
基于组块分割的无监督藏文句法分析方法研究
2022-06-14 09:49卓玛扎西才让加色差甲班玛宝
计算机仿真 2022年5期
卓玛扎西,才让加,色差甲,班玛宝
(1. 青海师范大学计算机学院,青海 西宁 810016;2. 藏语智能信息处理及应用国家重点实验室,青海 西宁 810008;3. 青海省藏文信息处理工程技术研究中心,青海 西宁 810008)
1 引言
句法分析是自然语言处理领域中的一项基础性研究工作,已成为机器翻译[1]、语义分析[2]、问答系统[3]、信息抽取[4]等诸多自然语言处理任务中不可或缺的流程之一。一般句法分析方法可分为有监督、半监督和无监督三种方法,自宾州树库开放以来,有监督的英汉文等句法分析研究取得了快速的发展,相比传统句法分析方法,性能取得了明显的提高[5]。
藏文句法分析研究由于受数据资源匮乏问题的限制,使有监督藏文句法分析在理论、方法和技术等方面还未取得显著进展,而无监督方法可以在一定程度上解决数据资源匮乏的问题,但单一的无监督方法在句法分析任务上的性能与有监督方法还存在一定的差距。针对以上问题,提出了一种基于组块分割的无监督藏文句法分析方法,该方法首先分割藏文组块的基础上采用扰动掩码算法(Perturbed Masking)[6],对藏文组块进行了无监督藏文句法分析,然后根据藏文自身的语法特征对无监督藏文句法分析结果进行了优化,以完成高效的无监督藏文句法分析任务,通过不同领域的数据和不同长度的藏文句子数据集上进行测试,证明了本方法的有效性及可行性。
2 相关研究
自20世纪40年代末开始,句法分析作为自然语言处理领域的核心任务和关键技术,一直是研究人员关注的热点问题[7]。英汉文句法分析经历了从有监督到半监督,再到无监督方法的研究历程,近几年无监督句法分析方法广受研究人员的关注。文献[8]提出了解析、阅读和预测三种任务混合的模型(Parsing-Reading-Predict Networks,简称PRPN),该模型首先推断未标注数据中的句法结构,增强语言模型的语法信息,然后用此模型完成无监督句法分析。文献[9]提出了一种有序神经元(Ordered Neurons)模型,不仅可以提高语言模型的效果,还可以让LSTM无监督地学习句法结构。文献[6]通过采用扰动掩码算法,提出了一种无监督的探索BERT可解释性的方法,其中无监督句法分析在WSJ10数据集和PTB23数据集上的F1值分别达到了58%和的42.1%,通过和文献[8,9]进行对比,验证了基于扰动掩码算法的无监督句法分析方法的有效性。文献[10]构建了3万句汉文二分结构的树库,为了简化传统句法分析任务,把汉文句法分析转换为迭代二分的序列标注问题,通过训练循环神经网络模型,完成表示完全二叉树的句法层次结构。随着无监督学习研究的升温,以上国内外文献采用不同方法进行了无监督句法分析,为藏文句法分析理论提供了参考。
目前,藏文句法分析的研究主要以有监督的方法为主,文献[11,12]采用判别式的依存句法分析方法,研究了藏文依存句法分析和藏文复合句切分标注方法。文献[13]通过Fillmore格语法与藏文传统语法进行对比,提出了格结构体是藏文句子最直接组成成分的观点。文献[14]通过分析藏文疑问句的构成特点,对藏文疑问句进行了分类,归纳了各类藏文疑问句的结构特征,并利用PCFG对藏文疑问句进行了句法分析。文献[15]通过对比藏文语义块和组块,提出了组块可简化句法结构和组块分析可降低藏文句法分析难度的思路。以上文献采用的都是有监督方法的藏文句法分析方法,并在局部实验或限定领域内取得了较好的实验结果,为进一步研究藏文句法分析提供了参考,但上述方法都属于传统的基于规则和统计以及二者相结合的方法,需要大量高质量的句法标注树库和繁琐的人工特征工程,但到目前藏文没有一个公开的句法树库,无法使用深度学习等先进的方法进行大规模藏文句法分析。
3 藏文组块及其分割规范
3.1 藏文组块的定义及分类
1)藏文组块的定义

2)藏文组块的分类

各类组块的具体定义如下:
谓语组块:指一个句子中的谓语成分,一般由动词、形容词和助动词等词或短语来充当。

3.2 藏文组块分割规定
根据3.1节中藏文组块定义及分类,可以对各类藏文组块进行分割,分割方法如下:

无监督藏文句法分析是在没有标注数据的前提下,利用无标注数据研究藏语自然语言语法结构的方法。随着预训练语言模型的发展,无监督句法分析效果日益增高,但还是无法满足大规模高效藏文句法分析的需求。因此,可根据藏文传统语法,通过规定藏文组块边界,为下一步无监督句法分析提供支撑。
4 基于组块分割的无监督藏文句法分析
4.1 基于组块分割的无监督藏文句法分析模型
通过组块分割方法,对藏文无标注句子进行切分后,可以将藏文句法分析任务转化为多个子任务,设计了基于藏文组块分割的无监督藏文句法分析模型,模型结构见图1。
从图1中可以看出,基于组块分割的无监督藏文句法分析模型由组块分割模块、无监督句法分析模块和藏文句法优化模块构成,各模块的功能如下:

图1 基于组块分割的无监督藏文句法分析模型结构
1)组块分割模块

2)无监督句法分析模块
无监督句法分析模块对无标注的藏文句子进行句法分析,包含两个子功能:一是分析藏文句子的组块和组块之间的句法层次结构,是一个粒度较粗的句法分析,用递归二分方法,将组块序列按照从左到右的顺序依次进行切分,得出藏文句子的各类组块层次结构,如图2所示。

图2 藏文组块句法结构
从图2中可以看出,每一次迭代把藏文句子S分成了一个组块和剩余序列(s1或s2等),当完成谓语组块的切分后迭代结束。二是分析藏文组块序列中的每一个组块,采用文献[6]的方法,通过扰动掩码算法求出基于藏文预训练语言模型(UniLM)的组块内部词语义相关度矩阵,采用二分聚类算法分析藏文组块内部句法结构。其二分聚类算法是把藏文组块C=[x1,x2,…,xn]分为C1=[x1,x2,…,xk]和C2=[xk+1,xk+2,…,xn]两个部分,即用二分聚类算法求最合适的切分点K,希望将相关性较大的词归为一类,输出最优句法结构,将目标函数K定义为

(1)
式(1)中的f(xi,xj)为藏文词xi和xj的词义相关度,当i=j时,f(xi,xj)=0。
3)藏文句法优化模块
藏文句法优化模块优化无监督藏文句法分析模块输出的结果。经藏文无监督句法分析模块结果进行分析后发现,用二分聚类算法求藏文句子的切分点K时,出现两类的虚词聚类错误,分别如下:

根据现代藏文自身的语法特点,藏文句子中虚词具有接续和关联等语法功能,没有实际语义,不能单独使用,应与其上文(C1)先结合[19],进而设计了解决问题 (a)(b)的句法优化算法1。
算法1 藏文句法优化算法
输入 Input_file, Ge_list, k ∥ Input_file=[C1,C2],Ge_list是藏文虚词列表,k是式(1)结果
输出 TS_tree ∥藏文虚词错位处理后的句法结构
1)X=read( Input_file, X) ∥读组块列表
2)ge_list=read( Ge_list, ge_list) ∥读虚词集
3)for ge_word in ge_list do ∥ge_word是藏文虚词
4) if ge_word in X and C2[0] and not in C2[1] then ∥查看虚词位置
5) Knew=k+1 ∥重新设置切分点
6) TS_tree ←[[x1,x2,…,xKnew], [xKnew+1,…,xn]] ∥输出新的句法结构
7) else
8)TS_tree←[[x1,x2,…,xk-1,xk],[xk+1,…,xn]] ∥输出原句法结构
9) end if
10)end for
11)Return TS_tree ∥输出最后句法结构

4.2 基于组块分割的无监督藏文句法分析
基于组块分割的无监督藏文句法分析的流程如图3所示。

第一步:输入句子

第二步:分词

第三步:分割组块

第四步:句子组块和组块内部句法分析
第五步:优化句法
第六步:输出句法树
输出句法广义表的树形结构,如图4所示。
5 实验
5.1 实验数据描述
首先,以前期建立的规模为4.7G的藏文纯文本数据训练了UniLM语言模型,然后,构建了含新闻、法律、小说和文学等题材的规模为1200条藏文句法分析的测试集,测试集中每条句子的长度为4-15个词,将用分词系统对测试集进行了分词,为了保证分词质量,对分词结果进行了人工校对,测试集中的句子和组块数量分布如图5所示。
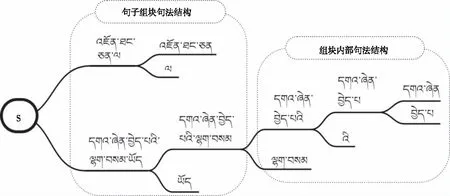
图4 藏文句子二分树形结构

