
差分隐私生成式对抗网络的框架与方法综述
2022-08-09 07:26牛翠翠潘正芝
贵州师范大学学报(自然科学版) 2022年4期
牛翠翠,潘正芝,刘 海
(1.贵州轻工职业技术学院 文化与旅游系,贵州 贵阳 550025;2.贵州大学 计算机科学与技术学院,贵州 贵阳 550025)
0 引言
数据共享可以打破数据壁垒,使得数据便于流通、交换和融合,有利于科学研究、数据建模和应用数据模型,以及挖掘数据的潜在价值。不过,通常个体数据包含身份、位置和社会关系等重要的隐私信息,特别是人类基因组数据包含遗传、表型、易感疾病和血缘关系等敏感信息[1],如果直接开放共享个体数据必然会存在隐私泄露的风险,例如,2019年9月4日Facebook证实超4.19亿条与Facebook账户关联的电话号码数据库被曝光,部分记录还包含用户姓名、性别和地理位置等敏感信息。因此,实现开放共享数据的隐私保护是迫切需要解决的问题。
通过产生逼近真实样本的生成数据,共享生成数据代替真实数据共享可以避免隐私泄露的风险,并且可以扩充小规模数据[2]。生成数据共享有利于训练更好的模型、发展新的技术和推进第三方聚集生成数据,以及提供生成数据便于科学发现的可重复性研究[3]。目前,生成数据的主要方法之一是生成式对抗网络(Generative adversarial networks,GAN)[4]。GAN由2个神经网络组成,分别是生成器G(Generator)和判别器D(Discriminator),生成器产生假样本,而判别器区分样本来自真实样本集还是假样本集,通过反复对抗迭代训练生成器和判别器,最终使得判别器无法区分生成数据与真实数据。因此,GAN可用于生成时间序列、连续和离散数据[5]。但是,在GAN的对抗博弈过程中,需要使用真实样本反复训练判别器,进而迭代训练生成器,还是会存在敏感信息泄露的风险[6],于是如何实现GAN训练过程中的隐私保护是关键的挑战。
具有严格数学定义的可证明差分隐私已成为流行的数据隐私保护方法[7]。因此,目前的工作主要使用差分隐私实现GAN迭代训练过程中的隐私保护,并且取得了具有突破性的研究成果。文献[8]综述了8种差分隐私GAN的方法,同时总结了这些方法的隐私和效用评价指标;文献[9]综述了GAN面临的隐私攻击,并总结了目前差分隐私GAN的研究成果。本综述不同于已有的综述工作,详尽和系统地从以下三方面综述现有的差分隐私GAN的框架与方法。
1)概述和分析用于重复使用差分隐私过程中累积隐私预算估计的组合定理,以及介绍GAN及其常见变式。
2)总结和分析GAN面临的隐私威胁模型,主要包括成员推理攻击和模型提取攻击,并对其攻击数学模型和评价指标进行比较分析。
3)归纳和分析差分隐私GAN的框架,并对比分析随机扰动方法和扰动机制,以及对比分析差分隐私GAN的隐私和效用评价指标。
4)概括和分析差分隐私联邦GAN的框架,并比较分析随机扰动方法、扰动机制和训练方法,以及比较分析差分隐私联邦GAN的隐私和效用评价指标。
最后,通过分析已有差分隐私GAN的框架与方法、差分隐私联邦GAN的框架与方法存在的问题,对未来的研究进行展望。
尽管文献[10]已对目前差分隐私GAN生成数据和差分隐私联邦GAN生成数据的工作进行了综述研究,不过该工作的综述较粗略,不够系统,也不够全面细致。因此,本综述区别于文献[10],更加系统地和全面地综述了差分隐私GAN的框架与方法。
1 差分隐私组合定理
统计推断攻击易导致隐私泄露,例如,攻击者通过查询统计所有患者的疾病状态之和,以及查询统计除了某个患者以外其他患者的疾病状态之和,再将这两个疾病状态统计值作比较便可获得该患者是否患有疾病的敏感信息。针对这样的差分统计推断攻击,Dwork等[7]提出差分隐私随机扰动查询统计值实现个体的隐私保护。除单个数据记录以外考虑所有背景知识,差分隐私具有严格的数学定义和坚实的理论基础,使差分隐私的性质和机制得到广泛研究和应用[11-12]。
数据库x和x′的元素数量相同,除了至多一条记录外其他都相同,那么数据库x和x′是邻近数据库,其Hamming距离满足h(x,x′)≤1。后续部分,随机机制M的输出空间表示为Range(M),符号R表示实数集合。
定义1(差分隐私)对于所有S⊆Range(M),x,x′∈Xk,且h(x,x′)≤1,使得
p(M(x)∈S)≤eεp(M(x′)∈S)+δ
那么随机机制M是(ε,δ)-差分隐私。如果δ=0,则M是ε-差分隐私。
