
非自回归翻译模型在蒙汉翻译上的应用
2022-06-23 06:25:08苏依拉仁庆道尔吉
计算机工程与应用 2022年12期
赵 旭,苏依拉,仁庆道尔吉,石 宝
内蒙古工业大学 信息工程学院,呼和浩特 010080
机器翻译(machine translation,MT)[1],是指借助计算机处理将一种自然语言(源语言)转换为另一种自然语言(目标语言)的过程,它属于计算语言学研究的范围。自20世纪30年代机器翻译崭露头角开始,机器翻译的发展已经越来越迅猛。在当今的日常生活、学习生活中,已经越来越离不开机器翻译的支持,其对于促进文化交流、促进多元交流有着十分重要的作用。目前机器翻译的发展历程经历了基于规则的机器翻译到基于统计的机器翻译[2],再到如今基于神经网络的机器翻译(neural machine translation,NMT),每一次的改进极大地推动了机器翻译领域的飞速发展。
蒙语机器翻译的研究最早在20世纪90年代提出了基于词典和基于规则的翻译方法,主要是研究日蒙机器翻译的研究[3]。蒙汉机器翻译的研究对推动内蒙古自治区的信息化、促进自治区社会进步和经济发展、繁荣和发展少数民族文化教育科技事业有着重要的意义,众多学者也提出了很多改进蒙汉翻译的方法[4-6]。在当前流行的翻译模型中,大多为编码器-解码器架构的翻译模型,且属于自回归翻译模型(autoregressive model)[7],自回归翻译模型在进行解码时,它们根据之前生成的序列生成当前序列,这个过程是不可并行的。
虽然当前主流翻译模型大多为自回归模型,也在众多生成任务中得到了广泛的应用,但是自回归翻译模型在蒙汉翻译过程中也存在着显著的不足:
蒙语语料较为匮乏,使用当前的翻译模型易导致数据稀疏和过拟合问题,语义信息的匮乏会影响上下文信息的依赖关系,进而造成蒙汉翻译质量不高[8]。
自回归模型的解码过程是串行输出的,当前序列依赖于之前生成的序列,导致生成时间复杂度比较高,一般借助GPU生成也需要很长的时间。
1 神经机器翻译模型
当前流行的神经机器翻译模型,大多为编码器-解码器结构,其流程为:将语料进行预处理,借助编码器编码生成向量,借助解码器对向量以及源语言信息进行处理,得到目标语言的翻译结果。
