
考试难度及其测量学调控手段
2022-08-11 04:05杨志明徐庆树
教育测量与评价 2022年4期
杨志明 徐庆树
每年的大规模高利害考试如高考、中考结束后,试卷难度问题就会成为大众关注的焦点。[1][2][3][4][5]考试是人才选拔和学业诊断的高效的、重要的手段,但考试太难会导致考生无从下手,考试太容易又会导致缺乏区分度。有人觉得专家们有能力预判考试难度,但到目前为止,专家们一直没有找到精准预判考试难度的办法,相反,专家们“看走眼”的事情却时有发生。那么,如何认识考试难度?有没有相对科学的考试难度调控方案?本文从教育测量学角度对考试难度及其测量学调控手段进行梳理,以便为科学把控考试难度提供一些新的思路。
一、考试难度概述
在教育测量学领域,考试难度体现为题目难度,题目的难度目前有3种不同的定义方法。考试难度的设定是否恰当需要从考试的目的等方面进行评价。用于选拔拔尖人才的考试与区分中上水平考生的考试,以及用于诊断学生学业发展的均衡性方面的考试,其试卷的难度要求是很不一样的,我们不能简单地用太难或太容易来评判某一项考试的好坏。
1.题目难度的3 种定义
依据经典测验理论(classical testing theory,CTT)和国际考试行业的惯例,题目难度(item difficulty)可以选用每题平均得分(average item score,AIS)与对应题目满分值(Max)的比值(pvalue)作为指标,其定义如式(1)所示。
p=AIS/Max ……………………………(1)
其中,当题目为0/1 计分题目时,p为题目的通过率,即答对该题的考生比例。与此对应的另一个指标q=1-p则是答错此题的人数比例。
显然,这种题目难度的定义非常直观,计算也特别简单,但它有两个缺陷。其一,难度值p越大,题目越容易;难度值p越小,题目越难。这种“反着说话”的方式容易引发大众的困惑。其二,难度值p不是一个度量单位等距的指标。因此,在评价试卷平均难度时,直接计算所有试题难度值p的均值的方法存在着“底气不足”的缺点。比如,一道通过率为0.80 的题目并不能解释为它比一道通过率为0.40 的题目容易一倍。
为了克服难度p指数的这些缺点,美国教育考试服务中心(Educational Testing Service,ETS)的测量学专家们设计了一个基于所有题目难度值分布服从正态分布假定的难度指标Δ,其定义如式(2)[6]所示。

其中,Δ 是基于考生总体(如全省考生)的题目难度指标,Zp是正态分布条件下题目难度p值所对应的Z值,其取值范围为[-3,+3]。
由式(2)可知,Δ为等距度量系统上的值,其取值范围为[1,25]。显然,难度指标Δ 值越小,题目越容易;难度指标Δ 值越大,题目越难。这就是说,难度的第二种定义Δ克服了难度p值的主要缺点,不仅理顺了难度Δ 值的大小与题目难易的一致性,而且具有等距特性的Δ 指标方便试卷中所有题目难度的平均值和标准差的计算,给出了试卷难度的精准表达方式。
与经典测验理论不同,现代测量理论中的题目反应理论(item response theory,IRT)通过logistic 曲线拟合每个题目在考生总体上的作答表现的方式,用IRT 模型中的位置参数b重新定义了基于等距量表的题目难度参数。由于IRT 模型众多,下文以应用最广的双参数logistic 模型(two-parameter logistic model,简称2pl,适用于0/1 计分题目)为例进行解读。非0/1 计分题目一般采用广义分步计分模型(generalized partial credit model,简称GPCM),限于篇幅,本文不讨论GPCM 的情况。
具体来说,对于0/1 计分的题目,其IRT 双参数logistic 模型如式(3)所示。
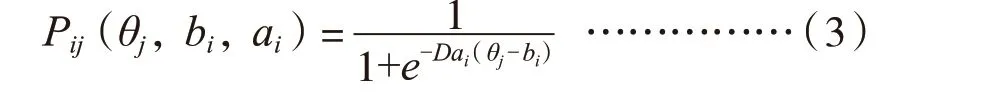
其中,Pij表示考生j答对题目i的概率,D=1.7,ai为题目i的区分度,bi为题目i的难度,难度取值的理论范围为[-4,+4],但在实际工作中一般设定其取值范围为[-3,+3]。
假若考生总体(比如全省考生)都作答了该题,则水平高的考生答对该题的概率必定会高,水平低的考生答对该题的概率必定会低。因此,在考生总体的能力分布范围内,考生答对该题的概率可以表现为关于考生能力参数θ的一个S 型题目特征曲线(item characteristic curve,ICC),其形式如图1 所示。
其中,纵坐标为考生答对题目的概率,横坐标为考生能力水平(θ),题目难度被定义为题目特征曲线拐点的横坐标值(b)。例如,图1 中最右边的曲线拐点位置为2,表示题目难度b=2,图形中左边两条曲线的拐点位置为-1,表示它们的难度b都等于-1。