根据上述形式化定义,独立于任何单个记录是否属于数据库中,差分隐私保证任何查询函数的响应是等可能的。对于邻近数据库x和x′,由(ε,δ)-差分隐私的定义可知,差分隐私机制M至少以概率1-δ满足ε-差分隐私。
对于数值数据的差分隐私保护,可以使用流行的Laplace机制和Gaussian机制实现差分隐私。
Δ1f=maxx,x′∈Xk,h(x,x′)≤1||f(x)-f(x′)||1
定义3(Laplace机制)对于数值查询函数f:Xk→Rk,Laplace机制是
LM(x,f(·),ε)=f(x)+(Y1,Y2,…,Yk)
其中Yi~Lap(Δ1f/ε)(i∈{1,2,…,k})是独立同分布随机变量。
Δ2f=maxx,x′∈Xk,h(x,x′)≤1||f(x)-f(x′)||2
定义5(Gaussian机制)对于数值查询函数f:Xk→Rk,Gaussian机制是
GM(x,f(·),ε)=f(x)+(Y1,Y2,…,Yk)

对于数据库x∈Xk和输出r∈,定义效用函数u:Xk×→R,其敏感度为
Δu=maxr∈maxx,x′∈Xk,h(x,x′)≤1|u(x,r)-u(x′,r)|
定义6(指数机制)指数机制EM(x,u,)选择输出元素r∈的概率正比于eεu(x,r)/(2Δu)。
差分隐私具有后处理(Post-processing)、序列组合(Sequential composition)、高级组合(Advanced composition)、并行组合(Parallel composition)[13]和隐私-效用单调性[14]的性质。
定理1(后处理)如果M:Xk→R是(ε,δ)-差分隐私,且f:R→R′是任意随机映射,则f°M:Xk→R′是(ε,δ)-差分隐私。

定理3(并行组合)如果Mi是εi-差分隐私,xi是属于数据库x的任意子集,且xi∩xj=Ø(i≠j),则组合(M1(x1),M2(x2),…,Mk(xk))是max{εi}-差分隐私。
对相同数据库或不同数据库重复使用差分隐私算法时,高级组合定理表明可以根据先前差分隐私机制的输出自适应地选择数据库、差分隐私机制和参数。
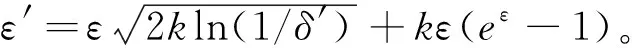

定理5(隐私-效用单调性)在差分隐私中,随着隐私预算ε增加,隐私保护效果递减,而数据效用递增,反之亦然。
因此,定理5的隐私-效用单调性表明差分隐私机制可以实现隐私保护与数据效用之间的权衡。
在重复使用差分隐私时,为了获得比序列组合定理更严格的累积隐私预算损失,Abadi等[15]提出累积隐私预算损失的矩估计(Moments accountant,MA)方法,以此更精确地估计隐私预算损失。根据差分隐私定义,考虑辅助输入aux和输出s∈S,可形式化描述隐私预算损失随机变量为
对于差分隐私机制M,则可定义隐私预算损失随机变量的λ阶矩为
φM(λ;aux,x,x′)=logEs~M(aux,x)[eλc(s;M,aux,x,x′)]
考虑所有可能的aux和所有邻近数据库x和x′,为了表明M保证差分隐私,定义
φM(λ)=maxaux,x,x′φM(λ;aux,x,x′)
因此,φM(λ)具有组合和尾界(Tail bound)的性质。
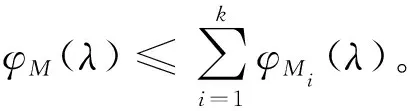
定理7(φM(λ)尾界)如果M满足(ε,δ)-差分隐私,那么δ=minλeφM(λ)-λε。
根据定理6和定理7,基于矩估计的累积隐私预算损失计算方法推广了定理2的序列组合方法,可以为重复使用差分隐私机制时提供更严格的隐私参数(ε,δ)估计。
相较于差分隐私的序列组合定理和矩估计组合定理,Mironov[16]提出Rényi 差分隐私(Rényi differential privacy,RDP),并给出隐私预算损失的RDP组合定理,以此为重复使用差分隐私机制的累积隐私预算损失计算提供了方便。
定义7(RDP)对于x,x′∈Xk,任意阶数α,且h(x,x′)≤1,使得
Dα(M(x)‖M(x′))≤ε
那么关于输入空间Xk的随机机制M是(α,ε)-差分隐私,其中
是Rényi散度(Rényi divergence)。
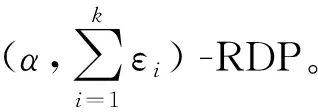
