
基于深度学习的代码表征及其应用综述
2022-09-15 10:27:34张祥平刘建勋
计算机与生活 2022年9期
张祥平,刘建勋+
1.湖南科技大学 服务计算与软件服务新技术湖南省重点实验室,湖南 湘潭 411201
2.湖南科技大学 计算机科学与工程学院,湖南 湘潭 411201
计算机软件是现代社会最具代表性的产物,它被应用在人们生活工作中的方方面面。在现代计算机软件发展过程中,数以百万计的开发者参与并贡献了大量高水平的软件代码。然而由于代码本身所具有的抽象性、复杂性与可变性,想要进行高效、快速的软件开发仍是一个艰巨任务。针对此问题,开发者们研发出许多软件开发辅助工具,这些工具旨在帮助开发者理解、编写以及维护代码,从而提高开发人员的工作效率。
传统的软件开发辅助工具通常是基于人工制定的代码分析任务构建的,因此此类工具在特定任务范围内能够起到很好的效果。但随着代码开源活动的兴起,全球开源项目呈指数级增长。开源贡献者在开源平台贡献了大量高质量的开源项目,这些项目中包含了丰富的程序信息,如源代码、代码注释、故障报告以及测试用例等。面对规模巨大、信息繁杂的代码数据,传统的代码分析方式难以获得令人满意的效果。Hindle 等人提出了代码的“自然性”假说,该假说认为程序语言与自然语言类似,包含了丰富的代码统计信息,这些信息可以用于构建功能更加丰富的软件开发辅助工具。代码“自然性”理论使人们意识到运用统计规律对代码信息进行分析是可行的,因此大量机器学习算法被运用到代码分析任务中,对代码进行多角度的信息挖掘,这极大地丰富了人们对于代码的认识。在此过程中,最基础的环节是如何将代码转换为合适的代码表征向量,以适应不同的机器学习任务。
传统的代码表征方法简单地将代码视为自然语言进行处理,使用自然语言处理领域中成熟的算法将代码转换为表征向量,并在其上应用机器学习算法完成代码分析。如使用TF-IDF(term frequencyinverse document frequency)算法将代码转换为与词频相关的代码向量表征,此类方法仅仅使用简单的词频统计信息,没有将代码中丰富的语义信息以及结构信息融入到代码向量中,因此所生成的代码向量质量较低。随着近几年深度学习取得的巨大成就,工业界与学术界对于在软件工程领域中探索和使用深度学习算法表现出了极大的热情。可针对不同的代码分析任务,使用不同的神经网络模型,生成高质量的代码表征向量。如使用循环神经网络能够将变长的代码序列转换为固定长度的代码向量,进行代码分类和代码克隆检测任务。使用序列到序列的神经网络模型进行代码自动生成任务,其中的编码器能够将代码编码为特征向量,之后使用解码器将其输出为代码序列。
在海量代码数据上使用深度学习模型进行训练、学习、归纳,自动地提取代码中人工难以提取的深层次特征。通过不断组合不同的神经网络模型,将低层网络中获得的低阶特征组合成更加抽象的高阶特征,进而发现数据所隐含的高维信息。将这些信息融入到代码表征向量中,能够有效降低代码特征提取部分对人工制定特征的依赖。与传统人工制定的代码特征提取方法不同,基于深度学习的代码特征提取方法无需依赖软件工程领域专家的背景知识,就能够从海量代码数据中自动地提取出适用于不同任务的隐含特征,进而避免了因为人类观察偏差所造成的失误。
本文对近几年基于深度学习的代码表征工作进行分析与总结,并对代码表征工作下一步的研究方向提出了一些看法。
1 背景知识
如何从大量的数据中学习到数据之间的内在规律并应用于数据分析任务,是当前机器学习的首要目标。作为机器学习方法的基础,一个高质量的数据表征方法能够极大地提高机器学习算法的性能。机器学习算法在数据表征的基础上对模型进行优化,进而拟合已有的数据分布,最终应用于不同的任务场景。现如今,由于计算机计算能力的提升,代码分析领域已从传统的人工制定特征提取方法转向对代码使用深度学习技术进行特征提取。与传统的使用人工制定的特征提取方法不同,后者对代码分析的效率要远高于人工分析。首先,基于深度学习的代码分析方法可以减少人工制定特征的时间,降低了对代码分析的成本。其次,基于深度学习的代码分析方法能够发现更多人工难以发现的高维特征,也能够从不同的视角获取代码之间联系。
基于深度学习技术的代码分析方法通常可以用图1 来表示其分析流程。图1 包含四部分,分别是:(1)代码处理;(2)代码表征;(3)任务实现;(4)结果验证。
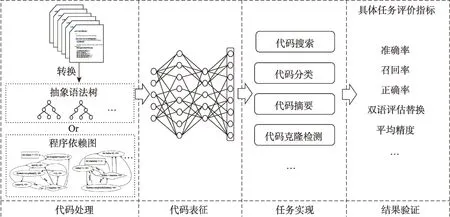
图1 基于深度学习的代码分析框架Fig.1 Framework of code analysis with deep learning
代码处理是从海量的代码库中收集代码,并根据任务的需要对代码进行简单的处理,如对代码进行漂亮打印(pretty-printing),将代码转换为抽象语法树(abstract syntax tree,AST)等。代码表征是指将代码转换为其对应的向量。这个过程中主要是根据代码不同的粒度,将代码转换为对应的向量表示。这一步骤对之后机器学习模型的效果有极大的影响。目前最常见的方法是使用Word2vec 算法将代码中词汇转换为对应的词向量,之后构建特定的神经网络模型对代码信息进行总结,得到代码的表征向量。将神经网络用在所获得的代码表征向量之上,对具体的代码分析任务做预测分析,这一过程需要根据具体任务设计不同的网络结构。最后,对模型所生成的结果进行验证,通过不同的评价指标,对具体任务结果进行验证。
而在代码分析任务中,最重要的是对代码进行合适的表征,使其能够包含任务所需的有效信息。
1.1 基于矩阵的表征模型
基于矩阵的表征模型通常基于一个词共现矩阵计算得到词的向量。词共现矩阵,形状为×,其中是词典大小,表示所使用的上下文信息长度。共现矩阵每一行F表示一个单词的分布表征,每一列F表示上下文信息。在文本处理中,词典大小数量通常十分巨大。如图2,要在内存中维护一个规模庞大的共现矩阵将会消耗大量的内存资源。因此有许多工作研究如何构建合适的词共现矩阵以便减少计算资源的消耗。这类工作的目标可以用以下语言进行描述:使用一个映射函数,将词共现矩阵映射为,即=(),的形状为×,使得≪。

图2 基于矩阵的分布表征Fig.2 Matrix-based distributional representation
