
深度学习应用于目标检测中失衡问题研究综述
2022-09-15 10:27吴艳霞梁鹏举
计算机与生活 2022年9期
任 宁,付 岩+,吴艳霞,梁鹏举,韩 希
1.哈尔滨工程大学,哈尔滨 150001
2.黑龙江省自然资源技术保障中心,哈尔滨 150030
目标检测是提取图片或者视频等数据特征去定位目标位置并进行准确分类,这是计算机视觉中的基本问题之一,并且在安全监控、自动驾驶、医疗决策、遥感等领域有广泛应用。
目标检测算法主要分类为:基于阶段的检测方案、是否采用锚的检测方案和基于标签的检测方案。尽管三类方法在深度学习的目标检测方面都很实用,但近几年大多数的目标检测方法都普遍存在失衡问题。其中基于阶段的检测方案中单阶段检测器出现的失衡问题较为严重,双阶段和多阶段相对稳定。Anchor-base的方法主要代表有SSD(single shot multibox detector)、RetinaNet等,造成失衡问题的主要原因是锚框对应的参数长宽比、空间特征信息和IoU 的微小变化会直接影响检测效果。Anchorfree的方法是近几年才提出的,典型的代表作是YOLO(you only look once)变种,主要特点是快速且鲁棒,但是由于追求检测速度导致的失衡问题也随之而来。基于标签的检测方案分为region proposal-based、author-IOU 和keypoint-based,其中region proposalbased 的检测方法核心思想是将依赖离线的算法工具直接嵌入到传统算法中,加快了检测速度,但是直接造成了均衡问题;author-IoU 的方案是巧妙地在训练过程中动态设置样本来筛选阈值去分配正样本优化IoU 对实例本身的不敏感问题;keypoint-based 的出现直接替换了anchor预设框的概念,用点代替框的同时也造成严重的均衡问题。
应用深度学习的目标检测综述,Litjens 等人讨论了各种应用深度神经网络的方法,如分类、检测、分割在医学图像分析中的应用。Johnson 等人仅考虑机器学习方法,未特别关注基于深度学习的方法。董文轩等人以时间和算法架构为研究主线,综述了近年来基于深度卷积的目标检测代表性算法的研究和发展历程。李柯泉等人介绍了图像目标检测模型中常用的卷积神经网络,从候选区域、回归和anchor-free 方法的角度对现有经典的图像目标检测模型进行综述。但以上文章并未提到目标检测失衡问题。
近几年关于目标检测失衡的综述主要介绍应用深度学习的通用目标检测发展过程。综述提出了一个分类法,用于正输入边界框的对象IoU 分布整个图像中对象的位置不同任务(即分类、回归)对整体损失检测方法的贡献,并详细分析典型优化方法。其中,Zou 等人对处理规模失衡的方法进行了辩证分析。程旭等人总结了深度学习中区域提案和单阶段基准检测模型。并从特征图、上下文模型、边框优化、区域提案、类别不平衡处理、训练策略、弱监督学习和无监督学习这八个角度分类总结当前主流的目标检测模型。但是仅仅讨论了类别失衡问题,并且未深度解析产生的原因。Dollar 等人对处理尺度失衡的特征提取方法进行了全面分析。张伟针对目标检测尺度失衡问题进行全面分析和归纳,总结引起尺度不平衡的原因,针对每种原因分析解决方案。然而从失衡的角度,以上综述只分析了一类或者其中一种失衡问题。与这些综述不同的是,本文应用深度学习模型剖析目标检测失衡的每一类问题在模型中产生的原因,并对优化失衡问题的方法进行全面对比分析。
目前针对目标检测的深度学习技术综述相对较多,但针对目标检测失衡问题的综述论文涉及较少或者简单介绍其中的一类。然而失衡问题发生在神经网络训练中的每一个环节并且每一个微小的变化都会产生意想不到的影响,因此目标检测中的失衡问题一直是困扰研究人员进一步优化检测器需要解决的核心问题之一。本文的目标是全面介绍目标检测中的失衡问题,剖析问题产生的原因并将问题根据产生原因进行分类,总结主要优化方案,分析优化策略的对比结果,最后展望此领域未来的研究方向。
1 目标检测失衡问题
近年来深度学习应用于目标检测算法取得了显著成果。最常用的检测算法主要分为两个方向:一是基于Region Proposal 的双阶段算法(R-CNN、Fast R-CNN、Faster R-CNN);另一类是YOLO 和SSD 系列的单阶段算法。图1(a)展示了单阶段网络的训练流程示例图,首先将图像输入到深度卷积神经网络进行特征提取,得到一组密集的假设锚,然后将假设锚与真实数据框匹配和采样,最后将以上输出反馈给分类和回归网络进行训练。与单阶段不同的是,在双阶段中第一阶段做前景-背景分类和候选区域回归,第二阶段是特征提取和候选区域筛选、精确和再分类。由于单阶段中删去RPN(region proposal network)操作,双阶段存在的失衡问题在单阶段中更为突出。当然,无论是单阶段还是双阶段检测方案均需要训练神经网络达到实验效果。
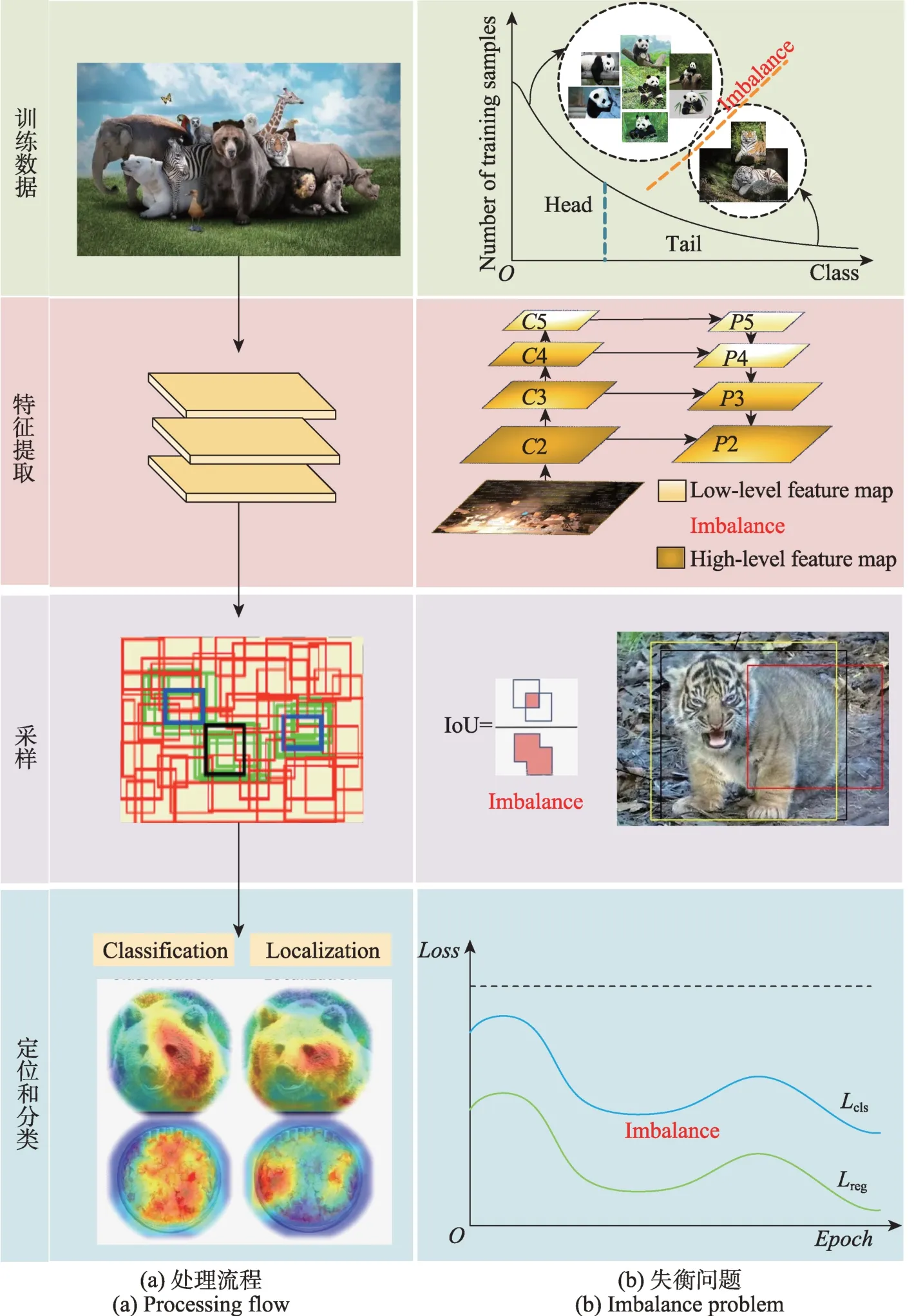
图1 失衡问题示例图Fig.1 Example diagram of imbalance problem
如图1(b)展示训练的四个环节存在的四类目标检测失衡问题,从上到下为数据失衡、尺度失衡、相对空间失衡和分类与回归失衡。其中数据失衡包括:前景/背景失衡、前景/前景失衡、类别标签失衡、长尾数据失衡。尺度失衡包括:目标实例/边界框失衡、特征失衡。相对空间失衡包括:回归损失失衡、目标位置失衡。
2 失衡问题分类
2.1 数据失衡
数据失衡是指在一个数据集中类别数量分布直接导致数据特征偏移形成的分布失衡。主要分为四种:前景/背景失衡、前景/前景失衡、类别标签失衡和长尾数据失衡。
(1)前景/背景失衡
前景/背景失衡中背景类是过度代表类,前景类是不足代表类。此类问题是由边界框匹配和标记模块边界框过多被标记为背景(负类)导致训练过程出现前景/背景失衡,因为它不包含任何背景标注,所以它不依赖于数据集中每一类的实例数量。
可以将前景/背景类失衡的解决方案分为四种:硬采样方法、软采样方法、无采样方法和生成方法。
(2)前景/前景失衡
