
基于支持向量回归与LSTM的城市PM2.5预测
2022-06-29 09:47尹博文张亚娟王晓芳张素琪
河北工业大学学报 2022年3期
尹博文,张亚娟,王晓芳,张素琪
(1.河北工业大学 人工智能与数据科学学院,天津 300401;2.天津商业大学 信息工程学院,天津 300134)
0 引言
城市PM2.5浓度反映地区的空气污染程度,其含义是某地区空气中细颗粒物含量,影响其变化的因素主要包括风速、湿度及NO2、SO2浓度等。2012年,中国开始按照新的《环境空气质量标准》开展PM2.5监测并发布数据。通过科学的手段对PM2.5值进行准确预测可以指导人们生产生活,更能提醒环保部门及时进行污染防治[1]。
2009 年Wang 等[2]通过自回归综合移动平均值(ARIMA)线性模型方法对洛杉矶市PM2.5进行了有效预测;2010年陈俏等[3]将支持向量回归与其他机器学习方法进行对比,说明了支持向量回归(SVR)在城市PM2.5预测中的优势,同时通过对简单核函数以及模型参数分析,得出不同核函数和参数直接影响预测准确度的结论;2012年Yao等[4]利用人工神经网络进行了多源PM2.5的估计,结果表明该方法较多元回归方法显著提高了预测准确度,但是在PM2.5值较高时,预测误差出现明显的上升;2013年白鹤鸣等[5]利用BP神经网络有效预测北京市区空气污染指数,但是该模型呈现出训练时间相对较长、结构较为简单难以应对复杂变化等问题。2015年Zou等[6]利用粒子群算法优化的SVR对仪器故障进行了回归预测,较优化前模型获得了更好的结果;2016年迟恩楠等[7]利用小波和乘法混合核函数的支持向量回归方法成功的对空间风压进行了预测;同年Zhu等[8]将ARMA时间序列与BP神经网络相结合,得到了更好的PM2.5预测结果,较使用单一方法进行预测提高了预测准确度,但是实验中仍缺少与其他方法的结果对比。2017 年Ye 等[9]利用ARIMASVR的方法对股票价格进行了较为准确的预测,该结果证明了将时间序列作为研究目标的方法可以显著降低原本模型的预测误差;2019年Song等[10]提出一种基于长短期记忆和卡尔曼滤波的预测模型,其结果较使用单一的LSTM提高了对空气中污染气体的预测准确率。
为了建立更加准确的城市PM2.5浓度预测模型,提出一种将支持向量回归与长短期记忆相结合的方法。首先使用Morlet小波核函数代替传统支持向量回归中应用较多的径向基核函数(RBF),解决了RBF非完全正交基的问题;然后使用改进的粒子群算法对该Morlet核函数进行参数优化,不但极大程度避免了算法陷入局部最优解,同时可在良好的时间复杂度内获得更优的预测结果;最后考虑到时间序列对城市PM2.5浓度的影响,将包含时间序列的LSTM预测结果与SVR预测结果进行非线性叠加,得到最终的预测结果。在实验部分进行了多组对比,结果均较ARMA时间序列、SVR与LSTM等较大地提高了预测准确度。
