
融合BERT-WWM和指针网络的旅游知识图谱构建研究
2022-06-23 06:25:06李胜楠
计算机工程与应用 2022年12期
徐 春,李胜楠
新疆财经大学 信息管理学院,乌鲁木齐 830012
随着人们的收入和消费水平的日益提高,越来越多的国人开始注重精神上的满足,旅游业已经成为国民经济的战略性支柱产业[1]。互联网上的旅游信息呈现出散乱、无序和关联性不强的问题,给旅游业的发展造成阻碍,给大数据环境下旅游知识的组织和利用带来挑战。知识图谱具有强大的语义处理能力和开放互联能力,是一种高效的组织、管理、分析和查询数据的方法[2]。将知识图谱应用于旅游领域不仅能够实现数据的集中存储、统一分发以及共建共享,在推动景区智能化信息管理、游客高效查询与决策以及旅游企业精准营销等方面也起着重要作用。因此,构建旅游知识图谱对推动旅游业创新性发展具有重要意义。
目前,旅游知识图谱的构建研究取得一定程度的发展。冯小兰[3]采用BLSTM神经网络模型在已构建的汉文语料库上进行关系抽取,获得与景点相关的属性关系,构建了西藏旅游知识图谱。曹明辉[4]通过引入BILSTMCNN模型,从爬取的旅游评论中抽取实体关系,构建了三亚旅游知识图谱。韩凌洁[5]基于Scrapy框架爬取旅游网站和百科网站的结构化数据,构建了内蒙古自治区旅游知识图谱。吴杰[6]以事件为中心对游客旅行过程中的时空关系进行建模,构建了海南旅游知识图谱。陈荣祯[7]参考DBpedia抽取方法,提出面向携程网页的半结构知识抽取框架提取旅游知识三元组,构建了全国旅游知识图谱。但以上旅游知识图谱在智能化、规模化、精确化等方面仍有很大的提升空间,为旅游知识图谱的构建提供有效知识,开展面向旅游领域的实体关系抽取任务仍需面对以下难题:(1)旅游评论中的实体具有一词多义问题。例如,“玉门关”既可以表示地名,也可以理解为旅游景点[8]。(2)旅游评论中存在着一对多和多对一两种类型的关系重叠现象。例如,句子“天山天池风景区位于阜康市,是国家5A级景区。”包含两个关系三元组(天山天池风景区,风景区地理位置,阜康市)和(天山天池风景区,风景区等级,国家5A级景区),一个头实体与多个尾实体之间存在关系,是一对多关系重叠问题。而句子“天山天池风景区与喀纳斯风景区都是国家5A级景区。”包含两个关系三元组(天山天池风景区,风景区等级,国家5A级景区)和(喀纳斯风景区,风景区等级,国家5A级景区),多个头实体与一个尾实体之间存在关系,是多对一关系重叠问题。综上所述,如何从非结构化文本中准确提取风景区、风景区地理位置、风景区开放时间等有用知识,解决文本中的一词多义问题和重叠关系提取问题、减少人工特征的投入等,仍是旅游知识图谱构建的核心问题和挑战性工作。
实体关系抽取是构建知识图谱的关键环节。传统的实体关系抽取方法先识别实体,再对实体对之间的语义关系进行分类,例如耿雪来[9]基于条件随机场和卷积神经网络相结合的方法先抽取实体再抽取关系,为蒙汉双语知识图谱的构建提供知识。张诺[10]通过引入BERTSpan模型完成实体识别任务,再基于BERT-BILSTMattention模型进行关系抽取,构建了山西旅游知识图谱。但该方法存在以下不足:(1)错误传播。