
基于机器学习预测血糖异常急性缺血性卒中患者预后模型研究
2022-08-29 11:34杨佳蕾陈思玎孟霞姜勇王拥军
中国卒中杂志 2022年7期
杨佳蕾,陈思玎,孟霞,姜勇,王拥军
在我国,卒中是导致死亡和长期残疾的主要原因。高血糖不仅是卒中发病的独立危险因素,也是导致患者死亡和残疾的危险因素之一,对预后有显著影响[1-2]。研究显示约40%的急性缺血性卒中患者入院时合并糖尿病或有血糖异常升高,这些患者的住院时间更长且短期和长期死亡率均更高[3]。针对血糖异常的急性缺血性卒中人群建立预后的预测模型,从而对患者进行精准风险分层和管理,对优化医疗资源配置和改善患者预后有重要意义。
目前常用的卒中预后预测模型主要是基于回归模型进行构建[4]。大数据时代的到来对数据处理逻辑、效率和深度都提出了更高要求,机器学习在临床医学中得到了更深入的应用[5]。本研究基于中国国家卒中登记研究Ⅲ(China national stroke registration studyⅢ,CNSR-Ⅲ),采用传统logistic回归和机器学习的方法建立血糖异常急性缺血性卒中患者的预后预测模型,并对其预测性能进行比较,以期为建立更完善的预测模型提供借鉴。
1 对象与方法
1.1 研究对象 本研究基于CNSR-Ⅲ研究。CNSR-Ⅲ为全国多中心的前瞻性卒中队列研究,纳入2015年8月-2018年3月的急性缺血性卒中或TIA患者15 166例。CNSR-Ⅲ的研究设计、随访方案、患者临床特征等信息已经发表[6]。本研究纳入标准:①纳入CNSR-Ⅲ研究;②年龄≥18岁;③完成头颅MRI检测,经DWI序列检测明确有高信号;④有糖尿病史或入院后经检测判断符合糖尿病诊断标准;⑤有3个月随访的mRS记录。CNSR-Ⅲ研究获得首都医科大学附属北京天坛医院伦理委员会的批准(文件号:KY2015-001-01),患者或其家属均签署知情同意书。
1.2 预测变量和结局变量 本研究的结局变量是急性缺血性卒中发病3个月预后不良。以面对面方式对患者进行随访,根据mRS分为预后良好组(mRS 0~2分)和预后不良组(mRS 3~6分)。
