
时空图卷积网络在人体异常行为识别中的应用
2022-06-23 06:24:40张蔚澜
计算机工程与应用 2022年12期
张蔚澜,齐 华,李 胜
1.西安工业大学 电子信息工程学院,西安 710021
2.南昌工程学院 信息工程学院,南昌 330200
监控摄像头在公共安防中发挥着巨大的作用。目前在许多公共场所的安防监控系统中,大多仅由一位或少数几位监控人员依靠“多画面分割器”来发现可疑目标。这种方式会给监控人员带来一定的视觉疲劳,导致监控效率低下,很大程度上失去了实时监控的意义。因此,通过对监控视频进行算法分析,辅助监控人员的安防工作,为保证社会公共安全提供强力而有效的手段。目前,深度学习使用特征学习和分层特征提取的高效算法自动提取来代替人工获得特征,以其强大的学习能力、高适应性、可移植性等优点成为研究的热门[1]。
近年来,行为识别是视频理解任务中一个重要的研究方向。行人的动作可以通过多种信息识别出来,如人体骨架[2]、时空信息[3-4]、光流信息[5-6]以及时间特征[7]等。文献[8]将视频分为描述静态信息的空间部分和描述运动信息的时间部分,分别训练模型再进行融合,获得较好的性能,但该方法不适用于长时间跨度结构的建模,且视频中提取光流需要大量的计算,很难达到实时性的要求。文献[9]和[10]采用三维卷积核提取动作的时空特征从而获取视频流的运动信息,该模型在机场监控视频下对人体行为识别,取得了较好的性能,但是由于三维卷积网络计算量大,影响算法效率。
人体骨架在行为识别任务中往往能传达更多的信息,现有使用循环神经网络[11-12]、时域卷积神经网络[13-14]等多种方法来提取骨架信息并对行为进行识别。文献[15]提出一种三维图卷积方法,引入具有三维采样空间的图卷积核,从时间与空间两个维度同时实现行为空间与时间信息的采集,同时设计了注意力增强结构来增强对于特定关节的关注,提升网络的识别能力;Yan等[16]提出一种在时间和空间分别卷积的动作识别网络,每个卷积层用一个图卷积算子描述空间特征,一个卷积算子描述时间特征,在NTU-RGB+D[17]和Kinetics数据集[18]上的识别精度达到较高水平,但该网络聚合节点特征仅用边上权值替代聚合操作中的权重,这种方式使网络对部分行为的识别能力有限。基于目前的研究现状,本文提出了一种基于时空图卷积网络的行为识别方法,通过姿态估计算法来提取骨骼关节点,并与融合了图注意力机制的行为识别算法相结合,进行人体姿态行为分析,从而有效提高了行为识别准确率。
1 系统框架
1.1 系统介绍
基于时空图卷积网络的人体异常行为识别系统的实现框架如图1所示,主要包括人体行为获取模块、骨骼关节点检测模块和行为识别模块这3个部分。该系统首先通过OpenPose算法对人体骨骼点进行检测,然后利用关节点数据进行骨架拓扑图结构搭建,最后与改进的时空图卷积行为识别算法相结合以实现人体异常行为识别。
1.2 系统流程
基于时空图卷积网络的人体异常行为识别系统处理流程如图2所示,其主要处理步骤如下。
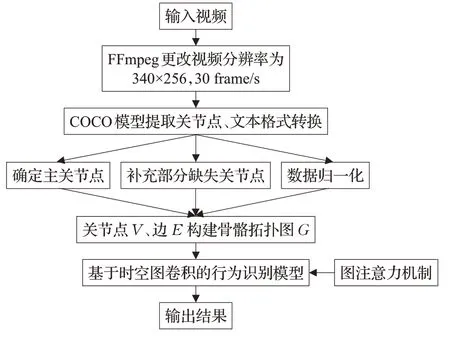
图2 人体异常行为识别系统处理流程图Fig.2 Processing flow of human abnormal behavior recognition system
2 系统模型
2.1 骨骼关节点的检测
