
基于双卷积神经网络的人眼状态和眨眼识别算法研究
2022-07-12 04:24:00马海魁陈军峰
中国电子科学研究院学报 2022年5期
马海魁, 陈军峰
(1. 武警工程大学, 陕西 西安 710086;2. 武警警官学院, 四川 成都 610213)
0 引 言
激光眩目器是一种重要的非致命性警用装备,然而如何实时地改变对目标人眼的照射能量以达到可控的照射效果是其实际应用的一大难题。为解决这一问题需要对目标人眼进行准确定位并对眼睛的开闭状态进行准确的预测。
目前,人眼定位及状态检测算法主要有Hough[1]、灰度积分投影[2]、Gabor[3]、模板匹配[4]等融合类算法。这几种算法里,对已知形状的目标检测上,Hough算法具备不受图形旋转影响和受曲线间断影响小的优势,即便检测的目标有稍许的缺损或污染也能被正确识别,其不足之处是计算量非常大;灰度积分投影的优点是定位目标坐标的算法计算量较低,不足之处是自然条件下背景图像较复杂,准确定位目标的识别率会降低;Gabor小波变换的优点是适用于局部特征提取,该算法的鲁棒性优良,其不足之处是存在维数灾难和特征冗余的问题;模板匹配优点是用合成的目标模板对图像进行匹配,有效压缩了计算量,提高了定位速度和精度,不足之处是目标姿态变化大的情况下不能保证定位准确率等问题。
此外,文献[5]使用时空滤波和方差图来定位脸部和眼睛的特征点,用Lucas Kanade特征追踪器进行眼睛追踪,算法不足在于眨眼检测会受到头部运动的影响,导致准确率较大幅度下降。文献[6]使用眼角、眼睑和虹膜来跟踪眼球运动和眨眼,实现基于流的人眼跟踪,其检测准确率达到90%,其不足之处是在多姿态的检测中,特别是侧面的检测时准确率还不够高。文献[7]提出的眨眼检测系统可以根据眨眼持续时间,将眨眼分类为自主和非自主,检测准确率达到95.3%。其不足之处是在光照变化时检测准确率会下降。文献[8]提出凝视跟踪方法,使用两个基于外观的跟踪器,分别对眼睑和虹膜进行跟踪。用于眼睑跟踪的跟踪器能够快速识别眨眼,使其适用于实时应用,其不足之处是算法比较复杂。文献[9] 提出的基于面部标志点自动跟踪的眼睛眨动检测方法,实现了眼睛和眼睑轮廓的定位,使用 savitzky-golay (sg)滤波器对所获得的信号进行平滑处理,使用有限状态机根据持续时间检查假眨眼和真眨眼情况,其不足之处是算法模型复杂,运算量大。