图1 双参数logistic 模型的题目特征曲线
需要说明的是,ICC 在拐点的切线斜率被定义为题目的区分度(a),它反映了在曲线拐点附近的难度变化所带来的题目答对概率的变化情况。区分度(a)值越大,表示该题目在题目难度附近区分考生水平的能力越强,反之,则区分考生水平的能力越弱。例如,图1 中左边两条曲线拐点相同(即题目难度相同),但过拐点位置曲线的切线斜率不同。ICC 越陡峭,说明题目在曲线拐点附近的区分度越大;反之,说明题目在曲线拐点附近的区分度越小。
显然,基于IRT 的题目难度与基于CTT 的题目难度定义很不相同。首先,基于IRT 的模型参数b具有等距特点。其次,基于IRT 模型的题目难度与考生的能力水平参数θ被定义在一个共同的度量系统即量表(scale)之上。再次,同一道题目对于能力水平不同的考生具有不同的区分度。比如,图1 中最右边的题目难度为2,则表明该题只对能力水平θ值接近2 的考生最有区分能力,对于能力水平太低的考生(如θ值在-2 附近的考生),该题几乎没有区分能力(大家基本上都会答错该题)。最后,难度相同的题目也可能具有很不相同的区分度(比如图1 中左边两条ICC 所代表的两道题目具有很不相同的区分度)。因此,在讨论试卷的区分度时,必须综合考虑试卷内所有题目的难度和区分度两个参数。也就是说,不能简单地因为题目太难就认定某次考试的区分度不高,或题目太容易就判定考试的区分度会高等。此外,在我国的许多重大考试中,大众和专家们都偏爱大题目(如每题满分5 分或10 分或20 分等)。对于这种大题目,除了难度值,还可以挖掘关于题目质量的其他信息。因此,很有必要对考试难度(含题目难度和分步计分难度)及其对社会影响的情况做深入讨论。
2.考试难度的两种评价
考试难度完全是围绕着考试目的来设定的。比如,为了实现选拔拔尖人才的目的,考试可以设置得很难;为了使得提前学、反复练的边际收益最小,考试可以设置得非常容易。换句话说,考试太难或太容易无所谓对错,只要能实现教育目的或选才目的就可以。通常,考试难度的评价方式有两种:其一是相对评价,即重点评价考试项目是否较好地区分考试机构所期待区分的考生群体;其二是绝对评价,即重点评价考试项目是否较好地帮助考生发现了各自的长处和短处。
(1)考试难度的相对评价
假若考试使用方的目的是选拔拔尖人才,如鉴别出考生总体中最优秀的5‰的人以方便少数顶尖高校的招生录取工作,则需要选择大量(如超过1/3 或1/2 分量的)难题组成试卷,只有这样才能有效区分优秀生中的最优学生。假若考试的目的是区分中上水平的考生以方便“双一流”等高校招生,则需要多用中等偏难的题目组成试卷,如在试卷中设定容易题目、中等难度题目、难题的分量分别为1/5,2/5 和2/5,或者1/5,3/5和1/5 等。假若考试的目的是淘汰极少数不合格的考生,则需要多用中等偏易题目组成试卷,如在试卷中设定容易题目、中等难度题目、难题的分量分别为1/2,1/2 和0/2 等。
特别地,假若有证据表明“很多优秀学生在初中毕业时还没有开窍,他们在高难度的考试面前还未能有机会展现自己的发展潜力”,则应当鼓励设置较容易的中考试卷,以避免过早淘汰潜在优秀人才。比如,在中考试卷中设定容易题目、中等难度题目、难题的分量分别为4/7,3/7 和0/7,或3/7,3/7 和1/7 等,即可达到这个目的。若能辅之以“普及12 年制义务教育”和“在普通高校增设职业技术教育专业或学院”等措施,则中考试卷完全可以变得十分容易。这种降低中考难度的办法或许能弱化“不要输在起跑线上”的错误教育理念,强化终身学习的正确观念。假若教育主管部门期待用中考来引导大众重视学生的德智体美劳全面发展(比如,强化综合素质评价的选拔功能等),而不是局限在应考科目上,则降低中考难度可以使得提前学、反复练和大量补课等措施的边际收益几乎为零,进而倒逼“双减”,使得每名学生都有时间和精力去学习不同的内容,体验不同的发展方向。
(2)考试难度的绝对评价
假若考试目的是诊断学生的学业掌握情况,则题目难度可以根据某种标准(如国家课程标准等)所要求的知识内容广度和能力层次深度设置试卷难度,而不必在乎有多少考生会做还是不会做。这种考试通常会要求报告每名考生在各个知识模块上的掌握水平,以及考生的能力发展层次,一般不要求报告考试总分,因为考试主办方的目的是了解学生在知识和能力发展方面的缺点和优点,以便调整教学进度和难度等。
