
基于RoBERTa的社交媒体会话中的讽刺检测模型
2022-07-13 01:52魏鹏飞廖文雄
计算机工程与应用 2022年13期
魏鹏飞,曾 碧,廖文雄
广东工业大学 计算机学院,广州 510000
基于文本的情感挖掘是近10年来备受关注的研究领域,其目的是研究如何从文本中获取用户对各种人或事物的意见倾向[1]。其中,面向社交媒体的讽刺检测是情感挖掘的一个重要分支和研究方向,主要研究如何采用自动化的技术,从社交媒体产生的数据中正确的识别讲话者的预期情感和信念。这项任务通常被看作是一项二分类任务(sarcasm vs.non-sarcasm),要么预测孤立的话语,要么预测添加了语境信息(会话语境、作者语境、视觉语境或认知特征)[2-5]的话语。本文重点研究带有会话语境信息的话语文本的讽刺检测任务。一般来说,如果不考虑语境,很难判断孤立话语的情感极性,如例1所示。
例1 A common thread exists though.Those attacking Glenn Greenwald all supported the regime-change Queen,Hillary Clinton.(尽管存在一个共同的主线。那些攻击格伦·格林沃尔德的人都支持政权更迭女王,希拉里·克林顿。)
例1 是来自于Twitter 平台的样本数据。意思是一部分人攻击了格伦·格林沃尔德,这些人都支持希拉里·克林顿。这仅仅是一种政治观点上的表达,有可能讲话者是对他人政治观点上的一种讽刺和否定。但是,从字面上人们无法判断其具有讽刺意味。因此,讽刺表达不一定复杂,但是需要在全面理解上下文以及常识知识的情况下进行判定,而不仅仅从字面上去理解,如例2所示。
例2 {“context”:[“TIL The saying ”breakfast is the most important meal of the day“ was originally coined in 1944 by a marketing campaign from General Foods,the manufacturer of Grape Nuts,to sell more cereal.”,“Fascinating to think a commercial product propaganda brainwashing campaign convinced an entire society the importance of a certain meal,for decades!”],“response”:“Yeah and all those nutritionists and doctors were in on it too!”}({“context”:[“早餐是一天中最重要的一顿”这句话最初是在1944 年由葡萄坚果制造商通用食品公司(General Foods)为销售更多谷类食品而创造的一项营销活动。”,“几十年来,一场商业产品宣传洗脑活动使得整个社会相信了其重要性。”],“response”:“是的,所有的营养师和医生都参与了!”})
