
基于TimeGAN-CNN-LSTM模型的河流水质预测研究
2022-09-01 10:37张丽娜陈会娟余昭旭
自动化仪表 2022年8期
张丽娜,陈会娟,余昭旭
(1.华东理工大学能源化工过程智能制造教育部重点实验室,上海 200237;2.上海西派埃智能化系统有限公司,上海 200233)
0 引言
河流为人类提供了赖以生存的水资源,而工业化进程的不断加快,导致河流水环境受到严重破坏[1]。因此,可靠的水质模型对预测河流水质变化趋势、采取治理措施和建立决策预警机制具有重要意义[2-3]。近年来,国内外很多专家学者已针对水质预测作了大量的研究,并取得了较好的成果。Wang等[4]将长短期记忆(long short-term memory,LSTM)神经网络用于水质预测,建立了基于LSTM的水质预测模型,解决了传统神经网络难以用于时间序列预测的难题,模型效果显著。单一算法的预测模型通常只包含数据部分信息,而基于混合算法的预测模型能够更加充分地提取数据中的有效信息,从而提高预测精度[5-6]。周朝勉等[7]提出了基于卷积神经网络(convolutional neural network,CNN)-LSTM的水质预测模型,以精确预测水质中的溶解氧浓度。与单一的LSTM模型和反向传播(back propagation,BP)神经网络模型的比较结果表明,基于CNN-LSTM的水质预测模型取得了更好的预测结果。Yang[8]等提出了基于注意内机制的CNN和LSTM(CNN-LSTM with attention,CLA)的水质预测模型,使用线性插值填充缺失数据,并通过小波技术对数据去噪。试验结果表明,基于CLA的水质检测模型可以稳定地预测不同时滞。
本文提出了基于时间序列对抗生成网络(time-series generative adversarial network,TimeGAN)-CNN-LSTM的河流水质预测模型。相比于现有研究结果,本文模型主要具有以下特点。
①本文模型通过TimeGAN对原有的水质数据进行数据增强,扩充了训练集,解决了训练模型时数据不充分的问题。
②本文模型利用CNN-LSTM模型提取水质数据在时间和空间上的特征。
试验结果表明,本文提出的河流水质预测模型准确率更高,具有良好的应用价值。
1 相关方法分析
1.1 TimeGAN
