
基于多智能体深度强化学习的分布式协同干扰功率分配算法
2022-07-02 06:22宋佰霖史蕴豪
电子学报 2022年6期
饶 宁,许 华,蒋 磊,宋佰霖,史蕴豪
(空军工程大学信息与导航学院,陕西西安 710077)
1 引言
电磁空间是继陆、海、空、天的第五维战场. 在感知、决策、行动、评估的闭环电磁频谱作战过程中,决策是确保电子对抗效能发挥的关键环节,科学决策可最优化资源的配置利用. 近年,智能决策已经成为认知电子战的一个重要研究方向[1],遗传算法、博弈论、分布式优化等理论[2~4]被相继用于干扰参数优化、资源分配等领域,但这些方法都需要较多的先验参数信息. 强化学习作为不需要先验信息的机器学习方法,能以与未知环境交互的方式优化策略,目前在通信干扰领域已有初步应用,如文献[5,6]通过建立多臂赌博机模型来学习最佳干扰样式,文献[7]将对无线网络的干扰建模为增广马尔科夫决策过程,通过实验表明干扰方可通过与环境交互的方式学习到干扰成本、网络吞吐量等重要信息.
随着计算机运算和存储能力的大幅提升,深度学习在人工智能领域获得了巨大成功,其与强化学习相结合的深度强化学习技术在无人驾驶、视频游戏、云边计算服务、机器人控制等领域也展现了惊人的自主决策能力[8~13]. 同时,人工智能也不断驱动无线通信网络的智能化发展[14]. 当前利用深度强化学习解决高维空间的资源分配问题成为研究热点,主要研究成果可分为基于单智能体强化学习的方法[15~17]和基于多智能体强化学习(Multi-Agent Reinforcement Learning,MARL)的方法[18~22]. 在单智能体强化学习的方法中,智能体将所有设备或用户的状态和动作信息集中在一起,构成一个整体的状态和动作空间,通过集中式控制完成用户调度[15]、信道管理[16]和功率分配[17]等任务,但这种集中控制的调度方法不可避免地带来决策维度高、通信开销大、系统扩展性差等问题[23],一般适用于决策维度较低的场景. 在基于MARL 的方法中,每个设备或用户均是一个智能体,通过各智能体协同决策的方式完成任务,可减小神经网络的输入和输出维度[24]. 为进一步提高决策效率,文献[18]在频率切换控制和功率分配的完全协作多智能体任务中采用集中式的策略梯度方法,各设备使用全局状态信息进行训练,得到了较好的协作策略;文献[19]和文献[20]采用分布式深度Q网络,先通过中心节点集中训练,而后将模型参数分发给各基站,提高了业务需求量较大情况下的用户满意度和系统稳定性;文献[21]在分布式深度Q 网络中采用竞争双Q 网络结构,各用户设备依靠信息传递获得的全局状态信息进行随机博弈;文献[22]假设不同地区的通信链路属性大致相同,使每个智能体可共享一个策略网络,通过集中决策的方式提高了多用户无线蜂窝网络的总传输速率. 综上所述,现有关于通信干扰领域的决策研究相对较少且大部分在信号体制层级[5~7],而未来电子战的体系对抗模式亟需开展协同干扰资源分配的相关研究.
本文面向对抗组网通信场景下多干扰设备协同干扰中的干扰功率分配问题,提出了一种基于多智能体深度强化学习的分布式干扰功率分配机制(Multi-Agent Distributive Jamming Power Allocation,MADJPA),通过建立多干扰设备对多通信目标协同干扰的干扰资源分配模型,搭建多干扰设备集中训练与分布执行的决策网络训练架构,并融合强化学习方法和最大策略熵理论设计干扰功率智能分配算法,在满足不同干扰压制系数的整体干扰压制条件下,优化了干扰资源利用,提高了学习最优分配策略的收敛速度.
本文的主要贡献如下.
(1)为了适应对多通信链路的多干扰设备协同干扰任务,将协同干扰功率分配问题转化为完全协作的多智能体任务,建立了战场条件下非完全信息决策的部分马尔科夫决策过程(Partially Observable Markov Decision Processes,POMDP),在所设计的POMDP 奖励函数中,综合考虑了整体干扰压制任务的实现以及干扰功率利用的最优化问题,可以在不同干扰压制系数条件下自适应地调整合理的干扰功率分配方案.
(2)为了降低多干扰设备协同决策的维度,并缓解多干扰设备条件下决策网络训练环境的不稳定性,构建了适用于战场通信对抗场景的集中训练与分布执行的决策网络架构. 基于此架构,单个干扰设备在决策时不需要其他干扰设备的信息,只依靠本地信息即可完成干扰设备之间的协同决策,减少了干扰设备之间由信息交换带来的通信时延和通信开销,更契合战场环境对决策时效性的要求.
(3)设计基于多智能体深度强化学习的分布式干扰功率分配算法,为了加快各干扰设备对全局最优协同策略的学习,在强化学习目标函数中引入干扰策略熵项,使算法在优化过程中同时最大化累积干扰奖励和最大化干扰策略熵,并结合梯度下降自适应调整干扰策略的熵系数,适时地控制各智能体在未知环境中的探索能力,进一步提升算法收敛速度,在干扰压制系数较大的情况下可更精细地分配各干扰设备的干扰功率.
2 对抗模型
本文以战场对抗环境下干扰方对敌方前突飞机遂行压制干扰任务为例,如图1 所示. 当敌方飞机发现其所使用的通信链路被干扰后,可切换至区域内其他基站的通信链路继续通信. 干扰方通过指挥控制端对目标频谱进行侦察,指控端内部的智能引擎根据侦察情报完成干扰任务分配,下发至各干扰设备. 假设干扰方有N台干扰设备,干扰设备的集合为Ns={1,2,…,N},干扰设备均采用拦阻干扰样式. 敌方飞机可根据实际情况和自身通联状态与不同基站进行通信,受干扰后可重新选择通信链路,Ms={1,2,…,M}表示所有基站的通信链路集合,假设各链路信道为互不干扰、相互独立的等带宽正交信道.
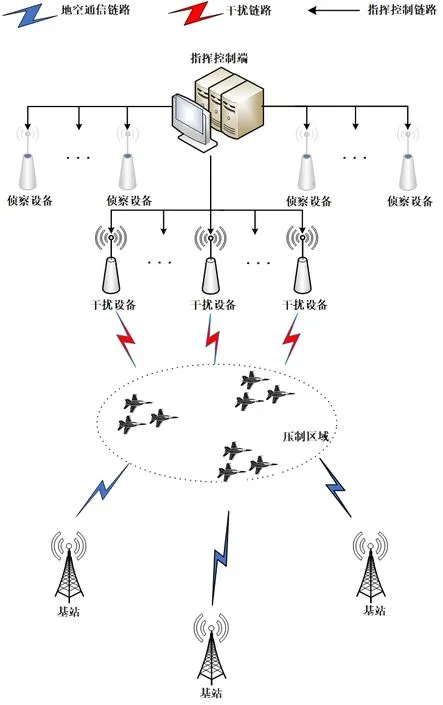
图1 对抗模型示意图
假设干扰方通过通信侦察和情报分析综合掌握了各链路的中心频率,获得了各链路的相对重要性指数:
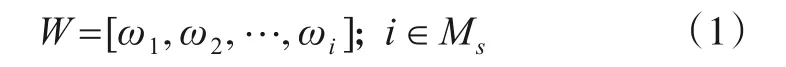
为尽可能破坏敌通联情况,形成对区域内的完全压制干扰,干扰方应在当前干扰资源条件下合理分配各干扰设备的干扰任务,通过各设备协同合作的方式对侦察到的所有通信链路都进行压制干扰,即达到对整体通信网的完全压制效果.
假设每部干扰设备可同时干扰U个目标,对不同目标的干扰功率需满足频分原则,即

