
基于openEHR的医疗过程数据抽取与转换软件设计实现
2022-08-18 02:17徐海峰毛华坚杨雨李梅赵东升
北京生物医学工程 2022年4期
徐海峰 毛华坚 杨雨 李梅 赵东升
0 引言
随着医疗领域数据量的快速增长,医疗过程挖掘成为近年来新的研究热点,其中事件数据(event data)抽取方法是实现过程挖掘的基础和前提[1]。医疗过程是指与患者临床诊疗相关的一系列活动,如诊断、用药、检查和实验室检查等。分析这些活动有助于降低医疗成本,提升服务质量,提高资源利用率。过程挖掘作为一个新兴的数据科学分支,支持基于事实的流程发现、合规性检查和过程改进[2]。过程挖掘在许多研究中得到了应用,并取得了较好的结果[3-5]。它关注于从来自一个或多个信息系统的事件日志(event log)中提取知识。目前,可扩展事件流(extensible event stream,XES)是用于存储和交换事件日志的国际标准格式。每个XES文档由包含多个事件序列的案例(case)组成,每个案例和事件可以有多个属性。然而,作为事件日志来源的医疗信息系统往往体系架构并不相同。对于临床科研或信息技术人员来说,从多个异构数据源中提取数据并转换为XES事件日志通常会花费大量的时间和精力。
信息系统间的语义互操作是进行高效、标准化数据抽取的基础。为了实现语义互操作这一目标,openEHR定义了一种由原型(archetype)和参考模型(reference model)组成的两层临床数据建模方法,已经成为欧洲(CEN 13606)和ISO标准[6]。该种双模型架构能适应医学知识的不断更新,并保持底层数据存储结构的相对稳定。openEHR的原型是针对某一临床业务概念的最大集,模板是对原型的进一步约束,以满足不同业务场景的需要。openEHR的原型主要有4种类型:COMPOSITION,SECTION,CLUSTER和ENTRY,每种类型分别对应着一个抽象表示的层次。根据临床活动特点,每个ENTRY类型又可分为观察、评价、指导、行动4个具体的子类[7]。通过共享和重用已定义好的原型,可以实现医疗机构之间的语义互操作[8]。随着openEHR规范和数据平台的不断完善,有越来越多的信息系统采用openEHR标准作为临床数据模型[9]。
由于openEHR原型能够支持医疗业务中涉及的各种应用流程,例如电子病历、电子健康记录、实验室检查和影像检查等,因此它可以涵盖过程挖掘所需的常见事件(活动)。另外,openEHR所定义的原型包含了事件的概念,过程挖掘的主要目的就是分析这些事件序列的模式。因此,基于openEHR的数据建模方法非常有利于进行过程挖掘和分析。可以通过将原型中的数据项映射到事件及其属性来生成事件日志。另外,openEHR的基本思想是以临床专家为主导,由信息技术人员负责开发相应的软件工具。所以,对于这些基于openEHR开发的系统,也应当支持临床人员能够独立进行数据查询和抽取操作。
在现有的查询语言方面,存在面向主流数据库的结构化查询语言(structured query language,SQL)和对象查询语言(object query language,OQL),它们依赖于特定的数据模式和物理表示(如关系表)[10]。为了编写有效的查询代码,用户必须知道特定数据库的存储模式。此外,由于这些系统的数据模式通常不同,即使它们存储相同的数据,为某一种模式编写的查询语句通常也不能够跨系统移植。另外,尽管一些面向Web的查询语言(如W3C Sparql和GraphQL)没有可移植性问题,但它们与数据库语言类似只能表达单一的语义层次。也就是说,它们的元数据模型只假设了实体属性值(entity-attribute-value,EAV)。
