
基于深度哈希网络的肺结节CT相似图像检索方法研究
2022-08-11 14:37郝瑞秦亚雪甄俊平强彦
中山大学学报(医学科学版) 2022年4期
郝瑞,秦亚雪,甄俊平,强彦
(1.山西财经大学信息学院,山西太原 030006;2.山西财经大学管理科学与工程学院,山西太原 030006;3.山西医科大学第二医院医学影像科,山西太原 030001;4.太原理工大学信息与计算机学院,山西太原 030600)
目前全球的肺癌发病率和死亡率高且呈上升趋势。全球男性肺癌发病率和死亡率占恶性肿瘤首位,女性肺癌发病率占第3 位,死亡率占第2 位。肺癌的高发病率和死亡率严重威胁着人类健康和生命,是亟待解决的公共健康安全问题之一。肺结节与早期肺癌的关系密切,对肺结节进行早期筛查和诊断可以有效地降低肺癌的发病率,进而提高患者的生存率[1]。CT具有较高的密度分辨率,可以较好地识别出正常肺部结构与病理结构[2],是目前早期肺癌常规筛查的主要手段[3]。但人工阅读大量的CT图片及数据工作量繁重、工作效率低,且极易漏诊及误诊,已不能很好地满足临床需求;另外,由于肺癌存在同病异影和异病同影的现象,肺癌影像上的相似性也为诊断带来了极大的困难。近年来,受到社会与环境变化以及人们生活习惯的影响,肺部CT图像呈现出两个主要特征:数量上极速增长,内容上愈加复杂,出现医生数量和专业水平不能较好地满足目前肺部CT 图像诊断需求的现象。因此,若能将医生固有的经验能力和计算机独有的高速图像检索能力融为一体,建立大规模肺部CT 图像相似病灶快速有效的检索模型,充分利用肺部疾病历史数据实现类似于医生诊断过程的相似病例自动检索方法,可大大减少医生的工作量,同时也能辅助医生对相似病例的诊疗方案进行回顾性分析,更好的为患者提供定制化智能诊疗方案[4]。哈希算法由于其占用存储空间小和计算相似度速度快的优势,已广泛用于大规模医学图像检索领域[5-7]。在医学图像诊断应用中,针对肺结节CT 图像检索的深度哈希算法研究还相对较少,而肺结节CT图像的识别与检索在肺癌诊断和治疗中占据重要的地位。为了提高肺结节CT图像检索精度,本文鉴于深度哈希在图像检索上的优势,提出一种基于深度哈希的肺结节CT 相似图像检索方法。由于肺结节CT 图像通常情况下属于灰度图像,因此本文在网络设计中针对卷积神经网络与双向长短期记忆网络的通道进行一定的调整,并在该深度网络中嵌入哈希函数以获取有效的哈希特征。然后,本文针对所获取的哈希特征提出一种分级检索算法。首先利用搭建的深度哈希框架预测图像的标注信息,在所对应的类库中利用哈希编码检索得到一定数量的图像候选对象;其次,根据图像高层语义特征进行相似度排序获取相似的肺结节图像列表。
1 材料和方法
1.1 公开数据集