1 改进粒子群算法优化的小波支持向量回归
1.1 支持向量回归原理
支持向量回归[11-12]是由支持向量机的概念发展而来,用于非线性条件下的预测等多种场景。支持向量回归问题可以描述为寻求非线性空间的映射关系表示如式(1)所示:

式中:xi表示的是训练集中各维度的值;i表示各维度变量;ω表示变量系数;b表示偏置量。
对于样本中的(x,y),所求得到一个预测模型f使得预测结果与真实值最为接近。假设该回归模型几乎可以完全表达真实值,只存在可以忽略不计的误差ε,SVR问题可以转化成式(2):

式中:C为正则化常数;ℓε为不敏感损失函数,ℓε的表达式如式(3)所示:

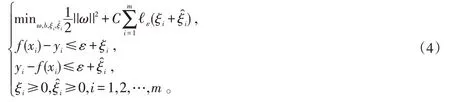

将式(5)代入到原式中,并且该过程需要满足Karush-Kuhn-Tucker(KKT)条件,即需要满足如式(6)所示:

支持向量回归的解的形式,可以表示为如式(7)所示。

1.2 Morlet 小波核函数
支持向量回归中核函数的作用是将低维线性不可分的情况映射到高维使之线性可分,此时引入合适的核函数如式(8)所示。

支持向量回归的核函数一般选择高斯核函数,然而高斯核函数并非完全正交基,考虑到小波函数可以通过伸缩以及平移的手段建立完全正交基,使SVR模型泛化能力更强[13-14]。小波函数可以作为支持向量回归核函数的条件是该基函数满足Mercer定理,构造支持向量回归的核函数的平移不变小波核函数形式,如式(9)所示:

该平移不变小波核函数需要满足傅里叶变换公式,如式(10)所示:
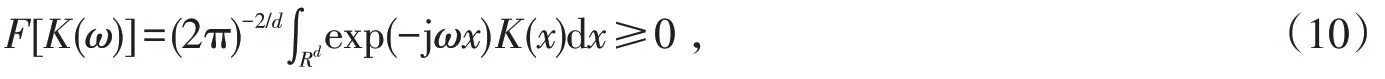
式中:Rd代表的是x的取值范围;d维的实数空间。
Morlet小波函数的实数表达如式(11)所示:

满足上述条件的实验所应用到Morlet小波核函数如式(12)所示:
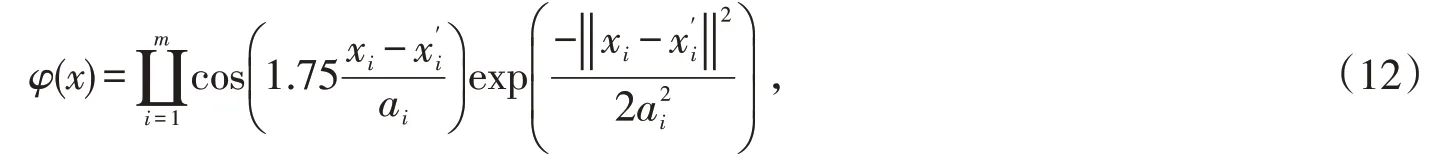
式中:m表示空间维度;ai表示伸缩因子。
1.3 改进粒子群算法参数优化
支持向量回归核函数中存在未知参数,分别是惩罚因子C与参数sigma,未知参数的取值直接影响模型泛化效果[15]。通常解决最优值搜索问题可以采用的方法有遗传算法、粒子群算法、蚁群算法等。考虑到粒子群算法模型简单、收敛性能好、搜索效率高等优势,同时需要尽量避免算法搜索过程陷入局部最优解,提出了改进粒子群算法对模型核函数参数进行最优值搜索。方法中粒子速度与位移更新公式如式(13)所示。