为此,openEHR组织提出了原型查询语言(archetype query language,AQL)来实现跨组织的数据获取和语义互操作,并支持参考模型和原型等多级模型结构。AQL作为一种描述式查询语言,专门用来搜索和抽取存储在基于原型构建的信息系统数据,并且它的语法独立于信息模型、应用程序、编程语言、系统环境和存储模型[10]。AQL通过组合原型的语义元素和参考模型中的相应数据结构元素来表示查询语句(SQL只是基于后者),这是其实现跨系统语义查询和共享的关键。其次,临床人员可以很容易地理解模板、原型和数据项的含义,而不必关注数据库的表、列、数据类型等存储结构和物理实现。
虽然AQL支持从大量与openEHR兼容的异构数据源中提取信息,但是目前仍缺乏易于使用的工具来提取数据并将其转换为过程挖掘所需的日志格式。此外,临床人员在查找数据项所属的原型或模板时比较麻烦,而且他们通常难以直接编写AQL查询代码。为此,课题组设计并开发了一个能够自动化生成并执行AQL代码的数据抽取软件,以帮助临床人员检索数据项和定义查询条件,实现从多种数据源中提取数据,并将结果转换成标准的事件日志格式,以方便后续的过程挖掘和分析。
1 相关标准介绍
1.1 ADL文件结构
原型定义语言(archetype definition language,ADL)是表达原型的形式化语言,它的文件组织结构如图1所示。其中cADL(ADL的约束形式)表示了原型中的定义部分,对象数据实例表示(object data instance notation,ODIN)用于表示语言、描述和术语部分。在ADL中,模板(template)是一类特殊的原型,通过“槽填充”来表达原型之间的组合关系。通常原型和模板可以汇编到操作模板(operational template,OPT)文件,并能够进一步生成下游应用(例如模式、应用程序接口等)以及电子病历系统的操作格式[11]。

图1 ADL的原型结构Figure 1 The archetype structure of ADL
1.2 AQL语言
AQL的语法结合了SQL结构语法和openEHR路径表示,它由4个子句组成:SELECT、FROM、WHERE、ORDER BY。FROM子句用于指定原型库中所有可用原型的子集。WHERE子句从定义好的子集中筛选数据,只保留符合条件的数据。SELECT子句用于从前两步匹配的数据中选择需要返回的确切数据项。此外,AQL为适应openEHR的层次结构,使用关键字CONTAINS表示原型之间的包含关系。AQL中的逻辑运算符包括AND、OR、NOT和EXISTS。AQL的查询参数可以在应用程序或电子病历系统解析。在实际应用中,AQL查询脚本通常可以通过调用库函数或API服务执行。例如,已有多个商业和开源项目支持通过RESTful API接口执行AQL语句[11]。
1.3 XES元数据模型
XES已被IEEE组织接受作为事件日志标准(1849-2016),用于实现事件日志和工作流的互操作[12]。目前已有许多开源和商业软件支持这种存储结构,比如ProM (www.processmining.org)和Disco (www.fluxicon.com)等。XES的元数据结构如图2所示。XES文档是一个包含由任意数量的踪迹(trace)组成的日志。每个踪迹描述与特定实例相关的事件顺序列表,事件(event)是在业务执行过程中的原子活动。因为日志、踪迹和事件对象只定义了文档的结构,它们本身不包含任何具体信息,所有信息都存储在事件日志的属性中。每个日志、踪迹和事件可以具有任意数量的属性,也可以在扩展部分定义新属性。XES的5种核心属性类型为字符串(string)、日期(date)、整数(int)、浮点数(float)和布尔值(boolean)[1]。
