
基于三维卷积神经网络降低肺结节检测假阳性的方法
2022-08-18 00:56侯智超杨杨李晓琴王晓曦高斌
北京生物医学工程 2022年4期
侯智超 杨杨 李晓琴 王晓曦 高斌
0 引言
全球肺癌患者数量较多并且死亡率高,挪威的一项研究指出,超过2/3的患者在诊断时已处于肺癌晚期(IIIB期和IV期)[1]。研究表明对肺癌进行早期筛查和治疗可以有效降低患者的死亡率,肺结节是肺癌早期特征之一,对其进行准确检测是肺癌早期筛查的关键。2011年美国国家肺癌筛查试验显示,使用计算机断层扫描(computed tomography,CT)筛查的参与者比使用胸部X线筛查的参与者死于肺癌的风险低15%~20%[2],目前临床中,主要是通过专业的医生观察CT切片来检测肺结节,这种方式工作量巨大,并且诊断结果很大程度上依赖于医生的临床经验[3]。尤其是对于医疗资源匮乏的地区,早期肺癌患者常常得不到及时有效的治疗导致病情加剧。因此,开发一种准确高效的自动肺结节检测方法辅助医生诊断显得尤为重要。同时,该技术也可以应用于疾病筛查和远程诊断,提高医疗资源的利用率。
近年来,深度学习技术不断发展,并在图像识别和分类方面表现出了极大的优势。其中卷积神经网络(convolutional neural network,CNN)算法结合了特征提取和分类[4-5],因此被广泛应用于肺结节的筛查任务中。Setio等[6]将传统的二维CNN应用于三维立体图像的研究,针对每个候选结节,提取了多个二维视图,并设计了3种探测器以分别探测不同形态的结节,通过融合3个系统的结果,达到了较好的效果。但其检测模型仍是基于二维CNN技术实现的,网络不能动态地学习到结节的空间信息。Ding等[7]的研究使用二维CNN得到结节的候选,但灵敏度不够高,因此又训练了基于三维卷积神经网络(three-dimensional convolutional neural network,3D-CNN)的降低肺结节检测假阳性模型进一步提高敏感性。Kim等[8]将结节周围的不同大小的区域放缩到固定尺寸,并以不同的顺序逐步积分,再加以结合,其多尺度的处理方法本质上是对数据进行了扩充,过程较为复杂,对计算机的运算能力需求较高。总之,二维平面的类结节形态的区域更容易引起模型的误判,使得网络模型从轴向切片很难区分血管等组织中的结节,造成检测结果假阳性偏高。
