
基于级联优化策略的视频显著性检测
2022-06-29 09:47郭迎春李雅楠
河北工业大学学报 2022年3期
郭迎春,李雅楠,于 洋
(河北工业大学 人工智能与数据科学学院,天津 300401)
0 引言
显著目标检测旨在让计算机视觉系统模拟人类的视觉系统,从复杂场景中快速抽取出显著目标区域用于后续的图像处理,广泛应用于图像/视频压缩[1]、目标分割[2]和目标追踪[3]以及运动目标检测[4]等领域。
与图像显著性检测相比,视频显著性检测方法起步较晚,发展不很成熟。虽然可以利用静态图像的显著性检测策略提取视频序列中的目标物体,但是对于视频而言,人类更多地关注到运动显著物体。而静态图像的显著性检测方法割裂了相邻帧乃至整个视频帧之间的联系,因而未能突出视频显著目标。目前视频显著性检测方法通常采用底层特征(如颜色、光流、亮度、纹理)进行显著性检测。从模型的构造方法看,基于底层特征主要有2种方法,即直通管线(Direct-pipeline)模型[5-13]和融合(Fusion)模型[14-17]。
直通管线模型旨在利用时空特征突出视频显著目标。Zhou 等[5]将视频帧分割成STRs(Spatio-temporal Regions),利用STR之间的特征对比度和先验项突出前景目标。其中每个STR的特征由3个特征向量(颜色直方图、光流归一化直方图和光流方向)表示。Wang等[6]提出利用空间边缘和时间运动边界的测地线距离生成时空显著图,之后又提出了用于显著性估计的梯度流场,并结合局部和全局对比度进一步突出前景目标,最后通过能量函数优化目标[7]。Liu等[8]构造了一个具有虚拟背景节点的超像素级的无向加权图,通过优化常规节点中每个节点到常规节点与虚拟背景节点最短运动特征距离之和获得运动显著图,经过双向时间传播和空间传播生成视频显著图。Chen等[10]将显著性目标检测表示为一个最小化约束能量函数问题,利用时空线索和局部约束实现全局显著性优化。Guo等[11]在梯度流场的基础上,提出一种自适应融合相邻两帧显著图的方法,并结合静态显著图提取视频显著区域。Cong等[13]提出基于稀疏重构的方法捕获帧内显著物体,通过前向和后向传播生成帧间显著图,最后利用全局优化模块突出一致显著目标。
融合模型利用空间线索和时间线索生成时间显著图和空间显著图,然后将2种显著图利用融合策略生成视频显著图。Kim等[14]采用RWR(Random Walk with Restar)框架融合空间转换矩阵和时间重启动分布以检测时空显著性。Xi等[15]利用时间先验和背景先验知识得到时间显著性和空间显著性,之后将2种显著值线性叠加并单位归一化融合成视频显著图。Chen等[16]对外观/背景建模作为时间层面的全局线索,指导颜色显著性与运动显著性的融合。