图5 测试集中的句子和组块数量
5.2 实验及结果分析
为了验证本方法的有效性,设计了三组实验,分别考查了藏文句法分析效果、不同句长对本方法性能的影响以及本方法在不同题材数据集上的通用性,为了能够有效对比实验结果,三组实验所用的预训练语言模型和测试数据都一样。
实验一:因目前尚未查阅到有关无监督方法的藏文句法分析研究报道,无法直接与前人的藏文句法分析研究工作和结果进行比较,故为了验证本方法的有效性,实验时采用文献[6]中的无监督句法分析方法,在本文测试集上进行了句法分析,以此作为基线。为了验证本方法的有效性和优越性,在词长度为4-15的1200句测试集上进行了对比实验,对比实验结果见表1。

表1 藏文句法分析对比实验结果
从表1中的实验结果可以看出,采用无监督进行藏文句法分析时,在测试集上基线模型的正确率达到了31.47%,经分析,基线模型效果较差的原因有二,一是测试集中30%的藏文句子词数大于10,随着词数增多,出现了各词之间的语义相关度降低问题;二是随着句子变长而虚词增多,易出现虚词聚类错误问题,因此直接采用文献[6]中的无监督方法进行藏文句法分析时,藏文句法分析效果不好。
另外,从表1中还可以看出,无监督藏文句法分析方法和组块分割方法结合时,藏文句法分析正确率达到了49.27%,表明加入组块分割方法有助于提高无监督藏文句法分析的效果。当无监督藏文句法分析方法和句法优化方法结合时,藏文句法分析正确率达到了53.24%,表明藏文句法优化算法符合藏文自身的语法特点,有助于提高无监督藏文句法分析的效果。当组块分割+无监督+句法优化时,藏文句法分析的正确率达到了82.76%,相比基线模型的正确率提高了51.29个百分点,验证了本文方法的有效性。
实验二 为了考查句子长度对本方法的影响,将测试集分成了四组不同句子长度的子测试集,然后在四组子测试集上进行实验,其结果见表2。
从表2中可以看出,随着句子长度的增加,句法分析性能呈下降的趋势,这是因为本方法的基础是无监督句法分析方法,而无监督方法随着句子长度的增加越难获取词与词之间的语义相关度。

表2 不同句长数据集上的句法分析结果
实验三 为了验证本方法的通用性,分别在新闻、法律和小说等题材的数据集上进行实验,并计算了与实验一的偏差,实验结果见表3。

表3 不同题材数据集上的句法分析结果
从表3中可以看出,本方法在不同题材数据上的句法分析效果有所偏差,在法律数据集上的效果最佳,正确率到达到了86.79%。在小说数据集上的效果较低,正确率只有79.11%。原因在于常用的法律文本结构规范,内容严谨,所以其句法分析效果较好。常见的小说文本语言灵活多变,会用各种修辞手法,所以导致其句法分析效果较低。各类数据集上的句法分析正确率与实验一的最高偏差为4.03%,证明本方法在不同题材数据集上的通用性。
6 结束语
在无藏文句法分析树库数据集的情况下,为了能够进行句法分析,提出了一种基于组块分割的无监督藏文句法分析方法,研究结果为:
1)对藏文组块进行了定义和分类,规定了面向藏文无监督句法分析的藏文组块分割边界。
2)结合组块分割、无监督藏文句法分析模型和藏文句法优化算法,提高了无监督句法分析效果,经实验表明,句子长度为4-15个词的单句数据集上正确率达到了82.76%,验证了本文方法的有效性。
猜你喜欢
小学生作文辅导·下旬刊(2020年5期)2020-07-23
中学课程辅导·教师通讯(2020年22期)2020-02-04
中学生英语·外语教学与研究(2017年4期)2017-04-14
黑龙江教育学院学报(2015年11期)2015-12-02
文苑(2015年9期)2015-09-10
新课程学习·中(2013年3期)2013-06-14
小学生时代·综合版(2009年11期)2009-12-29
中学数学研究(2008年3期)2008-12-09