目前已有一些工作关注于对共现矩阵的降维。如Sahlgren通过控制滑动窗口所滑动的方向、滑动窗口的大小来选取目标词不同范围的上下文信息,构造一个维度较小的共现矩阵,进而减少计算资源的使用。这个方法从共现矩阵的行(词汇个数)出发对共现矩阵进行降维。还有一些方法从共现矩阵的列(上下文信息)出发,如常见的分布表征方法,隐含语义分析模型(latent semantic analysis,LSA)、隐含狄利克雷分布模型(latent Dirichlet allocation,LDA)。比如LDA 模型,在构建共现矩阵的列时,所采用的是文档上下文信息而不是词信息,因而可以获得更高层次的语义信息。但是,将这些方法应用于代码表征任务中对所使用的代码语料库质量要求较高。如果所使用的代码库质量不高,如出现数据稀疏,包含较多噪声数据,使用上述方法难以获得高质量的代码表征结果。现有的一些方法研究如何在有限的内存资源中维护规模巨大的共现矩阵,如Sojka 等人提出一种增量构建方法,使得在超过2.7 亿个词的语料库上也可以进行LSA 和LDA 主题建模。
1.2 基于神经网络的表征模型
基于神经网络的表征模型能够将不同类型的数据映射到连续、低维的向量空间中。由于其生成的向量是将原始数据的特征分布式表示在向量的各个维度上,其所生成的表征向量也可以称为是分布式表征。在自然语言处理领域中对文本的表征通常是集中在单词、句子和段落层面上。文本的分布式表征极大地降低了表征向量维度,如使用独热表征(one-hot)需要()个参数才能区分()个输入空间(表示文本数据集中不同词汇的数量),而如果采用分布式表征,同样使用()个参数却能够区分(2)个输入空间。并且分布式表征向量包含文本的语义信息,可以通过计算两个文本的表征向量之间的余弦距离来获得两个文本之间的相似度。最常见的分布式表征方法有Word2vec 算法。Word2vec通过固定大小的滑动窗口来获得中心词的局部上下文信息。Word2vec 算法包含两种训练框架Skipgram 和CBOW,其对应的模型结构图如图3 所示。Skip-gram 框架根据所给中心词来预测其周围的词。因此其优化的目标函数为:
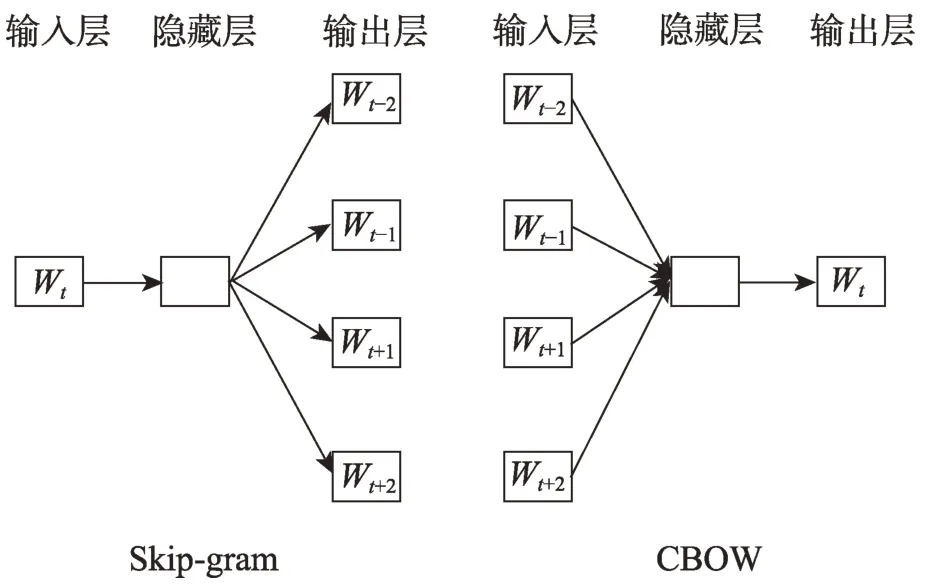
图3 Word2vec的两种训练框架Fig.3 Two training frameworks of Word2vec algorithm
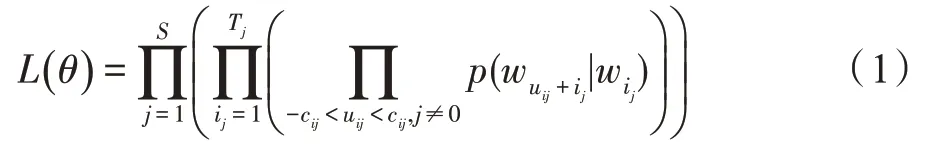
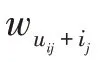
而CBOW 框架是根据周围的词去预测中心词,因此CBOW 框架的目标函数为:

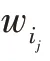
2 代码的表征方法
现有的代码分析工作通常是从以下两个角度对代码进行分析:(1)代码的静态分析;(2)代码的动态分析。其中代码的静态分析指基于代码的静态属性对代码进行特征提取,如代码的符号序列信息、API 调用序列信息、代码对应的抽象语法树以及控制流图中存在的结构信息。而代码的动态分析关注于代码运行过程中产生的中间结果,基于中间结果对代码任务进行分析。本文所研究的内容是静态情况下代码信息的抽取与表征,因此本章内容将从不同的代码静态信息出发,分析深度学习技术在不同代码分析任务中所起到的作用。而对于代码的动态分析方法,本文不作详述。
2.1 基于符号序列的代码表征
在基于符号序列的代码表征方法中,最基础的步骤是根据语法规则将代码中的词汇单元(token)划分出来。在这个过程中需要用到词法分析器,词法分析器能够按照预定的语法规则将代码中的字符串分割为一个个词汇单元,这些词汇单元通常包含关键字、数字、标识符等。在此过程中,代码中的空白符也会被移除。将代码表示为词汇单元序列之后,利用深度学习技术对其进行建模,学习代码序列中所包含的有效信息,如功能语义信息、语法结构信息等,最后生成具有丰富代码信息的表征向量,应用于不同的代码分析任务。
Harer 等人在C/C++的词汇单元上使用Word2-vec 算法用于软件漏洞的预测。其中词汇单元的表征向量用于初始化TextCNN 模型进而用于代码分类。White 等人也使用Word2vec 模型生成Java 词汇单元的表征向量用于自动代码修复。Chen等人使用Word2vec 生成Java 词汇单元表征向量用于在自动程序修复任务中找到正确的部分,该方法通过计算不同代码表征向量之间的余弦相似度来找到相似的代码片段。Henkel 等人从C 语言项目中使用Word2vec 生成抽象符号轨迹表征向量。他们在符号执行过程中收集轨迹信息,然后对轨迹中的符号名称进行重命名以降低词表大小。Nguyen 等人研究了Java 和C#中API 的表征向量,并用它发现了两种语言之间相似的API 用法。他们使用Word2vec 生成API 元素嵌入,并且基于已知的API 映射,该模型可以在两种语言中找到使用相似的簇类。将源代码翻译为API 序列,并使用Word2vec 从抽象的API 序列中学习了API 嵌入。Pradel等人使用代码片段嵌入来识别潜在的错误代码。为了生成训练数据,作者从代码库中收集代码示例,并应用简单的代码转换来插入一个人工构造的错误,之后生成了正反码示例的嵌入,并用于分类器的训练过程。以上方法通过使用Word2vec 算法,预先将代码中的词汇单元转换为实数向量,便于之后的深度学习模型进行特征提取。然而,受Word2vec 算法的限制,所生成的词汇单元向量仅仅保留了基本的词共现信息,对于代码中存在的逻辑信息,如变量定义与使用的先后顺序,循环语句中的逻辑判断信息都无法获取。因此在代码表征的过程中,Word2vec 算法通常只在最初的词汇单元转向量阶段使用,对于代码中包含的词法和语义信息,仍需要学习能力更强的神经网络模型才能进行完整的信息提取。