针对上述算法的不足,本文提出一种基于双卷积神经网络的人眼定位与状态识别的算法,该模型基于两个卷积神经网络的联合训练,将眼睛轮廓和二进制掩膜作为输入来预测眼睛的状态。实验结果表明此算法对普通视频及红外视频中的动态目标人眼位置及状态预测均具有良好的效果,能够应用于智能激光眩目器控制系统。
1 基于双卷积神经网络的人眼状态和眨眼识别算法
算法整体框架如图1所示。视频流作为输入,首先,采用基于多任务级联卷积网络检测器进行人脸区域检测,利用得到的眉毛和眼睛坐标信息定位人眼;而后,通过计算其对应眼标坐标集上的凸包,对提取的两个眼斑进行二元掩码运算,得到二进制掩码;最后,把提取的眼斑及其相应的二进制掩码带入彩色人眼和掩膜人眼两个卷积神经网络,通过两个神经网络联合训练对眼睛状态(睁开或闭合)进行预测。算法框架记录每一帧眼睛状态,若眼睛在闭上若干帧后首次睁开,即认定为眨眼。帧数的阈值根据人类平均眨眼时间设定为100 ms~400 ms[10]。

图1 基于双卷积神经网络的人眼状态和眨眼识别算法框架
1.1 眼睛轮廓提取
眼睛轮廓提取过程如图2所示。本文采用基于多任务级联卷积神经网络(Multi Task Cascaded Convolutional Networks,MTCNN)的检测器[11],其特点是检测准确率较高且运算复杂度较低。当视频流输入初始,首先对每帧图像检测面部区域。当检测到图像中存在人脸时,卷积约束局部模型(Convolutional Experts Constrained Local Model,CE-CLM)将检测出图像中人脸的坐标,该卷积约束使用点分布模型(Point Distribution Model,PDM)来捕捉坐标的形状变化,并使用区域专家模型来模拟每个坐标的局部外观变化,以得到图像中人脸眼睛、眉毛、嘴唇、下颚线和鼻子等68个坐标位置,而后提取出与眼睛和眉毛相对应的坐标。利用此信息将眼睛图像定义为一个轮廓边界,具体定义为,将轮廓的上边界和下边界分别设置为相应的眉毛最上端坐标和眼睛最下端坐标;轮廓左边和右边的边界分别设置为眼睛的最左和最右边坐标。之所以这样设置,是考虑到在闭眼时,上眼皮和下眼皮的坐标几乎相同,如果只用眼睛的坐标来确定上界,那么提取的闭眼轮廓高度与睁眼轮廓高度相差较大,带入卷积神经网络后会造成特征提取不准确。同时由于PDM能够捕捉足够数量的变化坐标,使得检测器对不同角度的人脸和眼睛定位均有较高检测率,在实际测试中准确率达到98.7%左右,这也为后续人眼动作识别奠定了良好的基础。

