
基于深度学习的跨对象脑电睡眠分期研究
2022-08-18 00:56张金辉汪鹏李蕾
北京生物医学工程 2022年4期
张金辉 汪鹏 李蕾
0 引言
睡眠对人类健康至关重要,影响着人们日常活动的方方面面。研究表明,拥有良好睡眠质量的人会更健康,拥有更优秀的大脑功能[1]。相反的,睡眠周期中断则会导致一些睡眠障碍,如失眠或睡眠呼吸暂停等。特别值得注意的是,睡眠阶段(如轻度睡眠和深度睡眠)对人类免疫系统、记忆、新陈代谢等都有着非常重要的作用。因此,通过睡眠监测和睡眠阶段分类来衡量睡眠质量是非常有价值的工作[2]。
睡眠阶段有6个,即:清醒期(wake,W)、快速眼动期(rapid eye movement,REM)和4个非快速眼动期(non-rapid eye movement,NREM)阶段(N1、N2、N3和N4)[3-4],睡眠分期就是将脑电图数据识别为这6个阶段中的一个。通常,睡眠专家会根据多导睡眠图(polysomnography,PSG)确定睡眠阶段。PSG主要包括脑电图(electroencephalogram,EEG)、眼电图(electro-oculogram,EOG)、肌电图(electromyogram,EMG),数据记录通常是30 帧/s,由睡眠专家按照时间顺序,参照相应睡眠分期标准,通过人工检查完成相应的阶段分期。但是,人工检查过程极为耗时费力,尤其是在数据量较大时,睡眠阶段分类的准确率极易受到相关专家个人经验和疲劳程度的影响。因此,迫切需要借助人工智能、深度学习等先进技术,研究开发自动睡眠分期系统来帮助睡眠专家进行阶段分类标注。
目前,应用自动分类标注系统实现睡眠分期需要面对一个严重挑战就是有标数据不足,而人工智能、深度学习等自动分类技术通常都需要规模足够的标注数据才能获得令人满意的效果。为了应对这个挑战,国际顶级会议NeurIPS 2021 首次提出并设立了专项竞赛BEETL Competition(Benchmarks for EEG Transfer Learning)。其中任务之一就是跨对象脑电睡眠分期,该任务的初衷是服务于医疗自动诊断领域,任务目标是在睡眠脑电图数据中自动标注睡眠阶段。
具体而言,在临床诊断过程中,EEG脑电图数据的黄金标准(gold standard)即有标数据仍然需要由医疗专家人工分析得到。鉴于脑电图的记录可能有几小时至数天的时长跨度,数据规模较为庞大,需要专家投入大量时间和精力,由此也导致获得有标数据的过程成本十分昂贵。基于此,研究对EEG的自动分析可以有效减少诊断所需时间,并通过标记需要进一步检查的信号部分从而有望用于实时检查。概括来讲,NeurIPS 2021提出并设立跨对象脑电睡眠分期竞赛任务,其目标旨在解决跨对象的脑电睡眠分期问题。考虑到在实际医疗诊断过程中,现有的基于同一标准收集的脑电图记录是容易获得的,而且不同对象的脑电图数据规模和特点也有所不同,因此值得研究的问题是:使用数量较为充分的部分对象(非目标对象)的对照数据集,结合目标对象的少量数据,如何进行可靠的目标对象自动睡眠分期标注。
近年来,深度学习在不同领域得到了广泛的应用,并显示出其优于传统机器学习的无需领域知识的特点。一些研究使用卷积神经网络(convolutional neural network,CNN)进行睡眠阶段的自动分类[5-6]。但CNN无法有效地建模EEG数据的时序依赖关系,由此提出了递归神经网络(recurrent neural network,RNN)用于获取EEG数据的时序相关性[7]。
除了使用不同模型以外,睡眠分期的研究还需要解决数据不平衡的问题。例如文献[8]使用了合成少数类过采样技术(synthetic minority oversampling technique,SMOTE)[9]进行过采样从而平衡数据。目标检测领域的难易样本数量不平衡问题与睡眠分期的数据不平衡问题相似,为解决此问题,Lin等[10]提出了效果更好的焦点损失(focal loss)调整高置信度样本的损失占比。
