
SQL-Detector:基于编码特征的SQL习题抄袭检测技术
2022-09-15 10:27莫晓琨韦婷婷
计算机与生活 2022年9期
许 嘉,莫晓琨,于 戈,吕 品+,韦婷婷
1.广西大学 计算机与电子信息学院,南宁 530004
2.广西大学 广西多媒体通信网络技术重点实验室,南宁 530004
3.广西大学 广西高校并行与分布式计算重点实验室,南宁 530004
4.东北大学 计算机科学与工程学院,沈阳 110819
数据库技术一直以来都是计算机学科的核心主干课程,熟练掌握结构化查询语言(structured query language,SQL)是数据库技术教学中的重要目标。与其他编程语言一样,掌握SQL 的关键在于进行大量编码实践。然而,大量教学实践表明学生在完成SQL 编程习题时普遍存在抄袭现象,从而影响了教师对其学习效果的评估准确性,不利于提高教学质量。因此,研发面向SQL 习题的抄袭检测技术,从而能从学生提交的大规模SQL 代码中检测到潜在的抄袭代码是现代计算机教育亟待解决的问题。
虽然研究人员针对Java、C、Python 等编程语言提出了代码抄袭检测技术,鉴于SQL 拥有许多区别于其他编程语言的性质,这些技术在解决面向SQL习题的代码抄袭检测问题时存在局限性。近年来,一些研究人员提出了专门针对SQL 习题的代码抄袭检测技术,可分为两类:基于字符串匹配的技术和基于编码特征匹配的技术。然而,现有技术仍存在不足。首先,基于字符串匹配的抄袭检测技术忽略了SQL 的特性,仅仅通过将某学生答案与其他学生的答案进行字符串相似性匹配来实现抄袭检测,忽略了学生在编码特征方面的差异,导致误判率较高。其次,当前的基于编码特征匹配的抄袭检测技术虽然利用了学生的SQL 编码特征来辨识抄袭行为,然而其一方面仅通过比较学生自身的编码特征变化来判定抄袭行为,没有对同一道SQL 习题下全体学生的编码特征进行相似性分析,另一方面其所考虑的编码特征过于简单(只考虑学生编码的关键字大小写书写特征、前后的换行特征和注释特征),没能充分利用SQL 的丰富编码特征(例如习题SCHEMA特征和习题函数特征)来提高检测精确度。鉴于现有研究工作存在不足,本文提出基于编码特征的SQL 习题抄袭检测技术,命名为SQL-Detector。SQLDetector 首先基于SQL 特性分别提取学生的习题编码特征和泛化编码特征;其次,以某道SQL 习题下全体学生的习题编码特征为输入进行聚类分析从而识别抄袭群体,最后通过比较抄袭群体中每名学生待检测SQL 代码的泛化编码特征和其历史泛化编码特征之间的相似性来判定抄袭行为中的抄袭者与被抄袭者。综上,本文主要贡献如下:
(1)从SQL 的特性出发,提出了面向特定SQL 习题的学生习题编码特征和面向编码习惯的学生泛化编码特征。基于这些编码特征能够实现对学生的画像。
(2)提出了基于编码特征的SQL 习题抄袭检测技术SQL-Detector。该技术首先通过对某道SQL 习题下所有学生的习题编码特征进行聚类分析从而识别出抄袭群体;其次通过比较抄袭群体中每名学生待检测SQL 代码的泛化编码特征和其历史泛化编码特征(即学生画像)之间的相似性来判定抄袭行为中的抄袭者和被抄袭者。
(3)组织广西大学计算机专业的284 名本科生于自主研发的SQL 在线答题系统中完成SQL 习题并收集学生们的SQL 代码作为实验测评数据集。实验结果表明,SQL-Detector 技术比相关最好的技术在抄袭检测精确度方面平均提高了14.0%。
1 相关工作
为了有效解决代码抄袭检测问题,研究人员提出了许多相关技术,这些技术大多面向Java、C、Python 等编程语言,可分为以下四类。
(1)词频统计
早在1977 年,Halstead 就提出了软件科学度量理论,该理论从操作符种类数量和操作数种类数量等属性定义软件代码,并以此构建代码的特征向量,继而可以通过计算两段代码的特征向量间的编辑距离判定它们是否存在抄袭现象。之后,Sposato 等人提出可以基于声明语句数量、函数数量、调用语句、结构化语句块(ifwhilefor)数量等属性来优化对代码特征向量的定义。Grier 则在Halstead 的研究基础上加入了代码有效行数、变量声明、控制语句数量等属性,构成了包含20 个属性的代码特征向量。
