
考虑词汇替换的汉语古音构拟检测
2022-07-29 14:07冉启斌
现代语文 2022年7期
一、引言
所谓“古音构拟”,是指通过比较一组亲属语言的语音异同以考求古代共同母语音系的研究方法,19 世纪盛行于欧洲,20 世纪初被借用来研究汉语音韵学
。高本汉较早对汉语上古音和中古音进行全面构拟。自高本汉之后,陆续有很多学者对汉语上古音、中古音进行了构拟。
总的来看,在汉语上古拟音和中古拟音中,各家存在诸多分歧。施向东指出,在汉语上古音研究中,主要体现为三个问题:阴声韵是否存在辅音韵尾、复辅音是否存在、上古汉语声调是否具有超音段音位性质
;冯蒸认为,上古汉语主要元音和韵部的构拟也存在分歧
;此外,拟音的介音情况以及是否应该从形态的角度来构拟等,也是讨论较多的问题
。中古拟音上的差异也是客观存在的。黄笑山指出,在中古音构拟中的声母系统、中古二等韵的介音、韵母系统、重纽、声调等方面,学界均存在着不同看法
。李莹娜认为,高本汉、王力、郑张尚芳等八家所构拟的中古音系,在声母、韵母和声调三个方面各有特点
。
关于古音构拟体系的检验标准,学界亦莫衷一是。潘悟云曾对上古汉语元音系统构拟体系进行了评述,并提出了五条检验拟音优劣的标准:构拟的音系是否符合语言的普遍现象,是否与亲属语言的实际音系接近,构拟的元音在整个韵母系统中的配置是否匀称,拟音是否能满意地解释谐声、通假、异读和音变,与亲属语同源词的语音比较是否贴切
。孙玉文对潘悟云所提出的五条检验标准以及潘悟云所构拟的上古音系统进行了全面剖析,并提出应从三个标准进行检验:构拟的音系能否系统地、历史地解释反映上古音的直接材料,能否系统地、历史地解释上古音到中古音的发展演变,拟音是否自成一个合理的音系。他还指出,类型学的证据只能作为检验上古拟音优劣的一项旁证
。施向东基于“内部构拟法”,对汉语上古拟音进行讨论,认为郑张尚芳的上古拟音对汉字谐声、先秦押韵、汉语语音从上古到中古的演变以及汉语与亲属语言同源词的音义关系和演变,具有很强的解释力
。马坤曾对白一平、沙加尔的拟音系统进行系统述评,认为它的优越性主要体现在三个方面:能够更好地解释语音演变、具有可验证性、注重构拟的实用性
。在中古拟音方面,由于有历史传承下来的《广韵》《韵镜》一类的韵书、韵图等书面文献材料,以及现代汉语方言和域外译音资料等“活”材料,相对于上古拟音来讲,各家中古拟音的分歧要小一些。目前,学界对中古拟音进行评测的研究较少,也未形成一套统一的评价标准。
可见,汉语的古音构拟及对拟音系统的检验存在一定分歧,并且在拟音的评估中存在着主观性较强、标准不统一等问题。冉启斌从一个新的角度对各家拟音进行检测分析,即通过运用相似性自动判断程序,来计算上古拟音、中古拟音、现代汉语方言语音相互之间的多种数据,并探讨不同拟音的合理性
。该研究除了从内部材料分析拟音的合理性外,还通过计算语言历史变化的数据作为外部参照,从而为拟音的评估提供了一种客观的、立体的方法。同时,该研究所搜集的拟音是将历史上的词汇替换现象考虑在内的,这可能会对相似度数值的计算产生一定影响,进而影响到拟音评估的结果。那么,词汇替换现象是否真地会对拟音评估的结果产生影响,这种影响究竟有多大?本文将采用冉启斌所提出的研究方法
,同时将词汇替换现象排除在外,对相关拟音进行再次评估,主要探讨词汇替换所造成的影响,以期对汉语词汇替换现象、汉语历时变化速率的认识有所助益,并进一步改进拟音评估方法。
二、方法与材料
(一)编辑距离与ASJP 模式相似度计算
相较于“活”的语言来说,拟音具有一定的特殊性,它并没有物理上的语音载体,只有通过记音符号书写的文字形式。因此,计算拟音的相似度,实际上只能采用计算转写拟音的字符串的相似度这种方法。本文所说的相似度又与字符串的距离息息相关,即距离越小则相似度越大,距离越大则相似度越小。