此外,Mironov已表明(α,ε)-RDP机制满足(ε+log(1/δ)/(α-1),δ)-差分隐私。例如,Gaussian机制满足(α,α(Δ2f)2/(2σ2))-RDP。因此,结合定理8可知,隐私预算损失的RDP组合相比于序列组合更严格。
2 GAN及其常见变式
GAN的基本网络关系如图1所示,GAN由生成器G和判别器D组成,G和D都是全连接神经网络,判别器D用于判断输入数据是真实数据还是生成数据,而生成器G用于产生逼近真实数据的生成数据,使判别器D不能区分输入的数据是真实数据还是生成数据[4]。

图1 GAN的基本网络结构Fig.1 Basic network structure of GAN
使用Gaussian分布随机初始化生成器和判别器的权重和偏置值参数,输入服从Gaussian分布或均匀分布pz(z)的随机噪声z到生成器G并产生数据G(z),将生成数据G(z)与真实数据x随机混合后并输入到判别器D,反复训练更新判别器D的参数得到判别概率D(x);共享判别器D的参数,再次随机输入噪声z到生成器G并产生数据G(z),此时将G(z)当作真实数据输入到判别器D中更新生成器G的参数,而判别器的参数保持不变,依上述过程循环迭代训练并更新生成器G和判别器D的参数,直到判别器不能区分真假数据,也就是区分真假数据的概率为D(x)=1/2,使得GAN的数学模型
minGmaxDV(D,G)
=Ex~pdata(x)[logD(x)]+Ez~pz(z)[log(1-D(G(z)))]
达到极大极小值,其中pdata(x)表示真实数据x概率分布。当达到极大极小值V(D,G)=-log4时,GAN的最终目标就是使生成数据的概率分布pg(x)收敛到真实数据的概率分布pdata(x)。
在GAN中,根据其数学模型,可知判别器D的数学模型为
maxDV(D,G)
=Ex~pdata(x)[logD(x)]+Ez~pz(z)[log(1-D(G(z)))]
而生成器G的数学模型为
minGV(D,G)=Ez~pz(z)[log(1-D(G(z)))]
综上可知,GAN具有坚实的理论基础,可以训练任何一种生成器网络,生成器和判别器的网络结构灵活,而且可以生成高质量的数据。不过,GAN存在训练不稳定、生成数据质量差和多样性不足,以及模型自由不可控等问题。
使用Wassertein距离度量真实数据与生成数据分布之间的距离,Arjovsky等[17]提出WGAN(Wasserstein GAN)解决GAN训练不稳定、生成数据质量差和多样性不足的问题,其数学模型为
minGmaxDV(D,G)
=Ex~pdata(x)[D(x)]-Ez~pz(z)[D(G(z))]
可知判别器D的数学模型为
maxDV(D,G)
=Ex~pdata(x)[D(x)]-Ez~pz(z)[D(G(z))]
其中判别器D满足1-Lipschitz条件‖f‖L≤1,而生成器G的数学模型为
minGV(D,G)=-Ez~pz(z)[D(G(z))]
基于梯度惩罚实现判别器D的1-Lipschitz连续性条件,Gulrajani等[18]提出WGAN-GP(WGAN with gradient penalty)解决WGAN的梯度消失问题,其数学模型为
minGmaxDV(D,G)
=Ex~pdata(x)[D(x)]-Ez~pz(z)[D(G(z))]+λEz~pz(z)[(‖▽D(γx+(1-γ)G(z))‖2-1)2]
其中λ是梯度惩罚系数,γ∈[0,1]是随机数,通过对真实数据x与生成数据G(x)进行随机采样可得γx+(1-γ)G(z),以此可以避免在整个样本空间上采样。因此,判别器D的数学模型为
maxDV(D,G)
=Ex~pdata(x)[D(x)]-Ez~pz(z)[D(G(z))]+λEz~pz(z)[(‖▽D(γx+(1-γ)G(z))‖2-1)2]
而WGAN-GP生成器的数学模型与WGAN生成器的数学模型相同。
通过引入条件变量y,Mirza和Osindero[19]提出可控的CGAN(Conditional generative adversarial networks),其数学模型为
minGmaxDV(D,G)=Ex~pdata(x)[logD(x|y)]+Ez~pz(z)[log(1-D(G(z|y)))]
使用CGAN可以指导性地生成数据,解决GAN面对复杂数据自由不可控的问题。根据CGAN的数学模型,可知其判别器D的数学模型为
