
基于模糊信息粒的停车泊位可变容量预测
2022-06-14 10:03卢海军张道明
计算机仿真 2022年5期
乔 雪,卢海军,张道明
(齐齐哈尔大学,黑龙江 齐齐哈尔 161006)
1 引言
在社会经济快速发展的背景下,大众的交通需求逐渐提升,拥有私家车的人数也与日俱增,导致商业区与行政服务集中区出现了停车难的情况,增加了交通的拥堵程度[1,2]。研究结果显示,三分之一的交通拥堵是由寻找停车位造成的[3,4],所以,停车泊位可变容量预测具有非常重要的研究意义。
刘菲[5]等人提出基于优化LSTM模型的停车泊位预测算法,建立LSTM模型,通过该模型对经过网络预测后的时间序列进行进一步训练。利用多个实测道路停车场的实时数据进行有效性验证,分析实验结果可知,该算法预测效率较高,但预测精度有待提升。金康[6]等人提出基于引力和斥力的停车位发现算法,该算法通过定义停车位引力因子和车间斥力实现对停车位的分级,并分析了各因子之间的竞争关系。实验结果表明,该算法缩短了车辆停车位的搜索时间,但若预测步长数量有所增加,所得结果的精准度会出现极大程度的下降。
针对上述问题,本文通过模糊理念的运用,对基于模糊信息粒的停车泊位可变容量预测进行研究,将时间作为变量,创建路内线性函数与路外阶段性函数表达式,基于容量函数及对应约束条件,实施各项指标运算,采用模糊信息粒处理时间序列数据,通过隶属度函数完成数据转换,利用特征数据合理描述初始窗口信息,得到以子序列窗口为基础的模糊信息矩阵,通过大量记忆模块的引入与样条插值处理,对特征数据进行重构,最后根据获取的完整预测时间序列数据,使停车泊位可变容量预测得以完成。
2 基于模糊信息粒的停车泊位可变容量预测方法
2.1 停车泊位可变容量分析
一个物体的粒化会生成一系列粒,而每一粒都是一个簇点,复杂的空间信息构成了信息系统,而大量的空间信息粒则组成了空间信息。信息粒化(Information Granulation,简称IG)在许多方法与技术里都占有一席之地,其对信息粒的处理主要采用非模糊化形式,但空间信息与判定推理时涉及到的大部分空间信息粒都是模糊的,也就是说,空间信息粒具有模糊性。
根据上述原理分析,运用模糊信息粒对停车泊位可变容量进行预测。由于停车泊位容量可变,因此对路内、路外的停车泊位展开分析,分别构建相应的函数表达式。将规划路内停车泊位的可变容量设定为N内,建立线性函数,如下式所示
N内=at+b0
(1)
式中,b0为路内停车泊位的初始可变容量,a为参数,t为当日零时整的预测时间戳。
不同于路内停车场,路外停车泊位要建立地下停车场、立体停车库等专门的停车场所,因此其泊位可变容量具有一定的周期性,并且建立周期很长。由于停车泊位可变容量将随着时间的递增而呈现阶段性的提升趋势,因此以时间t为变量,对规划路外停车泊位可变容量阶段性函数进行创建,得到如下公式

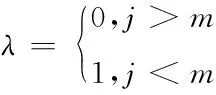
(2)
式中,λj为停车场所建立的第j阶段系数,Nj为第j阶段的路外停车泊位容量,m为规划停车场建立阶段的总数。
综合上式,得出停车泊位可变容量函数表达式

(3)
其相应的约束条件为pi(t)≤p′i(t),根据时间分布函数pi(t)以及第j小时的停车泊位容量进行求解,其计算公式分别如下所示
