
低压台区分段线损率预测系统设计
2022-09-01 10:38汤中壹金杭晓姚雅艳周缘杰
自动化仪表 2022年8期
汤中壹,金杭晓,姚雅艳,周缘杰,陈 瑜
(国网浙江省电力有限公司缙云供电公司,浙江 丽水 321400)
0 引言
在为用户供电的过程中,电力系统会受到阻抗作用而产生一定的线损。线损表示一种电量的损失。如果线损过大,则经济收益减少,不利于电力设备的运行。对低压台区进行线损率预测,是目前供电企业重点研究的科研项目之一。这不仅能够提高企业的经济效益,在当前可持续发展的要求下,还能够促进节能减排,为构建绿色低碳型社会提供支撑。
文献[1]建立了一个基于专家样本库和最小二乘支持向量机的线损率预测模型。该模型采用优化的离散粒子群算法,在低压台区的工作运行记录数据中筛选出运行状态信息,并将其作为样本记录;以此为基础建立专家样本库,对配电网的供电量、电流等信息进行记录;在专家样本库的基础上,结合最小二乘支持向量机算法,完成线损率预测模型的建立。但该方法运算过程复杂,收敛速度较低。文献[2]提出了基于大数据分析的低压配电台区线损自动测算方法。该方法利用大数据分析方法构建定量回归分析模型;利用分段检验分析配电台区线损的大数据序列,构建数据相空间的重构模型;利用递归图谱分析对低压配电台区所产生的线损进行定量回归分析,得到规则性特征完成低压配电台区线损率的预测和度量。该方法面对庞大且复杂的低压台区供电数据流时,预测准确性不高。
基于上述方法的不足,为解决收敛速度慢和线损率预测准确性低的问题,本文设计了基于B+搜索树算法的低压台区分段线损率预测系统。该系统采用智能电表和通用无线分组业务(general packet radio service,GPRS)通信技术,优化了预测系统的硬件拓扑结构;引入B+搜索树算法筛选整理原始数据;将B+树参数作为索引参数,归一化处理线损数据;创新性地基于B+搜索树的索引,构建低压台区分段线损率预测模型,完成了低压台区分段线损率预测。
1 低压台区分段线损率预测系统
1.1 硬件设计
供电企业对线损的预测,一般是根据统计分布量与实际用户缴费额折算的用户用电量进行比较,提取比较差异后,即可将其记录为线损。因此,受到外界干扰较大的低压变电站区域的分段线损率极不准确。对此,本文需要优化线损率预测系统。
首先,要从源头上实现用电和供电数据的采集和分析,获取低压站区详细的用电数据[3-6]。因此,本文设计的预测系统硬件拓扑如图1所示。