尽管上述视频显著性检测方法在各个时期中发挥着自身独特的优势,但是在目标位于边界、动态背景复杂以及前景目标被遮挡等更具有挑战性的场景下,这些方法受自身局限性的影响往往不能很好地解决这些问题。因此复杂场景下的显著目标检测仍然是一个亟待研究和解决的课题。本文对视频序列构造了一个时空上下文模型,提出了基于运动对比度和时空精细化的无监督视频显著目标检测框架,使目标物体具有良好的空间平滑性和时间连续性,并准确突出显著性一致的区域。
本文的主要贡献可归纳为以下3点:
1)提出了一种基于运动对比度的显著目标检测方法,当目标出现被遮挡或者位于边界等比较复杂情形时,能够有效地突出视频中的运动物体;
2)为了使显著目标更加精确,本文结合外观线索、运动线索与空间线索计算帧内局部对比度与全局对比度,精细化前景目标;
3)本文利用帧间的颜色和运动相似性自适应融合前一帧显著图增强了目标物体的时空一致性。
1 基于级联优化策略的视频显著性检测算法
本文的目的是精确有效地检测出复杂视频场景中的显著目标区域,主要工作分为4个部分:在1.1节中重点介绍了运动边界连通度的计算过程,并在其基础上估计背景概率约束运动对比度生成运动对比度图;在1.2节中分析了单帧图像的局部和全局的显著性,进一步精细化前景目标生成空间显著图;在1.3节中度量了相邻的两帧图像的相似程度,自适应融合前一帧图像的显著图得到时间显著图;在1.4节中对运动显著图、空间显著图和时间显著图进行融合生成时空一致的视频显著图。图1为本文提出方法的总体框架图。
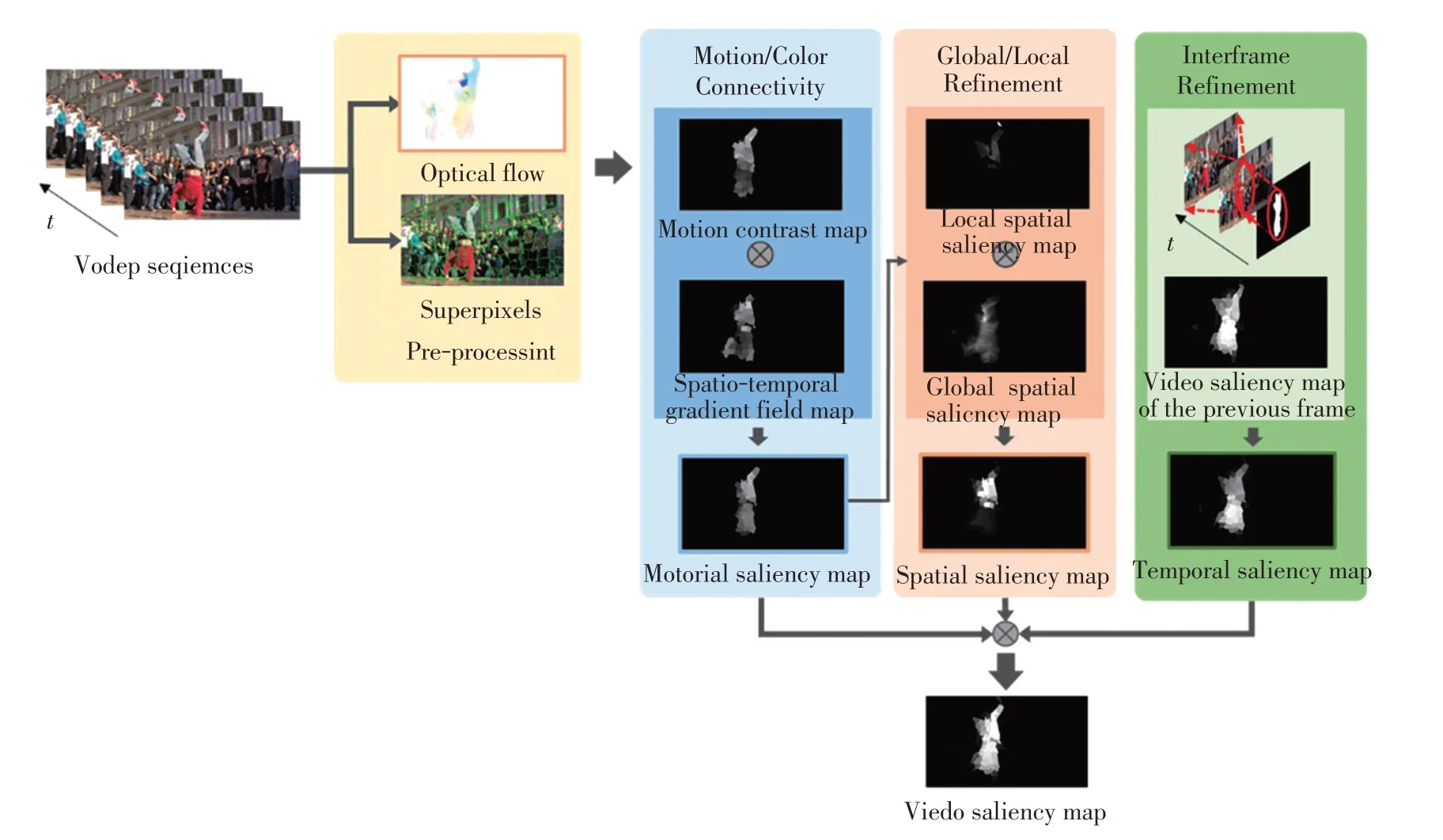
图1 提出方法的框架图Fig.1 Framework of the proposed approach
1.1 运动显著图
对于视频,人们更多地将注意力分配到运动明显的物体。为此,本文提出了一种运动显著性线索,即运动对比度,来捕获视频中的人类感兴趣区域。
给定一个视频序列F,首先采用LDOF 算法(Large Displacement Optical Flow)提取光流矢量,并通过SLIC 算法(Simple Linear Iterative Clustering)对视频序列进行超像素分割,每一帧图像将得到一组子图像区域spi(i=1,2,…,N),N表示超像素的个数。然后提取超像素级的颜色特征、空间特征和运动特征。其中,超像素spi的颜色特征C(spi)由超像素块内所有像素CIE-Lab颜色空间中L、a、b3个分量平均值构成向量表示,空间特征P(spi)由超像素中心的空间位置坐标构成的向量表示,运动特征V(spi)由超像素块内所有像素的光流矢量的平均值构成的向量表示。
