
双端可共享网络的多模态行人重识别方法
2022-07-13 01:57焦明海
计算机工程与应用 2022年13期
罗 琪,焦明海
东北大学 计算机科学与工程学院,沈阳 110000
行人重识别的任务主要是给定一个目标人物的图像,在已有的图像集中选出与目标人物身份一致的图像。行人重识别方法包括表征学习和度量学习,表征学习没有直接在训练网络的时候考虑图片间的相似度,而把行人重识别任务当作分类问题或者验证问题来看待。而表征学习在训练时会考虑到同一行人的不同图片间的相似度大于不同行人的不同图片间的相似度,从而学习出两张图片的相似度[1-2]。近年来,随着监控系统的普及,行人重识别技术也取得了很大的进展。为了实现全天候监控,使用可见光摄像头和红外摄像头分别采集白天的可见光图像和夜晚的红外图像。由于不同模态相机的波长范围不同,造成了较大的模态差异以及类内差异,导致两种模态之间存在显著的视觉差异,因此如何减小类内差异与模态差异,成为多模态行人重识别领域的重点和难点。此外,人物图像通常是在不同的环境下拍摄的,有距离和角度的不同,使得训练图像和测试图像的人物大小以及所占图像比例不同,进而影响重识别的准确率,因此本文提出了一种新的数据处理的方法,训练数据集得以增强,使得模型更具有鲁棒性[3-4]。
现有的多模态行人重识别研究中,提出了许多方法用于解决模态差异及类内差异。Wu等[5]提出一种域选择的子网络,可以自动选择样本所对应的模态,该方法将RGB图像和红外图像作为两个不同域的输入,使用深度零填充后放入上述网络中,使得所有输入都可以用单流结构来表示[5]。Dai 等[6]提出了一种新型的跨模态生成对抗网络(cross-modality generative adversarial network,cmGAN),利用深度卷积神经网络作为生成器,生成公共子空间下RGB 和IR 图像的表示,并利用模态分类器作为鉴别器,对不同的模态进行鉴别。此外,Wang等[7-8]通过模态之间互相转换的方法,使用生成对抗网络生成与输入图片相反的模态,使得多模态问题转换为单模态问题。Liu 等[9]提出的方法中将两个模态的图片分别输入到两个独立的骨干网络中,然后利用一些共享层将这些特定于模态的信息嵌入到一个公共空间中[10]。但上述方法对于网络训练增加了额外的成本,相比之下,Ye等[11]提出一种模态感知协作的中层可共享的双端网络,将Resnet50的第一层卷积层作为各自模态的浅层特征提取器,后四层卷积层作为共享网络,输入融合两个模态的浅层特征后继续进行特征提取,并使用三元组损失训练网络,该方法大大降低了训练难度,但上述方法鲁棒性不高,对于一些姿态不对齐的图片无法较好的识别。