pi(t)=xPi+yt
(4)
Pij=Pi+j·(tj-1)
(5)

(6)
并采用下列函数Fi(·)表示第i类机动车驾驶员的出行效用
Fi(pi,di,hi,vi)=βi1pi+βi2di+βi3hi+βi4vi
(7)
由于函数计算对泊位容量的预测准确性不高,所以,引入模糊信息粒,提升预测精准度。
2.2 模糊信息粒引用及数据转换
2.2.1 引用模糊信息粒
基于一定的分类准则,对一个信息整体进行分类,从而完成对部分的划分,其中分解得到的部分就是信息粒。当前共存在三种主要的信息粒化模型:模糊集模型、粗糙集模型以及商空间理论模型。通过模糊信息粒化方法的应用,实现停车泊位可变容量的模糊信息粒化处理。该粒化方法由窗口分类与信息模糊化两个环节构成,其中,窗口分类把所有时间序列分解成若干个子序列,各子序列都是一个操作窗口;信息模糊化基于一定的模糊原则,转换所有窗口数据为对应的模糊信息粒。作为粒化阶段的重点,信息模糊化应实现初始窗口信息可以被新架构的模糊集合替代。
若针对单个窗口,将总体数据序列Q当成一个窗口,然后实施模糊化处理,也就是说,模糊化任务在序列Q中架构模糊粒子g。下式表示模糊概念G和模糊粒子g的关系
g=Fi(x·G)
(8)
式中,x为论域的变量,以X为论域的模糊集合就是模糊概念G。
模糊粒子的常用形式为三角形、高斯型、抛物型以及梯形等。因为预测对象为停车泊位的容量变化,相当于对窗口数据的大小极值进行求解,因此,需要采用三角形模型粒子完成数据转换,下式所示即为其隶属度函数表达式
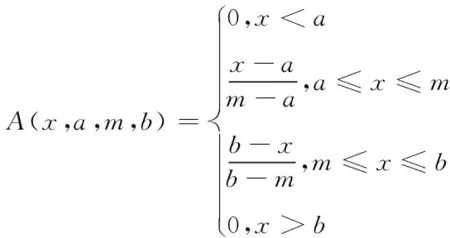
(9)
式中,a为初始数据变化的极小值参数,表示该窗口的数据变动下限;m为平均值,表示数据变化平均水平;b为极大值,表示数据波动上限。
2.2.2 窗口数据变化
因为停车泊位容量是一种可以根据时间改变而持续变更的数据,因此针对其庞大的非线性时间序列[7]数据,需采用压缩方法提取重要信息,从而取得相应的特征数据集合。通过模糊信息粒化策略的采用,能够重构和粒化停车泊位容量的时间序列,该策略为提取大规模数据重要信息的有效途径。模糊信息粒化时间序列共有以下两个阶段:
1)分解时间序列为若干个子序列,形成执行窗口。
2)模糊化所有操作窗口,架构模糊集合,该集合即为模糊信息粒。
由于经过处理的数据样本仍能留存初始样本数据的属性,因此,对一组较小的样本区间进行获取,计算过程将更为便捷。
设定X为停车泊位的时间序列数据,其表达式如下所示
X={xt1,xt2,…,xti}
(10)
式中,xti为在ti时的停车泊位容量。
根据现实需求对一个等间隔时间粒度T序列数据进行分解,将所得的多个子序列[8]数据作为粒化窗口,并得到各粒化窗口相应的停车泊位容量极值与初始、末尾时刻停车泊位容量。设定第k个粒化窗口中泊位容量的极小值为lowk,极大值为upk,初始时刻泊位容量用startk表示,末尾时刻泊位容量用endk表示,得到下列表达式
Pk=(startk,lowk,upk,endk)
(11)