为了准确区分视频当中的前景和背景区域,本文提出了边界运动连通度,即度量图像中任意一个超像素与背景区域之间的关联程度,由此获得背景概率降低运动对比度线索的误检率。首先定义超像素spi的边界运动连通度ΦV()spi如公式(1)所示:
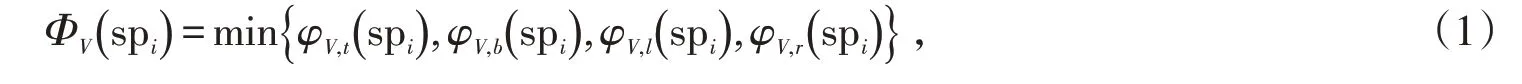
式中:φV,t、φV,b、φV,l、φV,r分别为沿上、下、左、右4个边界计算得到的运动连通度。
以上边界运动连通度为例,计算视频序列中超像素spi生成运动关联域的面积,其定义如公式(2):
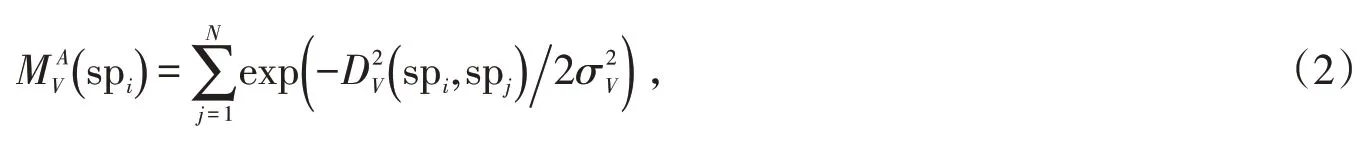
式中:DV()spi,spj表示超像素spi与spj之间的运动距离(i,j=1,…,N,i≠j),由超像素spi沿着最短运动路径到spj得到边的权重累加值,控制生成运动关联域的范围,在本文中设置为1。
接着计算超像素spi与上边界运动关联长度如公式(3):
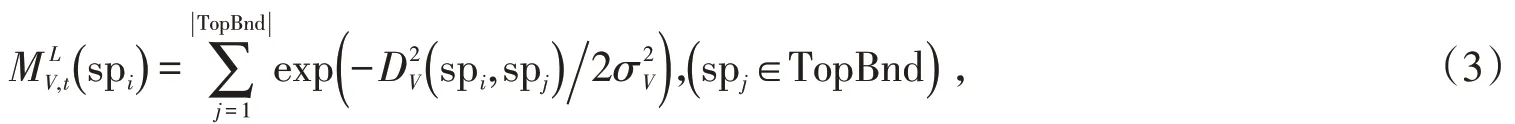
式中:spi表示上边界中任意的超像素,|TopBnd|为上边界(TopBnd)中超像素个数,控制着上边界区域运动关联程度,设置为经验值1。根据超像素spi的运动关联域面积和沿上边界运动关联长度进一步计算获得上边界运动连通度,其计算方法如公式(4):

与上边界运动连通度计算过程类似,分别可以计算出沿下、左、右3个边界运动连通度。通过公式(1)可获得最终的边界连通度。利用公式(5)对边界连通度进行归一化映射为运动背景概率pV,bg(spi)为:
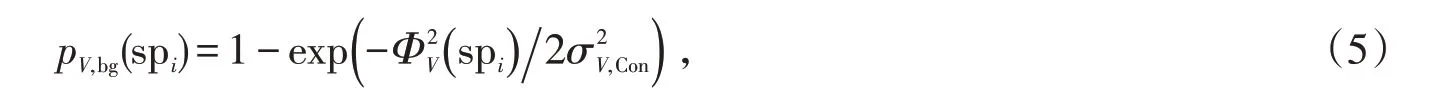
式中:σV,Con控制边界运动连通度转化为背景概率的强度,在本文设置为1。
为了突出与视频中主导运动不同的区域,计算任意超像素spi与全局范围内的超像素之间的运动特征距离,同时进行空间加权减弱距离当前超像素较远区域的影响,并结合背景概率作为约束项,由此定义超像素spi运动对比度如下:
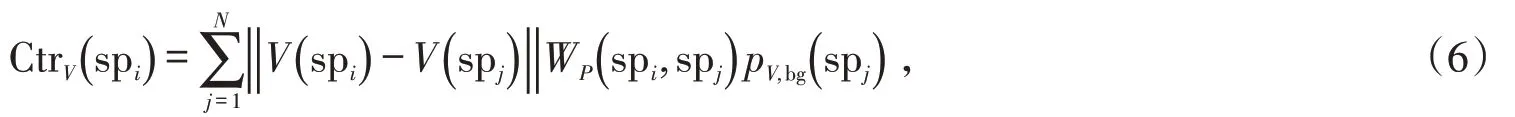
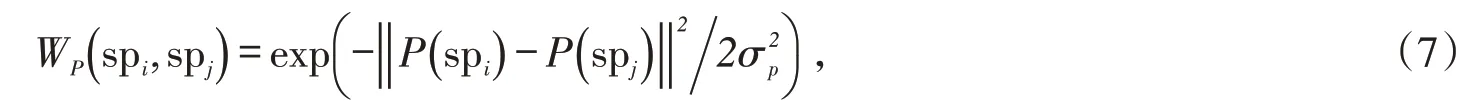