古音的构拟在很大程度上是参考了现代汉语中的某些方言的,同时,不同的拟音与方言的相似度是不同的。限于篇幅,这里仅列出10 个方言区中与各家拟音平均相似度最大和最小的方言。具体如表3 所示(表中括号内为相似度):
手动试切对刀中,如果确定了一把基准刀,且在刀偏表中输入它的刀偏置为零,而且非基准刀相对于基准刀有一定的刀偏置,这种试切对刀方法叫相对刀偏法对刀。每一把刀具都独立建立自己的补偿偏置值,即在刀偏表中每把切削刀都有刀偏置。这种对刀方法方便检查对刀的准确性和监控设备安全性,在教学实习应用更广泛。但必须注意的是,机床在对刀前必须先回机械零点。
方言语档是由现代汉语方言所构成的语档,共包含60 个方言点。方言点的选择主要依据的是《中国语言地图集》的划分,同时,尽量平衡各方言区、方言小片之间语档的数量。这里以方言点的名称来代指该地的方言,如“北京”指“北京话”。本文60 个方言语档与冉启斌的语档略有不同,其中,有45 个是一致的,另外15 个由于搜集途径和时间的不同而有所差异,这些不同的方言点均采用邻近的点予以替代,即在方言分区上保持一致,因此,对计算结果的影响不大。60个汉语方言语档的分布情况,具体如表1所示:
该鱼具有多元价值功能,其中最为突出的是食用营养和滋补保健价值,鳜鱼是一味高档美味佳肴,也是西餐常用鱼之一,肉质细嫩、爽脆、弹牙,味道鲜美,而且还是一味高级滋补保健品。根据中国传统中医理论,该鱼味甘、性平,无毒,归脾、胃经;具有益脾胃、补气血的功效。
基于编辑距离的“相似性自动判断程序(Automated Similarity Judgment Program, 简 称‘ASJP’)”,则为语言之间的距离计算提供了极大的便利,同样得到了广泛的应用。Brown 等使用相似性自动判断程序,通过自动判断语言100 个核心词之间的词汇相似度,来测量语言之间的距离
。Holman 等对ASJP 计算模式进行了改进,将编辑距离作为判断词汇距离的标准,并将用于计算相似度的核心词数量精简到40 个
。Wichmann 等系统讨论了归一化编辑距离和归一化编辑距离商两种编辑距离在计算语言相似度上的表现
。Holman 等基于词汇相似度,利用ASJP 数据,对世界语言进行了自动断代
。截至目前,ASJP 数据库已经更新到第19 版。
(2)蛋白质含量的测定[10]:取100 μg/mL牛血清蛋白标准溶液0.2、0.4、0.6、0.8、1.0 mL分别加入到试管中,用超纯水补充到1 mL,再分别加入5 mL考马斯亮蓝溶液并混合均匀,放置5 min后依次在595 nm处测定吸光度,用Excel软件进行直线回归分析,以吸光度为x,牛血清蛋白浓度为y,绘制标准曲线。
如前所述,进行ASJP 模式的相似度计算,需要收集由核心词转写而来的文字材料,我们将这种文字材料称为“语档(doculect)”。本文的语档包括拟音语档和现代汉语方言语档(以下简称“方言语档”)两部分。其中,拟音语档又分为两种:上古拟音语档和中古拟音语档。本文所考察的拟音系统与冉启斌的研究一致,来自于高本汉、王力、李方桂、董同龢、周法高、郑张尚芳、潘悟云、白一平—沙加尔(这里选用其2014年版本的拟音,以下简称“白—沙”)等八家
,这八家同时构拟了上古音和中古音。
综上所述,采用PDCA循环护理模式对PICC置管患者进行护理,护理质量得到明显的升高,有效地预防导管相关并发症的发生,降低并发症发生率,利于患者治疗的顺利开展,促进治疗效果升高,让患者尽早康复出院,提高患者对护理的满意程度。
(二)拟音语档与方言语档