其中,Pmax为干扰设备的最大辐射功率.
设t时刻链路i的基站发射信号功率为Pi,信道增益为Gi,用和分别表示干扰设备j分配至该链路的干扰信号功率以及相应的干扰信道增益. 考虑到一条链路可能受到不同干扰设备的干扰,链路i中飞机接收电台处的干信比(Jamming Signal Ratio,JSR)可表示为
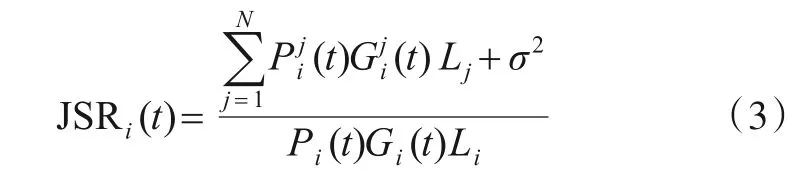
其中,σ2表示环境噪声功率;Li和Lj分别表示地空通信链路和干扰链路的传输损耗. 为便于分析不考虑信号的带外损失,假设路径损耗为自由空间传播损耗[25],损耗可表示为

其中,f为链路中心频率;d为信号传播距离.
为了定量描述通信干扰对通信接收机的影响程度,引入干扰压制系数. 当每条链路的干信比均超过干扰压制系数K,即满足式(5)时视为实现整体完全压制干扰.
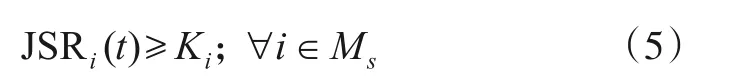
其中,Ki为链路i所对应的干扰压制系数. 各通信链路的干扰压制系数对于干扰方而言是未知的.
结合各链路重要性指数,针对干扰压制系数未知时,实现整体完全压制干扰的干扰功率分配问题可转为求解优化问题,如下所示:

3 基于MARL的分布式干扰功率分配算法
3.1 POMDP
式(6)、式(7)是非凸优化的NP-Hard 难题,尤其当同时存在离散空间和连续空间的待优化参数时应用传统数学优化方法难以求解. 本文采用深度强化学习(Deep Reinforcement Learning,DRL)方法解决该问题. 不同于一般的监督学习与无监督学习,DRL 作为不需要先验信息的机器学习方法,采用试错方式进行策略优化,即控制智能体不断与环境交互,根据环境给出反馈修正策略,目的是使得累积奖励期望最大,这种学习方法能够很好地处理本文研究的优化问题.
DRL 需要根据问题模型建立相应的马尔科夫决策过程,本文将多干扰设备的协同资源分配问题建模为完全协作的多智能体任务[26],考虑到战场条件下该任务的非完全信息决策属性,将其定义为POMDP,可用Γ=S,A,P,Ζ,O,r,N,γ表示,其中S为全局环境状态空间,A为动作空间,P为状态转移概率,Z为局部观测空间,O为观测函数,r为奖励函数,N为智能体数量,γ为折扣因子.POMDP过程可描述如下.

根据本文所研究的多智能体协作任务,将POMDP的元素具体定义如下.
(1)动作

其中,sign(·)为符号函数.
所有干扰设备的联合动作可表示为

其中,S为全局状态空间.
(3)奖励
MARL 中奖励函数可引导算法的优化方向,将奖励函数的设计与实际优化目标联系起来,算法性能可在奖励驱动下得到提高. 本文定义的奖励函数包含对整体的完全压制干扰奖励和干扰功率利用最优化奖励.
定义对整体的完全压制干扰奖励为

在多干扰设备协同任务中,所有设备共享一个奖励值,利用该公共奖励值驱动MARL 算法实现整体的完全压制效果和最优干扰资源利用之间的平衡.
3.2 集中式训练、分布式执行
多智能体协同任务中,各智能体的策略与其他智能体的行为和合作关系相关联,相关的学习算法通常可分为以下几种结构.
一是集中式学习. 将所有智能体的动作和观测进行联合,得到一个扩张的动作空间和观测空间,利用神经网络将所有智能体的联合观测动作映射到一个集中策略函数和集中价值函数,然后直接使用传统的单智能体强化学习方法,如图2 所示. 每个设备将自身状态上传至集中网络,由集中策略网络统一决策所有设备的策略. 此种学习方式会使得联合观测和状态空间随着智能体数量的增加而扩大,如本文假设干扰设备数量为N,通信链路数为M,由POMDP 可知集中策略网络输入维度为2MN,输出维度为MN. 随着干扰设备数量N增多,集中策略网络的维度增多,策略探索开销变大[23].

