
基于BiLSTM-Attention-CNN的XSS攻击检测方法
2022-08-09 07:26李克资张庆玲张思聪
贵州师范大学学报(自然科学版) 2022年4期
李克资,徐 洋*,张庆玲,张思聪
(1.贵州师范大学 贵州省信息与计算科学重点实验室,贵州 贵阳 550001;2.贵州省公安厅-贵州师范大学大数据及网络安全发展研究中心,贵州 贵阳 550001)
0 引言
XSS攻击是最常见的恶意脚本注入攻击之一,当攻击者将恶意JavaScript负载注入到由用户的浏览器执行的Web页面时,就会发生这种攻击。
在受害者的浏览器上执行的恶意脚本可能导致劫持用户会话、错误信息、篡改Web页面、插入恶意内容、网络钓鱼攻击、控制用户的浏览器和访问业务数据[1]。更严重的是,跨站请求伪造(Cross site request forgery,CSRF)、远程代码执行(Remote code execution,RCE)等漏洞结合在一起,可能导致主机被攻击,威胁到受害者的内网安全。
跨站攻击传统上分为3类:反射型XSS攻击(又称非持久型 XSS 攻击)、存储型 XSS 攻击(又称持久型 XSS攻击)和基于文档对象模型(Document object model,DOM)的XSS攻击。跨站攻击通常很容易实现,但由于编码方案的高度灵活性(如URL编码、base64编码、HTML等)[2]以及不同浏览器之间的差异,采用传统的检测方法很难防止跨站攻击。
传统的检测技术有基于黑盒测试[3]、白盒测试、模糊测试[4]。文献[5]使用基于正常和恶意URL和JavaScript的特征,使用3种机器学习算法(朴素贝叶斯(naive Bayesian)、支持向量机(Support vector machine,SVM)和J48决策树)预测跨站点脚本攻击。类似的,文献[6]首先人工提取XSS攻击载荷特征将其构建为特征向量,然后使用多种机器学习算法对XSS攻击进行检测。但是,这些基于传统机器学习的方法的特点是严重依赖特征提取工作,缺少客观性。并且由于编码方案的高度灵活性,经过编码混淆的XSS攻击载荷可读性差,更不易检测。针对传统机器学习检测方法的不足,近年端到端的深度学习检测方法成为研究热点。文献[7]在漏洞检测中运用了长短期记忆网络(LSTM),通过使用LSTM的序列分析能力提高了对代码上下文依赖的分析。文献[8-9]研究对比了CNN、LSTM、CNN-LSTM在漏洞检测中的应用,其实验结果表明深度学习的方法在漏洞检测领域有较好的表现。文献[10]提出使用CNN进行XSS检测,通过使用多层卷积操作提取数据中的关键特征然后输入到softmax进行分类,实验结果表明提高了准确率并减少了误报率,论证了CNN在XSS检测领域的有效性。文献[11]使用LSTM模型检测XSS,实验结果验证了LSTM在XSS检测的有效性,但是对于恶意混淆的 XSS检测还不够准确,检测效果还有待提高。文献[12]中对BiLSTM在XSS检测领域进行了研究,对比了特征维度和优化器等模型参数的不同对精度和时间的影响,对BiLSTM在XSS检测领域检测做了较为广泛的对比实验,论证了BiLSTM在XSS检测领域的有效性。
