等问题,表6 解析了基于索赔风险预测模型方法的局限性。

表6 索赔风险预测方法的局限性Table 6 Limitation of claims risk prediction models
Lee 等人早前提出了一种预测死亡风险的离散时间模型。之后,文献[69-71]相继提出了死亡风险预测的连续时间随机模型、多人口死亡风险模型、降维死亡风险模型等。随着ML 算法的发展,使用X 光图像检测技术成为一种预测保险死亡风险的新方法。2021—2022 年间,文献[72-74]运用X 光图像检测了COVID-19 的患者病情,通过神经网络、逻辑回归、XGBoost、SVM 和决策树等ML 方法进行训练,补充非COVID-19 图像的监督预训练,提取自监督和图像表征。针对数据集没有包括临床数据和样本数量的限制,其泛化能力不足。表7 给出了基于死亡风险预测模型方法的局限性。
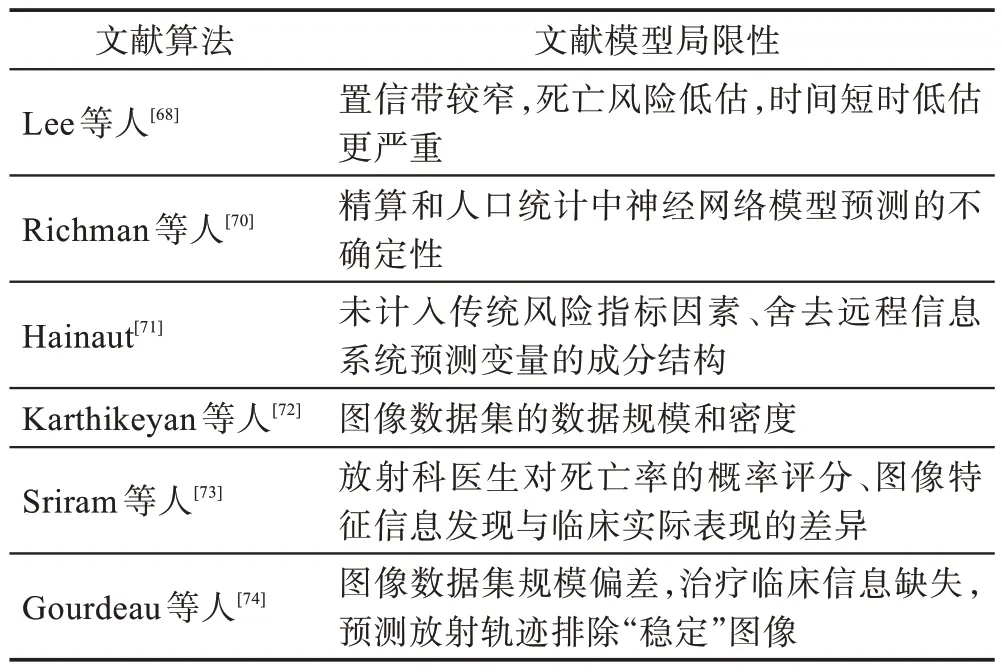
表7 死亡风险预测方法的局限性Table 7 Limitation of mortality risk prediction models
3 区域金融系统风险防控机器学习分析
2008 年国际金融危机后,从始于2010 年巴塞尔协议Ⅲ,到2017 年最终方案的确认,既强调资产风险,又匹配资产负债期限,着重防范和化解银行系统风险,统一规划微观审慎管理与宏观审慎监管。当今,金融系统风险(systemic financial risk)主要研究策略是识别风险并监管风险。过往文献对金融系统风险着重于风险损失演化、“大而不倒”金融机构的识别,以及对金融、经济的影响冲击研究。本章将从金融机构网络、大数据、金融稳定性和监管量化视角展开对区域金融系统风险防控的机器学习研究。
3.1 金融机构网络的风险分析
基于网络的金融系统风险(network-based financial systemic risk)被定义为从宏观视角研究网络系统对金融系统的风险传导。2008 年美国金融危机和2010年爆发的欧债危机以来,金融机构网络系统风险已经成为研究者持续关注的热门课题。金融机构相互连接形成的复杂网络存在着风险传导的或然性。一方面,银行系统流动性要求银行间的直接关联;另一方面,产品同质化和风险规避致使银行间有着广泛的间接联系。正如Battiston 等人所言,经济和金融政策需要应用网络分析(network analysis)、行为建模(behavioural modelling)和复杂系统(complex systems)理论的融合。Haldane 等人分析了金融体系的衍生工具交易是金融网络风险的主要来源。同时,Prasanna 等人和Hu 等人发现了金融网络系统和风险传染致使金融网络的风险扩大。之后,Diebold 等人利用加权有向图(weighted directed graph)的连通性(connectedness),研究了美国2007—2008 年金融危机期间主要金融机构的日度股票收益的波动率。Acemoglu 等人总结了复杂金融网络的转折点和稳定性将决定金融政策的发展方向。
(1)金融网络的风险敞口与传导