实体识别引入的错误会影响关系抽取任务的性能。(2)实体冗余。实体识别任务中抽取出来的任意实体之间不一定都存在语义关系,这些冗余实体增加了计算复杂度,进而导致错误率提升。(3)交互缺失。实体识别和关系抽取两个子任务之间有着紧密的内在联系,该方法忽视了子任务之间的潜在交互,导致性能不佳。因此,为了解决传统实体关系抽取方法存在的问题,一些研究者提出使用联合抽取法完成实体关系抽取任务。Miwa等[11]提出堆叠双向树型LSTM-RNNs模型,该模型通过将实体识别和关系抽取的网络参数进行共享实现联合抽取,但该方法仍存在无法剔除冗余实体的问题。Zheng等[12]在此基础上将实体关系联合抽取问题转化为序列标注问题,通过计算偏重损失提升实体标签间的相关性。虽然该方法能实现实体与关系之间的深层交互,但是采用就近原则分配关系,未考虑文本数据中存在的关系重叠现象,造成关系抽取不全面。Zeng等[13]引入机器翻译的思想,将输入语句看成是源语言,将实体关系三元组组成的序列看作是目标语言,以此联合抽取实体关系,有效解决了关系重叠问题,但无法识别多字实体。吴赛赛等[14]提出将主实体标注为一固定标签,将文本中与主实体存在关系的其他实体标注为两者间的关系类型,这种新的标注方法有效解决了关系重叠问题,但需要大量的标注工作,导致工作成本巨大。
综合考虑以上问题,结合现有的实体关系抽取技术,本文提出一种融合BERT-WWM和指针网络的实体关系联合抽取模型构建旅游知识图谱。本文主要创新和贡献如下:(1)BERT-WWM预训练语言模型结合上下文语义信息动态生成特征向量,有效解决旅游评论中的一词多义问题。(2)直接对三元组进行建模,这种端对端的联合抽取方式充分利用了实体与关系之间的依赖关系,避免造成实体冗余、错误传播等问题。(3)引入级联结构和指针网络解码输出三元组,有效解决旅游评论中的关系重叠问题。(4)由于旅游领域没有公开的大规模标记数据集,本文爬取了关于新疆22个旅游景区的游客评论,让模型在一个真实的旅游数据集上进行实验,证明了该模型的有效性。(5)构建的旅游知识图谱以结构化的形式更加直观地描述旅游实体间复杂关系,实现了旅游信息的整合与存储,有效解决旅游信息散乱、无序和关联性不强的问题。
1 实体关系联合抽取模型
融合BERT-WWM和指针网络的实体关系联合抽取模型的总体结构由两部分组成,如图1所示,分别为编码层和三元组抽取层。首先,将输入句子输入到BERT-WWM模型中,通过BERT-WWM的Embedding层和双向Transformer层得到每一个字符的特征向量表示。然后,在三元组抽取层直接对三元组进行建模,利用句子编码抽取头实体(subject),并按关系类别抽取尾实体(object)。最后,引入级联结构构建下游指针网络,解码输出三元组。
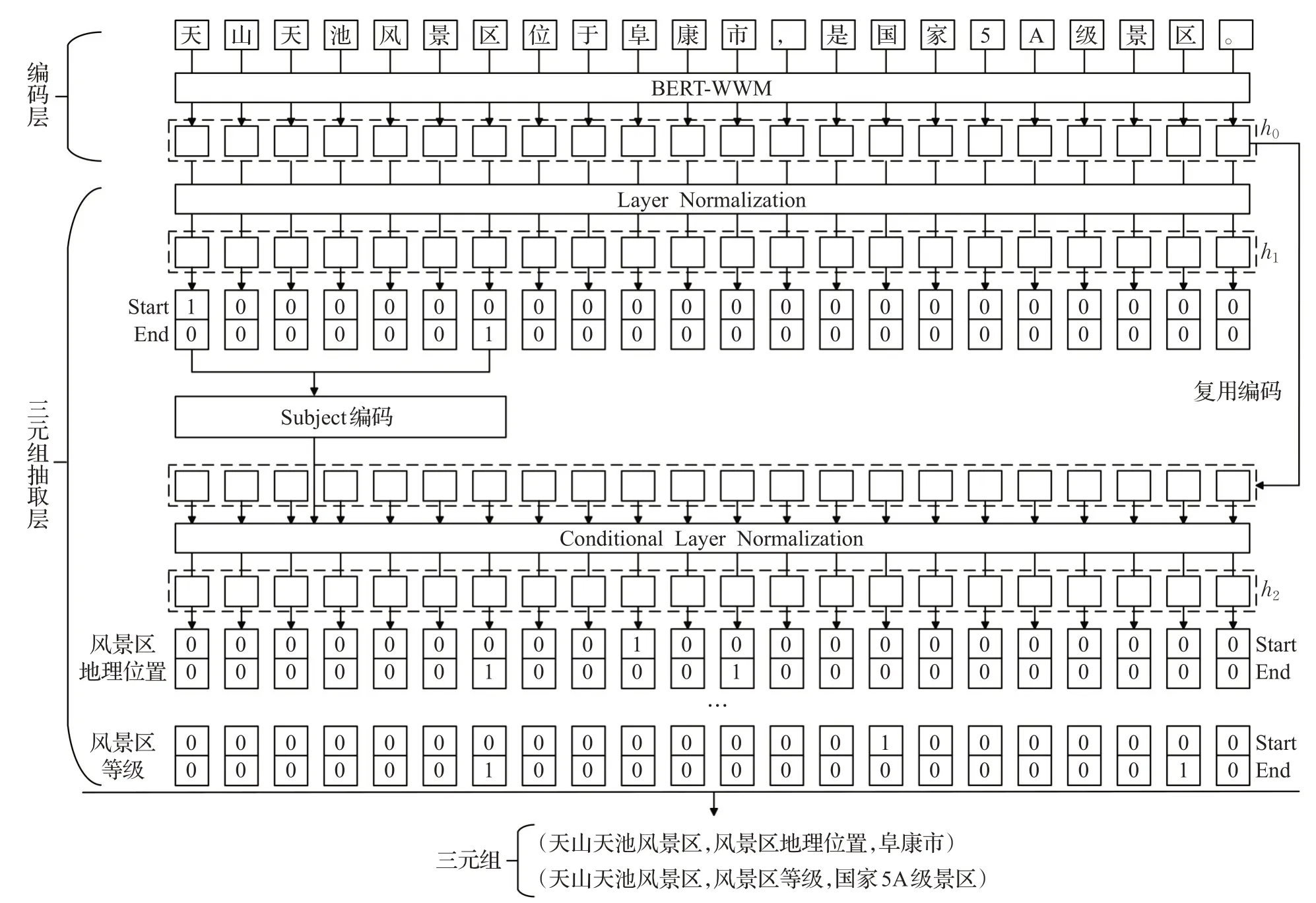
图1 融合BERT-WWM和指针网络的实体关系联合抽取模型Fig.1 Joint extraction model combining BERT-WWM and pointer network
1.1 BERT-WWM预训练语言模型