传统的NMT模型,无论是基于循环神经网络(recurrent neural network,RNN)还是基于Transformer的翻译模型[9],都可以归类为自回归模型。这里的自回归指的是在翻译目标语句时,模型是从左到右逐字翻译的,当前字需要依赖于上一生成的字,这就导致编码器-解码器模型进行推理生成时,只能逐字翻译,解码器不能并行输出。相比于自回归翻译模型,非自回归翻译模型克服了自回归模型性依赖于上下文输出的缺陷,借助于编码器的改进实现了并行输出,大大提升了生成的速率。同时借助于跨言词嵌入[10]和知识蒸馏技术[11],对蒙汉语料进行相应处理,缓解源与目标的依赖关系,缓解数据稀疏以及过拟合问题等。使非自回归翻译模型既有高准确率也有高生成速率。
在文献[12]中,基于Transformer翻译模型进行改进,提出了非自回归Transformer模型(NAT)在机器翻译上的应用,在同样的条件下,相比于Transformer模型,NAT翻译模型在生成速率上大幅领先Transformer模型,这是因为对编码器进行了改进,增加了一个Fertility模块[13],来统计源句每个词的出现次数,进而得到目标句子的长度,将Fertility与源句子的复制共同作为解码器的输入,实现翻译的并行输出。但也会导致翻译准确率的下降,而借助于知识蒸馏,将源语言与目标语言的依赖关系降低,进而同步提高翻译效果与生成速率。故本文基于Transformer和NAT蒙汉翻译模型,使用内蒙古工业大学所拥有的120万蒙汉平行语料作为实验数据,对蒙汉语料进行通用BPE处理和知识蒸馏处理做对比实验。
1.1 基于Transformer的神经机器翻译模型
2017年,谷歌提出了一种新的网络架构:Transformer。其完全基于注意力机制,克服了之前使用的卷积神经网络和循环神经网络所出现的问题,大幅度提升了机器翻译的效果。注意力是人类特有的一种能力,可以选择性地选取重点,注意力机制的提出便基于此[14]。Transformer建模公式如式(1)所示:
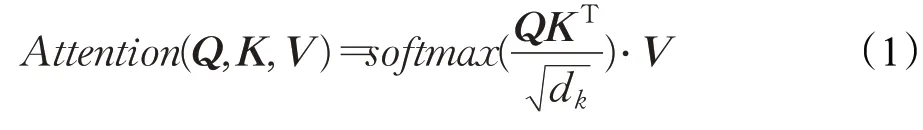
在自注意力层中,每个单词有3个不同的向量来表示,它们分别是Query向量(Q),Key向量(K)和Value向量(V),长度均是64,即dk。它们由嵌入向量X乘以三个不同的权值矩阵WQ、WK、WV得到,其中三个矩阵的维度也是相同的,均是512×64。其中为了梯度的稳定,Transformer使用了score归一化,即除以dk,softmax是激活函数,最终计算结果表明Q应该关注V中的哪些值,也就是句子中需要重点关注的语义信息,以及对应语义信息的关注度达到多少。
人类面对海量信息时,可以选择性地捕获重点信息,忽略掉无关信息,来获取关键信息。神经网络在处理大量输入信息时,也可以借助注意力机制选择性地获取处理一些关键信息,来提高神经网络的处理性能,Transformer翻译模型便是完全基于注意力机制来实现的。图1为基于注意力机制的Encoder-Deocder模型的结构[15]。