图2 集中式学习
二是独立式学习. 各智能体独立维护自身策略函数和价值函数,且各函数的输入只依赖智能体各自观测和动作,各智能体基于自身策略网络独立决策并独立训练自身网络. 此种学习方式中,策略网络的输入维度为2M,输出维度为M,与智能体数量无关. 但对于某个特定智能体而言,由于其他智能体学习过程中策略不断变化,容易造成环境非平稳,训练难以收敛.
三是值函数分解. 在独立式学习的基础上,将各智能体的值函数进行加和,以值函数近似的方式求解全局值函数,然后站在全局的角度去优化更新每个智能体的值函数. 此种学习方式能解决环境非平稳性,但只适用于离散动作空间,不适用于本文所研究的问题.
本文将集中式学习与独立式学习的优势相融合,采用集中式训练、分布式决策的结构,如图3所示.
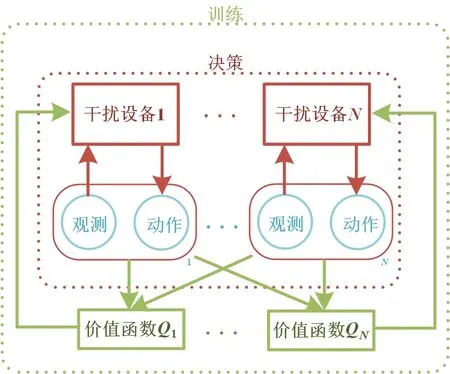
图3 集中式训练、分布式决策结构
“集中式训练”重点在于每个设备在训练时需将其他干扰设备的观测和动作(可视为全局状态信息)输入其评估网络,通过集中式地评估联合动作来增强各干扰设备的协调配合. 集中评估的方式可使得其他干扰设备策略相对已知,克服了策略变化造成的环境不平稳[27].“分布式决策”意为各设备在决策干扰动作时只需将各自的观测输入至各自的策略网络中即可完成协同决策,不再需要中心控制器集中处理各干扰设备的联合观测信息. 此时智能体策略网络的输入维度为2M,输出维度为M,相比于集中式学习,决策维度降低了M(N-1),而由实际经验看,决策维度太大是导致决策失败的重要原因之一,降低决策维度可提升方法的可行性.
3.3 MADJPA算法
在集中式训练、分布式决策框架下,为了提高每个智能体在未知环境中的探索效率,本文采用同时最大累积奖励和策略熵[28]的优化路线,在式(8)中加入策略熵项,即
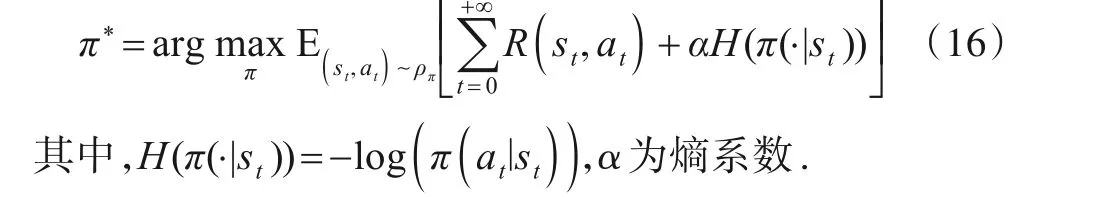
策略熵即策略分布熵,当策略熵较大时意味着策略的随机性较强,在未知环境中的探索能力较强,而适度的探索可实现对环境模型的充分学习,避免陷入局部最优.
为平衡智能体在未知环境中的探索和对现有知识的利用,设置熵系数α的优化目标函数[24],以梯度下降方式更新其值,熵系数优化目标函数为
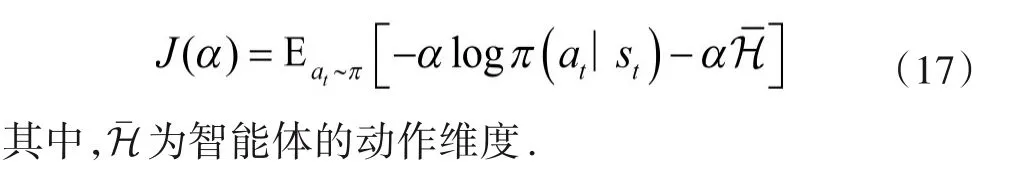
初始阶段,α值较大策略随机性也较大,探索效率较高;随着智能体对环境模型的不断学习,α自适应减小;当α下降至0 时,式(16)中无熵项,此时智能体的优化目标就变为传统的最大化累积奖励.
在递归求解最佳策略π*时采用的Q函数迭代式可表示为

本文用神经网络拟合Q函数和策略函数,并采用Kullback-Leibler(KL)散度约束来更新策略[29],即
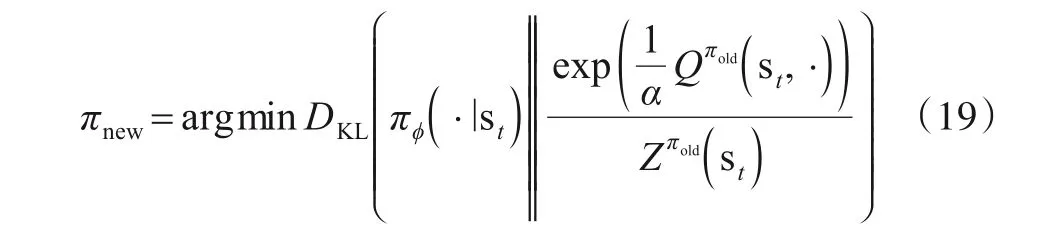
其中,DKL(∙)表示KL 散度约束;Qπold(si,·)表示原策略下的Q函数;Zπold(si)表示原策略的对数配分函数.
在各个智能体内部进行基于最大策略熵深度强化学习的策略优化,据此本文提出了基于MARL 的分布式干扰功率分配算法(MADJPA),图4 所示是MADJPA算法示意图.