(2)字符串匹配
基于字符串的代码抄袭检测技术先对代码进行语义分析以便生成代码的标记令牌(token),然后使用字符串匹配算法(例如最长公共子序列法和最长公共子串法)度量代码的标记令牌间的相似度,从而发现抄袭现象。现有的代码抄袭检测系统多是基于字符串匹配的思路实现的,例如:卡尔斯鲁厄理工大学研发的JPlag系统、斯坦福大学研发的Moss系统和悉尼大学研发的YAP 系统。
近年来,Danpin 在经典的winnowing 算法的基础上提出了simhash 算法,能够挖掘出八种学生常见代码抄袭手段以提高代码抄袭检测的精确度。王颖则基于贪婪字符串平铺的方法对学生提交的编码答案进行抄袭检测。
(3)语法树匹配
基于语法树匹配的方法首先将代码转换为其抽象语法树结构(abstract syntax tree,AST),再通过各个代码的语法树间的匹配来完成代码抄袭检测。例如,Kim 等人基于在抽象语法树中寻找相似子树的方法计算语法树间的相似度,从而判断是否存在抄袭。Jiang 等人则定义了抽象语法树的九维特征向量以实现对抽象语法树的表示,并使用LSH 算法度量特征向量间的相似性。
(4)编码特征匹配
Arabyarmohamady 等人提出了一个基于代码风格的C 语言代码剽窃检测框架,通过检测该生的代码风格变化和与其他同学代码风格的相似性实现代码抄袭检测。Ljubovic 等人设计提出了一种基于云的集成开发工具,该工具可以提取出学生编码过程中的动态编码特征,包括代码添加行数、代码删除行数和平均粘贴长度等,最终通过神经网络实现了代码抄袭检测。
相较于面向其他编程语言的代码抄袭检测技术,面向SQL 代码的抄袭检测技术较少,现有研究工作或是利用字符串匹配的方法或是利用编码特征匹配的方法实现对SQL 代码的抄袭检测。
(1)基于字符串匹配的SQL 习题抄袭检测技术
Scerbakov 等人通过对SQL 代码进行分词并计算SQL代码间的编辑距离来判定两份作业为抄袭作业。Russell 等人提出了面向SQL 习题抄袭检测的Equal算法。Equal算法根据SQL 代码字符串间的相似度返回4 到10 之间的分数,10 分代表两个SQL 代码完全匹配,4 分代表在忽略了大小写、不必要空格和括号等信息后两个SQL 代码完全匹配。基于贪婪式字符串匹配的JPlag 系统是广泛被使用的代码抄袭检测系统。JPlag 系统虽然无法直接用于SQL 习题的抄袭检测,然而允许开发人员添加SQL 解析器对其进行扩充以实现对SQL 习题的抄袭检测。
基于字符串匹配的SQL 习题抄袭检测技术的关注点在于SQL 代码中的单词是否相同。当习题的SQL 答案简单或习题不具有多个等价答案时,该类技术的误判率较高,无法利用学生编码特征来识别学生提交的SQL 代码间的差异。
(2)基于编码特征匹配的SQL习题抄袭检测技术
葛文馨等人在2019 年提出了一种基于学生编码习惯的SQL 习题抄袭检测算法。该算法首先对学生历史提交的SQL 代码进行预处理;其次以预处理后的学生历史提交的SQL 代码为输入来训练朴素贝叶斯分类器,以便对学生新提交的SQL 代码进行代码功能类别判定(功能类别包括SQL 的数据查询功能、数据操纵功能以及数据控制功能等);之后对同一类别的SQL 代码提取能反映出学生编码习惯的特征矩阵,文献中考虑的编码习惯包括学生的关键字大小写习惯、代码换行习惯和代码注释习惯;最后基于学生新提交的SQL 代码的特征矩阵和其历史提交的SQL 代码的特征矩阵间的Jaccard 相似度来判定学生新提交的SQL 代码是否存在抄袭行为:与历史不相似则判定为抄袭,反之则判定为非抄袭。
相关研究的实验表明,由于考虑了学生在编码过程中呈现出的独特编码习惯,基于编码特征匹配的SQL 习题抄袭检测技术能够降低抄袭检测的误判率,是当前用于解决SQL 习题抄袭检测问题的主流方法。然而该类方法的现有研究工作:(1)仅通过比较学生自身的编码特征变化来判定抄袭行为,忽略了对学生间编码特征的相似性分析;(2)考虑的编码特征过于简单,从而制约了其抄袭检测的精确度。
2 SQL-Detector技术实现框架
针对现有SQL习题抄袭检测技术的不足,本文提出了一种基于编码特征的SQL习题抄袭检测技术,即SQL-Detector技术。该技术的实现框架如图1 所示。
