
基于样本构造和孪生胶囊网络的医学意图识别
2022-09-02 11:28龚建全王德军孟博
中南民族大学学报(自然科学版) 2022年5期
龚建全,王德军,孟博
(中南民族大学 计算机科学学院,武汉430074)
近年来,由于中国人口老龄化问题的加剧以及医疗资源的分配不均,各种医疗资源的需求加速增长.随着医疗信息化的普及和人机对话技术的发展,构建面向医疗诊断的智能对话系统成为了可能.医疗对话系统可通过互联网及时与患者沟通,收集患者的健康信息,生成电子病历,进而减轻医务人员的负担,提高医疗诊断的效率,具有重要的应用前景.医疗领域中意图识别作为自然语言理解的关键任务,可从患者话语中抽取出关键信息,从而服务于对话系统的下游任务,因此意图识别的好坏将直接影响对话系统的性能[1].近年来由中国中文信息学会发起的中文医疗信息处理挑战榜CBLUE 受到了研究人员的广泛关注,意图分类任务作为其中八大任务之一,对推动医疗信息处理的发展具有重要的意义.
意图识别又名意图分类,可看作一种短文本分类任务[2].区别于通用领域的意图识别,在医疗领域的非结构化文本中,存在大量医学知识和专业术语,面临着如下的难点:医学问句的特征稀疏,并且种类粒度细、不易区分.例如,相较于订票系统只包含订票、退票、改签、查询几个意图,医疗问题意图可粗粒度地分类为病症、药物、治疗、其他这几种一级类别,每种一级类别又可细粒度地拆分为几种甚至十几种二级类别.如病症可细分为疾病表述、病因分析、病情诊断、就医建议等意图,这导致医疗领域包含的问题意图类别较多,与此同时相似意图之间容易产生混淆,因此医疗领域意图识别任务的识别准确率不高.
针对上述意图识别在医疗领域存在的问题,提出了基于样本构造和孪生胶囊网络的医学意图识别方法,以下是本文的主要贡献:
(1)为了在有限的医学问句中学习到对应意图的语义特征,本文将意图识别任务转化为语义相似度任务,构造出问句对相似度样本和问句-意图对相似度样本进行分阶段训练,一阶段训练将问句对输入模型,将相同意图的问句映射到同一向量空间;二阶段训练将问句-意图对输入模型,将意图标签映射到对应问句的向量空间.
(2)提出一种结合BERT 和胶囊网络的孪生网络 模 型(S-BCN),采 用BERT 预 训 练 模 型(Bidirectional Encoder Representations from Transformers)[3]提取上下文语义特征,并通过胶囊网络(Capsule Network)提取局部语义特征,再通过相似度计算出融合全局特征和局部特征的向量的语义相似度,同时利用孪生网络共享参数的特性,实现了任务的转化并减轻了训练负担.
1 相关工作
意图指的是对话系统中用户的意愿和行为,如预定机票、查询餐馆等.首先,专家根据对话系统的需求预定义好意图类别,再根据用户给出的问题话语以及所涉及的相关领域进行分类[4].针对意图识别问题,国内外的研究人员已对其进行了大量的研究和探索.目前意图识别方法主要分为两类:基于规则的意图识别方法和基于机器学习的意图识别方法[5].
1.1 基于规则的意图识别方法