近些年来,国内也有不少学者介绍、采用了ASJP相似度计算模式。江荻借鉴ASJP 的方法,采用编辑距离,对195 种藏缅语言或方言进行了自动分类,所得关系树与传统藏缅语分类结果基本一致
。冉启斌和索伦•维希曼使用ASJP 工具,对ASJP 数据库中的世界语言核心词进行了距离计算,提出了划分语言与方言层级的参考指标。他们还针对汉语方言的特征,对ASJP 编码进行了修订,并计算了65 个汉语方言语档之间的距离,构建了系统发育树和系统发育网络,呈现了汉语方言之间亲缘关系的远近
。吴丹丽使用ASJP 工具,计算了248 个汉语方言的距离,分析了汉语北方方言和南方方言在同质性上的差异
。
对输水管线走向和布置位置要反复踏勘,选择地形起伏小、地质条件较好、穿越各种地物和设施较少,路径较短的线路作为最佳设计方案。要摸清地面和地下设施情况,与有关部门联系沟通,掌握已作出的规划情况,协商作出管道布置意见,避免盲目规划布线,造成实施困难。
国内学者也采用编辑距离进行语言学研究。王璐利用编辑距离计算了吴语五个方言点之间的距离,作者指出,五个方言点之间的语言距离和互通度呈负相关
。赵志靖、江荻对侗台语族的语言进行了编辑距离计算,所得的分类结果与历史语言学的分类结果基本一致;作者明确指出,编辑距离可以应用于东亚语言的研究中
。赵志靖还对藏缅语族的语言进行了编辑距离分类,得到了比较理想的分类结果,再一次验证了编辑距离在东亚语言中的适用性
。编辑距离运用于语言或语言变体之间距离计算的有效性可见一斑。不过,编辑距离用于数据量较大的计算时,需要依托计算机程序进行处理。


八家拟音上古与中古的相似度均值为41.87。董同龢构拟的上古音与中古音之间的相似度达到63.26,是八家中最高的。依据上文的参考指标来看,董同龢上古、中古拟音之间的关系类似于方言变体之间的关系,相似度过高。潘悟云上古、中古拟音之间的相似度为22.05,是八家中最低的,处于同语族语言的范围。此外,高本汉上古、中古拟音的相似度也比较高,达到59.74;郑张尚芳的则比较低,只有22.28。董同龢、高本汉、王力的上古拟音与中古拟音,处于方言变体的范围;李方桂、周法高、白—沙、郑张尚芳、潘悟云的上古拟音与中古拟音,则处于同语族语言的范围。
“以往医院采购需要预算立项,每年一次,现在医院计财处在前期预算立项环节设立预算库,以后有需求可以随时提出,经评估论证后可直接进入预算库排序。”唐通军介绍道。
语档搜集好之后,利用ASJP 程序计算出一系列相似度数据,并在Excel2019 和SPSS26 中完成数据的整理和分析。
三、拟音与汉语方言
在报告相关数据之前,我们需要确定一个参考标准。索伦•维希曼、冉启斌对ASJP 数据库中的世界语言核心词进行了距离计算,提出了划分语言与方言层级的参考指标
。本文对拟音相似度大小的评估将会参考这一指标。他们主要从ASJP 数据库(第18 版)中,抽取出不同语系之间、相同语系不同语族之间、相同语族不同语言之间、相同方言的不同变体之间的多个语档,分别计算了各自的相似度,进而测算出四种不同区分层级之间的临界值:相似度小于2.37%的,属于不同语系的语言(以下简称“跨语系语言”);相似度在2.37%~18.64%之间的,属于相同语系不同语族的语言(以下简称“跨语族语言”);相似度在18.64%~50.90%之间的,属于相同语族的语言(以下简称“同语族语言”);相似度大于50.90%的,则属于相同方言变体(以下简称“方言变体”)。作者还指出,语言与方言的不同层级区分在不同语系的语言中情况都可能不一样,上述的临界值只是一个普遍的参考指标。
总之,在测算语言或语言变体距离方面,ASJP 模式的距离与相似度计算具有良好的表现,能够满足本文测量各家上古拟音与中古拟音之间、中古拟音与现代汉语方言之间相似度的要求。本文对相似度值的界定与冉启斌一致,即相似度值为1 减去归一化编辑距离商