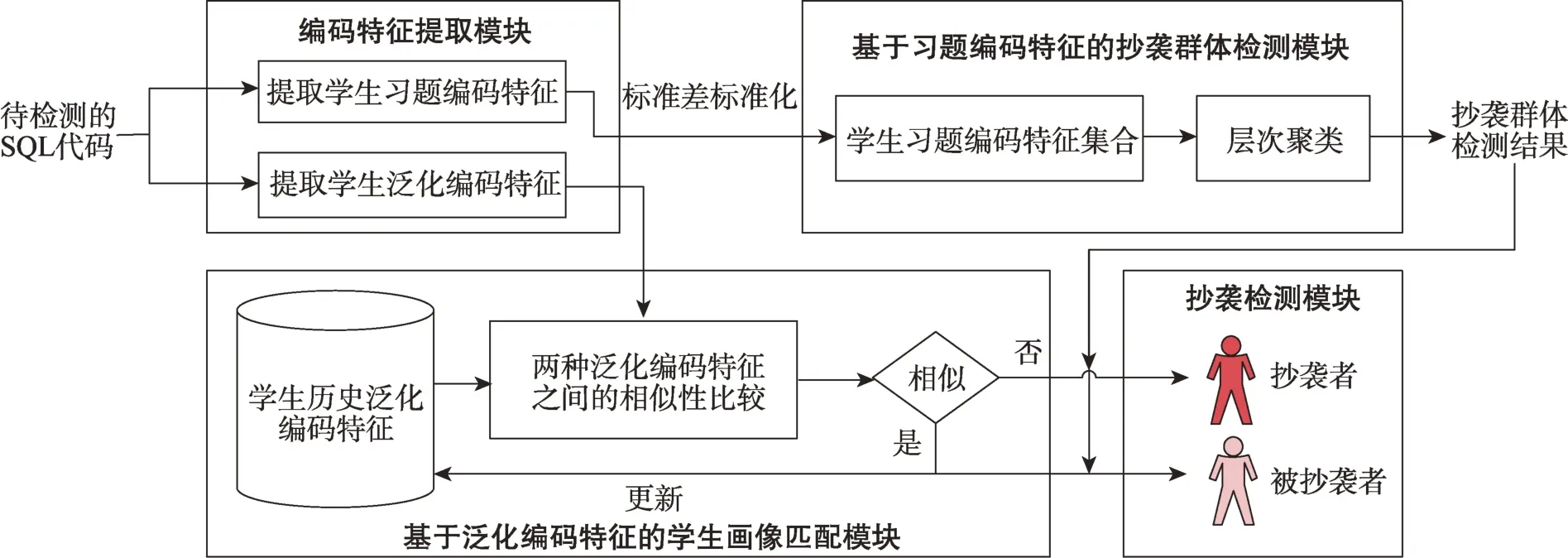
图1 SQL-Detector技术实现框架Fig.1 Implementation framework of SQL-Detector technique
如图1所示,SQL-Detector技术包含四个重要模块:
(1)编码特征提取模块。该模块以学生提交的SQL 代码为输入分别提取学生的习题编码特征和泛化编码特征。其中,学生习题编码特征为学生针对某道SQL 习题给出的SQL 代码所反映出的编码特征,与该SQL 习题的特性紧密相关,学生习题编码特征用于发现该习题的抄袭群体。学生泛化编码特征则反映了学生在编写SQL 代码时所展现出的泛化性编码习惯,用于对学生的SQL 编码习惯进行画像。
(2)基于习题编码特征的抄袭群体检测模块。该模块以经过标准化处理后的所有学生的习题编码特征(表示为学生的习题编码特征集合)为输入,之后通过层次聚类算法对学生的习题编码特征集合进行聚类分析,以检测出抄袭群体。
(3)基于泛化编码特征的学生画像匹配模块。该模块将学生当前提交的SQL 代码的泛化编码特征与该生的历史泛化编码特征(即该生的画像)进行相似性匹配:若相似则认为该生当前提交的SQL代码为本人撰写,继而使用该生当前提交的SQL代码的泛化编码特征对该生的历史泛化编码特征进行更新;反之则认为该生当前提交的SQL代码可能存在抄袭行为。
(4)抄袭检测模块。该模块以“基于习题编码特征的抄袭群体检测模块”输出的抄袭群体和“基于泛化编码特征学生画像匹配模块”输出的匹配结果为输入对学生的抄袭行为进行识别。对于存在于某抄袭群体中的学生:若该生当前提交的SQL 代码的泛化编码特征与其历史画像间的相似度不大于某阈值,则将该生判定为抄袭者;反之,若该生的泛化编码特征与其历史画像间的相似度大于该阈值,则将该生判定为被抄袭者。
3 基于编码特征的抄袭检测技术
本章将详细介绍SQL-Detector 技术的各个功能模块的实现思路。
3.1 编码特征提取模块
学生在SQL 编码过程中会展现出不同的编码特征。表1 列出了针对同一道SQL 习题,即“查询Geology 学院所修学分总数超过50 的学生信息”,学生A、学生B 和学生C 所给出的SQL 代码。不难发现,这三名学生给出的SQL 代码虽然实质上是一样的,但是在关键字大小写、代码缩进和换行这三方面因编码习惯不同而存在差异。例如,在关键字大小写书写习惯方面,学生A 习惯采用全小写的方式书写关键字,学生C 习惯采用全大写的方式书写关键字,学生B 则习惯采用首字母大写的方式书写关键字。此外,三名学生还在代码换行和缩进方面呈现出不同的习惯。可见,编码特征能有效刻画学生个体间的差异,有助于辨识出学生的抄袭行为。为了有效识别抄袭行为,本文提取的编码特征包括两类,即学生习题编码特征和学生泛化编码特征。其中,学生习题编码特征反映出学生针对习题所给出的SQL 代码的编码特性,与特定习题紧密相关。学生泛化编码特征则反映出学生编写SQL 代码的泛化编码习惯,不与特定习题绑定。
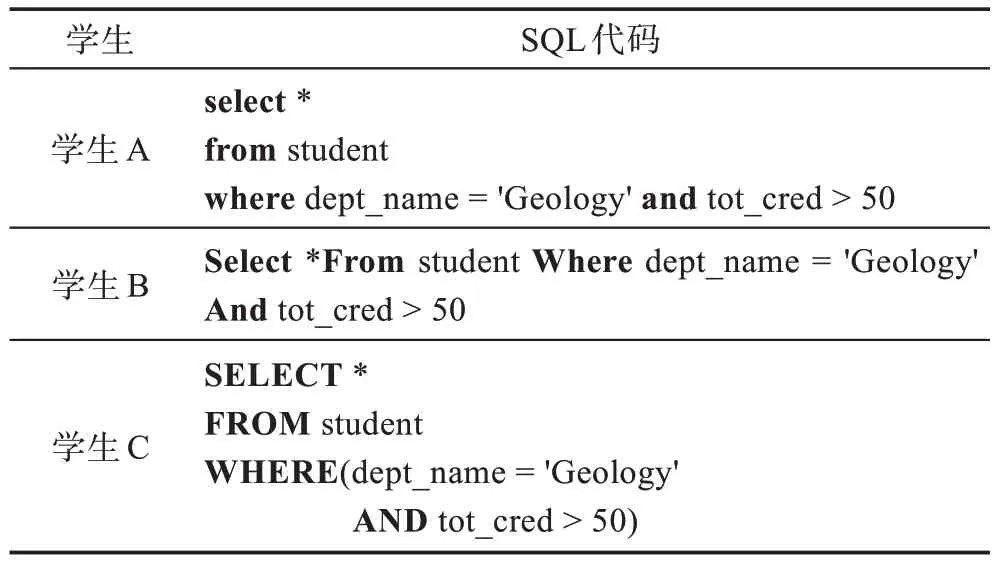
表1 学生存在不同的SQL 编码特征Table 1 Students show different SQL coding features
通过分析SQL 的语法、句法特性,总结得到八类与特定SQL 习题相关的学生习题编码特征,分别是:
(1)习题SQL 关键字特征。SQL 关键字是SQL标准中指定的具有特殊含义的单词,例如SELECT、FROM、WHERE 都是SQL 关键字。SQL 规范中 对SQL 关键字的大小写不做书写规定。因而,不同学生在书写SQL 关键字时会呈现出不同的关键字书写习惯。学生的SQL 关键字书写习惯是可以帮助识别学生个体的SQL 编码特征。某学生的习题关键字特征是基于其提交的SQL 代码的每个子句定义的:当子句中以全小写的方式书写关键字时,设置为1;当子句中以全大写的方式书写关键字时,设置为2;其他方式设置为3。