在前景/前景类失衡中,过度代表类和不足代表类都是前景类。根据问题的起因可以分为两种:数据集和批处理。数据集引起的前景/前景失衡是由于目标存在不同性质,在数据集中会出现目标类之间的失衡。通过直接生成人工样本并将其插值到训练数据集中的生成方法可解决此类问题。批处理引起的数据失衡是指不同的类在一个批次中的分布不均匀导致模型在训练期间偏向于代表性过强的类而忽略了代表性不足的类。针对批处理引起的失衡问题,OFB(online foreground balanced)表明通过给每个待采样边界框分配概率,可以在批处理级别上解决前景/前景类失衡问题,使得批处理中不同类的分布均匀。同理,该方法旨在提升抽样过程中正样本数量较少的类。
(3)类别标签失衡
类别标签失衡主要是发生在半监督学习的训练中,是由训练过程中参数的更新过度依赖固定阈值来计算无监督损失导致的,仅用预测置信度高于阈值的未标记数据造成标签之间的失衡从而影响检测结果。主要分类是标签内失衡、标签间失衡和标签集失衡。
目前的解决方案分为重采样、分类器自适应和集成方法。
(4)长尾数据失衡
长尾数据失衡是指在训练样本中,其中头部有大量的样本点,但尾部仅有少部分样本,如图2 所示。这种训练样本级的类失衡导致深度学习模型的识别和分类表现不佳。目前的研究方案分为以下三类:类-再平衡、信息增强和模型改进。
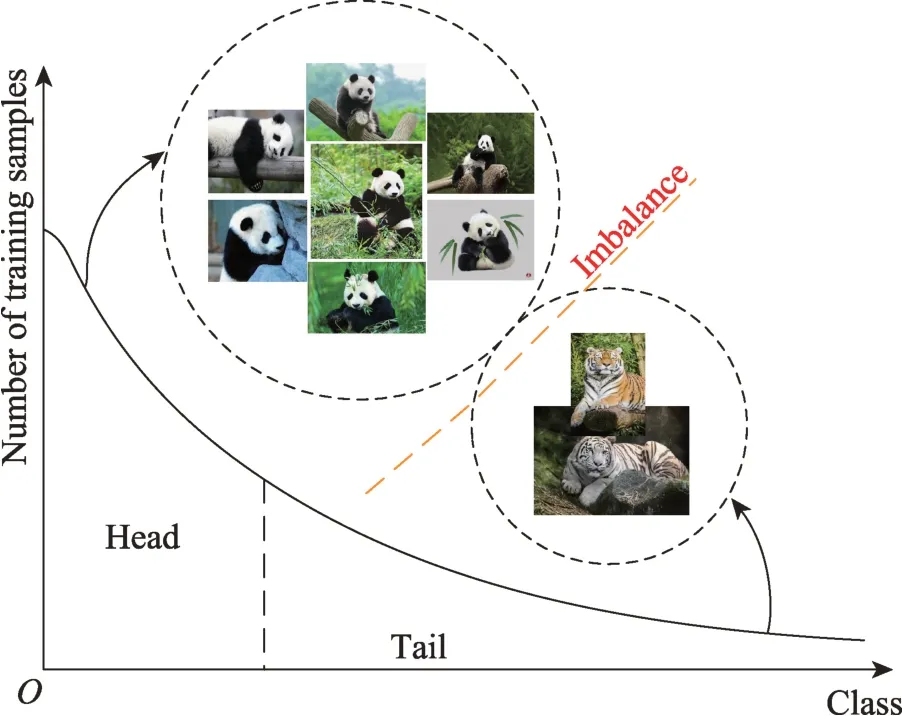
图2 长尾数据标签分布Fig.2 Label distribution of long-tail data
2.2 尺度失衡
尺度失衡是目标检测对象与预测边界框的尺度之间的失衡。主要分为以下两种:目标实例/边界框失衡和特征失衡。
(1)目标实例/边界框失衡
当部分大小的目标或输入边界框在数据集中过度表示时会导致尺寸失衡。已经证明,这会影响估计ROIs 的尺寸和整体检测性能。He 等人提出了边界框对目标检测结果的直接影响分为图3 中的四种情况。
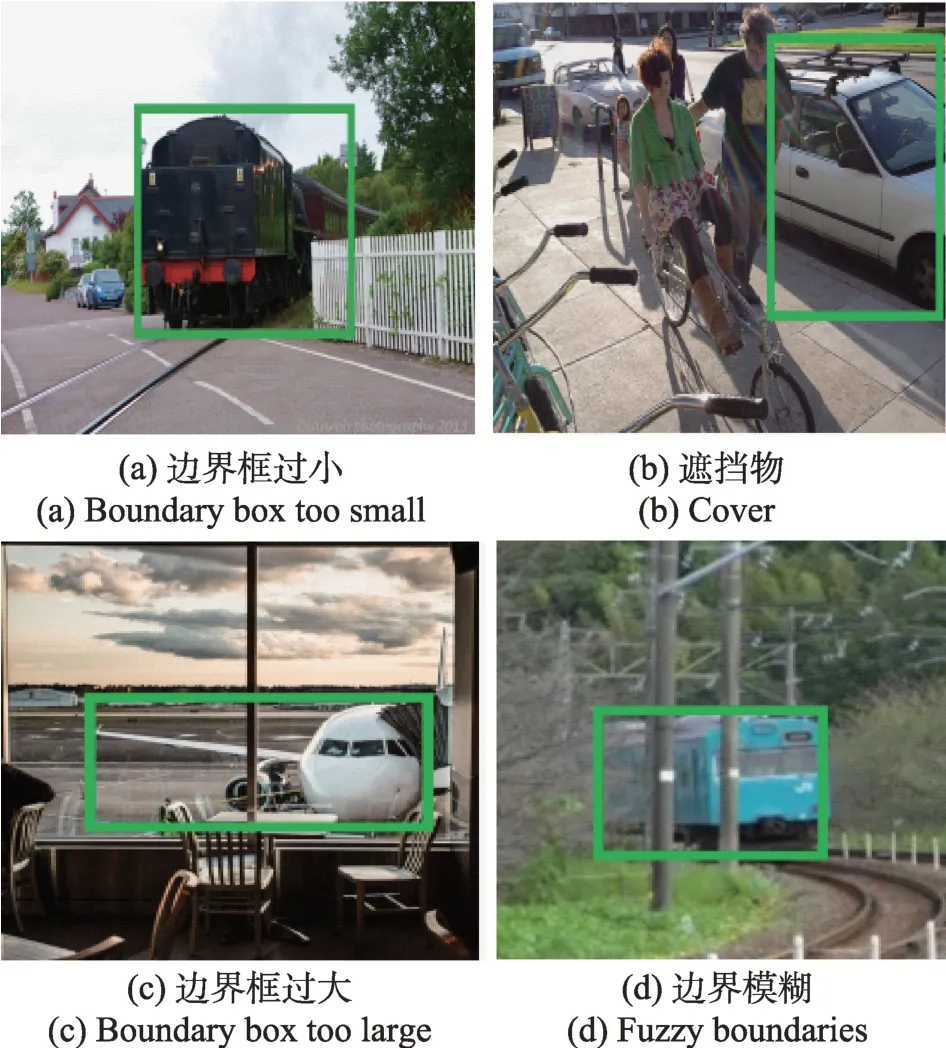
图3 边界框示例图Fig.3 Example diagram of boundary box
图3(a)(c)中的边界框标记不准确;(b)有遮挡物导致的标记偏差;(d)图像中待检测物体边界模糊。以上几个问题会直接导致目标检测的分类和定位偏差。
深度学习应用于目标检测的检测器时存在一个缺陷是依赖于主干卷积神经网络,预先训练图像分类任务以便从输入图像中提取视觉特征。Henderson等人提出一种专门为目标检测任务而设计的主干网络,通过限制高层特征的空间降采样率,减小此类问题对检测结果带来的影响。
(2)特征失衡
主干网络的特征集在低特征和高特征层之间进行平衡,才能得到一致的预测结果。传统的FPN(feature pyramid network)系统架构如图4 所示,2 层自下而上通过低级特征的5 层特征金字塔,然而2和2 层直接集成层,导致2 和5 层中的高级和低级特性的效果是不同的。
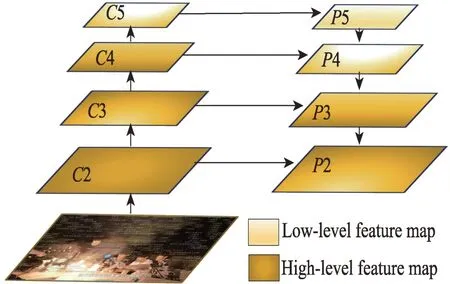
图4 特征失衡问题在FPN 中的体系结构Fig.4 Architecture of feature imbalance problem in FPN
解决FPN 架构中的失衡问题的主要趋势是从改进的自上而下特征层连接到新的架构,用新的架构来解决特征失衡问题的方法分为两大类:金字塔特征提取方法或主干特征提取方法。
对于金字塔型代表方法是PANet(path aggregation network)。PANet 是第一个表明FPN 提取的特征可以进一步增强,采用自顶向下和自底向上的双向融合骨干网络,提升预测掩码的质量。主干特征提取的代表方法是STDN(scale transferrable detection network),利用Dense-Net 块提取主干特征的最后一个层特征生成金字塔特征。
2.3 相对空间失衡
相对空间失衡是由图片大小、形状、位置(相对于图像或另一个框)和IoU(边界框)的空间属性的失衡造成的。在单阶段检测器分类与定位是并行的,因此空间失衡在单阶段检测器中愈加严重。例如,损失函数的选择、位置的微小变化可能会导致回归(局部化)损失的大幅变化。主要分为:回归损失失衡和目标位置失衡。
(1)回归损失失衡
回归损失主要分为点回归损失和边框回归损失(IoU 损失)。其中点回归损失包含均方差损失、平均绝对误差损失、Huber Loss 和分位数损失。边框回归损失包含IoU Loss、GIoU Loss、DIoU Loss、CIoU Loss、EIoU Loss 和Focal-EIoU Loss。其中最常见的回归损失失衡是IoU 分布失衡。
IoU 分布失衡是当输入边界框呈倾斜的IoU 分布时,会观察到IoU 分布失衡,回归后退化的锚的比率逐渐向回归器训练的阈值下降。另一方面,假阳性锚的比例正向增加,其中阳性锚被回归变量丢失。R-CNN方法是第一个解决IoU 失衡的方法,直接最小化Anchor 和目标框之间的归一化距离以达到更快的收敛速度。Multi-Region CNN和AttractioNet迭代地将相同的网络应用到边界框达到均衡。另一个解决IoU 失衡的方法是HSD(hierarchical shot detector),在边界框回归之后运行分类器使分布更加均衡。
(2)目标失衡
目标失衡是由目标在整个图像中的分布不匀导致的,目前的深度检测器使用密集采样锚作为滑动窗口分类器。大部分方法默认锚点在图像中均匀分布,因此图像中的每一部分都被认为具有相同的权重。另一方面,图像中物体的不均匀分布导致物体位置存在失衡问题。主要解决方案是同时学习锚点的位置、尺度和长宽比属性,针对不同的任务设计生成锚点,减少锚点的数量同时提高召回率。
2.4 分类与回归失衡
目标检测任务中包含分类任务和回归任务,分类的目的是目标识别,而回归的任务是位置的回归,实现目标定位。分类与回归都是监督学习,对输入的数据进行预测。其中分类的输出结果是分散的,例如目标所属的类别,猫、狗、熊等,最终的目的是得到一个决策面。回归的输出结果是连续的目标值,最终目的是得到一个最优拟合线。分类的分支任务是用来目标识别,回归的分支任务是用来实现目标定位。
分类与回归失衡是指训练过程中目标(损失)功能被最小化。根据定义,目标检测要同时解决分类和回归任务,如图5(a)所示。然而不同的任务可能由以下情况导致失衡:(1)如果分类损失函数相较于回归损失下降速度很快,会导致其中一个任务主导整个训练,如图5(b)。(2)不同任务的损失函数范围不同,导致了任务之间的失衡,如图5(c)。(3)各个任务的训练成本不同直接影响任务的学习速度,从而影响训练结果,如图5(d)。