高质量软件项目中,通常每份代码都会有其对应的代码注释。而实际情况下,编写代码注释同样会消耗软件开发者大量的开发时间。因此目前也有很多学者研究如何自动地生成代码对应的注释以减少开发者的工作内容。目前有许多工作基于Seq2seq框架构建模型完成该任务。Seq2seq 模型是一种能够根据给定的词汇序列,通过特定的方法生成另一种词汇序列的方法,比如在机器翻译中,使用Seq2seq模型可以将中文文本序列转换为其对应的英文文本序列。而在代码注释生成领域中,Seq2seq 模型使用编码器(encoder)对代码中的词汇序列进行编码,得到上下文向量的中间表示,之后使用解码器(decoder)对上下文向量进行解码,从而生成这些代码序列所对应的功能注释。其中编码器与解码器通常是使用序列神经网络作为基本的序列特征提取模型。例如,Iyer 等人提出了CODE-NN 模型,该模型使用附加注意力机制的LSTM 序列神经网络模型对代码词汇序列进行编码。在编码过程中注意力机制会对代码中的每一个词汇单元都附加上注意力权重,最后获得代码对应的向量表征。如要进行代码注释生成工作,只需直接对上下文中间向量使用解码器即可生成对应的代码注释。该方法在C#和SQL所构成的代码数据集上进行代码注释生成,在METEOR 和BLEU 两个指标上取得了当时最优的结果。考虑到注意力机制对模型输入输出长度不同的数据有较好的建模效果,Allamanis 等人使用基于注意力机制CNN 对代码进行建模,该模型将函数表示为词汇单元序列,在词汇单元序列上进行卷积操作,考虑到注意力机制能够获取代码序列中不同词汇的重要程度,在模型中使用了注意力机制。以上有关于代码注释生成的工作不同于传统的基于人工定制规则的方法,基于神经网络的代码生成模型能够挖掘更深层次的代码信息,获得更加丰富的代码表征向量用于下一步的代码分析任务。但是这些方法也存在明显的缺点,因为代码具有较强的逻辑结构关系,如不同API 之间的调用关系、语句的执行顺序等。如果仅仅考虑代码中文本信息进行模型的训练,那么代码中的结构信息大部分都会丢失。
代码补全任务是根据已有代码词汇序列预测下一个词汇或者下一段代码序列。循环神经网络模型能够较好地对序列数据进行建模,因为其能够在任意长度的上下文窗口中存储、学习和表达相关信息,并且在时间序列上有延拓。现在很多工作使用循环神经网络对代码序列这类长文本数据进行特征提取。例如White 等人使用RNN(recurrent neural network)神经网络对代码中的词汇单元序列进行建模。作者在Github 网站上收集了16 221 个Java 项目进行模型的训练。最终在Java 代码的代码补全任务上取得了72.2%的准确率,这一结果远远高出了当时的元语法模型所取得的效果。Li等人考虑了在代码补全任务上超出词表问题(out of vocabulary,OoV),在传统的RNN 神经网络的基础上增加了注意力机制,结合指针网络能够复制已出现过的上下文信息的特性,实现了超出词表外代码片段的补全任务。在两个基准数据集上的实验证明该方法中注意力机制和指针混合网络在代码补全任务中的有效性。Bhoopchand 等人针对代码中不同标识符之间存在的长依赖问题,提出了基于指针网络的程序语言模型。该方法采用RNN 的变种模型LSTM 神经网络作为构建神经语言模型的基础模型。LSTM 模型作为RNN 模型的一个变种模型,能够在一定程度上缓解长文本中词汇之间的依赖问题(如,一个变量在代码开头就被定义,但是直到程序末尾时才被使用)。该方法通过使用指针网络在之前的输入数据中选择已出现过的标识符作为输出的备选结果,最后通过一个选择器综合考虑语言模型和指针网络两者的结果,共同预测输出词语的概率分布。该工作从Github网站上收集了4 100 万行Python 代码,在该数据集上进行代码补全实验,实验结果显示LSTM 模型的补全预测结果能够提供距离当前补全位置较远的上文中所出现过的标识符,能够取得更高的补全准确率。与传统的基于统计规则的模型相比,这类基于词汇序列的神经网络模型的效果明显优于前者。但这些模型也存在许多不足,若是将代码简单地转换为词汇序列,那么代码中不同语句之间的顺序信息、不同API 的调用信息等代码所特有的结构信息就会丢失,这势必会影响代码分析任务的性能。同时,受制于所使用基本模型本身的缺陷,如要使用神经网络对文本信息进行处理,必须要先确定最大文本长度以适应模型的输入,这同样会增加代码信息的提取难度。
代码搜索指根据用户对代码功能的描述语句在代码库中检索符合功能的代码。传统的代码搜索大多采用的是信息检索领域中的检索技术,通过计算查询语句与代码之间的相似程度进行搜索。最简单的方法就是关键词匹配。随着深度学习技术在各个领域所取得的突破性进展,也有大量学者将其应用于代码搜索领域。运用深度神经网络将代码与自然语言查询语句转换为同一个语义空间中的向量,通过对向量之间的相似度计算,能够有效地挖掘出代码与查询语句之间更高层的联系。深度学习在代码搜索上的应用通常是在代码的词汇序列上使用RNN神经网络模型进行建模,将词汇序列转换为序列向量。同时使用RNN 神经网络模型对自然语言查询语句进行建模,将其转换为查询语句向量。在检索时,在同一向量空间中搜索与查询语句向量相似的代码向量作为检索结果。在此过程中,最重要的研究内容就是如何将序列表征向量与自然语言查询语句的向量映射到同一代码语义向量空间中。Gu 等人首先将深度学习技术应用在代码搜索领域,对给定的自然语言查询语句生成其所描述的API 用法序列。该方法将问题转换为自然语言中的机器翻译问题,使用RNN 神经网络对自然语言查询语句进行向量表征。同时使用不同模型对代码的不同粒度的信息进行表征建模,使用RNN 模型对代码的词汇单元序列进行表征,使用RNN 模型对代码的方法名进行表征,对代码中的API 序列使用MLP 模型进行表征。为了获得三个向量中最显著的特征,对这三个向量使用了最大池化操作,最后将这三个向量进行拼接,作为代码最终的向量表示。该工作使用了三元组损失函数(triplet loss),考虑了查询语句、与查询语句对应的代码(正例)、与查询语句不对应的代码(负例)三者之间的关系,通过最大化正例之间相似度以及最小化负例之间的相似度来训练模型,使得模型能够具备将不同源信息映射到同一语义向量空间中的能力。作者在Github 网站上收集了1 820 万条带有注释的Java 方法代码片段进行实验。实验结果表明,该方法与其他传统的基于文本匹配的方法相比,搜索的准确度上取得了显著的提升。Shuai 等人考虑到自然语言查询与代码之间的语义关系,提出了一种共同注意力表征学习模型,用于同时学习代码与自然语言查询语句之间的关联表征。该方法构建了一个代码和查询序列的相关矩阵,通过按行或者按列的最大池化操作获得它们之间的语义关系。同样的,在文献[16]的数据集上进行实验,实验结果在平均排名倒数(mean reciprocal rank,MRR)指标上得到了26.72%的提升。