TimeGAN由自编码器和对抗网络两部分组成[9]。对抗网络主要包括序列生成器G和序列判别器D。TimeGAN模型结构如图1所示。
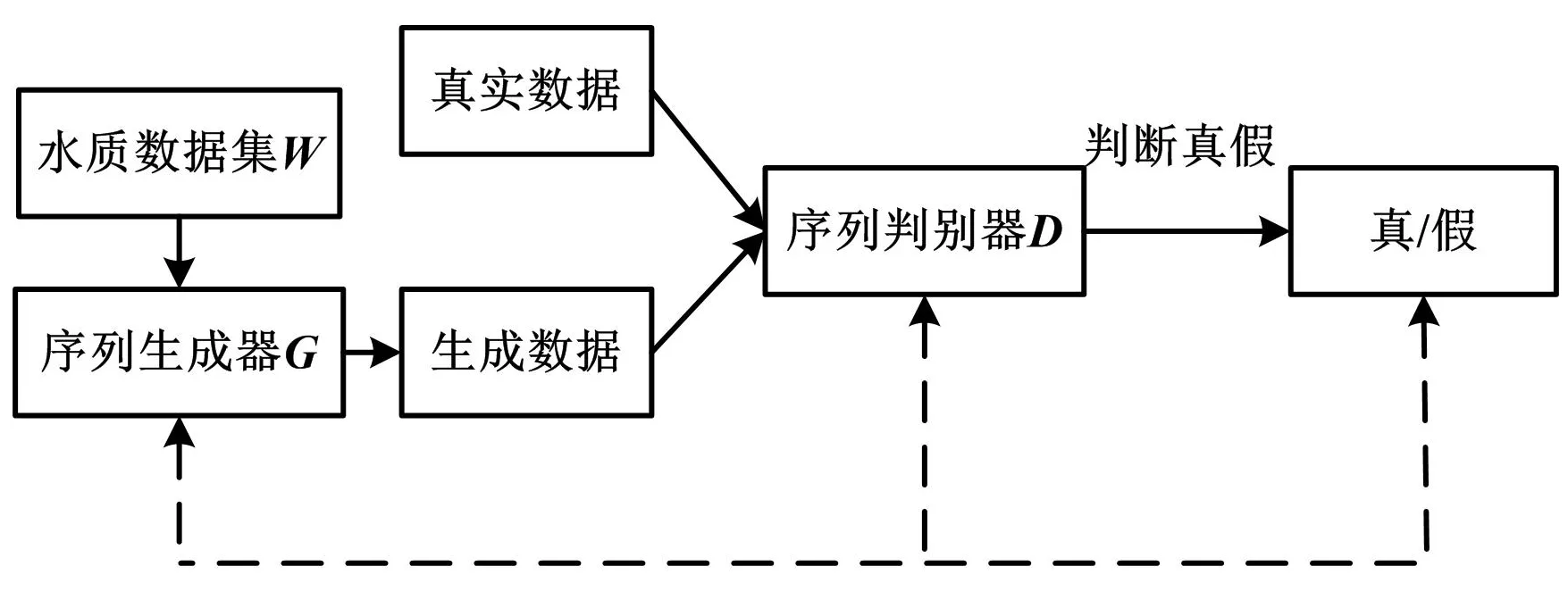
图1 TimeGAN模型结构
TimeGAN模型将水质数据集W输入序列生成器G获得生成数据,通过序列判别器D区分真实数据和生成数据。
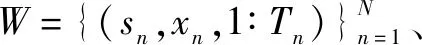
TimeGAN采用联合训练方法,依靠3个不同的损失函数对自编码器和对抗网络进行训练,分别为自编码器损失LR、监督损失LS和非监督损失LU。其中:LR表征自编码器对输入数据内在特征的掌握程度;LS反映生成器和判别器的竞争对抗互动;LU反映生成器生成的数据能够逼近真实数据经过自编码器编码后的数据的程度。计算公式如下:
(1)
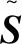
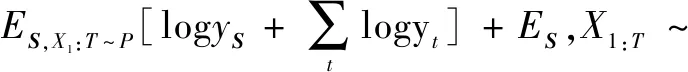
(2)
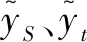
(3)
式中:ht、hS分别为当前随机时态特征和静态特征;zt为当前随机时态特征向量。
1.2 CNN
CNN是一种特殊的人工神经网络,主要由卷积层和池化层组成[10]。卷积层利用卷积核提取数据特征。池化层压缩卷积层提取的特征,从而减少运算量。一维CNN将卷积核视为1个窗口。首先,时间序列数据在窗口上进行平移,以提取局部序列段。然后,将局部特征与权重点乘,持续输出得到序列特征,进行池化下采样。该方法适用于提取时间序列的相应特征,能够过滤数据中与预测无关的噪声信息,优化预测性能。
1.3 LSTM
LSTM是循环神经网络(recurrent neural network,RNN)的一种。其采用LSTM单元代替RNN中的神经元,解决了RNN存在的梯度消失和梯度爆炸问题[11],适用于时序数据的处理。LSTM由输入门、遗忘门、输出门组成。
LSTM各模块的计算公式见式(4)~式(9)。
it=σ[Wi(ht-1,xt)+bi]
(4)
式中:it为LSTM的输入门;Wi和bi分别为输入门的权重和偏置;ht-1为上一时刻的输出;xt为t时刻的输入。
ft=σ[Wf(ht-1,xt)+bf]
(5)
式中:ft为LSTM的遗忘门;Wf和bf分别为遗忘门的权重和偏置。
(6)