金融网络被定义为一个模拟银行违约过程的风险敞口矩阵。Amini 等人通过异质性有向图(inhomogeneous directed graphs)研究了金融网络的级联过程(cascade process)和渐近传染(asymptotic contagions),提出了监管政策应对风险传染敞口设定为最小资本比率。Bluhm 等人基于互联银行资产负债表,研发了一个系统风险的网络模型,并提出了宏观审慎系统在险价值(value at-risk)方法。Choi发现了较大金融机构对金融网络有更大的积极作用,因此,做强做大金融机构将有助于保障银行体系的稳定性。Giudici 等人通过多元图模型(multivariate graphical models)和贝叶斯图模型(Bayesian graphical models)实证了不同国家作为金融网络中心节点具有不同的行为特征。Yu等人提出了一种新的复杂网络方法,模拟银行间网络的系统风险传染,发现金融机构具有充足资本储备金可用于预防风险传染。同时,Betz等人阐述了一个不同时期系统风险的评测框架。该框架揭示了银行业分化(fragmentation)与主权银行间的联动过程。Shen提出了一种模拟电子物流投资金融风险的贝叶斯网络方法(Bayesian networks approach)。
(2)金融机构网络的结构
多层银行网络(multilayer bank networks)是相同资产相同风险的金融系统的重要特征。Battiston 等人发现多层网络致使抵御金融风险的能力不断下降,并使金融危机成本不断增加。Poledna 等人描述了信用、衍生工具、外汇和证券关联的金融多层网络,且单层网络预期损失被低估了90%。同时,分析了金融多层网络系统风险总和低于总风险的非线性特征。Grassia 等人提出了一种检测复杂网络系统崩溃预警信号的量化系统风险方法,机器学习更好地量化复杂系统的脆弱性及其冲击反应。
当前,随机图论、博弈论、收益成本分析等一系列数学模型和复杂网络方法被引入银行系统风险的研究。流行病模型和随机最优模型等也被应用于金融网络研究。区域金融网络的系统风险研究还并不多见。显然,未来网络会变得更广泛并产生大量数据,网络金融系统风险应从大数据视角展开分析。
Amini 等人提出了一种基于度序列和任意权重分布下异质性、加权、有向随机图风险传染的新框架。文献[84-85]引入多元高斯图、动态贝叶斯、级联违约、复杂网络传染等多元网络方法,识别和预警金融复杂网络的系统风险敞口;文献[88-90]通过复杂性、违约概率、违约可回收率分析了多层网络成本持续增加,图卷积神经网络和多层次感知机的引入,更好地拆解了网络复杂系统,量化了复杂网络系统绩效。表8分析了针对金融机构网络风险ML 的局限性。
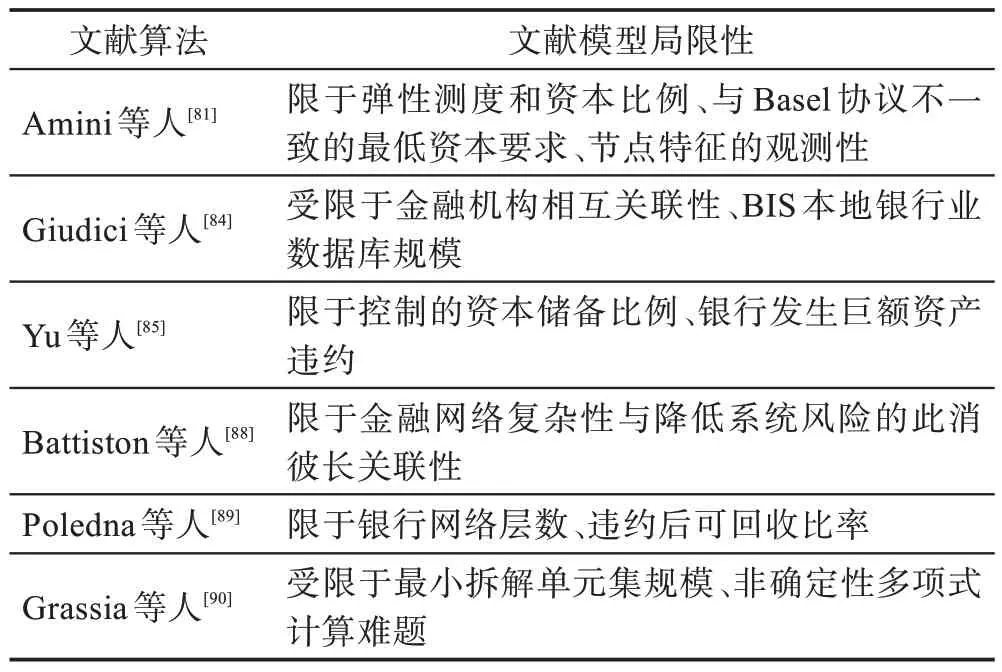
表8 网络风险预测方法的局限性Table 8 Limitation of network risk prediction models
3.2 系统风险防控的大数据分析
如今,大数据不仅借助数据挖掘技术和商业智能进行了理论研究,而且在金融系统风险分析、供应链金融风险等管理中开展了广泛的实证应用。金融系统风险防控的大数据分析主要从算法和数据两方面展开。
(1)系统风险大数据分析