BERT-WWM[15]预训练语言模型由Embedding层和Transformer层组成,结构如图2所示。首先,定义模型的输入句子为e=(e1,e2,…,en),ei表示输入句子的第i个字符,n表示句子长度。在Embedding层中,输入句子e=(e1,e2,…,en)以词嵌入向量(token embeddings)、分割嵌入向量(segment embeddings)和位置嵌入向量(position embeddings)三者求和的方式转换为输入序列T=(t1,t2,…,tn)。其中,词嵌入向量通过查询字向量表得到,分割嵌入向量用来表示该词属于的句子,位置嵌入向量表示该词的位置信息,T是一个n×m维的矩阵,ti为ei对应的m维字嵌入向量[16]。然后,将输入序列T=(t1,t2,…,tn)输送进Transformer层提取特征,得到语义丰富的输出序列h0=(h1,h2,…,hn)作为后续实体关系联合抽取的句子编码。
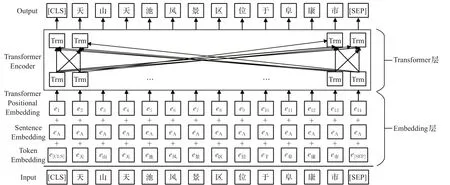
图2 BERT-WWM模型结构图Fig.2 Structure diagram of BERT-WWM model
Transformer层是BERT-WWM的主要框架,由多个Encoder和Decoder组成,具体结构如图3所示。Encoder包括四层:第一层为多头注意力机制(Multi-head attention);第二层和第四层为残差网络和归一化(Add&Normal);第三层为前馈神经网络(Feed Forward Neural Network)。Decoder在Encoder的基础上加入Encoder-Decoder attention层,用于帮助当前节点获得当前需要关注的重点内容[17]。
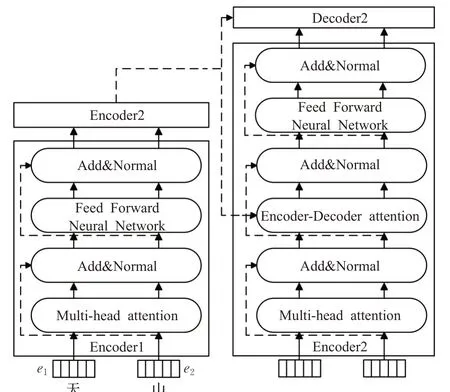
图3 Transformer模型结构图Fig.3 Structure diagram of Transformer model
其中,Multi-head attention是Transformer层的核心,其主要思想是通过计算词与词之间的关联度来调整词的权重,反映了该词与这句话中所有词之间的相互关系以及每个词的重要程度。首先,输入序列T=(t1,t2,…,tn)输送进Encoder,通过线性变换得到表示目标字的Q矩阵、表示上下文各个字的K矩阵以及表示目标字与上下文各个字的原始矩阵V[18]。然后,通过计算放缩点积求得self-attention的分数值,该分数值决定了当模型对一个词进行编码时,对输入句子的其他词的关注程度,具体计算方法如公式(1)所示。最后,将经过i次计算的self-attention分数值进行拼接和线性变换,最终获得一个与原始字向量长度相同的增强语义向量,作为Multi-head attention层的输出,具体计算方法如公式(2)、公式(3)所示:
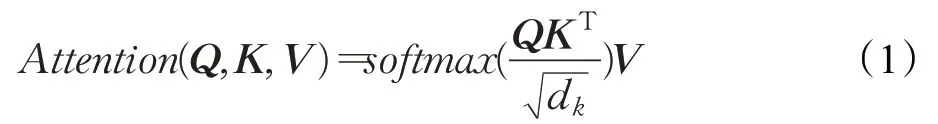
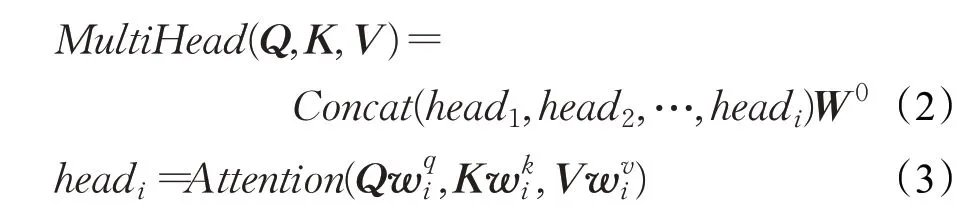
其中,Q、K、V表示输入的字向量矩阵,dk表示输入维度,wqi、wki、wvi表示headi的权重矩阵,W0表示附加的权重矩阵。