Bahdanau等[13]采用编码-解码RNN做端到端的机器翻译,模型可以在预测下一个词的时候,自动地选择原句子相关的部分作为解码的输入,后来被提为Attention机制。注意力机制被看作是实现意识的第一步, 意识为人工智能系统进行逻辑分析和推理决策的关键, 是人工智能系统下一步的前进方向。最初,注意力机制在图像领域[14-15]发展,后来又逐步引入了自然语言处理(NLP)[13,16-17]和语音处理[18]领域。注意力机制是根据在序列中每一个词或特征对任务的作用来计算注意力,注意力越大,表明这个词或者特征应该受到更多的关注,增加对关键信息的选取,减少对噪音信息的注意,可以有效地提升准确率,并减少收敛时间。Yang等[19]提出一种基于注意力机制的 GRU 网络,在文本分类中分别在Word和Sentence级别建立Attention机制,学习Word对Sentence的注意力权重和Sentence对Document的注意力权重,有效提高了检测精度。曾义夫等[20]在情感分类中引入注意力机制,借助循环神经网络的序列学习能力得到语句编码,并构造相应的注意机制从编码中提取给定方面词的情感表达,实验效果表明在分类准确率和泛化能力上均优于相关工作。文献[21]将注意力机制、图网络以及双向LSTM用于漏洞挖掘,提出了一种面向源代码漏洞挖掘的神经网络模型,该模型利用BiLSTM抽取源代码的上下文信息,并利用注意力机制捕获关键特征,在实现漏洞挖掘的同时,有效地避免了漏洞与非漏洞代码类间差异小所导致的准确率降低。Attention模型通过计算概率分布来突出输入的关键信息对模型输出结果的影响,增加对关键信息的选取减少对噪音特征的注意,给重要的特征赋予更高的权重,从而提高特征抽取的准确性。
基于上述研究,本文引入Attention机制,结合BiLSTM和CNN模型用于XSS攻击检测。首先利用 BiLSTM提取XSS数据双向序列特征;然后引入Attention机制,将较大的权重赋予给相关性高的特征,增加对关键信息的选取,减少对噪音特征的注意;最后通过使用CNN模型进一步选取相关性大的特征中有助于XSS检测的最优特征。
1 BiLSTM-Attention-CNN检测方法
本文检测方法整体框架如图1所示,首先通过收集相关的XSS数据构成原始数据集,然后对数据进行数据预处理得到适应神经网络模型的输入(见1.1节),最后构建BiLSTM-Attention-CNN混合模型(见1.2节)进行检测分类。