本文所采用的数据集是LIDC-IDRI[7]公开数据集。LIDC-IDRI 原始图像是由美国国家癌症研究所收集的。该数据集共收录了1 018 个研究病例,每一个研究病例都包括了两种文件,分别是肺部图像文件(.dcm)和由4 位放射科医师给出的诊断结果标注文件(.xml)。每一个病例都包含切片,每张切片大小为512×512 像素。本文利用1.2 节所述方法从LIDC-IDRI中分割肺结节图片,并根据肺结节图片对应的标注信息良恶性程度得到了5 类肺结节,其中良恶性程度为3 表示不确定信息,对该部分数据舍弃,剩下的整合为良性与恶性两种标签信息。良恶性结节的个数分别为2 102和1 313,所占比例分别为62%和38%,良恶性程度分布相对比较均匀。模型所用的训练集和测试集分别按照70%和30%的比例随机抽取。
1.2 ROI的获取
由于数据集中所有的肺部CT 图像,都会显示肺组织内部的空气、液体、脂肪、软组织等物质,因此,为了减少肺部CT图像信息冗余现象,有必要锁定图像中存在肺结节的感兴趣区域(region of interest,ROI)区域。本文首先利用二值化阈值分割算法确定肺实质区域,然后通过形态学膨胀腐蚀算法对分割出的区域进行边缘轮廓平滑处理,最后通过最大连通区域算法分割肺实质区域。通过读取XML 标注文件中的医师标注的良恶性程度信息和位置信息,将肺结节病灶区域所对应相应的肺实质区域进行识别并进行分割,并且为了统一图像大小,使其与设计的网络结构所要求的输入图像保持一致,将预处理得到的ROI 固定大小为32×32 像素的图像(图1)。
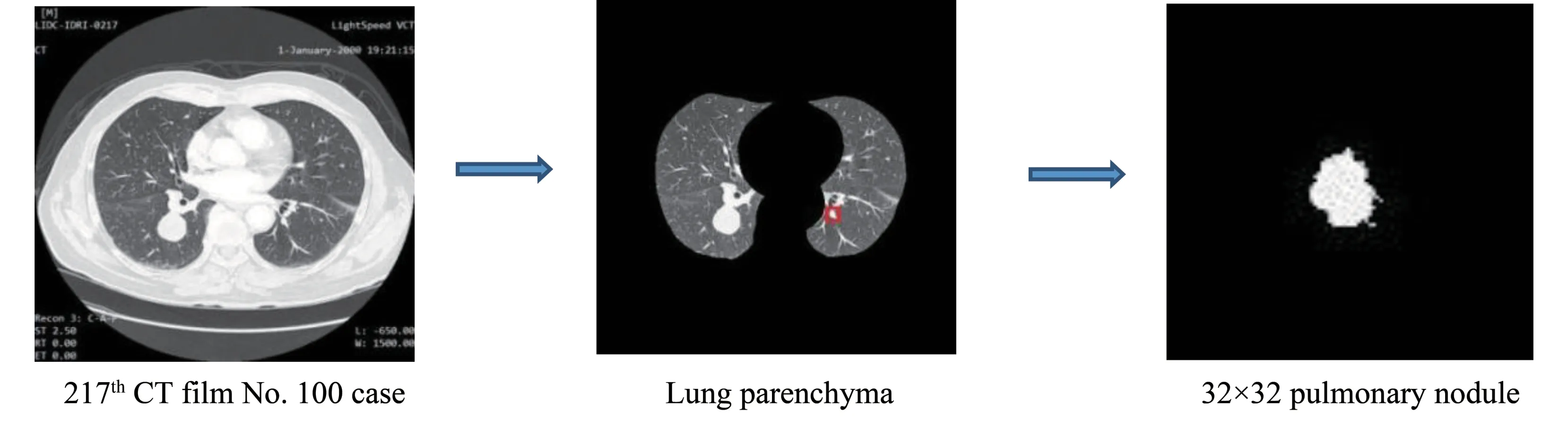
图1 肺结节ROI预处理过程Fig.1 Preconditioning of pulmonary nodule ROI
1.3 方法
本文研究的肺结节CT 图像检索主要包含3 大部分:①结合深度学习方法,针对肺结节CT图像设计一种能够完整表达图像信息的网络结构,并借助肺结节CT 图像标注信息进行监督学习;②在网络结构中嵌入哈希层,围绕哈希层节点数、哈希函数构造以及哈希表示等将高维图像特征映射为低维紧凑的哈希码;③针对所获取的高维图像特征以及哈希码,设计分级检索算法逐级计算图像相似度,并获取最终的检索结果。
1.3.1 图像特征表示 由于深度学习模型在特征提取方面效果较好,同时为了保证肺结节CT 图像检索的效率,本文通过联合注意力机制的卷积神经网络和双向长短期记忆网络,构造能够全面提取图像的潜在关键特征的深度模型,并在深度模型中嵌入哈希层,通过设置相应的激活函数与阈值函数以实现图像哈希特征的有效映射(图2)。

图2 肺结节图像深度学习模型Fig.2 Deep learning model of pulmonary nodule image
首先进行深度特征提取。肺结节图像具有相似度高和关联度高的特点,CNN在提取肺结节图像特征时,卷积和池化层都是独立地对局部图像区域进行操作,不会考虑其他图像区域从而忽略了不同区域间的上下文相关信息,这种上下文依赖性代表了图像中的有用空间结构信息[8-9],而BiLSTM 是由前向和后向的两个独立的LSTM 结构组合而成,各循环神经网络单元之间具有反馈连接,可以挖掘不同区域间依赖关系和上下文相关信息以获得更好特征表示。