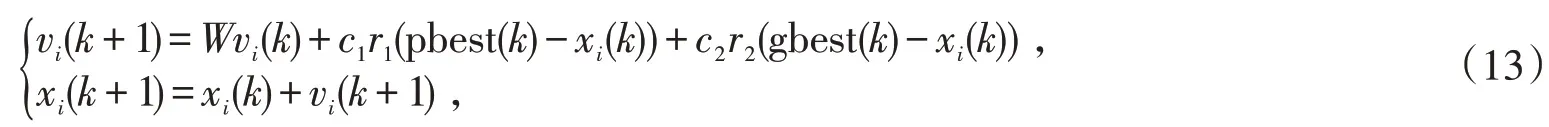
式中:vi(k)表示k时刻时的粒子的速度;xi表示粒子的位置;r1,r2分别为随机均匀概率值,并且取值范围是[0,1];c1,c2表示学习因子;pbesti表示局部最优位置;gbesti表示全局最优位置。式中存在未确定的参数W,表示粒子移动的惯性系数,具体意义是当该值较大时,该粒子将在原方向上有较大的移动能力,当值较小时,粒子在周围方向具有较高的搜索能力。该值一般采用线性函数取值如式(14)所示,也因此造成了局部最优解的情况。为了尽可能地避免粒子群算法由此产生的性能问题,同时保证搜索算法较低的时间复杂度,W值的选取采用非线性自适应算法,如式(15)所示:
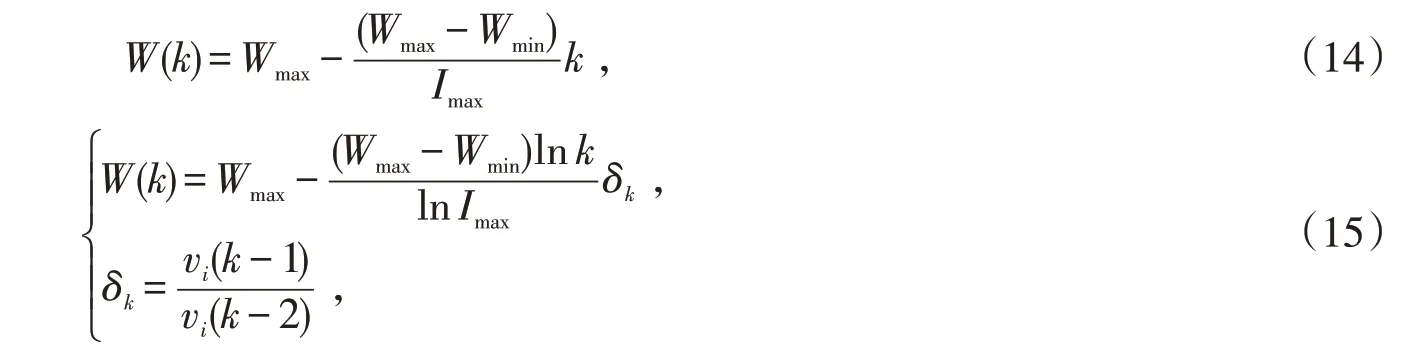
式中:Wmax与Wmin分别表示实验预先设定的最大及最小的惯性系数;Imax表示最大的迭代次数;k表示已迭代次数;引入一个概念值δk,表示速度趋向基数,该值依赖于之前两个时刻的速度变化比例。该值的不断变化,实现了W的自适应变化。这里值是非线性的,降低了线性函数情况下陷入局部最优解的可能。改进粒子群算法应用到Morlet-SVR的参数优化中,具体流程如算法1所示。
算法1 改进粒子群算法参数优化
输入 实验训练集数据,Morlet核函数表达式,粒子群最大进化次数,调优参数精度范围accuracy,粒子惯性公式,粒子群最大速度,粒子种群数量
输出Morlet核函数的最优参数sigma 与支持向量回归最佳参数C

2 基于支持向量回归与LSTM 的预测模型
2.1 LSTM 原理
长短期记忆网络(LSTM)是一种改进后的循环神经网络,通过设置隐藏层间的相关权重,解决RNN无法处理长距离依赖的问题[16-18],在诸多时间序列预测的场景下广泛应用。PM2.5这一与时间密切相关的复杂变量需要融合时间序列进行分析,从而提高预测的准确性。在LSTM中包含三个重要的门:更新门、遗忘门、输出门,其模型图如图1所示。
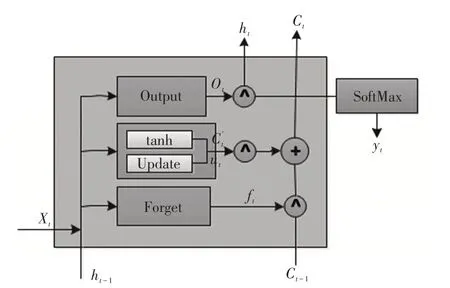
图1 LSTM 模型示意图Fig.1 Schematic diagram of LSTM model
LSTM单元的方程组如式(16)所示:

式中:ft其中是关于遗忘门的遗忘阈值;ot表示输出门的输出阈值;ht表示当前细胞输出。在更新门ut(图中Update)中存在参数权重Wu与偏差bu,其作用是确定sigmoid激活函数更新细胞单元的时机,当sigmoid函数取值接近1时,将更新该单元,接近0则忽略。表示部分输出tanh,影响该值变化的因素包括权重WC与偏差bC;Ct-1表示t-1时刻的细胞状态,以及ut共同影响最终的结果Ct。