为了弥补目前网络识别效率低的问题,本文在基于模态感知协作双端共享网络[11-13]的基础上,将共享特征提取器上的卷积层嵌入非局部注意力块(non-local attention blocks)[14],使得特征提取器可以提取到更多有效的特征,然后将两个特定模态的特征拼接后输入到共享网络进行特征提取,在进行距离度量时采用聚类损失函数[15]来代替三元组损失函数,使得网络在大规模数据集中的识别准确率更高。由于行人重识别的主要任务是识别行人的身份,并不需要关注图像是何种模态,故本文舍弃了模态识别器以及模态识别损失,使得训练复杂度降低,减少了额外的成本。同时为了增加模型的鲁棒性,提出一种预处理方法,使训练数据更接近真实数据。
1 基于双端可共享网络的多模态行人重识别方法
1.1 数据预处理
在实际场景中,不同的摄像头由于拍摄的角度和距离不同,导致得到的图片与真实的行人大小比例不符,且图片上半部分背景图像占比较大,成为数据集中的难样本,如图1(a)所示,数据集中没有足够的该类图片对网络进行训练,会使网络更多的专注于正常比例的数据,进而降低了重识别的准确率。本文针对上述问题对数据进行处理,使得训练图像更贴近实际情况,使样本更具有差异性,增加网络训练难度,使模型具有鲁棒性。

图1 图像处理前后对比Fig.1 Comparison before and after image processing
本文选择每个行人身份所对应数据集的1/4作为预处理的数据集,首先将数据集中的图像大小统一调整为144×288,然后将训练数据的大小调整为108×216,即长和宽缩小1/4,再将图像左右两侧各填充18像素,下方填充72像素,使得图像大小统一为144×288。最后将调整后的图像与原数据一起作为训练数据。处理后的图像如图1(b)所示。
经过该处理步骤后的图像很好的模拟了真实监控图像中行人位置不对齐及大小比例不一致的问题,使用预处理后的数据集增加了网络训练的难度,使网络更能适应真实场景。使用该方法对数据集SYSU-MM01 和RegDB进行重新构建,使用文献[11]提出的模态感知协作双端共享网络在构建的新数据集上进行实验,实验表明,在SYSU-MM01的rank-1识别率下降了7.46个百分点(all serach 模式)和7.53 个百分点(indoor serach 模式),在RegDB 的rank-1 识别率下降了5.79 个百分点(visible to thermal 模式)和5.82 个百分点(thermal to visible模式)。