(7)
式中:ct为单元状态;ct-1为上一单元的状态。
ot=σ[Wo(ht-1,it)+bo]
(8)
式中:ot为LSTM的输出门;Wo和bo分别为输出门的权重和偏置。
ht=ottanh(ct)
(9)
式中:ht为t时刻的输出。
LSTM结构如图2所示。

图2 LSTM结构
2 TimeGAN-CNN-LSTM模型构建
本文使用的数据集有144组数据,训练样本数量较少。当训练样本数量比较少时,模型容易陷入对小样本的过拟合问题。因此,本文提出了一种基于TimeGAN-CNN-LSTM的河流水质预测模型。在模型训练过程中:使用TimeGAN对河流水质历史数据进行数据增强;采用CNN对输入的水质数据进行特征提取;利用2层LSTM对河流水质进行预测。
TimeGAN-CNN-LSTM模型训练过程具体步骤如下。
①将数据集划分为训练集、验证集与测试集。
②使用TimeGAN生成合成时间序列数据。将数据输入TimeGAN模型中,输出创建自编码器和对抗网络,根据式(1)~式(3)所定义的3个损失函数LR、LS和LU评估输出的结果。
③对合成时间序列数据进行归一化,并将该数据作为模型的输入数据,使其介于[0,1]之间。归一化公式为:
(10)
式中:X为原始数据;Xnorm为归一化处理后数据;Xmax为原始数据中最大值;Xmin为原始数据中最小值。
④训练CNN-LSTM模型,采用CNN对输入数据进行特征提取,将数据特征输入到2层LSTM中,实现对河流水质的预测。在CNN中,卷积层的神经元数量设置为64,卷积核的尺寸为1×1,个数为4,使用ReLU激活函数使网络训练更快。另外,设置两层LSTM的神经元个数分别为64和32。
⑤模型搭建完成后,为了防止数据过拟合以及训练时间较长,选择Adam优化算法训练模型。
⑥将步骤①中的测试集数据输入模型中,并对模型输出结果进行反归一化,得到河流水质预测值。
TimeGAN-CNN-LSTM模型训练过程如图3所示。

图3 TimeGAN-CNN-LSTM模型训练过程
3 试验与结果分析
3.1 数据集介绍
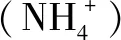
3.2 评价指标
为了更好地评估模型的预测效果,本文分别采用平均绝对误差(mean absolute error,MAE)、均方根误差(root mean square error,RMSE)和拟合优度(R-square,R2)对预测结果进行评定。
MAE表示模型的精确度。MAE的值越小,模型的精确度越好。RMSE表示模型的稳定性。RMSE的值越低,模型越稳定。决定系数R2表示模型的好坏。一般来说,R2的值越大,模型的拟合效果越好。
MAE、RMSE、R2的计算过程见式(11)~式(13)。
(11)

(12)
(13)

