
基于多源异构的能源数据处理技术研究
2022-09-02 06:25潘建宏张俊茹郝保中
电子设计工程 2022年16期
潘建宏,张 帆,王 磊,张俊茹,郝保中
(1.国网吉林省电力有限公司,吉林长春 130000;2.国家电网有限公司大数据中心,北京 100052;3.国网辽源供电公司,吉林 辽源 136200;4.国网白城供电公司,吉林 白城 137000)
近年来,5G 与人工智能技术的迅速发展使能源行业数据呈现出指数级的增长;此外,冷-热-电综合能源系统的运行和管理模式越来越复杂,相关数据监测传感网络的建设快速推进,使能源大数据呈现出类型多、数量多等典型特征[1-3]。虽然能源数据发展前景明朗,但也遇到数据质量与多源异构数据融合的挑战[4-6]。而能源大数据的准确识别取决于数据质量,且能源数据的误差会影响数据处理的精度,并造成数据判断失误[7]。多源异构数据融合是处理能源大数据的关键,对融合不同种类的能源数据有促进作用,因此该文开展了基于多源异构的能源数据处理技术研究。
能源大数据中90%以上均为实时测量的数据,因此在辨识的过程中主要以测量数据为主,以判断数据质量的优劣。通常而言,当数据误差大于5%时,判断为不良数据[8-9]。文献[10]通过分析数据之间的相关性,将相关性理论引入到能源大数据的不良数据识别中,并提出不良数据的相关性识别方法。文献[11]提出无监督学习的能源大数据识别算法,通过训练样本数据确定模型参数,但该方法对样本数据依赖性强,且不利于工程化应用。
针对上述问题,该文提出一种基于多源异构的能源数据处理技术,以SCADA 系统内潮流数据作为样本数据,通过仿真分析验证了所提方法的有效性。
1 基于随机森林的多源异构数据融合
1.1 多源异构能源数据感知
基于不同的能源大数据,能够从不同的角度建立数据模型,但由于建模的标准并未完全统一,所以目前还存在有数据不规范的问题,而采用基于随机森林模型建立能源大数据训练网络,能够较好地解决多源异构数据融合问题[12]。
能源数据感知是构建能源异构数据的基础,并且关系到数据识别的精度[13]。随着近年来科学技术的不断发展,大量能源传感器被部署在数据能源终端,并通过网络相连接,进而实现了不同形式的能源数据融合。通常能源数据传感器的位置可用下式表示:
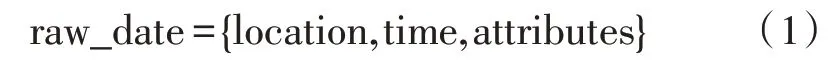
其中,位置信息通常用离散数值表示。而根据location 的位置信息,可获得能源数据的行与列信息;attributes 为用于标识数据的感知信息,采用“键-值”信息对表示一个或多个数据集合。为保证原始数据与目标的关联性,基于位置信息对原始数据进行网格化和归一化处理,从而保证网络内数据的统一性:

式中,Di为数据传感器处于地点i到网络中心点(xc,yc)的距离,经整合可得到:

通过对原始数据进行数据集合,生成数据训练集与测试集,从而验证模型的准确率及优化模型的性能。
1.2 多源异构能源数据融合建模
在给定的定义域D内,包含多源异构数据集合S,其到目标任务的推理模型可表示为:
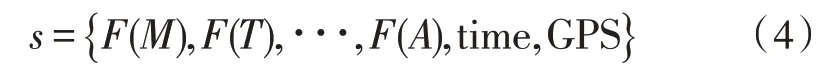
式中,F(M) 为基于气象数据M的特征抽取,time 为时间,GPS 为地理位置信息。那么,对于目标任务g即可构建训练样本集D1:

若目标任务g为未知时,训练样本集则可用D2表示为:

样本训练集D1可用传统的机器学习技术处理,但对于未知目标任务的训练样本集D2却无法使用,此外,样本数量过少也会降低模型的精确度。需要注意的是,在多源异构数据的融合过程中,不能使用固定数据模型进行训练。
1.3 基于随机森林的多源异构数据融合框架
基于随机森林算法提出的能源大数据MCS-RF框架,实现了能源大数据的半监督学习,并通过采用增量学习与离线学习的思想,在在线训练实时图像数据中用增量学习方法对模型剪枝进行更新,从而解决大数据的稀疏问题。
随机森林为一组决策树,假设第t棵树为ft=f(x,θt):X→Y,其中θt为捕获能源大数据的随机向量,整个森林被表示为:F={f1,f2,···,fT},其中T为森林树的数量,那么能源数据的评估概率可以定义为:
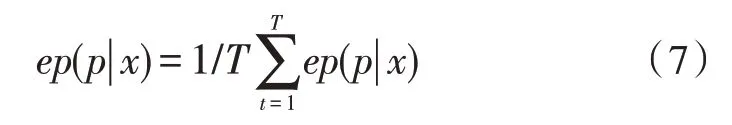
式中,ep(p|x)为第t棵树的叶子概率密度,且森林树的决策函数可表示为:

若ma(x,p)>0,则可得泛函误差为:

式中,E为求取数学期望,也可以通过(x,p)得到整体分布。
由于能源大数据的某些信息无法标注,使用半监督学习算法的损失函数可表示为:
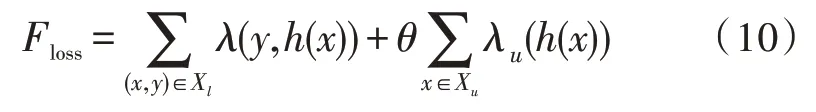
式中,Xl、Xu分别为标记数据与未标记数据,h(·)为二分类器,λu(·)为对未标记数据进行编码的样本数据。
2 能源数据处理技术
2.1 能源数据的不良数据辨识
在数据采集与处理的过程中,周围环境的变化以及通信信号的不稳定性,都会导致能源样本数据采集出现一定的误差,并影响数据的准确度与数据分析结果,因此需要采取措施对噪声数据进行修复[14-15]。目前,不良数据的辨识通常是基于能源数据的状态估计,随着数据量的增加、辨识次数变多以及运算量的增大[16],若能在数据收集阶段引入不良数据的辨识技术,将有利于对数据的进一步处理。能源系统状态估计能够在测量误差的情况下配置系统的真实状态,为保证数据的高质量提供基础,其测量方程z可表示为:

式中,h(x)为测量函数,v为服从正态分布的测量误差。因为测量误差经常发生变化,为方便计算,可以将目标函数重新定义为:

式中,wi为测量误差权重,通常取为测量方差的倒数。
应用最优化的思路,用加权最小二乘法表示误差目标函数为:

式中,R为方差矩阵,其维数为m、对角元素为。残差搜索法是目前处理残差应用较为广泛的一种方法,其工作流程如图1 所示[17]。

图1 残差搜索法工作流程
2.2 能源数据的异构融合
能源数据具有数量大、种类多的特点,通常由不同的系统采集得到,而各个系统之间的数据无法交互,难以实现数据共享,不利于数据的统一管理。为了实现能源数据的多源融合,需要对数据进行清洗和去噪处理。而当数据出现缺失时,将会导致整体数据挖掘不充分、应用不全面,因此需要采用数据挖掘算法对数据进行聚类处理来实现融合。
聚类本质上属于无监督范畴,对于不同类的能源数据,需要采用不同的聚类算法。关联规则是对不同事务之间的数据挖掘,目的是辅助决策者制定策略,最典型的关联规则算法为Apriori 算法,其采用逐层生成测试策略,主要思路为先确定阈值,再找到频繁属性集X的非空子集Y,从而生成X与Y之间的关联规则。Apriori 算法的基本流程如图2 所示。

图2 Apriori算法的基本流程
2.3 数据离散化处理
为了消除能源大数据中的冗余信息,需要将离散数据转换为适用于关联规则的数据,其基本思路是将连续数据分为多个区间,为了减少数据存储的片区,并将原始样本数据转为离散数据,该文应用k-means 算法将大数据转化为离散数据集,主要原理如下:
首先定义误差平方和函数,计算样本xi与xj的欧式距离:

然后,进行平方和准则计算:

式中,k为聚类个数,C为聚类集合,mi为样本均值。
紧接着定义样本数据置信度,应用关联规则计算出现的支持度计数,计算公式如下:

式中,|db(l,o)|=|(n-o)/l|为总的数据子集个数。若支持度不超过用户设定值,则表示在该周期内其为强关联规则。周期性关联规则挖掘流程如图3所示。

图3 周期性关联规则挖掘流程
3 算例分析
该文以SCADA 系统内潮流数据作为样本数据,其测量值的标准差为0.02,相角标准差为0.005,仿真分析某市35 kV 线路的电力数据,模拟分析4~6 月内的潮流数据变化。实验每隔1 min 采集一次SCADA 系统内的潮流数据,每天共1 440 个样本数据,其存储格式如表1 所示。

表1 原始数据存储单元
设置聚类个数k=8,经过分析,虽然得到的3个月内数据聚类结果各不相同,但也有部分相似之处。为了得到统一的数据,首先采用聚类方法对数据结果进行处理,然后进行离散化处理,建立关联规则数据库,从而得到有功功率的离散等级,如表2 所示。

表2 能源数据P值离散等级结果
以天为单位设置样本数据标号,随机选取其中72 个样本数据为不良数据,来验证该文方法的可行性。对于不良数据,分别选取4 个良好样本数据分别为T4、P4、Q5、I2,对其进行辨识处理后生成不良数据集合。基于关联规则匹配发现T4 时刻出现不良电流数据,再通过测量残差来搜索出全部数据的测量值,从而证实了T4 采样时刻的电流数据为不良数据。对于多个数据而言,可以分别设置两个不良数据点,再按照该文所述方法即可得到辨识结果,如表3 所示。
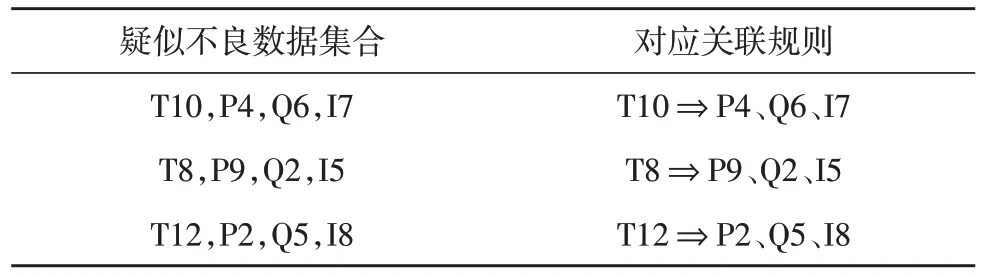
表3 多个不良数据辨识结果
若基于传统的残差算法进行识别、排序和测量,需要计算到不再出现阈值外的数据为止。当存在多个不良数据时,两种方法所需辨识次数的对比如表4所示。从表中能够看出,该文所提方法的识别次数较少,且综合性能更优。

表4 辨识次数对比
4 结束语
应用大数据处理技术对多源异构的能源数据进行分析和处理,是当今综合能源系统的发展趋势。在此背景下,该文将关联规则的数据挖掘方法应用于能源系统中。采用随机森林完成了数据融合,基于增量学习与离线学习的思想搭建了能源大数据的MCS-RF 框架,通过将离散数据转为适用于关联规则的数据,提高了不良数据的识别及能源数据状态估计的准确性。但在处理离散数据时使用了k-means聚类方法,所以计算结果容易受到主观因素的影响。为此,在下一步研究工作中将考虑应用HAC 层次凝聚式聚类法来处理离散数据。
猜你喜欢
中国交通信息化(2022年7期)2022-10-27
小学教学研究(2022年5期)2022-04-28
新世纪智能(数学备考)(2021年9期)2021-11-24
当代陕西(2019年15期)2019-09-02
电子制作(2019年14期)2019-08-20
商周刊(2019年1期)2019-01-31
学苑创造·A版(2018年11期)2018-02-01
雷达学报(2017年6期)2017-03-26
读者(2017年5期)2017-02-15
互联网天地(2016年1期)2016-05-04