为了提高模型对句子的泛化能力和特征表示能力,BERT-WWM在进行自监督训练MLM(masked language model)时对输入句子中15%的token进行随机选取,并将这些token以80%的概率替换为Mask进行预测[19]。考虑到中文文本中词所能表达的意思更为重要和完整,BERT-WWM将以字为单位的Mask方法变为对整个汉语单词Mask,即一个词的部分字段被Mask,则将整个词Mask,训练完成后字的编码就具有了词的语义信息,具体样例如表1所示。此外,为了提高模型理解长序列上下文关系的能力,BERT-WWM在进行NSP(next sentence prediction)训练时给出句子A和句子B,并判断句子B是否为句子A的下句。

表1 全词掩码策略样例Table 1 Example of whole word masking
1.2 标注策略
实体关系抽取的标注策略包括序列标注法和指针网络标注法。其中,序列标注法采用就近原则标注实体关系,即一个实体在上下文中与多个实体存在关系时模型只能将关系分配给距离最近的实体对[20],这种方法只考虑了一个实体属于一种关系的情况,难以有效应对关系重叠问题。如图4所示,序列标注法只能对“天山天池风景区”标注一次,识别出“天山天池风景区”与“阜康市”存在“风景区地理位置”的关系,无法识别“天山天池风景区”与“国家5A级景区”存在“风景区等级”的关系。

图4 序列标注法Fig.4 Sequence labeling method
指针网络标注法将句子中的实体的开始token和结束token标注为“1”,剩余token标注为“0”,并将开始token和结束token拼接输出实体[21]。如图1所示,通过建立级联结构,指针网络标注法可对token进行重复标注,有效解决关系重叠问题。因此,本文选择指针网络标注法完成解码任务。
1.3 三元组抽取层
三元组抽取层的主要思路是利用BERT-WWM模型的输出序列h0=(h1,h2,…,hn)抽取出subject,然后根据关系类别抽取出subject对应的object,最后建立级联结构并使用指针网络解码输出三元组。
1.3.1 抽取subject
首先,为了缓解梯度爆炸或消失问题,将句子编码h0归一化得到句子编码h1,计算方法如公式(4)、公式(5)所示:
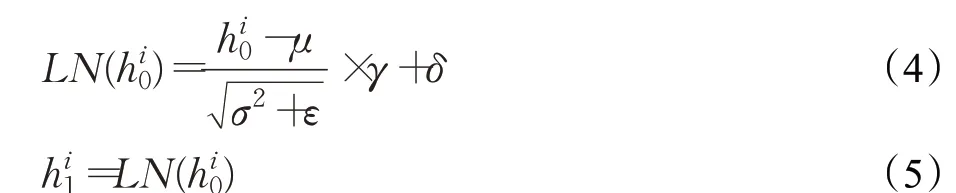
其中,hi0为句子编码h0的第i个输入特征,μ为均值,σ为方差,γ、δ为可训练参数,ε为一个大于0的极小常数,hi1为句子编码h1的第i个输入特征。
然后,使用句子编码h1计算输入句子中每个token是某个subject开始或者结尾的概率,分别使用ps_starti和ps_endi表示,并根据概率是否大于阈值,为每个token标注“0/1”标签。计算方法如公式(6)、公式(7)所示:
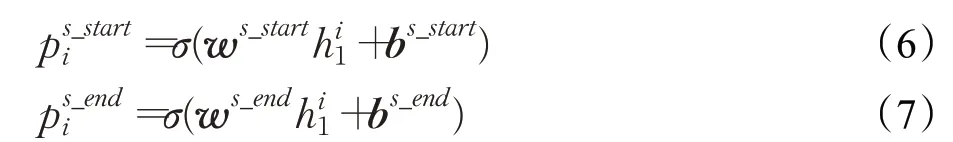
其中,w(⋅)表示可训练权重,b(⋅)表示可训练偏置,σ表示sigmoid激活函数。
1.3.2 联合抽取object和关系