图2 眼睛轮廓提取示意图
1.2 二值化掩膜生成
在提取眼睛轮廓后,通过在其对应的眼睛标坐标集使用凸包算法生成二值化掩膜。凸包内区域像素值设定为1(白色),凸包外区域像素值设定为0(黑色)。计算掩膜是由于其特征图简单,只需关注眼睛的开放程度,即可以准确地区分闭眼和睁眼。睁眼轮廓的掩膜像大部分像素值为1,相反闭眼轮廓掩膜大部分像素值为0。掩膜中的白色前景(仅眼睛区域)和黑色背景(掩膜的其他部分)之间的高度对比将使得卷积神经网络只关注眼睛的外部形状和轮廓,从而学习睁眼/闭合的真实映射关系。二值化掩膜生成示意图如图3所示。

图3 二值化掩膜生成示意图
1.3 人眼状态预测
在提取了眼睛轮廓及其相应的二值化掩膜后,把该信息输入到一个双卷积神经网络,即:将眼睛轮廓(RGB彩色图像)作为彩色人眼神经网络的输入,将同一眼睛轮廓的二值化掩膜作为掩膜人眼神经网络的输入。彩色人眼神经网络旨在学习整个眼睛轮廓的全局特征,而掩膜人眼神经网络则侧重于学习局部特征,如眼睛轮廓的形状、轮廓以及白色(眼区)像素和黑色(非眼区)像素的空间分布。鉴于其不同的结构,彩色人眼神经网络和掩膜人眼神经网络可以提取眼睛轮廓的不同特征。因此,本文将此两个网络并联共同训练用于眼睛状态分类。
1)彩色人眼神经网络。将大小为32×32的眼睛轮廓的彩色图像作为输入。本文对经典LeNet-5架构进行改进,使用了三个卷积层、三个最大池化层和两个全连接层。同时在每个卷积层之后使用一个最大池化层减少特征图的空间维度[12],最终可减少网络中的参数总数,防止过度拟合。彩色人眼神经网络结构如图4(a)所示。
2)掩膜人眼神经网络。将大小为32×32的二值掩膜作为输入。该模型结构与彩色人眼神经网络类似,只是在两个全连接层中的神经元数量减少了一半。这样做是为了减少过拟合,因为输入的二进制遮罩图像只有一个颜色通道,与相应的RGB眼罩相比,变化要小得多。因此,掩膜人眼神经网络的模型复杂度需要比彩色人眼神经网络低,以便在相同数量的数据上训练时学习相同质量的辨别特征。对于进入神经元的来自上一层神经网络的输入向量,使用线性整流激活函数的神经元会输出至下一层神经元或作为整个神经网络的输出。掩膜人眼神经网络结构如图4(b)所示。

图4 神经网络结构