2.2 基于API调用序列的代码表征
基于应用程序接口(application programming interface,API)序列的代码表征方法是将代码中的API 调用序列作为研究对象。当开发者对所需要使用的开发框架或库不熟悉时,需要学习具体框架的API 使用方法,尤其是当使用规模庞大的框架如JDK(Java development kit),成千上万个API 大大增加了软件开发难度。如果能够通过输入自然语言查询语句获得API 的使用方法,将能极大地提高软件开发效率。现有的与API 调用序列有关的工作将API 序列作为研究对象。对程序中包含的API 序列进行建模,获得API 序列的表征向量,之后通过对比自然语言和代码API序列向量的相似度来完成API序列检索。
Gu 等人提出了基于深度学习的API 检索方法,该方法根据自然语言查询语句来检索与其匹配的API 序列。作者将API 检索问题转换为机器翻译问题,通过使用Seq2seq 框架构建一个自然语言到API 序列的模型。首先将自然查询语句视为源语言,将自然语言查询语句中的每一个单词转换为词向量,之后使用RNN 模型构建一个编码器。该编码器计算每个单词的隐藏状态,并且根据前一个单词的隐藏状态去预测下一个可能的输出单词,最后得到上下文向量。同时,也使用RNN 模型构建一个解码器,将编码器所生成的上下文信息作为该解码器的初始隐藏状态,每个时间步都会生成一个单词作为API 调用序列的内容。在模型训练中使用了束搜索(beam search)算法,以最小的代价来搜索最优的API序列。该方法在其处理好的751 万对数据上进行实验,利用BLEU(bilingual evaluation understudy)来评估生成的API 序列的质量,结果表明该方法较其他方法取得了40%左右的提升。Lu 等人提出了一种用于恶意软件行为分析的深度学习和机器学习组合模型。其中一部分分析了API 调用序列之间的依赖关系,另一部分采用基于残差的双向LSTM 神经网络获取API 序列中的冗余信息。这种组合方式显著提高了恶意软件检测精度。
Saifullah提出了一种使用带注意力机制双向LSTM 的模型,将代码的词汇信息、句法信息以及上下文语义信息相融合,用于生成API 调用序列。在整个过程中,作者首先对原始代码进行预处理,包括代码中方法名的抽取、变量名称规范化、参数规范化。在处理好的数据上使用基于注意力机制的双向LSTM 编码器进行编码,生成上下文信息向量,之后在该向量上使用解码器进行解码,同时采用了束搜索策略,生成最优的API调用序列。
在代码注释生成任务中,Hu 等人从代码中抽取出API 序列以及摘要,使用Seq2seq 模型对两者进行预训练。将API 序列作为Seq2seq 模型的输入,而代码摘要作为Seq2seq 模型的训练目标,这一步骤使得生成的API 序列表征与摘要表征映射到相近的向量空间。同时,该方法也采用了与CODE-NN 模型类似的结构对代码词汇单元序列和摘要进行训练,将这些知识输入到网络模型中辅助代码注释的生成过程。该工作的创新点在于将预先构建的Seq2seq 模型对API 序列进行预训练,并且将该预训练模型中的编码器部分作为后面模型的编码器,通过将其拼接到代码token 序列和摘要训练模型的解码器上生成代码摘要。该工作取得了当时最优的结果。
2.3 基于抽象语法树的代码表征
抽象语法树(AST)是源代码的抽象语法结构的树状表示,可以有效地表示程序的语法及其结构。抽象语法树并没有包含代码中所有的真实语法信息,它忽略了一些不重要的细节,只保留了必要的节点信息。树中的每个节点都对应源代码中的一种结构。在抽象语法树中,非终结符对应于树的中间节点(如Assign、If、For 等),与代码片段的具体类型相对应,与程序结构紧密相关;而终结符则位于树的叶子节点(如字符串、变量名、方法名等),与程序语义密切相关。抽象语法树可以被用于构建代码优化插件,如对代码进行语法检查,对代码进行格式化,对代码编写风格进行检查等。不同的编程语言有不同的抽象语法树构建工具,表1 列出的是目前流行抽象语法树构建工具。

表1 不同编程语言的抽象语法树生成工具Table 1 Tools of AST generation for different programming languages
利用深度神经网络对抽象语法树进行建模得到其向量表示,根据该特征向量完成代码模式检测任务。在克隆检测任务中,White 等人提出了基于循环神经网络的代码克隆检测方法,该方法将代码分为词汇以及句法两个层次。对于词汇级别的信息,作者在代码的词汇单元序列上使用RNN 神经网络进行建模。而对于代码的句法级别的信息,作者首先将代码转换为其对应的抽象语法树结构,之后将抽象语法树转换为其对应的满二叉树,最后作者将满二叉树转换为Olive Trees,并在其上使用另一个RNN 神经网络进行建模。该文将这两个特征相结合作为整个程序的特征向量,根据该向量进行代码克隆检测任务。Mou 等人提出了一种基于树的卷积神经网络模型(tree-based convolutional neural network,TBCNN)。该模型考虑到不同代码对应的抽象语法树是不同的这一现象,采用了“连续二叉树”的概念,直接在代码所对应的抽象语法树上进行卷积操作。在卷积操作之后获得了不同数目的AST 结构特征向量,由于数目不同不能直接作为神经网络的输入,因此该方法还采用“动态池化”技术,最终将数目不同的特征向量转换为了一个向量。TBCNN 是一个通用的代码表征生成模型,所生成的向量能够包含代码片段中特有的代码模式,因而可以应用于不同的代码分析任务中。如文中使用所生成的代码表征向量用于代码功能分类任务,在POJ104数据集上(由C 语言编写的104 个任务的代码数据集),分类任务的准确率能够达到94%。