首先,为了加强层与层之间的联系,嵌入CLN(conditional layer normalization)网络层,将subject的编码sj和句子编码h0进行特征融合得到新的句子编码h2,计算方法如公式(8)、公式(9)所示:
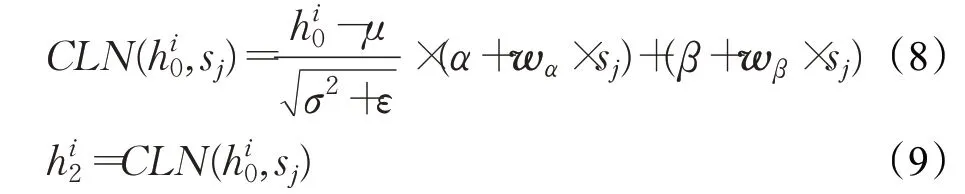
其中,hi2和hi0分别表示句子编码h2和h0的第i个token的编码表示,wα和wβ表示两个全零初始化的变换矩阵,α和β为模型训练过程中由梯度下降得到的参数值。
然后,利用新的句子编码h2计算句子中每个token在第j个subject、第k种关系条件下,是object的开头或者结尾的概率,分别使用po_starti,j,k和po_endi,j,k表示,并根据概率是否大于阈值,为每个token标注“0/1”标签。计算方法如公式(10)、公式(11)所示:
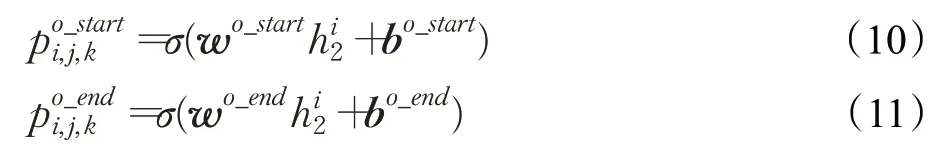
其中,w(⋅)表示可训练权重,b(⋅)表示可训练偏置,σ表示sigmoid激活函数。
2 实验
2.1 实验数据集
本文选择采用网络爬虫工具后裔采集器,从携程网、马蜂窝网上以新疆22个旅游景区为单位对游客评论进行抓取。通过对爬取的游客评论的浏览,发现游客主要关心风景区、游玩项目、著名景点、用时参考、门票、等级、地理位置、开放时间等20种实体关系。鉴于此,本文对爬取到的数据进行去重、补全等预处理后,对以上20种实体关系类型进行人工标注,标注示例如下:{“sentText”:“天山天池风景区位于阜康市,是国家5A级景区。”,“relationMentions”:[{“em1Text”:“天山天池风景区”,“em2Text”:“阜康市”,“label”:“/风景区/地点/风 景区地理位置”},{“em1Text”:“天山天池风景区”,“em2Text”:“国家5A级景区”,“label”:“/风景区/等级/风景区等级”}]}。人工标注后得到数据4 000条,共10 196个实体关系对,将4 000条数据按8∶2的比例划分为训练集和测试集,得到训练数据3 200条,测试数据800条。
2.2 实验参数设置
实验采用Windows操作系统,中央处理器的型号为4.25 GHz八核ADM r7,内存配置为16 GB 3 200 MHz DDR4,GPU为2070s,实验语言为Python3.6版本。采用谷歌公司人工智能团队开发的深度学习框架Tensorflow1.14.0搭建实验模型,模型参数设置如表2所示。

表2 模型相关参数设置Table 2 Model parameters setting
2.3 评价指标
采用精确率(P)、召回率(R)和F1-score(F1)评判模型性能,各评价指标的计算方法如公式(12)、公式(13)、公式(14)所示。其中,TP表示模型能正确检测出的实体个数、FP表示模型检测到的无关实体个数、FN表示模型未检测到的实体的个数。
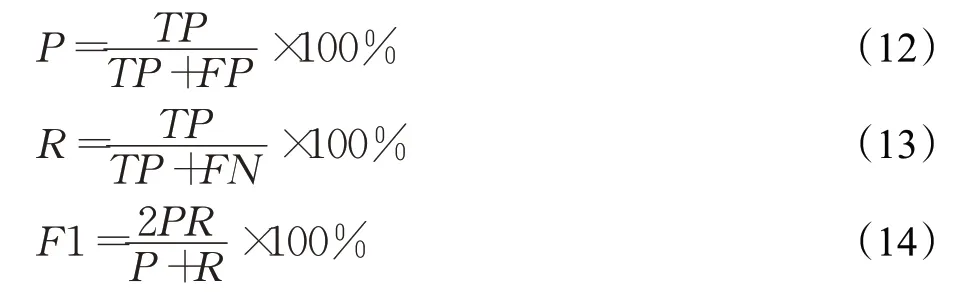
2.4 结果分析
2.4.1 性能评估
为了验证融合BERT-WWM和指针网络的联合抽取模型抽取旅游领域实体关系的优越性,本文分别选用联合抽取方法和流水线方法共3个模型作为基准模型进行对比实验:
(1)基于Word2Vec+CNN+BILSTM的联合抽取方法。该方法首先使用Word2Vec模型生成字向量,然后引入CNN获取词语部件特征中的关键语义特征,将得到的特征分别与当前词语所对应的字符向量结合,一起输入到BiLSTM模型中获取上下文特征,最后采用指针网络解码输出三元组。
(2)基于BERT-WWM+BIGRU+Attention的联合抽取方法。该方法使用BIO标注策略,基于BERT-WWM模型对实体进行词向量化,然后结合BIGRU和注意力机制对输入句子进行特征提取,最后加上全连接层完成实体关系抽取任务。
(3)基于BERT-WWM的流水线方法。该方法采用BIO标注策略,首先使用BERT-WWM搭建实体识别模型,进行命名实体识别,然后使用BERT-WWM作为编码器并连接全连接神经网络进行关系分类。
实验结果如表3所示。所有联合抽取方法的性能表现均优于流水线方法,其中本文提出的融合BERTWWM和指针网络的联合抽取方法比基于BERT-WWM的流水线方法在F1值上高出8.70个百分点。对最终预测数据进行分析,发现采用流水线方法的模型对不存在关系的实体进行了提取,且对距离较近的实体对之间的关系一般能准确提取,但距离较远的实体对之间的关系基本无法提取,证实流水线方法存在实体冗余和交互缺失问题。
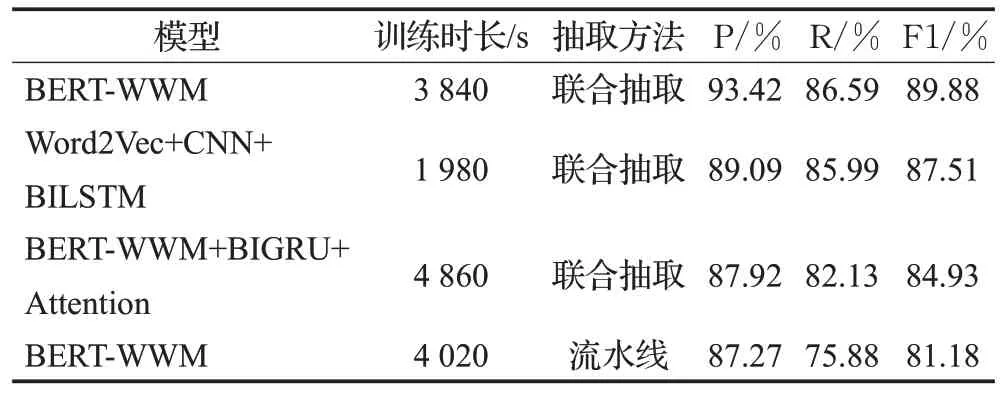
表3 模型综合性能评估Table 3 Model comprehensive performance evaluation
此外,本文提出的融合BERT-WWM和指针网络的联合抽取方法比基于Word2Vec+CNN+BILSTM的联合抽取方法在F1值上高出2.37个百分点。分析原因在于Word2Vec词嵌入模型是一种静态的语言模型,不能很好地融入上下文信息,解决一词多义问题。例如,“天气很好”和“天山天池风景区”这两句话中出现的“天”字表达的意思不同,但是Word2Vec将2个“天”字表示成了完全相同的词向量,这与实际情况不符。而采用双向Transformer网络结构的BERT-WWM模型能够通过学习上下文实现特征微调,充分挖掘文本信息。但加入BERT-WWM的实体关系抽取模型的训练时间更长,原因在于BERT-WWM涉及的参数规模更大,需耗费更多的计算资源。
2.4.2 重叠关系实验及分析
为了测试不同模型抽取重叠三元组的能力,将存在重叠现象的三元组分为一对多和多对一两类,不存在重叠现象的三元组归为Normal类,实验结果如图5所示,可看出融合BERT-WWM和指针网络标注的联合抽取模型的性能表现最优,在面对不同类型的三元组时F1值均达到88%以上。值得注意的是,在面对Normal类型三元组时,采用BIO标注的BERT-WWM+BIGRU+Attention联合抽取模型的性能与融合BERT-WWM和指针网络标注的联合抽取模型的性能差距较小,而在面对一对多和多对一的重叠三元组时F1值差距增大。分析原因在于BIO标注法采用就近原则标注实体,只能对一个实体标注一次,导致关系抽取不全面。此外,流水线模型对于重叠关系抽取的F1值低于联合抽取模型,表明流水线方法很难预测重叠关系。