2.2 支持向量回归与LSTM 结合模型
支持向量回归方法在解决有限规模样本、非线性等问题体现出良好的性能,较深度学习方法预测更迅速,经验风险更小;LSTM能够发掘时间序列对PM2.5的影响。考虑到2种方法在不同场景下的优势,文章的研究目标需要同时考虑预测性能、经验风险等,将上述2种方法的预测结果按照表达式(17)所示,构成最终的预测结果。
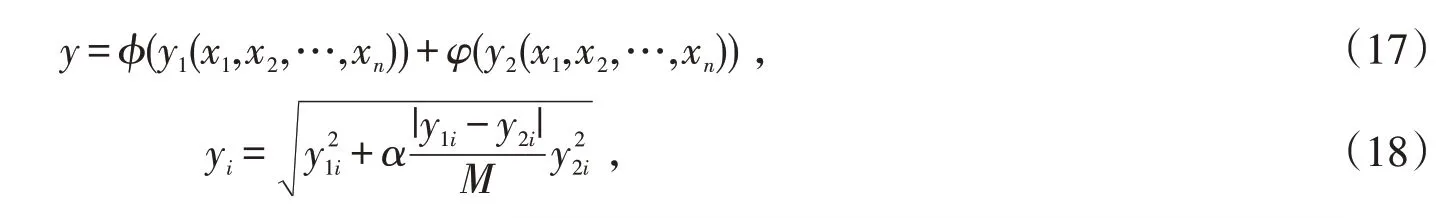
式中:y1i、y2i分别表示SVR、LSTM这2种方法在第i次实验中的预测结果;xi表示一维向量;φ与φ表示不同的函数。根据式(18)所示进行结果计算,得到最终的预测结果,式中:α表示时间关联系数,该值的取值范围是[0,1],与预测的时间间隔正相关,间隔越久该值的取值越大;M表示|y1i-y2i|的最大值。
基于支持向量回归与LSTM 的城市PM2.5预测模型图如图2所示。
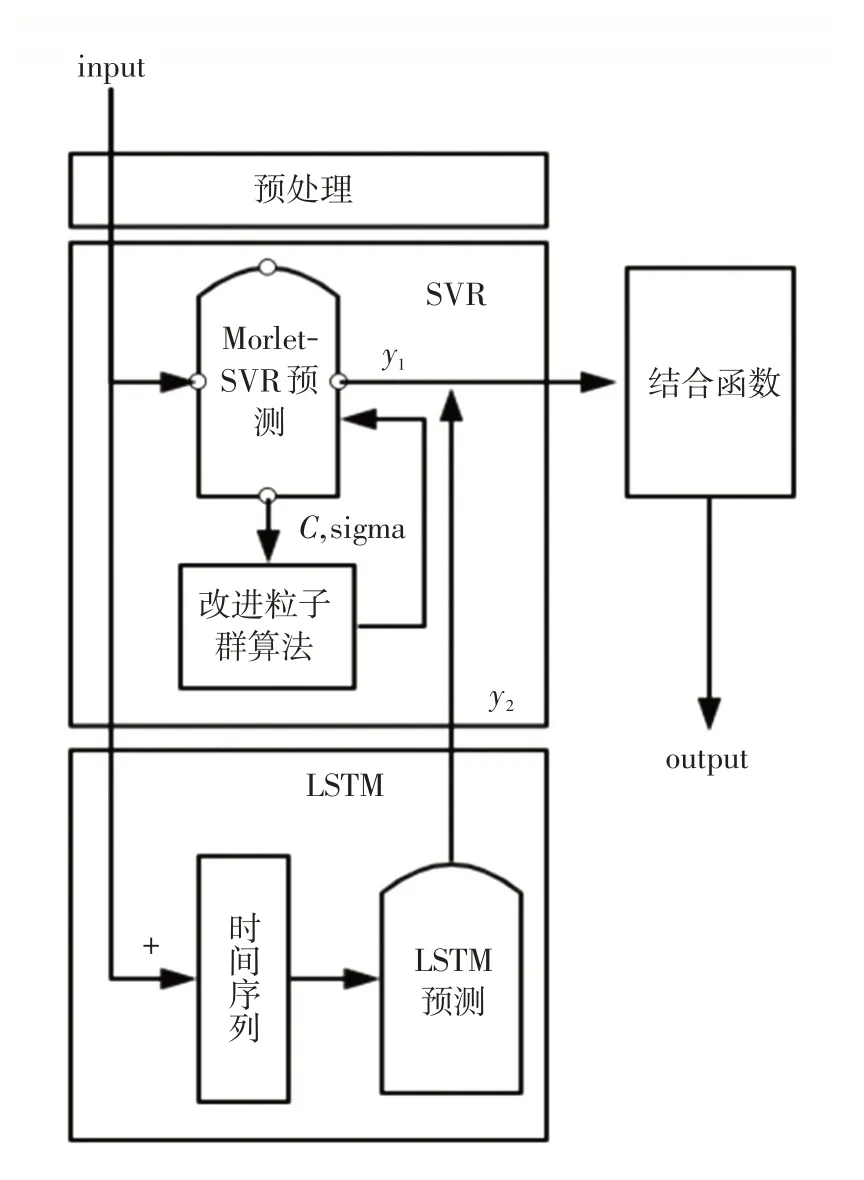
图2 基于支持向量回归与LSTM 的预测模型图Fig.2 Prediction model graph based on support vector regression and LSTM
3 实验与结果分析
在实验预处理方面,采用KNN-Kmeans 的方法进行不完全数据集的填充;采取分别归一化的方式处理训练集与预测集数据,实验过程的流程如图3 所示。在结果分析中首先分别对比ARMA、随机森林、神经网络以及支持向量回归方法预测结果;然后对比Morlet小波核函数以及RBF核函数支持向量回归的预测结果;接下来通过改进粒子惯性函数的方式应用粒子群算法对Morlet 核函数中的参数进行寻优,并将寻优前后的结果进行对比;最后针对城市PM2.5这一与时间序列密切相关的研究变量,将支持向量回归结果与LSTM 结果进行非线性叠加计算,将最终预测结果与其他方法的结果进行对比。
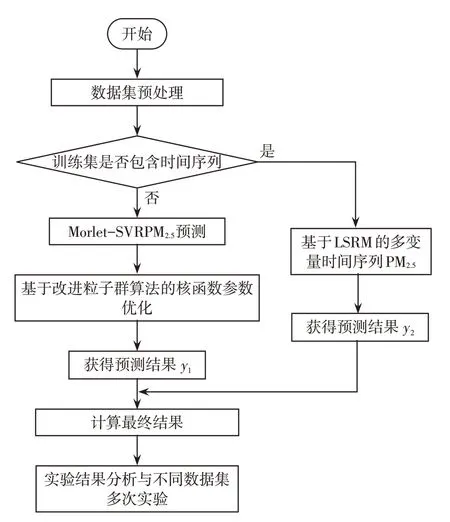
图3 实验过程流程图Fig.3 Flow chart of experiment process
3.1 支持向量回归与LSTM 结合模型