骨骼关节点检测模块主要检测人体骨骼关节点,本文使用OpenPose[19]人体姿态估计算法完成该模块的检测,使用COCO数据集中人体关节点标注模型得到18个骨骼关节点,最终拼接成人体姿态特征生成树,身体关节点与序号映射关系如图3所示,18个身体关节点序号将作为后续行为识别模块拓扑图结构构建的依据。
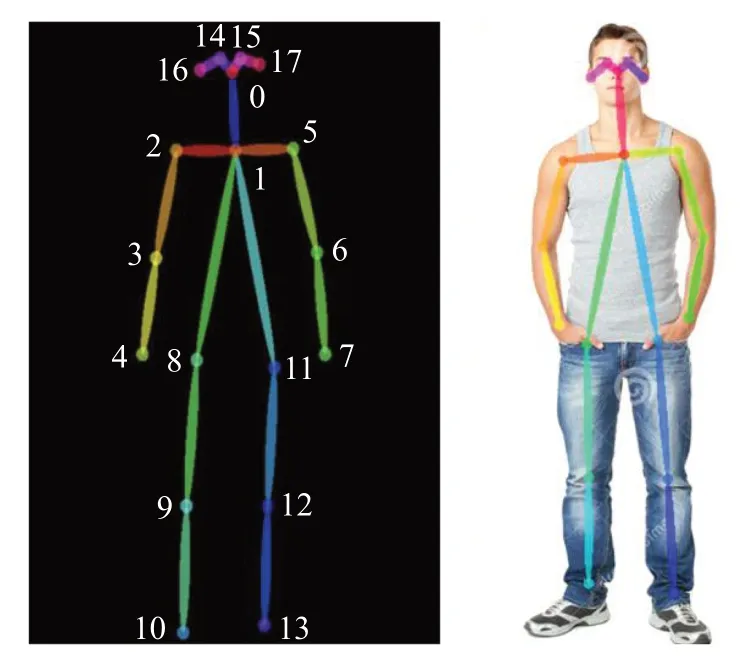
图3 人体姿态特征生成树、人体关节点映射关系图Fig.3 Spanning tree of human posture features and mapping relation diagram of human joints
2.1.1 基于OpenPose的人体关节点检测原理
(1)关节点的检测
OpenPose首先通过关节点置信图(confidence maps)来检测骨骼点的位置。每个关节点置信图表示不同关节在每个像素位置的可能性。
首先为帧图像中行人k生成单人置信图,如式(1)所示,xj,k∈ℝ2是行人k的身体关节点j的标注点位置,δ控制峰值的扩散。当像素点p靠近标注点xj,k时为置信图的峰值,如果图片中只有一个人,则每个关节点置信图中只有一个峰值。
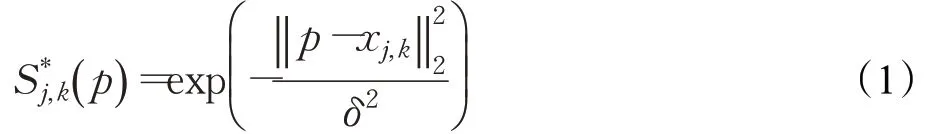
当图像中存在多人时,取多个关节点置信图中的最大值作为关节点的峰值,则每一个人k的每个可见关节点j都有一个峰值,如公式(2)所示,置信图的峰值点即为检测的关节点。

(2)关节点的关联
接下来利用候选关节对之间的部分亲和域(part affinity fields,PAFs)来建立骨骼区域模型,2D向量来综合像素点的位置和方向两种信息,如图4所示,以人体小臂检测为例,已知肘部关节点xj1,k和手部关节点xj2,k的位置,当像素点p在小臂c上时,则L*c,k()p的值是一个从xj1,k指向xj2,k的单位向量υ;对于其他点,值为0:
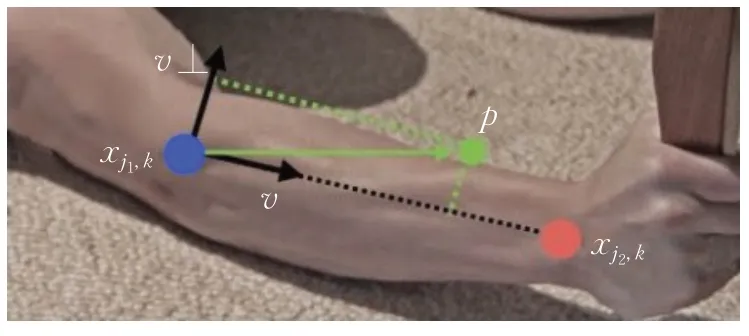
图4 小臂处关节点连接示意图Fig.4 Schematic diagram of joint connection at forearm
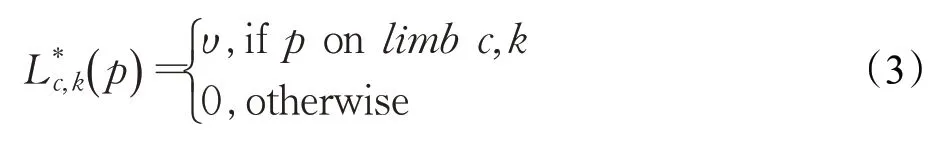
帧图像所有人的PAFs求平均得到标注的人体亲和字段,如式(4)所示。其中nc(p)是所有人体部分亲和字段在像素点p是非零向量的个数。
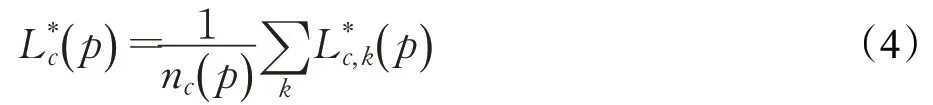
对于任意两个关节点位置xj1和xj2,计算PAFs的线性积分来表征关节点对的关联置信度E,如式(5)所示,p(u)为xj1和xj2连线上的像素点。
(3)多人关节点匹配
当监测画面中存在多人,对置信度图执行非极大值抑制,获得离散的关节点位置候选集,同时对存在的若干个节点匹配候选。根据关节点的关联性PAFs,将关节点作为图的顶点,关联置信度E为图的边权,多人关节点连接问题就转化为二分图匹配问题的集合,用匈牙利算法找出肢体c连接集合Zc边权和最大的组合,其数学表达如式(6)。每两个节点之间同步匹配,得到最佳的时间复杂度。m、n分别为关节点类型为j1、j2的集合Dj1、Dj2中的点,Zmn j1j2的值为0或1来表示第n个j1关节和第m个j2关节是否相连。
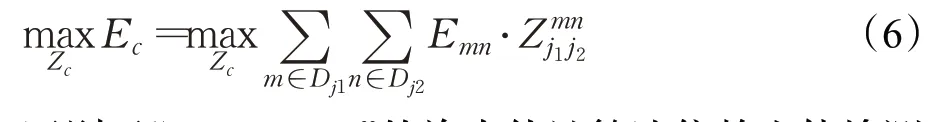