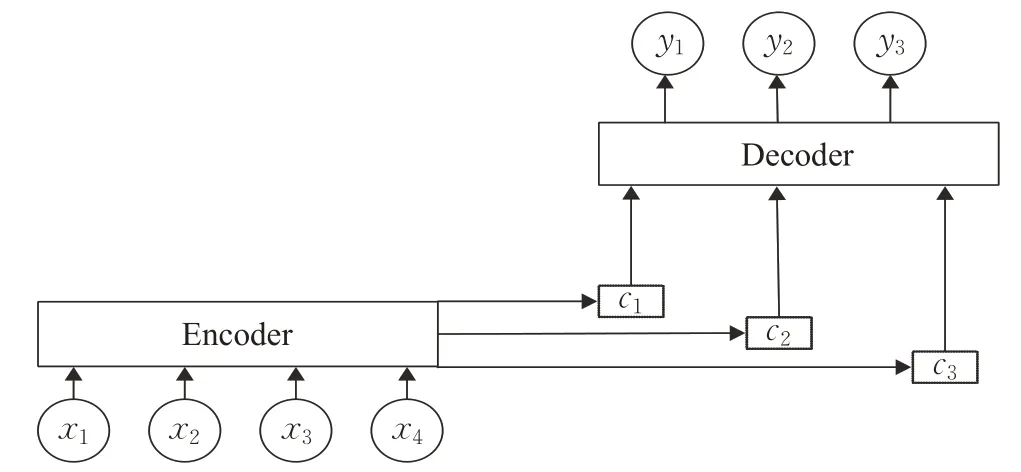
图1 基于注意力机制的编码器-解码器架构图Fig.1 Encoder-decoder architecture based on attention mechanism
Transformer模型的架构也是基于编码器-解码器。但其结构相比于之前更加复杂,包含六层编码器和六层解码器。图2为其基本架构图。
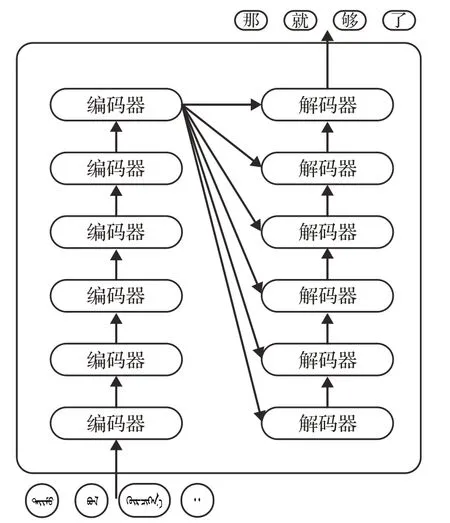
图2 Transformer基本架构图Fig.2 Architecture of Transformer
对于每一层的编码器和解码器,编码器包含两层:自注意力层与前馈神经网络。自注意力层能够帮助当前节点结合上下文语义信息来获得正确的语义理解。解码器除了包含以上两层外,在两层的中间还有一层注意力层,帮助当前节点获取当前需要重点关注的内容。图3为单层编码器-解码器的结构。
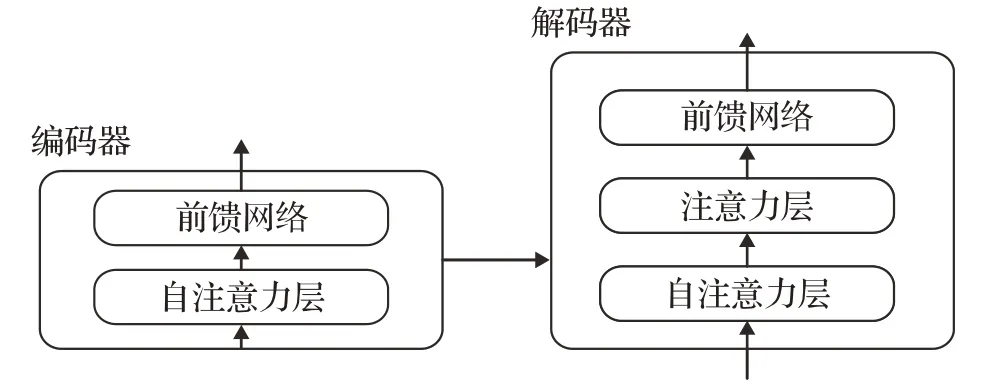
图3 单层架构图Fig.3 Single layer architecture
模型需要对输入的数据进行一个生成嵌入向量操作,得到嵌入向量后,输入到编码层,自注意力层处理完数据后把数据输入到前馈神经网络中,其计算过程可以并行处理,得到的输出会输入到下一个编码器。最终编码完成后,将其输入到解码层中,解码层全部执行完毕后,在结尾通过一个全连接层和softmax层,得到最终概率值最大的对应词就是本文得到的翻译结果。具体流程图见图4。
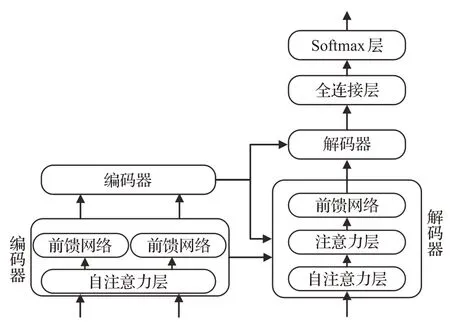
图4 整体流程图Fig.4 Overall flow chart
1.2 基于非自回归Transformer的神经机器翻译模型
相比于自回归模型相,非自回归模型在实现上主要有以下两个区别:一是解码器的输入,二是目标序列长度的获取。自回归模型解码器的输入是上一步解码出的结果,每一步解码生成都依赖于上一步解码的结果,当解码到EOS标志时,序列的生成过程便自动停止,得到最终的解码序列。而非自回归模型没有这样的依赖特性,克服了解码的串行输出,实现了解码器的并行输出。图5为两者区别。
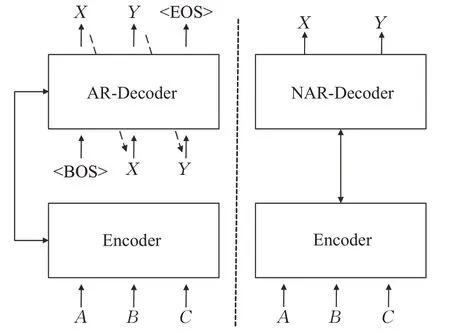