实验中所用到的数据,均来源于某市3 处监测点的真实观测数据。首先选取连续的720 h 的气象数据(湿度、风速、气压)与环境污染数据(PM2.5、PM10、SO2、NO2),并按照前648个作为实验训练集,剩余后72个作为测试集进行划分。由于选取的列数据中出现少量数据缺失,采用KNN-Kmeans方法进行数据填充,综合了2种聚类方法实现了更符合本数据集原始特征的填充方法:选定时间间隔为5 h,当时间间隔内的数据超过半数,即3 个或3 个以上为某一值时,认为在该时间间隔内的大气状况相对稳定不变,此时实验将该值作为填充值;若不存在上述情况,则按照K均值的计算方法进行填充,选择时间间隔内所有数据的平均值进行填充。实验数据填充中的时间间隔根据实验需要和原始数据集的特征设定。
为获得量纲统一的数据集,避免由于个别因素的比例尺过大带来的实验预测影响,同时提升模型的收敛速度和运算精度,采用对训练集和预测集分别归一化处理的方法,排除了因数据集随机划分造成的误差,归一化公式如式(19)所示,结果表示归一化后的向量:

SVR训练平台为WINDOWS 10操作系统,8 G内存,2.7 GHz CPU环境并应用libSVM程序库进行Matlab 编程。在粒子群优化实验前根据实验需要,预先设置种群的最大进化数量maxgen 及初始数量sizepop取值分别为15和1 000;设置最大最小变化结果值,使所求参量在可控范围内变化,防止产生过高的时间冗余。将popCmax 的初始值设为1 000,表示SVR 模型参数C的变化的最大值,popCmin 的初始设为0.05;popsigmamax 的初始为1 000,表示SVR参数sigma 变化的最大值,popsigmamin 设置为0.01;设置粒子的初始速度VC与Vsigma均为5。
LSTM 预测部分利用tensorflow 机器学习训练平台,选取的数据集包括时间序列以及预处理后的数据集;设置输入维度input_size 数值为7,输出维度output_size 为1,隐藏层单元rnn_unit 数值10,以及学习率lr为1,时间步time_step 的值为12,每批训练样本数batch_size 数值40,重复训练次数numbers 数值5 000。
3.2 支持向量回归与LSTM 结合模型
3.2.1 监测点PM2.5 基本情况与算法分析
实验中对研究的3 个国控监测点的720 个PM2.5的值进行了初步分析,通过直观观察可以方便建立数学模型。各个监测点的PM2.5值数据变化均较为明显,呈现出非线性变化规律,不同时间间隔的极值不同,平均PM2.5水平在90 μg/cm3;3个监测点PM2.5反映出的图形较为相似,其污染与气象差异相对较小,如图4所式。针对图像呈现的复杂变化规律,支持向量回归恰能够在小规模样本数据下体现其良好的自适应性。均方误差MSE 是评价预测模型的重要指标,客观反映了预测模型的误差大小,误差越小预测准确度越高;最大误差是预测值与实际值之差的绝对值最大值,反映了极端个体与真实值的偏离程度。表1为对比不同机器学习方法的均方误差与最大误差,SVR体现了一定的优势。