随着高维度、多尺度等方法的出现,大量的研究在设计模式上采取增加分支、分解问题等方法,并在不同规模的实验中证实了采用3D-CNN策略对空间信息的获取效果上比二维CNN要好[9],在肺结节筛查与假阳性减少任务中均取得了不错的效果[10-12]。Dou等[13]提出了基于3D-CNN的降低假阳性方法,分别使用不同尺寸样本训练网络,并将输出进行融合得出最终的预测结果,在LUNA16数据集上证明了方法的有效性。Xiao等[14]提出的MSH-CNN使用具有不同层次上下文结构的多尺度三维数据块作为输入,使用3D-CNN的两个不同分支来提取特征并进行了融合,为提高肺结节分类准确率提供了新思路。高慧明等[15]提出的多尺度3D-CNN肺结节假阳性降低方法,将每个候选结节通过不同输入尺度的3D-CNN的检测,将结果进行加权融合,得到了较好的结果,为提高结节分类准确性提供了参考。因此将目标问题分解再策略性地综合多个步骤的结果,可以有效提升检测的效率。
综合以上,本文提出一种基于3D-CNN降低肺结节检测假阳性的方法,针对数据集分布不均衡的问题,结合空间多视角采样和无监督的方法,对正负样本分别进行预处理,然后搭建3D-CNN并进行训练,利用多模型集成策略直到得到最优的结果,并在独立测试集中进行了检验。
1 数据
本研究基于美国2016年肺结节分析(Lung Nodule Analysis 2016,LUNA16)挑战赛的开源数据集开展,该数据集由888套CT图像组成,共包含1 186个直径在3 mm以上的结节。官方提供了两个版本的假阳性减少任务的候选注释,其样本分布统计如表1所示。此外,官方还提供了一份不相关点位注释,标记了直径小于3 mm和仅由1~2名医生标注的结节。

表1 样本分布统计Table 1 The statistics of sample distribution
本文用V1和V2来表示版本1和版本2,由于多位医生可能对相同的结节给出了标记,因此各版本中标记为结节的数量大于实际结节的数量,课题组使用V2数据集进行训练,并在V1数据集上进行测试。
1.2 数据处理
1.2.1 数据集预处理
LUNA16数据集中的CT图像由不同仪器扫描产生,成像因素造成灰度和分辨率的差异。为了防止由于图像的差异而对后续研究产生影响,需要对图像进行像素归一化处理。根据人体肺部附近组织及空气CT值的分布范围,本研究使用线性变换将CT切片(-1 000,400)范围的值归一化到(0,1)之间。
(1)
式中:Hmax为400,Hmin为-1 000,分别为最大和最小亨氏值;Vp和V分别为亨氏值和归一化后的值。