3)双卷积神经网络。上述彩色人眼神经网络和掩膜人眼神经网络经过单独训练后,通过连接两个神经网络对应的顶部全连接层。在串联层的基础上增加一个全连接层和一个softmax函数,用于对闭眼和睁眼进行分类。训练时,固定预先训练好的彩色人眼神经网络和掩膜人眼神经网络的卷积层的权重值,并与联合模型的连接层和全连接层一起重新训练其顶层[13],同时定义综合损失函数训练两个网络模型[14]。整个双卷积神经网络的损失函数表示为
(1)
式中:Li和ψi分别是第i个模型的损失函数和调谐超参数权重。i=1代表彩色人眼神经网络;i=2代表掩膜人眼神经网络;i=3代表融合模型。参数ψ1、ψ2、ψ3根据经验分别设置为1、1和0.5。每个损失函数Li是交叉熵损失,其定义为
(2)
其中,
(3)
(4)
(5)
从图5中可以看到双卷积神经网络的三个softmax输出在训练时计算损失函数,而在预判时只使用集成模型的softmax输出。使用学习率为0.001的Adam优化器[15]对双卷积神经网络进行120次训练。本文采用丢弃正则化技术[16],同时在每个卷积层之后使用一个最大池化层减少特征图的空间维度[12],最终减少网络中的参数总数,防止过度拟合。
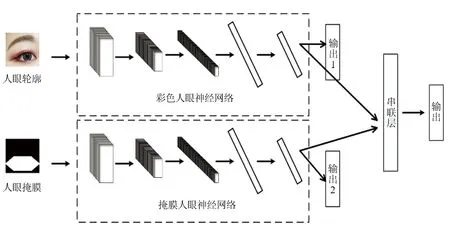
图5 双卷积神经网络模型架构
1.4 眨眼检测
从输入的视频流中,检测每一帧的人的眼睛是睁开还是闭上。当眼睛在闭上一定时间后再次睁开时,即定义检测到了眨眼。人类平均眨眼时间范围从100 ms~400 ms,对于一个30帧的相机,相当于3~12帧。因此,可以通过眼睛在再次睁开前保持闭合的帧数来判断是否眨眼。如果眼睛闭上的帧数超出了这个范围,即认定为无效眨眼。本文采用有限状态机来模拟检查真假眨眼。预先定义两个参数,即眨眼下限 0.1 fps和眨眼上限 0.4 fps(fps为视频摄像机的流媒体速率,单位是帧/s),这是有限状态机检测一个真正的眨眼所需的最小和最大的帧数。同时设置“闭合帧计数器”,用于计算眼睛闭合的帧数初始值为0。有限状态机初始状态为0,最终状态是状态3。当检测到闭眼时,会出现以下状态,如图6所示。
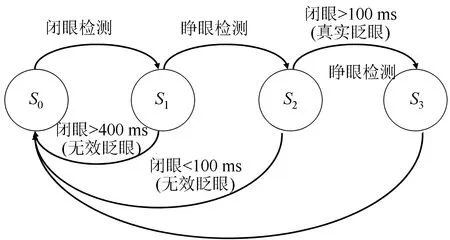
图6 有限状态机检测眨眼过程
1)有限状态机从状态0过渡到状态1。在这个状态下,每一帧的闭眼帧计数器都会递增1。如果闭合帧计数器超过眨眼帧数上限,则检测到一个无效眨眼,该状态被重置为状态0。闭合帧计数器也被重置为0。
2)当检测到睁眼时,有限状态机从状态1转换到状态2。如果闭合帧计数器小于较低的眨眼帧数,则检测到无效眨眼,状态被重置为状态0。闭合帧计数器也被重置为0。