(2)习题SCHEMA 特征。SCHEMA 是数据库的组织和结构,包含表(table)、列(column)和视图(view)等数据库对象。首先将SQL 代码涉及的SCHEMA 信息整合为SCHEMA 字典。某学生的习题SCHEMA 特征是基于其提交的SQL 代码的每个子句定义的:若子句中出现的SCHEMA 信息不在SCHEMA 字典中,表明学生书写的SCHEMA 信息存在错误,此时将该生的习题SCHEMA 特征定义为错误SCHEMA 信息与SCHEMA 字典中与其最相似的元素间的编辑距离乘以该元素的字典序;否则,表明学生写对了相关SCHEMA信息,则将其习题SCHEMA特征定义为SCHEMA 信息在SCHEMA 字典中的字典序与SCHEMA 信息在子句中的位置之间的乘积。
(3)习题函数特征。SQL 规范中规定了一系列用于完成特定计算的内建函数,基本类型包括Aggregate 函数和Scalar 函数。其中,Aggregate 函数包括AVG、COUNT、MAX 等;Scalar 函数包括NOW、LEN 和MID 等。将SQL 规范中定义的内建函数整合为函数字典。某学生的习题函数特征定义为其SQL代码的每个子句中所引用的函数在函数字典中的字典序与函数在子句中的位置间的乘积。
(4)习题关系运算符特征。SQL 的WHERE 子句和JOIN 子句中可能存在着一些对关系的判定。对于某个具体的关系判定,学生可能运用不同的关系运算符和关键字给出等价的写法。例如A>10 与NOT(A<=10)在判定语义上是等价的。根据SQL 规范中给出的关系运算符和关键字生成关系运算符字典。某学生的习题关系运算符特征定义为其SQL 代码的每个子句中关系运算符在关系运算符字典中的字典序与关系运算符在子句中的位置之间的乘积。
(5)习题括号特征。括号是SQL 中的合法符号,学生编写SQL 代码时对括号的使用习惯存在差异,体现在当括号不是必需前提下,有些学生习惯于使用括号,有些学生则放弃使用括号。某学生的习题括号特征定义为其SQL 代码的每个子句中的每个括号在子句中的位置之和。
(6)习题空格特征。空格在SQL 中被用于分隔词与词。由于空格不存在语义,SQL 语法对空格的数量和位置没有固定要求。因而,学生在编写SQL时对空格的使用习惯存在差异。体现在不同学生可能会在不同的地方使用不同数量的空格,例如利用空格来调整SQL代码的整体格式。某学生的习题空格特征定义为其SQL代码的每个子句中所有连续空格符序列的基数与连续空格符序列起始位置的乘积之和。
(7)习题缩进特征。SQL 支持编辑时使用缩进符调整一行的起始字母与页面边界之间的距离。SQL 中对缩进符的使用习惯因人而异,因而也可作为辨识学生的编码特征。例如,一些学生在编写SQL 时习惯将多个条件判断语句分行列出,并通过缩进符将这些条件判断语句对齐(如表1 的学生C 的代码所示)。某学生的习题缩进特征定义为其SQL代码的每个子句中所有连续缩进符序列的基数与连续空格符序列起始位置的乘积之和。
(8)习题换行特征。当查询语义较为复杂时,反映该查询语义的SQL 代码的篇幅将大幅增加,此时若不对SQL 代码进行断句处理则会降低SQL 代码的可读性。因此,SQL 编写人员会使用换行符将SQL代码基于其语义结构分割为若干行。由于换行符的使用位置不影响SQL 语句的执行结果,换行符的使用习惯也因人而异。某学生的习题换行特征定义为其SQL代码的每个子句中各个换行符的所在位置之和。
为保证所提取的学生习题编码特征对于区分学生个体具有细粒度的辨识度,先对学生提交的SQL代码进行子句划分,然后以子句为单位提取学生的习题编码特征,最后将学生提交的SQL 代码中所有子句的编码特征拼接形成该生的习题编码特征向量。需要说明的是:首先,对于学生SQL 代码中相同类型的子句出现多次的情况,将同类型子句的编码特征进行累加;其次,当SQL 代码不存在某种类型的子句时,其编码特征向量中与该子句类型对应的所有取值位置全部设置为0。七类SQL 子句与其能提取的习题编码特征之间的对应关系详见表2。
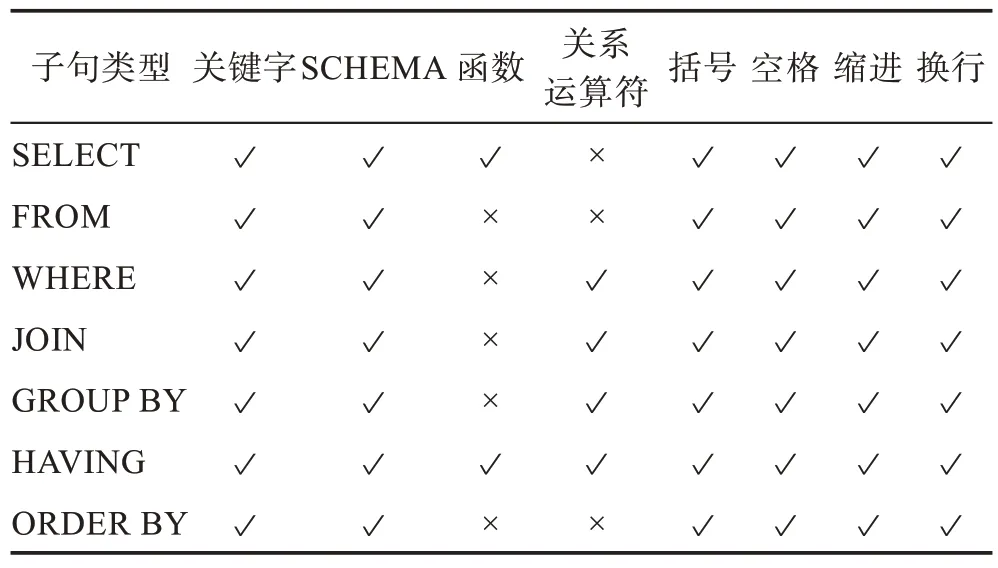
表2 子句类型与习题编码特征之间的关系Table 2 Relationships between clause types and exercise coding features