结合临床经验、既往文献报道以及本研究数据收集情况(缺失值<30%)确定纳入模型分析的预测因子,包括年龄、性别、BMI、发病前mRS、吸烟史、重度饮酒史、卒中病史、高血压、脂代谢紊乱、冠心病、心房颤动、肾功能不全、肝功能不全、发病至到院时间≤24 h、入院NIHSS、出院NIHSS、≥50%责任颅内动脉狭窄、≥50%责任颅外动脉狭窄、多发梗死灶、梗死灶前后循环分布、TOAST分型等临床特点,入院后24 h内的实验室检查结果(白蛋白、球蛋白、血红蛋白、纤维蛋白原、HDL-C、hs-CRP、糖化血红蛋白、脂蛋白磷脂酶A2活性及含量、脂蛋白a、前蛋白转换酶枯草溶菌素9、人几丁质酶3样蛋白1、载脂蛋白-C3、载脂蛋白-A2),入院后的治疗措施(抗血小板、抗凝、降压、降脂、抗氧化和降糖治疗)。
1.3 模型构建 缺失数据中的连续变量采用线性插值法填补,分类变量采用众数填补。本研究采用传统logistic回归以及随机森林模型、梯度提升决策树(gradient boosted decision trees,GBDT)模型和极致梯度提升(eXtreme Gradient Boosting,XGBoost)等机器学习模型。
1.3.1 数据集划分 采用分层采样10折交叉验证的方法将数据集随机平均分割成10份,循环抽取其中9份作为训练集,用于预测模型训练,通过逐渐减少训练误差达到模型参数权重的优化;另外1份作为测试集,对不同模型的预测效能进行评价与对比[7]。
1.3.2 机器学习预测模型 随机森林模型是一种由多决策树构成的集成算法,每棵决策树针对样本进行独立判断,最后综合多决策树的分类情况得到预测结局的最终结果。随机森林模型可以处理高维度数据,无需做特征选择,对变量的共线性不敏感,结果对于非平衡数据比较稳健[8]。GBDT模型使用回归树作为决策树,采用连续的方式构造决策树,每棵树都试图纠正前一棵树的错误,目的是使最终的预测误差最小。每棵树只能对部分数据做出好的预测,所有树的结论累加起来得到最终结果,是一种泛化能力较强的算法[9-10]。XGBoost模型的本质是GBDT模型,但是对算法进行了改进,具备可扩展、高效的特点[11]。在XGBoost机器模型中,预测因子的重要性通过SHAP值体现,使用SHAP值显示变量特征对模型输出影响的分布[12]。