从金融系统风险来说,大数据分析是基于金融大数据研究风险源与分散风险的相互关系。金融大数据包括银行同业资金流动、全球资本流动等金融信息,被用于风险预警和风险识别以应对金融风险。近十年来,涌现了大数据算法、网络合约与金融市场相关性、金融信用风险评估、股市波动分析以及股价与舆情关联性等模型。Cerchiello 等人建立了第一个基于两个异质性数据源的大数据系统风险模型,实证了联合运用贝叶斯方法的不同数据结构,并评测了金融风险与公众舆情的相关性。Sarlin引入了模拟系统风险的机器学习、网络分析、仿真和模糊系统(simulation and fuzzy systems)等智能算法。Sarlin提出了一种具有绘图、地图和网络三个模块的金融监管可视化工具。Cerchiello 等人研究了基于金融推文和金融市场的风险传染模型,当发生冲击时可预测金融风险的相关性。
(2)系统风险的数据问题
金融系统是大数据的主要来源。金融系统风险分析依托于高质量的数据。目前,区域和全球金融市场数据的不可利用性或质量问题使得系统风险的研究文献并不多见。如何保证大数据的有效性问题研究是一个亟待解决的话题。Cerchiello 等人提出的多源异构数据集成(multi-source heterogeneous data integration)应视为大数据。Flood 等人分析了金融风险总是与时间和时变数据相关,难以确保数据资源的有效金融风险分析。加之,金融机构的复杂性,数据集成和质量也是一个不容易解决的问题。Jagadish 等人总结了大数据分析应包括数据收集、建模分析、数据解读和应用等步骤。然而,大数据的异质性(heterogeneity)、时效性(timeliness)、不一致性(inconsistency)和不完整性(incompleteness)等也成为金融市场应用中的障碍。同时,Yang等人提出了一个改进存储数据的框架和分类标准。Brammertz等人提出了从金融合约信息粒度(information granularity)中提取金融大数据的监管信息,并研发了针对机构、系统和个人等多层次金融目标的混合模型。为了给大数据分析奠定坚实的基础,需要进一步完善数据质量的评价指标体系(evaluation index system)。
(3)金融市场的情绪分析
推文、新闻、法律等互联网数据一直视为研究金融风险的文本数据。当前,研究学者从舆情视角分析了金融系统风险。首先,Nyman 等人发现金融系统风险可通过基于文本集(text set)的市场情绪来衡量。Chiang 等人从金融新闻网站收集并构建了一个金融文本数据库,提取常用词集并测算了情绪指数(sentiment index),发现了情绪指数可用于预测电子行业的股票指数。Tsai 等人利用金融银行报告的文本信息预测金融风险,实证了软信息(soft information)与金融风险具有强相关性,发现了金融风险与市场情绪间存在强相关性。Meyer 等人运用粒度情感分析(granularity sentiment analysis)研究金融新闻,揭示了定价和风险预测模型,通过自然语言处理提取相应句法句型和预测情绪。情感分析(sentiment analysis)和舆情挖掘(opinion mining)旨在利用文本挖掘发现客户和市场的态度、舆情和趋势。