。
我们对词汇替换前八家上古拟音与自身中古拟音的相似度进行了计算,具体结果如表2 所示:

在ASJP 模式的相似度计算中,语档包含的内容是40 个核心词的转写材料,具体词项可参看Holman等人的研究
,此处不再列出。拟音语档和方言语档的搜集主要参考了“东方语言学”“汉字古今音资料库”“复旦大学东亚语言数据中心”“古音小镜”等网络资源。需要注意的是,本文在搜集语档时,不考虑词汇替换的现象,这与冉启斌不同。以“sun”为例,在冉启斌搜集的材料中,上古拟音用“日”,中古拟音用“太阳”,现代汉语方言中按具体情况有“太阳”“日头”“阳婆”等
,即在同一个词义上发生了词汇的替换,我们将这种情况简称为“词汇替换后”。本文中的“sun”这一意义,上古拟音用“日”,中古拟音用“日”,现代汉语方言中也用“日”,即没有发生词汇的替换,我们将这种情况简称为“词汇替换前”。
实际上,汉语上古音与中古音之间的差距应该大于方言变体之间的差距,而高本汉、董同龢等的上古拟音与中古拟音之间的相似度均处于方言变体的范围,其相似度显然过高了。因此,从上古音与中古音相似度这一角度来看,高本汉与董同龢的上古拟音与中古拟音在自洽性上较其他的拟音系统欠佳。与高本汉等早期学者不同,郑张尚芳、潘悟云的上古拟音与中古拟音的相似度较小,说明他们构拟的上古音和中古音有较大的不同。这也从一个侧面说明,随着研究的日益深入,对古汉语的构拟也愈加合理。
莱文斯坦编辑距离(以下简称“编辑距离”)由Levenshtein 首先提出
,在计算字符串的距离上具有很好的效果,并在学界得到广泛应用。Sankoff 等曾详细介绍了编辑距离应用于基因测序、测量转码后的鸟鸣声这一案例
。Kessler 第一次将编辑距离应用于测量爱尔兰盖尔语方言语音之间的距离
。之后,编辑距离广泛运用于荷兰语、撒丁语、挪威语、德语、斯堪的纳维亚语等语言/方言的研究中
。

从表3 可以看出,客家方言与高本汉、王力、李方桂、周法高、白—沙等五家上古拟音平均相似度最高,并且均处于同语族语言的范围;粤方言与董同龢上古拟音的相似度最高,也处于同语族语言的范围。赣方言与郑张尚芳、潘悟云两家上古拟音的相似度最高,但处于跨语族语言的范围。在八家上古拟音中,郑张尚芳、潘悟云、白—沙三家与方言的平均相似度总体上都比较低,或许能反映出他们在上古音的构拟中纳入的方言因素,相对其他五家来说是比较少的。在中古音方面,客家方言与八家构拟的中古音都是相似度最高的,并且平均相似度内部差异较小(平均值±标准差:39.09±2.64);与上古拟音的情况(25.04±7.63)相比,其一致性更高。这可能是因为在本文所选的客家方言语档中保留的中古音成分较多,也可能是因为各家在构拟中古音时较为广泛地参照了客家方言。
与上古拟音相似度最低的都是晋方言,也就是说,晋方言核心词中保留的上古音成分是比较少的。按理说,应该是官话与上古拟音的相似度最低,但在本研究所使用的语档中,官话的内部相似度不如晋方言的内部相似度高
,官话内部的差异或许是导致它与各家上古拟音的相似度不是最低的重要原因。在中古拟音方面,晋方言与李方桂、潘悟云、白—沙三家的相似度最低,吴方言与其余五家的相似度最低。与上文所述的情况类似,在与拟音相似度最低的方言中,同样是上古拟音的内部差异(9.43±5.83)大于中古拟音的内部差异(20.65±2.10)。
根据压汞法的测试数据,作出 lnV和 ln(P-Pt)的双对数图,进行直线拟合求得其斜率K。计算分形维数方程为