早期的意图识别方法,通常由领域内的专家来制定.专家根据领域知识以及语料库的分析,构建出一系列规则将用户问句进行分类[6].该方法通常根据所制定的规则获取到用户问句的关键词,将关键词与专家所构建的同义词词库进行比对,含有与关键词相似词汇的词库会被分到对应的意图类别.LI 等[7]通过实验研究发现,用户的不同表达方式会导致语料库的规模逐渐增大,因此专家需要制定更多的规则、更丰富的词库来达到对应的分类效果,这种方法会造成工作量急剧增加.并且,通过规则制定的意图识别方法不具有泛化能力,限定领域的规则往往只能用在限定用户问句的语料库中,一旦应用到其他领域中,识别效果可能会很差.因此,使用基于规则的方法进行意图识别时,更换用户文本的类别将导致专家重新制定一套规则来进行分类,不具有通用性.
1.2 基于机器学习的意图识别方法
近年来,随着机器学习技术的发展,各种深度学习模型在实体识别、信息抽取、机器翻译等各项任务上得到了广泛应用.基于机器学习的方法通过在大量标注好的语料库上进行训练得到分类模型,而使用不同架构的深度学习模型训练会产生不一样的分类效果.CHO 等[8]提出使用循环神经网络(Recurrent Neural Network,RNN)构造文本在向量空间中的表示,该模型可以通过上下文学习到对应的语义信息,但容易产生语义偏执问题.KIM 等[9]通过使用卷积神经网络(Convolutional Neural Networks,CNN)应用到句子分类任务上解决了该问题,并且取得了较好的效果.CNN 最早被应用到图像分类中,卷积核都较为简单,只能学习到语义的局部特征.针对此问题,XIA 等[10]提出一种基于胶囊网络的意图识别模型,通过动态路由机制提取到每种意图对应的语义表示,在识别效果上有了很好的提升.鉴于单个模型识别的局限性,GOO 等[11]提出一种意图识别和语义槽填充联合识别的模型,通过使用槽位门控机制来学习意图和语义槽两者间的联系.BERT 模型采用一种双向transformer[12]编码架构进一步提升了意图识别的效果,利用掩码语言模型(Masked Language Model)解决了模型单向表征能力的限制,因此能学习到上下文深层的语义特征.与基于规则的意图识别方法相比,基于机器学习的方法在识别效果和泛化能力上都有了明显的提升.
综上所述,意图识别的关键在于模型是否能从问句中学习到对应意图的语义特征.GE 等[13]通过构造弱语义负样本使CNN 模型能更好地学习到样本的图像特征,同时证明了构造样本对提升图像分类任务甚至所有分类任务的效果的重要性.本文受上述文献的启发,通过任务的转化构造问句对相似度样本和问句-意图对相似度样本进行分阶段学习,同时融合BERT 模型提取的上下文语义特征和胶囊网络提取的局部特征,提升意图识别的效果.
2 基于样本构造和孪生胶囊网络的意图识别方法
区别于常规的文本分类算法进行意图识别,本文提出一种基于样本构造和孪生胶囊网络的医学意图识别模型S-BCN,通过“转化—计算—打分”的途径,将意图识别问题转化为语义相似度问题.首先将意图分类数据集构造出问句对相似度样本和问句-意图对相似度样本,一阶段将问句对相似度样本输入模型进行初步训练;二阶段将问句-意图对输入模型再次进行训练,最后将测试集输入模型计算问句和每个意图标签的相似度,通过打分模块得到问句的预测标签.系统流程如图1所示,总共包含以下3个部分:①相似度样本构造;②孪生胶囊网络模型;③打分模块.本节将对系统的3个部分分别进行详细地介绍.