式中:WP()spi,spj表示在空间域超像素spi对spj的影响程度,空间位置距离超像素spi越远的区域,对其的影响程度越低;‖* ‖ 表示特征之间的欧氏距离;σp控制周围区域在空间上的影响范围。从图2 中可以看出,运动对比度图能够有效突出运动显著的目标物体,物体细节较为清晰。
为了增强前景目标的完整性,在运动对比度图CtrV的基础上融合时空梯度场图TSG[7],生成运动显著图MS:

式中:⊗表示自适应融合2种显著图操作并将融合后的显著图归一化到[0,1][11]。从图2中可以看出,运动显著图(见图2f))相比于运动对比图(见图2d))和时空梯度场图(见图2e)),可以更加均匀地突出显著物体,并保持一致高亮,且削弱了不显著的背景噪声。

图2 运动显著图的构建Fig.2 Examples of constructing motion saliency map
1.2 空间显著图
运动显著图可以突出视频帧中运动显著区域,从图2f)中可以看到得到的显著目标仍然不够准确,因此这里利用帧内图像的对比度线索(包括局部和全局空间线索)来进一步精细化运动显著图MS中的前景区域O。
计算单帧图像中任意一个超像素spi与背景区域之间的特征距离(包括颜色和运动),在空间位置距离其较近的背景超像素赋予较高的空间权重,可得到局部空间显著性,计算方法如公式(9)所示:
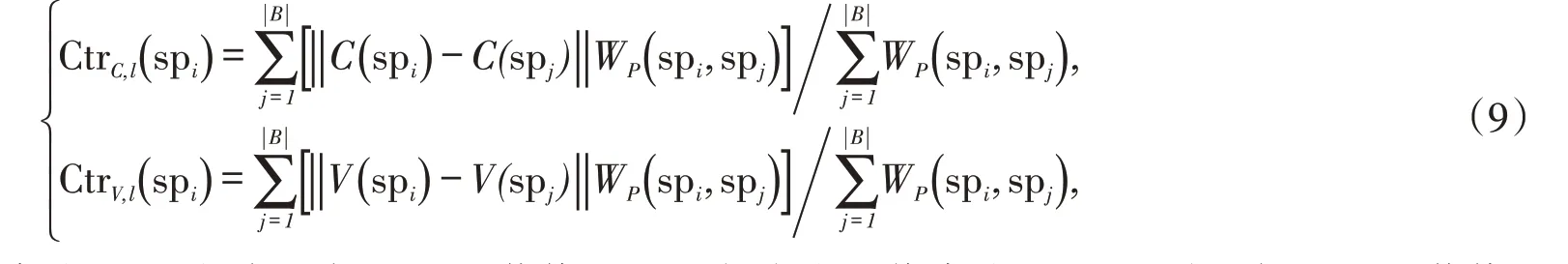
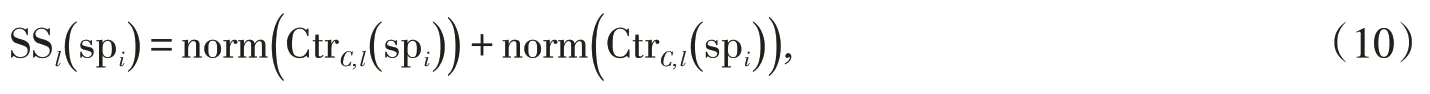
式中:norm(*)表示单位归一化到[0,1]范围操作[15];||B表示背景区域中包含的超像素个数。
接着利用另一种度量方法来突出超像素spi与背景区域在外观和运动对比明显的区域,即每个超像素到背景区域的最短特征距离(包括颜色和运动)路径累加值,称为全局空间显著度,具体计算方法如下:
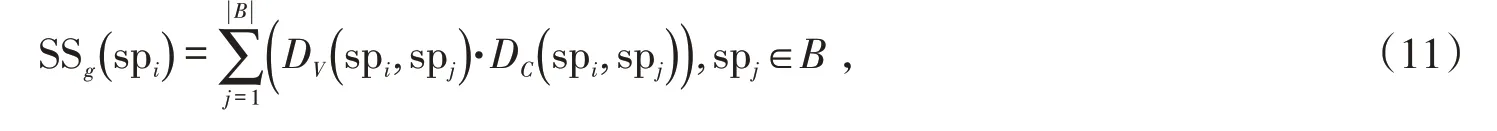
式中:DC和DV分别表示帧内超像素spi到背景区域中超像素spj沿最短颜色特征路径距离之和与最短运动特征路径距离之和。接着将局部空间显著图SSl和全局空间显著图SSg归一化到[0,1]范围内,融合两种空间对比度线索增强空间一致性,获得最终空间显著图:

式中:norm(*)表示单位归一化到[0,1]范围。与运动显著图MS相比,空间显著图SS(见图1)能够均匀突出显著目标,使物体细节部分相对更加完整,并且能够有效抑制前景目标边缘附近的背景噪声。
1.3 时间显著图