图5 自回归与非自回归模型区别Fig.5 Differences between autoregressive and non-autoregressive models
NAT翻译模型采用的也是编码器-解码器结构,与Transformer相比,是对编码器进行了改进,增加了一个Fertility模块,来统计源句每个词的出现次数,进而得到目标句子的长度,将Fertility与源句子的复制共同作为解码器的输入,实现翻译的并行输出。图6为非自回归Transformer的架构。
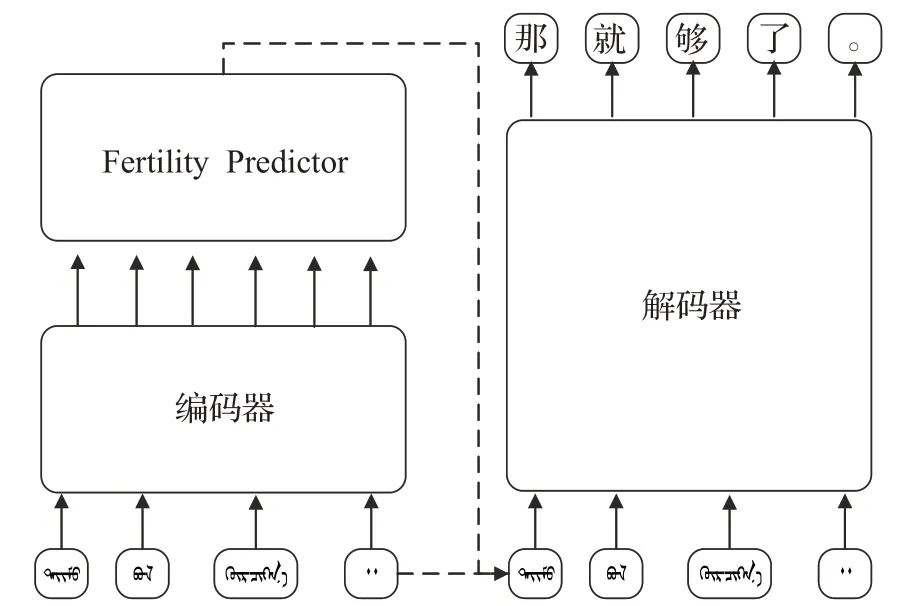
图6 NAT结构Fig.6 Architecture of NAT
不同于之前所提出的大多数语言模型,先前的翻译模型大多为自回归模型,在进行解码输出的时候要根据先前的输出来决定当前的输出,是串行输出,导致了解码速度过慢,而NAT通过对编码器的改进解决了这个问题,在基本维持翻译效果的条件下,大大提升了解码生成的速度。
2 相关技术
2.1 跨语言词嵌入
在当前机器翻译研究中,不同语言训练出来的词向量虽然是独立的,但是它们的分布形态却非常相似,两种语言中意义相近的词所代表的词向量在坐标空间上的分布非常相近,如图7所示。
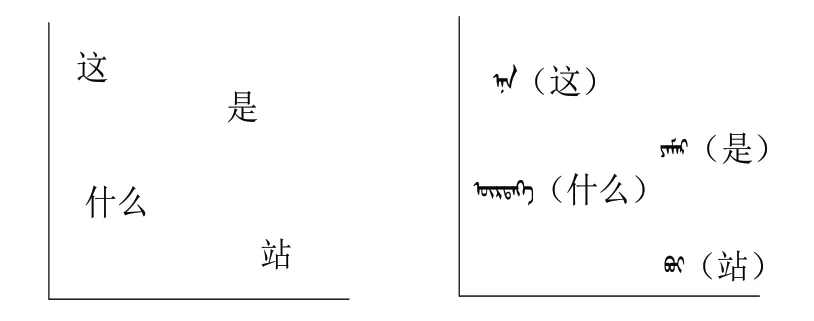
图7 双语向量空间分布Fig.7 Bilingual vector space distribution
因此可借助某种线性或非线性的转换[15],将蒙汉双语的词向量映射到同一个共享的空间中,使得意义相近却来自不同语言的词向量具有相近的词向量表征,缩小两种语言之间的表征差距。模型可以借助对方语义信息来推理词语含义,可以在双语之间进行知识迁移,数据量少的语言借助高资源语料来进行推理,提高翻译模型的效果。
为了从源空间映射到目标公共空间,一种常见的方法是学习一种最小化双语词典对应词对距离的线性映射。通用的做法是分别独立地对双语语料进行训练[16],得到两者的嵌入向量,对其进行学习训练,得到一种线性映射,使得最小化双语词典中列出的等效之间的距离,得到通用向量空间。
设X和Z表示给定双语字典的两种语言中的词嵌入矩阵,使它们的第i行Xi*和Zi*是字典中第i条的单词嵌入。本文的目标是找到一个线性变换矩阵W,使XW最接近Z,借助欧氏距离来进行评估,见式(2):
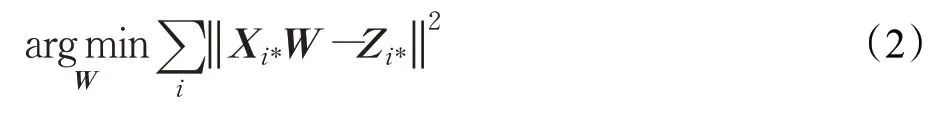
接下来进行最大余弦长度归一化处理,将两种语言中的词嵌入向量归一化处理为单位向量,保证了训练实例对优化目标有相同的贡献,见式(3):