图5 分类与回归损失函数图Fig.5 Classification and regression loss function diagram
3 优化策略
3.1 数据失衡优化策略
数据失衡问题的优化策略之一硬采样,采用启发式方法执行,通过一组给定的标记BBs中选择正负样本示例的子集来解决失衡问题。双阶段算法中的硬采样代表作是Faster R-CNN,通过预先定义的前景背景比例随机检测样本,但这种方案忽视了难易样本的区别。OHEM(online hard example mining)提出来一种考虑正负样本损失值的方案。但是倾向于采样更难的目标示例,而不是更容易的示例,导致难易样本差距更大。S-OHEM(stratified online hard example mining for object detection)是基于OHEM的改进,根据loss 的分布抽样训练样本避免了仅使用高损失的样本来更新模型参数,却引入额外超参数增加了训练成本。
软采样方法的经典之作是Focal Loss,它动态地给复杂例子分配权重,如下公式所示:
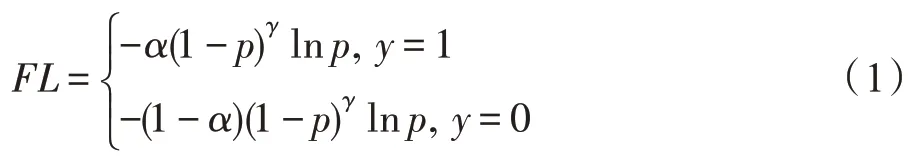
在式(1)中,当=0 时,Focal Loss退化为香农交叉熵损失。当=2 时,体系结构中复杂示例和简单示例之间达到良好平衡状态。Focal Loss针对的是难易样本失衡问题,提出关注部分很少但很难被分类的样本上,避免容易样本在分类过程中主导检测器的训练过程,设计出简单的密集检测器RetinaNet取得显著成果。然而当样本中有离群点,即使模型已经收敛了,Focal Loss还是由于离群点导致判断错误。因此梯度均衡机制GHM(gradient harmonized singlestage detector)出现了,提出计算梯度密度的倒数作为损失函数的权重分别引入到分类损失函数(GHMC)和边框损失函数(GHM-R)。它抑制了容易产生的正、负梯度。与Focal Loss 的不同点是,GHM 运用一种基于计数的方法计算具有相似梯度范数的样本数量,如果有许多具有相似梯度的样本,则降低样本的损失,如式(2)所示。

式中,(BB)为梯度范数接近BB梯度范数的样本个数;为输入边界框的个数。GHM 方法预先假设简单的例子是具有多相似梯度的示例。与其他方法的不同点是GHM 能够证明不仅对类别耦合任务有效,也对回归任务有效。
2020 年PISA(prime sample attention)提出新的研究角度,从样本独立性和平等性出发,根据mAP测量的整体性能重新定义范式,更关注对检测性能方面发挥关键作用的样本,开发一种简单有效的采样和学习策略。提出了IoU-HLR 对小批量边界框样本的重要性进行排序优化失衡问题。
由于上述方案中超参数量不断增加,无采样方法应运而生,代表方案是AP-Loss,直接根据最终的损失分类建模成一项排序任务,并使用平均精度作为任务的损失函数减少超参数数量来平衡前景/背景类失衡问题。DR-Loss将前景/背景的置信度值分布推向决策边界,优化派生分布的期望进行排序代替原始示例,解决背景中困难样本的问题,从而达到相对平衡的状态。
2021 年Chen 等人提出的无采样机制是基于类别自适应的思想。在研究中发现训练检测器时不采用抽样启发式会直接导致检测精度大幅度下降,而这种下降主要由于分类梯度失衡。因此Sampling-Free 通过初始化bias、引导损失函数权重和类别分数阈值自适应来解决正负样本失衡问题取得了显著成效。然而与减少超参数量的初衷相悖。
生成方法的主要思想是将人工生成的样本注入到数据集中解决数据失衡问题,代表作是生成性对抗网络(generative adversarial networks,GAN)。优势是在训练过程中生成更难的样本训练模型,得到更稳定的模型。例如,TADS(task-aware data synthesis)是一种特定于任务的合成数据生成方法,通过评估目标分类器的优缺点来产生有意义的训练样本。合成器和目标网络以对抗方式进行训练,其中每个网络都以超越另一个的目标进行更新,优化数据失衡问题。另一种研究方向是GA-RPN(guided anchoring region proposal network),一种新的anchor 生成方法。该方案通过图像特征来指导生成anchor,运用CNN 预测anchor 的形状和位置,生成稀疏而且形状任意的anchor,并且设计Feature Adaption 模块来修正特征图使之与anchor 精确匹配,从基于anchor 的角度优化失衡问题。
此类方案的性能对比结果如表1 所示,可以总结为:(1)软采样方案中的PISA 在Faster R-CNN 上获得最高AP 值41.5%,相对硬采样中的MBS 提升了5.1个百分点;PISA 在RetinaNet 上取得40.4%的效果,相比无采样方案的AP Loss提升了5.4个百分点。(2)生成方案中,在Fast R-CNN 上,GA-RPN 相比TADS 提升了7.4 个百分点。(3)四类方案中整体性能都处于上升趋势,其中软采样方案和生成方案相对提升显著。
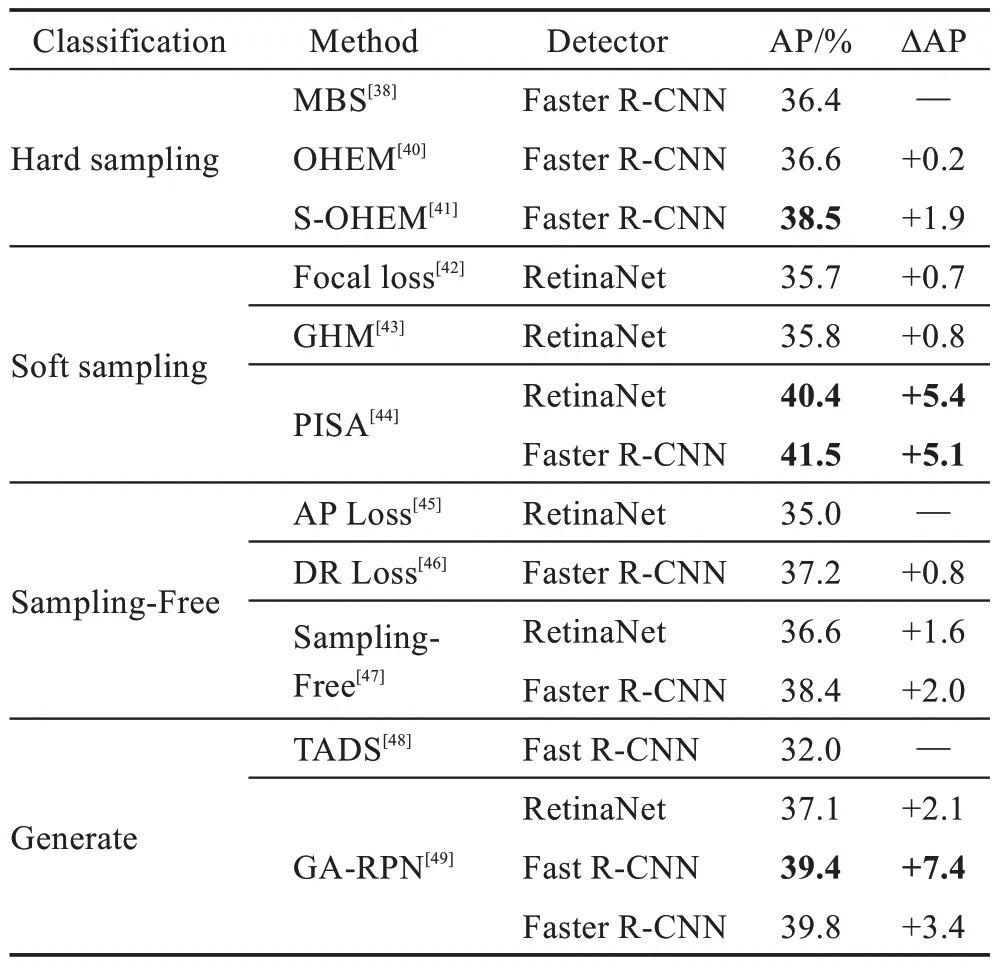
表1 前景/背景失衡优化策略性能对比Table 1 Performance comparison of foregroundbackground class imbalance optimization strategies
针对前景/前景失衡问题,Oksuz 等人开发了一种生成器pRoI Generator,根据IoU 分布自动生成RoI来模拟正样本的采样方式,平衡前景/前景失衡问题。实验证明pRoI 在Pascal VOC 2007 数据集上获得了77.8%的mAP。pRoI 应用在Faster R-CNN 上在低IoU 下取得更好或者同等性能,同时也体现出该方案的局限性,在高IoU 下无优势。另一种方案是预先训练主干网络的最后一层的特征做内积,再构建类之间的相似度度量,并分层分组来优化数据集级前景类失衡。针对设计的层次树中的每个节点,根据分类器的置信度得分来学习分类器。