视频中相邻帧间的显著目标具有一致性,相应区域的显著值存在高度相似性。基于这个先验知识,本文提出一种时间精细化方法,计算当前帧与前一帧在外观和运动的相似性,作为权重项动态融合前一帧的视频显著图获得当前帧的时间显著图。
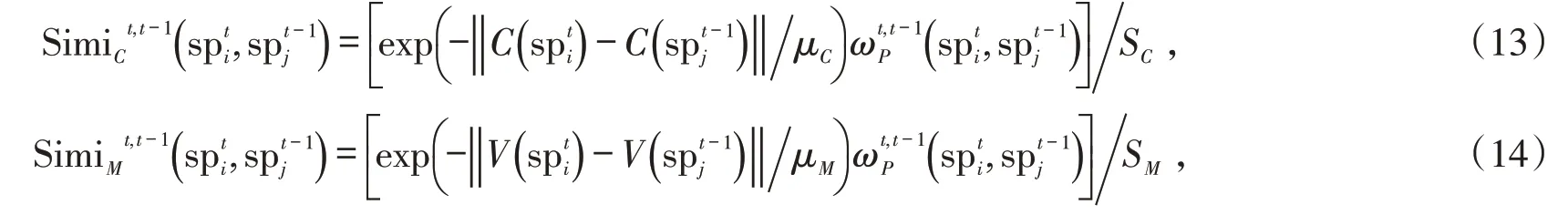
式中:SC和SM分别是当前帧中的任意超像素与前一帧任意一个超像素的颜色特征和运动特征相似度的总和;μC和μM分别是当前帧的近似前景目标中的超像素与前一帧前景目标中的超像素的颜色特征和运动特征的距离的最小值;为空间加权权重,计算公式如下:
式中:μP是当前帧的近似前景目标与前一帧的前景目标的空间距离的平均值。接着根据相邻两帧图像之间的相似性自适应融合前一帧的视频显著图,得到时间显著图的定义如下:
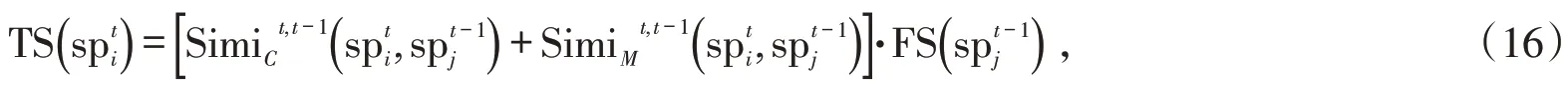
式中:FS 表示前一帧图像的视频显著图。如图1 所示,运动显著图MS 和空间显著图SS 缺失了细节(膝盖)部分,由时间显著图TS可以检测出较完整的内容。
1.4 显著图的融合
由1.1节、1.2节和1.3节分别得到了运动显著图、空间显著图和时间显著图。为了结合各种显著图的优势使最终的显著图更加稳健,同时削弱背景噪声,需要将3种显著图进行融合生成视频显著图:

如图1所示,与运动显著图MS、空间显著图SS和时间显著图TS相比,视频显著图VS前景目标一致高亮,均匀突出了运动显著图、空间显著图和时间显著图的共同显著目标,减弱不一致显著区域的影响。
2 实验结果
本小节主要介绍本文方法所采用的数据集和评价算法优劣的性能评价指标。同时与近几年显著目标检测领域中的经典算法进行了对比,并对实验结果进行定性和定量的评估与分析,以验证本文方法的先进性。
2.1 数据集和实验设置
本算法主要与10种典型的显著性检测算法进行了比较,分别为TIMP(TIme-MaPping)[5],RWR(Random Walk with Restart)[14],MB+M(Minimum Barrier)[18],SAGM(Saliency-aware Geodesic)[6],GF(Gradient Flow)[7]、MSTM(Minimum Spanning Tree Model)[19]、SGSP(Superpixel-Level Graph And Spatiotemporal Propagation)[8]、FD(Fusion and Diffusion)[16]、SCSD(Spatiotemporal Consistency Saliency Detection)[11]和SRP(Sparsity-based Reconstruction and Propagation)[13]。