目前,机器学习情绪分析方法主要有回归与排序方法(regression and ranking methods)、词典与机器学习情感分析(lexicon and machine learning sentiment analysis)、规则排放模型算法(rule-based emission model algorithm)、正面词汇与负面词汇比例(fractions of positive and negative words)等。
文献[92-94]主要引入机器学习、图模型、贝叶斯方法,以及金融稳定分布图、银行关联图可视化,识别和预测金融推文、金融市场的关联风险、风险沟通等系统风险的重要特征。从系统风险数据视角看,文献[91,95-96]分析了多源异构数据、大数据规范、数据提取和清洗、数据整合和加总,强化了数据信息丰富的金融风险管理系统基础。从金融市场情绪视角看,文献[99-100,102]通过文本集、新闻机构和网站,运用KNN 算法、支持向量机、朴素贝叶斯,结合半监督学习和监督学习,抑或使用自然语言处理提取句法句型特征,更准确预测金融新闻情绪,识别和预防金融系统风险。表9 分析了针对大数据风险预测ML的局限性。

表9 大数据风险预测方法的局限性Table 9 Limitation of big data risk prediction models
3.3 系统风险防控的金融稳定性分析
现代金融创新要求构建一个稳定的金融体系,以便更好地既规避金融风险又保证流动性。全球金融危机后,第二代预警模型(early warning models)随着技术的发展开始应用于金融稳定测度。如今,决策树(decision trees)、稀疏模型(sparse models)和无监督学习(unsupervised learning)成为用于金融稳定的主要机器学习技术。
首先,决策树模型是研究金融稳定的重要预警模型。Duttagupta 等人基于二元分类树(binary classification tree)方法,分析了50 个新兴市场和发达经济体的银行危机,决策者只需监控特定变量是否超过目标国家的预警门槛值。Manasse 等人测度了可能导致新兴市场银行危机的脆弱性,通过交叉验证聚合(cross-validation aggregating,CRAGGING)方法测试了540 个备选预测变量,识别出两个银行危机的“危险区域”。2019 年Gabriele基于15 个欧盟国家的样本,使用CRAGGING 算法识别了银行系统危机的脆弱性,发现了信贷总量高和市场风险低的认知是关键因素。Tanaka 等人根据银行财务报表的预测变量,通过随机森林模型评测了银行业的脆弱性。Ward基于17 个国家的长期样本,运用自助聚合(Bagging)和随机森林算法衡量了银行危机的风险,决策树集成学习(tree ensembles)算法的预测性能好于传统Logit模型。2019 年Casabianca 等人基于100 个发达和新兴经济体的数据,使用自适应提升算法(AdaBoost)识别了银行系统危机的累积,发现了机器学习算法比Logit 模型具有更好的预测性能。