1.4 统计学方法 使用SAS 9.4软件进行统计学分析。符合正态分布的连续变量以表示,非正态分布的连续变量以M(P25~P75)表示,组间单因素分析采用t检验或Wilcoxon秩和检验;分类变量以频数(%)表示,组间单因素分析采用χ2检验。将所有预测变量纳入logistic回归模型和机器学习模型,计算各模型ROC的AUC,采用Brier分数评价校准度,综合F1分数、准确率、灵敏度和特异度评价不同模型的预测价值。以P<0.05为差异具有统计学意义。
2 结果
2.1 基本资料 研究共纳入3694例符合标准的患者,平均年龄62.4±10.4岁,男性2408例(65.2%),3个月预后良好3109例(84.2%),预后不良585例(15.8%)。单因素分析显示预后不良组的年龄、入院和出院NIHSS高于预后良好组,卒中病史、高血压、冠心病、心房颤动、肾功能不全、发病至到院≤24 h、≥50%责任颅内动脉狭窄、≥50%责任颅外动脉狭窄、多发梗死比例和住院期间的抗凝、降压、降糖治疗的比例高于预后良好组,实验室检查中球蛋白、纤维蛋白原、hs-CRP、脂蛋白a、人几丁质酶3样蛋白1水平高于预后良好组;BMI,男性、吸烟史和住院后抗血小板治疗比例,白蛋白、血红蛋白、载脂蛋白-C3和载脂蛋白-A2水平低于预后良好组;此外,两组间发病前mRS、梗死灶前后循环分布及TOAST分型差异也具有统计学意义(表1)。
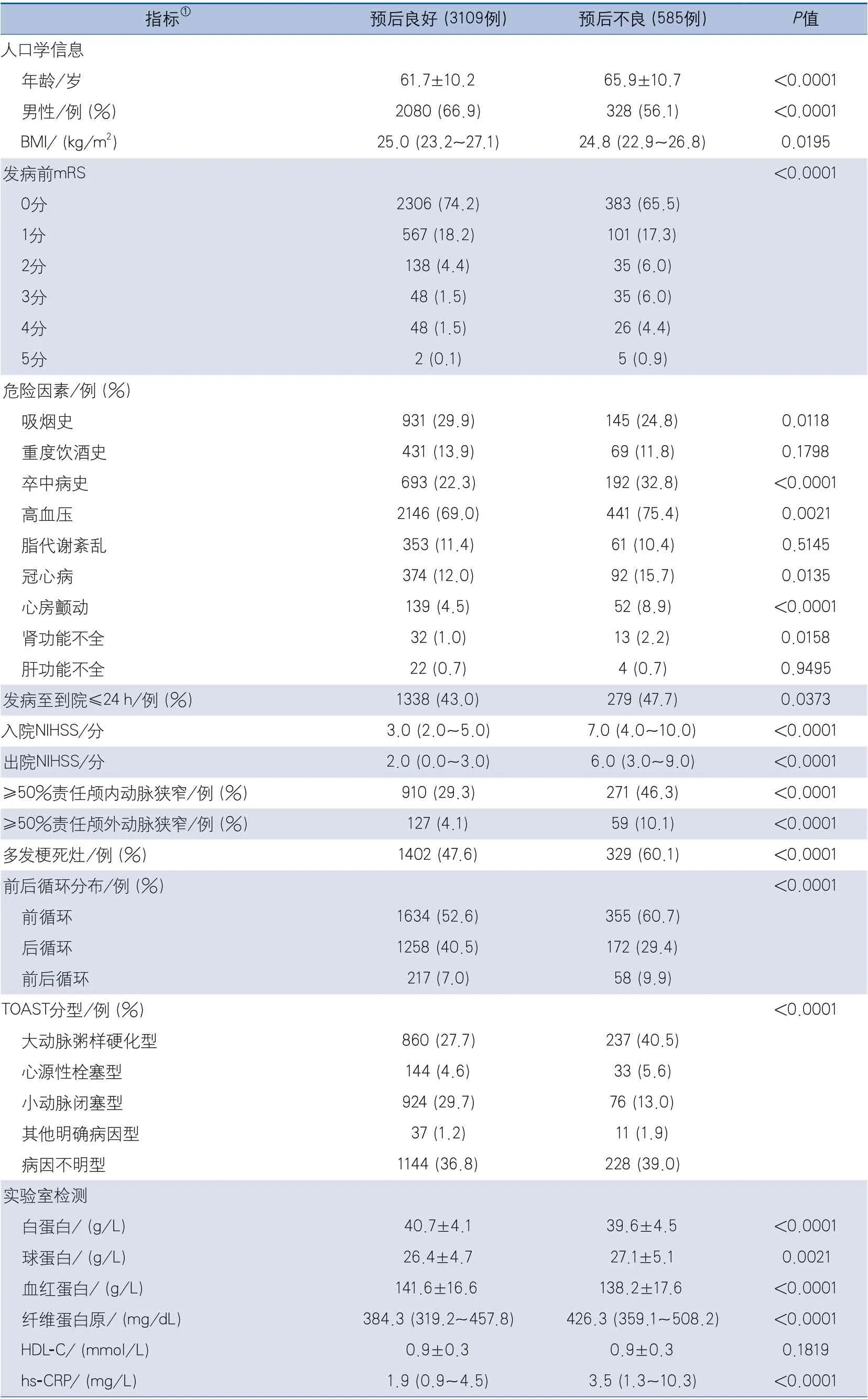
表1 患者临床特征
2.2 回归模型与机器学习模型的预测性能比较传统logistic回归模型、随机森林模型、GBDT模型和X G B o o s t 模型预测预后不良的AUC分别为0.843(0.814~0.872)、0.847(0.823~0.871)、0.845(0.819~0.871)和0.848(0.820~0.876)。机器学习模型的AUC有高于logistic回归模型的趋势,但差异没有统计学意义。