针对以上方案存在的问题,GraphSMOTE(graph synthetic minority oversampling techniques)在特征提取阶段先用GNN(graph neural networks)学习Embedding,得到低维且稠密的特征避免引入域外噪音,且能够同时编码节点特征和图结构。然后生成合成节点,将生成的结果输入到GNN 分类器最终进行端到端的训练。该模型构造一个嵌入空间来编码节点之间的相似性,从未生成新样本,具备良好的可扩展性。
2022 年Hou 等人提出新的研究方向,从Batch内失衡的角度解决失衡问题,设计批量转换在训练期间隐式探索样本关系,实现不同样本间的协作关系,同时将BatchFormer 设计成即插即用模式,在测试期间将其删除,来减少时间消耗。实验表明Batch-Former 在数据集ImageNet-LT、iNaturalist 2018 和Places分别取得了47.6%、74.1%和41.6%的AP值。在零样本学习中的MIT-States、UT-Zap50K 和C-GQA 数据集上取得了6.7%、34.6%和3.8%的AUC 值。
类别标签失衡问题的优化方法之重采样,是一种应用广泛的优化数据失衡问题的方案。例如,MLSOL(synthetic oversampling of multi-label data based on local label distribution)首先根据局部标签分布计算实例的权重向量和合成实例生成的类型矩阵,使用加权采样进行实例选择,新实例的标签会根据位置发生变化,从而避免标签失衡。
另一种采样方式是MMT(mutual mean-teaching),利用更鲁棒的“软”标签对伪标签进行在线优化,并设计针对三元组的合理伪标签以及对应的损失函数来优化标签失衡问题。实验证明MMT 在Duke-to-Market和Market-to-Duke上分别取得76.50%和65.75%的mAP 值,相比不采用MMT 的方案优化效果显著。
类别自适应的核心思想是直接从数据集中的类中学习失衡分布。基于非对称的stagewise loss函数来动态调整正负样本的损失来解决弱监督多标签学习中的失衡问题。Zhang 等人提出COCOA(crosscoupling aggregation),结合当前标签对应的二元类不平衡分类器的预测结果和多类不平衡学习器的预测结果得到每个类标签的最终决策优化失衡问题。实验证明COCOA 在F-measure、G-mean、Balanced Acc、AUC-ROC 和AUC-PR 五个评价指标中分别取得了4.22、5.00、4.50、4.31 和4.55 的效果。
集成方法的核心思想是结合多个分类器作为集合训练多变标签的分类器,可以实现多样化的多标签预测和解决失衡问题。MCHE(multi-label classification using heterogeneous ensemble)通过结合最先进的多标签方法,提出多标签学习者的异构集成。该方法同时解决了样本失衡和标签相关性问题。由五个分类器组成,在同一数据上使用不同的算法进行训练。测试连接单个预测的方法,以及通过交叉验证调整不同阈值和加权方案。ECCRU(ensemble of classifier chains with random undersampling)通过耦合欠采样和改进对多数样本的利用,扩展了ECC 对失衡的弹性。实验证明ECCRU3 在F-measure、Gmean、Balanced Acc、AUC-ROC 和AUC-PR 五个评价指标中分别取得了2.81、2.72、1.91、1.84 和2.06 的效果。相较于COCOA 方案有明显优势。
长尾数据失衡的优化方案之一类-再平衡,目的是平衡模型训练过程中不同类的训练样本数。SimCal提出了一种新的双层类平衡采样策略来处理长尾实例分割。具体来说,双层采样策略结合了图像级重采样和实例级重采样,以缓解实例分割中的失衡问题。BALMS(balanced meta-Softmax)开发了一种基于元学习的采样方法来估计长尾学习的不同类别的最佳采样率。提出的元学习方法是一种双层优化策略,通过在平衡的元验证集上优化模型分类性能来学习最佳样本分布参数。FVR(framework for long-tail visual recognition)提出一种自适应校准函数对分类器的输出进行评估和一种广义重加权校准方法,通过数据集分布的先验信息对损失函数进行调整。FASA(feature augmentation and sampling adaptation)提出使用平衡元验证集(作为度量)上的模型分类损失来调整不同类别的特征采样率,从而可以对代表性不足的尾类进行更多采样。
面对长尾失衡问题,类-再平衡方案的性能分析如表2,其中AP 表示平均精度,AP、AP和AP分别表示稀有类、常见类和频繁类的平均精度,可以看出整体检测精度不断提高。其中FVR 方案的表现不如BALMS,但是提出的自适应校准和广义重加权是一个新的研究方向。
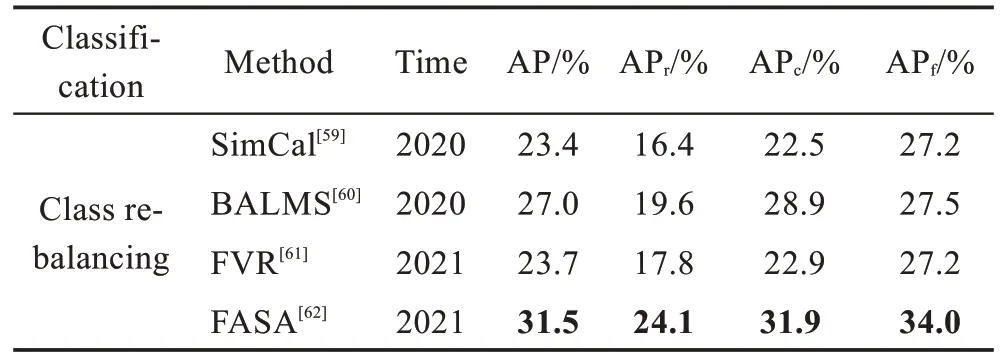
表2 类-再平衡策略性能对比表Table 2 Performance comparison of class re-balancing
信息增强的核心思想是试图在模型训练中引入额外的信息,以便在长尾学习中提高模型性能。LEAP(learnable embedding augmentation perspective)为每个类构建“特征云”,通过对尾类样本进行一定的扩充,并寻求通过在特征空间中增加具有一定扰动的尾类样本来转移头类特征云的知识,以增强尾类特征云的类内变化,最终减轻了类间类内特征方差的失真。M2M(major-to-minor)提出通过基于扰动的优化将头级样本转换为尾级样本来增强尾级,这基本上类似于对抗攻击。处理后的尾类样本将用于构建给模型训练的更平衡的训练集。GIST(geometric structure transfer network)提出在分类器级别进行头对尾传输。通过利用头类相对较大的分类器几何信息来增强尾类的分类器权重,GIST 能够获得更好的尾类性能。