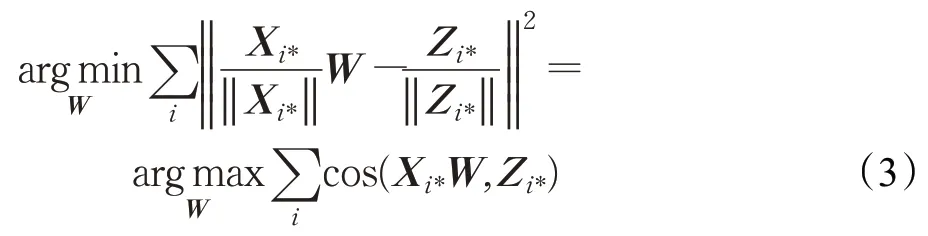
通过上述操作得到矩阵W来将两种语言进行嵌入映射,得到跨语言词向量,缩小两种语言之间的推理距离[17],提升机器翻译的效果。
2.2 知识蒸馏
虽然NAT模型通过改进编码器结构实现了解码器的并行输出,大大提升了机器翻译的速度,但解码阶段是完全独立进行的,而在实际的翻译中,最终翻译语句并不是条件独立的。条件独立性假设阻止了翻译模型正确地捕获目标翻译的高度多模态分布,模型忽略目标语言上下文信息会导致目标语义信息不充足以及翻译效果的降低。
而知识蒸馏方法可以在一定程度上解决这个问题,对数据集进行知识蒸馏处理可以在保持原有生成速率的同时,进一步提高翻译的效果。因此,应用知识蒸馏方法,来改善NAT模型的缺陷。
具体流程如下:首先需要训练一个自回归机器翻译模型,作为教师模型,在实验中为了设置方便,统一采用Transformer模型来作为教师模型;接下来,借助教师模型在训练集上进行集束搜索,构建新语料库,即蒸馏数据集;最后将蒸馏数据集应用在NAT模型(学生模型)中使用负对数似然(negative log likelihood,NLL)函数进行训练,来改善NAT模型翻译效果。其实现过程如式(4)~(7)所示:
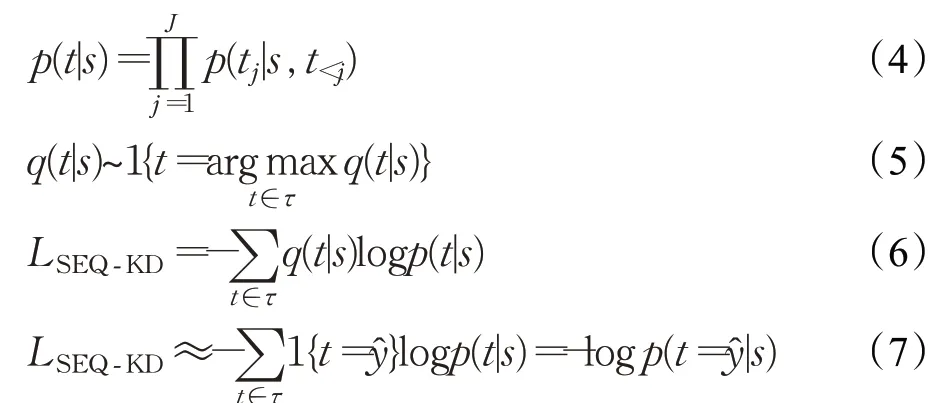
其中,p(t|s)是序列级分布,q(t|s)是教师模型在可能样本上的序列分布,对其取近似值,ŷ为借助教师模型进行集束搜索所生成的蒸馏数据集。其流程如图8所示。
在文献[18]中,分析了知识蒸馏方法在机器翻译中所起的作用,以及知识蒸馏如何起到促进作用的原因,了解其中的原理对该文实验有着极大的积极作用。借助于教师模型的集束搜索对数据集进行知识蒸馏,可以降低数据集的复杂性和减少目标端对上下文的依赖,更好地帮助NAT翻译模型模拟输出数据的变化,进而提升NAT模型的翻译效果。
3 实验过程
3.1 语料划分及处理
本文实验所用数据为内蒙古工业大学所拥有的120万蒙汉平行语料,语料库的格式为蒙语-汉语的平行语料,在使用之前需对语料库进行了筛选,将语料库中包含的文章类的内容进行了整理筛选,实验过程中没有使用文章部分,因为文章部分每一句之间上下文之间都存在依赖关系,对于非自回归模型并不友好,不能较好地实现非自回归模型的并行,故排除掉文章内容后进行语料划分。蒙汉平行语料数据集的划分如表1所示。

表1 数据集划分Table 1 Dataset partition