maxDV(D,G)=Ex~pdata(x)[logD(x|y)]+Ez~pz(z)[log(1-D(G(z|y)))]
而生成器G的数学模型为
minGV(D,G)=Ez~pz(z)[log(1-D(G(z|y)))]
3 GAN的隐私威胁模型
因使用真实数据训练判别器,易带来隐私泄露的风险[6]。因此,目前的工作主要研究了GAN面临成员推理和模型提取两种隐私攻击,如表1所示,本节主要从攻击对象、攻击类型、攻击特点、攻击效果和评价指标等方面总结和分析GAN所面临的这2种隐私攻击。

表1 GAN的隐私攻击Tab.1 Privacy attacks of GAN

其具体方法是攻击者将xi分类为真实样本或假样本,以此最大化成员推理的效用分数Φ(xi)期望值,其中正确识别成员时Φ(xi)=1,否则Φ(xi)=-1,pi=D(xi∈x),qi=D(xi∈G(z)),p(xi∈x)=|x|/(|x|+|G(z)|)。
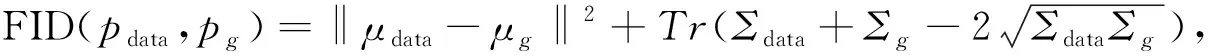
总的来说,GAN目前面临成员推理和模型提取两种主要的隐私攻击,而且使用的隐私攻击数学模型和攻击方法不同也不统一,相应的隐私攻击评价指标不同也不统一,主要包括攻击的准确率、欧氏距离、ROC-AUC(Area under the receiver operating characteristic curve)[26]、TVD(Total variantion distance)和FID等。针对这些隐私攻击,已有的研究工作中主要是基于差分隐私实现GAN的隐私保护。在后续部分,主要针对目前差分隐私GAN的框架与方法、差分隐私联邦GAN的框架与方法进行总结与比较分析。

续表1
4 差分隐私GAN的框架与方法
本节归纳差分隐私GAN的框架,并分析其合理性。同时,总结和对比分析目前的差分隐私GAN方法,以及用于对其隐私和效用分析的评价指标。
4.1 差分隐私GAN的框架与分析
如图2所示,目前主要基于数据扰动、梯度扰动和目标函数扰动方法实现GAN的差分隐私保护。在数据扰动中,使用差分隐私噪声直接随机扰动训练数据,可以避免GAN面临的隐私攻击,不过数据扰动因直接对数据添加噪声,会破坏数据之间的关联性,必然会导致训练数据的效用损失,以此训练GAN获得的网络模型质量低,进而影响生成数据的质量。因此,可以使用差分隐私噪声随机扰动目标函数系数实现GAN的隐私保护,以此避免对数据扰动而导致训练模型质量差的问题,但是因对目标函数的系数进行随机扰动,可能会产生差分隐私GAN的收敛慢、训练不稳定和训练模型质量差等问题。因此,梯度扰动是目前实现差分隐私GAN的主要方法,首先通过对梯度进行裁剪,然后使用精心设计的噪声添加到裁剪梯度实现GAN的差分隐私保护。在梯度扰动中,仅仅使用差分隐私噪声随机扰动判别器的梯度,而不破坏训练样本数据及其关联性,也不会破坏训练的目标函数。通过对判别器进行梯度扰动后,根据迭代训练的累积隐私预算损失估计,判别器满足差分隐私,基于差分隐私的后处理性质,生成器也满足差分隐私,从而保证生成数据的差分隐私。只不过在基于梯度扰动的差分隐私GAN框架中,因对梯度进行了随机扰动,相比于数据扰动和目标函数扰动可能需要迭代更多次才能使差分隐私GAN的目标函数收敛且趋于稳定,而且还需要计算差分隐私GAN框架迭代训练的累积隐私预算损失估计,以此保证在累积隐私预算损失估计完全消耗后,差分隐私GAN框架的训练终止。
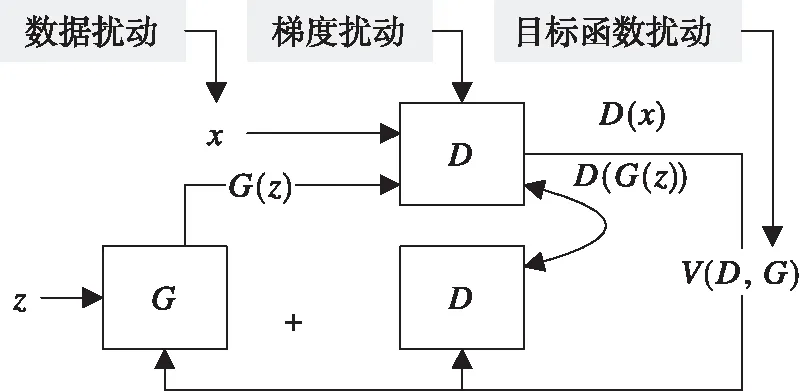
图2 差分隐私GAN框架Fig.2 Differentially private GAN framework
4.2 差分隐私GAN的方法与评价指标
针对使用敏感数据训练神经网络存在隐私泄露风险的问题,现有的工作主要是基于差分隐私实现神经网络模型的隐私保护。接下来,如表2所示,主要从梯度扰动、数据扰动、目标函数扰动和标签扰动等策略综述差分隐私GAN的方法。
1)基于梯度扰动的差分隐私GAN方法