此外,针对不同CT图像的空间分辨率各不相同的问题,本研究基于Python的SimpleITK程序包,使用线性插值法对数据进行重采样,将数据的空间分辨率调整为1 mm×1 mm×1 mm。
LUNA16数据集中肺结节的直径均小于40 mm,最大直径为32.27 mm。权衡计算效率与在空间上可提取特征的范围,本研究选取40×40×5大小的数据块作为研究单元。其中,包含结节的样本为正样本,不包含结节的样本为负样本。由于在处理负样本时,所选取区域可能囊括不相关点位,影响数据集质量,为保证采样时不会涉及到这些不相关的点位,课题组对V1、V2版本中在不相关点位半径30 mm(样本对角线长度的一半)内的点位进行了筛除,V2中负样本的数量由753 418减少为638 752,V1中负样本的数量由549 714减少为466 933。
1.2.2 基于无监督学习的负样本数量均衡
LUNA16数据集中,负样本的数量是正样本的数百倍,为了降低正负样本分布不均衡对模型效果的影响,使用图像增强技术对正样本进行扩充。同时使用K均值(K-means)聚类法对负样本进行无监督聚类,将具有相似特征的负样本聚为若干类,从而进一步实现正负样本的均衡分布。
由于每个样本的维度较大,因此课题组在对负样本进行聚类之前构建了自动编码器,对其进行特征降维。
(1) 基于自动编码器的特征降维。自动编码器是神经网络的一种,由编码器和解码器组成。编码器用于学习如何将输入图像压缩为一个n维向量,解码器则学习将这个向量重构为输入图像。当解码器的输出与编码器的输入足够接近时,则可认为这个n维向量可以代表输入图像。
本研究利用自动编码器分别提取了图像的8维、16维、32维、64维特征向量。实验中发现当特征向量的维度设置为32维以上时,解码器的输出与编码器的输入相似度较高,但维数过大计算压力也会随之增大。因此,本研究最终选用32作为编码器输出的特征维数,训练轮次为5轮。本文设计的自动编码器的结构和参数如图1所示。
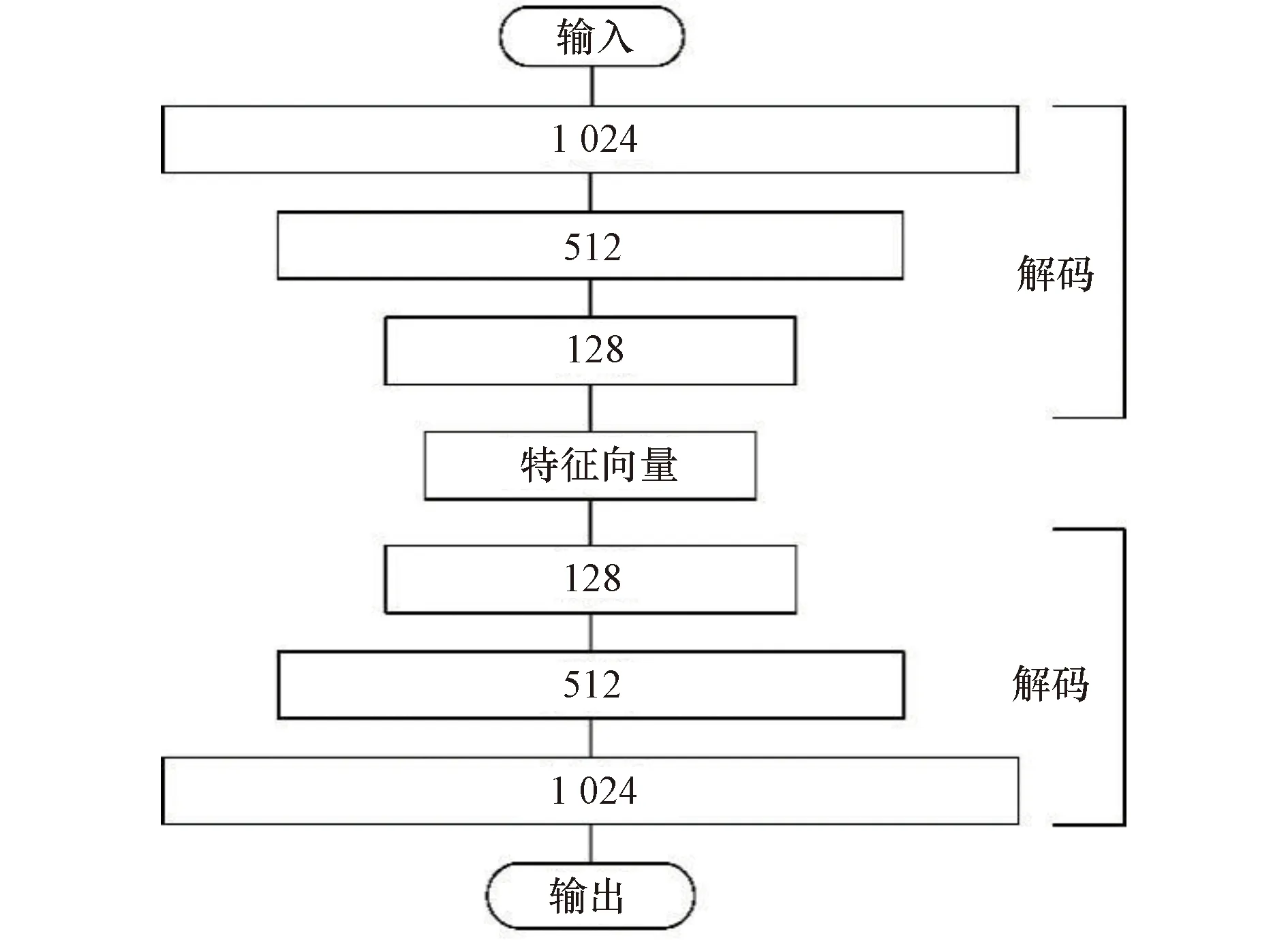
每层的数字表示当前层的神经元个数,编码部分N个神经元输出N维的编码特征值,每个神经元的权重由自动编码器自动调整。图1 自编码器结构示意图Figure 1 Schematic diagram of the structure of Auto Encoder
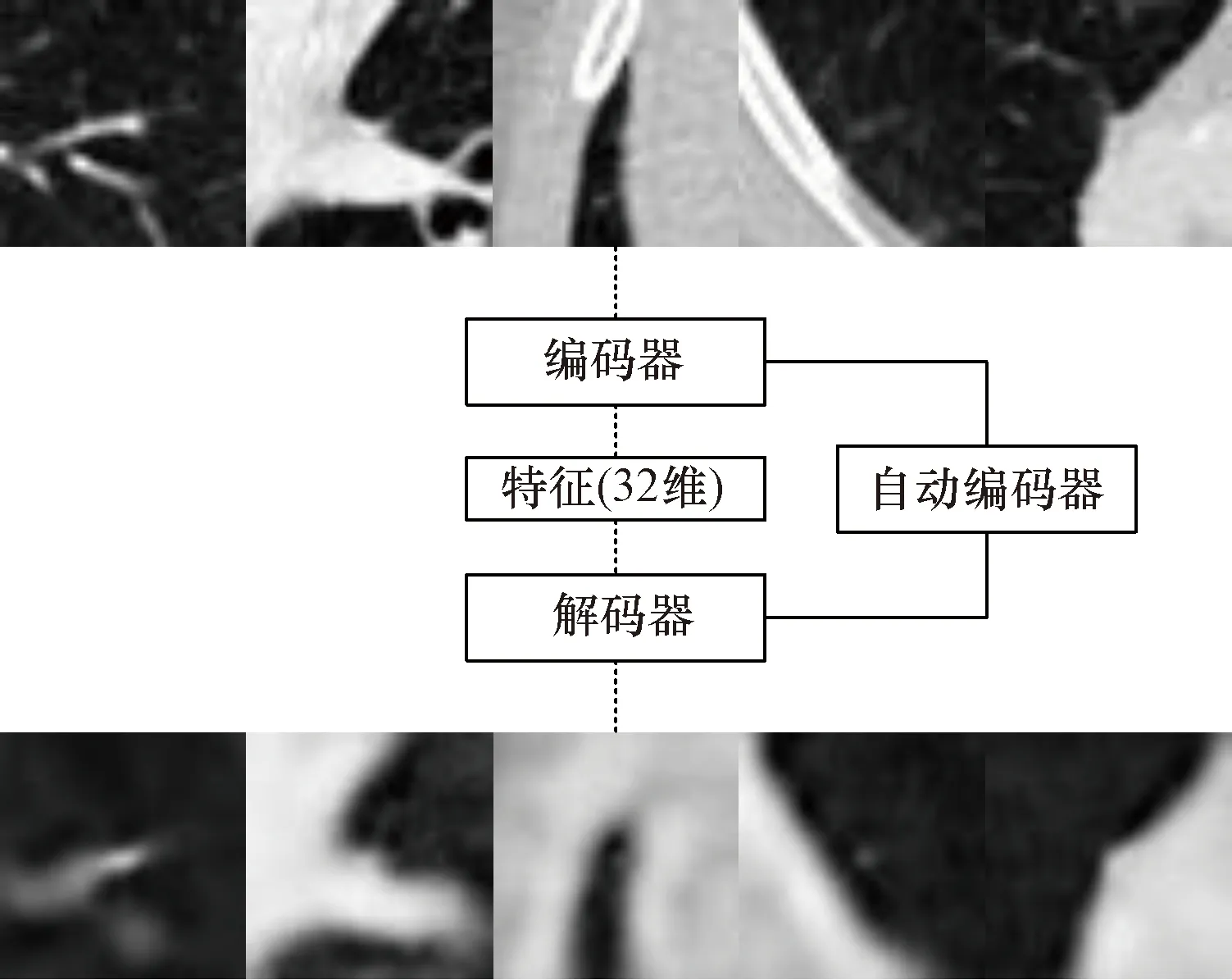
限于篇幅在此只展示了5个样本的第3层切片的编解码过程。图2 编解码过程示意图Figure 2 Schematic diagram of the encoding and decoding process