在AUC最高的XGBoost模型中,采用SHAP图可视化重要性前10位的预测因子为出院及入院NIHSS、年龄、性别、血红蛋白水平、hs-CRP水平、白蛋白水平、发病前mRS、TOAST分型和载脂蛋白-A2水平(图1)。传统logistic回归模型、随机森林模型、GBDT模型和XGBoost模型的灵敏度分别为0.373(0.340~0.405)、0.679(0.629~0.728)、0.426(0.383~0.468)和0.634(0.583~0.686),机器学习模型的灵敏度优于logistic回归模型(均P<0.05),所有模型的校准度均良好,各模型的其他评价指标包括F1分数、准确率和特异度差异均无统计学意义(表2)。

表2 logistic回归模型与机器学习模型对预后不良预测性能的比较
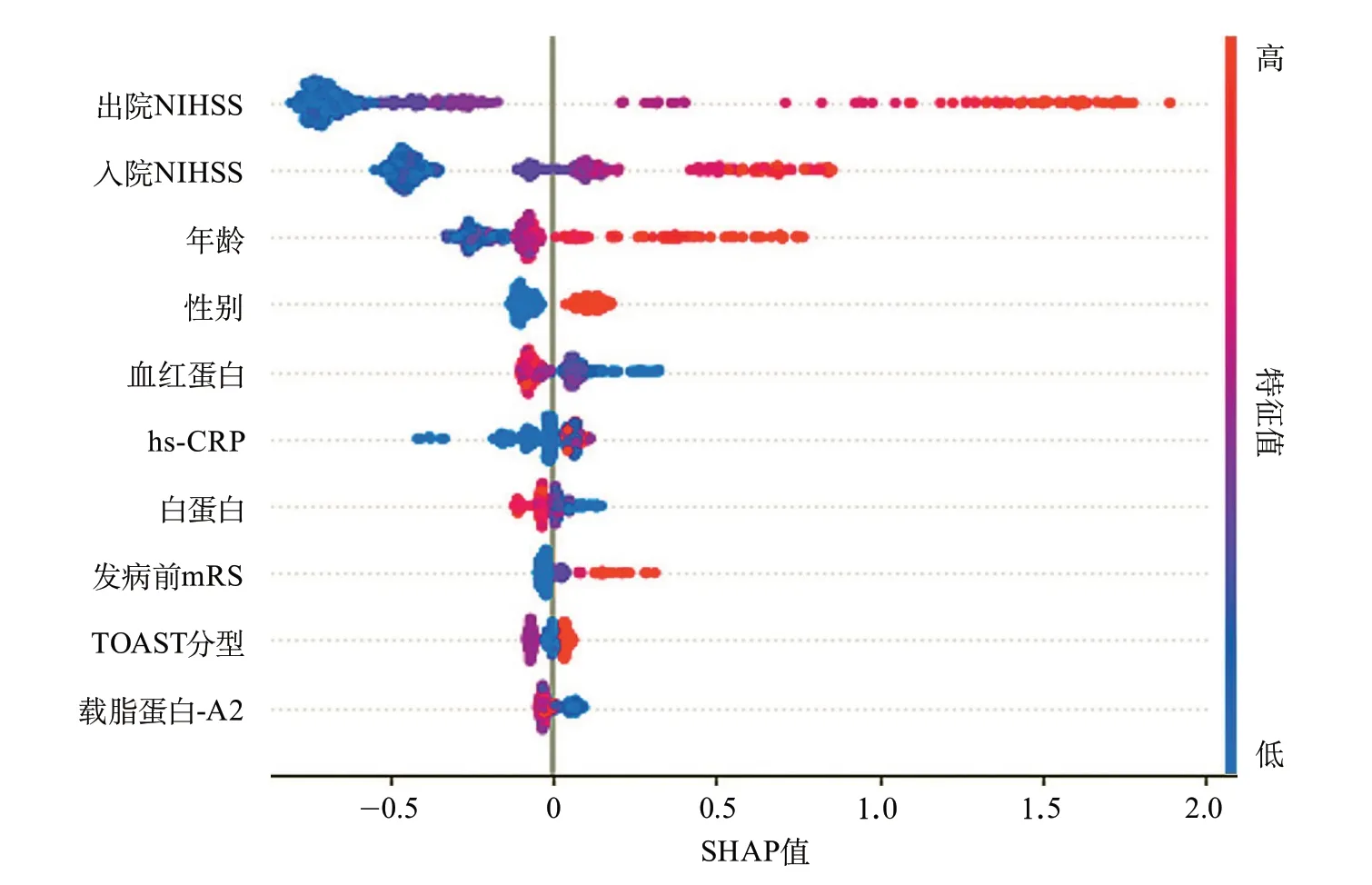
图1 极致梯度提升模型中前10位预测因子SHAP图
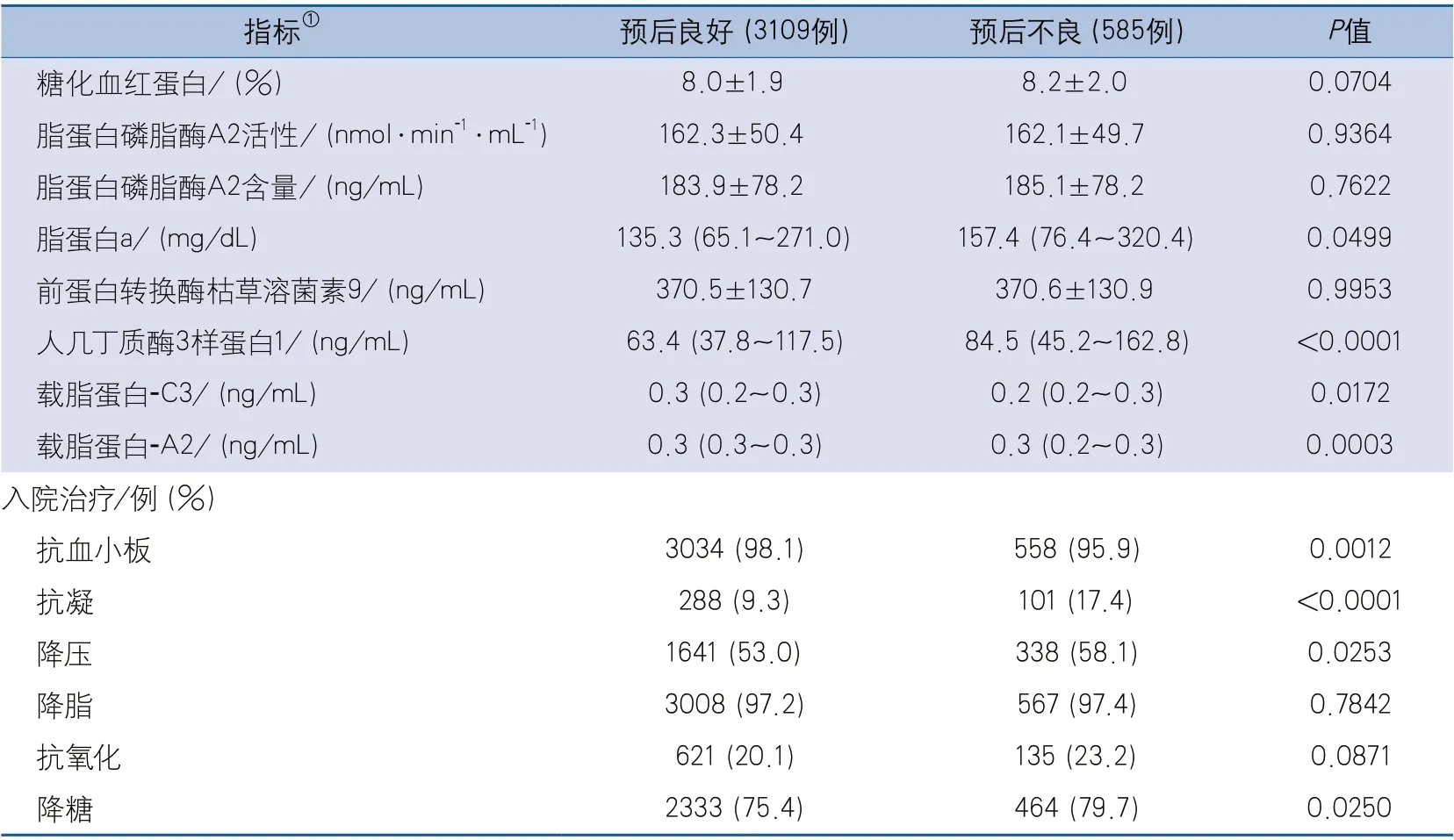
续表
3 讨论
本研究基于随机森林、GBDT和XGBoost等3种机器学习方法建立了预测血糖异常急性缺血性卒中患者3个月功能预后的预测模型,并且与传统logistic回归模型的预测效果进行比较。研究结果显示,尽管机器学习模型的区分度(AUC)稍优于logistic回归模型,但是并未体现出显著优势。这可能是由于本研究纳入了3694例患者,3个月预后不良者585例,即总样本量与正样本数量相对于万级人群数量较少,没有体现出机器学习模型在处理大样本数据方面的优势。在既往纳入2604例急性卒中患者的回顾性研究中,研究者采用深度神经网络模型、随机森林模型及logistic回归模型预测患者3个月功能预后良好(mRS 0~2分),并且与洛桑急性卒中登记(acute stroke registry and analysis of Lausanne,ASTRAL)量表进行比较。研究结果显示当机器学习模型选择与ASTRAL评分相同的变量时,即使采用不同的决策树构建模型,机器学习也未能显著提高预测模型的效度[13]。对于纳入logistic回归模型和机器学习模型的预测变量,是否需要分别使用单因素或多因素logistic回归、Boruta算法或其他方式进行特征筛选,然后再分别纳入不同模型,这值得后续研究进行进一步探索。