综上,一个学生习题编码特征向量是一个48 维的整型向量。具体而言,向量的第1~7 维记录了SELECT 子句中出现的七类习题编码特征(如表2 所示);第8~13 维记录了FROM 子句中出现的六类习题编码特征;第14~20 维记录了WHERE 子句中出现的七类习题编码特征;第21~27 维记录了JOIN 子句中出现的七类习题编码特征;第28~34维记录了GROUP BY 子句中出现的七类习题编码特征;第35~42 维记录了HAVING 子句中出现的八类习题编码特征;第43~48 维记录了ORDER BY 子句中出现的六类习题编码特征。
与学生习题编码特征不同,学生泛化编码特征是对学生在不同的SQL 习题中都将呈现出的编码习惯(即泛化编码习惯)的刻画,用于对学生的SQL 编码习惯进行画像。学生泛化编码特征包括以下六类,它们是:
(1)泛化关键字特征。与习题关键字特征不同,泛化关键字特征只记录了学生在各个SQL 子句中针对主关键字的大小写书写特征,而非针对所有关键字的大小写书写特征。首要关键字与SQL 子句的类型相关,例如SELECT 子句的主关键字是“SELECT”、FROM 子句的主关键字是“FROM”。学生泛化关键字特征的赋值规则为:当以全小写的方式书写子句的主关键字时,设置为1;当以全大写的方式书写子句的主关键字时,设置为2;其他方式设置为3。
(2)泛化括号特征。与习题括号特征不同,泛化括号特征只记录学生在各类SQL 子句中是否使用了括号,而并不需要记录括号在子句中出现的具体位置。
(3)泛化换行特征。与习题换行特征不同,泛化换行特征只记录学生在各类SQL 子句中是否会对子句进行换行处理,而非记录换行符在子句中的具体位置。
(4)泛化空格特征。与习题空格特征不同,泛化空格特征只记录学生在各类SQL 子句中是否存在连续使用多于两个空格的情况,而不记录学生使用空格的具体位置与数量。
(5)泛化缩进特征。与习题缩进特征不同,泛化缩进特征只记录学生在各类SQL 子句中是否在子句中使用缩进符,而不会记录缩进符在子句中的具体位置。
(6)字段名修饰特征。字段名修饰特征记录了学生在完成单表查询任务的SELECT 子句中是否使用了表名对字段进行修饰(即使用table.column 的模式对字段进行引用)。由于是否加表名对字段进行修饰并不影响单表查询的查询结果,学生的字段名修饰特征能反映出学生的编码习惯。
综上,包含以上6 类泛化编码特征的学生泛化编码向量是一个36 维的整型向量。具体而言,向量的第1~7 维记录了学生对七类SQL 子句(详见表2)的主关键字的大小写书写习惯;第8~14 维记录了学生在七类SQL 子句中是否使用了括号;第15~21 维记录了学生在七类SQL 子句中是否使用了换行符;第22~28 维记录了学生在七类SQL 子句中是否连续使用了多个空格符;第29~35 维记录了学生在七类SQL 子句中是否使用了缩进符;第36 维记录了学生在单表查询的SELECT 子句中是否使用表名对字段进行修饰。
3.2 基于习题编码特征的抄袭群体检测模块
基于习题编码特征的抄袭群体检测模块以某道SQL 习题对应的所有学生的习题编码特征向量为输入,并利用层次聚类的方法得到抄袭群体。由于学生习题编码特征向量的各个维度间存在量纲不一致的问题,使用Z-score 标准化方法对学生习题编码特征向量的各个维度进行了归一化处理,以降低因量纲差异所导致的计算误差。以归一化后的所有学生习题编码特征向量为输入,并以欧式距离作为向量间的相似性度量函数,最终利用凝聚式层次聚类算法得到抄袭群体:若一个聚类簇中包含多个学生,则判定该聚类簇中的学生为一个抄袭群体。
3.3 基于泛化编码特征的学生画像匹配模块
基于泛化编码特征的学生画像匹配模块以某学生待检测SQL 代码的习题泛化编码特征向量为输入,通过比较该向量与基于该生历史提交的SQL 代码计算得到历史泛化编码特征向量(即学生画像)之间的相似度来判定该生是否抄袭别人的代码。若相似度高则表明该生的泛化编码习惯与其历史编码习惯一致,因而认为待检测SQL 代码为该生本人撰写,并使用该生待检测SQL 代码的泛化编码特征向量对该生画像进行更新;反之则表明该生的泛化编码习惯与其历史编码习惯呈现出较大差异,此时判定待检测SQL 代码非该生本人撰写,并将该结果报送给抄袭检测模块。学生历史泛化编码特征向量中每维的取值是该生历史提交的多个SQL 代码的泛化编码特征向量中相应维度取值的加权和。具体而言,学生的历史泛化编码特征向量中第维(表示为hgf[])的计算方法如式(1)所示。