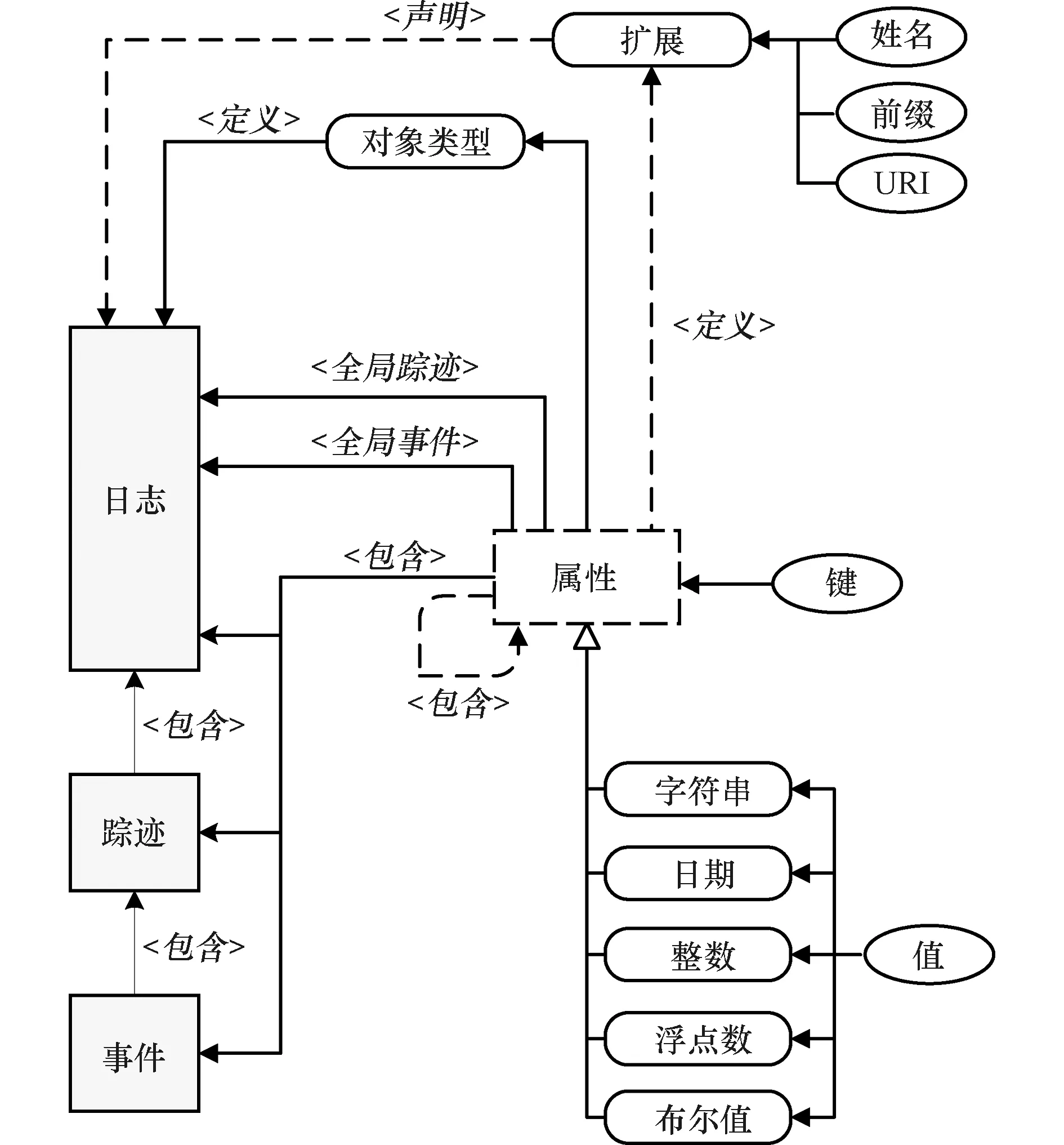
图2 XES标准的元数据模型Figure 2 Meta-model for the XES standard
2 软件设计与技术实现
课题组设计的基于openEHR AQL的软件主要完成两方面工作,即数据查询和格式转换。数据查询包括元数据(原型的数据项)检索和服务器中的具体数据查询两部分。为实现以上功能,软件的工作流程如图3所示。首先对原型和模板库的元数据进行预处理,确定其对应关系。其次,根据用户输入的检索关键字,找到相应的原型和数据项。然后生成相应的AQL脚本并在openEHR服务器上执行,以返回所需的数据值。最后,将检索到的数据转换为XES文件格式进行输出。

图3 数据抽取软件框架Figure 3 The framework of data extracting software
2.1 元数据预处理
目前,openEHR的临床知识管理器(clinical knowledge manager,CKM)等公共存储库中已存在大量的原型。为帮助临床专家快速查找到相关的原型,课题组基于openEHR发布的Java-libs[11]开源项目,首先解析定义各原型(archetype)的ADL文件,提取出原型ID、父原型ID(当原型被专业化时)、临床概念和数据元素等特征。此外,通过将ADL文件中的定义和术语部分相结合来确定各数据项的完整路径。最后,通过解析业务系统所使用的OPT模板文件,得到每个模板与所包含原型的层次关系,生成一个从元素(及其属性)到原型的树状结构映射字典。
2.2 扩展查询
为了能够智能地查找到所需的数据项,课题组对输入关键字基于语义扩展后在完整的openEHR路径中进行搜索。当用户输入要查询的关键字时,首先基于WordNet[13]提供的字典文件,使用麻省理工学院的JWI(Java WordNet Interface)接口得到相应的同义词列表。再测试这些扩展后的同义词是否包含在模板、原型或openEHR路径中。若包含时,列出所有相关的临床信息模型,供用户进行准确选择。在本研究中只列出了ENTRY类别的原型,COMPOSITION等其他类别是根据模板文件中定义的原型映射关系推理得出。
2.3 AQL代码生成
由于AQL是一种基于模型的查询语言,它只依赖于各原型的定义,所以其脚本生成过程可以分为3个步骤。首先根据用户指定的原型及原型之间的层次(包含)关系来确定FROM子句。其次,根据查询条件,比较运算操作和具体数值,构造出各条件表达式,然后对多个条件表达式进行逻辑组合,得到WHERE子句。第三,根据用户选择的数据项,得到相应的openEHR路径以生成SELECT子句。当需要时还可以使用ORDER BY子句对返回的结果集进行排序。
2.4 数据格式转换
过程挖掘关注于以事件日志形式记录的业务流程中的活动(事件),这些活动通常包括案例号(ID)、活动名称、执行者、时间戳等属性。AQL查询结果的原始形式往往是二维表结构。例如,openehpy开源项目在openEHR服务器执行AQL脚本之后返回的是数据框(DataFrame)对象。由于返回文件的格式不能直接用于过程挖掘分析,因此需要对结果进行相应的转换。openXES (www.openxes.org)是一个面向XES标准[14]的开源Java项目,课题组利用它来实现符合XES规范的读取、写入和存储事件日志。