为增强提取的肺结节图像特征的表达能力,本文利用CNN 与BiLSTM 分别获取图像的局部区域特征与区域间上下文相关信息,为了避免信息学习的覆盖,本文采用了并行式的网络结构。同时为了减少信息学习冗余现象以及重点关注对标注信息影响较大的特征,本文在并行设计的2 个分支网络后面分别加入注意力机制(attention mechanism,AM)。此外,本文的网络输出分为2 个输出:第1 部分输出是嵌入哈希函数的深度哈希层,实现对图像的特征表示并映射为相应的哈希码;第2 部分输出连接到softmax 分类器,用于对肺结节良恶性类型进行有效分类,利用其类别信息监督学习图像特征。
其次构建哈希函数。构建合理的哈希函数,实现图像特征向哈希编码的映射是图像哈希方法应用于图像相似性检索至关重要的一部分。本文在全连接层后面插入一层哈希层学习图像的二值特征,其设计主要围绕哈希节点的选取、哈希函数的构造以及图像特征二值化3 个方面进行。①哈希节点的选取。由于全连接层提取的图像特征是高维的,不宜直接进行相似度计算,因此哈希节点个数在设置时不应超过全连接层节点数以达到降维目的,同时也要保证其能够唯一的表示图像的标签信息。因此最终的哈希节点数设置如公式1所示。
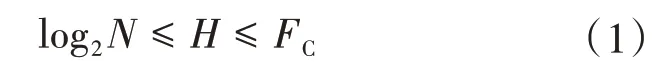
其中N表示标签数目,FC表示全连接层节点数;H表示哈希层节点数。②哈希函数的构造。本文在构造哈希函数时借鉴了LSH的核心思想,为了便于神经网络训练,本文选取sigmoid 函数作为哈希层的激活函数,如公式2所示。
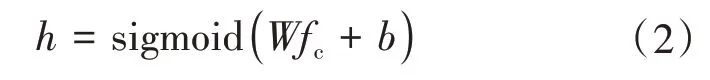
其中fc表示全连接层信息,h表示哈希层信息,W表示权重是,b表示偏置。③图像特征二值化。上述函数得到的结果是[-1,1]上的连续值,为了得到图像的二值特征,本文设置了阈值函数对哈希层的输出进行离散化。该函数设置如公式3所示。

最后对网络进行训练。本文CNN 采纳速度较快的AlexNet 网络,训练过程中最关键的是损失函数的设计与梯度下降算法的选择。本文在设计损失函数时遵循经验风险与结构风险的共同组合。其中经验风险本文选取交叉熵损失函数;同时为了对网络结构进行控制,缓解欠拟合或者过拟合现象的发生,本文加入了L2参数惩罚项,将正则化参数λ设为0.01。在实验中将Batch-size 设为32、Epoch设为25 进行训练。在神经网络训练过程中,本文选取Adam 训练器进行优化,该训练器易于训练且具有较好的鲁棒性。此外,该训练器是自适应学习率,不需要手动设置,提高模型泛化性。
1.3.2 查询图像检索 目前的检索策略是直接在低维空间计算训练集中每一幅图像与待查询图像的哈希编码之间的汉明距离。虽然具有计算效率高和内存占用少的优势,但是在哈希编码对原始图像表示学习中存在量化损失,进而导致其表示具有一定的局限性。因此,仅使用汉明距离衡量图像间的相似性不够准确。因此本文设计一种分级检索算法,实现由粗到细的精检索。其具体检索流程:①通过深度学习模型预测查询图像的肺结节标注信息,找到与其对应的类库,缩小搜索范围;②为了进一步快速筛选图像,在类库中计算与查询项汉明距离最接近的一组相似图像构建候选池,实现初步粗检索;③计算查询项与候选池内图像通过深度学习模型提取的全连接层特征之间的欧式距离度量相似度得到最终的检索结果,实现精确检索。