在3 个公开的标准数据集DAVIS[20]、FBMS[21]和Segtrackv2[22]上评估了这些显著性模型的性能。所有的测评结果来源于亲自运行作者公开的源代码或者作者提供的测试结果集。
DAVIS数据集是一个物体分割数据集,包括50个视频序列,帧数范围为25~104帧,共有3 455个帧标注。该数据集富有挑战性的场景,例如运动背景、背景复杂、目标物体遮挡和目标物体位于边界等。
FBMS数据集是一个运动物体分割数据集,分为训练集和测试集。其中训练集包括29个视频序列,353个帧标注。测试集包括30个视频序列,367个帧标注。FBMS数据集大多数视频序列帧数超过100帧,其涵盖了摄像机的抖动、模糊、运动复杂、前景物体形状大小变化、背景复杂等各种挑战。其中,本文利用FBMS测试集进行试验评估。
Segtrackv2 数据集最初用来评估跟踪算法,也适用于评估视频分割算法,近年来被广泛应用于视频显著性目标检测评估的任务中。该数据集包括14个视频序列,帧数范围为21~244。该数据集包含摄像机抖动、光照变化和运动复杂等情形。
2.2 定性评价
本文与其他10种经典模型在3个数据集(DAVIS、FBMS和Segtrackv2)上进行了比较。每个数据集选取两个典型的具有挑战性的视频序列,如图3所示,从上到下依次是DAVIS 数据集:bmx-bumps(目标物体位于边界,物体被遮挡),goat(背景杂乱);FBMS 数据集:lion01(目标与背景颜色相近),rabbits04(摄像机运动);Segtrackv2数据集:bird-of-paradise(摄像机静止),parachute(亮度变化)。

图3 不同模型得到的显著图在DAVIS、FBMS 和Segtrackv2 数据集上的直观对比效果Fig.3 The visual comparison of the saliency maps obtained by the different models on the DAVIS,FBMS and Segtrackv2