除上古拟音与中古拟音的相似度、拟音与各个方言的平均相似度外,还有一些数据可以考察。为便于分析上古拟音至中古拟音、中古拟音至现代汉语时期的变化情况,我们分别整理出以下数据:各家上古拟音与方言语档(“北京话”除外,下同)的相似度S1、各家中古拟音与方言语档的相似度S2、北京与方言语档的相似度S3。其中,方言语档主要是作为参照。之所以把北京除外,是因为本文将拟音视为现代汉语的前身,即假设汉语的变化是由上古拟音演化到中古拟音,再由中古拟音演化为现在的北京话。也就是说,上古拟音、中古拟音和北京话是时间上的先后关系。上述三项数据如表4 所示:
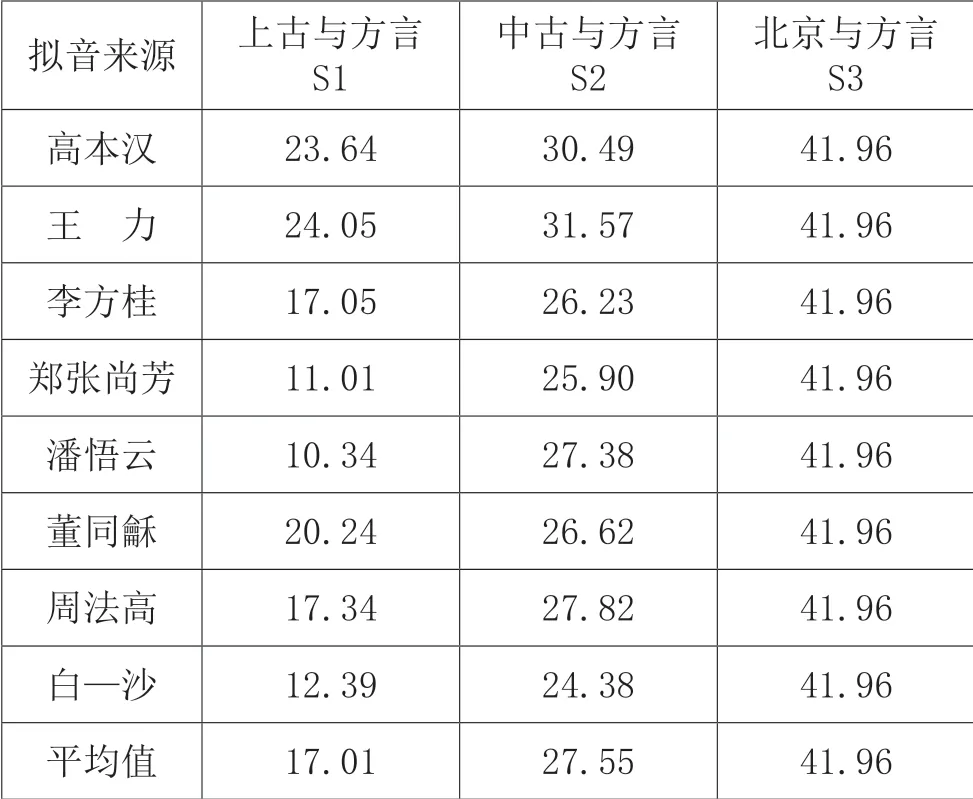
从表4 可以看出,北京与方言语档的相似度(S3)为41.96。八家上古拟音与方言语档相似度(S1)的均值为17.01,其中,王力的S1 值在八家中最高,为24.05;潘悟云的S1 值则在八家中最低,为10.34。白—沙、周法高、潘悟云、郑张尚芳和李方桂等的上古拟音,与方言语档的相似度均低于18.64,处于跨语族语言的范围内;高本汉、王力和董同龢的上古拟音,与方言语档的相似度均高于18.64,处于同语族语言的范围内。可见,早期学者所构拟的上古音总体上较近期学者的拟音更接近现代汉语方言。八家的中古拟音与方言语档相似度(S2)的均值为27.55,其中,王力的S2 值仍然是八家中最高的,为31.57;白—沙的S2 值则最低,为24.38。八家中古拟音与方言语档均处于同语族语言的范围。综合上古、中古拟音来看,白—沙、潘悟云和郑张尚芳等与方言语档的相似度往往比较小,而王力和高本汉等则往往比较大。
四、常用词汇替换对相似度计算的影响
根据汉语历史发展的实际情况,并考虑到计算的简便,我们假设各家的上古音均在春秋与战国之交的公元前5 世纪中叶使用,中古音的时期则定在《广韵》刊行的11 世纪初。这样,从上古音到中古音跨越的时间约为1.45 千年,从中古音到现代汉语跨越的时间约为1.00 千年(以下简称这两段时期为“两时期”)。那么,根据两时期相似度的变化值和时间跨度,可以计算出上古拟音至中古拟音的相似度变化速率:CS1=(S2-S1)/1.45,中古拟音至现代汉语的相似度变化速率:CS2 =(S3-S2)/1。然后,根据两时期相似度变化速率的比值,可以得出相似度变化速率比:CR =CS2/CS1 =(S3-S2)/(S2-S1)*1.45。上述三项数据,具体如表5 所示(见下页):
表5 中,“前”“后”分别代指词汇替换前后的情况,其中,“词汇替换后”部分来自冉启斌的研究
。需要说明的是,关于语言相似度变化速率的研究并不多见,Holman 等曾依据ASJP 计算的相似度来推断语言的分化年代,并提出了一个基于词汇相似度来计算语言分化年代的公式
。根据该公式带入汉语的相关数据,大致可以计算出一般情况下汉语两时期的相似度变化速率比:CR =44.3/20.21 =2.19。由于汉语的情况较为复杂,这个数值的合理性还有待进一步验证,因此,在下文的分析中仅作为参考值。

需要指出的是,这里主要对词汇替换前的数据进行分析。上古至中古相似度变化速率(CS1)的均值是7.27,也就是说,八家的上古拟音演化到中古拟音,其相似度平均增加了7.27。其中,潘悟云的CS1 值是八家中最高的,为11.75;郑张尚芳次之,为10.27。与之相比,董同龢的CS1 值是八家中最低的,只有4.40;高本汉、王力、李方桂等的CS1 值也比较低。之所以会出现这种现象,与前文所述拟音内部上古、中古的相似度情况近似。较早期的学者上古与中古拟音之间的相似度较大,因此,上古至中古之间的变化速率就会较小。