区别于“Up-Bottom”的姿态估计算法依赖人体检测框的结果,Openpose采用“Bottom-Top”的检测思想,避免了检测框漏检而检测失败的问题,检测过程快速高效;创新地使用了PAFs,即使图像中人数较多,但结合肢体向量与位置信息进行关节点快速匹配,使检测更具有鲁棒性,完成了多人实时的关节点检测。
2.1.2 骨骼数据的优化
OpenPose算法完成了从图像格式(.jpg)到骨骼数据格式(.txt)转换,将获取到的多帧骨架图数据保存为形式。x,y表示该关节点在当前帧画面中的横、纵坐标,s表示该关节点的置信度,m表示帧画面中第m个人员实例。由于同一个动作的不同帧之间可能会出现漏检的情况,需要对骨骼关节点数据进行处理,过程如下:
(1)确定主关节点。由图3可知,有且仅有脖子关节点(No.1 neck)连接所有关节,所以将脖子关节点定为主关节点。若一套动作的图像中,某个人所有的帧都未检测到主关节点则剔除该套动作,并在剔除后根据检测到的主关节点数重新确认图像中的人数。
(2)部分关节点缺失的处理。检测时当人体某一部位被遮挡或侧身于摄像头,部分帧会丢失部分关节点,但行为识别的网络要求输入的关节点数量是一定的,因此需要对缺失的关节点进行处理。由于关节点数据以每一帧的顺序进行排列保存,这里采用K最近距离邻法(K-means clustering)的思想,选择邻居K的值为2,以帧距离为度量,根据最近邻帧特征加权[20]预测:若第t帧的第i个关节点数据pi()t缺失,则利用与该帧最邻近的、第i个关节点数据未缺失的前后两帧t1、t2,将不同距离的邻帧对缺失帧产生的影响给予不同的权值,补充后的关节点数据为:
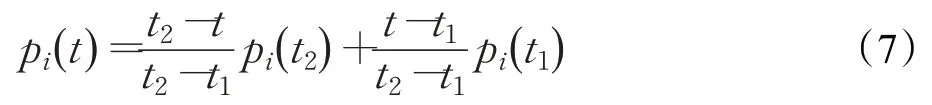
该缺失值补充方法得到的值较为科学准确,由于仅利用前后两帧的数据进行估计,计算量小,几乎对检测过程没有影响,并且缺失值的补充使后续行为拓扑图结构的构建更加完整,提高了网络识别的准确性。
(3)关节点数据归一化处理。Openpose算法提取的关节点坐标不仅与行为动作有关,还与人体在画面中的位置,距离摄像头的远近都有关系,用来识别的关节点特征应只与当前的行为动作有关,应对其进行归一化的处理[21]。归一化处理如式(8)所示:
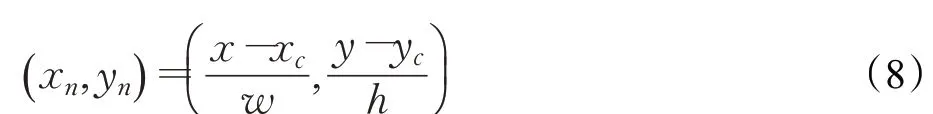
其中,(x,y)表示关节点坐标,(xc,yc)表示主关节点的坐标,w、h表示图像的尺寸,(xn,yn)为归一化后的关节点坐标。
2.2 融合图注意力机制的时空图卷积行为识别
本文主要针对百货商场这类室内公共场所,通过对行人的关节点坐标及置信度进行时空图卷积建模来实现行人的行为识别。模型从空间上的图卷积来提取空间信息,前后相邻帧的常规卷积来提取时间信息,二者的串联叠加逐步将每个节点的感受野扩大到时空范围。
2.2.1 空间图卷积网络
骨架数据是由OpenPose算法得到一系列帧关节坐标,已知人体关节点与序号的映射关系,以关节点为图节点V,以时间和关节点的自然连接为边E,构造时空图G。
图卷积网络能够将卷积神经网络的特性运用到图结构数据中去,核心思想是将边的信息发挥到节点信息中,利用聚合操作来表示新的节点特征。图卷积层节点聚合如公式(9)所示:

在考虑聚合节点i的度D̂ii同时,还应考虑被聚合的领节点j的度D̂jj,因此使用几何平均数来对度节点的特征值进行归一化从而降低不同度数量上特征值之间的差距。归一化处理后图卷积网络定义如公式(11)所示,W为图卷积层的权值矩阵。