通过对比图2的输入图像和输出图像,可以看出经过训练的自动编码器较为准确地重建了输入图像,这种有损压缩的方式一定程度上抑制了部分噪声。此时通过自动编码器提取到的特征向量可作为代表性特征用于无监督聚类。
(2) 无监督聚类。K-means算法是一种常见的无监督聚类算法,通过迭代计算来不断优化聚类结果,其步骤是首先随机选取K个初始的聚类中心,然后计算各样本与各聚类中心的距离并将样本分配给距离它最近的聚类中心所组成的簇。每完成一次样本分类后,就要重新计算一次新簇的加权平均值并作为新簇的聚类中心,这个过程将不断重复直到满足设定的终止条件[16]。
本研究使用K-means算法对负样本进行无监督聚类。为确定K的取值,课题组应用手肘法,使用所有负样本数据绘制了数据误差平方和(the sum of squares dueto error,SSE)随K的取值的曲线,如图3所示。

图3 K值-数据误差平方和曲线Figure 3 The curve of K and SSE
从图3曲线中可以看出SSE随K值在K为3和5时都有较为明显的拐点,但本文聚类的目的是为了充分利用负样本,建立多个模型来降低网络运算压力,聚类数不宜过少,因此课题组最终采用5作为K的取值,将图像聚类为5类,聚类后的5类负样本数量分布如表2所示。图4展示了小部分数据聚类后第3层切片的视图效果。
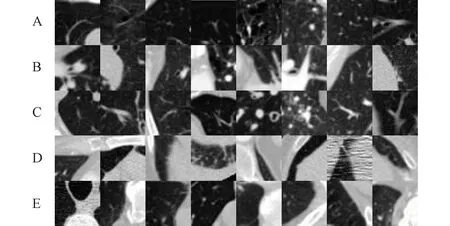
A、C两类肺部空腔占比很大,C较A略多一些组织结构;B、E两类多为靠近肺壁的空腔位置,但在数据块中相对位置分布不同;D类 则多为条状或较小的空腔结构。图4 K-means聚类结果示例Figure 4 Clustering result example of the K-means method

表2 样本数量分布统计Table 2 The statistis of each category of the sample
由表2可以看出,5类负样本的数量分布并不均匀,为了避免某类样本数量极多或极少引起深度学习网络对特征的学习有所偏向,课题组对于数量相对较多的A类和C类进行随机筛选以保证各类数据量相对平衡。降低数据量的方法如式(2)所示。
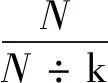
(2)
式中:n为降低数量后的样本数,向下取整;N为每个类别的样本数;k为常数,本研究中将k设置为80 000。