图1 检测方法的整体框架Fig.1 The overall framework of the detection method
1.1 数据预处理
数据预处理是将XSS攻击载荷转化为模型输入所需要的标准向量格式。对收集到的数据进行解码、分词、向量化等数据预处理,然后输入到BiLSTM-Attention-CNN 检测模型中进行分类训练和测试。本文数据处理主要分为3个方面:数据清洗、分词、向量化。
1.1.1 数据清洗
由于现在安全水平的不断提高,使用明文的攻击载荷往往会被防御系统检测到,所以攻击者会根据不同的浏览器的解析策略对XSS攻击载荷进行编码混淆,以绕过检测,表1为常见的编码方式。

表1 编码方式Tab.1 Coding scheme
为了提高模型的检测效果,本文根据表1的编码方式按照对应的编解码规则编写程序,对原始数据进行数据清理工作。图2显示了混淆代码经过解码还原为原始代码的一个实例。
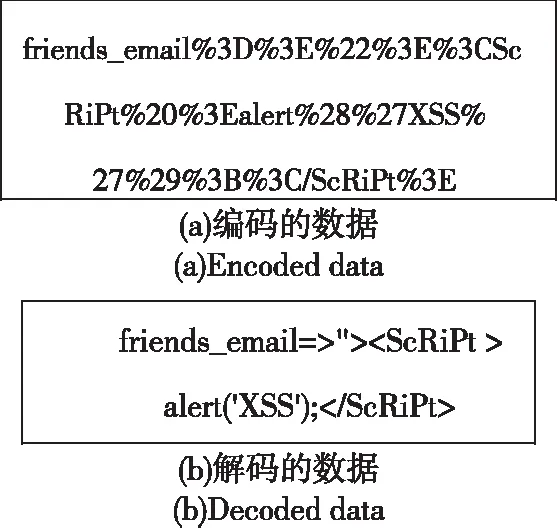
图2 解码实例Fig.2 Decoding example
1.1.2 分词
对数据进行清洗后,为了降低向量化后的数据维度,本文先将代码中的数字转换为0,将链接如“http://www.sida.com”转换为“http://n”。然后利用脚本语言的特点,根据不同功能的分词类别,设计了一系列自定义正则表达式对输入的代码数据进行分词,如表2所示,分词结果如图3所示。

表2 分词Tab.2 Tokenize

图3 分词样例Fig.3 Tokenizing sample
1.1.3 向量化
数据的向量化处理采用 Word2vec方法中的Skip-gram 模型,其模型是通过序列中一个词预测其周围词的向量,Skip-gram 模型由输入层、映射层和输出层组成。通过Word2vec 转换后的词向量不仅把词表示成分布式的词向量,而且还可以捕获词之间存在的相似关系。由于神经网络的输入长度固定,但是样本长度不固定,选择合适的向量维度对模型的表现非常重要。所以根据样本长度,将长度超过向量维度的进行截断,长度不足的用-1填充,使得所有向量长度一致。
1.2 BiLSTM-Attention-CNN模型设计
文献[10]提出使用CNN进行XSS检测,通过使用多层卷积操作提取数据中的关键特征然后输入到Softmax进行分类,实验结果表明提高了准确率并减少了误报率。验证了CNN在XSS处理任务中的可行性和有效性。
文献[11]提出使用LSTM的深度学习检测模型,LSTM模型优点在于能够处理上文对下文的依赖问题,常用于较长序列的自然语言问题,但是该模型只能处理XSS上文对下文的单向序列依赖。文献[12]对BiLSTM在XSS检测领域进行了研究,BiLSTM优势在于可以对XSS数据进行双向序列特征提取。文献[12]对比了特征维度和优化器等不同模型参数对精度和时间的影响,实验证明了BiLSTM在XSS检测领域的可行性和有效性。