例2 是互联网社交平台Reddit 的一段对话数据。其中,“context”是上下文语境信息,“response”是人们要对其进行讽刺检测的目标话语。单纯从目标话语“营养师和医生都参与了”来看,表达了比较积极的情感,但是,联合上下文语境去理解,实际上是对这种营销活动的一种消极/讽刺情感的表达。所以,如果不了解说话者的上下文语境信息,人们便无法准确地预测说话者的意图。因此,上下文的语境信息对于讽刺检测任务是很有必要的[6]。
为了更好地建模这种带有会话上下文的话语,本文提出了一种接收多输入的网络模型架构。首先,本文将上下文和目标文本分别输入到具有多头注意力机制的RoBERTa中提取句子特征;然后,通过AOA注意力机制学习两者之间的关注信息;最后,将得到的关注信息与句子特征进行级联,进行二分类结果预测。本文的主要贡献有以下几点:
(1)提出了一个基于RoBERTa 的社交媒体会话中的讽刺检测模型。
(2)采用AOA 注意力机制来学习上下文特征与目标特征之间的相关性。
(3)通过实验比较分析了模型各组件对分类精度的影响,有效地解释了此模型的有效性。
(4)在Twitter 和Reddit 这两个数据集上分别做了实验,实验结果解释了会话上下文的数量对讽刺检测的影响。
1 相关工作
1.1 独立话语的讽刺检测
早期研究中,许多工作单独考虑目标话语。传统方法中较多采用SVM[7-8]进行讽刺预测,弊端就是依赖于人工提取特征。随着深度学习的发展,特征提取也可以完全由神经网络完成。因此,许多研究人员将神经网络引入讽刺检测任务中,并取得了比传统的方法更好的结果。文献[9]使用基于预训练的卷积神经网络(CNN)来提取情绪、情感和人格等特征以进行讽刺检测。文献[10]采用卷积神经网络、长短时记忆网络(LSTM)和深度神经网络(DNN)的混合模型有效的提升了分类精度。文献[11]使用注意力机制(attention mechanism)对文本进行特征提取。
1.2 会话上下文讽刺检测
单纯的只在目标话语上进行建模的研究,往往预测起来更加困难。最近,越来越多的研究人员开始探索会话上下文在讽刺检测中的作用。文献[12]采用双向门控神经网络(BiGRU)来捕获语法和语义信息,并使用池化操作从历史推文中自动提取上下文特征,实验结果表明,此模型实现了当时最好的结果。文献[13]使用预训练BERT[14]对上下文和目标文本进行特征提取。
受文献[3,14-15]启发,本文提出了一种将RoBERTa与AOA注意力机制结合的模型用于社交媒体会话中的讽刺检测任务。有关讽刺检测任务更多的研究,可以阅读文献[16-17]。