图4 MADJPA算法示意图


此外,为了避免评估网络对动作Q值的过高估计,本文在评估网络中采用孪生网络结构[31],即评估网络内部有两个结构相同的神经网络,每次取两者输出较小的结果计算干扰动作的目标价值,故式(18)可改写为

利用孪生网络的输出计算联合干扰动作的目标价值为
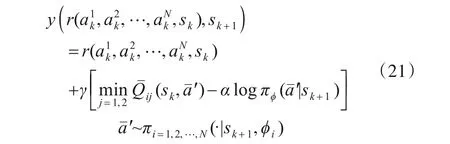
并更新孪生评估网络参数θi1和θi2,即
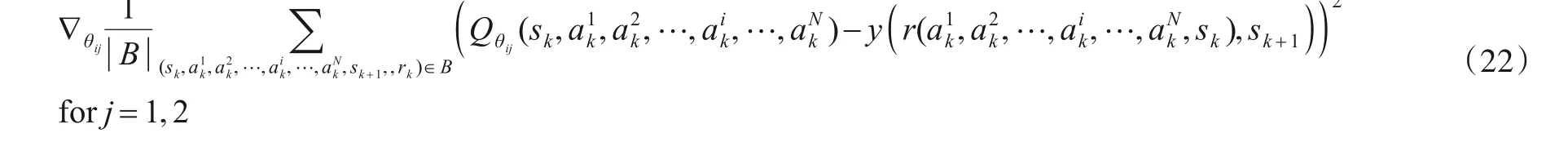
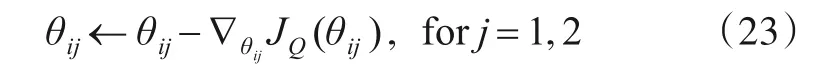
紧接着更新策略网络的参数ϕi,即

当训练完成后各干扰设备获得分布式干扰策略,执行任务分配时每个干扰设备仅依靠本地观测可完成决策. 分布式策略如图5所示.

图5 分布式策略
算法伪代码如算法1所示.

算法1 MADJPA伪代码输入:干扰设备数量N,设备编号i ∊{1,2,…,N};通信链路数M;干扰压制系数Kj输出:各设备干扰策略π*i,i ∊{1,2,…,N}开始:步骤1:初始化每个干扰设备的策略网络πi(zi,ϕi),以及孪生评估网络Qi1(s,a1t,a2t,…,aN t ,θi1),Qi2(s,a1t,a2t,…,aN t ,θi2),网络参数分别为ϕi,θi1,θi2;步骤2:初始化每个干扰设备的目标孪生网络Qˉi1(s,a1 t,a2 t ,θˉi2),网络参数分别为θˉi1,θˉi2;步骤3:初始化共享经验回放池CRB;步骤4:FOR each episode:初始化环境和状态;FOR each step t:t,…,aN t ,θˉi1),Qˉi2(s,a1 t,a2t,…,aN对每个干扰设备i:根据当前的观测zi t,利用策略网络选择干扰方案ait~πi(ait|zit,ϕi);得到各设备的联合干扰方案,执行当前干扰方案ait得到下一观测zi t+1和公共奖励rt;将所有干扰设备的经验(st,a1t,a2t,…,ait,…,aN t ,st+1,rt)存入公共经验回放池CRB:D ←D ∪{(st,a1t,a2 t,…,ai t,…,aN t ,st+1,rt)}当CRB内样本数量大于τ时,训练网络:从CRB中采样小批次样本B={…,(sk,a1k,a2k,…,aik,…,aNk,sk+1,rk),…}Length=batch_size对每个干扰设备i:计算干扰方案目标价值y(r(a1k,a2k,…,aNk,sk),sk+1)=r(a1k,a2k,…,aNk,sk)+γ ■■■min j=1,2 Qˉij(sk,aˉ′)-α log πϕ(aˉ′|sk+1)■■■aˉ′~πi=1,2,…,N(·|sk+1,ϕi)利用梯度下降更新孪生评估网络参数θi1和θi2,即Qθij(sk,a1k,a2k,…,aik,…,aN k )2∇θij 1|B∑|(sk,a1k,a2k,…,aik,…,aNk,sk+1,rk)∊B()-y()r(a1k,a2k,…,aik,…,aNk,sk),sk+1 for j=1,2 θij ←θij-∇θijJQ(θij),for j=1,2利用梯度下降更新策略网络参数ϕi,即∇ϕi 1 min Qθij(sk,aˉϕi(sk))-α log πϕi(aˉϕi(sk)|sk)2|B ∑sk ∊B()|aˉϕi(sk)~πi=1,2,…,N(·|sk,ϕi)ϕi ←ϕi-∇ϕiJπ(ϕi)柔性更新孪生目标网络参数θˉi1和θˉi2,即θˉij ←τ ∙θˉij+(1-τ)∙θij, for j=1,2 END FOR END For结束得到各设备策略网络π*i,i ∊{1,2,…,N}
4 算法计算复杂度分析和收敛性证明
4.1 计算复杂度