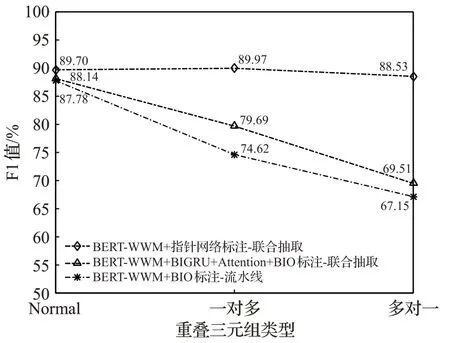
图5 模型抽取不同重叠类型三元组的F1值Fig.5 Model extracts F1 values of triples of different overlapping types
2.4.3 不同三元组个数提取结果分析
为了测试不同模型从具有不同三元组个数的句子中提取实体关系三元组的能力,根据句子包含的三元组数量将800条测试数据划分为5组进行实验,结果如图6所示。融合BERT-WWM和指针网络标注的联合抽取模型的性能表现最优,5个测试小组的F1值均达到85%以上,随着句子所包含的三元组数量的增加,模型性能表现稳定。而基线模型的性能表现不佳,F1值大幅度降低,表明融合BERT-WWM和指针网络标注的联合抽取模型受输入句子的复杂程度的影响最小。
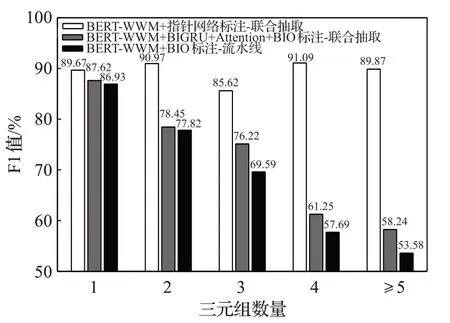
图6 模型抽取不同数量三元组的F1值Fig.6 Model extracts F1 values of different numbers of triples
2.4.4 模型参数分析
由于BERT-WWM模型在实际预训练中每层所学习到的信息不同,所以本文考虑探究不同Transformer层数对旅游数据集实体关系联合抽取结果的影响。选取Transformer层数分别为12、9、6、3进行对比,结果如表4所示。从训练时长可看出减少Transformer层数可以加快模型的训练速度。当Transformer层数小于9时,模型识别性能随Transformer层数的减少而下降,当Transformer层数大于等于9时,模型识别的准确性趋于平稳,在12层时模型性能达到最优,P值、R值、F1值分别达到93.42%、86.59%和89.88%,说明BERT-WWM模型在第12层附近学习到的信息能够更好完成实体关系联合抽取任务。
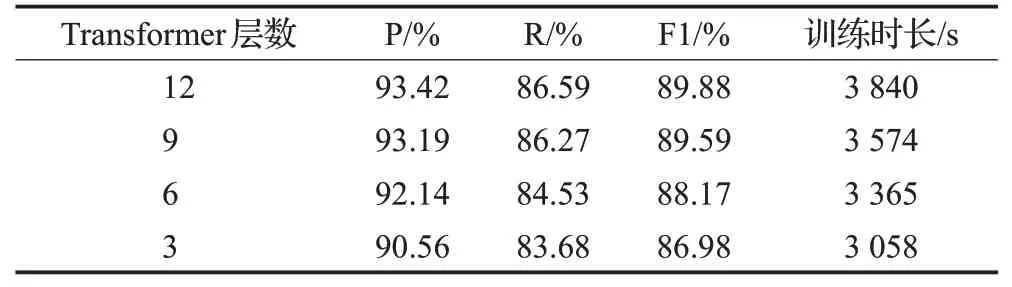
表4 模型在不同Transformer层数下的性能表现Table 4 Performance of model under different layers of transformer
当Transformer层数为12层时,对20种类型三元组的识别结果进行统计,结果如表5所示。可看出整体结果较为均衡,F1值均保持在90%水平左右,但“风景区—附近景区—风景区”“风景区—风景区文化艺术—文化艺术”这两种类型的三元组的预测结果明显低于平均水平,同时也是拉低模型效果的重要因素。分析原因可能是因为构成“风景区—附近景区—风景区”三元组的头、尾实体的相对位置多变,模型无法很好识别,构成“风景区—风景区文化艺术—文化艺术”三元组的尾实体大部分属于新疆维吾尔自治区博物馆中的藏品,如:“天王踏鬼彩绘木俑”等,名称较为复杂。
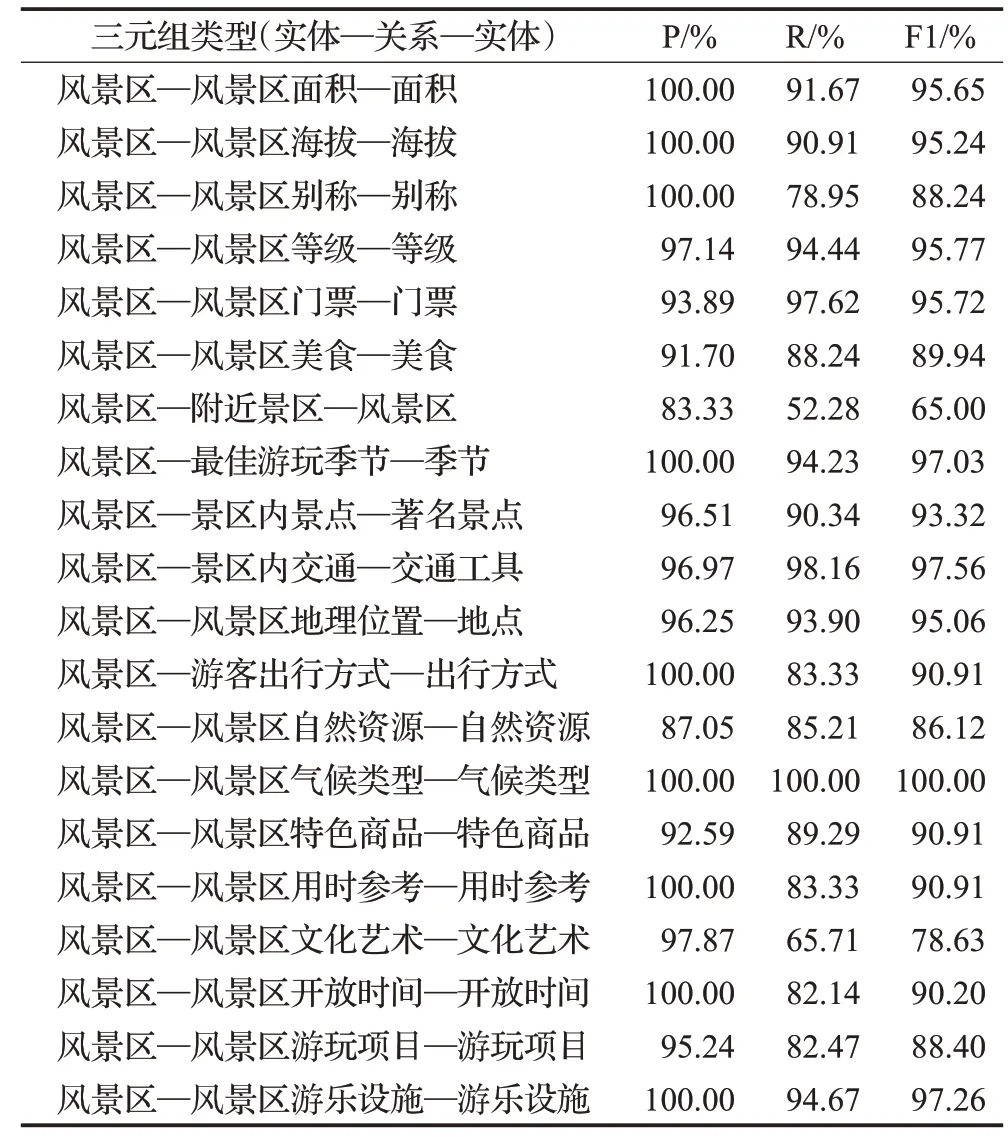
表5 模型抽取不同类型三元组的性能表现Table 5 Performance of model to extract different types of triples
3 旅游知识图谱构建与应用