1.2.3 基于多视角的正样本扩充
在单次扫描的CT图像中,正样本相对于负样本数量极少,因此有必要对正样本进行合理扩充来平衡正负样本的数量。肺结节在空间上具有一定的对称性,从二维来进行采样及扩充是无法提取到结节的空间信息的,通过在空间多个视角上进行采样,再利用三维数据增强方法进行样本扩充,可以使训练集包含更丰富的特征。常用的图像扩充方式包括随机平移、翻转和旋转等。课题组选用随机平移、翻转和旋转的方式来对正样本进行扩充。具体方法是首先根据官方提供的1 186个正样本点位,在CT图像中进行了空间多视角采样,共选择了8个方向,每个方向上都会得到一个5×40×40的样本。采样方向如表3所示。然后将得到的样本以90°的整数倍进行旋转扩增,之后再进行轴向180°翻转实现进一步扩增。在此仅展示采样方向为D1、D8样本扩增示意图,如图5所示。

表3 空间采样方向的数学表示Table 3 The mathematical representation of spatial sampling direction
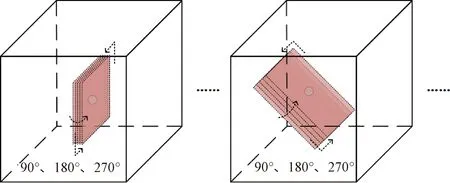
图5 数据扩增示意图Figure 5 Schematic diagram of data augment
在数据采样的过程中,有小部分数据距离CT图像边界太近,自动切片时在横向、纵向和轴向3个方向无法获取形状统一的数据,因此课题组舍弃了这一小部分数据,最终扩充后正样本的数量为83 520个。然后将5类负样本的每一类均匀分为5份,无法整除的部分放在最后一份中,分别与正样本进行组合,得到5个训练数据集,每个数据集的正负样本数量分布基本相同,数据分布如表4所示。
表4 数据集样本数量统计Table 4 The statistics of dataset
2 方法
2.1 CNN相关技术简介
1998年Lecun等[17]首次正式提出CNN的概念。CNN是一种包含特征提取器的多层神经网络,由卷积层、池化层、全连接层和激活层等网络层组成。以下对各层原理进行简单介绍。
2.1.1 卷积层
CNN中卷积层用来提取图像的特征信息,卷积核的个数决定该层输出的特征图的数量,卷积核的尺寸和移动距离决定了特征图的特征分布和精度。三维卷积的表达式:
Xk(x,y,z)=
(3)
式中:Xk和Xk-1表示第k个卷积层的输入与输出;W表示该卷积层的三维卷积核;b表示偏置项;σ(·)表示激活函数。
2.1.2 池化层