肺结节相似图像检索主要算法设计。
输入:待查询肺结节图像x,深度模型参数加载,肺结节图像库,返回查询结果数k;输出:k个相似图像。①初始化相似图像池集合T,检索结果集合S;②加载模型,将待查询图像输入该模型,得到其标注信息、哈希编码以及全连接层特征;③在对应的标注信息库中,根据公式(4)计算待查询项与类内图像哈希码之间的汉明距离,并对其进行排序;

其中,x和y为n位的哈希码,⊕为异或运算。取前2k个图像添加至T集合中,T={y1,y2,…,y2k};④对T 集合中的图像提取其全连接层特征;⑤根据公式(5)计算待查询项与T集合中各图像的欧式距离,并按照距离重新排序;
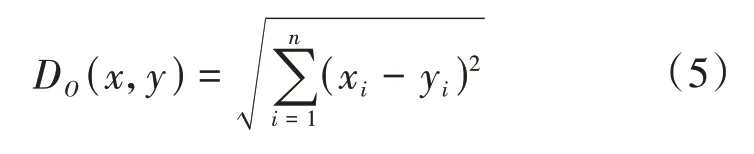
其中,x,y分别为图像的n维特征向量。⑥取前k项添加至S集合中,S=;⑦返回S集合。
2 结果
本文研究的肺结节CT 图像检索提出了实验环境和实验评价指标和据此获得的结果。
2.1 实验环境
本文实验使用的操作系统为Windows 1 064 bit,处理器为Intel(R)Core(TM)i5-10400F CPU@2.90~4.3 GHz,显卡为GeForce RTX2060,内存为16 GB,深度学习框架为pytorch 1.2,参数配置见表1。
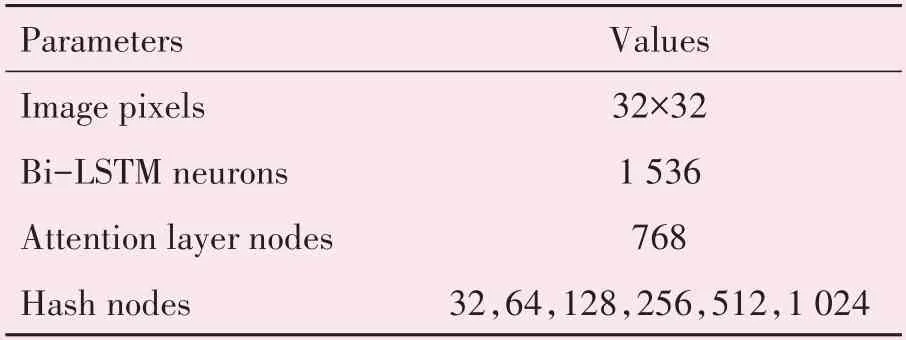
表1 参数配置Table 1 Parameter configuration
2.2 评价指标
为了反映图像哈希算法的效果与性能,本实验选择的评价指标有准确率(precision,P)、召回率(recall,R)、调和平均数F1、P@10、MAP。

P@10 是对检索相似图像返回前10 项结果计算精确度。
AP 指单个类别下每个图像检索的相似图像的准确率的平均值。而MAP 则是所有类别的AP 的平均值。
2.3 实验结果
针对肺结节CT 图像数据集,借助肺结节标注信息对数据集进行分类,其目的是验证本文深度学习模型所提取的图像特征能够更充分的反映标注信息。并且与传统的支持向量机(support vector machine,SVM)、极限学习机(extreme learning machine,ELM),以及深度网络对比,其中“+”表示网络构造为串联,“-”表示网络构造为并行,验证本文算法所提取图像特征的有效性(见表2)。
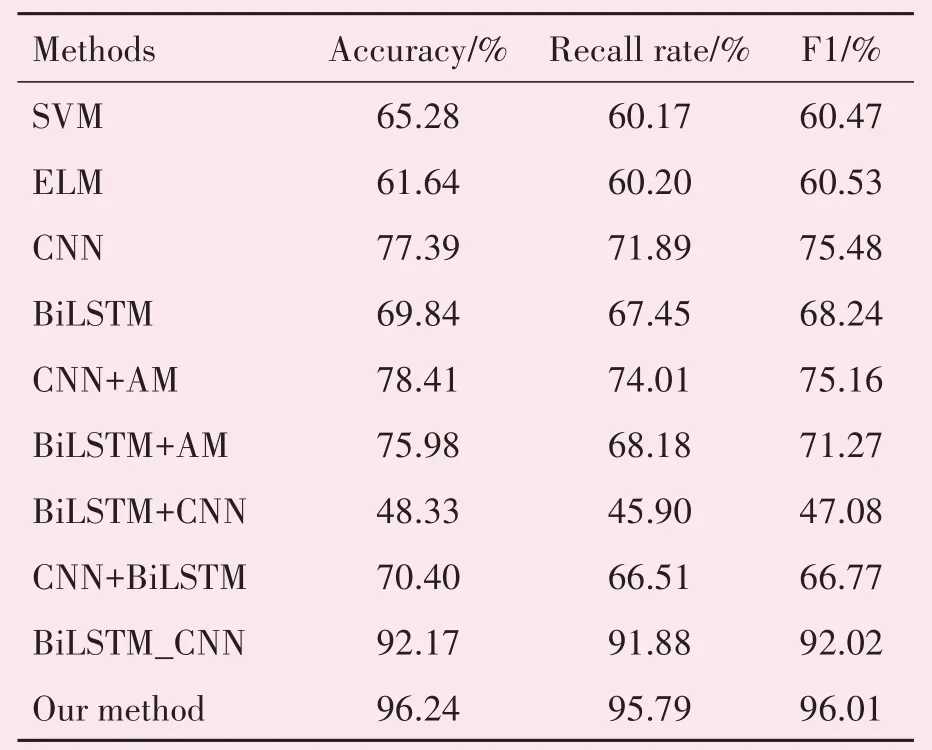
表2 分类准确率对比Table 2 Comparison of classification accuracy