Wei等人提出了CDLH(clone detection with learning to Hash)方法,该方法在抽象语法树的基础上使用LSTM 模型,通过共享权重的方式学习两个代码片段之间的表征向量,这种模型使其能够检测出第四类代码克隆类型。Chen等人同样采用了基于树的卷积神经网络,该方法考虑到已有的方法仅仅使用抽象语法树会造成代码语义信息的丢失,因此该方法将API 的调用信息作为补充信息合并到抽象语法树中,之后进行代码表征。在POJ104 和BCB数据集上进行实验,在F1 指标上获得了0.39 和0.12 的提升。Zhang 等人提出了一种基于抽象语法树的神经网络代码表征方法,该方法将代码转换为其对应的抽象语法树,不同于传统的基于抽象语法树的代码表征方法,该方法对抽象语法树进行语句级别上的切割,将完整的抽象语法树分割为多个语句树。针对每个语句树,该方法设计了语句编码器用于将语句树转换为对应的语句表征向量,通过使用双向GRU(gated recurrent unit)神经网络对语句向量进行建模,对双向GRU 层输出的隐含状态向量进行最大池化(max-pooling)操作,以获得最显著的代码特征。其中,将抽象语法树分割为多个语句树变相地缓解了由于抽象语法树规模过大所带来的长依赖问题。该方法所生成的代码表征向量被应用于代码克隆检测任务中,在BCB 数据集和POJ104 数据集上取得了当时最好的检测结果。Wang 等人同样考虑了仅仅使用代码的抽象语法树进行代码表征建模实际上仍然有代码结构上的缺失这一问题,构建了代码抽象语法树的图形表示,通过将抽象语法树各个叶子结点相连构建出适合图神经网络处理的数据。上述方法均在抽象语法树上进行代码的表征学习,力图充分提取代码中的结构信息与语法信息。但是为了获得代码的结构信息,这些方法首先都是将代码转换为对应的抽象语法树,才能够将其作为深度学习模型的输入,同时由于深度学习模型本身的局限性,如循环神经网络仅能处理序列数据,还需要将树形数据转换为序列数据,而在这个过程中必定存在结构信息的丢失。
Hu 等人提出了基于AST 的代码注释生成模型,该方法同样是将代码转换为其对应的抽象语法树,同时为了能够将抽象语法树作为神经网络模型的输入,作者还提出了一种基于抽象语法树的结构遍历方法,进而将抽象语法树转换为节点序列。并且作者也考虑了超出词表问题,当抽象语法树的节点类型和值不在预先定义的词表中时,使用节点的类型来替换该词。最后,使用基于注意力机制的Seq2seq 框架完成注释生成任务。Alon 等人利用抽象语法树路径(AST path)来表示程序,通过AST 路径来表示程序的结构和语法。该方法首先将代码转换为对应的抽象语法树,从抽象语法树中提取不同的路径信息,将路径上所有结点的值构成的元组称为路径上下文信息(path-context)。将每个路径上下文信息中的结点进行嵌入得到节点向量,之后将这些向量拼接成一个向量来代表这个路径上下文信息。同时作者还考虑使用注意力机制关注不同权重的路径信息。该方法在变量名预测、方法名预测以及表达式类型预测任务中都取得了目前最好的结果。之后Alon 等人又对该模型进行了改进,使用双向LSTM 对抽象语法树的路径信息进行建模,将该模型应用于代码摘要任务中。Alon 等人还在代码补全任务上同样使用基于抽象语法树路径信息的模型,该模型通过估计抽象语法树上不同节点的条件概率来预测下一个节点的信息,进而完成代码补全任务。
2.4 基于图的代码表征
图的结构可以对程序中的数据流动关系进行建模,例如控制流图以及数据依赖图。图中节点表示程序中的元素,例如程序中的token 或变量、程序中指针(pointer)的内存地址,图中的边表示节点之间的依赖关系或数据流动情况。代码的控制流图反映了代码中语句执行时的跳转流向,而代码的数据依赖图反映了代码中数据的流向。通过将程序表示为图的形式使得模型能够更好地理解代码中不同部分之间的依赖关系。
随着深度学习的发展,基于深度神经网络的图模型被用于代码理解相关任务中,包括代码风格修正、代码修复、代码注释生成等。Allamanis 等人考虑到代码中的长依赖问题,如在代码中变量的定义位置与使用位置之间的距离问题,提出了基于图的代码表征方法,力图学习代码中的语法以及语义结构。该工作首先将代码转换为对应的抽象语法树,之后通过不同的连接规则连接抽象语法树各个节点,获得了不同节点之间的关联关系,这其中就包含了变量之间的依赖关系。最后将构建好的代码图数据作为输入,输入到图神经网络中进行表征学习。该方法在程序变量命名以及变量名误用检测任务中取得了不错的效果。
Lu 等人从代码中提取数据流与函数调用信息,将其融合到抽象语法树中,从而将代码构建为一个包含丰富信息的图结构表示。在传统的GGNN(gated graph sequence neural networks)模型上引入了注意力机制,用于获得图中每个节点的重要程度,进而获得更具有区分度的代码表征向量。所生成的代码表征向量用于代码功能分类任务中,实验结果表明,该方法能够有效地应用于代码分类任务中。
Brockschmidt 等人同样在代码的抽象语法树上增加相应的边以构建代码图,代码图的构建方法与文献[50]类似。之后采用图神经网络对程序的结构和数据流进行建模完成程序自动生成任务。Ben-Nun 等人提出了一种与语言以及平台无关的代码表征方法inst2vec。该方法首先使用编译器对代码进行编译,得到代码的中间表示。但由于该中间表示并没有包含代码之中的数据流信息以及控制流信息,因此该方法将数据流和控制流也融合到该中间表示中,进而构建了代码上下文流图。最后在所构建的图上使用循环神经网络进行建模,获得代码的表征向量。该向量在程序分类实验中准确率取得了当时最好的效果。这些基于图的方法本质上是通过对代码的抽象语法树的改造,显式地将不同节点之间的联系以图的形式表现出来,这一过程能够增加一些人工归纳的规则,因此对一些代码分析任务能够取得较好的效果。
3 代码表征的相关应用
对代码表征的介绍离不开具体的应用场景,对代码表征的质量进行评价通常也是基于具体的代码分析任务。因此,本章将对主要的几个代码分析任务进行简要介绍,并详细介绍代码表征在这些任务中的具体工作。
3.1 代码克隆检测