此外,从经典测验理论的视角看,考试难度p值是相对于考生群体来定义的。考生群体水平高,则题目的得分均值与题目满分值的比值p(如0/1 计分题目的通过率)就高,反之,p值就低。因此,在估算题目的难度参数值时,国际考试行业十分注意应考群体的代表性。基于非代表性应考群体所估算的题目难度往往是一个带有偏差的估计值,或者高估题目难度(应考群体水平普遍较低),或者低估题目难度(应考群体水平普遍较低)。因此,在组卷或建设考试题库时,所有题目的难度参数估计值需要通过测验等值(test equating)的方式调整在一个共同的度量系统之上。比较理想的做法是针对考生总体设定题目难度度量系统,随后增加新题目时先做好题目参数链接的工作。题目难度等参数等值工作不仅在CTT 理论框架下必须完成,而且在IRT 理论框架下也必须完成,具体方法本文略过。
根据上述讨论,大众或考评机构比较容易判断每次考试的难度是否符合考试的目的。图2 是某市中考英语科目中书面表达试题的考生成绩分布情况。
由图2 可知,假若去掉缺考者或完全放弃英语科目者(平均得分为0.5 分的22328 人),其他6 万多名考生在该题目上的得分分布基本为正态分布。这说明本次中考英语科目中书面表达试题的难度把握较好,对于各种能力层次的考生具有较好的区分度。

图2 某市中考英语科目中书面表达试题的考生成绩分布
需要注意的是,在总计8 万多名考生中出现了2 万多名学生弃考该题的情况,值得从教学改进的角度(绝对评价角度)做进一步探究,但在估算该题难度时,所有弃考者不能包括在考生样本之中,否则,该题的难度会被大大高估(其实并没有那么难),因为这2 万多名考生放弃作答该题不等于他们在这方面的知识和能力水平为0。换句话说,直接运用CTT 或IRT 方法估算题目难度参数时,必须确保考生样本对总体的代表性,并非在任何条件下使用所有应考者数据的题目难度估算结果都是准确的。
二、调控考试难度的测量学方法
在国际考试行业,调控考试难度的测量学方法主要有3 种:其一,利用小规模试测方式估算题目的难度等参数,并实现题目参数等值,然后在正式考试组卷之前估算整个考试的难度;其二,采用计算机化自适应测试(computerized adaptive testing,CAT)[7][8]模式或计算机化自适应多阶段测试(computerized adaptive multi-stage testing,ca-MST)[9][10][11][12]模式,测试系统能根据考生在前期的作答表现自动调整随后的题目难度,或更容易或更难,直到测量精度达到要求;其三,运用标准设定(standard setting)方法,通过专家组预估考试的难度。
1.利用代表性小样本试测新题的方法预控考试难度
在国外的许多大型考试中,所有新题都需要通过试测的方式获得题目难度等参数的估计,并根据试测的结果重新调整试题内容或表达方式等。这是因为,至今为止,所有的专家预估方法都无法完全凭主观判断准确预估题目难度,专家也是人,他们难免有“看走眼”的时候。
通常,试测工作的一个简单方式是在命题工作基本完成的情况下(或在高考、中考正式开考前10~20 天),选择一个与考生总体非常匹配的10~30 人样本,在完全保密的状态下完成新题目的试测工作。这些考生可以是已经被有关高校提前录取了的学生,或者是命题组中已经完成了命题任务的专家,特别是来自中学的教师。
通过对考生进行微小试测,题目中的大部分不妥之处一般能够得到发现。这些可能的问题包括(但不限于):(1)选题需要用到课外背景知识,有可能导致某个特定人群(比如农村考生或女生)作答不利;(2)题目表述可能引发歧义;(3)主观题所需要的作答演算过分复杂,可能导致作答该题会大大超时;(4)客观题中的单项选择题可能没有正确答案或存在多个答案等。有条件的考评机构往往会通过事先建设好题库的方式预估考试难度。
国外也有考试项目通过把新题藏匿在部分考生的正式考试之中的方法预测题目的难度等参数,样本量一般为600~1600 人,所选考场大多在“应试”风气不太严重的地方,这些新题不会计入考生成绩。显然,我国的一些高利害考试不宜采用国外的这种问题解决办法,只能通过高成本的方式实施完全保密状态下的微小试测方式来预控考试难度。
2.采用计算机化自适应测试方式控制考试难度
计算机化自适应测试是根据考生前期作答的表现,测试系统自动调整其随后所要求作答的题目或题组,使得题目或题组的难度与考生水平逐渐接近。其理论基础主要是题目反应理论,其基本特征是考试的个性化和等值化,即不同考生所要求作答的题目可以在难度和区分度、数量、作答时长等方面不同,但其考试成绩可以通过测验等值技术表达在一个共同的度量系统(量表)之上。