模型改进是从网络模型的角度优化失衡问题。KCL提出了一种k-positive contrastive loss 来学习平衡的特征空间,这有助于缓解类不平衡并提高模型泛化能力。另一种方案是引入一种原型对比学习策略来增强长尾学习。PaCo(parametric contrastive)通过添加一组参数可学习的类中心进一步创新了监督对比学习,如果将类中心视为分类器权重,则它们起到与分类器相同的作用。DRO-LT(distributional robustness loss for long-tail)使用分布鲁棒优化扩展了原型对比学习,这使得学习模型对数据分布变化更加鲁棒。
表3 总结了在不同数据集上信息增益和模型改进方案的检测准确度对比结果。从表2 与表3 可以总结出,相较于类-再平衡,信息增益和模型改进方案的整体性能具有优势。尤其是GIST 在iNaturalist 2018数据集上的ACC 已经达到70.8%。PaCo 在ImageNet-LT 数据集上相较于KCL 提升5.26 个百分点,DROLT 在CIFAR-LT-100 数据集上相较于Hybrid-PSC 提升2.34 个百分点。
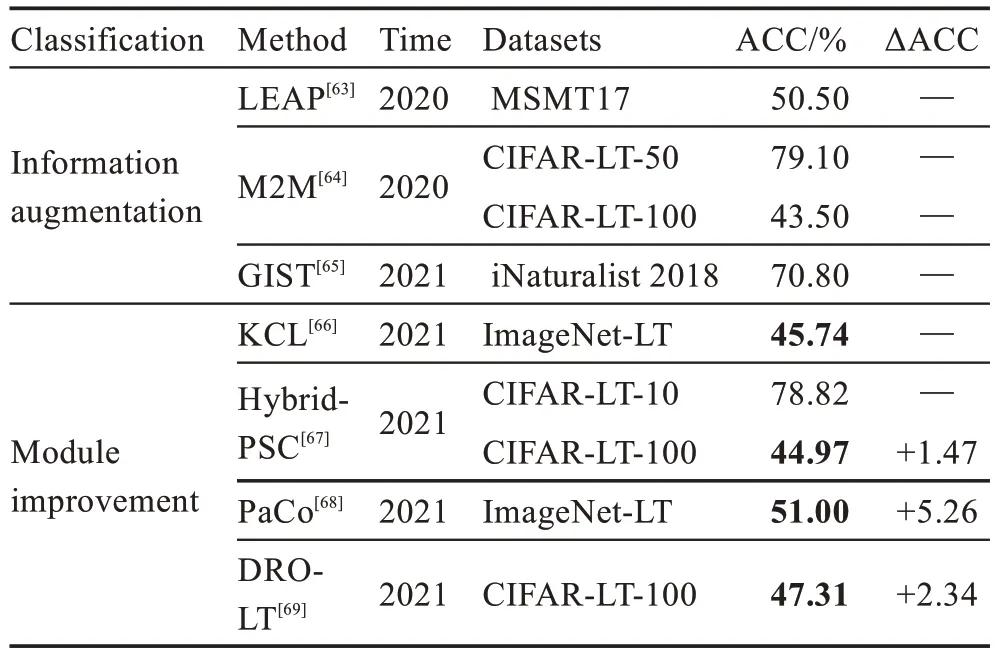
表3 信息增益和模型改进方案性能对比Table 3 Performance comparison of information augmentation and module improvement
因此无标签的类-再平衡值得进一步研究,具体而言,实际的长尾任务除了类别失衡之外,还存在标签频繁出现导致的失衡问题,影响着训练结果。如何获得准确的标签频率从而精进类-重平衡方案是进一步研究的方向。
3.2 尺度失衡优化策略
针对目标实例/边界框失衡,主要的优化策略如下:(1)从主干特征层次进行预测的方法是根据主干网络不同级别的特征进行独立的预测。由于不同的层次在不同的尺度上编码信息不同,该方法考虑了多尺度上的目标检测。Scale Aware Fast R-CNN方法是学习两个分类器的集成,一个用于小尺度目标,一个用于大尺度目标,进行联合预测。同时Fast R-CNN 采用随机梯度下降训练,使用分层抽样进行采样。并且对每一张图都要取足够的候选框,因此与Faster R-CNN 相比,在检测速度上效果不好。(2)特征金字塔网络(FPN)在进行预测前将不同尺度的特征进行组合。FPN 利用了一种附加的自上而下的方法,横向连接高层和低层的功能,在增加极小计算量前提下处理目标检测多尺度失衡问题。但是由于直接从主干网络提取特征进行组合导致了一定的特征失衡。(3)相比FPN 的不断叠加特征,SNIP(scale normalization for image pyramids)巧妙地引入图像金字塔来处理数据集中的尺寸失衡问题。SNIP是Singh和Davis 提出的一种新的训练方法。该研究证明通过向检测器输入特定尺度数据进行训练会损坏数据,并且在单个检测器上使用多尺度训练。由于保留数据的变化导致尺度不平衡。因此SNIP 只对尺寸在指定范围内的目标回传损失,减小了Domain-Shift的影响。在训练过程中用不同大小的图像训练多个网络模型和检测器网络,并且对于每个网络只标记适当尺寸的输入边界框为有效框来控制多尺寸训练下数据损失。SNIPER(scale normalization for image pyramids with efficient resampling)不是处理图像金字塔中的每个像素,而是以适当的比例处理真实实例周围的上下文区域。在训练期间每个图像生成的chips 的数量会根据场景复杂度自适应地变化。(4)图像与特征金字塔相结合的方法是生成超分辨率特征图。Noh 等人提出了用于双阶段目标检测器的小目标检测的超分辨率,这些检测器在RoI 标准化层之后缺乏小目标的强表示。另一种方法,Scale-Aware Trident Network结合基于特征金字塔和图像金字塔方法的优点,未使用多个下采样图像,而是用扩大卷积来提高检测准确率。为了保证每个分支的特定比例,将三种不同的感受野网络并行化,根据其大小为适当的分支设置输入边界框,并且提出了一种使用单个参数共享分支来近似其他分支优化损失函数的方案。
特征失衡的优化方案中,PANet(path aggregation network)通过自下而上的路径扩展特征金字塔,将底层特征更快地输入到预测层,然后建立自适应特征池,将每个ROI 与每个级别相关联,再应用ROI 池化操作进行融合,得到固定大小的特征网格传播到检测器网络。但是PANet 依然采用顺序路径提取特征。ThunderNet 网络的检测部分采用压缩的RPN 网络,即CEM(context enhancement module)整合局部和全局特征增强网络特征表达能力,并提出Spatial Attention Module 空间注意模块,引入来自RPN 的前后景信息用以优化特征分布。然而Libra FPN打破顺序提取特征的方式,采用缩放和平均将来自不同层的所有特征图都集成为一个单一特征图,再运用卷积网络将细化后的结果添加到金字塔特征的每一层,保证提取特征能够被充分利用。使用整体平衡的设计优化检测器训练过程中的失衡,从而尽可能地挖掘模型架构的潜力。
STDN(scale-transferrable detection network)使用DenseNet-169 作为基础网络提取特征,基于多层特征做预测,并对预测结果做融合得到最终结果。该方案提出Scale-transfer Layer,在几乎不增加参数量和计算量的情况下生成大尺度的特征图,STDN 不仅mAP 高,而且运行速度快。
NAS-FPN(neural architecture search FPN)通过使用神经架构搜索方法来搜索最佳架构,以在给定主干特征的情况下生成金字塔特征,此方案在图像分类任务中取得良好效果。Auto FPN是另一个使用NAS 的方案,同时学习从主干到金字塔功能和其他功能的连接。虽然NAS-FPN 实现了更高的性能,但Auto FPN 效率更高,内存占用更少。
GraphFPN使用拓扑结构的神经网络跨空间和尺度地执行特征交互。通过泛化卷积神经网络的全局通道注意力,为图神经网络引入了两种类型的局部通道注意力。提出的图特征金字塔网络增强卷积特征金字塔网络的多尺度特征,使得特征层之间达到平衡。