图1 S-BCN模型结构图Fig.1 S-BCN model structure diagram
2.1 相似度样本构造
2.1.1 问句对相似度样本构造
意图识别任务中,数据集通常为Query-Label 这种成对形式.问句对相似度样本的构造通过将同种意图的问句对当作正样本,并令其语义相似度为1;将异种意图的问句对当作负样本,并令其语义相似度为0.如图2所示,通过转化为语义相似度任务,构造出一个相似度标签,训练数据样本格式转化为三元组的字符串列表形式,正样本为(Query1,Query2,1),负样本为(Query1,Query2,0),并将这些样本输入孪生胶囊网络模型进行一阶段训练.

图2 问句对相似度样本构造Fig.2 Construction of question pair similarity sample
2.1.2 问句-意图对相似度样本构造
问句-意图对相似度样本的构造运用拆解法的思想,把单个的多分类任务划分为多个二分类任务.其中,将每个医学问句和对应的正确意图当作正样本,并令其语义相似度为1;剩余的所有意图标签均作为负样本,并令其语义相似度为0.该方法构造出的问句-意图对相似度样本的正样本形式为(Query,Label,1),负样本形式为(Query,Label,0),如图3 所示.这些样本将输入孪生胶囊网络模型进行二阶段训练.
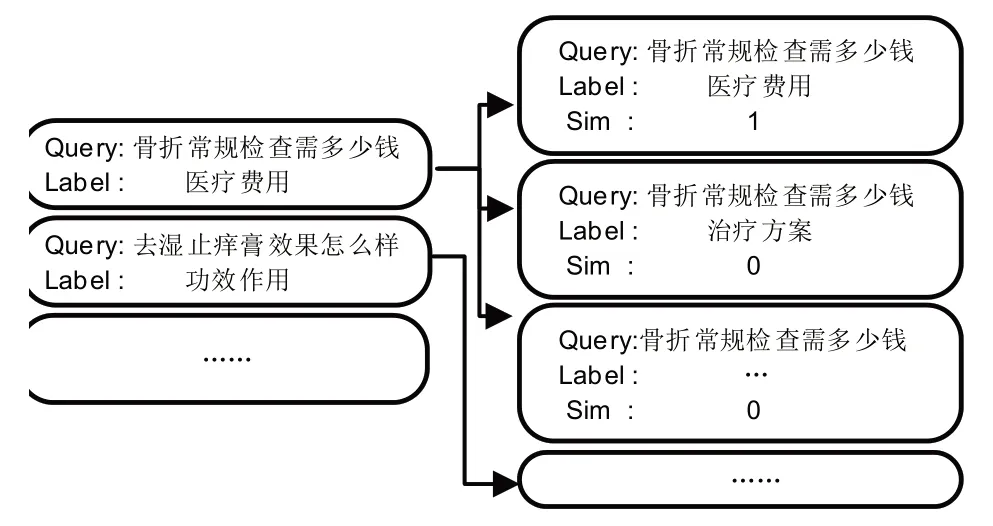
图3 问句-意图对相似度样本构造Fig.3 Construction of question-intent pair similarity sample
综上所述,通过对意图分类数据集进行任务转化具有两点优势:(1)通过相似度样本构造提升数据利用率,解决数据稀缺问题;(2)两类样本分阶段训练,充分利用孪生网络的优势,使模型更好地学习到相似问句及问句与意图间的映射关系.
2.2 孪生胶囊网络模型
本文将BERT 模型的注意力机制与胶囊网络的动态路由机制[14]相结合,同时利用孪生网络[15]共享权重的特性,提出一种基于孪生胶囊网络的医学意图识别模型S-BCN.如图1 所示,模型主要包含以下3 个模块:BERT 预训练模型层,将医学问句或意图标签进行语义编码,生成词向量矩阵;胶囊网络层,利用动态路由机制提取句子的局部语义特征,得到句子的向量表示;相似度计算,用来衡量两个向量表示的差异性.
2.2.1 BERT预训练模型层
采用孪生BERT 网络分别在两个样本集上进行微调,其中一端将给定的医学问句转化为标准序列“[CLS]q1q2…qn[SEP]”作为输入,另一端将给定的医学问句或意图标签转化为标准序列“[CLS]l1l2…ln[SEP]”作为输入,两个网络共享权重,经由BERT将句子的每个词语输出对应的词向量,其中句子最大长度设为L,词向量维度为V,生成词向量矩阵X如公式(1):

2.2.2 胶囊网络层
胶囊网络层包括3个模块:卷积层、采用向量化胶囊的主胶囊层、采用动态路由机制的卷积胶囊层.
卷积层为常规的卷积神经网络,设该层包含N1个卷积核W,其高度为K、宽度为V,词向量元素yi经过卷积运算如公式(2)所示:

其中f表示ReLU 激活函数,b表示其偏置,因此可计算出特征矩阵Y如公式(3)所示:
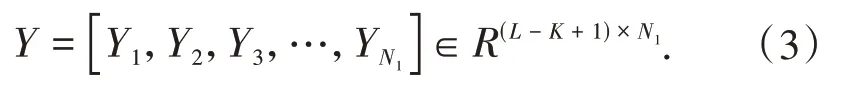
主胶囊层区别于卷积神经网络,该层融合句子相同位置的语义特征,保存为向量化的胶囊,通过采用N2个m维的转换矩阵N2×1×m,把上一步得到的特征矩阵Y转化为胶囊矩阵Z,如公式(4)所示:

卷积胶囊层的作用是建立上层胶囊与下层胶囊之间的连接关系.首先通过N3个m×m的转换矩阵W3对Z的K1行胶囊进行线性变换,计算出预测向量zi,如公式(5)所示:

然 后 再 对进行加权和运算得到uj,如公式(6)所示:

其中ci为动态路由过程更新的耦合系数,由该层的胶囊与上层的胶囊uj连接的权重bi经过softmax 函数运算得出,其中权重bi的更新方法如公式(7)所示:

其中bi为上次迭代得到的权重,初始化为0.从而计算出最终的胶囊矩阵U,如公式(8)所示:
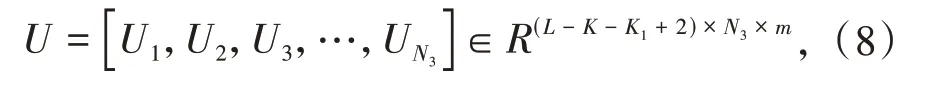
对模型两端输出的胶囊矩阵进行池化操作,最终得到两个输入文本的向量表示s和t.
2.2.3 相似度计算
为了衡量孪生胶囊网络两端输入文本的差异,需要计算由上一层得到的两个句子向量表示的语义相似度.目前常见的相似度的计算方法有:欧式距离、曼哈顿距离、余弦相似度等.本文通过使用各种相似度计算方法进行实验,最终选取余弦相似度作为衡量两个句子向量表示差异的标准.
余弦相似度(Cosine Similarity)利用测量两个向量之间的夹角大小来计算它们的相似程度,其数值体现在它们的余弦值,因此其夹角越小,余弦相似度就越接近于1.对于n维空间的两个向量s和t,其余弦相似度计算如公式(9)所示:

2.3 打分模块
根据训练好的孪生胶囊网络模型,可计算出医学问句和所有意图标签的意图相似度.设有n种意图类别,医学问句映射的向量表示为s,意图标签的向量表示为ti(i∈[1,n]),则其问句-意图相似度为Cosine_Sim(s,ti),进而得到医学问句的预测意图集合,根据问句-意图相似度打分排序,取最大值作为该医学问句的预测意图,如公式(10)所示:

3 实验
3.1 实验数据
本文使用中文医疗信息处理挑战榜CBLUE(Chinese Biomedical Language Understanding Evaluation)的医疗搜索检索词意图分类任务的数据集进行实验[16].该榜单是由中国中文信息学会医疗健康与生物信息处理专业委员会发起的一个多任务榜单,包含中文医学命名实体识别、实体关系抽取、临床术语标准化等8个子任务.该数据集由往年的CHIP(China Health Information Processing)会议发布的学术评测以及阿里夸克医疗搜索提供的数据构成,数据来源包括医学相关的临床试验、电子病历、医学书籍以及来自搜索引擎的搜索日志.其中医疗搜索检索词意图分类任务的数据统计如表1所示.

表1 意图分类数据集统计Tab.1 Intent classification dataset statistics
该数据集包含医学搜索中常见的医学问句以及对应的包含病情诊断、病因分析、治疗方案等11种意图标签,其中训练集的医学意图数据样例及其占比如表2所示.

表2 医学意图及问句示例Tab.2 Examples of medical intents and questions
为了检测孪生胶囊网络在医学意图识别任务上的表现,本文基于CBLUE 提供的意图分类数据集构造出问句对相似度数据集和问句-意图对相似度数据集,其中问句对相似度样本形式为(Query1,Query2,Label),样例如表3所示.

表3 问句对相似度数据集示例Tab.3 Examples of question pair similarity dataset
问句-意图对相似度样本形式为(Query,Intent,Label),样例如表4所示.

表4 问句-意图对相似度数据集示例Tab.4 Examples of question-intent pair similarity dataset
3.2 模型设置
本实验BERT 预训练模型层采用词向量维度为300(V=300),输入文本最大长度为300 字(L=300).胶囊网络层中,卷积层采用窗口大小设为3(K=3)的卷积核,数量为32个(N1=32),其步长为1,主胶囊层胶囊向量维度为16(m=16),转移矩阵数量为32(N2=32),卷积胶囊层采用窗口大小设为3(K1=3)的转换矩阵,数量为16个(N3=16).网络训练的批处理大小 设 为25(batch_size=25),学 习 率 设 为1.5×10-4(learning_rate=1.5×10-4),采用Adam作为模型的优化器.
3.3 评估指标
为了评估模型在意图识别上的性能,本文使用准确率(Accuracy)作为医疗搜索检索词意图分类任务的评估指标,计算方式如公式(11)所示:

3.4 实验结果
为了验证本方法在医疗领域意图识别任务上的有效性,实验选取了多个模型与本文模型S-BCN进行对比实验:BERT 预训练模型(Bidirectional Encoder Representations from Transformers,BERT),卷积神经网络模型(Convolutional Neural Network,CNN),双向长短期记忆网络模型(Bi-directional Long Short-Term Memory,Bi-LSTM),胶 囊 网 络 模 型(Capsule-Network),结 合BERT 和 胶 囊 网 络 模 型(BERT+Capsule-Network).最终实验结果如表5所示.