由于全连接层的图像特征是高维的,直接进行相似度计算成本较高,需要将高维特征投射到低维空间,因此本文在全连接层后嵌入哈希层,并通过设置不同位数的哈希节点来获取低维特征,其目的是确定具有最优区分标注信息能力的哈希编码位数。在LIDC-IDRI数据集上进行实验,结果见表3。

表3 哈希节点与分类准确率变化表Table 3 Relationship between hash nodes and classification accuracy
为了验证本文所设计的哈希图像检索方法的有效性,与其它哈希算法进行对比,分别选取P@10以及MAP 作为评价指标。结果分别如图3-图4所示。
3 讨论
国内外相关学者开展基于内容的医学图像检索算法研究并构建了相应的检索系统,其基本原理是通过提取图像的颜色、纹理以及空间位置等浅层特征以构造特征向量;利用传统的哈希算法将特征向量压缩为低维紧凑的哈希特征;通过汉明距离衡量图像的相似性。传统代表算法主要有谱哈希(spectral Hashing,SH)[5]、局部感知哈希(locality sensitive Hashing,LSH)[6]、二进制重构嵌入(binary reconstructive embedding,BRE)[10]、迭代量化(iterative quantization,ITQ)[11]、最小化损失哈希(minimal loss Hashing,MLH)[12]、核监督哈希(kernelbased supervised Hashing,KSH)[13]等。上述算法主要依赖于图像的浅层语义信息,并不能完整地表达CT 图像信息且得到的哈希特征并不是最优特征,从而使得图像检索算法检索精度低下。深度哈希算法相较于传统的哈希算法具有优势,其所学习到的哈希编码具有更有效的特征表示并且不需要人工设计抽取特征,卷积神经网络哈希(convolutional neural network Hashing,CNNH)首次采用卷积神经网络将特征学习与哈希编码结合起来进行深度图像检索[14]。不过,由于其图像特征表示无法为哈希编码学习提供反馈信息,该算法不是一种端到端的学习方法。二进制哈希码深度学习(deep learning of binary Hash codes,DLBHC)采用一种监督学习框架根据数据的标签信息可以同时学习图像特征表示和二进制编码,并提出由粗到细的检索策略,在满足检索精度的同时加快了检索速度[15]。深度神经网络哈希(deep neural network Hashing,DNNH)在网络中通过设计三元组监督信息来捕获图像的相似性的深度哈希方法,使用图像的相似对与不相似对所构成的三元组对CNN 进行训练,是一种端到端的学习方法,但在前期需要进行大量的图像预处理工作且人工标记相似对与不相似对具有较大的主观性[16]。
肺部疾病影像不仅表现复杂,近几年数量也增长迅速,这导致影像科医生任务繁重。而当前的智能诊断算法可有多种应用模式,如能够实现肺部病灶检出、分割及其性质判断等,这不仅有效提升医生诊断的效率,更有望推动分级诊疗、优化医疗资源配置,而且基于人工智能的肺部影像诊断技术已经从单一特定的疾病诊断逐渐发展到多疾病联合诊断[17]。本文针对肺结节CT 图像检索的深度哈希算法进行研究,探讨其在医学图像诊断中的应用。