为了实现服务器端的AQL查询功能,需要3个准备步骤。首先,从CKM下载或使用原型编辑器(ocean archetype editor)工具创建业务所需要的原型。其次,使用模板设计器(template designer)将原型中的元素组合并约束在模板中,以操作模板的文件格式导出。然后,将目标业务系统所涉及的模板文件生成相应的Java类,并将患者的电子健康记录存储为各个类的实例。目前搭建的系统是基于openEHR软件开发工具包(SDK),后端服务器采用Postgres数据库作为持久化存储层。在数据上传到服务器完成后,可以通过openEHR REST API接口进行远程访问(http://10.9.9.112:18080/ehrbase/swagger-ui.html)。
3 系统验证与测试
目前,中国约有1 300万脑卒中患者,每年约有200万人死于脑卒中,是导致我国成年人死亡和致残的首要原因[15]。课题组以国家卫生健康委员会脑卒中防治工程委员会卒中院内筛查干预项目[16]为例,验证本文的技术方法,测试软件的功能。该项目目标是建立脑卒中筛查干预的国家数据标准,采集卒中高危人员的筛查干预和卒中患者的治疗随访数据,构建中国脑血管病大数据平台(http://chinasdc.cn),评估患者的卒中风险并进行干预,从而降低我国脑卒中人群的总体发病率。该项目的大数据平台基于openEHR进行数据建模,共涉及32个模板、82个原型、999个数据项,并通过RESTful API支持AQL调用和执行。表1列出了卒中院内筛查干预项目所使用的主要原型。该项目已在全国200多家卒中基地医院和上千家基层医疗机构开展工作,采集了超过500万的人群筛查数据和60万卒中患者的电子病历数据,可用于测试本文提出的数据抽取方法,为医疗过程挖掘研究提供数据资源[17-18]。

表1 卒中筛查项目使用的原型示例Table 1 Examples of archetypes used in stroke registry programs
软件的图形操作界面如图4所示,能够支持SELECT、FROM、WHERE、ORDER BY等常用查询操作,以及AND、OR、NOT等逻辑条件组合。用户在点击“选择项目”或“设置条件”按钮后,图4下方的参数列表给出了查询的相应元素信息,以帮助生成AQL代码。课题组在卒中院内筛查干预项目的合作医院部署了该数据抽取软件,经过对相关临床研究人员简单培训后,他们可以使用本工具生成相应的AQL查询脚本,或手工输入AQL语句,执行后获取检索结果(图5)。用户还可以将查询结果以常用的逗号分隔值(CSV)文件或转换成XES日志格式导出(图6)。

图4 抽取工具的图形操作程序界面Figure 4 Graphical user interface of the tool developed

图5 AQL代码与查询结果Figure 5 AQL scripts and query results

图6 部分生成的XES日志Figure 6 Generated event logs in XES format