1.2 网络结构
当前深度神经网络中的特征提取器都是基于卷积网络来提取特征,普通的卷积操作属于局部操作,无法捕获长范围的依赖,非局部注意力块可以将更大范围内有关联的样本点进行融合,有效地捕获长范围的依赖,其结构如图2 所示。本文将Resnet50 网络的后四层卷积层使用非局部注意力块代替,同时去除了模态分类器,让网络更多的关注于图像的内容而非模态,降低了训练复杂度。
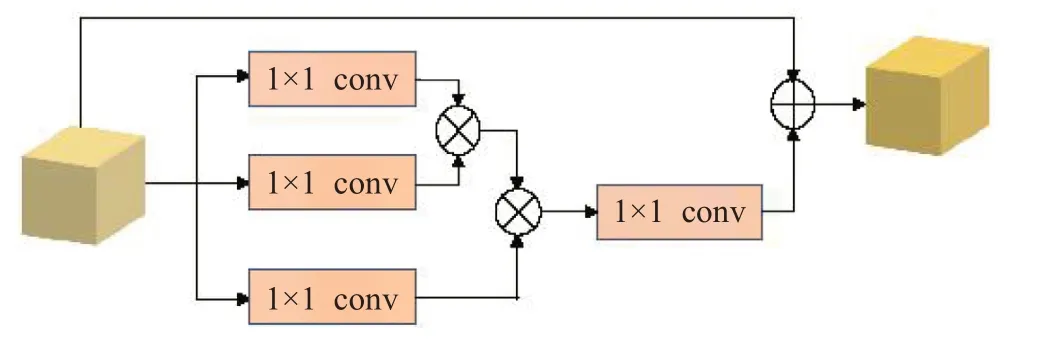
图2 非局部注意力块网络结构Fig.2 Network structure of non-local attention blocks
如图3所示,本文采用改进的Resnet50作为骨干网络,网络的前半部分有两个输入,分别输入可见光图像和红外图像,经过各自的卷积网络提取浅层特征后,将得到的两个特征进行拼接,输入共享网络进行深度特征提取,进行归一化操作后,使用聚类损失对特征进行距离度量;使用两个特定模态分类器辅助共享分类器的学习,同时为了便于分类器之间的知识转移,使用集成学习损失Le和一致性损失Lc来训练分类器。
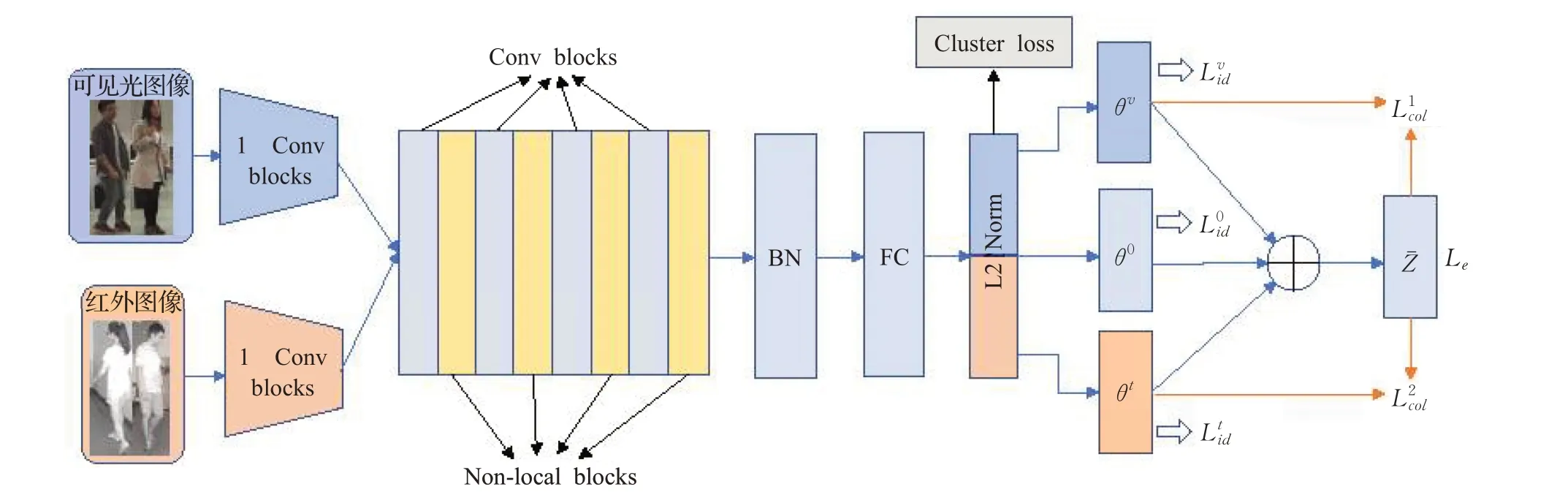
图3 网络结构Fig.3 Network structure
卷积操作在空间上只能处理一个局部区域,想要捕获长范围依赖关系只能依靠重复操作,逐步传递信号。非局部操作是以输入特征图中所有位置特征的加权和来计算某一位置的响应,以此来捕获深度神经网络的长范围依赖关系。在共享网络中对多模态图片进行特征提取,需要关注两种模态的图片中有关联的部分,即多模态图像的共有特征,使用非局部操作可以更高效地提取两种图像的共有特征。在训练过程中,每个模态输入相同数量的图片。首先选择P个人物身份,每个身份分别选择K个可见光图像和K个红外图像,不同模态的图像分别输入到相对应的网络通道内。整个训练过程的batch size大小为2P×K。
1.3 损失函数
1.3.1 聚类损失
目前的行人重识别任务中多使用三元组损失来进行度量学习,然而三元组损失仅考虑三个样本的距离和标签,没有充分利用更多的样本,同时为了使训练更有效,必须进行难样本挖掘,这个过程是耗时的,并且随着数据集变得更大,选择出的三元组数量会更多,使得训练复杂度提高。随着训练的进行,网络更多的关注那些难样本,而忽略大部分的普通样本。因此,本文使用聚类损失来替换三元组损失,该聚类损失基于均值来计算距离,使得损失函数不仅最小化难样本之间的距离,还间接地最小化所有类内图像之间基于均值的距离,从而提高训练效率。其原理如图4所示。