2 数据集
本文使用的数据集来自于ACL2020(Second Workshop on Figurative Language Processing:https://competitions.codalab.org/competitions/22247)讽刺任务的比赛所提供的两大社交媒体平台Twitter 和Reddit 的数据。Twitter 数据集通过使用标签#sarcasm 和#sarcastic获取。Reddit数据集是self-annotated reddit语料库[18]的子集,该语料库包含130万个讽刺和非讽刺的帖子。表1 中是Reddit 数据集的一个讽刺样本,每个样本都是一段完整的对话的帖子,其中Ci是上下文中的第i句话语,T是要预测为讽刺或非讽刺的目标话语。具体来说,C2是对C1的回复,T是对C2的回复。Twitter数据集与表1类似。

表1 Reddit数据集的讽刺样本Table 1 Sarcasm example from Reddit
表2和表3显示了两个数据集详细的统计信息。训练集和测试集上两者相差不大,每段对话的话语数和话语的平均长度都给出了标准差信息,其中,Twitter 数据集中话语的平均长度比Reddit 数据集更长。对于Reddit 数据集而言,测试集中的话语数和话语的平均长度明显大于训练集,这可能会使模型的开发更具挑战性。

表2 Twitter数据集统计Table 2 Twitter dataset statistics

表3 Reddit数据集统计Table 3 Reddit dataset statistics
3 基于RoBERTa的会话中的讽刺检测模型

3.1 RoBERTa嵌入层

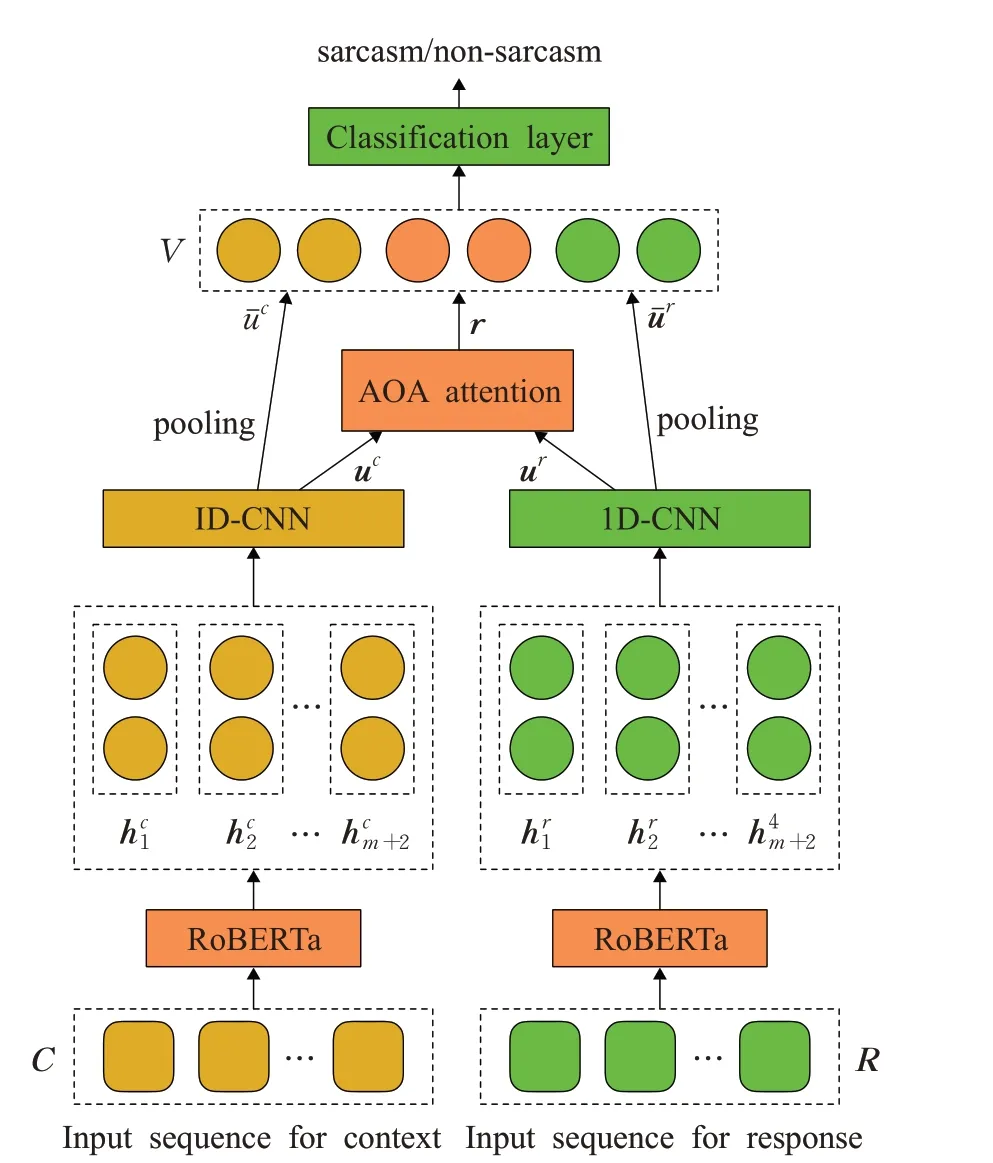
图1 基于RoBERTa的讽刺检测模型Fig.1 RoBERTa-based sarcasm detection model

3.2 一维卷积层和全局平均池化层
文献[21]提出了一种一维卷积神经网络应用于句子分类的工作,并且在实验结果上获得了不错的效果。如图2 所示,本文也使用这种1D-CNN 的网络结构,提取序列中多类型的局部特征,同时也可以实现一定的降维能力。
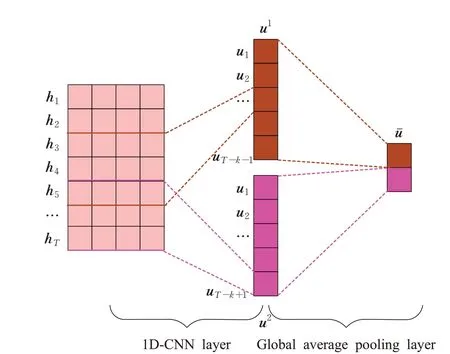
图2 一维卷积层和全局平均池化层Fig.2 1D-CNN layer and global average pooling layer



其中,uˉc∈ℝk和uˉr∈ℝk分别为context和response经过池化后的输出向量。
3.3 AOA融合层