图4 监测点PM2.5随时间变化Fig.4 Monitoring point PM2.5 changes with time
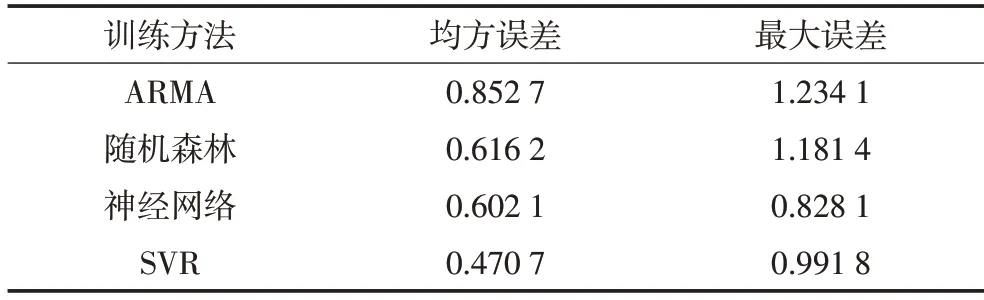
表1 不同方法预测结果对比Tab.1 Error comparison of prediction results under different methods
3.2.2 Morlet 小波核SVR 预测结果
分别使用Morlet 小波核与RBF核支持向量回归进行建模,并与预测集真实值的数值进行对比结果如图5所示。
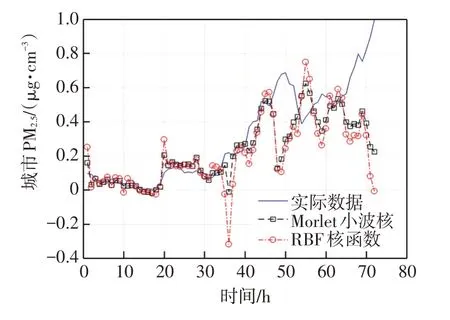
图5 Morlet 小波核与RBF 核SVR 预测结果对比Fig.5 Comparison of SVR prediction results between Morlet wavelet kernel and RBF kernel
表2所示对比不同核函数SVR的模型预测均方误差、最大误差。由此得出实验结论:Morlet 小波核SVR 在城市PM2.5预测建模上较其他核函数精度更高,体现了该应用的合理有效性。
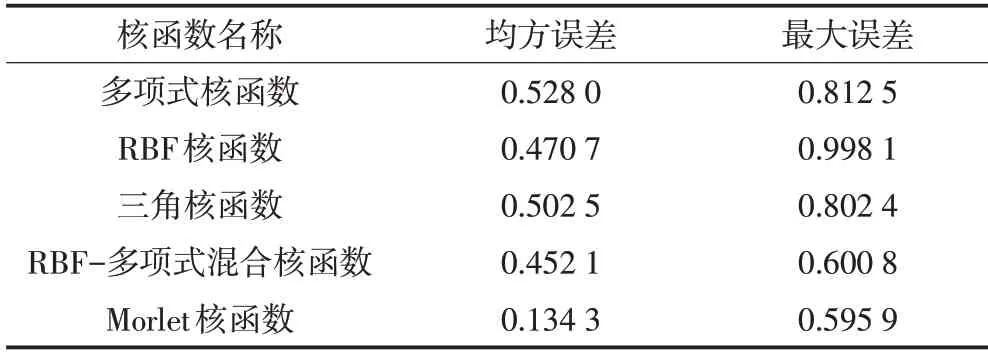
表2 不同核函数预测结果对比Tab.2 Comparison of prediction results of different kernel functions
3.2.3 改进粒子群算法参数优化结果与预测对比
改进的粒子群优化算法的目的是获取模型最优参数C以及sigma,实验结果如图6所示获得到了最优参数。
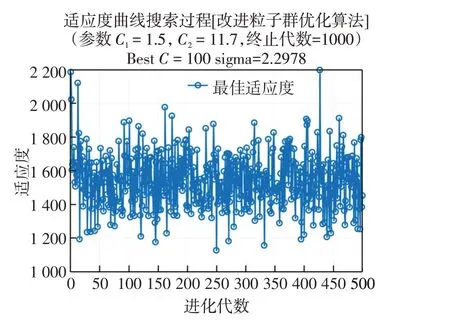
图6 改进粒子群算法最优参数搜索结果Fig.6 Search results of optimal parameters of improved particle swarm optimization
根据搜索结果,确定了Morlet-SVR 最佳参数值,并均将参数代入实验中,如图7中显示了参数优化前后预测结果与测试集实际值对比。
据图7 分析,粒子群算法优化前当时间间隔为45 h,预测结果与实际结果开始出现明显偏差,优化后则是在时间间隔大于55 h,出现小范围偏差,大于65 h出现较大偏差。由此得出结论:改进粒子群算法可以提高准确预测的时间长度,能够提高模型的预测精度。然而由于训练数据集规模有限,且模型本身具有一定的局限性,当时间间隔较大时,预测结果依旧存在着与实际值的偏差。
3.2.4 基于SVR 与LSTM 的模型预测结果