其中,L表示基于历史上该生提交的多个SQL 代码的泛化编码特征向量统计得到的向量在第维的独特取值个数;v表示第维的第个独特取值;p则表示第维的第个独特取值在该维度上的取值占比。
3.4 抄袭检测模块
该模块以“基于习题编码特征的抄袭群体检测模块”输出的抄袭群体和“基于泛化编码特征学生画像匹配模块”输出相似性比较结果为输入,目的是为了区分抄袭群体中的抄袭者和被抄袭者。若抄袭群体中某学生的习题泛化编码特征向量与该生的历史泛化编码特征向量之间相似度低,则将该生判定为抄袭者;反之,则将该生判定为被抄袭者。
基于编码特征的SQL 抄袭检测算法的伪代码详见算法1 所示。该算法以学生针对某SQL 习题所提交的SQL 代码集合和所有学生的历史泛化编码特征向量集合为输入,输出针对该SQL 习题的抄袭检测结果集合。其中,中的每个元素为二元组形式<Q,R>:Q表示第个学生针对该习题所提交的SQL 代码,R则为此SQL 代码的抄袭指示标记(R=copier 表示该生为抄袭者;R=giver 表示该生为被抄袭者)。算法首先遍历中的每个学生提交的SQL代码(行2),提取出针对待检测习题的每个学生的习题编码特征向量(行3)、泛化编码特征向量(行5),并对所有学生的习题编码特征向量进行归一化处理(行4)。其次,利用层次聚类方法对归一化后的所有学生的习题编码特征向量进行聚类分析,从而得到聚类簇集合(行6)。之后,遍历中的每一个簇,当簇内包含多个学生时,将该簇加入抄袭群体集合中(行8~10)。对于每个抄袭群体中的学生(行11~12),首先读取该生的历史泛化编码特征(行13)和针对当前待检测习题的习题编码特征(行14),再使用欧氏距离计算该生的习题泛化编码特征ef与其历史泛化编码特征hgf之间的相似度(行15)。若相似度不大于阈值,则判定该生为抄袭者,并将检测结果添加至抄袭检测结果集中(行16~17);若相似度大于阈值,则判定该生为被抄袭者,将检测结果添加至的同时使用gf更新该生的历史泛化编码特征(行18~20)。最后,算法返回抄袭检测结果集(行21)。
基于编码特征的SQL 习题抄袭检测算法
输入:待检测学生SQL 代码集合,学生历史泛化编码特征向量集合。
输出:抄袭检测结果集={<Q,R>}。


下面对算法1 的时空复杂度进行分析。该算法的主要计算代价在于对所有学生的习题编码特征进行层次聚类,因此算法时间复杂度等于所采用的层次聚类算法的时间复杂度。层次聚类是数据挖掘的重要研究内容之一,拥有很多实现策略。本文采用Ward Linkage 方法实现聚类。Ward Linkage 方法(又称离差平方和法)是凝聚式层次聚类方法的典型代表。在SQL 代码抄袭检测场景中运用Ward Linkage 方法对SQL 代码进行聚类分析相较于传统的-均值聚类方法更具优势:(1)Ward Linkage 方法不需要指定聚类数目的值,因此聚类结果质量对值依赖性不强,且能产生高质量的聚类结果;(2)Ward Linkage 方法的聚类结果较-均值聚类更具可解释度,因此能更好地解释抄袭群体和非抄袭群体之间的编码特征差异。对于算法1,运用Ward Linkage 方法实施对学生习题编码特征进行层次聚类的时间复杂度为(||),其中||是待检测学生答案集合的基数。易知,算法1 的空间存储开销主要来自于层次聚类过程中对邻近度矩阵的存储,邻近度矩阵存放的是层次聚类中每个簇间的距离,故算法的空间复杂度为(||)。与本文最相关的研究工作(即文献[4])提出的SQL 代码抄袭检测技术的时间复杂度为计算SQL 代码两两间相似度的开销,即(||)。文献[4]的空间复杂度由待检测SQL 代码集合的关键字词频矩阵大小决定,为(||),其中为SQL 关键字的基数。可见,本文提出的SQL-Detector 技术与文献[4]技术的时间复杂度相同。虽然SQL-Detector 技术的空间复杂度一般高于文献[4]技术,但因为SQLDetector 技术一方面利用同一道SQL 习题下全体学生的编码特征的相似性分析来提高抄袭检测的精度,另一方面考虑了更丰富的SQL 编码特征,因此其在SQL 代码抄袭检测精度方面比文献[4]技术有显著提升(详见第4 章)。