其中,度量方法IS(Inception score)也是评价生成数据质量的一种方法,具体形式化为IS=eEx~pg[KL(p(y|x)||p(y))],其中p(y|x)是生成数据x属于类别y的条件概率分布,KL散度(Kullback-Leibler divergence)KL(p(y|x)||p(y))度量概率分布p(y|x)与p(y)之间的距离。因此,IS越大,生成数据质量越高。陈竑毓[31]通过设计自适应裁剪梯度策略,并结合梯度扰动策略提出差分隐私多生成器WGAN,以此实现差分隐私保护的同时生成较好的图像数据。基于WGAN生成数据与真实数据相似的最优结果,对比生成数据与原始数据的差异进行反馈调参,Tao等[32]提出差分隐私WGAN有效保护敏感数据,而且保证较好的数据效用。方晨等[33]基于GAN提出差分隐私数据发布方法,通过设计动态隐私预算分配、自适应裁剪阈值选取和权重参数聚类等优化策略来灵活调整隐私预算分配并减小总体噪声规模,以此生成符合真实数据统计特性且不泄露隐私的高质量数据,而在动态隐私预算分配过程中,使用衰减函数逐渐减小每次迭代训练的差分隐私噪声尺度大小,通过指数机制选择衰减函数的超参数,最终选取生成数据质量最佳的超参数。Ha和Dang[34]提出本地化差分隐私GAN框架,用于噪声数据生成。Chen等[35]提出梯度净化(Gradient-sanitized)的WGAN,允许在严格的隐私保证下发布经过脱敏的数据,并能更准确地扭曲梯度信息,从而训练更深层次的模型并生成更多的信息样本。于雅娜等[36]提出差分隐私WGAN-GP方法,该方法可以有效实现敏感信息的隐私保护,且可以生成具有较好质量的数据。Yang等[37]提出差分隐私WGAN-GP来训练具有隐私保护功能的生成模型,为敏感数据提供强大的隐私保护,并生成高质量的数据。Fan和Pokkunuru[38]提出差分隐私解决方案,用于生成高质量的网络流数据,并通过训练具有差分隐私的GAN框架来保护敏感训练数据的隐私。Zhang等[39]提出基于GAN的图数据隐私发布模型,该模型可以使度分布保持较高的可用性,并满足(ε,δ)-差分隐私。
2)基于数据扰动的差分隐私GAN方法
当使用GAN生成数据时,数据扰动方法通过添加差分隐私噪声到训练数据实现GAN隐私保护。Li等[40]提出图数据隐私保护方法,使用GAN对图数据执行匿名化操作,使得在不指定特定特征的情况下充分了解图的特征成为可能,并通过在图生成过程中向概率邻接矩阵添加差分隐私噪声来保护匿名图的隐私。Neunhoeffer等[41]提出差分隐私Post-GAN增强,结合GAN训练期间获得的生成器序列产生的样本,以创建高质量的数据集,并使用差分隐私乘法权重方法对生成的样本重新加权[42]。Indhumathi和Devi[43]提出医疗保健Cramér GAN,该算法只在已识别的准标识符中添加差分隐私噪声,将最终结果与敏感属性相结合,其中匿名医疗数据被用作训练Cramér GAN的真实数据,Cramér距离用于提高模型的效率,而由医疗保健机构生成的数据可以实现隐私保护,并抵抗各种攻击。Imtiaz等[44]提出结合差分隐私机制的GAN,通过直接向聚合数据记录添加噪声来生成逼真的隐私医疗数据集,可以生成高质量的差分隐私数据集,并保留原始数据集的统计特征。
3)基于目标函数扰动的差分隐私GAN方法
在目标函数扰动中,已有的工作将Laplace噪声注入到系数中,以构造GAN训练中的差分隐私损失函数。Zhang等[45]提出新的隐私保护GAN,基于函数机制,通过向潜在空间注入Laplace噪声来扰动目标函数的系数,以确保训练数据的差分隐私,并且可以生成高质量的和逼真的数据样本,也不会泄露训练数据集中的敏感信息。
4)基于标签扰动的差分隐私GAN方法
Papernot等[46]利用差分隐私噪声的标签扰动构建PATE(Private aggregation of teacher ensembles)模型,为训练数据提供了强大的隐私保障,该机制以黑盒方式将不相交数据集训练的多个模型相结合,由于这些模型直接依赖于敏感数据,所以它们不会被发布,而是用作“Student”模型的“Teacher”。因为Laplace噪声仅仅添加到“Teacher”的输出,因此“Student”可以学习预测由Laplace噪声扰动所有“Teacher”中选择的输出,并且不能直接访问单个“Teacher”、基础数据或参数。在GAN和PATE框架的基础上,Jordon等[47]用PATE机制代替GAN的判别器。因此,判别器满足差分隐私。不过,该机制的缺点是需要使用公共数据来学习训练模型。