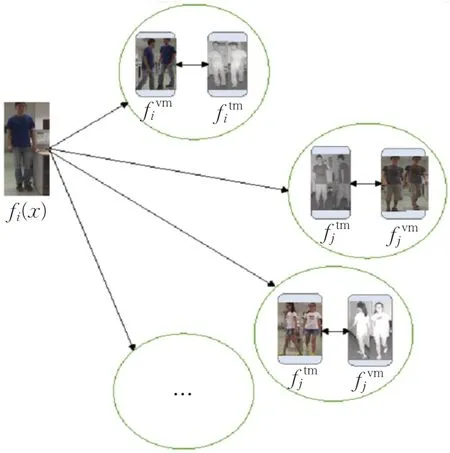
图4 多模态聚类示意图Fig.4 Schematic diagram of multimodal clustering
设f v(x) 、f t(x) 分别表示输入x经过网络中L2 Norm 层后得到的可见光图像特征和红外光图像特征,对于同一个批次中K个相同模态的样本,某一身份i的平均特征可表示为:



其中ω(t)是一个逐步上升的S性函数,随着训练次数的增加而从0增加到1。
2 实验结果及分析
2.1 数据集及评价标准
SYSU-MM01数据集[5]是一个大规模的跨模态Re-ID人物数据集,由中山大学校园内的4个普通RGB摄像机和2个近红外摄像机所采集。SYSU-MM01包含491个身份,每个身份出现在两个以上不同的相机中。数据集共有287 628 张RGB 图像和15 792 张红外图像。该数据集有固定的训练集和测试集,训练集共有32 451张图像,其中RGB图像19 659张,红外图像12 792张。SYSUMM01 数据集同时包含室内和室外环境下拍摄的图片,因此使用该数据集进行测试时可分为all serach和indoor search两种模式。
RegDB[16]是由双摄像机系统采集的小型数据集,包括1台可见摄像机和1台热敏摄像机。这个数据集总共包含412个身份,其中每个身份有10个可见光图像和10个红外图像。本文实验中分别将可见光图像和红外图像作为query,同时将另一模态的图片作为gallary 进行实验。
本文采用累计匹配特征(CMC)和平均精度(mAP)作为评价指标。CMC测量对应标签的人物图像在top-k检索结果中出现的匹配概率,mAP 用于度量给定查询图像在图像集中出现多个匹配图像时的检索性能。
2.2 实验内容
2.2.1 参数设置
本文实验的环境为:Intel Core i7-8700 CPU(3.2 GHz),显卡NVIDIA RTX 2080Ti,显存11 GB、内存16 GB,64位Ubuntu 16.04系统,Python 3.6、Pytorch 1.0.1。