4 实验评价
4.1 实验设置
为了验证基于编码特征的SQL 习题抄袭检测技术SQL-Detector 的有效性,本节对SQL-Detector 技术与相关技术的抄袭检测精度进行了实验评价。实验中参与比较的相关技术包括文献[4]提出的SQL 习题的抄袭检测技术和代码抄袭检测领域所用的经典技术JPlag。其中,文献[4]的技术通过提取学生SQL代码的部分编码特征(即学生的关键字大小写习惯和换行习惯)来生成特征矩阵,继而通过比较当前代码的特征矩阵与该生历史特征矩阵间的Jaccard 相似度来判定代码是否存在抄袭行为。JPlag 技术则首先将需要比对的两组SQL 代码解析为Token 集合,然后基于贪婪式字符串匹配算法计算两组Token 集合间的相似度,从而发现代码间的抄袭行为。实验中设定文献[4]技术所依赖的相似度阈值为文献[4]给出的最优阈值,即0.5;设定JPlag 技术的相似度阈值为文献[4]中给出的最优阈值,即0.7。实验中基于Java 语言实现本文提出的SQL-Detector 技术以及本文对比的文献[4]技术、JPlag 技术。实验所用计算机服务器的配置为:Intel Core i5-8500 3.0 GHz(4-Core)CPU、8 GB内存、1 TB硬盘、64位Windows 10操作系统。
组织广西大学计算机专业的284 名本科生于自主研发的SQL 在线答题系统中完成12 道SQL 习题并收集学生们的SQL 代码作为实验数据集,实验数据集的详细信息如表3 所示。为了评估不同技术对于学生提交的SQL 代码的抄袭检测精确度,邀请两名具有8 年以上SQL 教学经验的教师对数据集中的学生SQL 代码是否存在抄袭行为进行标注:存在抄袭行为标记为1,反之则标记为0。
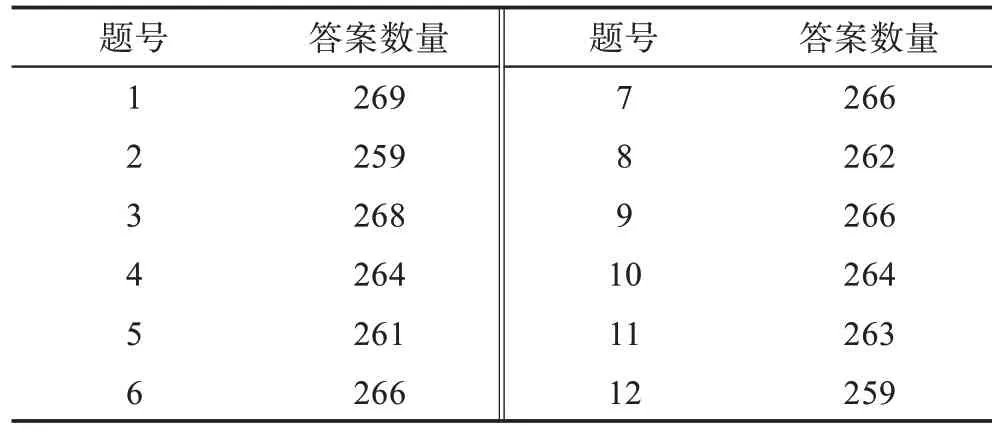
表3 实验数据集详细信息Table 3 Details of experimental dataset
4.2 评价指标
为了便于与其他技术进行比较,仿造其他技术的输出结果,实验中将SQL-Detector 技术检测为‘copier’或‘giver’的SQL 代码都标记为1(即涉及抄袭行为)。实验评价指标包括查准率、查全率和1值。
查准率()表示预测为正的样例占真实正样例的比率,其计算方法如式(2)所示:

其中,、、和分别表示真正例(true positive)、假正例(false positive)、真反例(true negative)和假反例(false negative),且样例总数(即后文中的Total)为以上四种样例的数目之和。
查全率()表示正例被正确预测的比率,其计算方法如式(3)所示:

1 值则同时兼顾了查准率和查全率,其计算方法如式(4)所示:

4.3 实验结果与分析
SQL-Detector 技术中的习题编码特征聚类模块是基于Ward Linkage 凝聚式层次聚类方法执行对所有学生习题编码特征向量的聚类分析。相似度阈值的设定影响到聚类结果的质量,进而影响到对抄袭检测群体的识别质量。因此,本节首先对习题编码特征聚类模块使用的相似度阈值进行实验分析。表4 展示了不同相似度阈值下SQL-Detector 技术的抄袭检测结果的1 值。如表4 所示,随着相似度阈值增大,1 值呈现出增大的趋势,这是因为过小的阈值会导致聚类簇的数量过多,因此不能有效识别习题编码特征具有较大差异的抄袭行为。当相似度阈值超过0.8 时,1 值则出现了下降趋势,这是因为过大的阈值会导致聚类簇的数量过多,从而导致本来具有抄袭现象的代码没有被聚为一类,继而引发了误判。后文实验中将SQL-Detector 技术中聚类所依赖的相似度阈值统一设置为0.8。

表4 层次聚类中相似度阈值对抄袭检测精度的影响Table 4 Impact of similarity threshold in hierarchical clustering on accuracy of plagiarism detection