另一个研究方向是基于主干特征网络的探索,例如Multi-level FPN主要由特征融合模块FFM(feature fusion module)、细化U 型模块TUM(thinned Ushape modules)和尺度特征聚合模块SFAM(scale-wise feature aggregation module)三个模块组成。实现了比FPN 融合更多的特征,且按照不同size进行融合。
2022 年AdaMixer的出现提出了自适应的特征采样位置,将Query 解耦成内容向量和位置向量,并且将位置向量采用参数化使得Query 与多层特征形成的3D 特征空间直接联系。该方案通过自适应地学习目标物体的位置和尺度变化来优化失衡问题。消融实验证明AdaMixer 在不加入额外金字塔网络的条件下效果高出0.01(AP)。在COCO 数据集上取得AP 值45.0%,相比GraphFPN 高出0.013。
3.3 相对空间失衡优化策略
针对回归损失失衡的优化策略,GIOU-loss(generalized-IoU loss)直接把IOU 设为回归的loss,基于一种距离度量方法不仅关注重叠区域,还关注非重合区域,从重合角度优化尺度失衡问题。更进一步,DIoU Loss(distance-IoU loss)将目标与anchor 的距离、重叠率和尺度都作为建模参考值,实现了收敛速度比GIOU-loss 更快,并且当出现两个框在水平方向或者垂直方向时,DIoU Loss 回归非常快,而此时的GIOU-loss 会退化为IOU loss。CIoU Loss(complete-IoU loss)是在DIoU Loss 的基础上考虑长宽比问题,引入了一个影响因子,把预测框的长宽比拟合目标框的长宽比来计算损失,改进了DIoU Loss 存在的对小尺度样本精确度低的问题,优化了大小尺度样本间的失衡问题。EIoU Loss摒弃IoU Loss 的长宽比指标,直接运用边长(宽和高的值)作为惩罚项,直接优化DIoU-Loss 存在的边长被错误放大问题,从而达到平衡。
基于IoU 系列方案的性能对比结果如表4 所示。从相对对比结果看到整体性能是在提升的,CIoU 在YOLOv3、SSD 和Faster R-CNN 上相较于GIoU-loss 和DIoU-loss 分别有3.10%、0.74%和1.66%相对提升结果。EIoU 在COCO val-2017 数据集上相比GIoU 和CIoU 分别有1.66%和4.11%的相对提升结果。整体性能呈上升趋势,下一步研究可以继续探索基于IoU 的优化策略。
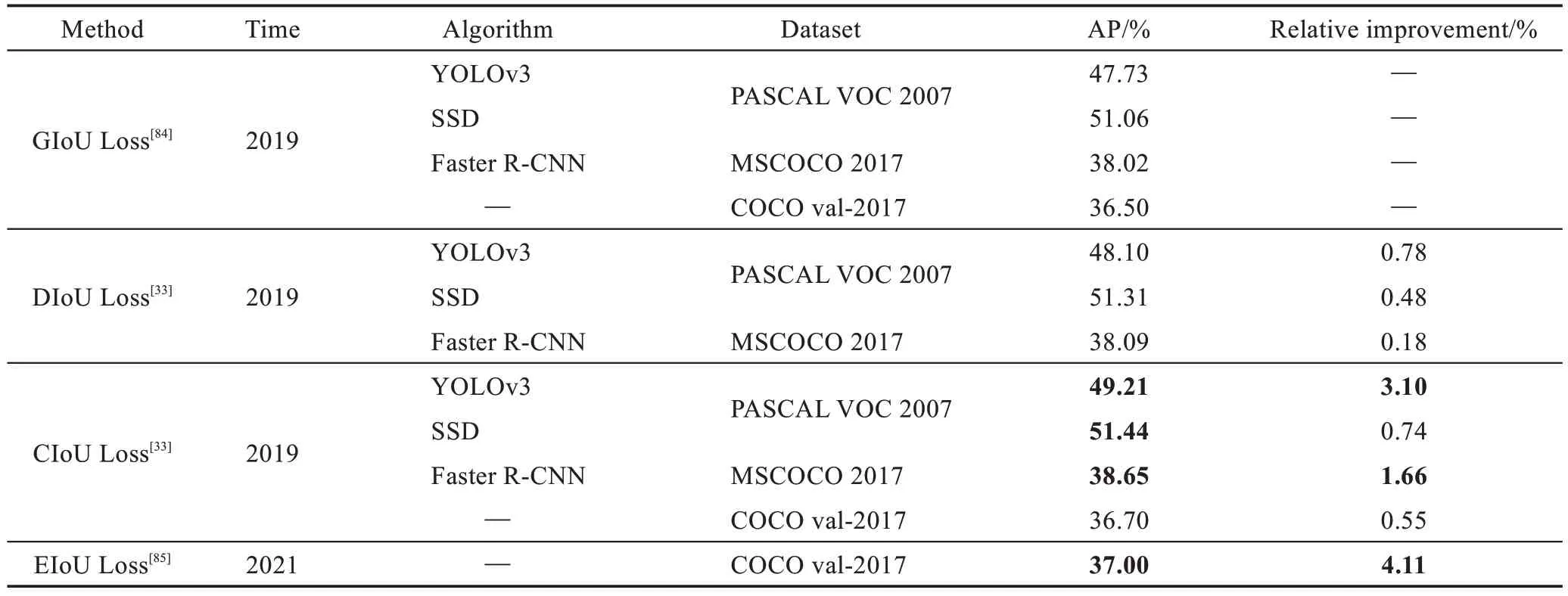
表4 IOU 系列性能对比Table 4 Performance comparison of IOU
另一种优化思路是Cascade R-CNN,在样本数不减少的情况下通过调试最优阈值来训练一个高性能检测器。在出现偏态的分布下使回归对单个阈值过拟合,证明正样本的分布对回归有影响,表明分布的失衡可以从左偏移到近似均匀,甚至右偏移,为训练最优阈值提供足够的样本。IoU-uniform R-CNN增加可控的抖动,并以这种方式只向回归变量提供近似一致的正输入边达到均衡。相对于其他方法,Oksuz等人的一个重要研究是系统地使用边界框生成器生成边界框,优化失衡问题的同时提高检测效率。
针对目标失衡问题,主要的工作是在anchor上做改进来优化失衡问题。Wang 等人提出同时学习锚的位置、尺度和长宽比属性,以减少锚的数量,同时提高召回率。利用在特征图上的完全卷积分类器,提出基于可变形卷积的锚特征自适应,以获得基于锚大小的平衡表示。2018年RefineDet算法改进SSD算法,采用ARM+ODM结合调整anchors的失衡,简化模型的同时优化失衡问题。2019年提出RepPoints,通过卷积的方式预测各个点的相对位置偏移,以此作为卷积网络的偏移量对原特征图进行卷积,得到重合率更高的特征与目标区域,再进行第二阶段的预测来优化失衡问题。Free anchor没有学习锚,而是减小匹配策略的硬约束。通过修改loss函数删去固定阈值使网络自主学习选择anchor 真实目标匹配。实验证明Free anchor 在COCO 数据集上获得43.1%的AP 值。
2020 年YOLO 系列中YOLOv4在输入端引入数据增强(Mosaic)、cmBN 模块;将主干网络更换为CSDarknet-53 结合Mish 激活函数;将原来的FPN 换为PANet 中的FPN;针对回归失衡问题采用CIOU_Loss 进行回归预测。实验证明YOLOv4 取得43.5%(AP),相比Free anchor 和RefineDet 的43.1%(AP)和41.0%(AP)有优势。
3.4 分类与回归失衡优化策略
针对分类与回归任务失衡问题,Jiang等人证明了基于CNN 的目标检测方法存在分类置信度和定位置信度不匹配问题,并设计IoU-Net来解决此类问题。IoU-Net学习预测每个检测得到的边界框和与之匹配的目标之间的IoU 作为该框的定位置信度。利用这种定位置信度,检测器能确保定位更准确的边界框在NMS 过程中被保留下来,从而改进NMS 过程。研究者在MS-COCO 数据集上进行了大量实验,证明IoU-Net的有效性。
Kendall 等人已经证明,基于多任务学习的模型的性能在很大程度上取决于每个任务损失之间的相对权重。但是以前的方法主要关注如何增强模型体系结构的识别能力。
2020 年出现的aLRP Loss(average localisationrecall-precision loss)是第一个用于分类和回归任务中的基于排名的损失函数且仅引入单个超参数。aLRP执行对高精度的分类实施高质量的定位,并且证明了正面和负面样本之间的平衡。