3.3 结果分析
本次试验基于Windows10操作系统,使用Python语言编码,版本为python3.8.8,编程工具使用Jupyter Notebook。其中:TimeGAN使用ydata_synthetic包实现;CNN-LSTM模型使用keras包实现;LSTM模型使用TensorFlow框架实现。
不同模型的损失曲线对比如图4所示。
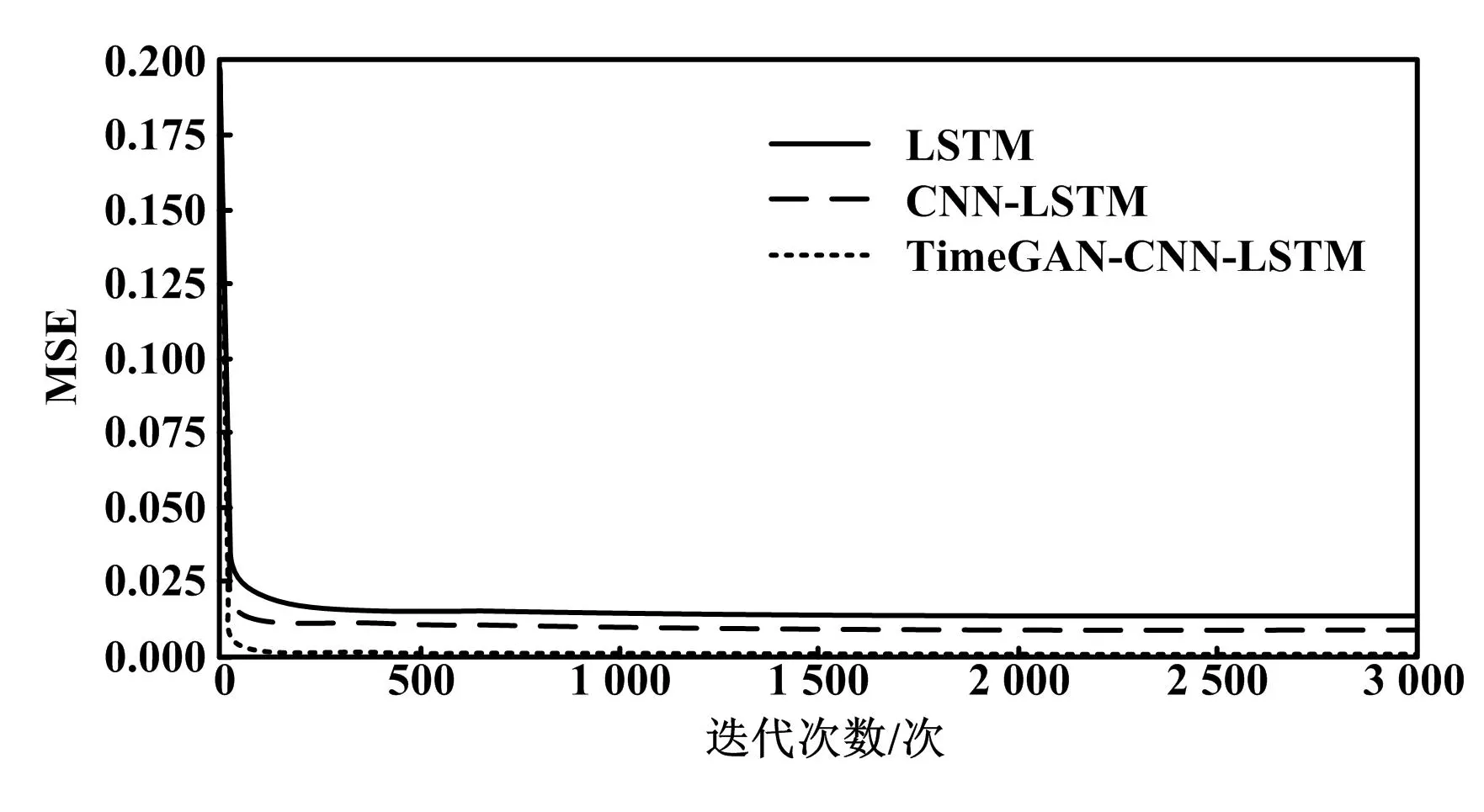
图4 不同模型的损失曲线对比
在训练模型之前,数据经过选择分为训练集、验证集和测试集,将前100组数据划分为训练集、中间22组数据划分为验证集、后22组数据划分为测试集。其次,为了更加充分地挖掘数据之间的特征,使用TimeGAN方法对100组训练集数据进行扩充,同时设置时间序列长度为12,生成200组合成时间序列数据,验证集与测试集保持不变。然后,采用合成后的200组时间序列数据建立TimeGAN-CNN-LSTM模型。该模型迭代次数为3 000次,以MSE为预测损失函数。为了验证该模型的有效性,将其与CNN-LSTM模型、LSTM模型进行对比。其中:CNN-LSTM模型中CNN层、LSTM层神经元数量为64;LSTM模型的隐藏层神经元个数为32。随着迭代次数的增加,TimeGAN-CNN-LSTM模型的训练损失曲线的收敛速度最快且更接近于0。该结果表明,通过分别与CNN-LSTM、LSTM模型进行比较,TimeGAN-CNN-LSTM模型具有更低的均方误差,其预测结果更为准确。
为了进一步验证TimeGAN-CNN-LSTM模型对水质预测的优越性,可对比TimeGAN-CNN-LSTM与CNN-LSTM、LSTM模型。使用训练集和验证集来确定模型,将测试集输入到模型中得到预测值,并使用MAE、RMSE、R2统计指标对模型进行评估和比较。不同模型的预测性能对比结果如表1所示。

表1 不同模型的预测性能对比结果


图5 验证集在不同模型下的预测结果
测试集在不同模型下的预测结果如图6所示。

图6 测试集在不同模型下的预测结果
由图5、图6可知,与CNN-LSTM、LSTM模型相比,本文采用基于TimeGAN-CNN-LSTM方法的水质预测模型结果更接近目标值,说明该模型具有更好的泛化性能。
4 结论
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
锻压装备与制造技术(2021年5期)2021-11-13
北京航空航天大学学报(2021年9期)2021-11-02
科学技术创新(2021年5期)2021-03-17
——编码器
演艺科技(2020年7期)2020-08-13
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
小太阳画报(2019年4期)2019-06-11
散文诗(2018年20期)2018-05-06
北京航空航天大学学报(2018年1期)2018-04-20