基于多变量时间序列的LSTM 可以有效解决长距离依赖问题,同时发掘时间序列对PM2.5浓度变化的影响。如图8所示为基于该方法的预测结果。
图8中显示预测数据在45~70 h基本与实际数据一致,较支持向量回归方法不同,LSTM预测结果在0~45 h反映出与实际值的误差。在20~30 h与40~45 h这2个时间段有较大偏差;同时LSTM预测时间较长,模型中参数较多,只利用该方法不能达到对实验结果的预期。表3 所示为不同时间间隔2 种方法的均方误差对比。

表3 不同时间间隔MSE 结果对比Tab.3 Comparison of MSE results in different time intervals
据图7 和图8 的结果分析,在预测结果时间段的后20%中LSTM 解决了支持向量回归预测效果明显下降的问题;然而SVR模型简单,且在预测结果时间段的前50%中优势明显。最终将支持向量回归与LSTM这2部分预测结果按照式(18)进行非线性叠加:当相距起始时间节点越近,基于改进粒子群算法的Morlet支持向量回归预测结果更好,当时间间距较大,使用基于多变量时间序列的LSTM 效果更佳。2 种方法的预测结果偏差较大时,LSTM 更能反映实际值的变化趋势,计算结果体现了自适应性。实验结果对比基于PSO-SVR与LSTM-SVR这2种方法,如图9所示。
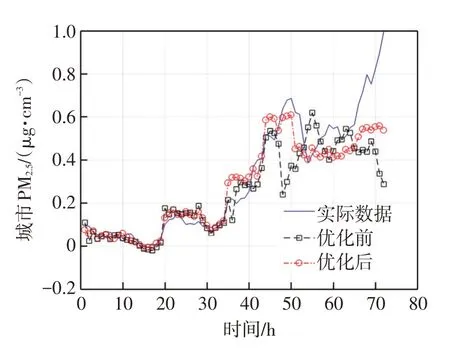
图7 改进粒子群优化前后预测结果对比Fig.7 Comparison of prediction results before and after improved particle swarm optimization
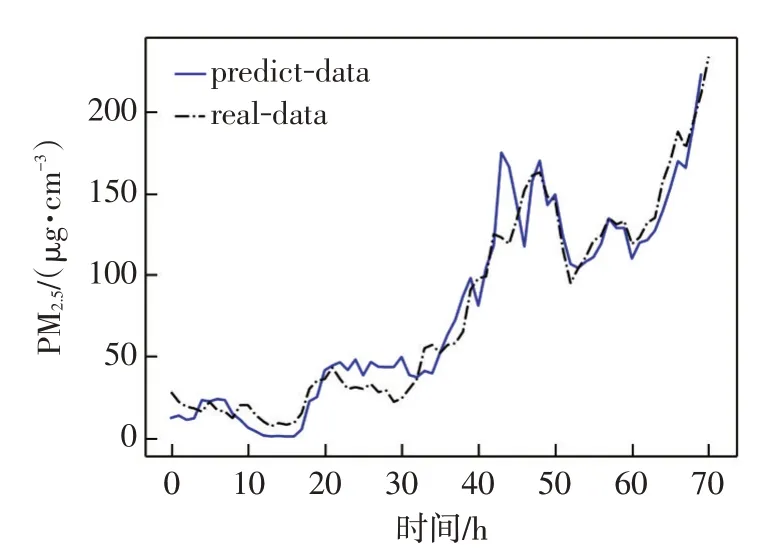
图8 基于LSTM 的时间序列预测结果Fig.8 Prediction results of time series based on LSTM
从图9 中可以观察到,基于LSTM-SVR 的研究方法较使用改进粒子群优化的Morlet-SVR进一步提高了预测精度。通过相关损失函数平均绝对误差MAE 以及模型准确率pre 作为衡量该模型预测准确度的指标。其中MAE 越小说明预测的准确度越高,计算公式如式(20)所示:
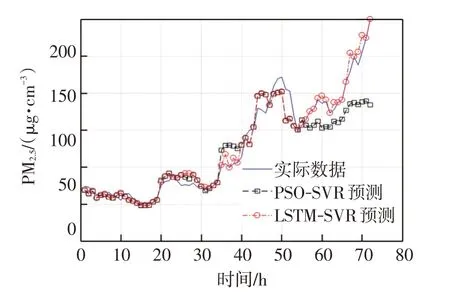
图9 基于PSO-SVR 与LSTM-SVR 的结果对比Fig.9 Comparison of results based on PSO-SVR and LSTM-SVR
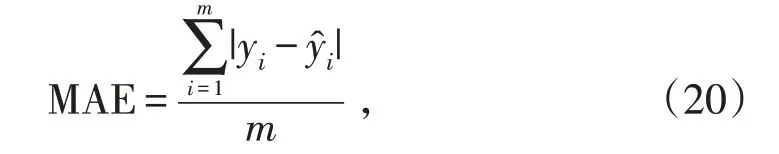