Double-Head RCNN的出现是一个转折点,开启了分类与回归的解耦之路。由于双阶段目标检测器中共享一个分类和回归的头部,然而对全连接头部和卷积头部结构之间缺乏联系。通过对比发现,两种头部可以实现互补。全连接头部可以更好地区分一个完整目标和一个目标的局部,用于分类任务,卷积头部输出更准确的回归边界框用于回归任务。在此基础之上研究者提出Double-Head RCNN。但由于输入到两个分支的是同一个proposal ROI pooling之后的特征,因此分类和回归任务失衡依然存在。Song 等人从空间维度上来解耦目标检测中的分类和回归失衡问题,作者证明分类和回归存在空间维度上的不对齐问题。即两个任务在特征学习时关注的点是不一样的,某些显著区域的特征可能具有丰富的分类信息,而边界附近的特征更有利于位置回归。TSD(task-aware spatial disentanglement)的出现为它们生成两个通过共享估计得到的解耦Proposal,将它们与空间维度解耦。实验表明,TSD 使COCO和谷歌Open-Image 上的所有主骨架和模型一致地增加约0.03 的mAP。
2021 年YOLO 系列提出一个无锚框的高性能目标检测器YOLOX,参考双阶段中的Double-Head RCNN 和TSD 中的思想用解耦头替换YOLO 的耦合检测头。实验结果如表5 所示,在速度增加的情况下,AP 精度提高0.8~2.9 个百分点。当网络结构较轻时,YOLOX-S 相较于YOLOv5-S 提升了2.9 个百分点,随着网络结构的加深和扩宽,AP 增长逐渐降低到0.8 个百分点。因此进一步研究探索如何精简网络结构成为关键。
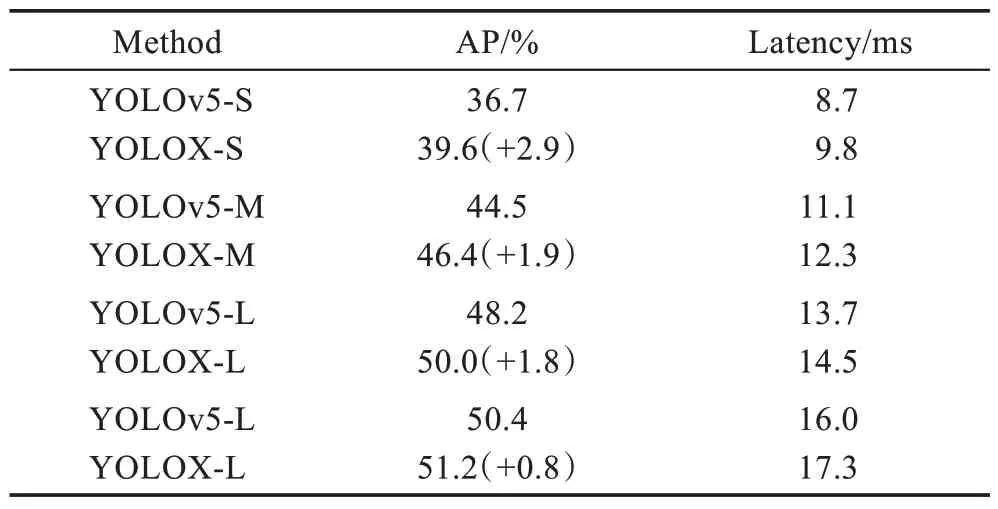
表5 YOLOX 性能对比Table 5 Performance comparison of YOLOX
在经典的失衡问题下,Yang 等人探索回归失衡问题提出了DIR(delving into deep imbalanced regression),并泛化到整个目标范围。分别提出LDS(labeldistribution smoothing)和FDS(feature distribution smoothing),运用目标之间的相似性解决在computer vision、NLP 和healthcare上的回归任务失衡。
单阶段中分类与回归失衡问题相较于双阶段更加严重,单阶段的分类任务和回归任务是并行分支且共享参数导致两个任务之间相互限制。TOOD(taskaligned one-stage object detection)设计T-head 增强分类与定位之间的相互作用,提出TAL 对两个任务进行显示对齐,该方法平衡学习任务交互和任务特定功能。实验证明在COCO数据集上达到51.1%AP。
RS(rank &sort)Loss的提出开辟了新的研究方向。该方案在没有额外辅助头的情况下对阳性样本属性(中心,IoU,mask-IoU)进行优先排序,也因此RS Loss 对目标失衡具有鲁棒性;使用无需调整的任务平衡系数来解决视觉检测器的多任务失衡问题。因此RS Loss 是采用一种简洁高效、基于损失且无需调参的启发式算法来平衡多任务中的失衡问题。
3.5 方案总结
本节系统总结分析应用深度学习的目标检测算法针对失衡问题提出的优化策略。
数据失衡问题主要改进思路是从采样的角度优化失衡问题,优势是直接且高效,局限性表现在内存和时间成本上。从表6~表8 可以得出以下结论:
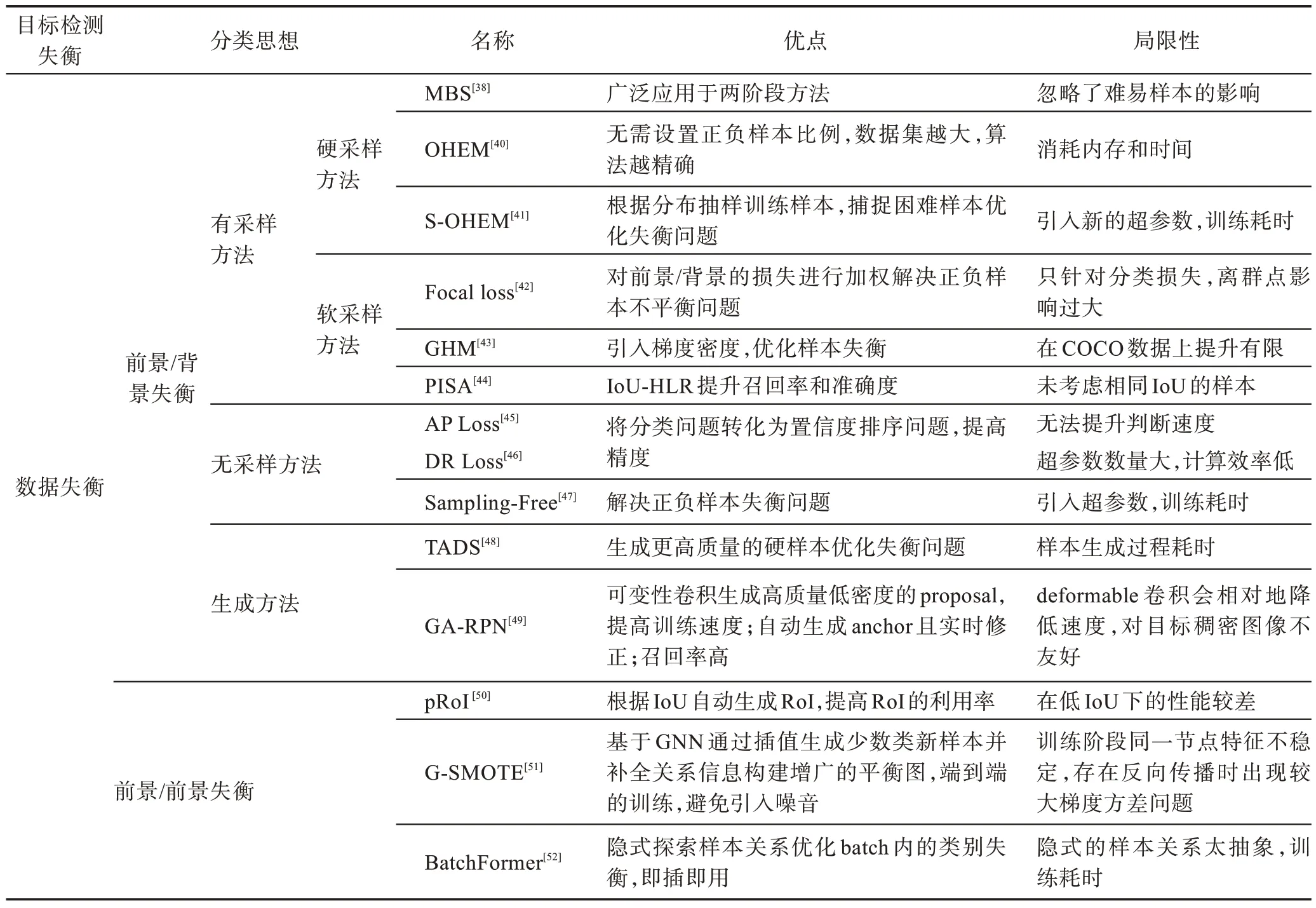
表6 前景/背景&前景/前景失衡优化策略总结Table 6 Summary of foreground/background&foreground/foreground imbalance optimization strategy
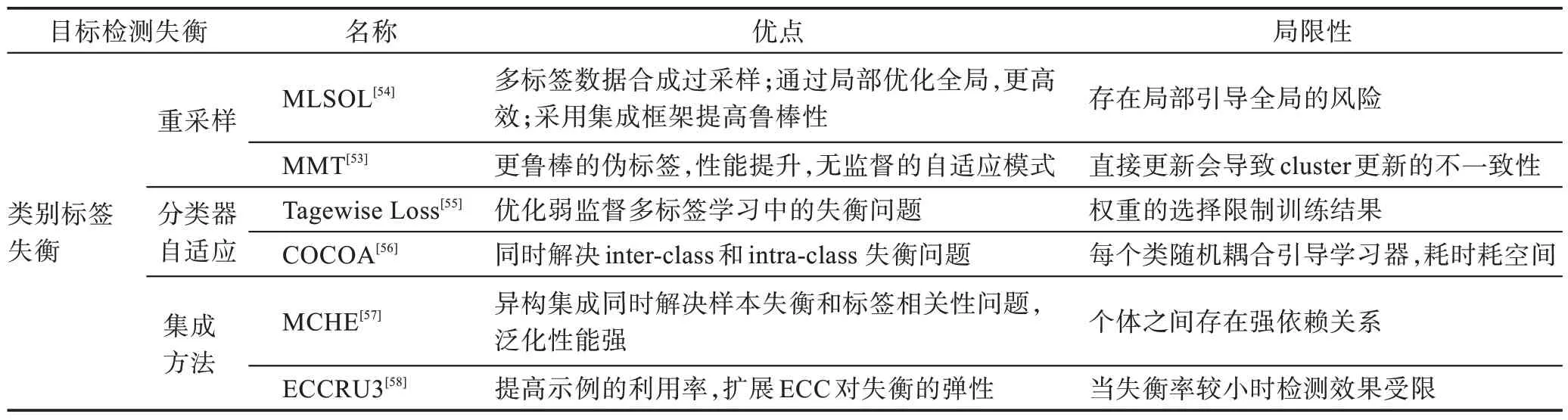
表7 类别标签失衡优化策略总结Table 7 Summary of category label imbalance optimization strategy

表8 长尾数据失衡优化策略总结Table 8 Summary of long-tail data imbalance optimization strategy
(1)前景/背景失衡的优化方案在早期主要采用硬采样,核心思想是设置固定数量或者比例的正负样本优化失衡问题,优势是启发式抽样提高算法精度,局限性主要表现在时间成本上。软采样方案的核心思想是通过对训练过程的相对权重来设定样本损失权重,优势是训练更高效,局限性表现在泛化性上。无采样方法的核心思想是引入新的分支,根据前一批样本预测后一批样本的权重。优势是分类问题转化为排序问题更精确,局限性表现为超参数过量。近期出现的生成式方案主要是基于GAN 的生成器和判别器组成的一系列方法,优势是提高召回率,局限性表现在训练时间上。
(2)前景/前景问题的优化主要是针对数据集失衡和每个批次内的类别失衡问题。基于数据集的失衡代表作是pRoI Generator,生成新的图像和类别进行优化;基于批次内的类别失衡优化思路是提升捕捉类间关系实现不同样本之间的协作关系,使得样本之间达到平衡如Batch Former。综合评价两种改进方向各有优缺点,并且探索样本关系会一直是优化前景/前景失衡的热门话题。
(3)类别标签失衡的优化策略中重采样方法是具有优势的,因为它脱离于分类器且不需要任何特定的多标签分类器来预处理MLD。但标签之间失衡的差异以及标签之间的高并发会直接影响重采样结果。因此在低并发的情况下是最有优势的策略。分类器自适应是依赖分类器进行优化的策略,优势是直接从数据集的分布中学习且自适应输出结果。但由于分类器是根据实验环境设计则很难在不同的环境中适用。集成方法的创新点在于集合几个基本模型的优点来产生一个最优的预测模型,可以完成多样化的多标签预测,异构集成突破了同时解决样本失衡和标签相关性的问题,然而该方案存在计算复杂性问题。
(4)长尾数据失衡的优化方案中类-再平衡方法相对简单,却取得很好的效果。但该方法是以牺牲头类性能为代价来改善尾类性能。虽然整体性能有所提高,却无法从本质上解决缺少信息的问题。为了解决这一局限性,提出对所有类进行信息扩充,即信息增益。信息增益的代表方案是数据增强,一种运用类条件统计量来优化失衡问题的方案。该方案可以保证在不牺牲头部信息的条件下提高尾部性能。然而,简单地使用现有的与类无关的增强技术来改进长尾学习是不利的,因为头部类有更多的样本会被更多地增强,存在进一步增加失衡的风险。模型改进方案中解耦训练越来越受到关注。该方法在类-再平衡分类器学习的第二阶段不引入大量计算开销,却带来显著的性能提升。解耦训练的思想在概念上很简单,易于设计解决各种长尾学习问题的新方法,但同时也伴随着训练时间的问题。