但目前尚缺乏专门针对跨对象的脑电睡眠分期研究。为了对此开展探索性研究,参考文献[10]的思想,本文基于NeurIPS 2021 BEETL Competition提出的任务一,针对数据类别不平衡问题,设计实现了一种基于类感知损失函数的单通道跨对象脑电睡眠分期方法,并进行实验分析。
1 研究方法
1.1 数据来源
实验数据使用的是NeurIPS 2021 BEETL Competition提出的任务一——跨对象脑电睡眠分期所发布的数据。数据来源于PhysioNet Sleep Dataset,该数据集包含由专家标注的197个整晚多导睡眠图睡眠记录,可用于有监督学习,其中包括了EEG、EOG和EMG,数据集的睡眠分期原则遵循R&K (Rechtschaffen and Kales)标准,睡眠阶段分为W、R、N1、N2、N3、N4。
在该任务一中,数据集只选择了EEG信号,包含了2个EEG通道(Fpz-Cz,Pz-Oz),采样率为100 Hz,每一段样本时间长度为30 s,称为一帧,每一帧属于某一类睡眠阶段。在该数据集中,每一个对象的帧都被随机打乱,帧之间不具有时间上的连续性。任务提供了一个Sleep Source有标注源数据集,该数据集包括来自40名对象的80段记录,每段记录包含若干帧,年龄为25~59岁(中青年组),基于此数据集,目标是从中青年组数据集迁移睡眠分期能力到60~80岁(老年组)和80岁以上(极老年组)年龄段的数据,而老年组和极老年组分别只提供了5名对象的有标注数据,显然其规模远小于中青年组,不足以支撑深度学习模型的训练。数据集各睡眠阶段具体样本数量分布如表1所示。
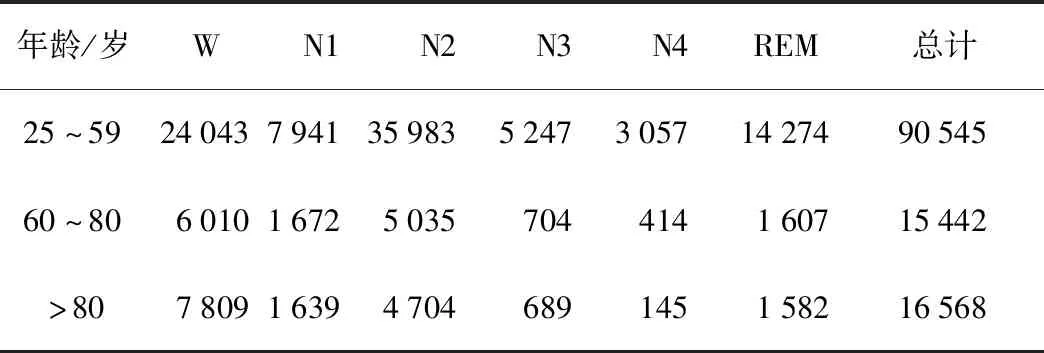
表1 不同年龄组各睡眠阶段数据分布Table 1 Data distribution of sleep stages of subjects in different age groups
1.2 数据集划分方法
NeurIPS 2021 BEETL Competition专项竞赛任务一提出了从中青年组到老年组和极老年组的两个迁移目标,为了充分利用已有全部有标注数据,课题组将其设计为两次有监督训练。在每次训练中,使用相同的数据集划分方法,把全部中青年组数据都作为训练集的一部分,再将80%的目标数据集混入训练集中,即训练集中同时包含了中青年组全部数据及80%的老年组/极老年组数据,从而提供迁移学习的信息,将10%的目标数据集作为验证集,其余10%的目标数据集作为测试集,用于训练完成之后的测试。基于表1中的样本数量信息,划分后的各集合样本数量如表2所示。

表2 不同年龄组数据集划分Table 2 Data set partition for different age groups
1.3 睡眠分期方法
首先需要对脑电图数据进行预处理。每条EEG脑电图记录的时间序列为X={x(i)|i=1,2,…,N},N=3 000,对X进行标准化处理,计算步骤如下。
(1) 对X求平均值:
(1)
(2) 对X求无偏估计标准差:
(2)
(3) 对X进行标准化:
(3)
(4) 扩大X的尺度:
X′=1 000X
(4)
扩大X的尺度是为增大模型学习的梯度,此处的1 000倍扩大参照文献[11]来实现。
使用AttnSleep模型[12]进行自动睡眠分期标注,该模型总体结构如图1所示。

图1 AttnSleep模型结构图Figure 1 Architecture of AttnSleep model