此外,目前的研究主要集中在以统计方式发布隐私保护的数据,而未考虑上下文的动态性和相关性。为此,Ho等[48]在GAN中引入差分隐私标识符(Differential privacy identifier)作为第三方,生成器同时与判别器和标识符博弈,该标识符基于差分隐私和用户级隐私(User-level privacy)建立隐私约束,根据差分隐私预算的序列组合为连续数据发布提供隐私保障。并使用轨迹数据对隐私保护与数据效用进行实验分析,其隐私分析的评价指标是可视化生成轨迹与真实轨迹之间的偏差距离,而效用分析的评价指标是均方根误差(Root mean square error,RMSE)和Pearson相关性。
综上,并结合表2中的差分隐私扰动策略及评价指标,针对不同类型的数据,基于各种扰动策略的差分隐私GAN方法的总体思想是一致的。对于差分隐私GAN方法,目前主要使用隐私预算、距离或误差度量和成员推理攻击的准确率等评价指标对隐私保护进行分析,对数据效用分析主要使用机器学习任务的分类准确率,以及距离或误差、关联矩阵、Kernel密度估计、生成分数、ROC-AUC、PRC-AUC(Area under the precision recall curve)[26]、IS、FID、JS散度、直方图分布和图效用度量等作为评价指标。

表2 差分隐私GAN的扰动方法及评价指标Tab.2 Perturbation approaches and evaluation metrics of differentially private GAN
5 差分隐私联邦GAN的框架与方法
本节首先概述联邦学习(Federated learning,FL)的框架及其训练方法,然后概括差分隐私联邦GAN的框架,并分析其合理性。同时,总结和比较分析目前的差分隐私联邦GAN方法,以及用于对其隐私和效用分析的评价指标。
5.1 联邦学习框架及其基本训练方法
联邦学习适合于训练大规模分布、不平衡和非独立同分布(Non-independently and identically distributed,Non-IID)的多源本地数据,并向服务器共享模型更新(Model update),以此使个体对自己的数据具有自主本地隐私控制权,并通过模型聚合和平均的训练算法(FedAvg)产生更好的全局模型[51]。每个本地用户的损失函数为
其中ni是本地用户i的样本量,f(xj)是期望输出,oj是实际输出,则联邦学习的损失函数为
其中n=n1+n2+…+nK是总样本量。

5.2 差分隐私联邦GAN的框架与分析
在分布式环境中,聚集大规模数据便于更好地训练数据模型和应用分析,然而本地用户希望对自己的数据具有本地的隐私控制权,不愿将真实数据共享给服务器。因此,结合联邦学习框架,目前主要基于差分隐私GAN实现分布式生成数据的聚集,以此避免共享真实数据导致隐私泄露的风险。总结现有的差分隐私联邦GAN框架,通过使用梯度扰动策略,目前主要有两种模型训练方式基于差分隐私实现联邦GAN的隐私保护,包括基于FedAvg算法的差分隐私联邦GAN框架和基于串行训练(Serialized training)的差分隐私联邦GAN框架。
基于联邦学习模型聚合与平均的FedAvg算法建立差分隐私联邦GAN框架,如图3所示,每个本地用户使用梯度扰动策略添加差分隐私噪声到判别器的梯度,以此训练生成器并更新其本地参数,根据迭代训练的累积隐私预算损失估计使得判别器实现差分隐私保护,基于差分隐私的后处理性质可以使生成器也满足差分隐私。服务器聚集本地差分隐私生成器模型,基于差分隐私的并行组合性质使聚合的生成器模型满足差分隐私,再由差分隐私的后处理性质,对聚合的生成器模型进行平均获得的全局模型也满足差分隐私。重复此过程,每个用户再根据差分隐私生成器全局模型更新本地生成器模型,最终消耗完隐私预算损失估计,终止模型训练。不过,在使用FedAvg算法的差分隐私联邦GAN框架中,因为每个本地用户都要上传本地模型和下载全局模型来进行训练和模型更新,势必带来很大的通信开销。因此,需要新型的联邦学习训练方法构建差分隐私联邦GAN框架,以此有效地实现联邦GAN的隐私保护。
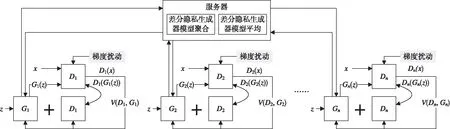
图3 使用FedAvg训练方法的差分隐私联邦GAN框架Fig.3 Differentially private federated GAN framework using FedAvg training approach
