
基于改进鲸鱼算法的地理空间数据可视化提取系统设计
2022-07-21 02:57胡坤霖温剑锋朱安峰徐海燕
自动化技术与应用 2022年6期
胡坤霖,温剑锋,徐 刚,3,朱安峰,徐海燕
(1.中南大学 计算机学院,湖南 长沙 410083;2.浙江安防职业技术学院 应急管理学院,浙江 温州 325016;3.中南大学 地球科学与信息物理学院,湖南 长沙 410083)
1 引言
当前社会正处于“信息爆炸”时代,由于科技进步,人们被海量数据包围。其中空间数据是地理信息系统的关键组成部分,也是国家基础建设的主体。通常将其当作为与空间位置相关的、展示客观世界的不同实体数据。其组成要素包括空间、属性、拓扑以及时间数据等。其中,空间数据表示位置、轮廓与形状信息;属性数据则代表地理要素属性特点,例如种类、等级等;拓扑数据反映要素之间具有的空间关系;时间指各类信息采集的时间特性。对于这些铺天盖地的地理空间数据,首要问题就是如何从这些信息中提取有用信息。
文献[1]提出基于平行坐标轴动态排列的空间数据可视化提取方法。结合信息属性特征对地理空间位置进行聚类分析,利用Voronoi图与颜色明暗映射对空间中不同区域进行标注;通过平行坐标呈现出地理空间的属性信息。优化数据线布局,改善地图和坐标系数据线分布的紊乱程度;至此,完成基于坐标轴动态排列的空间数据可视化提取系统设计。文献[2]提出面向双向、多变量的连续面域拓扑图可视化提取方法。利用格网密度补偿与积分补偿试探方式对连续面域拓扑图算法做优化处理,实现基本变量表示。再使用空间内插与符号扩展对不同变量在连续面域拓扑图中进行描述,达到空间数据可视化提取目的。
上述两种可视化提取系统连续性较差,在数据安全方面也存在一定缺陷。为此,本文在改进鲸鱼算法基础上设计一种新的地理空间数据可视化提取系统[3-4]。
2 地理空间数据预处理
为了准确提取出用户需要的地理空间数据,本文提出基于自组织神经网络的数据预处理方法[5-7]。神经网络可实现模式识别与分类,在海量数据中,有助于改善空间数据可视化提取质量,可以在不理想状况下实现噪声数据过滤。SOM在地理空间数据中能够进行降维处理,构建拓扑,不但保留数据初始关系,还能将数据的非线性关系变换为几何关系[8-9],减少计算量。
SOM模型自组织性能较强,通过对权系数Wi,j的不断调节,保证神经网络在相同形态中收敛。此时,神经元只针对某个输入模式敏感。假设X={x1,xi,xn}代表输入模式,W=(wi,j|1≤i≤n,1≤j≤c)表示输入神经元i与输出神经元j的权值矩阵,Y=(y1,y2,…,yc)描述输入节点匹配响应程度。则在t时间点有:

公式中,d表示欧式距离。输出节点响应程度体现出此节点有关输入部分的匹配度。若需满足最优匹配,则必须符合如下条件:
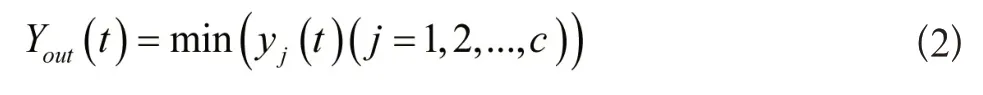
在此节点的拓扑邻域中对权系数进行调整:
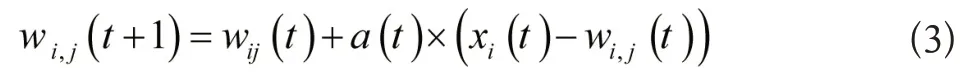
公式中,a(t)代表学习参数。
下述为自组织学习方法的全部学习步骤:
对输入与输出层的全部链接权值wi,j任意赋予[0,1]区间的值。确定迭代次数T、初始化近邻NE(t)。
步骤一:输入新模式Xk,并获取该模式和全部向量之间的空间距离。针对输出神经元j,利用dj,k表示其与输入模式之间的距离,则有:
步骤二:将dj,k最小节点作为优胜节点。其与输入模式之间最小神经元即为最佳输出神经元c。如果采用Wc描述神经元存在的权系数矢量,则有:

步骤三:判定全部模式是否完全输入,反之回到步骤一。在实际运用过程中,一般结合经验选取NE(t)的值。选择原则为:使原始NE(t)值较大,再逐渐缩小至0,此时能够快速获取输入矢量的概率结构,更加细致地调节权值,确保其满足输入空间概率分布要求。
SOM 模型能够对空间数据起到聚类作用,可将聚类中心[8]当做初始输入,具有压缩效果,确保拓扑有序。其非监督学习原则可以有效去除冗余数据,实现数据降维,有助于改善可视化提取性能[10-11]。
3 地理空间数据可视化提取系统设计
3.1 基于改进鲸鱼算法的可视化提取
在可视化提取系统中,视图长宽比是非常重要的性能。传统的可视化系统随着数据量的增加,长宽比性能迅速下降,这是因为系统容量不够导致的。为解决这一问题,本文利用改进鲸鱼算法寻找可视化提取的最佳目标,同时能够实现系统扩容。该方法模仿了鲸鱼的狩猎行为,其优势在于操作简便,需调节的参数较少,能够避免局部最优。算法整个过程包括觅食、收缩包围与捕食三个过程。
(1) 随机觅食

公式中,X'表示个体所处位置,G表示现阶段迭代次数,代表目标更新之前和其它目标之间存在的距离,A与C均表示随机参数。
(2) 缩小包围
当鲸鱼在寻找到食物之后,会再次进行位置更新,此时数学模型表示为:
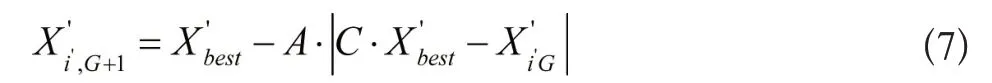
(3) 捕食
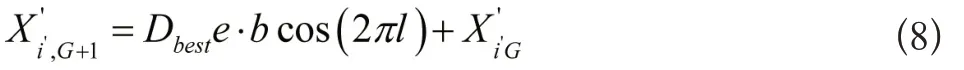
为此,本文对鲸鱼算法做出一定改进,当完成每次迭代后,在现阶段最佳解基础上对差分算子做变异、交叉处理,以便获得适应性更强的最佳解,再对当前最佳解进行替换,反之执行下一次迭代。差分进化处理过程的主要目的为:利用随机选取的方式使试验矢量中最少包括一个目标做出的贡献,否则种群不会发生变化:
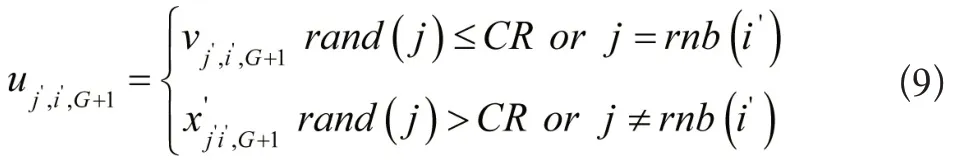
公式中,rand(j)[0,1]表示平均分布的随机数,rnb(i)[1,2,…,n]代表随机整数,CR[0,1]描述较差几率,取值为0.1。
将完成交叉处理后的目标与当前目标对比,令适应度较小的值进入到下次迭代种群中:
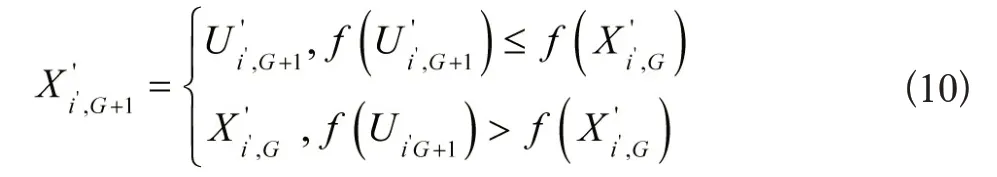
上述即为利用改进的鲸鱼算法构建的系统容量变化模型。此方法经过多次变异、交叉处理,丰富了种群类型,扩大搜索空间,提高全局搜索性能,避免陷入局部最优,获取最佳提取结果。此外系统容量得到扩大,可视化提取的长宽比性能也得到改善。
3.2 系统整体架构确定
结合以上设计原则,将可视化提取系统分为表现层、服务层、支撑层、资源层与基础平台层。此种分层设置思想具有很多优势,可将其中任意一层当作整体理解,也能够减少层次之间的依赖性,便于标准化服务。具体每层设计如下:
(1) 表现层
表现层就是用户的可视化界面,是系统最顶层架构,方便信息交互。该可视化提取系统主要针对空间数据可视化领域,通过表现层让用户更加直观感受到系统所提供的服务。
(2) 服务层
服务层在表现层下方,主要负责业务逻辑与基础设备,执行某些特殊功能,更好地服务于表现层。在服务层中主要定义了如下功能:数据导入接口:利用该接口,便于将地理空间数据导入到系统内部;数据表示:便于用户了解数据属性与维度;算法编辑:为上述算法提供导入功能,并实现与支撑层的数据交互;此外,该层还可以提供可视化展示等服务。
(3) 支撑层
支撑层是为表现层与服务层提供支撑能力的,在该系统架构中支撑层提供的服务如下:数据变换功能:将其他层次导入,利用该功能变换为符合系统要求的数据格式;数据和算法匹配:并不是所有算法都能够实现可视化展示,所以必须通过该功能对系统算法进行合理映射,以此获得最佳效果。
(4) 数据层
数据层可以为其他层次提供资源支持,在该系统中数据资源主要包括本地、外地数据。其中本地数据库能够对导入的信息进行储存。
(5) 基础平台层
此层能够为系统提供软、硬件等基础设备,支持其他应用运行。其可分为服务器与开发环境等。
3.3 系统模式设计
在所提可视化提取系统中,设计模式分为客户端、逻辑端以及服务器端三个方面。
其中客户端可以对用户提交的数据进行可视化显示;逻辑端主要任务为处理业务规则;服务端则为客户端提供各类数据处理功能,减少用户等待时间。系统模式设计图如图1所示。

图1 系统模式设计图
4 仿真实验数据分析与研究