2021 年Bluwstein 等人实证了机器学习在样本外优于逻辑回归的预测,根据每个观测的危机概率分解为预测变量的贡献总和,对机器学习模型进行了预测。其次,决策树集成学习方法也被用于主权危机的早期预警模型。2019 年Arakelian 等人根据宏观经济基本面、门槛值等预测变量,运用递归分区(recursive partitioning)方法衡量了区域欧洲主权风险。最后,决策树模型还可被用于预测货币危机。Joy等人使用CART 模型和随机森林算法,基于36 个工业化经济体的样本,识别了每种危机的主要变量,预测了货币危机和银行危机,并分析了危机的不同原因。
早前,Barry使用了贝叶斯方法解决估计误差项累积造成的不利影响。之后,Brodie 等人和Fan等人运用LASSO 回归方法对优化问题进行了正则化,构建了稳定的稀疏投资组合。从贝叶斯模型的金融稳定性来说,Eidenberger 等人研发了一个金融压力指数的预警系统模型,运用了30 个备选解释变量,并基于最大概率解释变量遴选了重要的预测变量。Chen 等人使用层次贝叶斯模型(Bayesian hierarchical model)研究了2008 年全球金融危机的决定因素,对组合变量选择进行了联合处理。2019 年Guidolin 等人基于时变贝叶斯模型估测了美国次贷危机的影响,估计了美国金融市场的跨资产风险传染。Lang 等人使用了Logistic LASSO 算法并融合惩罚参数的交叉验证,基于银行和宏观金融数据,实时递归了(real-time recursive)样本外测试其模型。2019 年Alessi等人将LASSO 算法应用于测度主权危机,识别了递归环境中主权信用违约互换(credit default swaps,CDS)的宏观横截面指标,并估测了特定经济基本面的市场时变敏感性。Holopainen 等人总结了Logit LASSO 模型、分类树(classification trees)和随机森林等机器学习方法作为预警模型,指出了决策树算法(tree-based algorithms)的性能高于朴素贝叶斯(naive Bayes approach)方法和LASSO 算法,LASSO 算法优于标准Logit 模型。显然,LASSO 回归模型是金融稳定的重要稀疏模型。
近年来,网络方法在金融稳定研究中得以广泛认同。正如Battiston 等人所说,金融系统终归是一个复杂系统,可通过传统网络方法研究其弹性、稳健性和稳定性等重要特征。Glasserman 等人已将网络模型用于风险传染建模。之后,Battiston 等人运用网络方法测度了金融系统风险。美国金融危机后,网络应用的文献数量呈指数式增长。Marcus 等人提出了有效的人机合作关系能够降低系统风险方法。人类和人工智能差异推动了新技术在金融市场、监管和政策制定中的使用,并分析了它们对金融稳定的潜在影响。2020 年Schuldenzucker 等人研究了无法确定银行违约时的系统风险。