在软件开发过程中,对代码的修改、复用、变换以及重构会使得软件系统中出现大量的相似甚至重复的代码片段,这个代码复用的过程就被称为代码克隆。已有研究表明,代码克隆这一现象在软件系统中是广泛存在的。如在FreeBSD 5.2.1 和Linux 2.6.6 系统中,克隆的代码片段分别占比20.4%和22.3%。在软件开发过程中,通过复制和粘贴现有的代码虽然可以在一定程度上提高软件开发的速度,但这些克隆的代码同样也对软件系统的维护带来了巨大的挑战。当被克隆的代码片段存在缺陷时,该缺陷将会随着其克隆活动的过程传播到软件系统中,将缺陷引入了软件系统中,会对软件系统的稳定性造成破坏,进而提高软件系统的维护成本。而代码克隆检测技术能够帮助软件开发者发现软件系统中相似的代码片段,提升软件系统的稳定性,降低软件系统维护人员的工作量,避免引入与克隆代码相关的缺陷。
目前已有的代码克隆检测方法大多遵循以下思路:(1)首先对代码片段进行预处理;(2)对处理好的代码片段进行信息抽取,将其转换为中间表征;(3)根据表征的方式不同计算不同代码片段之间的相似度,完成克隆检测任务。在这些步骤中,最重要的问题是如何将代码转换为合适的表征,使该表征尽可能多地保留原始代码中所包含的信息,以便进行代码相似度计算。
本节根据上文对代码表征方法的分类介绍,从代码表征的角度,将代码克隆检测方法分为两类:(1)基于代码序列的克隆检测;(2)基于代码结构的克隆检测。根据代码克隆相似程度的不同,Bellon 等人将代码克隆分为四种类型,即完全相同的代码(Type-1)、重命名的代码(Type-2)、几乎相同的代码(Type-3)和语义相似的代码(Type-4),从Type-1 到Type-4,代码克隆的相似程度逐渐降低,检测的难度也逐渐增加。在普通情况下,仅对代码的文本序列信息进行检测,就能够有效地检测出大部分Type-1、Type-2 的代码克隆以及少部分Type-3 代码克隆,而对于Type-4 类型的代码克隆,则需要基于代码结构的克隆检测方法才能够检测到。以下将对不同的克隆检测方法进行介绍。
基于代码序列的代码克隆检测,将代码视为自然语言文本进行处理。通常使用如后缀树匹配、最长相同序列匹配等匹配算法进行相似度计算。CCFinder、CP-Miner将原始的代码通过移除空格、注释,进行参数转换等预处理步骤之后,直接在其上进行相似度计算。Duploc将代码视为基本的字符串,通过检测两份代码最长的相同子序列进行相似度比较,从而判断代码的克隆程度。SDD是eclipse开发工具中的一个插件,该方法将代码视为纯文本,通过使用倒排索引和N 近邻算法减少克隆检测时间的开销。这种检测方法的优点在于其检测速度快,计算开销小,不依赖于特定的编程语言,甚至对于无法运行的不完整代码也能够进行克隆检测。但其缺点也很明显,由于这类方法仅仅从文本序列的角度出发,没有考虑代码本身所包含的丰富的语法、语义信息,因此对于Type-3、Type-4 的代码克隆检测能力不足。还有一些基于代码文本序列的克隆检测方法,如CDSW、XIAO、CCAlingner、srcClone将源代码转换为其对应的哈希值,之后直接使用哈希比较算法计算代码之间的相似程度。与单纯地将代码视为文本的克隆检测方法相比,由于这类方法使用了更符合编译原理的符号序列进行相似度计算,这些方法的克隆检测效果有一定程度的提升。但是,这种检测方法没有考虑代码中所包含的结构信息,因此检测不到代码的结构信息层面上的变化。
基于代码结构的克隆检测方法通常是根据语法规则,将代码转换为对应的抽象语法树,进而进行检测分析。抽象语法树是源代码编译过程中产生的一个中间表示,将源代码中所包含的语法信息以树的形式表现出来,之后采用基于树的相似度匹配算法计算代码之间的相似度。目前,许多工作都尝试从抽象语法树中提取更加丰富有效的代码特征,将抽象语法树转换为不同的表征向量,在这些代码表征向量上进行代码克隆检测。由代码的抽象语法树所生成的代码表征向量,不但包含了代码中的token 信息,同时也包含了代码的结构信息、语法规则,因而这类方法具有对Type-3、Type-4 克隆类型的检测能力。Zhang 等人将代码转换为其对应的抽象语法树,并对抽象语法树进一步划分,得到代码的语句树。通过在语句树级别上的建模,获得了代码表征向量。该表征向量被用于代码克隆检测,检测结果远超于仅使用文本序列的检测方法。但是基于树的方法通常需要遍历树,其计算开销会大于基于代码序列的克隆检测方法。
表2 展示的是近五年来基于深度学习的一些代码克隆检测工作。从中可以看出,使用深度学习技术能够有效地进行Type-3、Type-4 类型的代码克隆检测。这些方法使用不同的神经网络结构进行代码的特征提取。在此表中所使用的深度学习技术中序列神经网络占比较大,这说明主流的研究方向仍然是将代码作为序列进行处理。但是从此表中也可以看出,目前代码克隆检测模型也仅仅是关注于少部分语言,如Java 和C。造成这一现象的主要原因是当前代码克隆检测领域仅有少量的标准数据集。
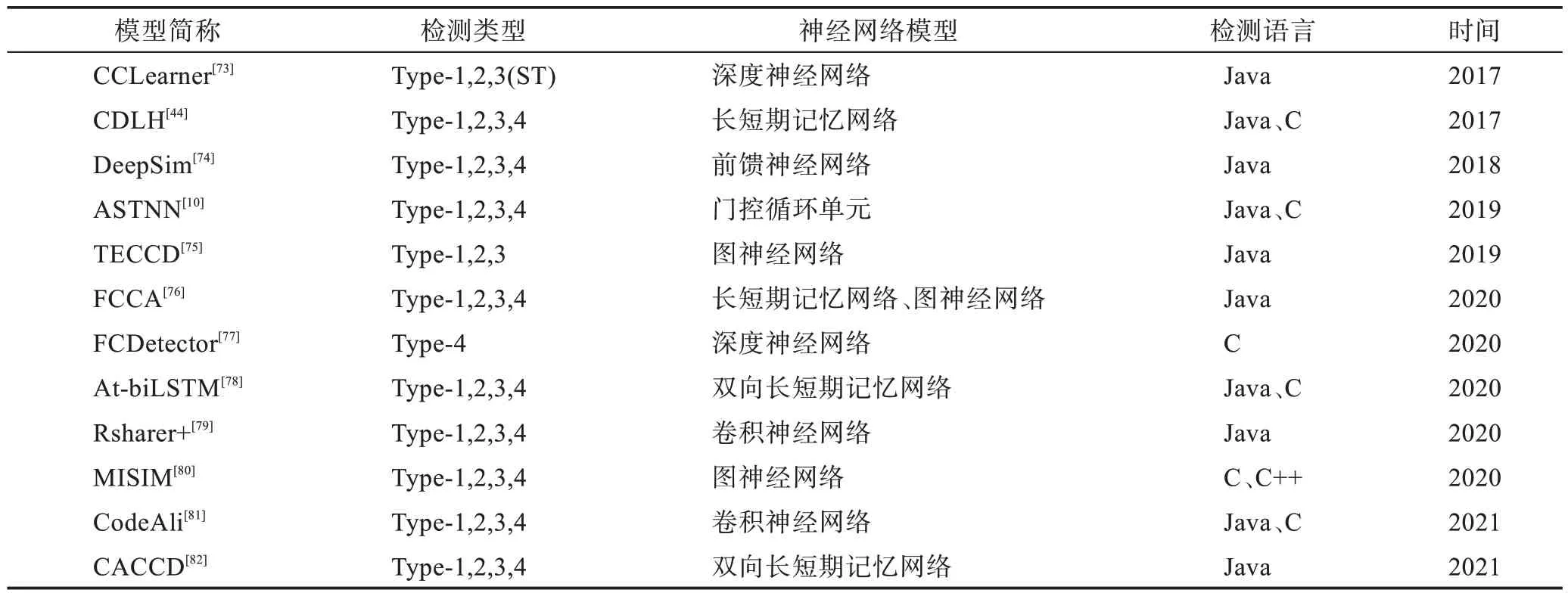
表2 基于深度学习的代码克隆检测方法Table 2 Deep learning-based code clone detection methods
3.2 代码搜索
随着近几年开源软件和开源社区的发展,越来越多企业和个人在开源社区贡献出软件代码。Singer 等人的一项研究发现,软件开发人员在软件开发过程中最频繁的活动之一就是进行代码搜索。当软件开发者在实现某个特定功能的代码需要调用已有的应用程序接口(API)时,如果开发者对其的使用方式不太了解,就需要进行代码搜索。通过在搜索引擎中键入API 的名称等信息,可以搜索到该API 的具体使用方式。又或者,软件开发者甚至都不清楚哪些API 能够实现他所需要完成的功能,也可以通过在搜索引擎中键入功能描述来搜索到可以满足开发需求的API,甚至完整的代码。通常情况下,软件开发者会使用搜索引擎(如百度、谷歌)进行代码的搜索。但这些通用的搜索引擎不是专门针对编程任务所开发的搜索引擎,在搜索过程中不会考虑代码的语义特征,当所需要搜索的代码功能比较复杂时,搜索效果较差。因此,当通用的搜索引擎不能满足开发者的需求时,开发者会在一些专业的代码问答网站(https://sourceforge.net/、https://stackoverflow.com/)或者开源社区(https://www.github.com/)上进行搜索。然而这些网站所返回的搜索结果通常与所想要解决的问题相关度较低,尽管代码片段中包含了查询语句中相关的词汇,但是所返回的结果仍然无法完成开发者的开发需求。