从图3中可以看出,本算法可以有效地检测到上述几种复杂场景中的显著物体。MB+M 和MSTM 未利用时空信息及相应的策略,所以难以有效检测视频中目标一致的物体。GF在物体位于边界和被遮挡的情况下(例如bmx-bumps),错误地将部分背景区域检测为显著区域。所提出的方法与之相比,表现出良好的性能优势。TIMP和RWRV在背景杂乱的情况下(例如goat),无法突出一致的显著目标,背景噪声严重,而本模型能够高亮地突出显著目标。RWRV,SAGM,GF 和SGSP 在光照变化的情况下,检测性能鲁棒性较差。由于引入边界运动连通度的机制,本方法无论是在动态背景还是在静态背景的场景下,均能检测出运动显著的目标区域。本文采用无监督的模型从低层特征中捕获前景对象,与近几年的方法相比,本方法适用于更加复杂的场景,而且能够有效地捕获到前景对象。
2.3 定量比较
本文采用4 种定量评价指标评估不同视频显著目标检测模型的性能:Precision-Recall(PR)、F-measure、S-measure 和MAE。为了公平有效地进行评估,本文将所有显著图重新调整到[0,255],从中依次选取阈值对显著图进行二值化得到二值图,然后与真值(GT,ground-truth)进行比较。图4为本算法与其余10种主流算法在DAVIS、FBMS和Segtrackv2数据集上的PR曲线。表1为最大F-measure值、S-measure值以及MAE测评结果。值得注意的是,表1中测评结果排名最好的数据均用加粗字体表示。
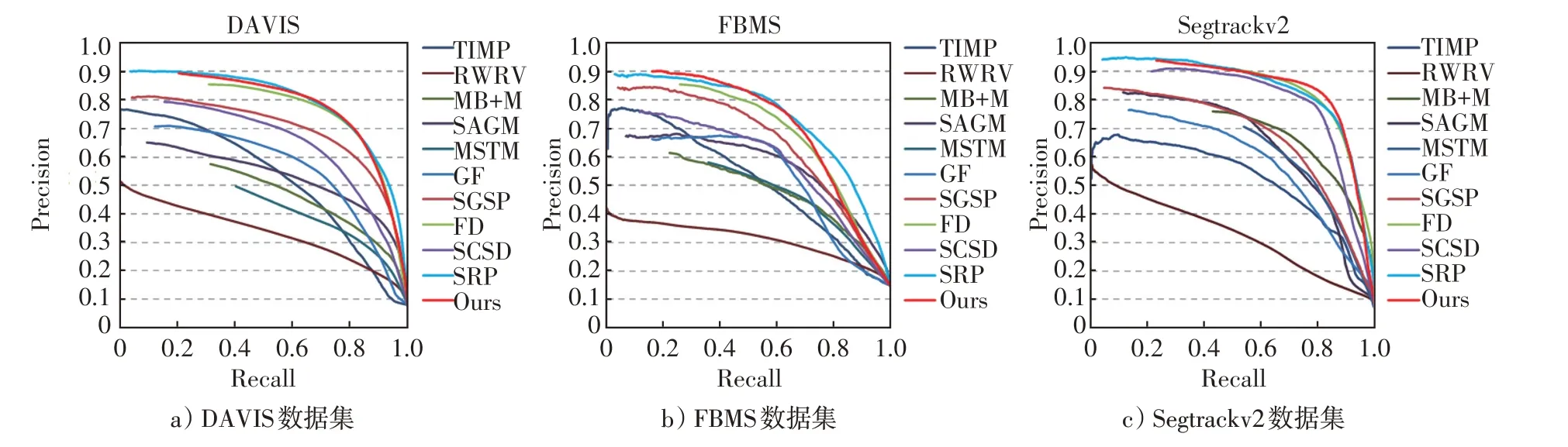
图4 不同算法在3 个数据集上的PR 曲线Fig.4 PR curves of different methods on three datasets
F-measure评估算法整体性能,利用查准率和查全率计算得到,其计算公式如下:

式中:β2控制着分割准确率和分割完全率的权重,这里β2设置为0.3[23]。
S-measure是Fan等[24]提出的一种新型的评估显著图度量方法,广泛用来评价显著图与真值图GT之间的结构相似度。

式中:So表示对象感知结构相似性;Sr表示区域感知结构相似性。α通常设置为0.5。
图4 显示了本算法与10 种主流算法的PR 曲线。与SRP 相比,本文的PR 曲线峰值略低,最大相差0.5%,几乎与SRP模型持平。但综合其他测评结果来看(如表1),无论是最大F-measure、S-measure 还是MAE 值,均明显优于SRP。其中,在最大F-measure值上与SRP 模型相比,本模型高于其1.8%~8%左右;在S-measure 值上,本模型均高于SRP,在MAE 上相差0.8%~1.8%。这说明本模型的测试效果的精度和和鲁棒性更胜一筹。且相比于其他模型,本文的PR 曲线明显处于最高值,性能效果明显。