在功能测试方面,课题组首先验证了该工具的扩展查询功能。例如,输入关键字“sex”(性别)后,提示在“openEHR-EHR-ADMIN_ENTRY.person.v1”原型中的“Tree/Person Basic Info/Gender”路径可能是用户要搜索的数据项,而只通过严格的关键字匹配时无法找到该结果。另外,课题组模拟了卒中院内筛查干预项目在临床研究中的3种典型查询场景。该软件能够分别生成相应的AQL脚本并将其提交到openEHR服务器执行,返回查询结果和转换后的事件日志。
案例1:查询所有高血压患者编号、血压值和检查时间,并按检查时间进行排序。高血压是指收缩压大于等于140 mmHg(1 mmHg=133.3 Pa)或舒张压大于等于90 mmHg。当输入“血压(blood pressure)”作为关键词,可以检索到相关的原型为“openEHR-ehr-COMPOSITION.encounter.v1”和“openEHR-EHR-OBSERVATION.blood_pressure.v2”。其余操作过程如图4和图5所示。
案例2:查询所有诊断为卒中的患者。在输入“诊断(diagnosis)”后,系统列出了涉及的原型为“openehr-ehr-COMPOSITION.report.v1”和“openehr-ehr-EVALUATION.problem_diagnosis.v1”。原型中数据项和对应属性组成的路径为“d/data[at0001]/items[at0002]/value/defining_code”。最后,生成的AQL语句如下,其中“I63”和“I64”是卒中对应的ICD-10编码。每个ehr_id代表一个特定的患者。返回所有符合条件的患者列于结果集中。

SELECT e/ehr_id/valueFROM EHRe CONTAINSCOMPOSITIONr[openEHR-EHR-COMPOSITION.report.v1] CONTAINSEVALUATIONd[openEHR-EHR-EVALUATION.problem_diagnosis.v1]WHERE d/data[at0001]/items[at0002]/value/defining_codematches(“I63”,”I64”)
案例3:查询实验室检验报告中的微生物项目名称和标本取样时间。当输入“实验室检查(laboratory test)”后,用户选择了“项目名称(analyte name)”、“采集时间(collection time)”和“报告编号(uid)”3个数据项。这些数据项所属的原型分别为“openEHR-EHR-COMPOSITION.report.v1”,“openEHR-EHR-OBSERVATION.laboratory_test_result.v1”,“openEHR-EHR-CLUSTER.laboratory_test_analyte.v1”和“openEHR-EHR-CLUSTER.specimen.v1”。这些原型相互关联和嵌套构成一条复杂查询语句,工具生成的AQL代码如下。

SELECT c0/items[at0024]/value/valueasF0,//项目名称 c1/items[at0015]/value/valueasF1,//采集时间 c2/uid/valueasF2 //报告编号FROM EHRe CONTAINSCOMPOSITIONc2[openEHR-EHR-COMPOSITION.report.v1] CONTAINSOBSERVATIONo3[openEHR-EHR-OBSERVATION.laboratory_test_result.v1] CONTAINS(CLUSTERc0[openEHR-EHR-CLUSTER.laboratory_test_analyte.v1] and CLUSTERc1[openEHR-EHR-CLUSTER.specimen.v1])WHEREc2/name/value=MikrobiologischerBefund