现有的代码搜索技术,通常是将源代码视为纯文本,直接利用信息检索领域中的检索模型去查找并匹配相关的代码片段。这些方法主要是通过比较自然语言查询语句和源代码之间的文本相似性进行搜索。然而因为其仅仅考虑文本相似性,而没有考虑语义或者功能相似性,通常搜索返回的结果不尽人意。随着计算机技术的快速发展,基于数据驱动的机器学习方法得到了广泛的关注。有研究对源代码进行统计分析,发现源代码与自然语言有着相似的统计学规律。因此,对源代码的分析开始借鉴自然语言处理领域的相关方法,如通过计算代码之间的文本表征向量来计算代码之间的相似度,对代码进行摘要提取、代码的跨语言翻译等。这种研究方式极大地推动了代码数据分析和挖掘的研究进程。
代码搜索和自然语言处理领域相结合,通常的做法是将自然语言查询语句和源代码转换为同一个向量空间的连续向量,并计算两者的相似程度。这类方式依赖于连续向量所能蕴含的上下文隐含语义信息量的多少。Gu 等人提出了CODEnn 模型,该模型没有使用传统的文本相似度匹配算法。它将自然语言描述语句和源代码片段共同映射到同一个高维度的向量空间中,使得描述语句和代码具有相似的向量表示。之后,通过计算自然语言查询语句向量和代码向量之间的余弦相似度来返回合适的代码片段。Sachdev等人提出了NCS(neural code search),该方法的主要思想是使用连续向量来获得代码的语义信息。在方法级别上将代码划分为不同的代码片段,并对每个代码片段生成连续的向量嵌入。同时,将自然语言查询也映射到相同的向量空间中,通过计算向量之间的距离来衡量代码之间的相关程度,以供查询。Lv 等人提出了CodeHow,该模型是一个包含扩展布尔模型和API 匹配的代码搜索工具。首先从代码的在线文档中收集每个API 的描述,获得API 的描述之后,对其进行编码并计算文本描述与查询之间的相似性,以及API 名称与查询之间的相似性。最后组合每个API 对之间的相似性,返回与查询匹配的可能相关API。Fang 等人与文献[16]采取了相似的做法,将代码拆分成方法名、API、词汇单元三部分,将这三部分转换为对应的向量,并在其上使用自注意力机制,获得各个部分内部元素的注意力分数附加在表征向量中,同时将代码的描述文本也用同样的方式转换为向量,最后使用余弦相似度来衡量代码与代码描述语言之间的相似度,返回代码搜索结果。
有许多研究也关注于代码本身所具有的特殊性,通过将代码转换为对应的抽象语法树,或者程序依赖图,使用深度学习技术获得这些特殊结构所包含的代码信息。与基于文本的嵌入技术类似,这类方法通常将项目中的代码转换为代码图,之后使用图嵌入技术用于表征代码图中节点信息。之后根据代码图解析查询语句,将查询语句的关键词与代码图中的候选节点进行匹配,生成子图并推荐搜索结果。Gu 等人首先对代码对应的抽象语法树进行简化,之后在其上引入了树型序列化方法,将抽象语法树转换为词汇单元序列,进行多模态的代码搜索。Meng设计了一种抽象语法树解析算法,能够在将代码转换为向量的过程中保留代码的词法特征和结构特征。Xu 等人提出了TabCS 模型,在代码的文本特征、代码对应的抽象语法树结构特征以及查询语句上同时使用注意力机制,捕获它们之间的语义相关性。Zou 等人通过使用图嵌入技术,将软件项目源代码转换为代码图。这类方法可以有效地表示软件代码图的深层结构信息。
3.3 代码补全
代码补全是自动化软件开发的重要功能之一,能够有效地提高软件开发者的工作效率。代码补全技术基于开发人员的输入,实时预测待补全代码中的类名、方法名、变量名等,通过这种方式能够有效减轻开发者的键入负担,减少拼写错误,进而提高开发效率。但是,早期的代码补全工具不能很好地满足开发人员的需求,这些工具常常忽略了编程语言的语法规则,所提供的代码补全列表仍然需要进行人工修正。并且,这些代码补全工具通常只利用已有的代码和语法规则,很少考虑待补全代码与上文之间的语义关联。Bruch 等人就提出了智能代码补全技术,从已有的代码库中挖掘更多的有效信息用于代码补全。
代码补全技术将待补全位置的代码的上下文信息和代码库中学习到的代码上下文信息进行关联,通过计算两者之间的相似度,推荐相似度高的代码片段作为代码补全推荐结果。根据代码补全的对象,可以将代码补全技术分为:(1)标识符补全;(2)代码片段补全;(3)关键词、缩略词补全。标识符补全指的是根据已有的代码,对不完整的标识符进行补全。一般补全的对象包括方法名、变量名、参数名等。代码片段补全指的是对于语句空缺的代码片段,使用代码补全工具自动地生成符合编程语言规范的语句用于补全。关键词、缩略词补全指的是对于输入的简短的词汇,将其补全为完整的函数或参数。但是由于所输入的词汇所能包含的信息量较少,通常情况下这种补全方法的补全结果较差。
虽然对于代码补全技术的研究在近十几年中取得了一定的成果,但是在实际的开发应用中仍然面临以下几个问题需要解决:(1)缺少统一的模型评估指标。目前已有的与代码补全有关的评估指标大多都是机器学习领域的通用指标,如准确率、召回率、平均倒数排名等。目前大部分文献仅采用其中一种指标用于模型的评估,因此对于不同的代码补全方法的性能难以进行比较。(2)缺少真实的基准数据集。在机器学习领域,对模型性能的评估不但与评价标准有关,还与所使用的基准数据集有关。目前代码补全的文献中所使用的数据集大多是研究者自行爬取的数据集,缺少一个公认的、合理的、真实的数据集用于评估代码补全模型的效果。
4 分析与讨论
随着近几年嵌入技术在自然语言处理领域中获得的成功,越来越多的代码分析工作也开始采用类似的方法对代码分析领域中尚未解决的问题进行研究。如本文中描述的代码表征研究方向,在目前的代码分析工作中有着重要的地位。其中的词嵌入技术和分布式假说赋予了深度学习工具强大的表征能力。使用神经网络技术,能够将代码所特有的语义信息和结构信息特征转换为计算机擅长处理的实数向量形式。在此过程中无需进行复杂的特征工程分析,减少人为操作所带来的信息损失。但是在现有的代码表征工作中,仍然存在以下几点困难尚未解决,包括代码库中存在的超出词表问题、表征模型的构建方式以及模型所生成的代码表征的质量评价标准等。接下来本章将对这些问题进行详细分析。