其中,k=1,2,…,n。对初始窗口数据采用四个特征数据进行合理描述,实现初始时间序列的简化,相当于将时间序列数据进行模糊信息粒化。基于所得的low、up数值,引入各窗口中的时间特征,对low、up值相应的峰值时间tlow与tup进行获取,最终获得Y1,Y2,…,Yn。根据下列表达式,转换时间为时间戳[9]Tstamp
Yk=(lowk,tlowk,upk,tupk)
(12)
其中,k=1,2,…,n。由于经过转换的时间戳数值较大,无法与数据特征进行拟合,所以,通过下列公式对时间偏移t′进行界定
t′=Tstamp-Yk[t+(k-1)×60T]
(13)
式中,Tstamp为当前时间戳,T为明确后的时间粒度,第k个粒化窗口用k表示。把所有粒化窗口的峰值时刻变成区间为(0,60T)的值后,得到下列表达式
Y′k=(lowk,t′lowk,upk,t′upk)
(14)
通过合并所有子序列窗口的模糊信息,可以取得如下所示的矩阵X′与Y′
2.3 模糊信息粒化下停车泊位预测的实现
根据模糊信息数据转换的特征矩阵,对停车泊位容量变化特征进行预测,从而制定具有记忆属性的预测策略,其不仅可以避免反向传输的梯度爆炸[10]与衰减等弊端,而且能够通过隐藏层中的记忆模块,实现时间序列短长期的关系联立,利用重要信息的筛除、储存控制,完成泊位容量的预测。
预测策略内含有大量的记忆单元,其主要组成部分有输入门、输出门、遗忘门以及储存模块,框架图如图1所示。
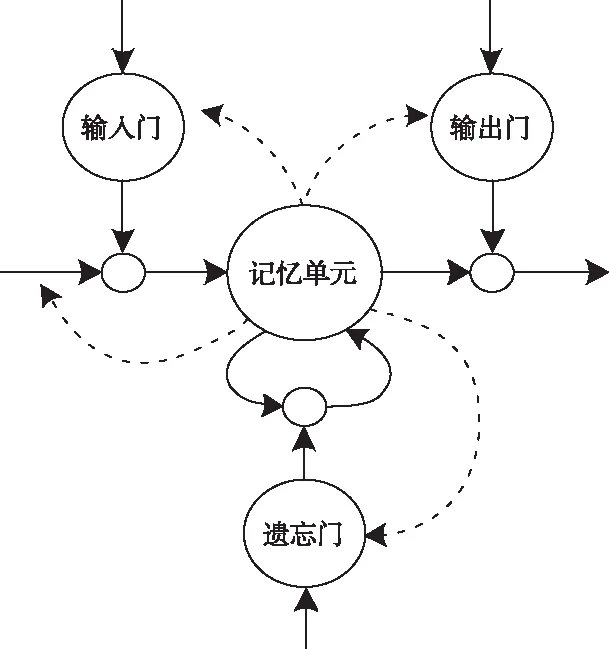
图1 记忆单元框架示意图
若策略输入由特征矩阵X′与Y′来实现,那么前者负责泊位数变化的预测,后者则负责峰值时间的预测。依据策略中隐藏层的迭代运算,得到第k+1个粒化窗口的泊位数量变化与相应峰值时刻t′lowk、t′upk,其中,泊位数量变化表达式如下所示
Pk+1=(startk+1,lowk+1,upk+1,endk+1)
(17)
由于上述预测特征数据为离散分布的形式,而插值就是基于离散数据,实施已知函数参数的确定或者建立近似函数,令其可以理想拟合已知数据,从而完成“断链”部分模拟值的求解,使曲线得以重构。
通过三次样条插值完成相应的数据处理,以重构特征数据,并获取预测区间中泊位容量的连续变化状态。相比于高次样条,该插值的运算量更小,内存占用更少,运行更加稳定,对整体的灵活性与运算效率做出合理的考虑后,制定如下的插值重构流程:
1)升序排列第k+1个粒子窗口时间序列,并实现区间划分,从而完成相应时刻泊位容量的获取。
2)经过三次样条插值函数的建立,使插值重构得以达成。
设定[t′startk+1,t′upk+1]、[t′upk+1,t′lowk+1]以及[t′lowk+1,t′endk+1]分别为粒化窗口分解的三个区间,以区间[t′startk+1,t′upk+1]为例,对相应的三次样条插值函数建立进行描述,因此,下列公式即为三次样条插值的函数表达式
S(xj)=dj(x-xj)3+cj(x-xj)3+bj(x-xj)
(18)
式中:j=0,1,…,n-1,xj与yj分别表示某一时刻及其相应的泊位容量,mj为常数值。
采用建立的插值函数插值重构预测区间,基于插值曲线获得相应的预测时间序列数据。同理插值处理区间[t′upk+1,t′lowk+1]与[t′lowk+1,t′endk+1]后,将所得序列数据相结合,即可获取完整的预测时间序列数据,最终预测出停车泊位的可变容量。