3)如果闭合帧计数器大于较低的眨眼帧数,有限状态机从状态2转换到状态3。检测到一个真正的眨眼,状态被重置为状态0。闭合帧计数器也被重置为0。
2 实验及结果分析
本文采用Blinks数据集来训练、验证和测试眼睛状态分类模型。从Blinks数据集中抽取1 408个闭眼帧和1 369个睁眼帧,其中,70%的数据用来训练,20%的数据用来验证,10%的数据用来测试模型。在眨眼检测中,本文采用ZJU[17]、Eyeblinks8[18]和Talking Face[19-20]数据集进行检测,精度和召回率两个指标作为评估指标,得到比较结果。这三个数据集各有特点:1)ZJU 数据集由20个人的80个视频组成,每个人都有正面视图、向上视图、戴眼镜和不戴眼镜4个片段,分辨率为320×240(30帧),无面部表情,无头部运动。2)Eyeblink8数据集包含了面部表情、头部运动和低头看键盘,分辨率为640×480,平均长度5 000~11 000帧,由70 992个视频帧上的408个眨眼组成。3)Talking Face数据集采用显式与隐式属性的协同学习方法,形成具有个性化的头部运动轨迹,考虑到不同个体的运动特点,可以预测其眨眼信息,同时也可以生成更加逼真包含眨眼信息的人脸视频。
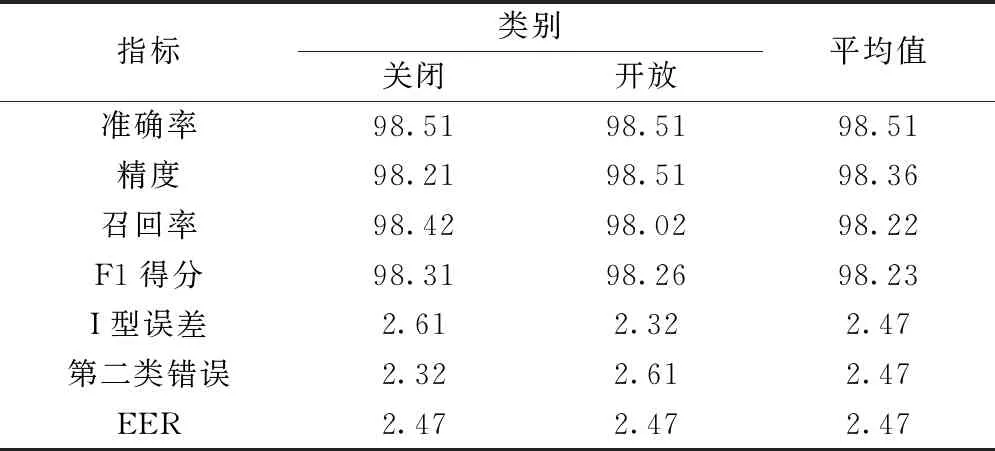
表1 双卷积神经网络的眼位预测指标 %
2.1 眼部状态分类实验结果
本文采用标准指标,如准确率、精确度、召回率、F1得分、第一类错误率、第二类错误率和等效错误率(EER)来评估提出的双卷积神经网络模型。图7和为双卷积神经网络模型的训练、验证精度和损失曲线。图8~图11所示的是精度-召回率和ROC曲线。表1列出在测试数据集上以眼睛为输入的双卷积神经网络的所有指标值,表2列出以整个面部图像为输入的相同指标。
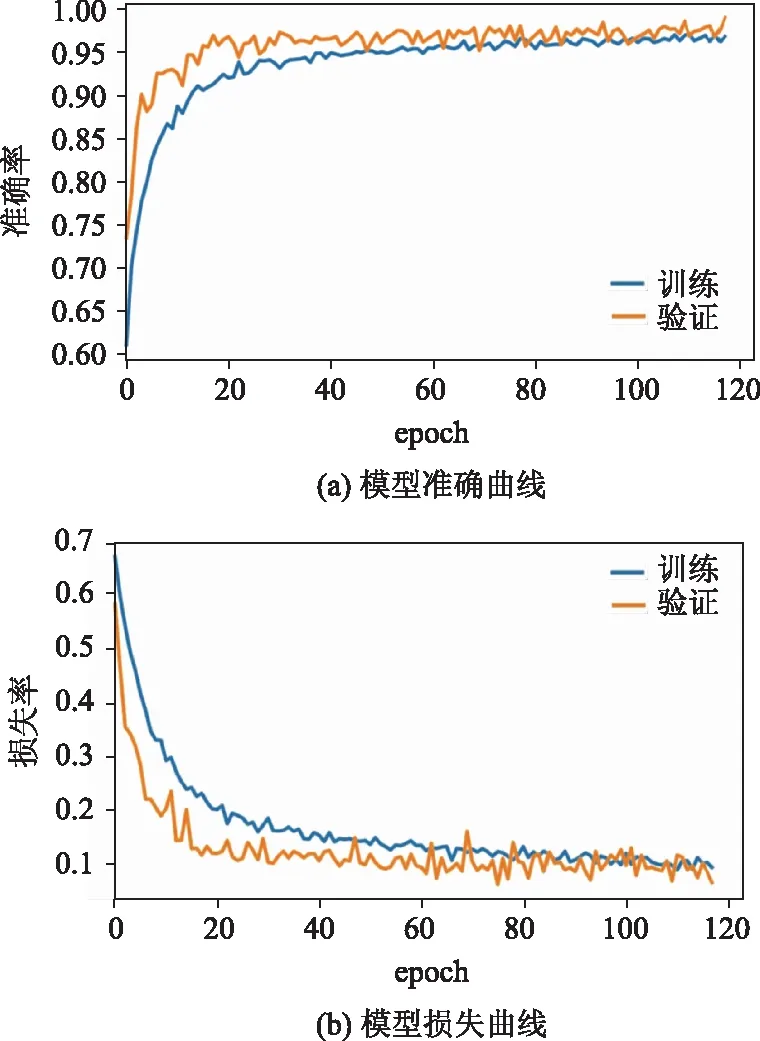
图7 双卷积神经网络模型的训练和验证准确性与历时的关系

图8 眼睛层图精度-召回率曲线
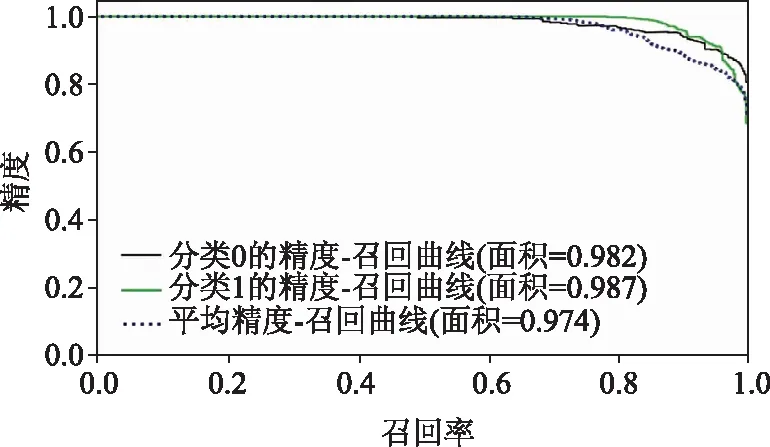
图9 人脸层精度-召回率曲线

图10 眼睛层ROC曲线
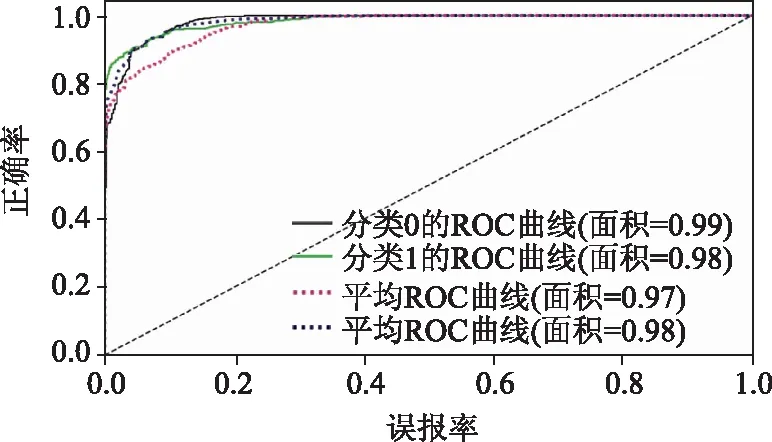
图11 人脸层ROC曲线

表2 双卷积神经网络的脸部水平预测指标 %