该模型包含特征提取、时域上下文编码器(temporal context encoder, TCE)两个模块。特征提取模块包含了多尺度卷积MRCNN(multi-resolution CNN)[13]和自适应特征重新校准AFR(adaptive feature recalibration)两个部分,MRCNN从不同的频带中提取对应于低频和高频的特征,AFR则建模特征间的相互依赖关系以增强特征学习。TCE模块使用了多头注意力机制以有效获得特征中的时间相关性[14]。
文献[13]使用了不同卷积核大小的CNN可以提取不同的频率特征,因此本文设置的MRCNN使用了双分支CNN。数据的采样率为100 Hz,尺寸为400的卷积核的时间窗口为4 s,可以捕获周期低至0.25 Hz的正弦信号;尺寸为50的卷积核的时间窗口为0.5 s,可以捕获周期低至2 Hz的正弦信号。
AFR用于重新校准MRCNN学习到的特征,AFR使用残差SE模块(residual squeeze and excitation block),自适应选择有助于分类的特征。在残差SE模块中,使用平均池化压缩(squeeze)信息,然后接2个全连接层用于聚合(excitation)信息。
TCE模块堆叠了两个相同的结构,其中包含了多头注意力层,注意力头的数量设置为5,然后是残差连接的层正则化层,然后是两层全连接层。
特别地,该模型使用了一个类感知损失函数,用于解决训练数据中不同类别样本的分布不平衡问题,利用此损失函数的特性,可以使模型获得迁移学习的能力。模型的优化器部分选择使用Adam来最小化损失函数并学习模型参数[15]。
1.4 类感知损失函数
一般方法中使用的是多类别交叉熵损失函数:
(5)
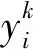
为了解决这个问题,文献[12]使用了类感知损失函数(class-aware loss function):
(6)
wk=μk·max(1,lg(μkM/Mk))
(7)
式中:wk表示分配给k类别的权重;μk是可调节的参数;Mk是k类别的样本数。
由式(7)可知,类别权重wk由对应类别的样本数量和可调参数μk控制。参照表1,通过对任务数据进行分析可以得到:在中青年组数据中,N2阶段的样本数量最大,占比为39.74%,N3和N4阶段的样本数量较少,占比分别为5.79%、3.38%;在老年组数据中,W阶段数据的样本数量最大,占比为38.92%,N3和N4阶段的样本数量占比分别为4.56%、2.68%;在极老年组数据中,W阶段数据的样本数量最大,占比为47.13%,N3和N4阶段的样本数量占比分别为4.16%、0.88%。参考文献[17],N1阶段与N2阶段和REM阶段较为接近,容易被分类错误。由此分析可得,不同年龄段的样本数据类别分布相差较大。对于前文所述的数据划分结果,由表3可以直观地得到训练集和测试集的分布差异。
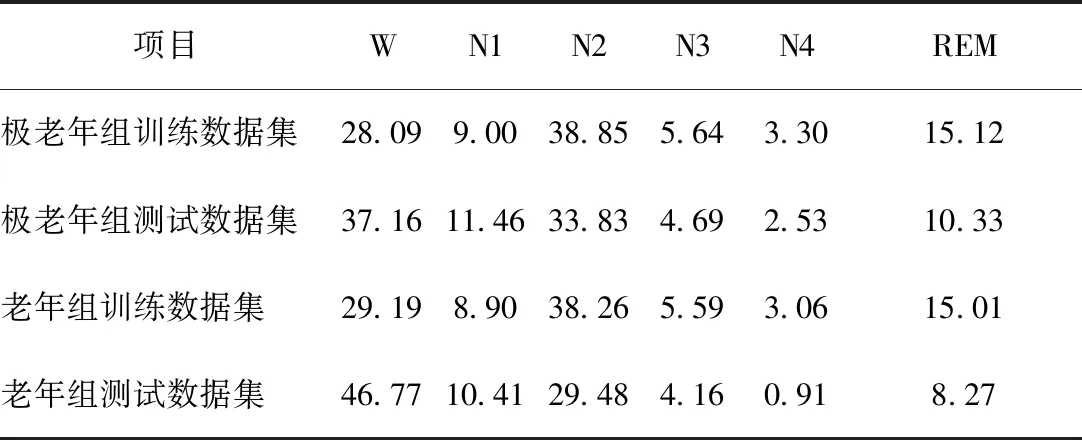
表3 训练集和测试集分布(单位:%)Table 3 Distribution of training data and testing data(unit: %)
基于以上分析并结合式(7),为各个类别设置的μk值如下:
(8)
取a=1,b=1.5,c=2,该组参数在不同设置下的对比实验参见表4。式中:K是类别数量,在该任务中即为6;μk参数用于控制wk的值,因此μk需要除以K保持μk小于1。

表4 极老年组各类别分类准确率Table 4 Accuracy of each class in the very old group
2 实验结果与分析
2.1 对比模型和评价指标