尺度失衡问题的核心改进思路是提升多尺度目标的检测效果,优势是实现多尺度目标检测性能,局限性表现在网络结构加深。表9 可以总结为:(1)目标实例/边界框失衡的优化策略主要是基于特征层的优化思路,从主干特征层次到图像与金字塔的结合是不断改进的过程,性能也在不断提升,但更进一步的模型改进遇到了瓶颈。(2)针对特征失衡问题的优化方案主要是基于FPN 的改进过程,如Libra FPN、Multi-level FPN、NAS-FPN 和GraphFPN,虽然该系列的改进取得显著效果,却在时间上有一定的局限性。当然也有PANet、ThunderNet、SSD、STDN 和Objectness Prior 等方案的进一步优化提升。主要研究趋势是克服时间和空间问题。
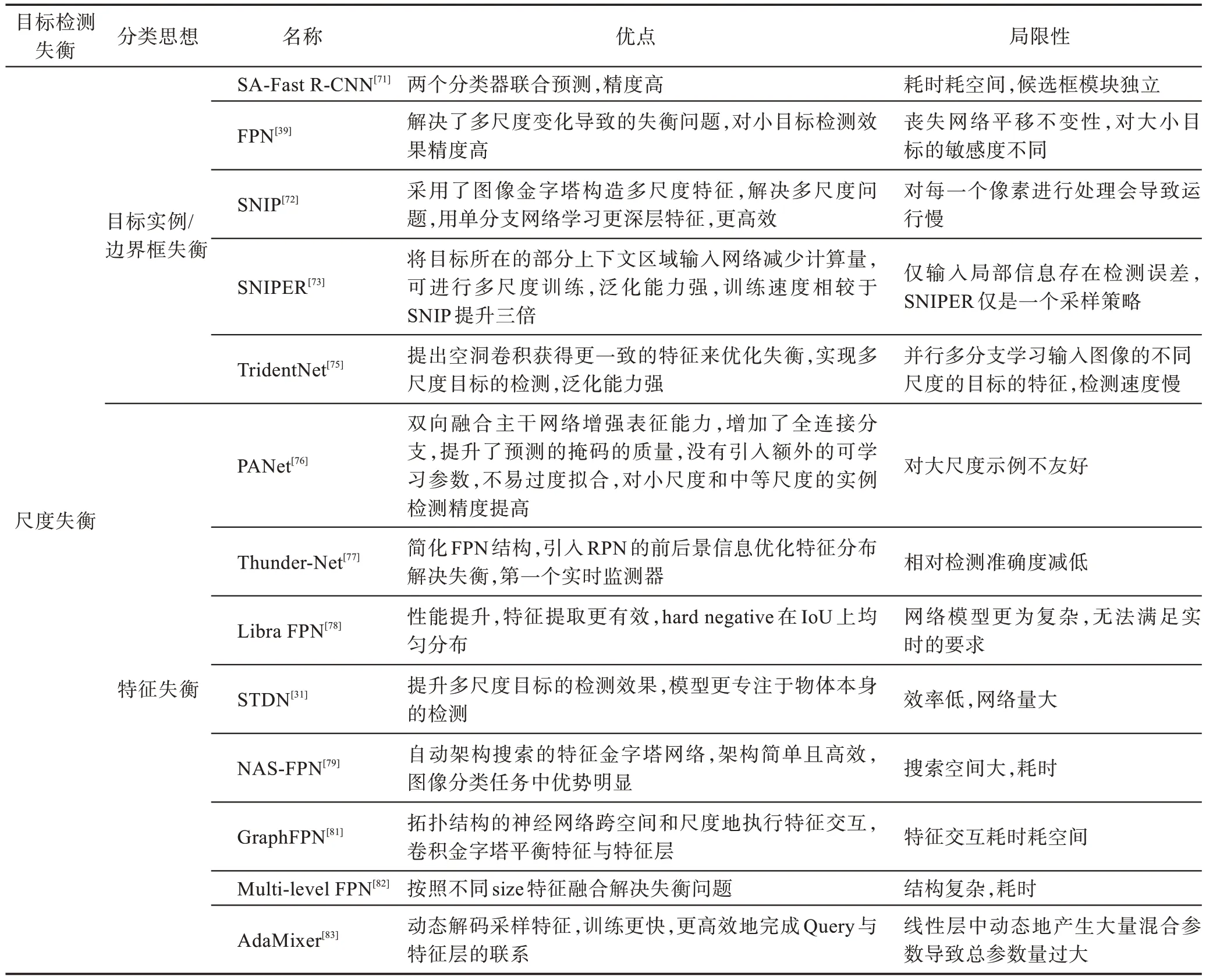
表9 尺度失衡优化策略总结Table 9 Summary of scale imbalance optimization strategy
相对空间失衡问题的改进思路分为回归和目标两类。表10 可以总结为:(1)回归失衡问题的改进是基于IOU 损失函数系列,优势是反映预测检测框与真实检测框的检测效果,局限性表现在收敛和退化问题上需要进一步研究。(2)目标失衡基于锚的方案和无锚点优化。基于锚点的优势是获得更精细的目标检测框,提高定位准确率;局限性是存储空间需求大和网络量较大影响检测速度。无锚点的方案优势是减少超参数,泛化能力强;局限性表现在检测精度偏低。因此提取更有价值的锚点成为研究热点。
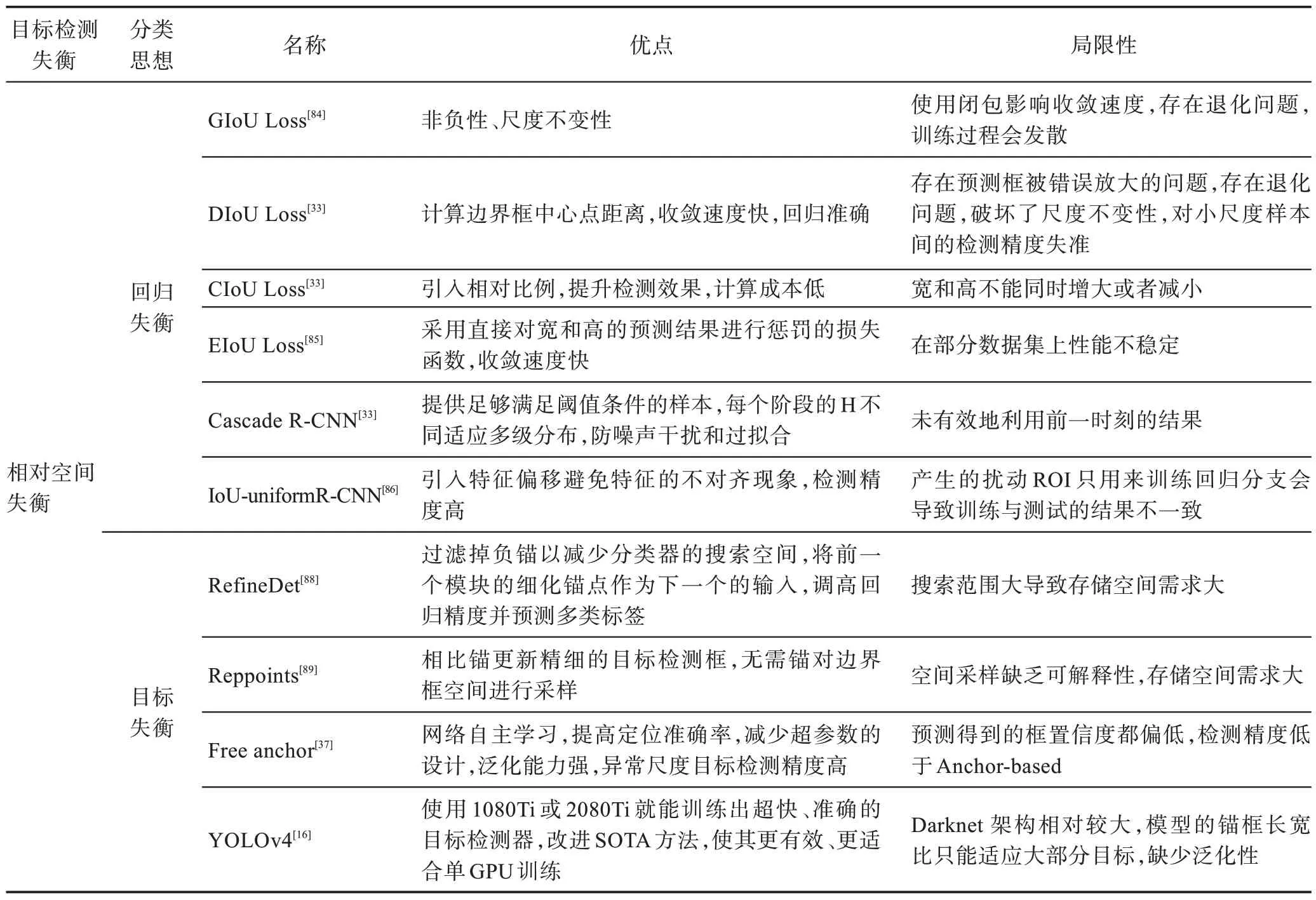
表10 相对空间失衡优化策略总结Table 10 Summary of relative spatial imbalance optimization strategy
分类与回归失衡的优化算法分为解耦和不解耦两个方向。如表11 所示优化方案主要在于如何设置权重来保持分类与回归平衡,如IoU-Net。此类方案是以一种控制的方式优化失衡,分类与回归失衡依然存在于每一个空间点。因此出现了新的研究方向在空间上对头部进行解耦来优化失衡问题,如Double-Head RCNN、TSD、TOOD 和YOLOX。这些优化方案都是运用解耦的思想使分类与回归达到时间或者空间上的平衡,但是网络模型在不断地扩宽,虽然失衡得到控制,性能有所提升,却导致训练和检测速度降低,难以满足端侧实时检测的要求,因此分类与回归失衡依然是一个有待解决的问题。
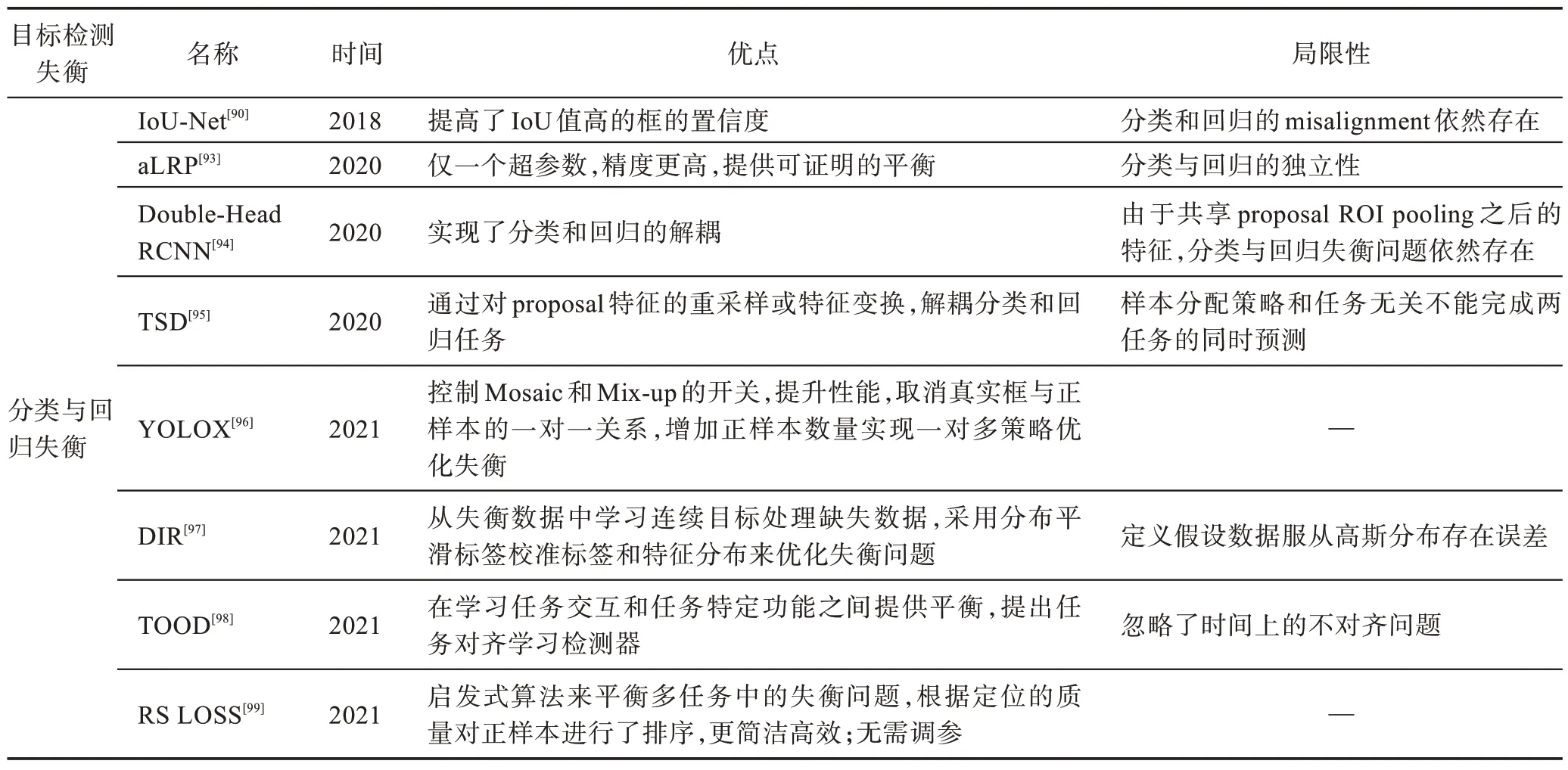
表11 分类与回归失衡优化策略总结Table 11 Summary of classification and regression imbalance optimization strategy
4 未来展望
随着特征提取网络的深入、优化和更新,目标检测的算法精度在逐步提升,但是依然存在待解决的问题。本文针对在深度学习系统中出现的目标失衡问题开展了一系列的优化策略总结,但随着应用环境和目标对象的多元化,检测难度越来越大。目标检测失衡问题也仍需解决,以下列出几个未来面临的主要挑战:
(1)抽象特征层语义提取方式。较高层次的特征包括对象或者部分对象的高级语义相对低层次的信息(边缘、轮廓等)更难提取。例如一只熊猫头的图片高层语义特征只显示一张脸的轮廓。目前的解决方案大多采用特征融合(FPN、HRNet),但会引入高低层特征信息不对等和高低层特征之间在空间上存在不对齐的问题。因此设计可行的特征筛选机制和利用图像的帧来对齐高低层特征或许可以提高高层语义的利用率。
(2)分析异常值和不变量对回归损失函数的影响。目前关于损失函数的研究方法中研究者根据具体问题描述损失函数的结果。例如,AP Loss 损失的计算是基于所有BBs 的置信度得分的单个示例的排名,因此损失是由整个集合得到而不是单个示例,却因单个或者个别异常值降低模型整体性能。因此是否可以借鉴LSTM 中“过滤门”的思想减小异常值和不变量引导整体的性能。
(3)剖析损失函数失衡问题,损失函数在深度学习目标检测中直接反映一个模型的性能。然而目前的研究都在优化损失失衡,未考虑失衡原因。基于距离度量的损失函数和基于概率分布计算的损失函数失衡的诱因不同。是否可以采用对抗训练的方式引入重构损失和分类损失对失衡问题引入额外约束探索此类问题。
(4)Anchors 相似性对失衡问题的影响,单阶段目标检测器的显著效果依赖于大量的锚,因此数据失衡问题在单阶段检测器中异常突出。Anchors 之间的相似性关系是否可以通过Anchor based 和Anchor free融合解决此类问题有待研究。
(5)量化与评估失衡问题,失衡问题发生在深度学习目标检测的每个环节。但在多样化的应用场景下如何量化失衡问题并且建模一个具有鲁棒性的评估模型将会是一个研究趋势。今后可以综合准确度、精度、召回率和平均精度等的计算方法评估每个环节的平衡度结果供研究人员参考。
目标检测作为计算机视觉任务的基础性研究,受到了很多学者的关注,近年来也取得了较大进展。本文从不同角度指出应用深度学习的通用目标检测算法中存在的失衡问题并总结目前的优化策略。未来,深度学习中的目标检测领域仍有许多问题需要解决,目标检测与各个领域的结合不断推动未来发展。
5 结束语
由于深度学习算法及其应用场景的多元化,检测失衡的问题也会随之有所差异,本着解决问题的角度,本文综述了目前一些具有代表性的优化策略。未来随着加速器以及应用场景的变化,相信此类问题会提出更好的优化方案。
猜你喜欢
电子产品世界(2022年4期)2022-04-21
中学生数理化(高中版.高一使用)(2021年2期)2021-03-19
计算机系统应用(2021年2期)2021-02-23
小天使·二年级语数英综合(2019年10期)2019-11-08
计算机测量与控制(2019年4期)2019-05-08
领导决策信息(2018年16期)2018-09-27
数学学习与研究(2017年3期)2017-03-09
共产党员(辽宁)(2015年2期)2015-12-06
科技视界(2015年24期)2015-08-22
读者·校园版(2015年19期)2015-05-14