4.1 代码库中的超出词表问题
当前代码分析文献大都根据代码文本中所存在的自然性这一特征进行具体的代码分析任务,如代码补全、代码克隆检测这类任务都是将代码视为自然语言文本进行处理。如本文背景知识部分所述,当使用自然语言技术对代码文本进行处理时,由于软件开发人员在编写代码时可以自由地创建标识符,这一过程将会产生一个规模巨大且稀疏的代码词表。代码词表的规模会直接影响代码分析任务的效率。在神经网络模型训练的过程中,通常的做法是对这个大词表中的词汇单元个数进行数量的限制,因此当某个词汇在词表中没有出现过,那么神经网络模型将无法对其进行处理。这就是代码分析中的超出词表问题(OoV)。
在自然语言处理领域,对于超出词表问题已有很多相关文献。这些方法将完整的词汇单元拆分为能够组合成完整词汇的子词汇单元,在自然语言分析领域中取得了一定的成果。在代码分析领域中,同样也有对超出词表问题进行研究的一些工作。文献[126],该工作本质上是使用当前自然语言处理领域中字节对编码(byte pair encoder,BPE)方法对大型代码库进行分析,并未考虑代码本身所具有的特性,如代码的局部重复性、标识符的整体性。文献[127]研究了代码中的超出词表问题对之后的机器学习模型性能的影响,发现词表的大小、输入数据中超出词表词汇的占比对机器学习模型的影响是很大的。文献[118]对代码词汇单元的拆分方式如图4 所示,若是将setter 变量名拆分为set、ter 两部分,将直接丢失其作为一个完整变量的信息。

图4 Java 代码的词汇单元与子词汇单元Fig.4 Word and subword units of Java code
因此,如何处理代码的超出词表问题,减轻其对后续代码分析任务的影响亦是一个重点的研究方向。本文认为可以从以下几点进行研究:(1)衡量词库中词汇单元的信息量,剔除信息量小的词汇单元;(2)构建特征提取能力强的神经网络模型,从字符层面对代码信息进行提取。
4.2 表征模型的构建
本文之前所列举的代码表征工作中,均是以结合具体的代码分析任务进行介绍。这是因为这些工作均是以具体的代码分析任务进行表征模型的设计。如代码克隆检测、代码分类这种依赖于代码模式特征的任务。对代码补全任务,应尽可能多地提取代码的结构信息。对于代码迁移任务,则通常需要采用序列神经网络对代码进行建模。在自然语言分析领域中,存在诸如BERT(bidirectional encoder representation from transformers)、GPT(generative pre-training)、ELMo(embeddings from language models)这类通用的预训练模型,能够直接应用于大多数的自然语言分析任务。而在代码分析领域中,尚缺少对于预训练模型应用于代码分析任务的工作。现有的生成代码表征的模型通常都是有监督学习模型,即所使用代码表征模型都是基于具体的代码分析任务构建的。这从根本上使得所学习得到的代码表征向量不能适用于多种任务。如目前在代码表征领域影响较高的Code2vec 工作,其生成的代码表征向量也被证明不能直接简单地应用于代码分析任务中。对于如何构造一个具有更强泛化能力的代码表征模型本文有以下几个观点:(1)将传统的代码分析工作中代码特征提取部分融合进代码表征模型的构建过程。(2)增加模型训练的数据量,提高代码表征模型的特征提取能力。
4.3 代码表征质量的评价标准
代码实际上具有高度的抽象性和复杂性,代码的大部分性质难以用简单明了的数学语言来定义。因此,对于代码分析模型所生成的代码表征的评价就显得尤为重要。但是目前对代码表征质量的评估并没有一个统一的标准。现有的工作都是基于具体的分析任务对表征向量进行评价。甚至在同一种类型的分析任务中,都存在着多种不同的指标。如在代码克隆检测的相关工作中,所使用的评价指标包括精确率(precision)、召回率(recall)、F1 值、准确率(accuracy)等评价指标,同时代码检测任务中所使用的数据集包括BigCloneBench、GoogleCodeJam、OnlineJudge等不同形式的数据集。在代码搜索任务中,也是通过计算最后推荐结果的归一化折损累计增益(normalized discounted cumulative gain,NDCG)来衡量代码表征质量的好坏。这种基于具体任务的结果来判断代码表征质量优劣的方式,并不是直接对表征向量的质量进行衡量。同时在代码分析任务中,不同任务所使用的数据集是不同的,也存在着许多工作是基于研究者自己所标注的数据,这使得应用于不同代码分析任务中的表征模型不能在同一标准上进行比较。对于此问题,本文建议以众包的形式构建代码分析领域通用高质量数据集,并在统一的评价标准上进行方法比较。
5 结束语
代码表征在软件分析任务中占据了重要的地位。通过使用深度学习模型生成代码表征向量,自动地提取代码中所包含的隐含特征,降低对人工制定特征的依赖,进而提升代码分析任务的效率。本文介绍了代码表征的基本概念,并对近几年来不同的代码表征及其应用的工作进行了综述,对这些工作的原理与技术进行了分类与总结,最后分析并讨论了现有的代码表征工作中仍然存在的问题以及对应的解决方法。
猜你喜欢
环球时报(2022-09-20)2022-09-20 15:18:57
今日农业(2020年24期)2020-12-15 16:16:00
时代英语·高一(2019年1期)2019-03-13 10:29:48
时代英语·高三(2019年1期)2019-03-13 10:29:26
动漫星空(2018年11期)2018-10-26 02:24:02
动漫星空(2018年2期)2018-10-26 02:11:00
动漫星空(2018年9期)2018-10-26 01:16:48
动漫星空(2018年5期)2018-10-26 01:15:02
时代英语·高三(2018年1期)2018-02-23 19:33:53
新高考(英语进阶)(2017年10期)2017-12-23 09:15:06