但对于XSS攻击检测任务,在XSS攻击载荷中,会有很多对检测XSS相关性低甚至无关的词语。因为有很多正常的请求也会存在某些词(如alert等)。BiLSTM和CNN模型能够较好的提取XSS攻击向量的全局和局部特征。但其无法对特征进行权重分配,即无法关注到对检测结果贡献度大的特征,无法提高特征抽取的准确性。从而无法突出关键特征信息对模型输出结果的影响。为了充分结合BiLSTM和CNN的特征提取特性,以及Attention机制对关键特征的选取优势。本文采用BiLSTM和CNN模型,引入Attention机制,提出BiLSTM-Attention-CNN检测模型(图4)。
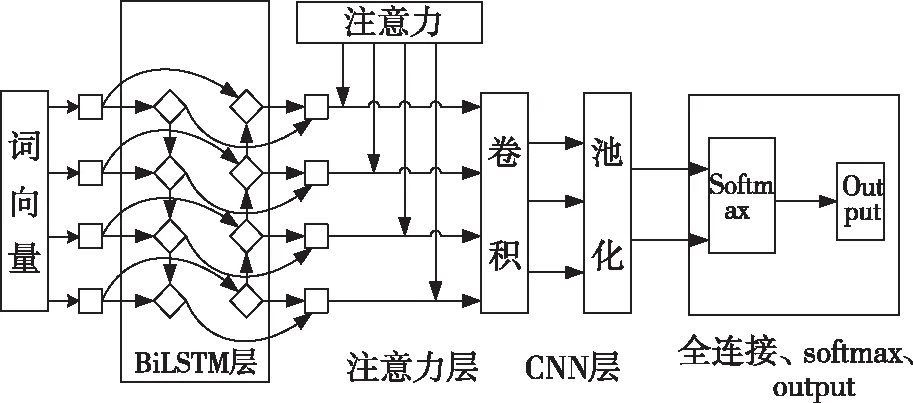
图4 BiLSTM-Attention-CNN模型Fig.4 BiLSTM-Attention-CNN model
输入层:数据预处理训练的词向量二阶张量输入模型。

注意力层:在这一层中,利用隐层的Attention机制来获得注意概率分布值。引入注意力机制根据不同特征对XSS检测的相关性学习不同的权重,选择相关性高的特征,增加对关键信息的选取减少对噪音特征的注意。Attention机制能够充分地利用句子的全局和局部特征,给重要的特征赋予更高的权重,从而提高特征抽取的准确性。常用的Attention机制有两种:点积注意力机制(Dot-Product Attention)和加性注意力机制(Additive Attention)。由文献[22]可知,点积注意力机制的处理效益更高。本文采用的是点积注意力机制。Attention的输出矩阵公式如式(1):
(1)

CNN层:CNN可以通过卷积操作对特征进行局部提取。通过使用CNN可以提取经过BiLSTM-Attention输出的特征向量中的有助于XSS检测的局部特征。CNN层采用TextCNN结构[23],首先通过使用多个不同的卷积核对BiLSTM-Attention输出的基于注意力权重的矩阵V∈Rn×k进行卷积操作:
ci=f(W×Vi:i+h-1+b)
(2)
式(2)中W∈Rh×k,h为卷积窗口大小,k为V中每一维向量长度。其意义为使用h个k维向量去产生1个新的特征ci,最后得到C∈Rn-h+1。
C=[c1,c2,…,cn-h+1]
(3)

(4)
(5)

全连接、SoftMax、Output层:经过CNN层之后将M输入全连接层,然后输入SoftMax计算分类的概率,SoftMax表达式为:
(6)
其中j=1,…,K,把含有任一实数的K维的x向量,压缩到K维的y实向量中,将元素值约束在(0,1),且元素之和为1。
2 实验及分析
2.1 实验数据和环境