如图4所示,基于新的串行训练范式构建差分隐私联邦GAN框架。根据当前GAN的全局模型,第一个本地用户使用梯度扰动策略随机添加噪声到判别器的模型,然后迭代训练更新其生成器的模型,并将更新后GAN的本地模型发送到第二个本地用户进行GAN的本地模型更新,直到第n个本地用户完成GAN的本地模型更新,并上传到服务器,使得服务器获得最终更新后GAN的全局模型。因为每个本地用户通过差分隐私噪声随机扰动判别器的模型,依据迭代训练的累积隐私预算损失估计使得判别器满足差分隐私,根据差分隐私的后处理性质保证生成器模型也满足差分隐私,进一步使用差分隐私的后处理性质使得最终获取的生成器和判别器的全局模型也满足差分隐私,以此使用最终全局模型可以有效地实现GAN的差分隐私保护。
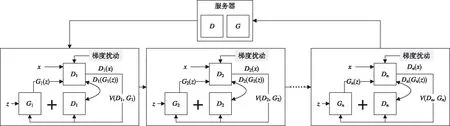
图4 使用串行训练方法的差分隐私联邦GAN框架Fig.4 Differentially private federated GAN framework using serialized training approach
5.3 差分隐私联邦GAN的方法与评价指标
为了实现分布式协同数据分析,收集大规模数据是一项重要任务。然而,由于敏感数据的隐私性,很难收集充足的样本。因此,可以使用GAN生成数据并可共享用于数据分析。然而,在分布式环境中,训练GAN面临着数据隐私泄露的新挑战。因此,现有的工作通过在分布式环境中结合GAN和联邦学习,为差分隐私生成数据收集提供了解决方法。如表3所示,本节主要从扰动策略、扰动机制和训练方法等方面总结和比较分析差分隐私联邦GAN的方法。
1)基于FedAvg的差分隐私联邦GAN方法
梯度扰动也可用于在联邦学习的GAN训练中确保训练数据的隐私保护。Augenstein等[52]提出差分隐私的联邦生成模型代表隐私数据的示例。Chen等[35]将梯度净化的WGAN扩展到联邦环境中训练具有差分隐私的GAN,并且表明该方法与文献[52]的方法之间的细微差异。不同医院通过数据共享联合训练模型以诊断COVID-19肺炎,但存在隐私泄露风险,Zhang等[53]为此提出用于检测COVID-19肺炎的差分隐私联邦GAN,可以有效诊断COVID-19,而不会影响IID和Non-IID环境下的隐私。数据的分布式存储以及由于隐私原因无法共享数据的事实,为联邦学习环境带来了新的挑战。因此,Nguyen等[54]提出新的联邦学习方案,以生成逼真的COVID-19图像,以便于在边云计算中使用GAN增强COVID-19检测,该方案在每个医院机构集成了差分隐私解决方案,以增强联邦COVID-19数据分析中的隐私。
2)基于串行训练的差分隐私联邦GAN方法
Xin等[55]通过在判别器的梯度更新过程中加入高斯噪声,策略性地结合Lipschitz条件和差分隐私敏感度,提出了基于联邦学习的差分隐私GAN,并使用串行训练范式,显著降低了通信成本。考虑现实中分布式数据往往是Non-IID的,这给建模带来了挑战,Xin等[55]进一步提出了通用隐私FL-GAN来解决这个问题,可以使用差分隐私提供严格的隐私保证,即使这些数据是Non-IID,也可以生成令人满意的数据。
此外,考虑到差分平均案例隐私(Differential average-case privacy)[56]增强了联邦学习的隐私保护,Triastcyn等[57]在联邦学习环境中使用GAN提出了隐私保护数据发布框架,通过FedAvg算法对生成器进行训练,以生成隐私人工数据样本,并通过实验评估信息泄露的风险,结果表明可以生成高质量的标签数据,用以成功地训练和验证机器学习模型实现高的准确率,而且通过估计期望的隐私预算损失,表明可以显著降低此类模型对模型逆向攻击的脆弱性。
对于差分隐私联邦GAN方法,主要通过裁剪梯度,并使用差分隐私噪声随机扰动裁剪梯度实现联邦GAN的隐私保护。在差分隐私GAN的联邦学习模型训练中,目前使用的是模型聚合与平均训练方法,以及串行训练方法,相较而言串行训练方法具有更低的通信开销。此外,根据表3可知,差分隐私联邦GAN方法的隐私评价指标主要是隐私预算和成员推理攻击的准确率,而对效用分析主要使用机器学习任务的分类准确率,以及误差、IS和FID等作为评价指标。
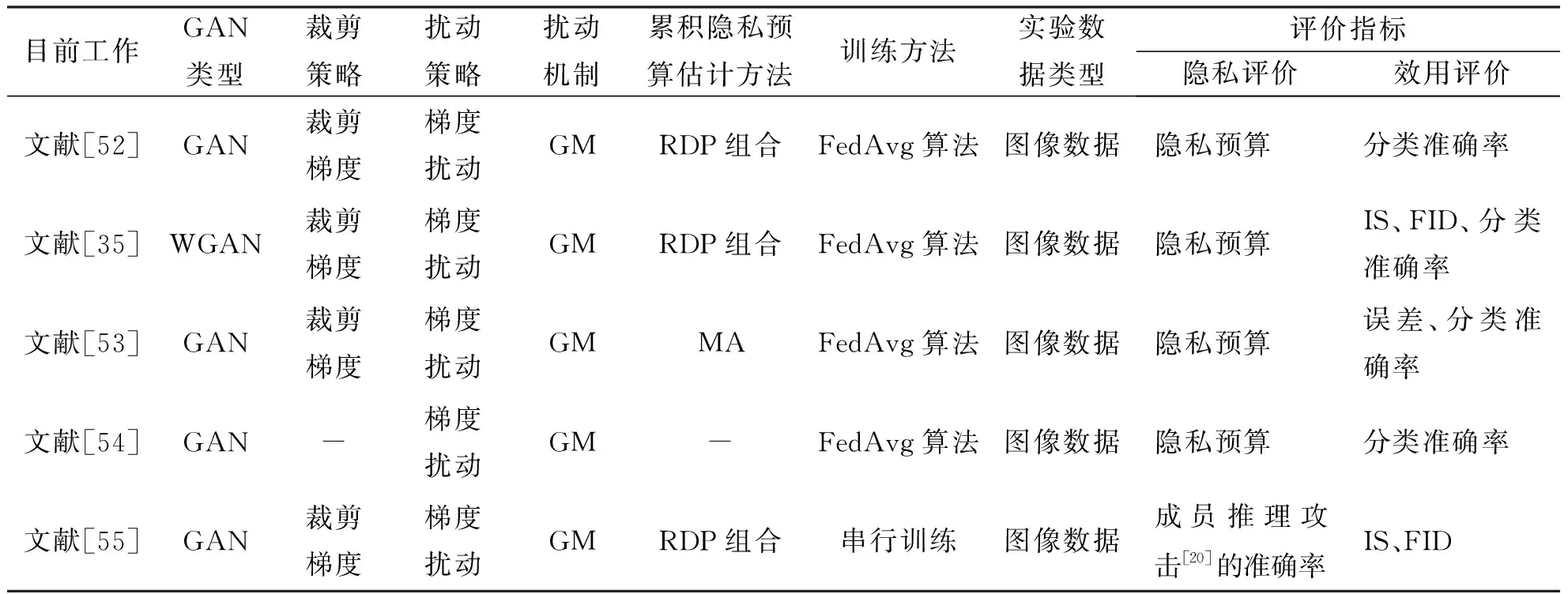