4.2 算法收敛性证明
对于本文算法的收敛性分析,给出下述定理.
定理 在联合策略集合Π中,当动作空间维度有限即|A| <∞,存在策略π∊Π,可收敛至最佳联合策略π*,且有Qπ*(st,at)≥Qπ(st,at),∀π∊Π.
证明 将策略迭代优化分为策略评估和策略改进两个阶段,在策略评估中,定义带熵奖励为

将式(18)重写为
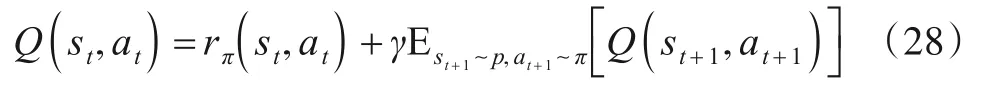
根据贝尔曼迭代公式有

令πi表示第i次迭代时的策略,可知序列{Qπ1,Qπ2,…,Qπi}是单调递增的,由于奖励和熵有界,故该序列可收敛于某个最佳策略π*.
在策略改进中,令式(19)中πnew(∙|st)为

对所有的π∊Π,π≠π*易知Jπold(πnew(∙|st)) ≤Jπold(πold(∙|s)),同样利用策略评估中的迭代证明,可得对所有的(st,at)均有Qπ*(st,at)≥Qπ(st,at). 可知Π中其他策略的Qπ低于收敛后的策略,因此π*为Π中最优.
5 实验仿真与分析
5.1 仿真参数设定
仿真场景中,设干扰方指挥控制端下属3个干扰设备,每个干扰设备可同时干扰2 个目标. 在敌任务区域内有若干地面通信基站,为敌机提供5 条可用的通信链路,假设每条通信链路有相同的干扰压制系数. 表1是经过通信侦察情报分析处理后获得的各链路综合情报信息. 为实现对敌机群任务空域内的整体完全压制干扰,在计算信号传播路径损耗时,均以各基站中与飞机电台最近的距离为通信信号的传播距离,以干扰设备中与飞机电台的最远距离作为干扰信号的传播距离.
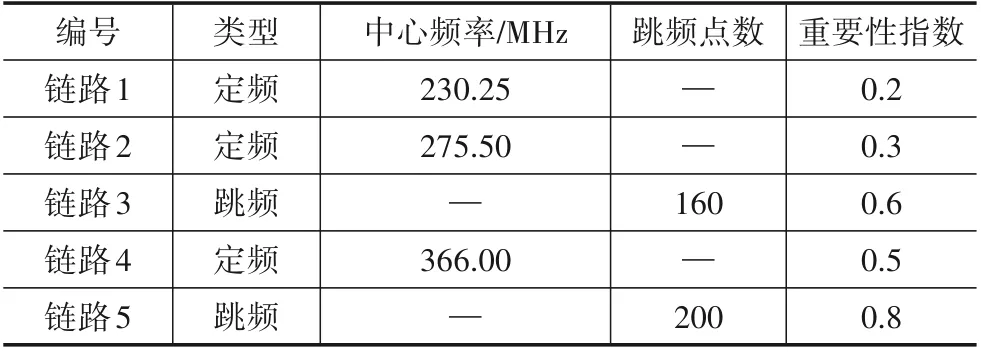
表1 各通信链路信息
实验及网络模型参数如表2.
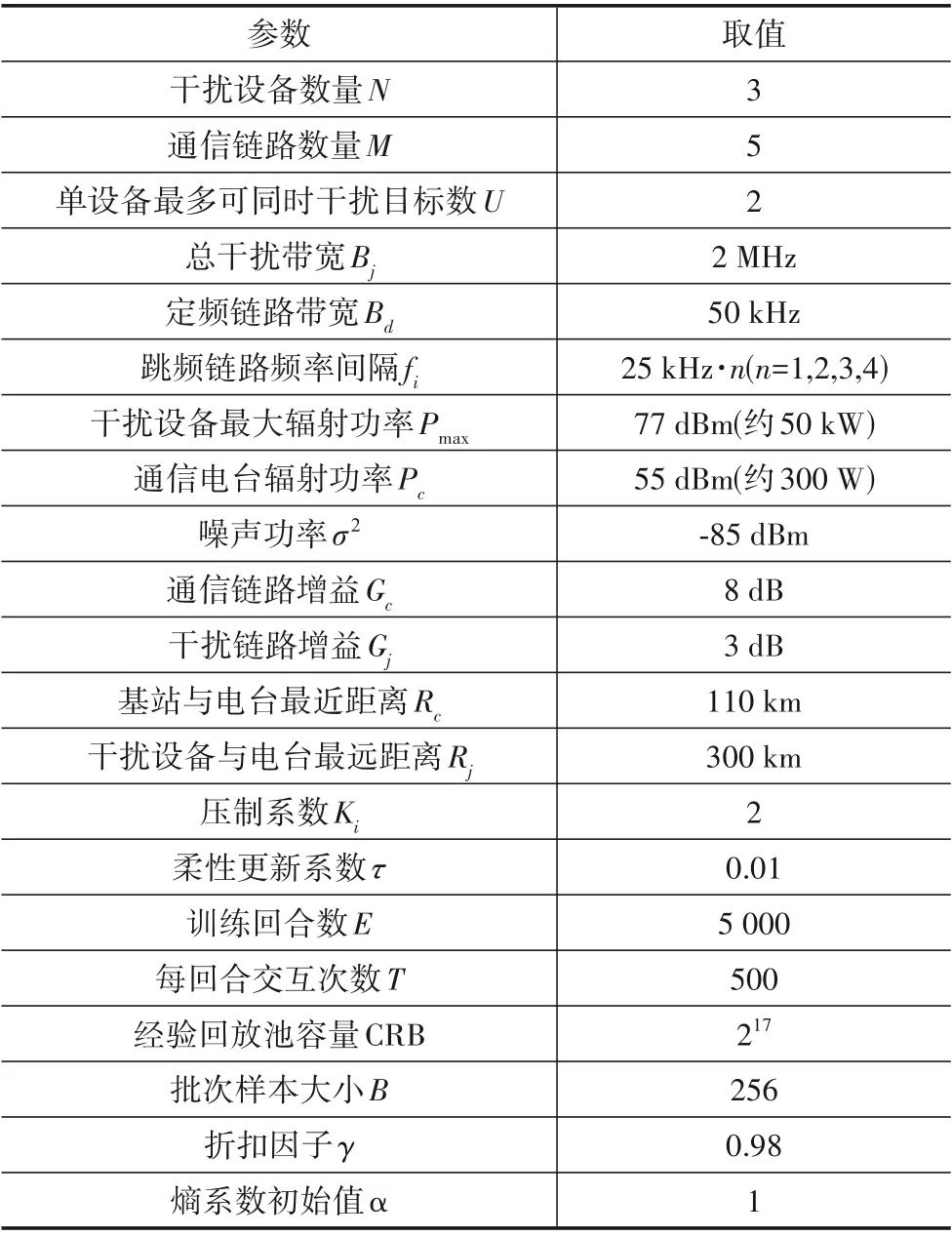
表2 实验及网络模型参数