恶意样例来源于XSSed数据库以及渗透测试中经过测试的攻击载荷(Payload),经过数据预处理得到42 321条标准数据;正常样例来源于 DMOZ 数据库,经过数据预处理得到76 523条标准数据。实验中,从样本中以7∶3的比例随机选取训练集和测试集。数据集的分布情况如表3所示。

表3 数据集分布Tab.3 Data set distribution
本文实验使用的计算机配置为:处理器 Intel®CoreTM i7-9700K CPU@3.60 GHz,内存32GB,显卡:GTX1080Ti,Ubuntu 18.04操作系统。实验环境为Python 3.8.3、Pytorch 1.6.0。
2.2 实验评估指标
实验用来评估XSS攻击检测模型的指标为:
准确率(Accuracy),表示被正确预测出来的真正例和真负例样本占总样本的比例,其计算公式为:
(7)
召回率(Recall),表示正例样本中被正确预测的概率,其计算公式为:
(8)
F1值,是召回率与精确率的一个调和均值,是对召回率与精确率的一个综合评价,其计算公式为:
(9)
以上公式中变量的含义表示如下:
TP(真正,True Positive):将实际上是正例的样本预测为正样本;
TN(真负,True Negative):将实际上是负例的样本预测为负样本;
FP(假正,False Positive):将实际上是负例的样本预测为正样本;
FN(假负,False Negative):将实际上是正例的样本预测为负样本。
2.3 BiLSTM-Attention-CNN模型的训练
2.3.1 向量维度
神经网络输入向量的维度是固定的,而样本的维度不一致,选择一个合适的向量维度,才能充分利用样本信息。若向量维度过短,会遗失大量有效信息,降低检测准确率;若向量维度过长,会大幅增加训练的时间,不能提高准确率且降低检测实时性。为了得到合适的向量维度,本文比较了不同向量维度对准确率和训练时间的影响,结果如图 5所示。
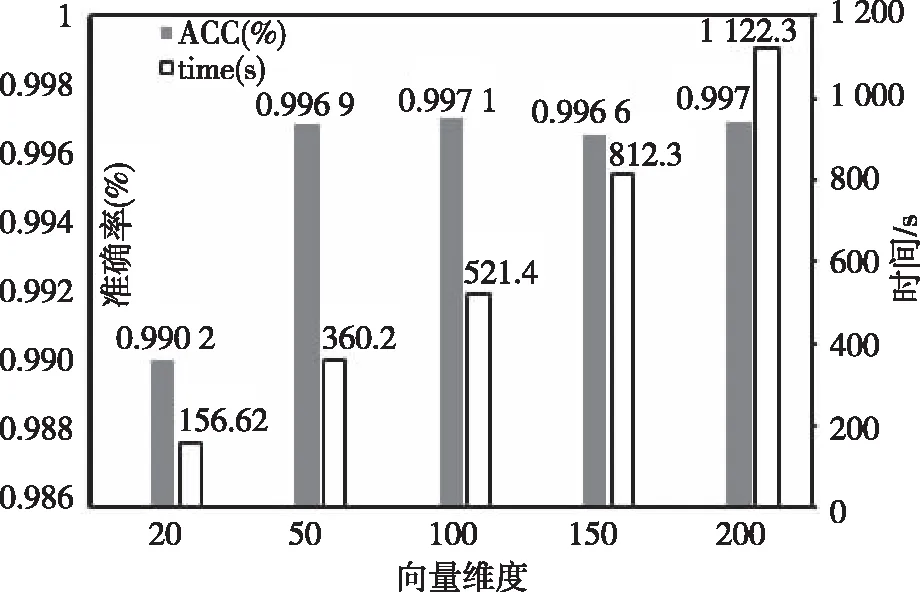
图5 向量维度Fig.5 The vector dimension
实验结果表明,维度超过50时准确率变化不太明显,但是训练时间几乎成倍增长,维度为100和50的准确率能达到最优,但是维度为50的训练时间明显低于维度超过50的训练时间,从而选择50作为向量维度。
2.3.2 卷积核尺寸对模型性能的影响
为了研究不同卷积和窗口大小对模型的影响,以便于选出最合适的模型参数,选取[2,3,4]、[3,4,5]、[4,5,6]和[5,6,7]进行对比试验,得到的结果如图6所示。
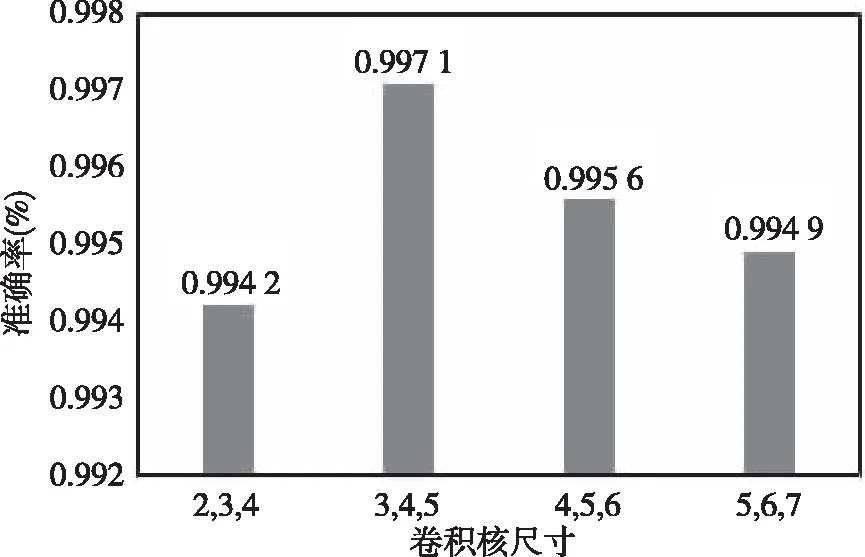
图6 卷积核尺寸对性能的影响Fig.6 Effect of convolution kernel size on performance