基于Neo4j图数据库具有查询性能高效、适应性强、支持图论算法等优点,以及旅游知识图谱中的数据相对于传统关系数据更具关联性和灵活性的特点,选择Neo4j图数据库存储三元组,构建旅游知识图谱。本文以喀纳斯风景区为例进行图谱展示,如图7所示,喀纳斯风景区地处阿勒泰地区,阿勒泰地区同时又包含可可托海风景区、白沙湖风景区,由此关联了风景区与地理位置两类实体。同时,喀纳斯风景区有月亮湾、观鱼台等著名景点,还有额河烤鱼、冷水鱼等美食,由此将风景区与著名景点、美食相关联。此外,图谱中的灰色节点展示了喀纳斯风景区的数据属性,如面积是10 030 km2,气候类型是温带大陆性气候等。
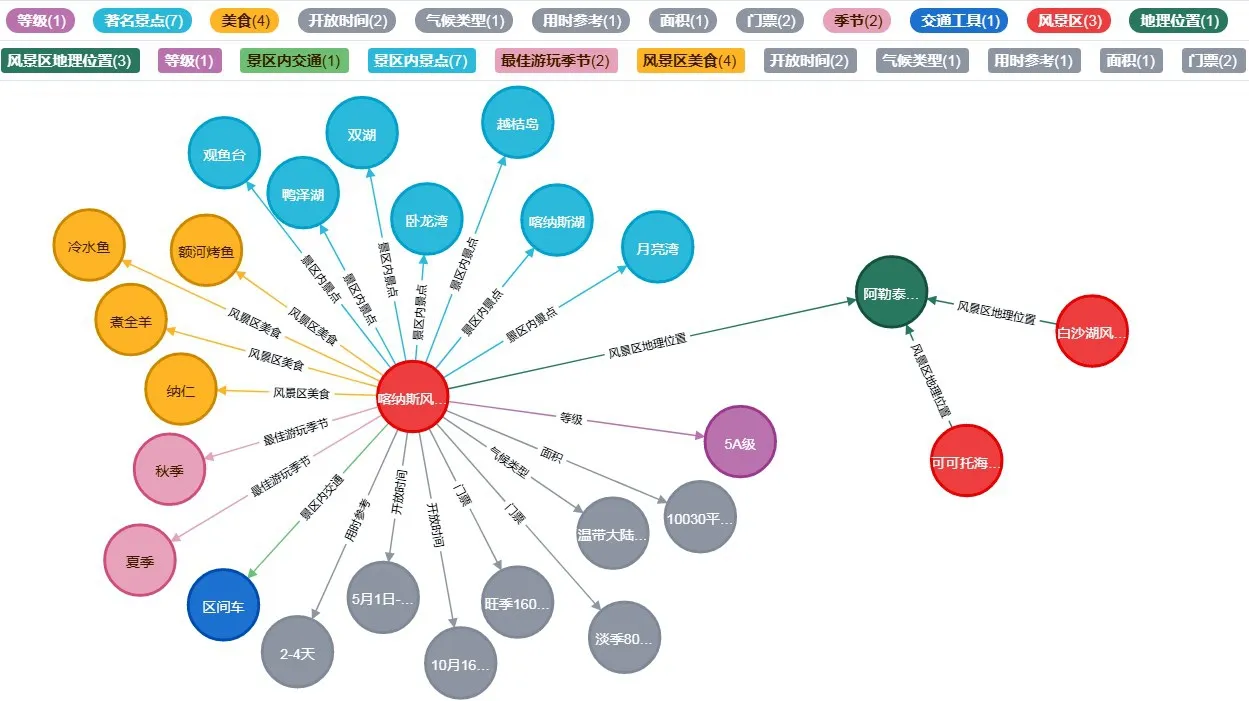
图7 喀纳斯风景区图谱展示Fig.7 Graph display of Kanas scenic spot
构建的旅游知识图谱可视化展现出不同旅游景区对应的景点、门票、开放时间等重要信息,在帮助游客高效查询与决策、景区智能化信息管理以及旅游企业精准营销等方面发挥重要作用,为催生旅游问答系统、推荐系统、云平台等智能化系统奠定基础。
4 结论
本文提出一种融合BERT-WWM和指针网络的实体关系联合抽取模型构建旅游知识图谱。首先,模型引入BERT-WWM作为编码层,相较于采用Word2vec编码的神经网络模型取得了2.37个百分点的F1值提升,表明BERT-WWM通过学习上下文实现特征微调,可以更好地解决不同语境下同一词语的不同语义问题。其次,模型解码采用指针网络,相较于采用BIO标注的BERTWWM+BIGRU+Attention联合抽取模型而言,在抽取一对多和多对一两种类型的重叠三元组时分别取得10.28个百分点和19.02个百分点的F1值提升,在面对拥有不同数量的三元组文本时最高取得31.63个百分点的F1值提升,表明本文模型更适合复杂场景,可以有效解决关系重叠问题和多个三元组抽取任务。此外,通过与现有流水线模型进行对比分析,本文提出的联合抽取模型最高取得8.70个百分点的F1值提升,表明联合抽取模型可以加强实体识别和关系抽取两个子任务之间联系,缓解错误传播和实体冗余问题。以上实验结果表明,基于该模型构建的旅游知识图谱具有较高的准确性,可有效实现旅游信息的组织和利用,为进一步促进旅游业发展提供技术支撑。
猜你喜欢
计算机与数字工程(2023年5期)2023-08-31 08:40:44
山西大学学报(自然科学版)(2021年1期)2021-04-21 03:38:02
五邑大学学报(自然科学版)(2019年3期)2019-09-06 02:22:22
娃娃画报(2019年5期)2019-06-17 16:58:10
现代园艺(2017年22期)2018-01-19 05:07:08
现代园艺(2017年19期)2018-01-19 02:50:17
广东第二课堂·小学(2017年9期)2017-09-28 14:51:06
人大建设(2017年9期)2017-02-03 02:53:29
电测与仪表(2015年5期)2015-04-09 11:30:42
单片机与嵌入式系统应用(2014年9期)2014-03-11 15:35:09