分析表2 的结果可以看出本文设计的深度模型在LIDC-IDRI 数据集上的识别准确率都高于常用的分类算法,这表明本文方法所提取的特征具有更强的图像表征能力,可以验证本文设计方法检索的有效性。从表2 还可以看出,网络结构好坏也是提取图像特征的关键,CNN 和BiLSTM 并行的模型优于串联的模型,这是因为CNN 和BiLSTM 串联,前者学习到的信息可能会覆盖后者学习到的信息从而导致信息损失,而并行网络结构可以避免此类情况的发生。此外,本文模型相较于BiLSTM_CNN并行网络模型准确率又有明显提升,究其原因是引入注意力机制能够为学习到的特征分配不同的权重将关键信息强调出来,更进一步提升模型效果。分析表3 可以得知,当哈希位数增加时,本文模型在LIDC-IDRI 数据集上的分类准确率也会随之增加,哈希位数为256 位时,准确率最高。但是,当哈希码位数继续增加时,分类准确率却有下降的趋势,这是因为哈希位数较少时学习到的哈希特征不能充分表达类别信息;随着哈希位数的增加,哈希特征数目也随之增加,学习到的图像内容与图像语义信息也会逐渐增强;但是哈希位数过长,则可能出现过拟合现象。图3 展示了检索结果返回前10项的检索精度对比,可以看出本文算法的检索精度为89.79%,优于其它的哈希算法。图4展示了不同哈希算法在LIDC-IDRI 数据集上的平均检索精度随着返回图像数目的变化图,可以看出本文算法的平均检索精度要优于其它的哈希算法,其平均检索精度高达91.00%,图3~图4 均验证了本文算法的有效性。
本文提出的一种新的、基于深度哈希网络的肺结节CT 医学图像检索模型,该模型融合了肺结节图像区域局部特征和区域间上下文相关信息,增强了肺结节图像特征表示。另外,利用本文设计的一种分级检索策略缩小了相似性检索的范围,对整个数据集通过分层检索得到相似图像。实验结果表明本文算法具有更高的检索精度,并且与其他模型相比,能充分提取图像语义特征,在准确率、召回率、F1、P@10、MAP值上均有明显提升,更加适用于大数据检索,表明本文方法可能为研发肺癌影像智能诊断系统提供了一种思路,在临床应用中具有一定的实用价值。
猜你喜欢
好日子(2021年8期)2021-11-04
祝您健康(2021年9期)2021-09-05
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2021年1期)2021-01-13
电脑爱好者(2020年20期)2020-10-22
技术与创新管理(2020年5期)2020-10-09
幸福家庭(2020年10期)2020-08-25
商情(2020年24期)2020-06-30
师道(2019年11期)2019-12-02
科学与财富(2019年27期)2019-10-25