在骨架图上卷积时,每一个节点的邻节点数是不固定的,无法进行卷积操作,因此定义空间配置划分将邻域分为3个子集,如图5所示。其中重心是骨骼节点坐标的几何中心。
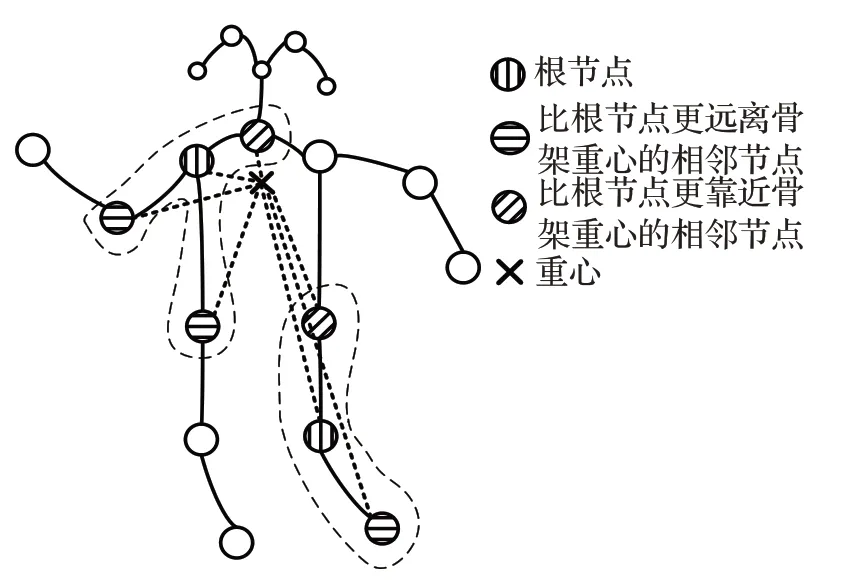
图5 图卷积领域划分规则图Fig.5 Graph convolution domain division rule graph
2.2.2 时间卷积网络
时间卷积中节点形状固定,使用传统的卷积层进行时间特征提取:按时序排列得到骨架空间-时序信息表达矩阵,如公式(12)所示。矩阵的维度为C×T,T为帧数,C为关节点信息,这里用姿态估计算法得到的关节点信息(x,y,s)可以类比于RGB图的R、G、B三个通道,该矩阵中的每个元素代表了一类特征通道在某一帧中的人体的关节点特征信息,V为18个关节点,M代表图像中人数。

2.2.3 融合图注意力的人体关节点动作识别
由公式(11)可知,原始图卷积在聚合邻节点特征时仅利用邻接矩阵A这一基于图结构的标准化常数来表示节点聚合的权值,这一点限制了模型对于空间信息相关性的捕捉能力,因此本文借鉴图注意力网络[22]的思想对关键节点进行自适应聚焦,通过计算中心节点与邻节点之间的注意力系数,捕捉骨骼节点之间的动态关联,突出具有行为判别性关节点,从而提升模型识别能力。
图注意力机制利用隐藏的自注意(self-attention)层,为图中的每个节点依据邻节点的特征分配不同的权值,并通过模糊注意力(masked-attention)将注意力机制引入到骨骼图结构中。关节点特征聚合与图注意力机制融合过程如下:
(1)关节点特征自注意力处理,来表示节点j对节点i的相关性,公式为:

其中,Xi、Xj分别为中心点i与其邻节点j的特征向量;W∈RCin×Cout是可学习权重矩阵,得到相应的输入与输出节点特征的转换。a()⋅表示对节点实行自注意力机制,利用拼接好节点特征及可学习的权重向量进行点积运算,学习节点i与节点j之间的相对重要性,a:RCout×RCout→R。这种方式可以忽略图结构性的信息,允许所有节点之间计算相互影响。
(2)时空图卷积层间数据变换。为增强层间特征聚合变换的非线性表达能力,引入LeakyReLU函数对层间的数据进行变换。经过激活函数处理后的注意力系数如式(14)所示:
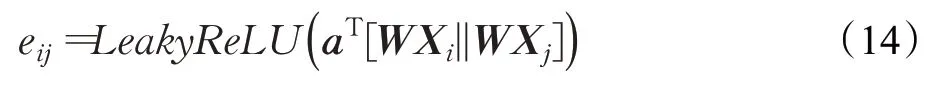
(3)模糊注意力处理及归一化。在构建好的邻接矩阵A基础上,利用模糊注意力,将注意力分配到节点i的邻居节点集B( )vti来聚合一阶邻节点的信息,并对所有i的邻节点j进行正则化,αij∈R3×V×V,因此注意力系数为:
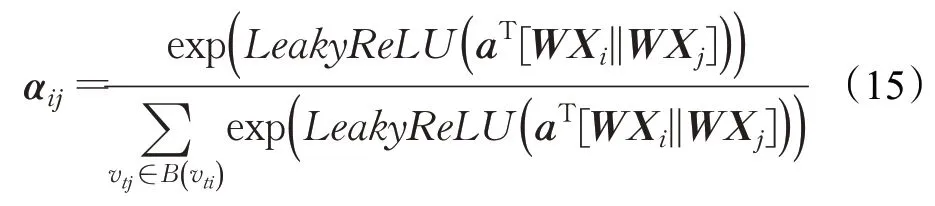
(4)节点间特征加权求和。节点i经过融合图注意力机制的图卷积层加权求和后的特征为:

Aatt是经过注意力系数加权后的邻接矩阵。
在原有特征更新的基础上,图注意力网络更巧妙地利用了骨骼节点之间的特征相互联系,多节点计算并行,为每个节点区分出了不同的重要度,增强了行为识别任务中需要的有效信息,对干扰节点信息更加鲁棒;且中心节点特征的注意力权重以邻节点特征为依据,独立于图结构,使得该模型可以处理不同的邻节点数目的骨骼关节点。
2.2.4 时空图卷积网络模型搭建
基于上述图卷积操作,构建用于人体异常行为识别的时空图卷积网络模型。模型建立过程如下:
(1)为了加快模型收敛,首先设置归一化层(batchnorm layer)对batch方向数据进行归一化。