Duttagupta 等人首次引入二元分类树,提出了应对银行危机的预警模型。文献[108-109]通过分类决策树、递归分区、分类树集成、自适应提升算法,提出了应对银行系统危机的预警系统,识别银行危机的宏观驱动力。文献[115,119]通过引入LARS-LASSO、Logistic LASSO 建模技术,运用协方差矩阵、损失函数、正则化逻辑回归、交叉验证,回归预测了总风险敞口稀疏投资组合、风险早期预警。文献[118]基于脉冲响应函数、贝叶斯估计,预测了美国金融危机跨资产传染机制。文献[75,123-124]从网络分析、人工智能、依赖关系框架,分析了金融市场、信用违约互换合约中的系统风险,成为用于金融稳定的ML 技术。表10分析了针对稳定性风险预测ML的局限性。

表10 稳定性风险预测方法的局限性Table 10 Limitation of stability risk prediction models
3.4 系统风险监管的量化分析
为了应对金融危机,无论是金融研究者,还是中央银行和国际金融组织一致认为金融监管缺失致使金融系统风险传递和蔓延。21 世纪以来,Galat 等人和Kara先后描述了金融系统风险监管研究过往涌现出的大量文献。全球金融危机的文献总结了金融网络、大数据分析和金融稳定性分析等多种衡量系统风险的方法,与此同时,文献研究中也描述了金融监管的设计分析。Posner 等人发现在评估金融监管成本时应该考虑效益成本分析(benefit-cost analysis)。系统风险监管的网络分析是金融监管研究的一个重要课题。从Bosma分析政策相互依赖性和Clark 等人总结的最优干预政策(optimal intervention policy)规则看,定量分析监管决策将成为未来金融监管的主流方向之一。之前,Cao 等人比较了不同的监管机制,并推导出应对系统流动性风险的方法。随后,Nucera 等人对系统风险进行了分类研究,发现价格与资本评级结果呈现出显著性偏差。
Posner 等人引入了一种应对金融风险监管系统危机的效益成分分析的新方法。通过解决信息外部性、规避系统危机等测算金融监管成本。文献[126,128-129]通过协调不同国家的资本充足要求、政策工具之间相互依赖性、最优干预政策措施,提出了定量识别和化解系统风险的金融监管的新方向。表11分析了基于金融风险监管量化预测方法ML 的局限性。

表11 监管量化预测方法的局限性Table 11 Limitation of quantitative supervision prediction models
针对以上分析的FSR 防控的不同ML 方法,表12阐述了各类ML 方法的优势、缺陷和适应场景等。
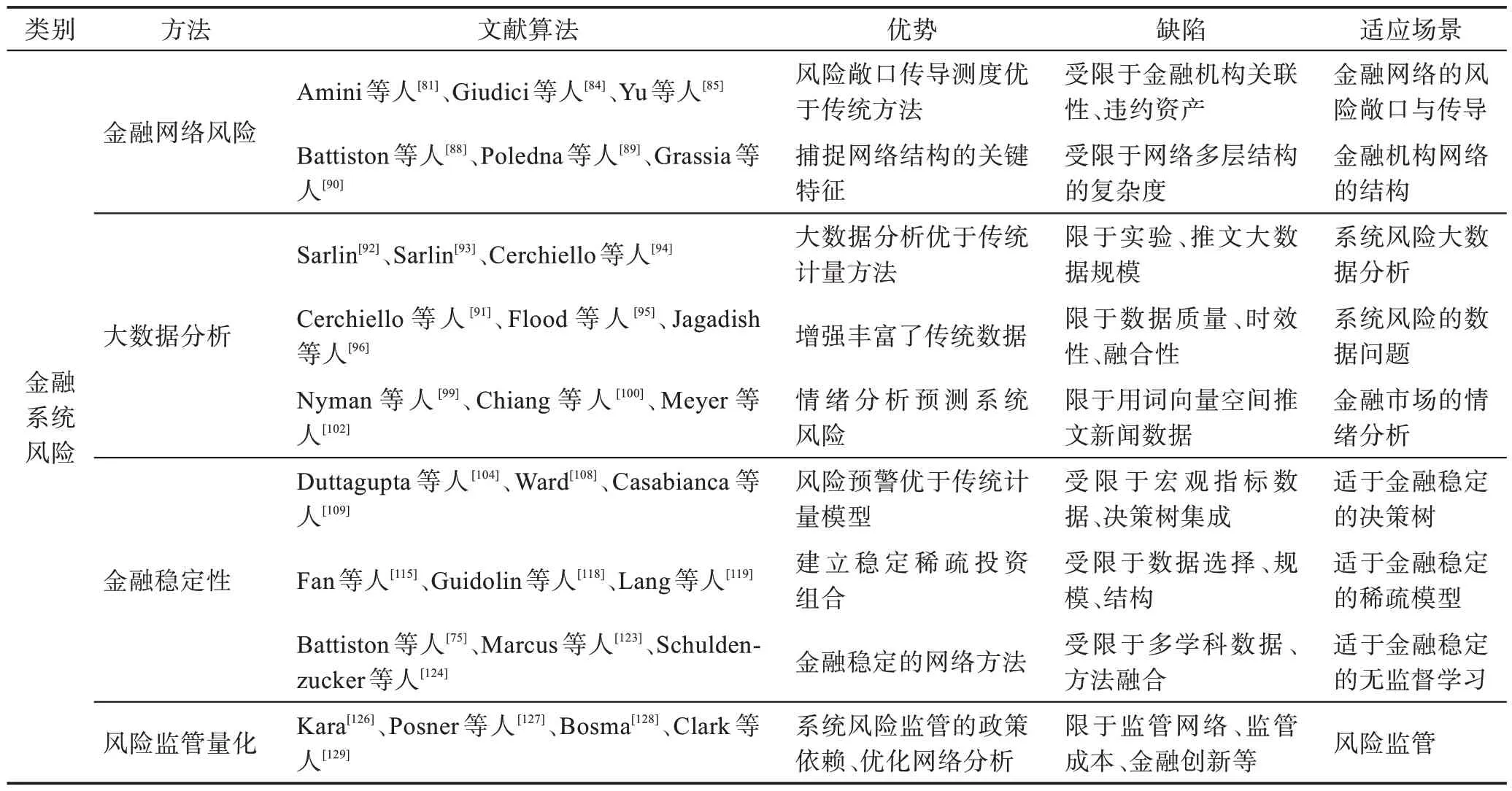
表12 FSR 防控的不同ML 方法比较Table 12 Comparison of ML methods for FSR prevention
4 区域金融风险防控机器学习研究展望
本文提出了区域金融风险防控机器学习方法的科学分类和简要概述,描述了金融风险分类、区域金融风险和机器学习方法。同时,本文基于巴塞尔协议Ⅲ的前后,梳理了传统区域金融风险防控的机器学习方法分析,并系统地综述了区域金融系统风险防控机器学习的具体应用。从以往区域金融风险防控机器学习文献来看,国外的分析研究方兴未艾,而国内的分析仅有零星研究。如今,随着经济学计算机化的发展,ML 在关注预防TFR 的同时,更加着重防范和化解FSR。图9 展望了未来RFRP 管控机器学习的数据、建模、预测、监管科技等方法技术将在以下六方面迎来新的发展。