本文提出的双卷积神经网络与单个彩色人眼神经网络和掩膜人眼神经网络比较结果,以及本文算法与基于分割的模糊逻辑算法[21]、深度残差CNN算法[22]、HOG-SVM算法[23]比较结果如表3所示。可以看出,本文提出的双卷积神经网络模型在准确度和等错误概率方面优于其他基线模型,包括单个彩色人眼神经网络和掩膜人眼神经网络。
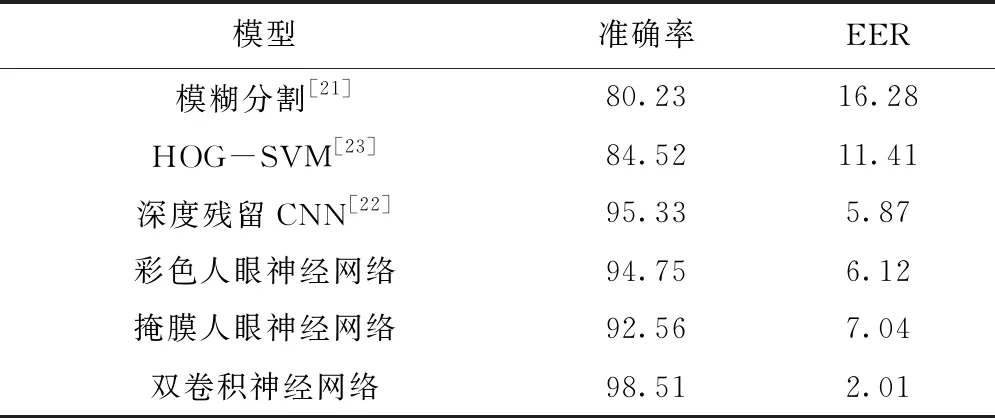
表3 普通图像算法比较测试结果 %
为进一步验证双卷积神经网络对于不同环境图像的效果,本文又采用开放的近红外眼睛图像数据集[23]上对其进行了测试,并与传统算法比较,结果如表4所示。可以看出,可以双卷积神经网络等效错误率为1.18%,在近红外数据集上优于其他模型。

表4 近红外图像算法比较测试结果 %
2.2 眨眼检测实验结果
通过比较标准测试集ZJU、Eyeblink8和Talking face上检测到的眨眼与真实眨眼比较眨眼检测算法,评估指标为精度和召回率,实验结果如表5所示。可以看出,本文提出的眨眼检测方法在精度和召回率方面优于其他现有方法。

表5 算法比较测试结果 %
3 结 语
针对动态人群人眼状态及定位问题,本文提出了一种基于并联架构的双卷积神经网络模型。实验表明,本文提出的算法模型复杂度低、运算量小,对自然环境中光线、角度变化具有更好的鲁棒性。其次,通过有限状态机在人眼眨眼检测的准确度方面要优于传统的haar加adaboost级联分类器。本文算法在实际中实现了27 帧/s的平均处理率,适用于对实时性要求较高的动态人眼目标检测场合。
猜你喜欢
课堂内外·小学版(低年级)(2023年6期)2023-04-29 00:44:03
导航定位学报(2022年5期)2022-10-13 08:35:28
中国体视学与图像分析(2021年3期)2021-11-24 02:20:44
制造技术与机床(2019年11期)2019-12-04 05:50:54
快乐语文(2019年9期)2019-06-22 10:00:38
中学生数理化·八年级物理人教版(2018年11期)2019-01-31 02:40:08
制造技术与机床(2017年10期)2017-11-28 05:20:18
优雅(2016年12期)2017-02-28 21:32:58
电影故事(2016年5期)2016-06-15 20:27:30
科技资讯(2016年21期)2016-05-30 18:49:07