池化层也称为下采样层,其主要作用是减少参数数量,防止过拟合。本研究采用最大池化方法,池化窗口设置为2×2×2,移动步长为2,即每一次移动保留最大的值,以对卷积后得到的特征图进行降维,池化过程如图6所示。

图6 最大池化过程示意图Figure 6 Schematic diagram of max-pooling process
2.1.3 激活函数
在CNN中,激活函数可以引入非线性因素,增强网络的学习能力,在卷积层和神经元起着至关重要的作用。本研究在卷积层和全连接层使用修正线性单元(rectified linear units,ReLU)激活函数[18]:

(4)
ReLU激活函数是一个分段线性函数,对输入起单侧抑制的作用。
在输出层使用Softmax 激活函数[19]对结果进行分类:
(5)
式中: 输出S表示每一个元素的范围都在(0,1)之间,并且所有元素的和为1的概率分布;Z表示包含任意实数的K维向量。
2.1.4 全连接层与批归一化层
全连接层由多个神经元组成,用于将卷积层和池化层提取到的特征进行汇总并映射到样本标记空间。批归一化层用来对数据进行分批次的归一化操作,在网络中的作用是防止数据分布偏移和梯度消失,将数据分布调整为均值为0方差为1的高斯分布,该层可以加速网络的收敛。
2.1.5 Dropout层
Dropout层在CNN中是独立的一层,其将网络中上一层的神经元按照设置的比例随机进行关闭,一般设置于卷积层或全连接层之后,可以有效防止过拟合。
2.2 网络构建与训练
本研究利用Python编程语言,基于Tensorflow-Keras深度学习库搭建的3D-CNN结构框图如图7所示。
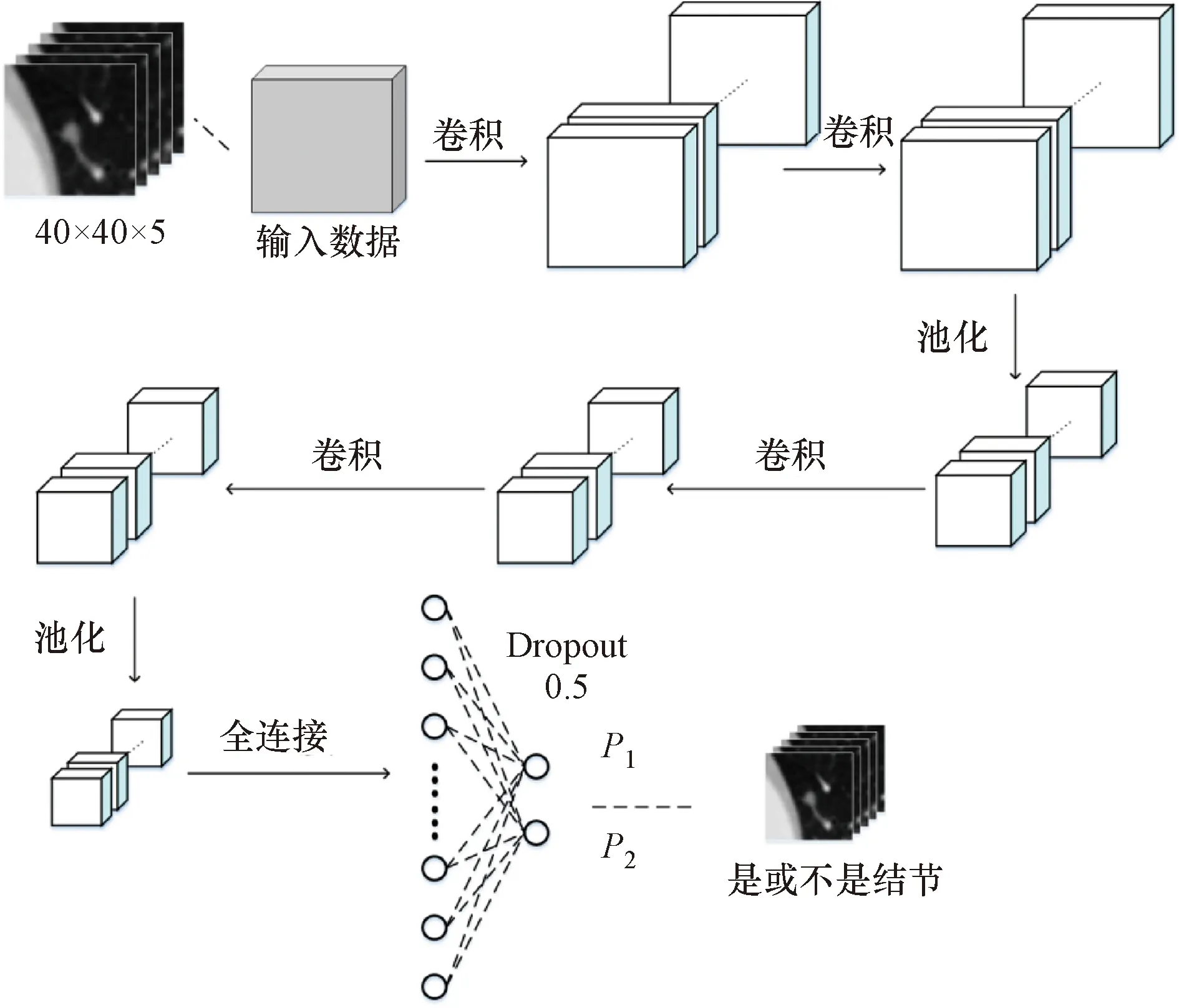
图7 3D-CNN结构框图Figure 7 Structure block diagram of our 3D-CNN
本文分别使用训练集1~5对所构建的网络进行训练,根据准确度和损失值的变化趋势来调整网络的结构和参数直到得到效果较好的模型。图 7网络的结构及各层参数如表5所示,输出层(全连接层2)的P1、P2分别表示属于两种结果的概率。

表5 3D-CNN的结构和参数Table 5 The structure and parameter of our 3D-CNN
本研究网络的训练基于TensorFlow-gpu V1.7.0和Keras V2.1.6,搭配CUDA V9.0.176和cudnn V7.4使用NVIDIA Quadro K2200 GPU进行加速计算,平均每个模型训练时间为2~3 h。