本研究对表现最优的XGBoost模型的预测因子SHAP值进行排序,结果显示对预测模型影响权重最大的前3个变量是出院NIHSS、入院NIHSS和年龄,这与既往研究一致[14-15],提示卒中严重程度与患者年龄是影响预后的重要因素。除此之外,性别、血红蛋白水平、hs-CRP水平、白蛋白水平及发病前mRS均可对预后产生显著影响。在TOAST病因分型中,SHAP值提示其他病因或不明原因型缺血性卒中的预后欠佳。本研究还发现低载脂蛋白-A2水平与预后不良相关。载脂蛋白-A2主要参与人体HDL-C的合成,低载脂蛋白-A2水平提示低HDL-C水平。有研究报道载脂蛋白-A2基因敲入家兔的血浆HDL-C水平较对照组高,在给予高脂饮食后,基因敲入家兔对饮食引起的高血脂有更好的抵抗能力,并且主动脉粥样硬化斑块形成较少[16]。本研究中的机械学习模型与既往研究均提示载脂蛋白-A2可能是干预动脉粥样硬化这一卒中危险因素的靶点。
本研究存在一定局限性。对于机器学习模型而言,本研究的总样本量及正样本数量较少,可能影响了机器学习模型构建优势的体现。另外,本研究部分特征变量因发生较多缺失而被剔除,这对预测模型决策树构建有一定影响。尽管本研究基于CNSR-Ⅲ研究全面、丰富的临床特征变量进行了分析,但是研究结果有待进一步结合其他外部大样本数据库进行联合分析与验证。
猜你喜欢
健康体检与管理(2022年4期)2022-05-13
锦州医科大学报(2022年2期)2022-05-07
中国典型病例大全(2022年9期)2022-04-19
科学与信息化(2019年28期)2019-10-21
科学与财富(2016年32期)2017-03-04
环球时报(2016-09-19)2016-09-19
决策与信息·下旬刊(2013年1期)2013-03-11
心脑血管病防治(2011年3期)2011-09-15