本文将输入图片大小设置为288×144,进行数据增强时对原图片进行零填充10 个像素,再随机裁剪为288×144大小的图片,最后随机水平翻转。增强后的数据集大小与2.1节中原数据集大小一致。在每次训练中随机选取P=8 个身份标签,然后在数据集中随机选取对应身份的K=4 个可见光图像及K=4 个红外图像,即每个批次训练包含32 张可见光图像和32 张红外图像,总的训练批次大小为64。训练迭代次数为60,学习率在前10次迭代中由0.01递增到0.1,在第10到第30次迭代中保持为0.1,30 次以后为0.01。其余参数设置与文献[11]保持一致。
2.2.2 实验结果
本文的特征提取网络以Resnet50 为Baseline,为验证非局部注意力块(non-local)对于特征提取的有效性,使用SYSU-MM01 数据集,在相同Baseline 下进行了有无非局部注意力块的对比实验。由表1可知,非局部注意力块的加入使得网络在两种模式下的rank-1 准确率分别提升了0.17 个百分点和0.46 个百分点,mAP 分别提升了1.02个百分点和0.23个百分点,表明非局部注意力块的加入使得网络提取到更丰富的特征。

表1 非局部注意力块验证实验(SYSU-MM01)Table 1 Non-local attention block verification experimen(tSYSU-MM01)%
上述实验使用三元组损失函数训练网络,将三元组损失函数替换为聚类损失函数并分别在两个数据集上进行实验,实验结果如表2及表3所示,rank-1和mAP均有所提升,从而证明了聚类损失函数对于特征度量具有更显著的效果。

表2 聚类损失函数验证实验(SYSU-MM01)Table 2 Cluster loss functions verification experiment(SYSU-MM01) %
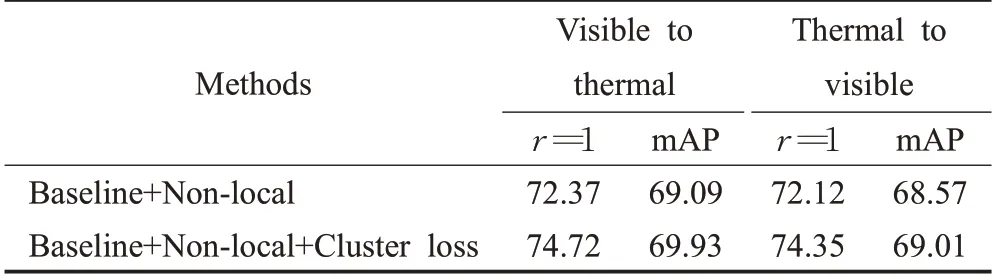
表3 聚类损失函数验证实验(RegDB)Table 3 Cluster loss functions verification experimen(tRegDB)%
2.2.3 算法比较
为验证本算法对于多模态行人重识别的优越性,本文将所提算法与近几年该领域的主流算法在SYSUMM01 和RegDB 两个数据集上进行了比较,其结果如表4 和表5 所示。本文算法的各项指标与对比模型(Zero-Padding[5]、cmGAN[6]、BDTR[17]、MSR[18]、DFE[19]、MACE[11])都有所提高。