中古至现代的相似度变化速率(CS2)较上古至中古平均上升近一倍,均值为14.41。也就是说,八家的中古拟音演化到现代汉语北京话,其相似度平均增加了14.41。其中,白—沙的CS2 值是八家中最高的,为17.58;郑张尚芳次之,为16.05;而王力的CS2 值则是八家中最低的,为10.38。
化合物 3A08:质谱 ESI/MS(negative mode),m/z 222,[M-H]-。 1H NMR(500 MHz,CDCl3,TMS),δ为7.20~7.23(m,2H),6.98(t,J=8.5 Hz,2H),6.03(br.s,1H,NH),4.37(d,J=6.0 Hz,2H),2.18(t,J=7.5 Hz,2H),1.60 ~1.65 (m,2H),1.27 ~1.29 (m,4H),0.87 (t,J=7.5 Hz,3H)。
通过多举措落实,武定地区主要用电行业高钛渣冶炼、铜精矿采选、水泥、球团矿冶炼和建材类砖厂等用电需求大大增加。截止10月,高钛渣开工率同比提高6.98%,电量同比增长12.46%;铜精矿采选开工率同比提高13.25%,电量同比增长225.38%;水泥开工率同比提高18.75%,电量同比增长979.34%;球团矿冶炼开工率同比提高17.28%,电量同比增长41.08%。由于主要用电行业开工率同比提高较大,致使楚雄武定供电局售电量大幅增长。近十年来售电量增长首次突破4亿千瓦时大关。
八家拟音相似度变化速率比(CR)的均值为2.16,这一结果与参考值2.19 非常接近。在八家中,CR 值最高的是董同龢,达到3.49,这个数值显然是过高了;高本汉、李方桂等的CR 值也比较高。CR 值最低的则是潘悟云,为1.24。最接近参考值的是白—沙,其相似度变化速率比为2.12。
将词汇替换前后的两种情况进行比较,可以看出,在词汇替换后,CS1 差值的均值为0.12,各家具体的差值则有正有负。其中,高本汉、王力、李方桂、董同龢四家,词汇替换后的CS1 提高了;郑张尚芳、潘悟云、周法高、白—沙四家,词汇替换后的CS1 则降低了。各家CS2 差值的均值为2.19,并且八家拟音CS2 的差值均为正数,也就是说,词汇替换前的CS2均比词汇替换后的要大。同时,各家的具体差值也是不一样的,其中,王力的变化范围较小,只有0.56;而李方桂的变化范围较大,达到3.92。
仅从CS1 和CS2 的差值来看,仍不足以说明太多问题;相比之下,CR 的差值则能够反映更多的信息。CR 代表相似度的变化速率比,亦即代表两个时期语言变化速率的比值,CR 越大则代表变化越快,CR 越小则代表变化越慢。在词汇替换后,按照一般规律来说,其变化速率应该比词汇替换前的情况要快,即词汇替换前与词汇替换后CR 的差值应该为负。如果CR 的差值为正,则表明词汇替换后的相似度变化速率比反而比较小,这是违背常理的。不过,从表5 可以看出,在八家拟音中,仅有郑张尚芳、潘悟云两家拟音的CR差值为负,而其余六家的CR 差值均为正值。从八家拟音相似度变化速率比(CR)在词汇替换前后的表现来说,郑张尚芳、潘悟云两家的拟音无疑更符合常理,其自洽性也是较高的。
除此之外,本文还考察了词汇替换对拟音与方言语档之间相似度的影响。具体做法是:选取词汇替换前和词汇替换后两种情况下均有的45 个方言语档,分别求出各家拟音上古、中古与这些方言语档在词汇替换前后相似度差值的数据。然后,根据差值数据的分布情况,采用配对样本T 检验(Paired T-test)或威尔科克森秩和检验(Wilcoxon Rank Sum Test)。最终的结果显示,八家上古、中古拟音在词汇替换前后与方言语档的相似度,均具有显著差异(ps <0.01)。也就是说,各家拟音在词汇替换前后,无论是上古拟音与方言语档的相似度,还是中古拟音与方言语档的相似度,均有显著的不同。将八家的数据合并以后看,上古拟音与方言语档的相似度、中古拟音与方言语档的相似度,在词汇替换前后也具有显著的差异(ps <0.001)。从描述统计中的均值和中位数来看,拟音均是在词汇替换前与方言语档的相似度更大,在词汇替换后与方言语档的相似度更小。