(2)为提取更大范围的动态时空相关性,时空图卷积网络模型由9个时空图卷积层叠加,每层交替地使用融合了图注意力机制的图卷积A-GCN和时域卷积TCN,并在第4层和第7层时间卷积后设置步长为2。
(3)对上一层输出的数据使用全局池化层(global pooling layer)汇总节点特征来表示整个图的特征。
(4)最后一层为全连接层(fully connected layer),输出结果为模型识别行为的类别。网络模型结构如图6所示。
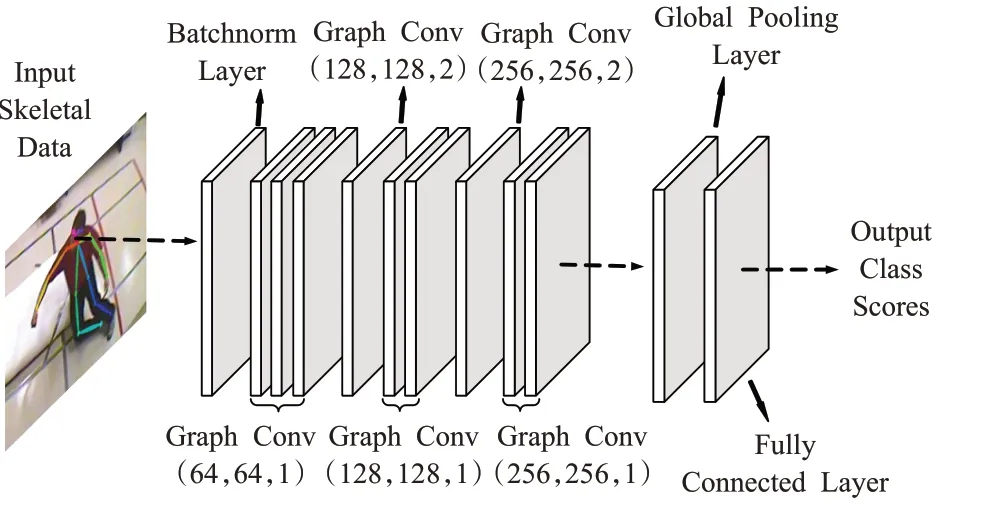
图6 基于时空图卷积网络的行为识别模型宏结构Fig.6 Macro structure of behavior recognition model based on spatial temporal graph convolutional networks
本文用[B,C,T,V,M]的张量来表示一个人体骨骼行为识别初始输入数据,其中B为训练批次;T代表行为关键帧的数量;M表示关键帧中的人数;V表示关节点数量;C代表关节的特征数。表1展示了模型每层参数配置。
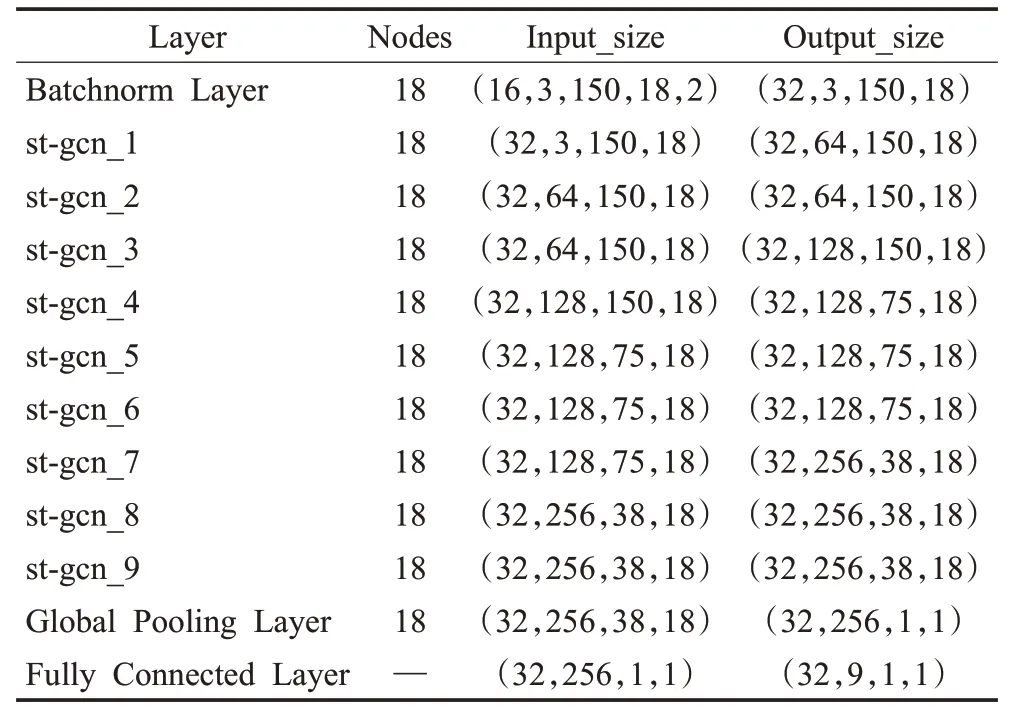
表1 时空图卷积网络参数配置Table 1 Spatial temporal graph convolution network layer parameter configuration
3 实验与结果分析
3.1 骨骼关节点检测结果与分析
为验证OpenPose对实际环境的适用性,该部分实验将光线环境、待检测人数以及目标大小作为变量,来验证不同条件下的检测效果,检测结果如图7、图8所示。
图7显示了在光照充足环境下OpenPose对行人的关节点检测效果:帧图像中行人四肢拍摄完全时,检测效果良好,关节点基本匹配正确,即使图7(b)画面右侧行人四肢拍摄不完全,但检测算法对被遮挡部分的关节点不会任意获取,只对看得到的部分进行检测,不会造成后续行为的误判;图8以傍晚的拍摄条件来模拟光线较暗的情况,可以看出,即使光照较暗时也能够对行人进行匹配,证明OpenPose对光线条件不充足的环境有很好的适应性。

图7 光照充足环境下的OpenPose检测图Fig.7 OpenPose detection diagram in well-light environment
图8 光线较暗环境下的OpenPose检测图Fig.8 OpenPose detection diagram in low light environment
根据检测结果可知,在光照环境、人数以及目标大小三种变量变化的情况下,基于OpenPose的骨骼关节点检测方法可以有效提取人体的骨骼关节点,后续结合骨骼关节点的优化方法,使得到的骨骼节点数据信息更加完整,有利于行为识别任务的推进。
3.2 人体异常行为识别结果与分析
本文使用的数据来源主要为新加坡南洋理工大学制作的NTU-RGB+D人体行为数据集。为增加模型识别的对比性,识别的行为分为正、异常两大类,包括站立(stand up)、坐下(sit down)、行走(walking)、摔倒(falling down)、脚踢破坏(kicking something)、脚踢(kicking)、推搡(pushing)、出拳(punch)、指点(point finger)。
3.2.1 模型评价指标