表3 差分隐私联邦GAN的扰动方法及评价指标Tab.3 Perturbation approaches and evaluation metrics of differentially private federated GAN
6 存在问题及未来展望
根据前面GAN的隐私威胁模型、差分隐私GAN的框架与方法,以及差分隐私联邦GAN的框架与方法的综述,本节分析目前工作中存在的问题,并对未来的研究进行展望。
1)GAN的新型隐私攻击及其评价指标
在目前的工作中,主要研究了成员推理攻击和模型提取攻击。但是,在面对更复杂的实际数据使用场景时,需要分析和提出GAN与联邦GAN的新型隐私攻击方法。进一步,因为目前研究中并未对GAN与联邦GAN的隐私攻击评价提供统一的指标,所以需要研究GAN面临各种新型隐私攻击时的统一评价指标,用以判定各种隐私威胁模型的优势,以便于为保护GAN和联邦GAN面临的新型隐私威胁提供方法设计指导。
2)新型差分隐私GAN及其隐私与效用评价指标
基于GAN的变式,扩展差分隐私GAN和差分隐私联邦GAN框架,并根据不同的数据类型,使用相应的Laplace机制、Gaussian机制和随机响应机制,实现不同数据类型和应用场景下的差分隐私数据生成。考虑到目前工作中并未统一给出差分隐私GAN和差分隐私联邦GAN的隐私与效用评价指标,可以从多方面给出其统一的评价指标,例如从机器学习任务的准确性、异常检测的性能对生成数据的效用进行评价。
3)差分隐私GAN更严格的累积隐私预算损失估计方法
在使用梯度扰动策略的差分隐私GAN和差分隐私联邦GAN中,目前判别器迭代训练中主要通过累积隐私预算损失矩估计或RDP组合方法获得更严格的差分隐私保证。不过,Chaudhuri等[58]提出容量受限差分隐私(Capacity bounded differential privacy,CBDP)可以获得相较于RDP组合更严格的累积隐私预算损失成本。因此,需要研究不同的裁剪策略,通过使用CBDP的组合定理严格估计累积隐私预算损失成本,以此使得差分隐私GAN框架的隐私-效用权衡更佳。
4)差分隐私GAN的超参数自适应调节和神经网络模型优化
在差分隐私GAN和差分隐私联邦GAN框架中,不合适的学习率和判别器训练代数等超参数会导致生成同一样本的模型崩塌(Model collapse)和不收敛等问题,微调超参数,如学习率和判别器代数,以此避免模型崩塌和不收敛等问题,因此需要研究和探索有效的超参数自适应调节的方法。此外,对于复杂的数据,通过使用深层次和更复杂的网络模型,使用LSTM解决模型梯度消失和不收敛的问题,以及使用模型的迁移学习方法,以此准确训练模型,提高生成数据的质量,保持数据的高相关性。
5)Non-IID数据的差分隐私联邦GAN及其新型训练方法
在实际的分布式应用环境中,多源数据具有大规模分布、不平衡和非独立同分布的特点,通过联邦学习的FedAvg或串行模型训练方法,直接使用目前的差分隐私联邦GAN框架,会使得生成数据的质量不佳。因此,需要提供新型的联邦学习训练方法,例如基于选择性随机梯度下降的分布式训练技术[59],以此解决传统联邦学习训练方法的通信开销瓶颈问题,并构建适合于Non-IID数据的有效差分隐私联邦GAN框架。
7 结论
本工作首先概述和分析用于累积隐私预算估计的差分隐私组合定理,以及GAN及其常见变式。其次,总结和比较分析了GAN面临的隐私威胁模型及其评价指标。然后,归纳和对比分析差分隐私GAN的框架与方法,以及其评价指标。同时,概括和比较分析差分隐私联邦GAN的框架与方法,以及其评价指标。最后,分析目前GAN的隐私攻击和差分隐私保护研究工作中存在的问题,并讨论未来的研究展望。本工作为对GAN的隐私攻击及其评价,以及GAN的差分隐私保护及其评价的研究提供参考,进而激励对GAN的隐私攻击及其评价到差分隐私保护及其评价进行系统性的研究。
猜你喜欢
数学杂志(2022年5期)2022-12-02
数学物理学报(2022年4期)2022-08-22
数学物理学报(2021年4期)2021-08-30
北京航空航天大学学报(2021年7期)2021-08-13
新世纪智能(数学备考)(2021年5期)2021-07-28
家庭影院技术(2020年10期)2020-12-14
数学物理学报(2019年4期)2019-10-10
家庭影院技术(2019年7期)2019-08-27
信息安全研究(2015年3期)2015-02-28
太空探索(2014年1期)2014-07-10