五、结语
语言是在不断地发展变化的,不同语言的演变速率也不尽一致。从这一意义上说,对拟音上古到中古、中古到现代的变化速率进行考察,能够更好地认识汉语的历时演变状况、估测汉语不同阶段的演进速度。对于大部分使用表音文字系统的语言来讲,语言的变化大都体现在词形的变化上,根据不同时期的词形变化即可计算出变化的速率。汉语则属于表意文字系统,语音的历时演变无法在文字上体现出来,这就为汉语演变速率的考察带来很大的困难。就此而言,一套自洽的、合理的拟音或许会有助于解决这一难题。本文依据拟音中核心词语的国际音标形式,采用基于编辑距离的ASJP 相似度计算,对八家拟音的合理性和自洽性进行评估。综合考虑拟音系统内部上古与中古之间的相似度、拟音与现代汉语方言语档的相似度、两时期相似度变化速率和相似度变化速率比等参数,以及八家拟音在词汇替换前后两种情况下的具体表现,我们认为,郑张尚芳的拟音在八家中是自洽性最高的,潘悟云、白—沙两家的拟音也相对较好。
在历史演变过程中,汉语出现了词汇替换现象。本文通过比较拟音中词汇替换前后两种情况下的相关数据,来探讨词汇替换对语言变化速率的影响。在八家拟音中,无论是上古拟音还是中古拟音,与方言语档的相似度,均是词汇替换前比词汇替换后要大,并且这种差异具有统计学上的显著性。这也说明,汉语历史上常用词汇的替换会对语言演变速率的计算产生一定影响。如果将词汇替换的情况考虑在内的话,那么,古音与现代汉语方言的相似度会更小一些。同时,从古音评估的结果来看,本文的结果与冉启斌采用词汇替换后的语档所计算的结果总体上是一致的
。我们认为,在汉语词汇替换(包括在方言中的替换)现象的有关研究还不足以覆盖ASJP 所用的40 个核心词的情况下,考虑到操作的便捷性和汉语的实际情况,直接采用词汇替换后的语档进行计算即可。一方面,它可以避免耗费精力去寻求替换之前的词汇;另一方面,这也是尊重汉语历史上本来就存在词汇替换这一事实。
总之,在计算语言和方言的相似度方面,ASJP 有着较大的便利性和可行性,冉启斌将它运用于对拟音进行评估,拓宽了ASJP 的使用领域
。本文基于语档相似度,进一步对拟音以及汉语历史上存在的词汇替换现象进行评估,为汉语变化速率的研究提供了初步的数据支持,有助于促进对汉语历时演变情况的认识。我们也希望,今后能够使用数量更多、制作更精细的语档,对相关问题进行更深入的探究。
[1]曹述敬.音韵学辞典[Z].长沙:湖南出版社,1991.
[2]施向东.略论上古音研究中的几个问题[J].渤海大学学报(哲学社会科学版),2012,(6).
[3]冯蒸.关于郑张尚芳、白一平-沙加尔和斯塔罗斯金三家上古音体系中的所谓“一部多元音”问题[J].南阳师范学院学报(社会科学版),2017,(4).
[4]白一平,潘悟云.上古音对谈实录[A].复旦大学汉语言文字学科《语言研究集刊》编委会.语言研究集刊(第二十一辑)[C].上海:上海辞书出版社,2019.
[5]黄笑山.汉语中古语音研究述评[J].古汉语研究,1999,(3).
[6]李莹娜.八家汉语中古拟音比较研究[D].西安:陕西师范大学硕士学位论文,2018.
[7]潘悟云.上古汉语元音系统构拟述评[A].江蓝生,侯精一.汉语现状与历史的研究——首届汉语语言学国际研讨会文集[C].北京:中国社会科学出版社,1999.
[8]潘悟云.汉语历史音韵学[M].上海:上海教育出版社,2000.