从F-measure 来看,所提出方法在3 个数据集上均获得了最高的分数。从S-measure 上看,在FBMS 和Segtrackv2 数据集上与其他模型相比,本模型分值最高。在DAVIS数据集上,所提出算法与FD分值相当。从MAE来看,在Segtrackv2数据集上取得了最低值。在其他2个数据集上,与获得最低MAE的模型相比,相差0.4%~1%左右。总的来说,本文提出的基于级联优化策略的视频显著性检测算法在复杂的视频中能够准确有效地定位显著区域,与近五年的视频显著性检测模型相比具有一定的竞争力。实验结果证明了本文方法的有效性和合理性。
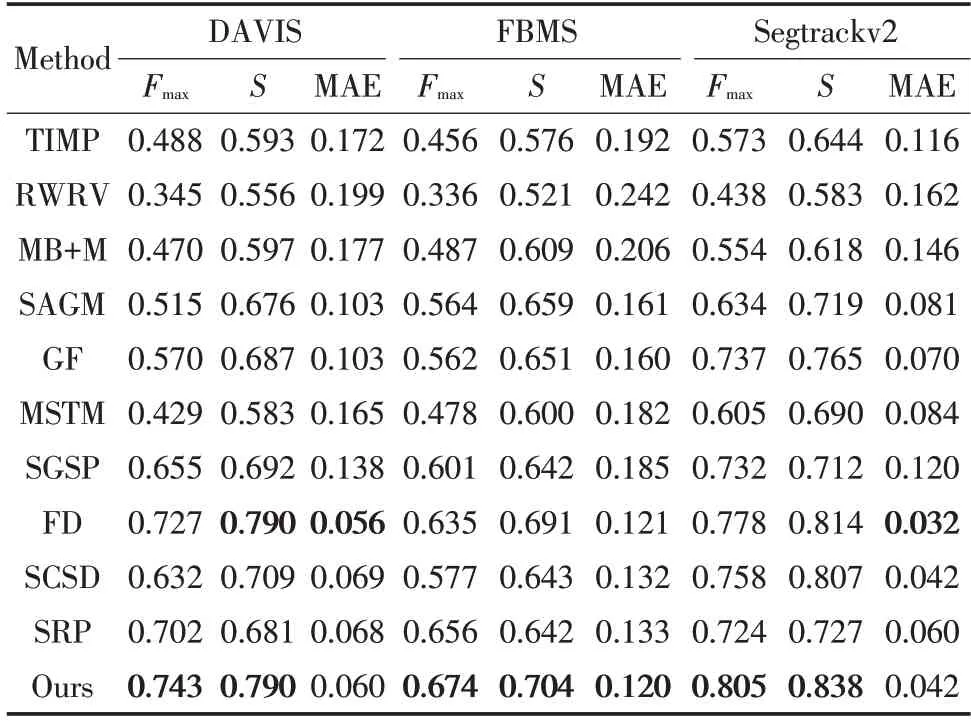
表1 与主流模型评估对比结果Tab.1 Comparison of evaluation results with the state-ofthe-art models
3 结论
本文提出了一种新的视频显著目标检测方法,相比于过去无监督模型,对具有挑战性的场景具有更强的鲁棒性。首先,在计算运动显著图时提出了基于运动对比度检测运动目标的方法,并融合时空梯度场图,一致突出共同的显著运动目标。接着,采用全局与局部两种对比度线索对运动显著目标进行精细化,使前景对象具有较高的显著性,抑制背景噪声。此外,利用帧间的相似性动态融合前一帧图像的显著图,突出帧间一致目标物体。本文在3个公开的数据集上进行实验,实验结果表明本文提出的方法具有一定的有效性和先进性。由于本文采用了光流提取运动特征,而提取光流耗费时间大,大大降低了检测的时间效率。所以未来的工作希望探索一种新方法,替代光流获取运动特性。而且在杂乱的背景中检测微小的显著物体并且应对更加复杂的场景也是本文目前工作的瓶颈,这也是未来需要研究的重点。
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
儿童时代·幸福宝宝(2021年11期)2021-12-21
现代装饰(2020年4期)2020-05-20
中学生数理化·高一版(2020年1期)2020-02-20
红领巾·萌芽(2019年8期)2019-08-27
中学生数理化·八年级物理人教版(2018年10期)2018-12-06
证券法律评论(2018年0期)2018-08-31
中国与非洲(法文版)(2017年10期)2017-11-23
CHIP新电脑(2016年3期)2016-03-10
科普童话·百科探秘(2015年4期)2015-05-14