为了更好地学习context 和response 之间的相关信息,本文引入了attention-over-attention(AOA)[22]模块。如图3所示,给定context的表示uc∈ℝ()m+2×k和response表示ur∈ℝ()n+2×k,首先计算一个交互矩阵I=ur⋅ucT,其中的每行或每列代表着context 和response 之间词对的相关性。然后,对行或列分别采用softmax 归一化处理,得到response相对context的注意力矩阵β和context相对response的注意力矩阵α。对β按列求平均,得到context-level的注意力表示βˉ∈ℝm+2,并与α做点乘,得到response-level 的注意力表示γ∈ℝn+2。具体的公式如下:

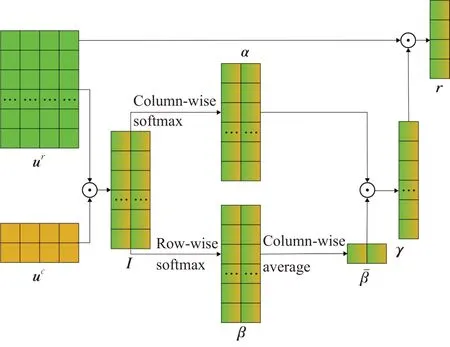
图3 AOA融合层Fig.3 AOA fusion layer
3.4 Classification输出层

3.5 模型训练
模型采用有监督的训练方式,损失函数采用交叉熵,同时使用L2正则和dropout防止过拟合:


4 实验
4.1 实验设置
在本文的实验中,代码编写采用Google 的Tensor-Flow(https://tensorflow.google.cn/)深度学习框架,版本2.3.0,语言为Python。实验环境采用了Google Colab提供的TPU。本文采用十折交叉验证进行模型选择,实验中超参数的设置和调整是根据实验的精度和损失手动调整的。通过广泛的超参数调优,实验的超参数如表4表示。
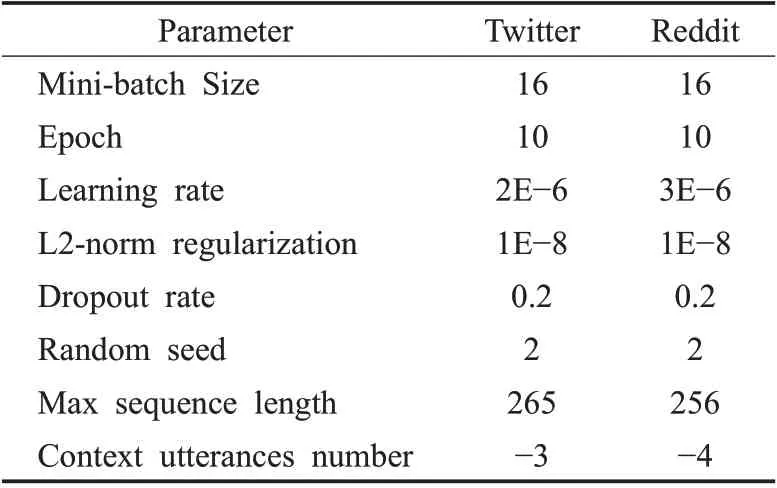
表4 实验参数Table 4 Experimental parameters
4.2 基准模型
本文提出的模型与以下基准模型进行比较。
(1)LSTM_attn:文献[23]提出了一种具有层次结构注意力的双重LSTM架构,其中一个LSTM建模对话上下文,另一个LSTM建模目标文本。
(2)BERT:文献[24]使用BERT编码句子信息,扩展了基于方面的情感分析方法,仅使用会话上下文中最后一句文本和目标文本作为输入。
(3)BERT+CNN+LSTM:文献[25]使用BERT 分别编码会话上下文和目标文本,然后将编码后的上下文信息经过CNN[28]和LSTM[29]层获取上下文句子语义信息,最后将上下文语义信息和目标文本语义信息输入到卷积层和全连接层构成最后的分类器。
(4)RoBERTa-Large:文献[26]将上下文和目标文本通过一个显式分隔符连接成一个句子作为输入,使用RoBERTa-Large微调模型预测结果。
(5)RoBERTa-Large+LSTM:文献[27]提出了一种双Transformer的模型架构,将获得的上下文和目标文本的表示,通过双向LSTM(BiLSTM)编码语义信息,最后使用softmax进行分类。
4.3 实验结果及分析