实验结果表明卷积核窗口大小为[3,4,5]时模型可以取得最佳的性能。窗口较小时可能由于特征捕获不足导致性能低,而随着窗口大小的增加,卷积操作的特征捕获能力增强,但是由于模型参数也会随之增加,导致模型消耗更多的空间和时间,最终导致模型性能开始下降。
模型参数的设置会直接影响到模型的分类效果,本文中模型实验是结合文献[10-12]中参数进行参考,并根据实验进行调整,本文最终选择的BiLSTM和CNN的参数见表4和表5。

表5 CNN模型参数Tab.5 CNN model parameter
图7展示了在当前参数设置下训练阶段Loss和ACC的变化。从图7可以看出在模型准确率在稳步上升,同时损失也在逐步下降,二者逐步变化到最终收敛到一个稳定值,这表明模型具有良好的检测效果。
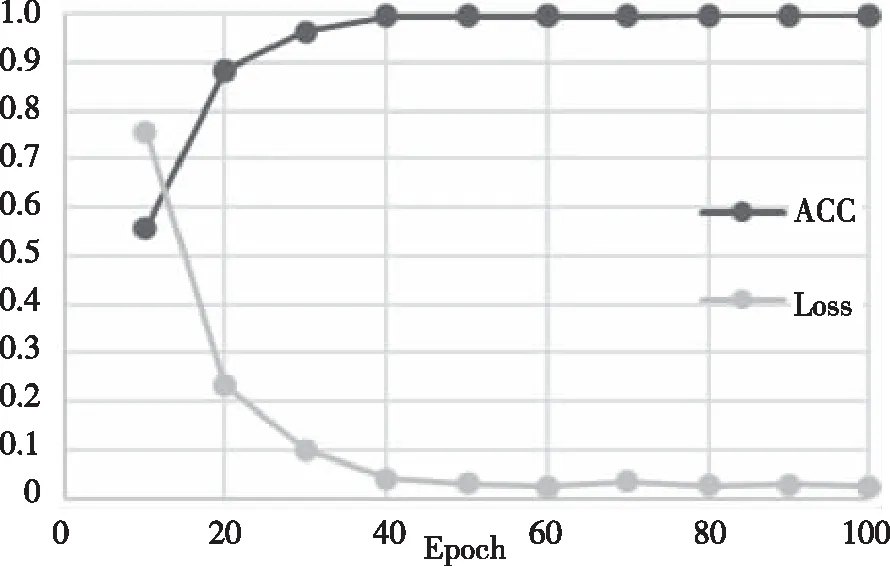
图7 训练结果Fig.7 The results of training
2.4 BiLSTM-Attention-CNN模型的测试
为了验证模型的有效性和优势,本文设计了对比试验:机器学习对比实验;深度学习对比实验。
2.4.1 机器学习对比实验
为了验证BiLSTM-Attention-CNN模型的效果,分别选取SVM、ADTree、AdaBoost 3种机器学习算法进行对比试验。SVM(支持向量机)是一种按监督学习方式对数据进行二元分类的线性分类器;ADTree是一种基于Boosting的决策树学习算法,它的分类性能要优于其他决策树;AdaBoost训练多个弱分类器,然后将弱分类器集合成一个强分类器。实验结果如表6所示,BiLSTM-Attention-CNN模型准确率达到了99.70%,召回率为99.82%,F1值为99.59%,相比SVM、ADTree、AdaBoost 3种机器学习算法大幅提升了检测效果。这是由于作为深度学习算法的BiLSTM-Attention-CNN模型可以自动的提取数据的特征并且通过多层的深度模型可以提取更深层次的特征。
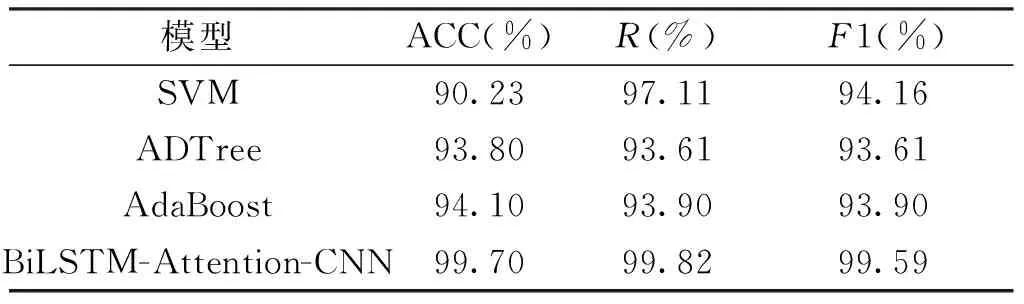
表6 机器学习方法对比结果Tab.6 The result of comparing machine learning
2.4.2 深度学习对比试验
选取CNN、GRU、LSTM和BiLSTM单一深度学习模型,以及未引入Attention机制的BiLSTM-CNN模型进一步对比,实验结果见表7、图8。可以看出,BiLSTM-Attention-CNN模型在准确率、召回率、F1值均为最优,虽然准确率方面提升较小,但召回率和F1值有较大的提升。这是因为首先通过使用BiLSTM捕获较长的双向依赖问题,再经过Attention可以选择相关性大的特征,获取文本中的有效特征,能降低噪音特征干扰,从而进一步提高分类的准确率,最后通过使用CNN模型选取相关性大的特征中最优的特征,所以BiLSTM-Attention-CNN模型在召回率以及F1值方面有进一步提升。