表5 展示了对于每道SQL 习题,三种SQL 习题抄袭检测技术对学生提交的SQL 代码的抄袭检测精确度,涉及查准率、查全率、1 值这三项指标。由表5可知,JPlag 技术的1 值最低,对12 道SQL 习题的抄袭检测结果的1 均值仅为41.8%,这是因为JPlag 技术仅通过比较学生提交的SQL 代码之间的字符串相似性来发现抄袭行为,而没能利用辨识度更高的,能反映SQL 语法、句法特性的学生编码特征来实现抄袭检测,最终导致了较高的误判率。文献[4]的SQL习题抄袭检测技术由于利用了SQL 语义下学生的部分编码特征来辨识抄袭行为,因而对于12 道SQL 习题,文献[4]技术的抄袭检测结果的1 均值(即73.0%)比JPlag 技术提高了74.6%。可见,基于编码特征的SQL 习题抄袭检测技术比基于字符串匹配的SQL 抄袭检测技术在抄袭行为辨识力方面更具优势。同时从表5 可观察到本文提出的SQL-Detector技术针对12 道SQL 习题的查准率、查全率和1 值均优于文献[4]的技术。特别地,SQL-Detector技术针对12 道SQL 习题的1 均值达到了83.2%,相较于文献[4]技术的检测结果提高了14.0%。SQL-Detector 技术的优势来自于:(1)从SQL 的语法、句法特性出发,抽取并利用了比文献[4]的技术更丰富的学生编码特征来辨识抄袭行为;(2)不但和文献[4]一样通过比较学生待检测SQL 代码的编码特征和该生历史编码特征之间的差异来识别抄袭学生,而且通过对待检测SQL 习题的所有学生的编码特征进行聚类分析来发现抄袭群体,即利用同一道SQL 习题下学生SQL 代码相似性分析来提高抄袭检测的精确度。可见,从具体编程语言特性出发来定义编码特征以及在抄袭检测流程中同时考虑同一学生的编码特征的历史一致性和待检测习题下不同学生编码特征之间的相似性是提高面向特定编程语言的代码抄袭检测精确度的有效手段。
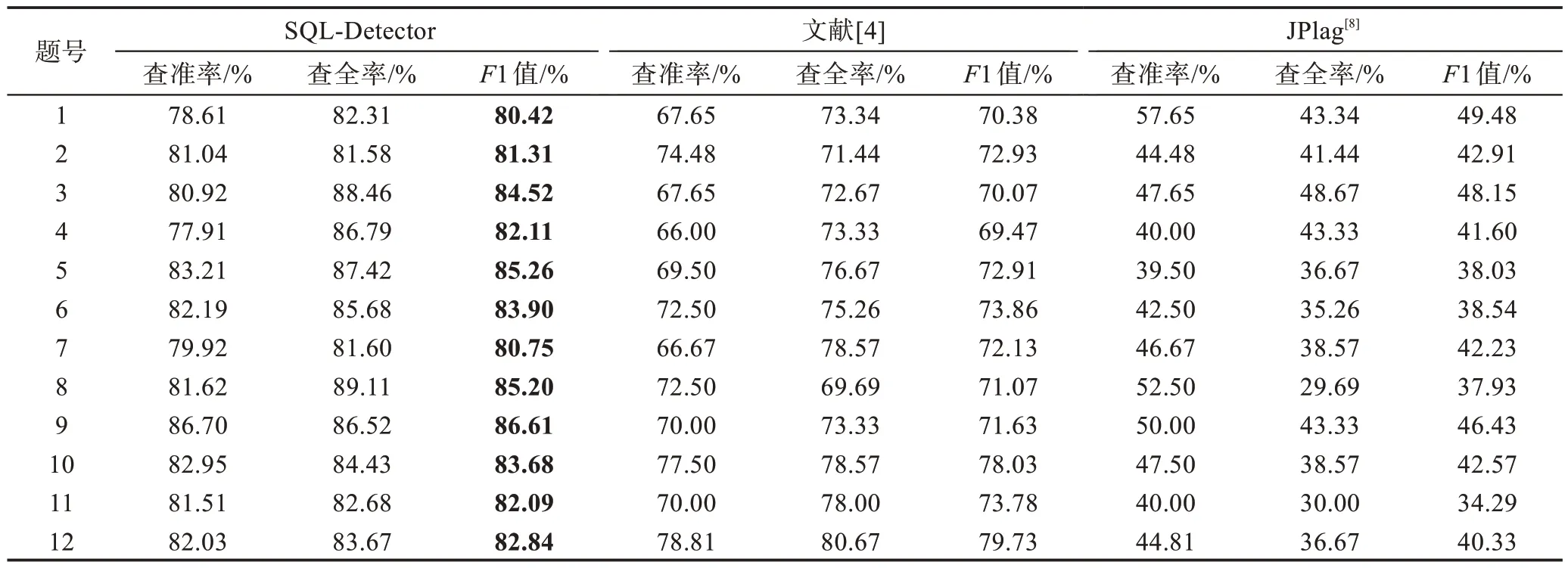
表5 SQL 习题抄袭检测精确度分析Table 5 Accuracy analysis of SQL plagiarism detection
5 结束语
面向SQL 习题的抄袭检测技术能够自动识别出学生提交的SQL 代码中的抄袭问题,从而帮助教师在数据库教学中更好地了解学生对SQL 的掌握情况,具有重要现实意义。然而,现有的SQL 习题抄袭检测技术存在局限性:一方面仅通过比较学生自身的编码特征变化来判定抄袭行为,忽略了同一道SQL 习题下学生所提交的SQL 代码在编码特征方面的相似性;另一方面所考虑的学生编码特征过于简单,没能从SQL 的语法、句法特性出发提取与利用更多的编码特征来提高SQL 习题抄袭检测的精确度。针对现有研究工作的不足,本文提出了一种基于编码特征的SQL 习题抄袭检测技术,命名为SQLDetector。该技术从SQL 的特性出发,提取出面向特定SQL 习题的学生习题编码特征和面向编码习惯的学生泛化编码特征。SQL-Detector 技术首先通过对某道SQL 习题下所有学生的习题编码特征进行聚类分析从而识别出抄袭群体。其次,通过比较抄袭群体中每名学生待检测SQL 代码的泛化编码特征和其历史泛化编码特征(即其历史画像)之间的相似性来判定抄袭行为中的抄袭者和被抄袭者。基于由多个教学班学生参与的教学实践中收集到的学生提交的SQL 代码进行实验评价与分析,结果表明SQLDetector 技术比相关最好的SQL 习题抄袭检测技术在抄袭检测精确度方面平均提高了14.0%。
未来将在数据库的教学实践中继续运用SQLDetector 技术帮助教师提高SQL 编程的教学质量,并不断收集和分析学生的抄袭样例,从而进一步优化SQL-Detector技术的抄袭检测流程。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
华人时刊(2022年1期)2022-04-26
保定学院学报(2022年2期)2022-04-07
动漫界·幼教365(大班)(2019年10期)2019-10-28
数学学习与研究(2018年15期)2018-11-12
新高考·高二数学(2016年7期)2017-01-23
股市动态分析(2016年17期)2016-10-20
太空探索(2016年6期)2016-07-10
股市动态分析(2015年16期)2015-09-10
环球时报(2009-11-25)2009-11-25