3.2 语料预处理
数据集划分完后,需对语料进行预处理,在本实验中对中文进行分词处理,分词流程包含停用词表的加载,将标点、语气助词、副词等出现频率很高的词进行筛选清除,降低停用词对有效信息产生的干扰。在蒙汉语料中适度地减少停用词的次数,可以提高关键词的分布密度,使关键词语义信息更集中,更突出,对后续机器翻译性能的提高有一定帮助。
处理完中文分词后,借助字节对编码(byte pair encoder,BPE)方法对蒙汉平行语料进行处理[19]。BPE是一种根据字节对进行编码的算法。BPE处理的主要目的是为了数据压缩,将字符串里频率出现最高的一对字符被一个没有在当前字符串出现过的字符代替,不断迭代。通过BPE处理后,可以大大降低数据稀疏以及未登录词问题对翻译效果的影响。
首先,BPE算法会将训练语料以字符为单位进行拆分,按照字符对进行组合,并对所有组合的结果根据出现的频率进行排序,出现频次越高的排名越靠前,排在第一位的是出现频率最高的子词,最终会根据语料生成codec文件。Codec文件分布如图9所示。

图9 蒙汉codec文件Fig.9 Codec file of Mongolian and Chinese
根据生成的蒙汉双语codec文件,对蒙汉语料进行处理,最终得到完整的BPE处理后的语料库。处理完毕的语料如图10所示。

图10 BPE处理后语料Fig.10 Processing of BPE corpora
对蒙汉语料库进行BPE处理,也就是对蒙汉平行进行标记和分段后,借助BPE生成的子词(subwords)词典,使用上述提到的跨语言词嵌入方法,对蒙汉语料进行映射处理,通过线性变换得到蒙汉双语嵌入词向量,来充分利用两种语言在同一向量空间分布的相近性,提升蒙汉机器翻译的准确率。
4 实验部分
4.1 实验设置
本次实验所用的Transformer翻译模型以及非自回归Transformer翻译模型借助Facebook AI实验室提出的开源库Fairseq(https://github.com/pytorch/fairseq)。借助内蒙古工业大学提供的GPU服务器进行实验,GPU型号为NVIDIA Tesla P100。实验环境为Ubuntu16.04,Linux系统,Python版本3.7.0,TensorFlow版本1.13.0,借助BLEU值来评估翻译效果,同时对翻译模型解码时间进行记录。