目前,计算机化自适应测试的模式主要有两种:基于题目层面的CAT 模式和基于题组层面的ca-MST 模式。国外使用CAT 模式的典型代表为工商研究生入学考试(GMAT)以及美国若干州的教育考试,使用ca-MST 模式的典型代表为研究生入学考试(GRE)以及基于美国共同核心课程标准的联考(the smarter balanced assessment consortium’s tests,SBAC)等。显然,计算机化自适应测试或计算机化自适应多阶段测试彻底解决了考试难度不可控制的问题,因为水平高的考生会被智能化的计算机测试系统不断推送更难题目,直到考生作答错误,并达到某种预设的测量精度才停止。水平低的考生也会被智能化的计算机测试系统不断推送更容易的题目,直到考生作答正确并达到某种预设的测量精度才停止。换句话说,考试无所谓难或容易,因为每个人的考试都是量身定做的。
不过,要实施这种计算机化自适应测试,需要具备一定的条件。首先,考试机构需要有一支专业的考试技术团队,相关高校需要培养出一批具有博士水准的掌握了IRT 和测验等值技术的人才。其次,考试机构需要建设一系列动态更新的考试题库,题库中所有试题的难度等参数都已经被估计好,并被链接在一个共同的度量系统之上。此外,需要有一批能够为考试实施提供计算机化测试的IT 服务机构,并具有考试安全方面的法律保障体系等。
3.采用标准设定的方法预估考试难度
在无法实施新题预测或计算机化自适应测试的条件下,使用标准设定的方法可以粗略预估考试难度,进而控制考试难度。
标准设定中的“标准”通常包括两个方面:其一是内容标准(content standard),其二是表现标准(performance standard)。[13][14][15][16]内容标准指的是某个年龄或年级的考生需要掌握的知识范围或技能领域,其关注的是“是什么”的问题,通常是以课程标准、考试说明(test specification)等形式进行说明的。表现标准指的是某特定等级(如合格、良好、优秀等)的考生对某个知识或技能应该掌握的程度。
标准设定的方法有很多,但大体上可以归纳为两类。其一是基于测验的方法(test-centered methods),如莱德尔斯基(Nedelsky)方法、艾贝尔(Ebel)方法、安戈夫(Angoff)方法、书签标记(bookmark)方法等。其二是基于考生的方法(examinee-centered methods),如临界组(borderline group)和对照组(contrasting groups)方法等。[17][18][19]
标准设定的基本思想(以艾贝尔方法为例)如下:
首先,组建一个专家小组。
其次,专家小组从以下两个角度对每道试题做出判定:在决定等级水平时,该道试题所考查的知识或能力内容有多重要,即专家们需要确定该题是极端重要(essential)、重要(important)、一般(acceptable),还是无足轻重(questionable)的;一个具有某个等级(如优秀)最低水平的考生,正确作答每道试题的可能性有多大。
最后,根据专家小组针对每道试题中的两个问题做出的初始判断,利用Excel 模板,综合专家小组的其他结果,求得具有某个等级最低水平考生需要答对全部题目的百分数。
依据以上思路,命题者可以大体预估题目难度和考试难度。限于篇幅,利用标准设定方法预估题目难度的具体方法另外专门讨论。需要强调的是,专家们的主观判断仅仅是个参考,他们“看走眼”的情况是无法避免的。换句话说,标准设定方法只是没有办法的办法。
总之,无论是用于选才、学业诊断,还是用于某种政策引导,大规模高利害考试的难度需要事先设定好,否则会带来不必要的管理成本。在教育测量领域,调控考试难度的方法主要有3种,即在保密状态下对新题目进行微小规模的试测、采用计算机化自适应测试模式,以及参照标准设定的方法预估题目难度,命题人员可以根据考试目的,参考实际情况选择适当的方法,科学把控考试难度,节约管理成本。
猜你喜欢
心理学报(2021年9期)2021-09-09
中国校外教育(2019年12期)2019-04-15
江淮论坛(2018年4期)2018-08-24
神州·上旬刊(2017年5期)2017-07-21
时代英语·高一(2017年3期)2017-06-13
时代英语·高一(2017年3期)2017-06-13
时代英语·高一(2017年3期)2017-06-13
时代英语·高一(2017年3期)2017-06-13
科技与创新(2017年8期)2017-06-07
电子制作(2017年2期)2017-05-17