图9 区域金融风险防控机器学习方法未来方向Fig.9 Future direction of machine learning for regional financial risks prevention
4.1 提升预测传统风险能力
近年来,TFR 防控中信用风险、市场风险、操作风险的测度问题,表现为模型复杂非收敛性、数据来源有限、运算速度过慢等问题。可借鉴ML、深度学习和大数据的逻辑算法思想,通过文本数据、音频数据和视频数据,丰富TFR 防控中的数据缺失,求解策略问题的非线性解,可准确预测在线借款方的违约风险;也可预测为投资者赚取更多的收益。同时,可以结合以往TFR防控中统计计量模型与ML算法互相补充有效数据信息也是未来研究的一个重要发展方向。
4.2 数据安全驱动风险防控
如今的研究中,许多模型算法的数据面临着时变数据不稳定性、数据隐私性、数据高噪音、模拟成本昂贵的问题。实践中为了解决RFRP 防控中ML 可能面对数据隐私致使数据不可用、记录缺乏、模拟昂贵的问题,需要基于小数据学习模型基于少量样本进行有效学习。针对RFRP 防控机器学习数据统计上的非平稳性或大量噪声时,用于分类情景或时间序列情景的稳健学习方法可以解决有问题数据。许多学者运用联邦学习分布式训练技术避免了数据泄漏,通过利用多方模型训练,而无需交换潜在的私人或敏感客户的金融数据,不需要从数据持有方访问数据,保护了数据隐私性和安全性。未来差分隐私建立了个人隐私更高的标准,在联邦学习技术防止多方泄漏私人数据和信息的同时,差分隐私技术是解决RFRP 的ML 模型整体安全性的一个重要发展方向。
4.3 大数据挖掘系统风险数据
当前利用数据挖掘的FSR 数据面临着因为数据的不可用性,大数据还没有完全被用于金融系统风险的问题。大多数研究FSR 的文献主要是从宏观层面、顺周期视角识别应对金融风险。大数据技术需要突破目前异常行为检测、微观主体分类管理、跨国公司监管建模等微观管理研究缺陷。识别“大而不倒(too big to fail)”机构是一项金融宏观审慎监管的重要任务。然而,随着金融系统高度网络化、复杂性,以及风险传染不确定性的研究,“大而不倒”逐渐转变为“复杂不倒(too complex to fail)”的问题。识别金融复杂网络关键节点是推动金融监管措施和政策的有效路径。显然,大数据分析技术、偏微分方程的金融生态稳定性是金融复杂网络的主流研究,大数据在FSR 中的应用将成为未来研究的主要方向。与此同时,系统重要性金融机构管理和数据挖掘需要进一步深入研究,以往金融网络中的风险传染和系统风险被认为源自系统重要性金融机构,因此,大多数国家重点监管这些金融机构。然而,研究表明非金融机构和金融机构关联的网络稳定性可能影响整个系统的稳定性。金融网络的多维体系结构呈现出网络金融机构受到非金融机构的影响,增加了金融系统的不稳定性。当前,RFRP 防控中区域网络关系着重关注于金融机构、非金融机构之间的债务、借贷资本和现金流量。因此,区域非金融机构和金融机构的数据来源是未来大数据研究的主要方向。
4.4 风险测度模型的构建优化