Transformer Transformer神经网络层数设置为6层,多头注意力机制设置为8头,隐藏单元维度设置为512,激活函数使用GELU,优化函数使用Adam算法,初始学习率设置为0.01,Label Smoothing设置为0.1,一阶矩估计的指数衰减率设置为0.9,二阶矩估计的指数衰减率设置为0.95,train_steps设置为200 000,batch_size设置为4 096。
非自回归Transformer神经网络层数设置为6层,多头注意力机制设置为8头,隐藏单元维度设置为512,优化函数使用Adam算法,激活函数使用GELU,初始学习率设置为0.01,dropout设置为0.1,fine-tuning设置为0.25。PyTorch0.3,torchtext0.2.1,train_steps设置为200 000,warmup_steps设置为4 000,batch_size设置为2 048。同时借助IBM Model 2提供的Fast_Align(https://github.com/fast_Align)来实现编码器Fertility模块的改进。
4.2 实验结果
如图11、图12所示,本文分别统计了基于Transformer神经机器翻译模型,基于非自回归Transformer神经机器翻译模型以及进行知识蒸馏处理后非自回归Transformer模型在200 000训练步数上的BLEU值变化趋势,同时统计了三组翻译模型在实验过程中所消耗的时间变化趋势,来对实验进行完整的分析。
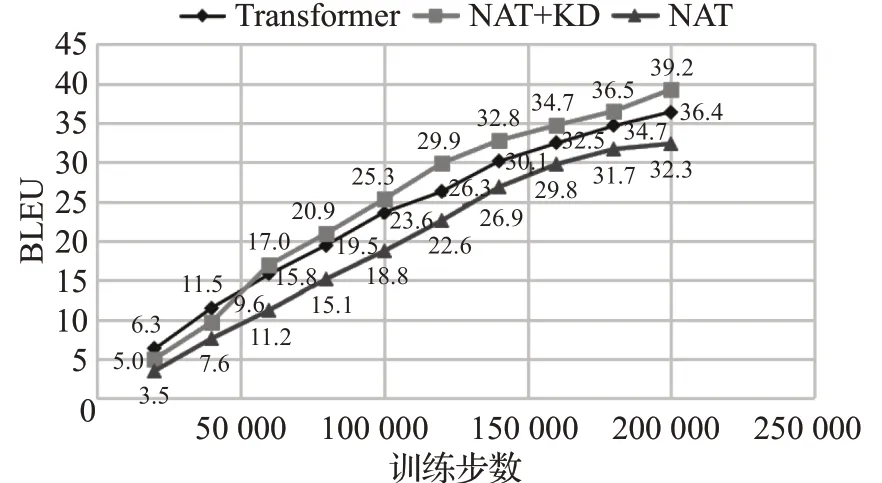
图11 三组实验模型BLEU值变化趋势Fig.11 Change trend of BLEU value in three experimental groups
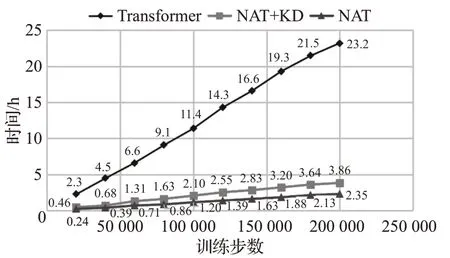
图12 三组实验模型消耗时间变化趋势Fig.12 Time consumption trends of three experimental models
表2是基于Transformer神经机器翻译模型,基于非自回归Transformer神经机器翻译模型以及进行知识蒸馏处理后的非自回归Transformer神经机器翻译模型在测试集得到的BLEU值以及消耗时间。
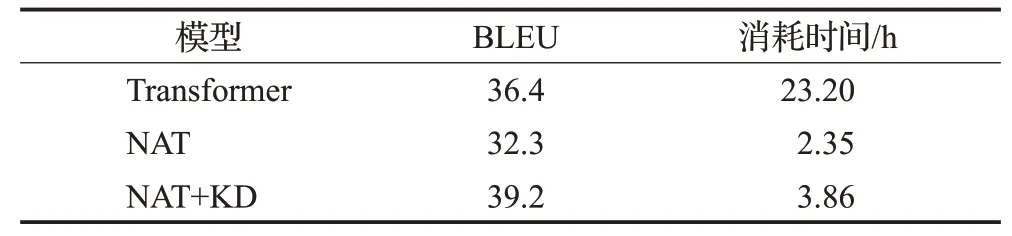
表2 三组翻译模型BLEU值和消耗时间Table 2 BLEU and time consumption of three translation models