在本文实验中选择EEGNet[16]作为对比模型,该模型是一种广泛应用于EEG的紧凑型卷积神经网络。EEGNet的两个卷积核尺寸分别设置为F/2和F/8,F是数据的采样频率即100,dropout的概率设置为0.25。 AttnSleep模型的输入选择了Fpz-Cz通道,EEGNet模型的输入为双通道。EEGNet和AttnSleep的学习率都设置为0.001,batch size为512,epoch为50。

2.2 实验结果及分析
本文基于1.2节构建的2个跨对象训练集分别训练2个睡眠分期模型,每次迭代中在验证集上测试模型性能,选择指标最高的模型分别在老年组和极老年组的测试集数据上进行睡眠分期测试实验,对应的参数设置保持一致。
表3显示了单通道AttnSleep及其改进模型和双通道EEGNet模型在老年组和极老年组数据上的实验对比结果,以及针对类感知损失函数的消融实验结果。从整体得分Score看,表中显示了AttnSleep模型及其改进模型相比EEGNet模型在老年组和极老年组数据上都拥有更强的分类能力。从消融实验看,表中AttnSleep(+CA-loss)代表在AttnSleep模型基础上使用了类感知损失函数的改进模型,可见与未使用类感知损失函数的AttnSleep模型相比, AttnSleep改进模型在老年组和极老年组2个组别分别提升了0.64和1.32。而且类感知损失函数在极老年组的提升效果更加明显,由表3的数据分布可知,相比于老年组,极老年组和中青年组的数据分布差异更大,因此类感知损失函数在极老年组的效果会更好。由表5及表6的具体类别分类准确率结果可知,类感知损失函数可以提升样本数量较少的N3、N4阶段的分类表现,也支持了上述结论。

表5 EEGNet与AttnSleep实验结果Table 5 Performance of EEGNet and AttnSleep

表6 老年组各类别分类准确率Table 6 Accuracy of each class in the old group
此外,为了检验从中青年组到老年组和极老年组数据迁移学习的效果,表3中最后一行给出了不融合中青年组数据,仅使用自身老年组80%数据训练的非迁移对照组实验结果。可以看出,融合使用了中青年组数据迁移学习的AttnSleep(+CA-loss)在两个组别的指标分别提升了0.26和5.41。由此可见,融合中青年组数据迁移学习可以提升老年组和极老年组的睡眠分期效果,尤其是在数据类别不平衡问题更严重的极老年组,提升效果更加明显,这也再次印证了类感知损失函数的作用。
综上,实验结果表明AttnSleep模型相比于EEGNet在该任务下的表现更加出色,且类感知损失函数对于跨对象的脑电睡眠分期有一定的增益作用。
3 讨论与结论
本文在跨对象的睡眠分期任务上探索改进了AttnSleep模型,重点面向数据集中类别不平衡的特点,设计并实现了类感知损失函数。采用本文所述的基于类感知损失函数的AttnSleep改进模型在NeurIPS 2021 BEETL Competition任务一提供的数据上进行了对比实验和消融实验,结果指标表明其有助于在目标数据不足的情况下提升跨对象脑电睡眠分期的效果。
本文的探索同时也验证了跨对象脑电睡眠分期任务的可行性。未来,优化特征提取、改进模型结构、不局限于年龄跨度的自适应脑电睡眠分期等,都将成为需要深入探索的方向。
猜你喜欢
心理学报(2022年10期)2022-10-12
今日农业(2022年15期)2022-09-20
心理学报(2022年3期)2022-03-08
心理学报(2022年1期)2022-01-21
少儿画王(3-6岁)(2020年4期)2020-09-13
小天使·二年级语数英综合(2019年10期)2019-11-08
东方教育(2018年20期)2018-08-22
体育时空(2017年6期)2017-07-14
读者·校园版(2015年19期)2015-05-14
海外英语(2013年8期)2013-11-22