数据集包括4 314个骨架训练数据,1 074个骨架测试数据。训练过程进行576 000次迭代,优化器为Adam,权重衰减系数为10-4,学习率为10-3,测试集上评价指标使用交叉熵损失函数以及准确率,定义如式(17)、(18)所示:

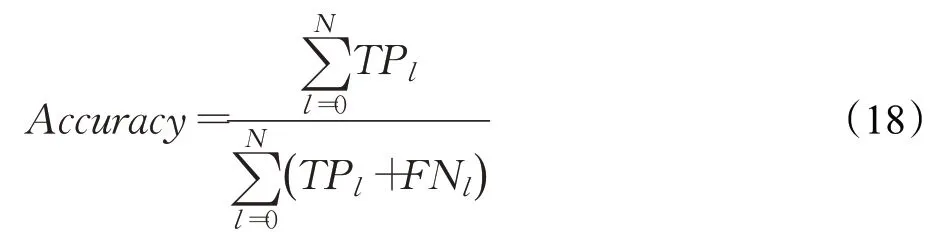
yi是全连接层的第i个输出,表示第i类动作的概率值;m是批量大小;N是动作的类别数;TP(True Positives)为正确识别行为的样本数;FN(False Negatives)为错误识别为其他类的样本数。
3.2.2 模型性能实验
首先验证模型使用不同激活函数对网络性能的影响,在融合图注意力的模型上进行实验,测试集上结果如表2所示,LeakyReLU函数明显提高了模型的识别准确率。这是由于训练中,LeakyReLU函数在输入为负数区域内给予非常小的线性分量来调整负值的零梯度,本文搭建网络层较深,使用Leakyrelu函数有助于确保梯度能够贯穿整个模型架构,同时加快网络收敛速度,提升网络性能。而ReLU函数在输入为负时转换为0,激活层可能对一些特征屏蔽,造成网络中存在部分“坏死”,有效特征的学习能力相较于LeakyReLU函数弱。

表2 不同激活函数对网络性能的影响Table 2 Impact of different activation functions onnetwork performance
对模型在本文建立异常行为数据集上进行验证。使用融合注意力机制识别模型与未融合的模型在数据集上得到的损失变化对比如图9所示,两种模型整体均趋于收敛状态,但融合前的模型总体收敛趋势相比于融合后模型收敛趋势慢,融合后的模型在迭代25 000次左右时呈现出逐渐收敛的状态,对比融合前收敛速度要快。
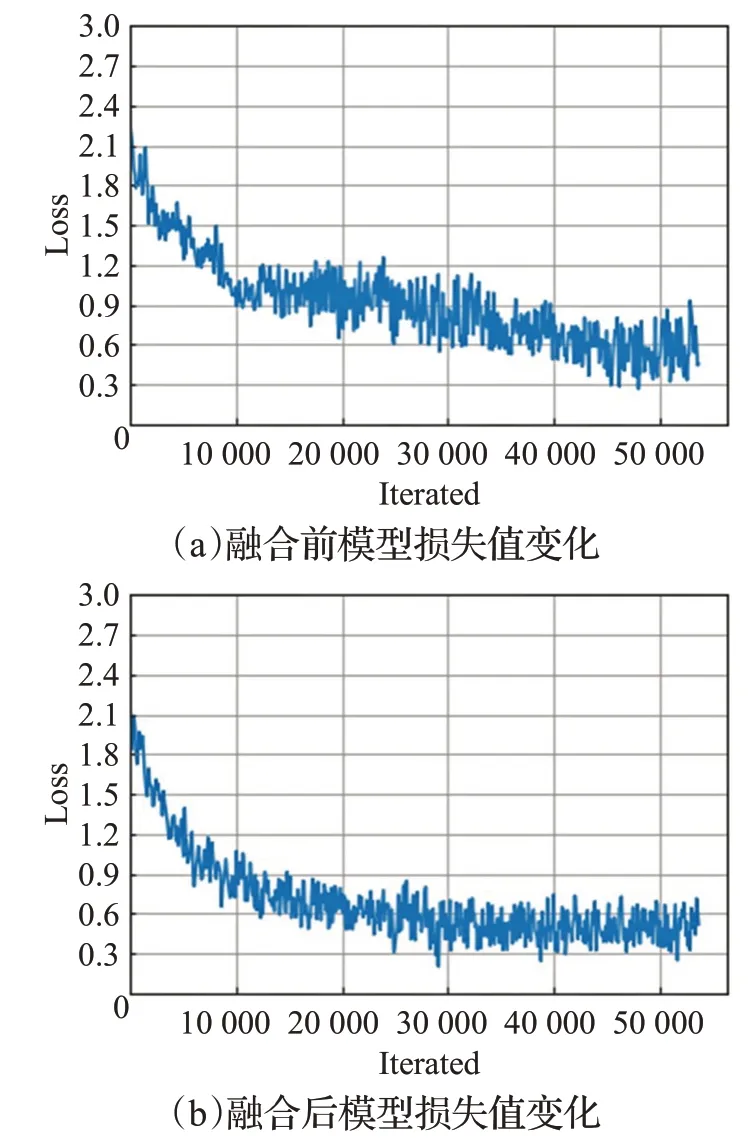
图9 模型损失值变化对比图Fig.9 Comparison diagram of model loss value change
图10为测试集平均准确率变化情况,融合前模型在测试集上的平均准确率在训练120轮次之后最高仅维持在80%左右;融合后的平均准确率在训练60轮次之后稳定在80%~90%,最高时为87.96%,相比融合前高。
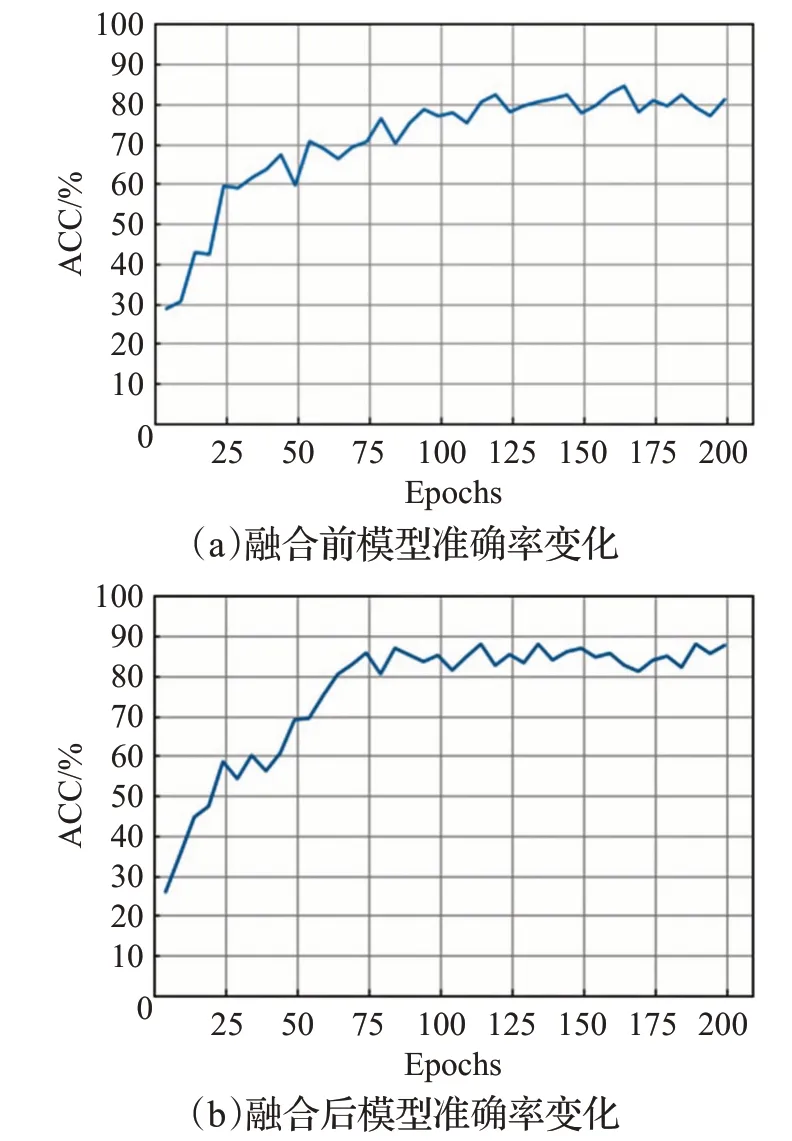
图10 模型准确率变化对比图Fig.10 Comparison diagram of model accuracy change
然后调用torchstat对模型相关参数进行分析,如表3所示。该表是输入尺寸为(16,3,150,18,2)的Tensor后的结果,为了表简洁直观,9个时空图卷积层中各卷积层的参数已做合并处理。
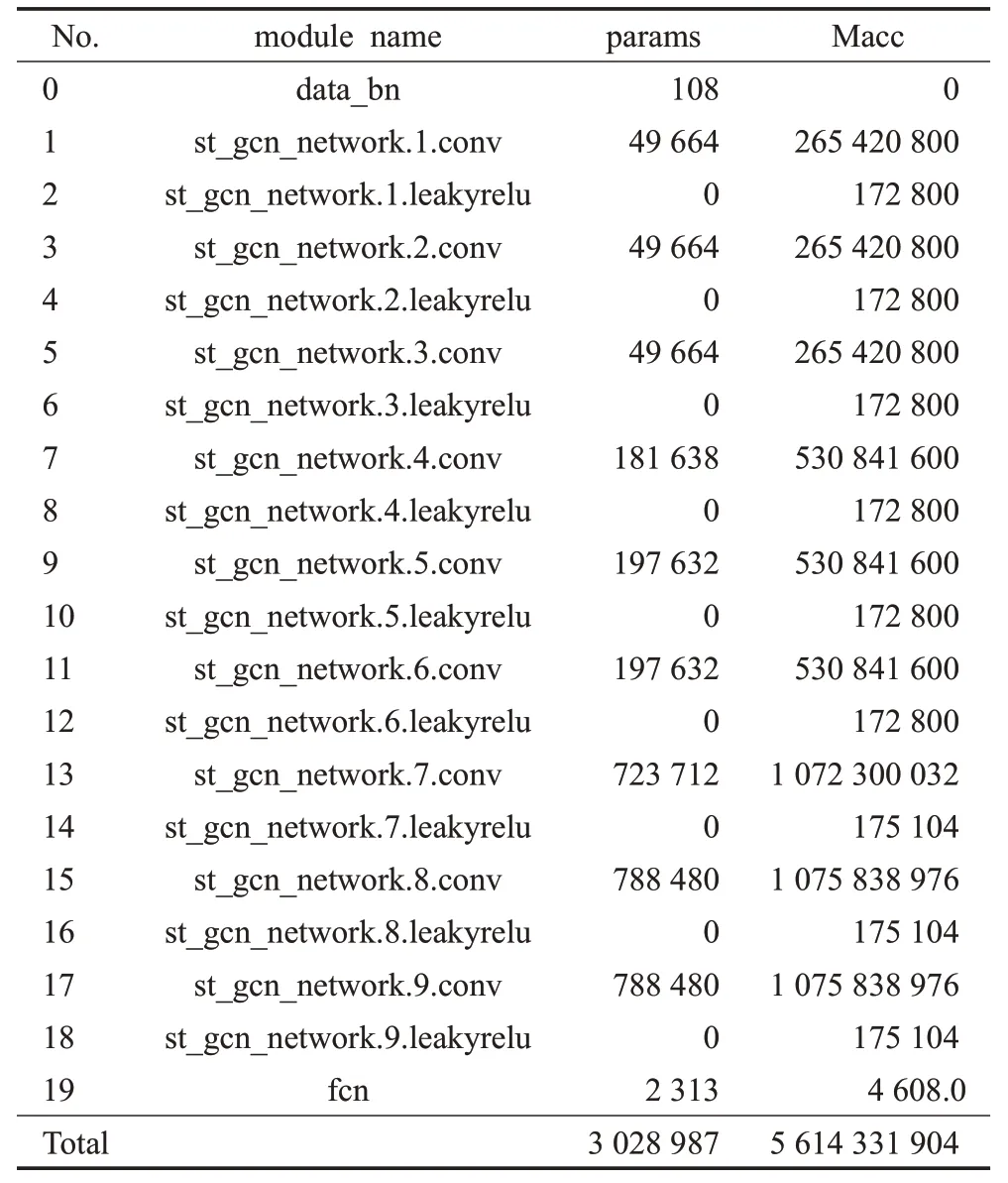
表3 人体异常行为识别网络模型参数Table 3 Human abnormal behavior recognitionmodel parameters
从模型的空间与时间复杂度两个方向分析:空间复杂度与模型的参数量(params)有关,由于空间复杂度只与卷积核大小、通道数以及网络深度相关,本文对模型融合注意力的操作并未改变这三种变量,因此融合后参数数量与融合前变换不大,空间复杂度低,约为2.89 MB(对结果进行单位转换);模型计算量影响时间复杂度,本文使用模型的运算次数(multiply accumulate operation,Macc)来衡量,融合后每一层空间图卷积增加了关节点间特征变换的拼接,但自注意力的拼接操作是在所有边上并行,且图卷积输出特征的计算在所有节点上并行,不需要特征分解或复杂的矩阵运算,未给融合前的模型增加大量的计算复杂度。但模型运算量约为5.23 GB,预测速度、实时性在算力较低的计算平台上可能会受到一定影响。