图1 预测系统硬件拓扑图
图1中,将电力用户端的数据采集设备从传统电表更换为智能电表。该型号的电表具有通信接口。与老旧的人工抄表方式相比,智能电表的主要通信方式是GPRS。低压变电所区间的线损计算,需要同时统计所有用户节点的数据,以保证计算结果的准确性。在通信过程中,用户端的智能仪表通过RS-485通信协议传输到采集器;采集器和供电端的智能仪表通过GPRS协议与系统服务器进行通信。
1.2 软件设计
1.2.1 利用B+搜索树算法建立索引
电力系统用户数量庞大,所以采集数据量大且格式也不统一。因此,本文在软件设计中引入B+搜索树算法建立索引,以便对数据进行筛选与整理。
B+搜索树是数树形结构的多层次索引的一种变形结构。经典三层B+搜索树结构如图2所示。
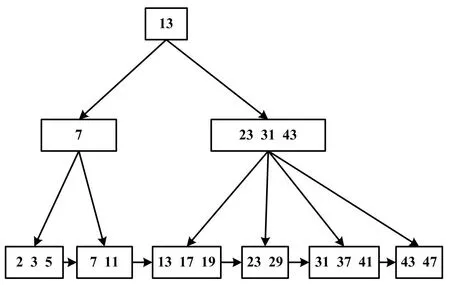
图2 经典三层B+搜索树结构示意图
图1中,B+搜索树的元素分布在树形的各个节点中,且非叶子节点与叶子节点之间具有排斥性。B+搜索树具有高效率、动态的检索特性,能够调节多路检索树的平衡,且随机检索的效率较高。
B+搜索树索引建立流程如图3所示。
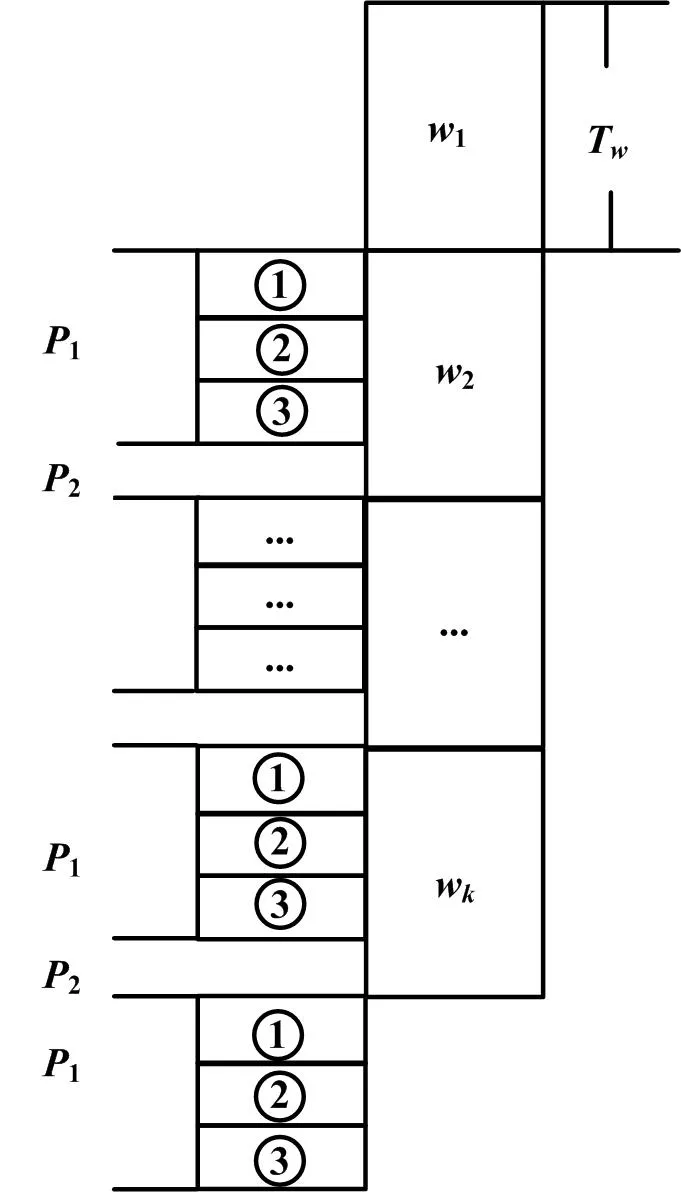
图3 B+搜索树索引建立流程
B+搜索树在系统中能够实现查询、插入以及删除等基本操作。在系统中自带的存储引擎中,需要以低压台区的电表时间窗口为基础,从时间的维度切分台区分段线损数据,并依据不同时间段的数据流,根据实际情况进行微批量处理。
图3中:w1,w2,...,wk分别为不同的数据流时间窗口;Tw为时间窗的长短;P1为索引构建过程的三个阶段,①表示底层索引的构建、②表示底层索引的发布、③表示顶层索引的更新;P2为当前时间窗索引构建完毕后的时间点与下一时间窗开始建立索引时间点的构建间隔[7-9],用于保证建立索引的稳定性。
在索引构建的过程中,需要对数据进行排序。为了提高排序效率,分段时间窗口,需设计一个线程作为分段排序任务的归并与简化依据。排序完成后,可以得到B+搜索树的骨架层数:
Fn=[logNbNw]
(1)
式中:Nb为节点的容量;Nw为时间窗数据流的量。
本文以组为计算单位,计算B+搜索树的子节点数:
(2)
依据B+搜索树自身性质所建立的数据索引,能够节省系统内的存储开销,并根据时间窗的变化实现数据的实时分配。
1.2.2 实现低压台区分段线损率预测
在系统线损率预测过程中,由于数据格式不同、分属不同的单元[10],采集到的样本会受到一定的限制。因此,本文对采集到的数据进行了预处理。
对数据进行标准化,即将其转换成无量纲数据。电网特征数据的标准化处理函数表示为:
(3)