[9]孙玉文.上古音构拟的检验标准问题[A].北京大学汉语语言学研究中心《语言学论丛》编委会.语言学论丛(第三十一辑)[C].北京:商务印书馆,2005.
[10]施向东.从系统和结构的观点看汉语上古音研究[J].南开语言学刊,2009,(1).
[11]马坤.历史比较下的上古汉语构拟——白一平、沙加尔(2014)体系述评[J].中国语文,2017,(4).
[12]冉启斌.变化速度与构拟评估——基于汉语语档历时相似度计算的考察[R].暨南大学汉语方言研究中心、暨南大学发音语音学实验室,2020-10-20.
[13]Levenshtein,V.I.Binary codes capable of correcting deletions, insertions, and reversals[J].Soviet Physics Doklady,1966,(8).
[14]Sankoff,D. & Kruskal,J.B.Time warps, string edits, and macromolecules :The theory and practice of sequence comparison[M].Addison-Wesley,Reading,MA,1983.
[15]Kessler,B.Computational dialectology in Irish Gaelic[A].Proceedings of the Seventh Conference of the European Chapter of the Association for Computational Linguistics[C].1995.
[16]Bolognesi,R. & Heeringa,W.De invloed van dominante talen op het lexicon en de fonologie van Sardische dialecten[J].Gramma/TTT:tijdschrift voor taalwetenschap,2002,(1).
[17]Gooskens,C. & Heeringa,W.Perceptive evaluation of Levenshtein dialect distance measurements using Norwegian dialect data[J].Language Variation and Change,2004,(3).
[18]Heeringa,W.J.Measuring dialect pronunciation differences using Levenshtein distance[D].PhD thesis,University of Groningen,2004.
[19]Nerbonne,J. & Siedle,C.Dialektklassifikation auf der Grundlage aggregierter Ausspracheunterschiede[J].Zeitschrift für Dialektologie und Linguistik,2005,(2).
[20]Gooskens,C.The Contribution of Linguistic Factors to the Intelligibility of Closely Related Languages[J].Journal of Multilingual and Multicultural Development,2007,(6).
[21]王璐.语言距离与吴语互通度[D].上海:华东师范大学博士学位论文,2014.
[22]赵志靖,江荻.侗台语族语言的编辑距离分类[J].计算机工程与应用,2018,(19).
[23]赵志靖.藏缅语族语言的编辑距离分类[J].南开语言学刊,2019,(2).
[24]Brown,C.H.,Holman,E.W.,Wichmann,S. &Velupillai,V.Automated Classification of the World’s Languages:A Description of the Method and Preliminary Results[J].Language Typology and Universals,2007,(4).
[25]Holman,E.W.,Wichmann,S.,Brown,C.H.,Vilupillai,V.,Müller,A.,Brown,P. & Bakker,D.Explorations in automated language classification[J].Folia Linguistica,2008,(3-4).
[26]Wichmann,S.,Holman,E,W.,Bakker,D. & Brown,C.H.Evaluating linguistic distance measures[J].Physica A:Statistical Mechanics and its Applications,2010,(17).
[27]Holman,E.W.,Brown,C.H.,Wichmann,S. et al.Automated Dating of the World’s Language Families Based on Lexical Similarity[J].Current Anthropology,2011,(6).
[28]江荻.藏缅语谱系的自动分类实验[A].《中国民族语言学报》编委会.中国民族语言学报(第一辑)[C].北京:商务印书馆,2017.
[29]冉启斌,索伦•维希曼.怎样区分语言与方言——基于核心词汇的距离计算方法探索[J].语言战略研究,2018,(2).
[30]索伦•维希曼,冉启斌.ASJP 模式的汉语方言计算分析——以65 个汉语方言语档为例[J].现代语文,2019,(5).
[31]索伦•维希曼,冉启斌.语言与方言的区分层级——ASJP 模式的核心词汇距离计算再分析[J].南开语言学刊,2019,(2).
[32]吴丹丽.基于词汇语音距离的汉语方言计算分析[D].天津:天津师范大学硕士学位论文,2020.
猜你喜欢
家教世界·创新阅读(2020年4期)2020-06-03
看天下(2019年25期)2019-10-15
福建基础教育研究(2019年8期)2019-05-28
百家讲坛(2019年18期)2019-02-16
卷宗(2018年24期)2018-11-07
中学生博览(2017年23期)2017-12-16
智富时代(2016年8期)2016-05-14
智富时代(2016年8期)2016-05-14
儿童故事画报(2016年2期)2016-04-18
文学教育·中旬版(2012年4期)2013-02-01