除了使用自动生成的AQL脚本之外,用户还可以直接输入简单查询语句。例如输入“SELECT e/ehr_id/value FROM EHR e”统计所有电子健康记录的编号。以上实验结果表明该工具的查询功能较全面,能够覆盖和支持包含时间信息的各种过程挖掘应用场景。
4 讨论
与本文相关的研究工作主要有:Yang等[19]基于扩展的贝叶斯网络表示openEHR原型,并使用推理过程来发现相关的原型信息。Almeida等[20]提出了一种将openEHR存储库中的数据导出到标准表的方法,以方便其他软件进一步的数据分析。Khennou等[21]将大数据分析工具集成到基于openEHR的系统中,以改进对电子健康记录的分析过程。然而,这些研究并没有提出一种便于临床人员使用的信息检索和数据抽取方法。Delussu等[22]采用openEHR的标准规范实现了一种可扩展的数据访问层,以管理结构化、异构的生物医学与临床数据。EtherCIS(ethereal clinical information system)是一个与openEHR临床信息表示标准相兼容的开源平台,支持从AQL到SQL的转换。刘骏健[23]基于AQL开发了模板查询语言(TQL),并定义了TQL的4种操作,如选择、插入、更新和删除。但是,这些研究并没有针对医疗过程挖掘所需要的事件日志进行优化和格式转换。本文的研究工作建立了openEHR和过程挖掘标准存储格式之间的桥梁,有助于屏蔽底层数据源的异构性。虽然开发的软件界面参考了EHRServer开源项目,但是课题组增加了(扩展)搜索和生成AQL代码及格式转换的功能。
5 结论
本文提出了一种基于openEHR AQL面向过程挖掘的数据抽取和格式转换方法,开发了抽取转换软件,使临床科研人员无需掌握实际数据库结构,通过领域知识模型来查询所需的临床数据。课题组以卒中项目为例,测试验证了软件的功能正确性。其优点是对临床业务人员来说应用简便,支持点击式操作创建查询脚本,能够屏蔽底层异构信息系统的操作复杂性。与使用SQL直接查询关系数据库的方法相比,AQL查询的性能稍低,这需要进一步优化openEHR服务器的底层实现。本工具的另一个局限性是目前只支持对英文原型的查询,课题组计划利用中文知识图谱实现对中文同义词和下义词的扩展查询。最后,虽然课题组的工具实现了构建和执行AQL的基本功能,但还需要增加其功能的完整性,如支持Exists、In等查询关键字和算术操作,以提高对临床科研的实用价值。
猜你喜欢
江苏省社会主义学院学报(2022年2期)2022-05-07
华人时刊(2021年13期)2021-11-27
小资CHIC!ELEGANCE(2021年45期)2021-01-11
诗选刊(2020年12期)2020-12-03
思维与智慧·上半月(2018年10期)2018-11-30
思维与智慧·上半月(2018年9期)2018-09-22
英美文学研究论丛(2018年2期)2018-08-27
小天使·二年级语数英综合(2017年12期)2017-12-05
——以夹江县“插花式”精准扶贫为例
中共乐山市委党校学报(2017年5期)2017-10-21
——以乐山市为例
中共乐山市委党校学报(2017年5期)2017-10-21