以往大多数研究主要用于预测,神经网络等高维参数模型准确识别了特征和标签之间的相关性,很少关注特征和模型预测之间的因果关系。但是,对于信用批准决策模型、因果关系解释模型等RFRP 防控研究对研发者和监管机构都是非常重要的环节。歧视发现和公平感知机器学习的技术改进,有助于信用批准决策等金融风险管理。神经网络的不确定性测量是一个非常活跃的研究领域,预测区间可以看作神经网络点预测不确定性的准确指标。未来的ML模型需要改善和优化以往学习中的高度随机性、不可解释性、不公平性等特征。同时,从金融系统风险的宏观性、全局性特征来看,基于金融复杂化网络的特征,未来应开发融合机器学习模型与传统计量方法的联合模型,发挥两者的优势互补是新的重要研究方向,为识别、测度和治理RFRP 防控注入坚实的理论基础。
4.5 图像数据增效的新方向
目前图像数据增效已经成为识别、测度金融保险风险管控的新发展方向。金融保险实践中密度不足的模糊成像将致使数据严重匮乏。为了扩充图像数据和模型泛化能力,需要引入图像数据增强算法。图像超分辨率重建算法增加了ML 中训练样本的数量,减少模型过拟合。超分辨率卷积神经网络提高了卫星图像超分辨率的数据增强技术,模型中高分辨率输出的重建质量使用峰值信噪比进行定量评估,同时运用超分辨率前后测试样本的可视化进行定性评估,数据增强缓解了数据稀缺问题。当前生成对抗网络的单幅图像超分辨率算法从低分辨率图像生成高分辨率图像,获得的图像MOS 值比其他方法更加接近原始的高分辨率图像。自注意力机制图像超分辨率重建方法运用神经网络,提高了图像重建质量,保障数据的传输安全。近年来,为了应对冠状病毒大流行的保险体系开始引入X 光图像检测技术。X 光技术可以实现操作简单、实时成像、追溯性强的独特检测效果。目前COVID-19患者数据的稀缺性,需要补充对非COVID-19 图像的监督预训练,基于X 光图像检测数据的ML 方法预测COVID-19 死亡风险有助于提高医疗保险系统决策效率。COVID-19在本地图像数据收集上训练的病情评估具有良好的分布外泛化性。图像数据增效为金融保险系统风险防控将迎来广泛的应用前景。
4.6 风险监管量化的集成对策
为了应对金融系统风险,RFRP 管控应建立一个理论研究和管理实践相结合的有机生态框架。这是管理科学的本质,也是信息技术的根本要求。近年来,应对RFRP 的金融科技监管(Reg-Tech)已经成为金融科技持续发展的重要话题。金融系统风险监管是一项复杂的系统工程,需要一套在数据科学定量研究中综合集成的政策工具箱。毋庸置疑,RFRP 的科学研究应是ML、行为监管、微观审慎、宏观审慎的相互融合。然而,最优政策选择需要对成本和收益进行综合评估。因此,对政策执行效果评价是RFRP的重要范畴。多目标方法以及成本效益分析是解决未来RFRP 量化监管深入研究的重要发展方向。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
成都信息工程大学学报(2021年3期)2021-11-22
银行家(2021年8期)2021-09-06
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
大社会(2020年3期)2020-07-14
当代陕西(2019年15期)2019-09-02