表7 深度学习方法结果对比Tab.7 The result of comparing deep learning
因为深度学习模型通常都会比较耗时,堆叠模型更是在提高检测精度的同时会增加收敛时间,所以本文对上述深度学习模型进行收敛时间的对比,对比结果见图8。

图8 深度学习对比结果Fig.8 The result of comparing deep learning
通过图8可以看出,CNN收敛时间最短,GRU、LSTM和BiLSTM收敛时间逐步增加,BiLSTM-CNN模型收敛时间最长。引入Attention机制的BiLSTM-Attention-CNN模型在保证检测精度的同时相比较BiLSTM-CNN减少了5.1%的收敛时间。得益于Attention机制的引入,可以选择相关性高的特征,增加对关键信息的选取减少对噪音特征的注意,所以能够在保证检测精度的同时减少收敛时间。
综上所述,BiLSTM-Attention-CNN模型在一定程度上能够有效的提取XSS中的全局和局部最优的特征,并且通过引入注意力机制,对不同的特征分配权重选取XSS中的有效特征,能降低噪音特征对模型的干扰,从而进一步提高分类的准确率并减少训练的时间。
3 结束语
本文通过首先对数据集进行数据清洗、分词,再使用word2vec进行向量化。然后引入Attention机制,结合BiLSTM和CNN进行XSS检测。通过利用BiLSTM对双向时序信息和长期依赖的处理以及Attention机制对不同数据分配不同权重,增加对关键信息的选取、减少对噪音特征的注意。最后通过使用CNN模型进一步选取相关性大的特征中有助于XSS检测的最优特征。实验表明,本文提出的BiLSTM-Attention-CNN模型相比SVM、ADTree、AdaBoost三种机器学习算法在准确率方面提高了9.45%、7.9%和5.58%。对比深度学习模型,如CNN、GRU、LSTM等,也有较大的提升;相比未引入Attention机制的BiLSTM-CNN模型,BiLSTM-Attention-CNN模型在保证检测精度的同时缩短了5.1%的收敛时间。
本文只是使用BiLSTM-Attention-CNN模型针对 XSS 一种漏洞攻击进行检测,后期将研究该模型在SQL 注入、缓冲区溢出、跨站请求伪造等多种 Web 漏洞检测以及漏洞挖掘方面的适用性。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中国交通信息化(2018年5期)2018-08-21
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