相比MACE 算法,在SYSUMM01数据集的all serach模式下,rank-1和mAP 分别提高了2.1 个百分点和3.26 个百分点,indoor search模式下两者分别提高2.53 个百分点和1.68 个百分点;RegDB 数 据 集 的visible to thermal 模 式 下,rank-1 和mAP 分别提高了1.05 个百分点和2.28 个百分点,thermal to visible 模式下两者分别提高1.15 个百分点和1.86个百分点。
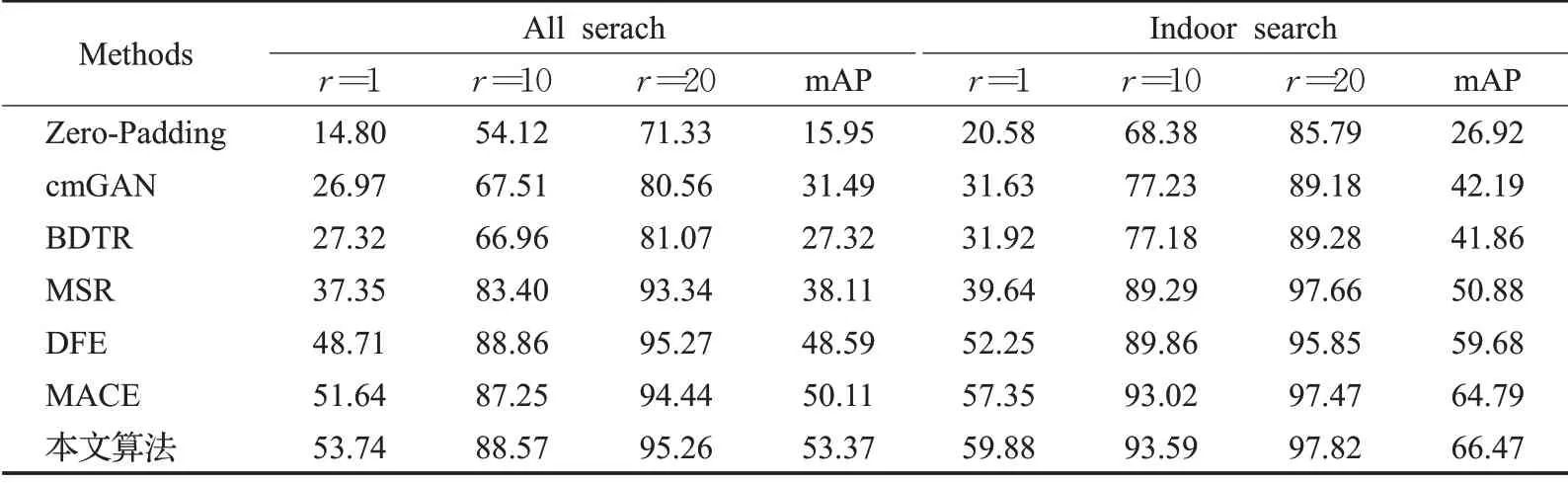
表4 SYSU-MM01上与主流算法评价指标比较Table 4 Comparison with mainstream algorithm evaluation indicators on SYSU-MM01 %
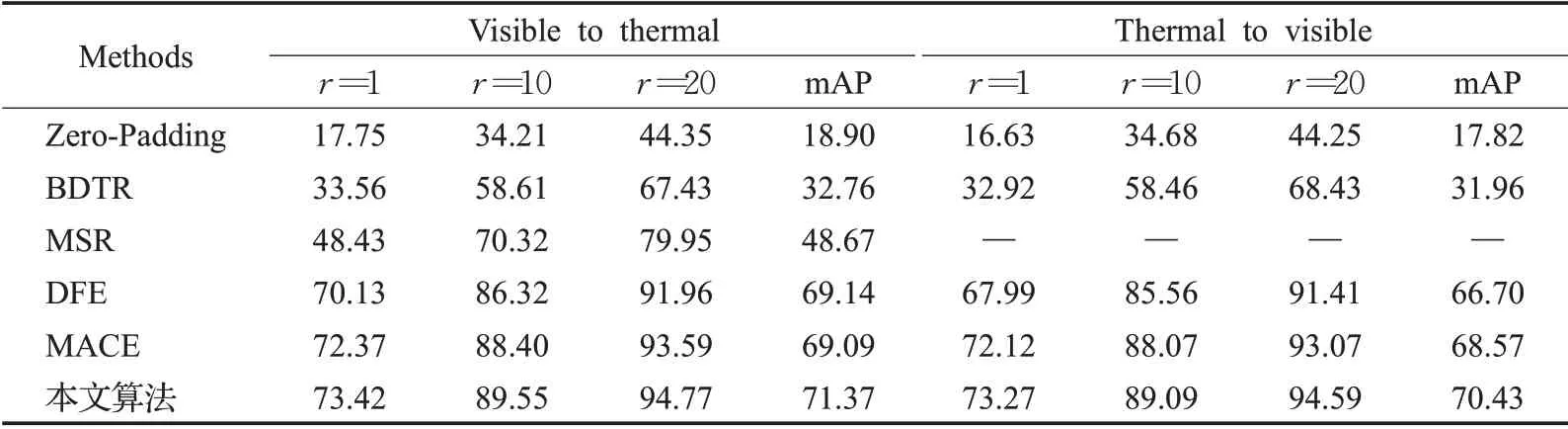
表5 RegDB上与主流算法评价指标比较Table 4 Comparison with mainstream algorithm evaluation indicators on SYSU-MM01 %
通过以上实验,证明了非局部注意力块的加入对于特征提取有更好的效果,聚类损失函数相比于三元组损失函数更有利于行人重识别网络的训练,从而验证了本文所提算法的有效性。
3 结束语
本文提出一种改进的基于双端可共享网络的多模态行人重识别算法。该算法使用嵌入非局部注意力块的Resnet50作为特征提取网络,有效提高了网络的特征提取能力。同时该算法使用聚类损失函数代替三元组损失函数进行度量学习,提高网络的重识别能力。多模态的行人重识别相比于单模态的行人重识别,其准确率较低,未来应在解决跨模态问题的同时寻求更高的准确率。
猜你喜欢
山西大学学报(自然科学版)(2021年1期)2021-04-21
意林(2021年5期)2021-04-18
北京航空航天大学学报(2019年9期)2019-10-26
五邑大学学报(自然科学版)(2019年3期)2019-09-06
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
扬子江(2019年1期)2019-03-08
计算机技术与发展(2018年12期)2018-12-20
电子制作(2018年19期)2018-11-14
小天使·一年级语数英综合(2017年6期)2017-06-07