智能体的策略网络、评估网络、目标网络的隐藏层均为3 层全连接网络,每层神经元分别为256,128,64,网络优化器均采用Adam,且策略网络的学习速率为0.000 1,评估网络和目标网络的学习速率为0.000 3,激活函数为Relu,策略网络输出层为tanh.
5.2 实验结果分析
在相同实验条件下,将本文所提的分布式算法MADJPA与文献[22]中的算法进行比较,文献[22]采用的是基于深度确定性策略梯度的集中式分配策略(Deep Deterministic Policy Gradient Centralized Alloca⁃tion,DDPGCA). 此外为定性分析最大策略熵对算法性能的影响,增加本文算法优化函数中不含熵项的MADJPA-No Entropy 算法(记为MADJPA-NE)的消融对比.
首先分析3 种算法对所有通信链路的整体完全压制效果,考察各算法对协同策略的学习能力.
图6(a)和(b)是压制系数为2 时3 种算法对所有通信链路的整体完全压制效果. 从图6(a)的学习曲线可以明显看出分布式的MADJPA 和MADJPA-NE 算法学习速度均相对更快,在300~500回合左右整体完全压制成功率有较大提升,其中MADJPA 最高整体压制成功率可达85%以上,MADJPA-NE 由于只追求最大化累积奖励而未同时最大化策略熵,探索略有不足,容易陷入局部最优,最高整体完全压制成功率不如MADJPA. 而集中式的DDPGCA 初始阶段由于各设备的联合干扰动作空间较大,探索的时间较长,学习过程波动性较大,加之DDPGCA 采用的深度确定性策略本身对未知干扰动作探索效率不够,最终整体完全压制成功率在70%左右. 可见将各干扰设备的干扰动作空间联合起来集中决策,会增加决策的复杂度,无论是从收敛速度还是收敛后的效果看,都不如分布式策略,并且加入最大策略熵准则后,分布式策略的整体性能可得到一定提升.