式中:m表示预测集合记录数量;yi表示该条记录的预测结果;表示该条记录的真实结果。模型准确率pre 反映了预测值与实际值的相似程度,该值的计算方法满足式(21):

式中:θi表示单次准确预测值,可以取4个值,当预测结果与真实结果满足不同的条件时,准确预测值也不同。其对应关系因实际需要而制定,在本实验中满足式(22):
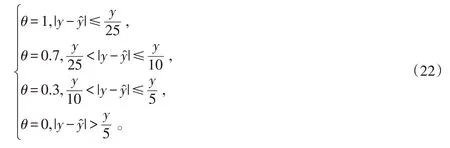
根据上述计算方法,获得不同模型下的MAE 与pre值,如表4所示。
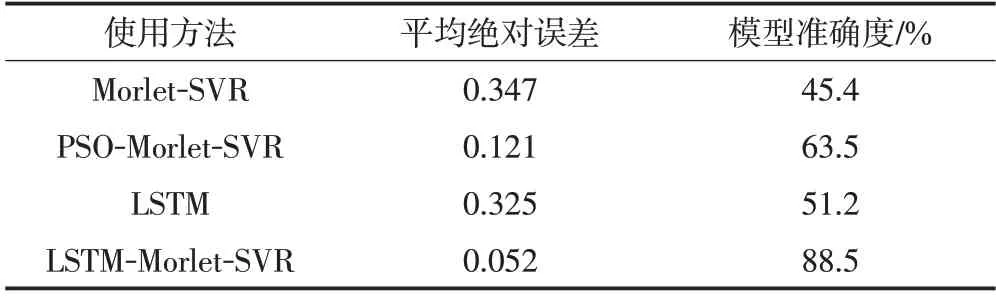
表4 不同模型准确度与误差对比Tab.4 Comparison of accuracy and error of different models
最后利用不同方法对该市区3 处监测点进行预测结果准确度对比,结果如图10所示。
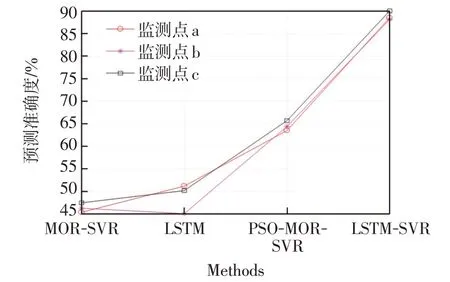
图10 不同监测点基于不同方法的准确度结果对比Fig.10 Comparison of accuracy results of different monitoring points based on different methods
根据上述3 处监测点的预测结果显示,基于支持向量回归与LSTM相结合的方法均优于其他方法。
4 结语
文章提出了基于支持向量回归与LSTM 的城市PM2.5预测模型。在模型建立的过程中,首先根据支持向量回归方法以及Morlet 小波核的优势,确定了支持向量回归的核函数;为获得更好的预测结果,采用改进粒子群算法对核函数的参数进行优化,并将最优参数代回模型进行预测;最后将非时间序列的Morlet-SVR 预测结果与时间序列下LSTM 预测结果进行非线性叠加,形成最终的预测结果,以满足模型对时间序列依赖的需要。从各步骤的实验结果可以看出,本文提出的基于支持向量回归与LSTM的方法在城市PM2.5预测上较ARMA 时间序列、神经网络、随机森林等方法具有明显优势,同时较传统的SVR与LSTM提高了预测准确度。后续工作将考虑对模型中的LSTM部分进行优化,通过合理设置隐藏层数、改变激活函数以及参数寻优等,进一步提高预测准确度。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
测控技术(2018年10期)2018-11-25
浙江工业大学学报(2017年5期)2018-01-22
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
高中生学习·高三版(2016年9期)2016-05-14