3 仿真与结果分析
为了验证基于模糊信息粒的停车泊位可变容量预测方法是否具有可行性,进行仿真。选取某一地区地上停车场作为实验对象,对文献[5]方法、文献[6]方法与本文方法进行对比分析。仿真环境基于MATLAB R2012a软件,采用64位Windows7系统,奔腾双核2.8GHz CPU,8GB运行内存。
对实验研究区域的停车设施进行重点调查,汇总分析调查得到的数据,从而得到该停车场停车泊位的周转率与利用率情况,具体结果如表1所示。

表1 实验区域停车场停车泊位情况
根据停车泊位的情况,将预测结果与实际值一起绘制成图,观察二者之间的拟合效果,该停车场的实际泊位容量曲线与本文方法的预测曲线如下图2所示。

图2 停车场泊位容量预测
根据预测曲线图发现,本文方法与实际容量曲线走势拟合度较高,本文方法的预测结果与实际值之间差距较小,可以说明该方法的预测结果较为准确,这是因为本文方法基于模糊信息粒方法,将时间序列关系进行联立,并采用三次样条插值方法实现特征数据的重构。在数据重构的基础上,预测区间泊位容量的变化状态,从而提高了预测准确度。
根据上述实验环境与停车场实际容量曲线图,选取某天的6:00-120:0时段做具体比较,分别采用文献[5]方法、文献[6]方法与本文方法对该停车场泊位容量进行预测,测试不同方法的预测准确度,结果如图3所示。
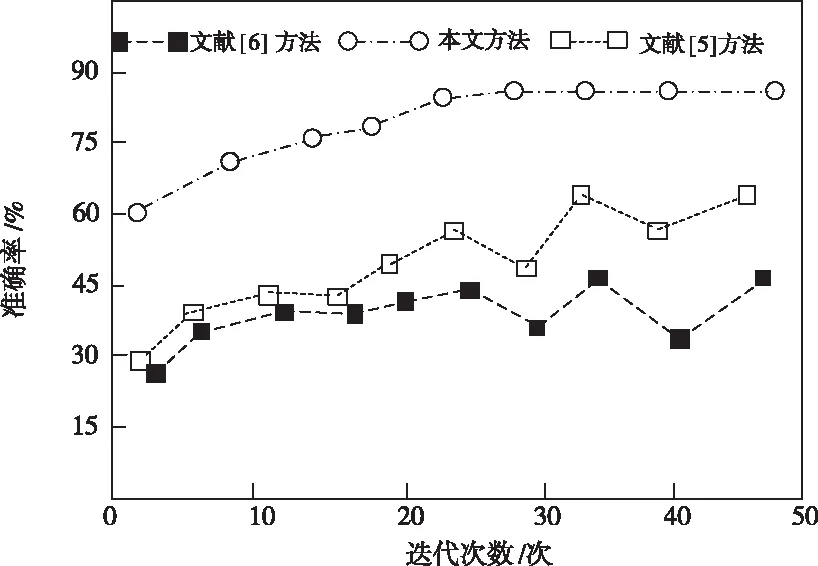
图3 不同方法预测准确率对比
通过图3可以看出,相比于文献[5]预测方法和文献[6]预测方法,本文方法的停车泊位可变容量预测结果准确率更高。说明基于模糊信息粒的停车泊位可变容量预测方法可以为用户提供准确的可用车位数量,辅助其迅速找到车位,使停车难度得到一定的缓解。该方法不仅可以防止用户抵达停车场所才得知没有泊位的状况产生,而且解决了因停车而引发的交通堵塞问题。
4 结论
为了使用户的出行更加便捷,本文提出一种基于模糊信息粒的停车泊位可变容量预测方法,依据时间变量,对线性函数与阶段性函数进行架构,根据所得容量函数与约束条件,对相关指标与用户出行效用进行计算,通过模糊信息粒及其隶属度函数,完成时间序列数据的处理与转换,利用记忆模块实现时间序列联立,依据插值的离散数据,建立近似函数,以达成特征数据重构,基于完整的预测时间序列数据,预测出停车泊位可变容量。经过仿真,本文方法能够精准预测停车泊位容量,信息粒化概念的引入,较好地解决了停车泊位容量预测不精准的问题,为后续研究提供了一定的理论支撑。
猜你喜欢
人民黄河(2021年4期)2021-04-27
发明与创新·小学生(2020年4期)2020-08-14
汽车与安全(2019年5期)2019-07-30
环境与发展(2018年6期)2018-09-17
城市地理(2017年9期)2017-11-02
珠江水运(2017年16期)2017-09-21
发明与创新·小学生(2016年4期)2016-08-04
现代经济信息(2016年6期)2016-05-31
计算技术与自动化(2014年1期)2014-12-12
科技致富向导(2013年21期)2013-12-10