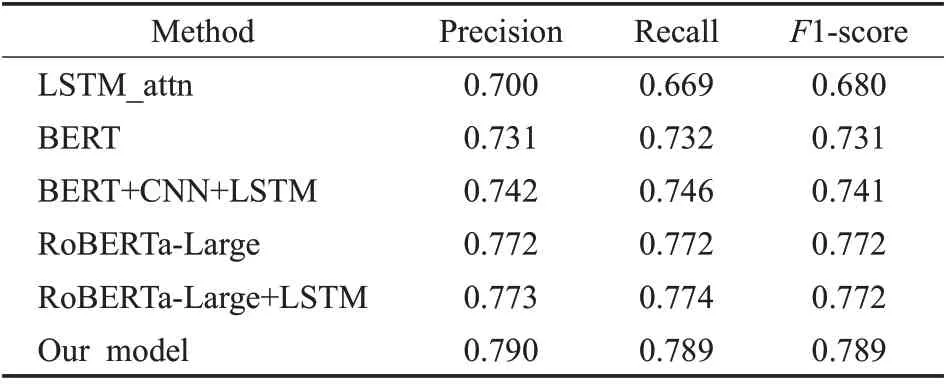
表5 Twitter数据集上的实验结果Table 5 Experimental results on Twitter dataset
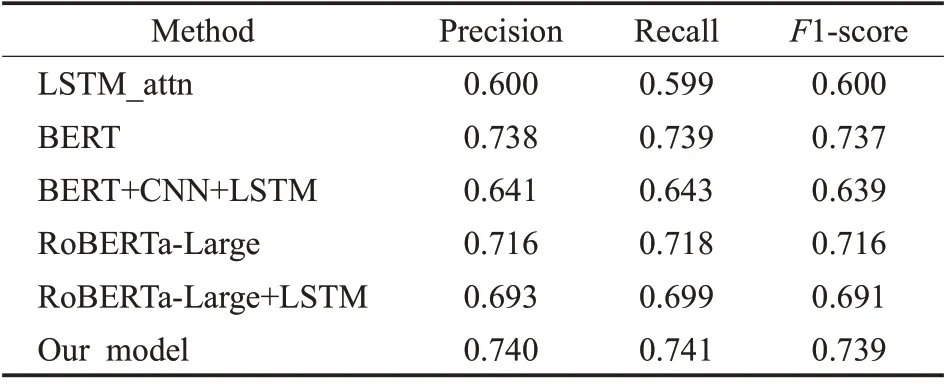
表6 Reddit数据集上的实验结果Table 6 Experimental results on Reddit dataset
在Twitter数据集上,基于迁移学习BERT和RoBERTa的模型效果有了大幅提升。BERT 采用BPE 的分词方法,可以解决一定的OOV问题,并且在大规模语料库上训练得到,在大多任务上泛化性能较好。RoBERTa 是BERT 的改进版,同属于Transformer 架构,预训练时采用更大规模的语料和更长的训练时间。在特征提取上有较大优势。RoBERTa-Large[26]模型比BERT[24]模型在Precision、Recall、F1-score 上分别提升了4.1、4.0、4.1 个百分点。BERT+CNN+LSTM[25]模型和RoBERTa-Large+LSTM[27]模型都加入了LSTM 提取序列语义信息,比未使用LSTM的模型在各指标上也有所提升。而在Reddit数据集上,引入了LSTM 的模型却在性能上有所下降。BERT+CNN+LSTM 模型[25]比BERT 模型[24]在F1-score下降了9.8 个百分点,RoBERTa-Large+LSTM[27]模型比RoBERTa-Large 模型[26]在F1-score 上下降了2.5 个百分点。另外,BERT模型[24]在Reddit数据集上性能超越了基于RoBERTa 的模型。本文将这些差异归因于Reddit 数据集中测试集的话语数和句子长度大于训练集造成的。具体来讲,模型是在较短句子的训练集上训练得到的,而应用于测试集上较长的句子上时,由于句子被截断会造成一定的句子信息的丢失,无法更好地建模句子上下文信息,使得模型泛化能力变差,模型的开发更具挑战性。
相比于表中的其他模型,本文提出的模型取得了更好的结果,特别是在Twitter 数据集上。本文的模型和RoBERTa-Large+LSTM[27]模型类似,都采用多输入,将context和response分别进行建模,但是本文加入了AOA融合模块,采用注意力机制捕获两者之间的相关语义信息,response 可以关注到重要的上下文context 词信息,context 也可以关注到相关的response 词信息,比LSTM能更好地建模单词级别的语义信息,特征捕获能力更强,能实现并行计算。实验结果也表明本文提出的模型比RoBERTa-Large+LSTM[27]在Twitter 数据集、Reddit 数据集上F1-score分别提升了1.7、4.8个百分点。