表2可以得到基于Transformer翻译模型的BLEU值为36.4,消耗时间为23.2 h,非自回归Transformer翻译模型的BLEU值为32.3,消耗时间为2.35 h,而进行知识蒸馏处理后的非自回归Transformer翻译模型的BLEU值达到了39.2,相比于Transformer翻译模型提高了2.8个BLEU值,消耗时间为3.86 h,大致为Transformer模型的1/8。
图11、图12和表2表明进行了知识蒸馏处理后的非自回归Transformer翻译模型,在保留非自回归Transformer翻译模型耗时短优点的同时,也提高了最终蒙汉翻译的准确率,相比于Transformer翻译模型,用时大大降低,同时BLEU值得到了2.8的提升。实验表明对语料进行知识蒸馏处理可以有效解决非自回归Transformer翻译模型的缺点,降低依赖性,在维持低耗时的前提下,进一步提升蒙汉翻译的效果。
5 结束语
当前蒙汉机器翻译研究中,大多数翻译模型的计算成本很高,获得高翻译效果的同时,消耗时间也是飞速增长,而非自回归Transformer翻译模型的提出可以有效解决这个问题,缩短消耗时间,但会导致翻译效果的下降这个新问题的出现。所以本文主要针对于NAT翻译模型,研究跨语言词嵌入[20]和知识蒸馏在翻译过程中所起到的作用,通过对各方法的实验结果进行对比分析。实验结果表明进行了知识蒸馏处理的NAT翻译模型在维持低耗时的前提下,相比于Transformer翻译模型提升了蒙汉翻译的效果。但知识蒸馏处理也存在不足之处,知识蒸馏将源语言与目标语言的依赖关系降低,这就使得在翻译生成时,可能会造成部分语义信息不足的问题,所以在接下来的研究中,考虑是否可以将无监督知识蒸馏方法[21]和源-目标语料对齐加入到模型训练中,融合更多语义信息,进一步提升蒙汉翻译的效果,这是未来工作的着重点。
猜你喜欢
中国石油石化(2022年12期)2022-07-16 08:28:28
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
家庭影院技术(2019年8期)2019-12-04 14:43:19
中国外汇(2019年19期)2019-11-26 00:57:32
家庭影院技术(2018年11期)2019-01-21 02:20:50
家庭影院技术(2018年11期)2019-01-21 02:20:48
内蒙古艺术(2018年4期)2019-01-18 02:56:36
赤峰学院学报(蒙文哲学社会科学版)(2018年4期)2018-12-05 05:21:00