图6 整体完全压制效果
此外,图6 中阴影部分表示根据500 次重复实验结果计算的波动范围,图6(a)和(b)均表现出DDPGCA 整体振荡幅度较大,而MADJPA 和MADJPA-NE 学习过程相对稳定,波动性较小,其原因在于DDPGCA 作为集中式策略,是在更高维的扩张动作空间进行策略探索和优化的,高维空间会增加决策困难度,而MADJPA 是分布式策略,其决策维度取决于单个设备的动作空间,维度相对更小,学习效率更高.
下面对比算法对各链路的压制效果. 图7是3种算法对各链路的压制成功率曲线. 从图7 可知,3 种算法均能优先干扰重要性指数相对较高的链路5 和链路3,然而对于重要性指数较低的链路1 和链路2,DDPGCA的压制率不高,相较而言,其他2 种算法能更好地协调各设备的干扰功率分配,各链路的压制成功率均较DDPGCA 有所提升,表明分布式的MADJPA 算法更有利于协同策略的学习. 此外,同样由阴影部分可知分布式算法的学习过程更平稳.
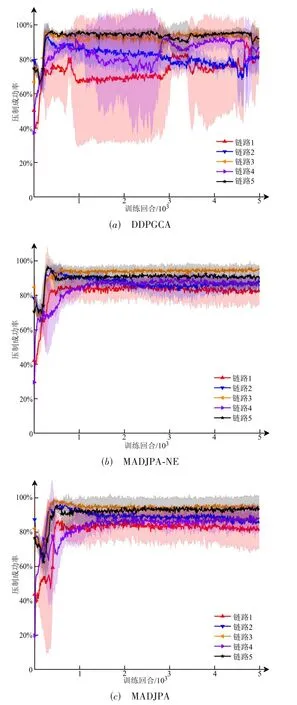
图7 3种算法对各链路的压制成功率曲线
为考察各算法在实现整体完全压制的同时能否尽量减少资源利用,对比了3 种算法对所有链路分配的总干扰功率,结果如图8 所示. 当3 个干扰设备额定最大功率和为81.2 dBm,3 种算法均能一定程度地减少资源利用,MADJPA 算法最终分配给各链路的干扰功率为80 dBm 左右,相比于全功率干扰节省了一定的干扰资源,同样也比DDPGCA 算法更节省干扰功率.战场环境下,在压制敌方的前提下减小自身辐射功率可减轻对己方通信的影响,也可避免功率过大暴露自身位置.
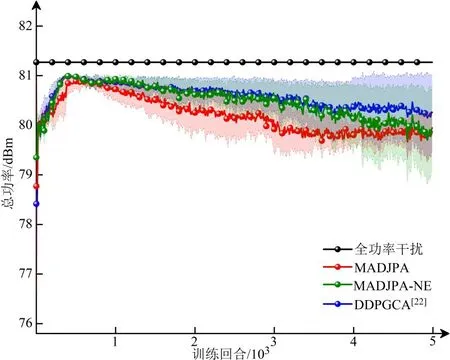
图8 分配的总干扰功率对比
最后对比了不同干扰压制系数条件下各算法能达到的最高整体完全压制成功率,如图9 所示. 当压制系数变大时,对相同目标压制干扰所需的资源更多,在有限资源条件下需要更合理更精细地协调各干扰设备的干扰功率分配. 图9 中随着压制系数上升,3 种算法的整体完全压制成功率都呈下降趋势. 其中压制系数为2时,MADJPA 整体完全压制成功率比DDPGCA 高出12.5%;当压制系数为4 时,相对地MADJPA 可高出16.8%. 在压制系数较大的条件下,集中式算法分配各设备干扰资源的效率较低,原因在于以单智能体集中决策的形式造成了维度更高的干扰动作空间,难以协调各干扰设备的任务调配,而分布式算法通过多智能体协作的方式降低了各设备决策维度,通过全局信息训练各设备策略网络的方式可更好地调度各设备的干扰功率,分布式算法的协同资源分配能力相比于集中式算法表现较优.

图9 不同压制系数的整体完全压制成功率
6 结论
针对通信组网对抗中的协同干扰功率分配问题,本文基于多智能体深度强化学习提出了一种新的分布式干扰功率分配算法. 算法通过构建完全协作的多智能体任务,在集中训练、分布决策的框架中将各干扰设备分别作为一个智能体,在训练时共享全局信息,并利用最大策略熵准则加速智能体间协同策略的学习. 相较于集中式的分配算法,本文提出的分布式算法收敛速度更快,学习过程更稳定,且干扰效率高于集中式算法.
猜你喜欢
湖南电力(2022年3期)2022-07-07
移动通信(2021年5期)2021-10-25
空间科学学报(2020年3期)2020-07-24
电子制作(2019年20期)2019-12-04
无人机(2018年1期)2018-07-05
制导与引信(2017年3期)2017-11-02
科技创新导报(2016年27期)2017-03-14
雷达与对抗(2015年3期)2015-12-09
弹箭与制导学报(2015年1期)2015-03-11
汽车电器(2014年5期)2014-02-28