2.3 基于简易集成法的多模型预测
简易集成法是机器学习常用的策略,在样本量较多或数据不平衡时对样本采取降采样,采样数取决于样本数目较少的类别,以保持每类样本数目相近,如1.2.2节的负样本降采样。采样后针对采样得到的子数据集训练模型,并对预测概率值取均值或加权均值得出。由1.2.3节所述可知,本研究的训练集中负样本是没有交叉的,在每个训练集中正负样本是均衡的,且正样本经过了充分的扩充,保证了模型具有较高的敏感性。使用直接平均法将5个模型的预测值进行集成,进一步提升了模型的特异性,使整个系统更加稳健,准确率得以提升,在结果与分析中对比了集成模型和单一模型的预测结果。
3 结果与分析
本研究使用官方给出的V1版本的数据集作为独立测试集,分别对5个数据集训练的模型进行测试,并使用敏感性(sensibility)和特异性(specificity)对模型进行评价。
(6)
(7)
式中: TP表示真实的正样本预测为阳性的个数(true positive,TP);TN表示真实的负样本预测为阴性的个数(true negative,TN);FP表示真实的负样本预测为阳性的个数(false positive,FP);FN表示真实的正样本预测为阴性的个数(false negative,FN)。本文模型的评价结果如表6所示。

表6 模型评价结果Table 6 Results of model evaluation
从表中可以看出课题组的网络生成的5个模型均有较好的表现,集成模型对每个模型异常的检测结果有进一步的削弱作用,通过直接平均对每个模型在测试集的预测结果进行综合,可以再次矫正误判,模型的性能因此得到提升。
此外,课题组采用了自由响应接收机工作特性(free-response receiver operating characteristic,FROC)[9]曲线证明了集成模型的有效性,如图8所示。特性曲线的横坐标为平均每组CT图像中假阳性的个数,纵坐标为敏感性。该准则通过计算竞争性能指标(competition performance metric,CPM)来衡量算法的性能,CPM指横坐标为1/8、1/4、1/2、1、2、4、8时的平均敏感性。单一模型和集成后模型的测试结果的FROC曲线如图8所示。
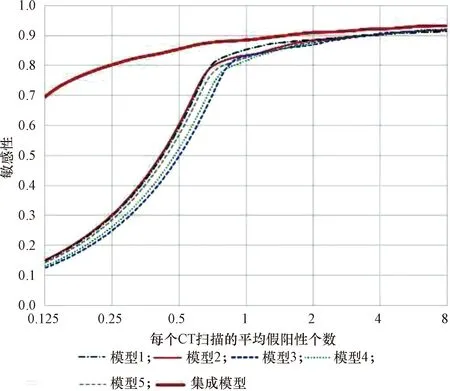
图8 FROC曲线Figure 8 The FROC curves