为证明本文构建的系统性能,利用Windows操作系统,在Canvas环境下进行仿真实验。在0至180数据量区间内,每次增多30个提取数据,对本文系统、文献[1]方法与文献[2]方法进行对比。
首先对三种方法的可视化长宽比性能进行仿真,结果如图2所示。
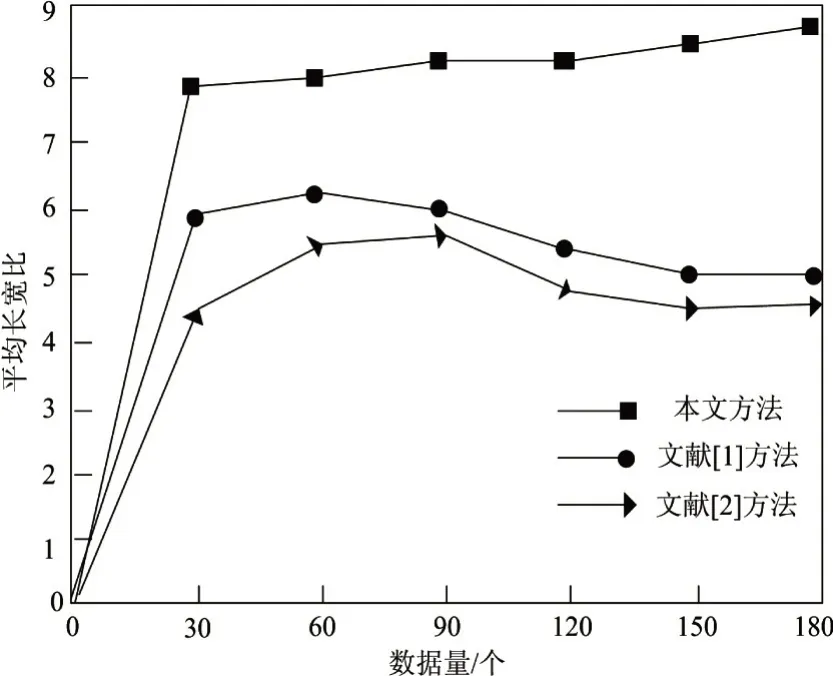
图2 可视化长宽比性能仿真结果
由于长宽比值越接近10,表明可视化提取效果越好,因此由图2能够看出,本文系统的可视化提取结果始终保持较高值,且随着数据量的增加并没有出现下降趋势。这是因为改进的鲸鱼算法自适应性较强,能够有效扩大系统容量,进而改善可视化长宽比。
其次,对三种不同方法的CPU占用率进行对比,占用率越小表明可视化提取连续性越高。结果如图3所示。
从图3可知,本文设计的系统CPU占用率较低,进而反映出数据提取的连续性较强。这是因为在系统设计过程中,经过一系列格式变换、数据排序等过程,提高系统处理数据的能力,使数据更加有序,获取更好的提取效果。
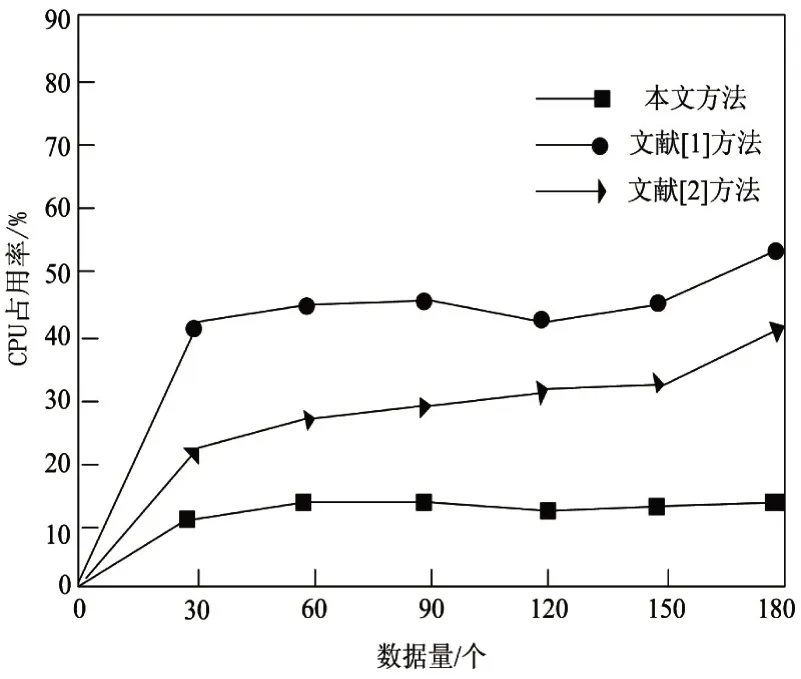
图3 空间数据CPU占用率对比图
最后测试该系统的抗攻击能力,向服务器中添加带有恶意脚本的数据,不同方法成功检测恶意数据的总量如图4所示。
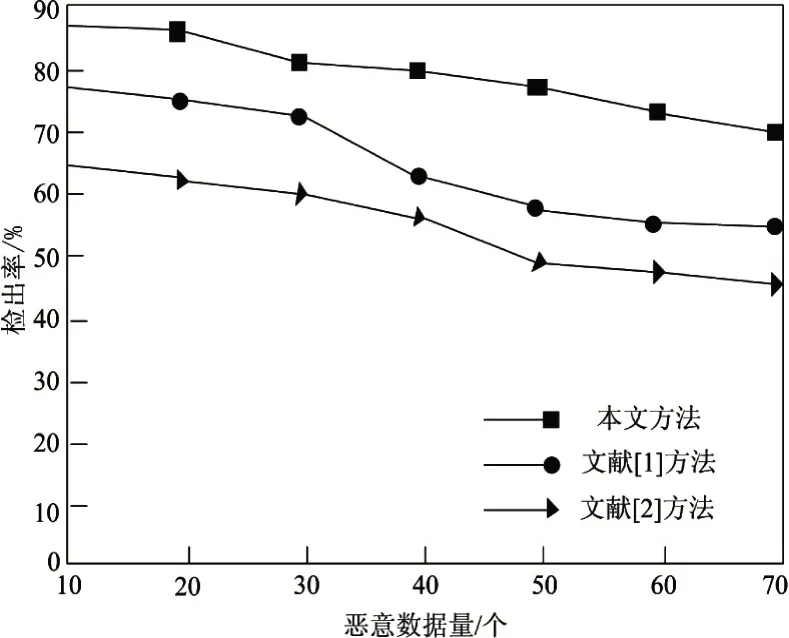
图4 不同方法下恶意数据检出率对比
结合如图4所示的检测结果,本文系统对于恶意数据的检出率最高。这是因为基于SOM的数据预处理方法不但能实现数据降维,还能有效减少恶意数据攻击,得到较为满意的数据预处理效果。
5 结束语
地理空间数据属于地理信息服务的基础,由于可视化效果不佳,影响了地理空间数据提取。为此,本文利用改进鲸鱼算法增强可视化效果,改善数据提取的连续性与安全性,进而提高用户使用效率。虽然该系统的仿真实验效果较好,但仍需做进一步改进。例如:系统中没有分析角色管理机制,这会加大安全风险。因此需设置角色权限,确保不同用户登录系统后不能查看与其身份不对应的内容。
猜你喜欢
幼儿100(2022年41期)2022-11-24
世界科学技术-中医药现代化(2022年3期)2022-08-22
北京测绘(2022年6期)2022-08-01
师道·教研(2022年1期)2022-03-12
北京测绘(2021年7期)2021-07-28
数学大王·趣味逻辑(2020年9期)2020-09-06
小天使·二年级语数英综合(2019年4期)2019-10-06
炎黄地理(2019年1期)2019-09-10
动漫星空(2018年4期)2018-10-26
科技传播(2011年8期)2011-08-15