表5 各模型的意图识别结果Tab.5 Intention detection results of each model
通过表5 可知,CNN 由于只能实现局部特征的提取,具有一定的局限性;Bi-LSTM 因其对输入文本的记忆性,识别率有了一定的提升;胶囊网络利用动态路由机制,采用投票的方式将提取的语义分配到父级的预测向量,提升了预测效果;BERT 基线模型采用全词掩码技术,达到了不错的准确率.而本文提出的基于孪生胶囊网络的意图识别模型SBCN,识别效果优于其他模型,准确率达到86.76%,相比BERT基线模型提高2.61%,说明本文方法可以有效提升意图识别的准确率.
3.5 实验分析
本文从模型预测结果中选取了几个典型样例进行分析,其中包含BERT 模型和本文模型S-BCN均预测正确的样本、仅本文模型S-BCN 预测正确的样本以及均预测错误的样本各两例,如表6所示.

表6 预测样例分析Tab.6 Analysis of prediction samples
从预测样例可分析得出以下结论:①对于医学问句的一些常见表达以及包含与意图相关的关键词的一类句子,大部分模型都能预测出正确意图,例如“心肌缺血如何治疗与调养呢”这种询问治疗方案的常见表达很容易被模型正确识别;②对于包含专有名词的一些医学问题,例如“小三阳”在医学中指乙肝患者携带的乙肝病毒的免疫学指标,BERT模型对这一类问题预测出了错误的意图.此外,对于“胃癌医院看病贵不贵”这一样例,BERT 模型可能因为检测到“医院”这一词的特征,而大部分“就医建议”对应的医学问题均包含这一关键词,因此预测意图为“就医建议”,而本文的模型S-BCN 通过样本构造和注意力机制与动态路由机制相结合的优势,充分提取出该意图类问题的语义特征,得到正确的结果;③对于“CT”这类口语化缩写以及“孕酮”这类医学专业词汇,使用常规模型和本文模型均没有得到正确的意图预测,这类医学问句需要模型利用足够的专业领域知识来理解其上下文语义才能得到正确的预测结果.
综上所述,从仅本文模型预测正确的样本上看,本文提出的基于样本构造和孪生胶囊网络的意图识别方法通过相似度任务的转化来构造成对样本,提高了数据利用率;并且由于孪生网络共享网络参数的优势以及注意力机制与动态路由机制相结合,使模型提取到了每个医学意图更多的语义特征,从而达到更高的意图识别准确率.从本文模型预测错误的样本上看,对于一类口语化描述以及包含专业医学词汇的问题,本文模型未能预测出正确的结果.
4 总结
本文针对医学问句特征稀疏、意图种类易混淆的问题,通过相似度任务的转化,提出了基于样本构造和孪生胶囊网络的医学意图识别模型S-BCN.该模型将BERT 的注意力机制与胶囊网络的动态路由机制相结合,解决了网络的局限性,同时利用孪生网络实现了任务的转化.实验证明:本文提出的方法对医学领域意图识别任务是有效的.
此外,本文探究了BERT模型与本文模型的差异,分析出本文模型的优势以及在医学领域意图识别中存在的问题,未来将在模型中融入医学领域专业知识作为研究方向,进一步提高本文方法的识别准确率.
猜你喜欢
法律方法(2022年2期)2022-10-20
北京航空航天大学学报(2022年8期)2022-08-31
中老年保健(2022年3期)2022-08-24
汽车实用技术(2022年14期)2022-07-30
福建基础教育研究(2022年4期)2022-05-16
现代装饰(2021年2期)2021-07-21
小学生优秀作文(低年级)(2020年4期)2020-07-24
长江学术(2016年4期)2016-03-11
长江学术(2015年1期)2015-02-27
延河(下半月)(2014年3期)2014-02-28