由图8可以看出,集成模型对系统性能有所提升,尤其是对低假阳性平均数水平下的敏感性有明显提升。集成思想将各单一模型的短板进行了二次纠正,对单一模型的不足进行了改进。每个训练集中丰富的特征分布使得网络在学习时可以更为全面地拟合某种规律。
4 讨论与结论
为降低CT图像初筛工作中肺结节的假阳性率,本文提出了一种基于3D-CNN降低肺结节假阳性的检测方法。该方法基于LUNA16挑战赛提供的两个版本数据进行训练和测试。针对数据集中正负样本分布不均衡的问题,本研究使用空间多视角采样技术来扩充正样本,充分利用了结节周围的空间信息;基于自动编码器及K-means无监督聚类方法对负样本进行分类,实现负样本降采样的同时保留了负样本的多样性。结果表明,训练集中样本的均衡性对提高分类模型的性能起重要作用。在评估模型的效果时,利用简易集成法对5个模型的结果进行综合判决,避免了单一模型可能带来的偶然性误差,有助于提高系统的鲁棒性。
相比于模型CADIMI[9]和任敬谋等[20]使用的基于二维CNN的肺结节检测方法,本文方法更充分地利用了结节与非结节的空间有效信息,CPM分数具有优势。相比于JackFPR[13]和DIAG CONVNET[6]基于3D-CNN的肺结节检测方法,本文方法的CPM分数较为领先,且在假阳性平均数大于1时得分较高,但与模型CUMedVis[13]相比仍有提高空间(表7)。
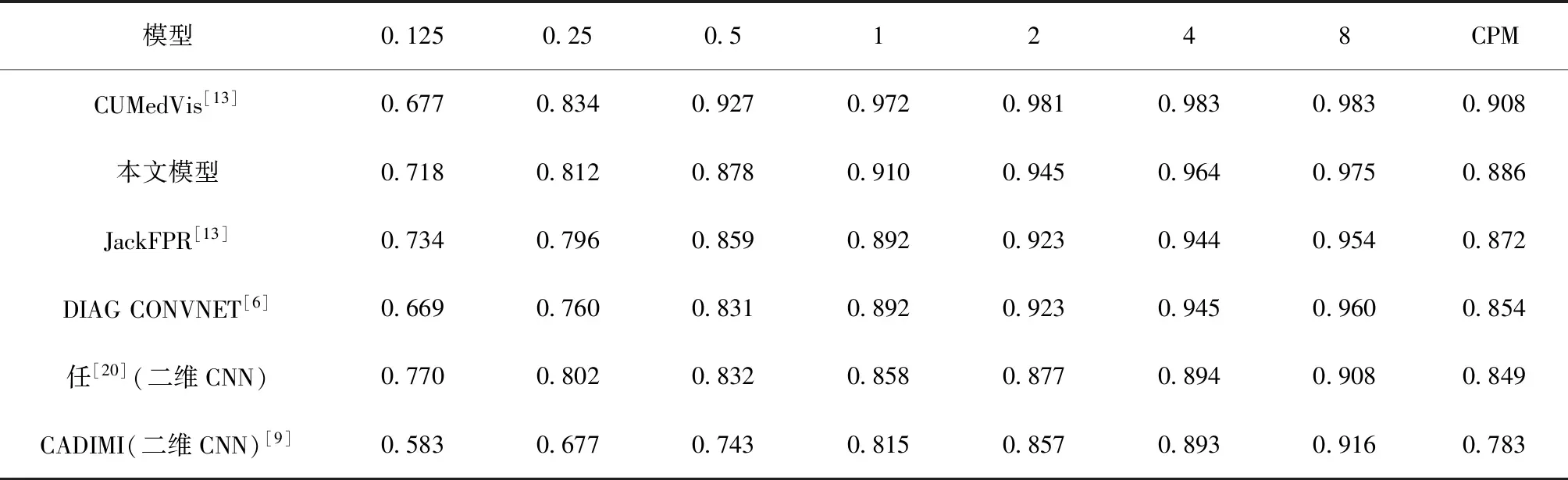
表7 本文模型与已有模型性能指标对比Table 7 The performance comparison between this model and the existing models
在独立测试集上的测试结果表明本文的方法可以有效降低肺结节检测假阳性,可以为肺癌筛查工作提供有效帮助。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2022年8期)2022-08-31
南京理工大学学报(2022年1期)2022-03-17
汽车实用技术(2022年4期)2022-03-07
好日子(2021年8期)2021-11-04
祝您健康(2021年9期)2021-09-05
数字技术与应用(2021年1期)2021-03-24
幸福家庭(2020年10期)2020-08-25
师道(2019年11期)2019-12-02
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