经分析,模型在本实验使用计算平台上虽然会略微牺牲检测时间,但关节点特征融合注意力的方式,使节点特征随着行为自适应聚焦,从而区分行为识别中的关键节点,提高了识别准确性。
3.2.3 图注意力机制对行为识别影响的验证实验
为验证融合图注意力机制是否能提升模型对行为的识别能力,本文分别对图注意力机制的节点特征自适应聚焦和行为识别的准确性进行实验。首先对打架、摔倒以及破坏公物(脚踢)三种异常行为的视频截取关键帧,将骨骼结构的18个关节点注意力权重进行可视化,如图11所示,该热力图显示了模型对不同关节点的关注程度。
图中行为执行时关节点位置的圆点大小代表不同节点特征的重要程度,而热力图色调越暖代表该关节所占权重越高。图11(a)的行人在有脚踢和推搡行为的打架过程中,模型将节点注意力关注在头部(鼻子)、胯部、膝盖、肩部、手肘和脚这些关节点上;图11(b)的摔倒行为有身体侧倒向地面和侧躺于地面,摔倒过程中胯部、膝盖、手腕和手肘关节点对摔倒行为识别的贡献程度较大,因此模型更关注这些关节点的信息;图11(c)的破坏行为执行人侧向站立于摄像头,脚踢行为更集中于执行动作的腿部多个关节点,且胳膊摆动的动作,因此模型更关心胯部、膝盖、脚部和手肘的动作变化。以上实验表明,在注意力机制的作用下,模型能够基于时空信息对邻节点间信息进行聚焦,强调提供关键信息的身体关节,并对其进行更多的关注,验证了图注意力机制在自适应聚焦行为特征上的有效性。
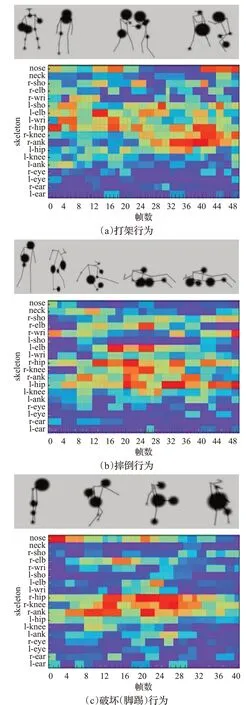
图11 注意力热力图Fig.11 Attention heat map
接下来在包含九种行为的测试集上验证图注意力机制对识别准确性的影响,这里利用混淆矩阵来表示。融合图注意力机制前后模型的识别结果如表4和表5所示,表中数字代表模型识别的统计结果。
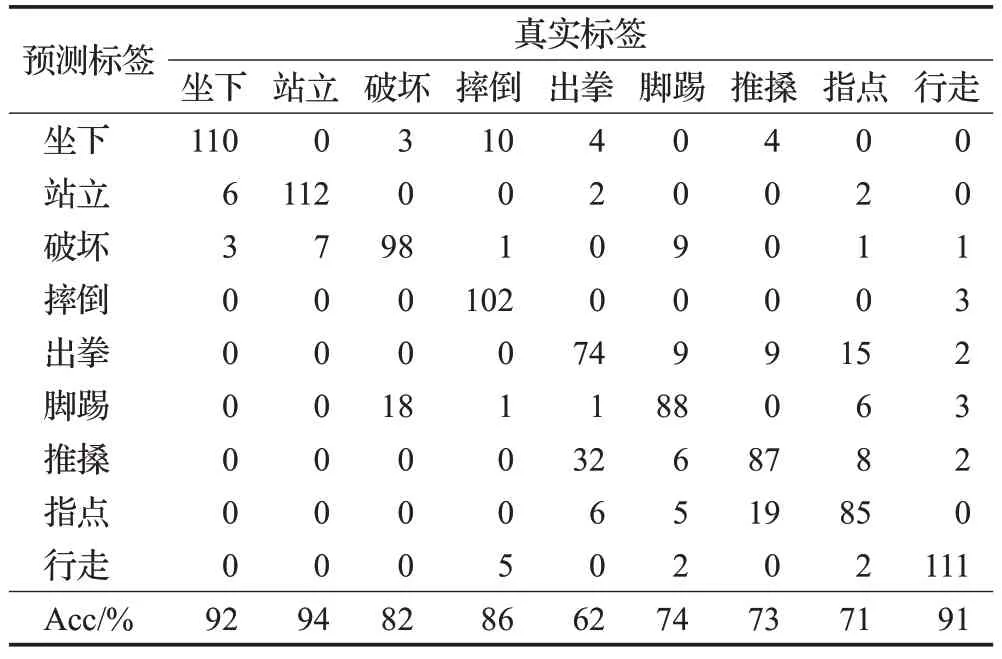
表4 未融合注意力机制的行为识别混淆矩阵Table 4 Behavior recognition confusion matrix for unfused attention mechanism
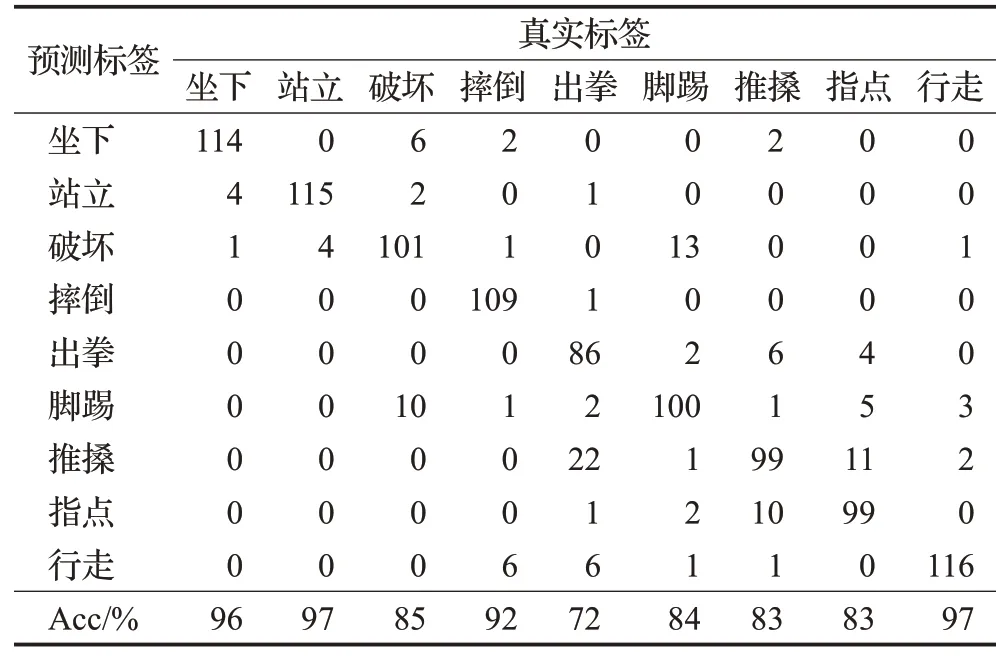
表5 融合注意力机制后的行为识别混淆矩阵Table 5 Behavior recognition confusion matrix after integrating attention mechanism
通过对比,九种行为的识别准确数量(矩阵主对角线方向)在融合后均有不同程度的增加,以出拳为例,准确识别数相比融合前增加了12个(约10.1%),同时对推搡行为的错误识别减少了10个(约8.4%),结合之前关节点特征聚焦的效果来分析:图注意力机制能够自动衡量出不同节点的重要性,指导模型根据动作寻找关键的骨骼节点,使其在识别过程中突出了具有判别性的关节点,弱化不同动作中对识别影响很小的节点信息,证明了利用注意力机制区分节点重要性对提高模型识别的准确性具有明显作用,同时对表现相似的行为,模型也能根据有效的时空节点特征学习节点之间的动态关联,对部分不易区分行为的识别准确性也有所提升,进而证明了融合图注意力机制的时空图卷积网络对识别异常行为的优越性。