在此基础上,引入改进的误差反向传播(back propagation,BP)神经网络。其传递函数的格式为:
(4)
式中:e-x为定义域内所有实数,值域为0~1。
这表明,经过BP神经网络预测之后,线损值能够归一化到0~1之间。
通过以上分析,经过数据预处理后,将用电数据与线损进行归一化,得到线损无量纲数据的样本集,并基于改进的BP神经网络构建线损预测模型,利用训练集进行学习训练后,将测试集输入到预测模型中,从而输出预测结果,完成低压台区分段式线损率预测。
2 实例测试
2.1 实例测试环境及数据
为了验证本文设计的线损率预测系统的有效性,随机选取某市供电公司供电覆盖区域内容量变压器为350 kVA的低压台区180个。这些台区采集到的数据共5.3 GB,但大部分都具有模糊性或数据残缺。因此,本文对数据集进行清洗,过滤、删除重复数据,检查所获取数据的完整性。对于一些缺失的数据,可以选择删除或利用平均值进行估算补全,检测孤立点。孤立点检测流程如图4所示。

图4 孤立点检测流程
在完成数据清洗与孤立点检测之后,对得到的3.9 GB预处理数据集作分档,并设定其孤立线损预测评判标准。低压台区分段线损评估标准如表1所示。

表1 低压台区分段线损评估标准
在对数据进行分类和归一化后,将这些数据作为样本,利用本文设计的线损率预测系统和文献[1]系统对线损率进行预测,并对预测结果进行比较。
2.2 试验结果对比与分析
为了准确得到两个系统的实际预测结果,将所选择的用户线路按照15∶1的比例划分为训练集和测试集,得到如表2所示的两种系统的线损预测结果。

表2 两种系统的线损预测结果
从表2所示的预测结果可知,在相同的试验环境下,本文系统得到的相对误差最高为4.27%,明显小于文献[1]系统。这是因为本文系统引入B+搜索树算法、采用了智能电表和GPRS通信技术、优化了供电数据的采集与传输,使得初始阶段数据采集与分析的准确性得到提升,保证了收敛速度,进而提升了线损预测结果的准确性。
3 结论
针对传统线损预测系统存在分段线损评估评判标准不一、线损率预测准确度较低的问题,本文设计了基于B+搜索树算法的低压变电站区域分段线损率预测系统。该设计改进了硬件拓扑结构,引入B+搜索树算法建立索引,便于对原始数据进行过滤和排序;通过优化B+搜索树的建立过程,得到B+搜索树参数作为索引参数;在线损率预测过程中,对数据进行预处理与归一化处理,实现了线损预测。
但是受到试验样本来源的限制,本文尚未对预测线损率与实际线损率进行比较分析。在未来的研究中,将结合海量实际低压台区运行历史数据,以多个维度的台区电气特征参数作为输入,进一步构建低压配电网同期线损率预测模型,从而为该领域的相关研究提供更为完善的线损计算与预测结果。
猜你喜欢
小学生学习指导(高年级)(2022年10期)2022-11-04
电气技术(2022年2期)2022-02-24
中国电气工程学报(2019年25期)2019-09-10
奥秘(创新大赛)(2019年3期)2019-03-13
作文评点报·低幼版(2018年17期)2018-07-12
电子制作(2017年2期)2017-05-17
电子制作(2017年2期)2017-05-17
电子制作(2016年1期)2016-11-07
电子制作(2016年1期)2016-11-07
百科探秘·航空航天(2016年5期)2016-11-07