4.4 上下文语境分析
为了进一步解释上下文的数量对讽刺检测的影响,使用了不同的上下文数量在Twitter 数据集和Reddit 数据集上做了一些实验,实验结果如图4 和图5 所示。可以看到图中的曲线都是随着上下文数量的增加,其评价指标随之上升,然后随之下降。在Twitter 数据集上,当取context中最后3句话时,F1-score得分最高为0.789,而在Reddit数据集上,取context中最后4句话时,F1-score得分最高为0.739。这表明了上下文的话语数并不是越多越好,同时缺少一定的上下文信息也会对其性能产生影响。将其原因归结为:(1)response常常是对临近上下文对话内容的回答,较远的上下文句子可能与response并不太相关;(2)较多的上下文句子,融入了更多与任务并不相关的信息,使得模型学习更加困难;(3)response仅是对上下文的回复,从而缺乏一定的上下文语境信息,难以预测其是否为讽刺意味。因此,一定数量的上下文话语对讽刺检测任务更加重要。
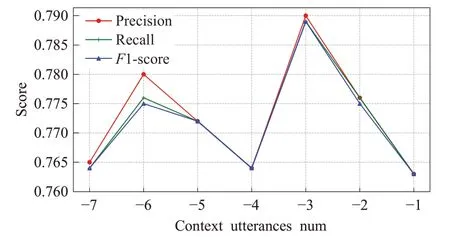
图4 Twitter数据集上的实验结果Fig.4 Experimental results on Twitter dataset
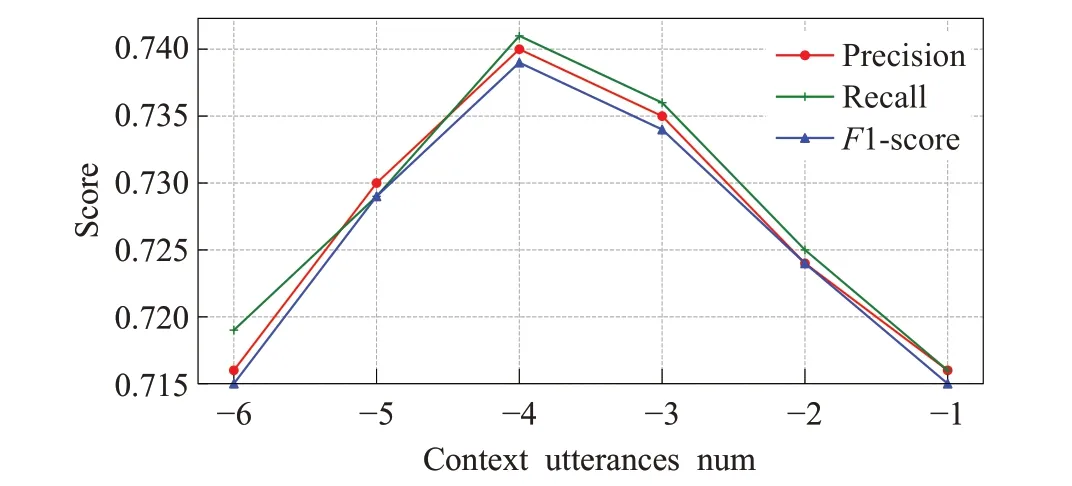
图5 Reddit数据集上的实验结果Fig.5 Experimental results on Reddit dataset
5 结束语
本文提出了一种基于RoBERTa的会话中的讽刺检测模型,该模型接收多输入,将上下文文本和目标文本分别编码得到词级别的上下文语义信息,然后与AOA融合模块提取的相关信息级联后进行讽刺结果的预测。实验结果表明,本文提出的模型在两个数据集上都获得了最好的效果,泛化能力强。
采用AOA 模块学习到了两者之间的相关信息,这是一种词级别的注意力学习方式,是否可以加入句子级别的注意力信息来提高检测结果。此外,虽然本文提出的模型检测率较现有模型有所提升,但并未完全实现高水平的检测率,因此采用何种方法能够更好地选出模型的最优参数,仍需进一步探索。
猜你喜欢
艺术生活-福州大学厦门工艺美术学院学报(2022年1期)2022-08-31
四川大学学报(自然科学版)(2021年6期)2021-12-27
河北画报(2021年2期)2021-05-25
计算机应用(2020年12期)2020-12-31
疯狂英语·爱英语(2020年9期)2020-01-07
疯狂英语·爱英语(2020年9期)2020-01-07
文苑(2015年9期)2015-09-10
时代英语·高二(2015年1期)2015-03-16
浙江人大(2014年6期)2014-03-20
浙江人大(2014年5期)2014-03-20