3.2.4 模型有效性验证实验
在540个短视频验证集上验证本文的异常行为识别模型,视频来源于真实监控、志愿者模拟以及本文定义的相关行为视频,所有视频拍摄角度均符合真实监控摄像角度。图12为本文所提模型对定义的行为进行识别的部分结果,其中对于双人打架的行为,由于在日常中打架行为过程复杂,通常由多个行为组成,因此将打架行为分解为本文定义中的脚踢、推搡、出拳、指点这些行为,在识别时,检测到这四类行为中的两类则认为成功识别出打架行为。

图12 行人行为识别部分结果Fig.12 Partial results of pedestrian behavior recognition
表6为行为识别模型在540个短视频验证集上的分类结果。可以看出,模型对这9类行为的识别准确率绝大部分达到80%以上,但对于出拳行为识别结果较差,这是因为出拳侧重于人体双臂部分的动作,相较于指点这种同样侧重手部行为的动作来说,行为特征相似,不易区分,并且识别同样也受行为执行者拍摄角度的影响,动作的关节信息可能提取无效,模型无法学习到行人手肘部位间的行为特征,使得识别的准确率存在一定的偏差。但本文所使用的实验平台上,基于时空图卷积网络的人体异常行为识别方法在验证集中的准确率高达85.48%,其中对异常行为识别的准确率达到81.63%,这说明该模型对公共场景中的异常行为有良好的识别效果,在实际监控视频中具有一定的检测有效性。
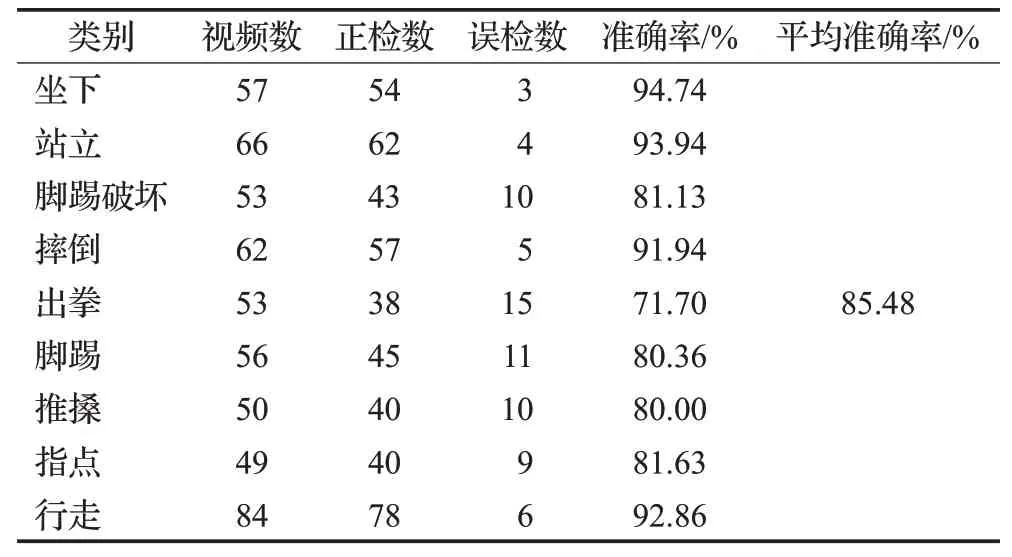
表6 融合注意力机制的模型识别结果Table 6 Model recognition results integrating attention mechanism
4 结束语
为了解决室内公共场合下监控资源短缺,行人异常行为容易发生漏检的问题,本文结合姿态估计算法,通过OpenPose检测到人体骨骼关节点特征信息来构建骨骼关节点图拓扑结构,利用融合了图注意力机制的时空图卷积网络对行人的异常行为进行识别,在数据集上9类行为的平均识别准确率达到87.96%,在验证集上的平均识别准确率达到85.48%。实验结果表明,所提融合图注意力机制的时空图卷积行为识别模型可以有效聚合节点特征,为每个关节点区分不同的重要程度,最终提高了异常行为识别的准确率。
需要指出的是,本文在对行人的破坏公物行为进行识别时,虽然利用所提的行为识别模型得到了较为准确的识别结果,但这仅说明模型能够较好地提取出能区分这些动作之间的特征,并未考虑动作与已知公共设施的相对位置。针对在实际的行为识别中,如何结合异常行为与公共设施的交互进行判断,拟在后续研究中进一步展开。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
科学技术创新(2021年19期)2021-07-16 10:07:04
沈阳航空航天大学学报(2020年6期)2021-01-27 02:11:30
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
军营文化天地(2017年6期)2017-06-28 11:30:19
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
电视技术(2014年19期)2014-03-11 15:38:20
