
改进FA优化LSTM的时序预测模型
2022-06-09 11:58张忠林
计算机工程与应用 2022年11期
张忠林,张 艳
兰州交通大学 电子与信息工程学院,兰州 730070
时间序列预测就是通过分析时间序列,去进行类推或者延展,常作为一种有效预测手段而被广泛应用于金融[1]、气象预测、交通分析预测[2]、市场分析、人类行为预测[3]等领域。其中,自回归模型[4]的出现使得时间序列预测建模逐步成熟,但是同时也存在一些问题,包括模型的识别、估计和解释等。近年机器学习的出现使得预测可以通过不断的重复训练来逼近真实模型以此达到较好的预测结果。人工神经网络[5]、支持向量回归、基于核方法[6]以及基于树[7]的集成学习方法在处理时间序列预测输入变量之间的序列依赖性时仍然存在一定的缺陷。长短期记忆神经网络(long-term and short-term memory network,LSTM)[8],由于其包含时间记忆单元,因此适合处理和预测时间序列中的间隔和延迟事件,从而广泛应用于时间序列预测任务。基于现有的文献,不难发现LSTM模型输入参数仍依靠经验选取,特别是时间窗口大小、批处理数量、隐藏层单元数目,随机性的赋值大大降低了模型的预测性能。为了提高输入参数的准确性以及扩展LSTM模型的应用范围,引入各种改进方式来提高LSTM的综合性能。
其中许多学者提出使用智能算法充当优化器优化LSTM的输入参数。受小生境技术的启发,有学者提出了多群体策略,以保持种群的多样性,这对于寻优效果至关重要。文献[9]采用不同的学习策略分布对不同类型的粒子进行更新,提高种群多样性,增强了粒子的寻优效果,从而优化了LSTM的输入参数,有效预测了股票价格走势。表明对智能优化算法种群多样的增强会有效提高算法性能,但该算法未考虑到算法陷入局部最优。文献[10]使用Logistics混沌映射去提升FA初始种群的多样性,并加入线性递减惯性权重去帮助算法跳出局部最优,取得了较好预测效果。以上研究表明对智能算法种群多样性的有效干涉会提高算法寻优性能。
由于不同的智能算法有其自身的优点,因此很自然会考虑将不同的算法或策略结合起来处理复杂问题。文献[11]将FA与序贯二次规划(SQP)相结合,用于钢筋混凝土基础的设计优化,该算法结合了FA的全局搜索能力和SQP的精确局部挖掘能力,弥补了搜索能力和开发能力之间的矛盾。文献[12]使用了蚁群与粒子群混合算法优化LSSVM的脉动风速取得较好的效果。研究表明,诸如此类的混合模型会将单一模型优势互补,具有更快的收敛速度和更高的解质量等综合性能。
受到以上研究的启发提出了一种改进的萤火虫智能混合(GAFA)优化算法,该算法将遗传算法(genetic algorithm,GA)[13]中的选择算子、交叉算子和变异算子集成到FA中,去增加FA种群多样性以提高算法性能,将改进后的FA应用于LSTM模型输入参数的优化,以此搭建一个高精度的时序预测模型。
1 相关工作
1.1 LSTM模型
LSTM模型有三个控制门来对信息进行选择性通过[8]。首先是遗忘门f对输入x t的遗忘程度,保留下来部分送往输入门,输入门i中的x t经激活函数sigmoid和tanh共同控制保留向量,最后经由输出门h输出当前值,其结构如图1所示。
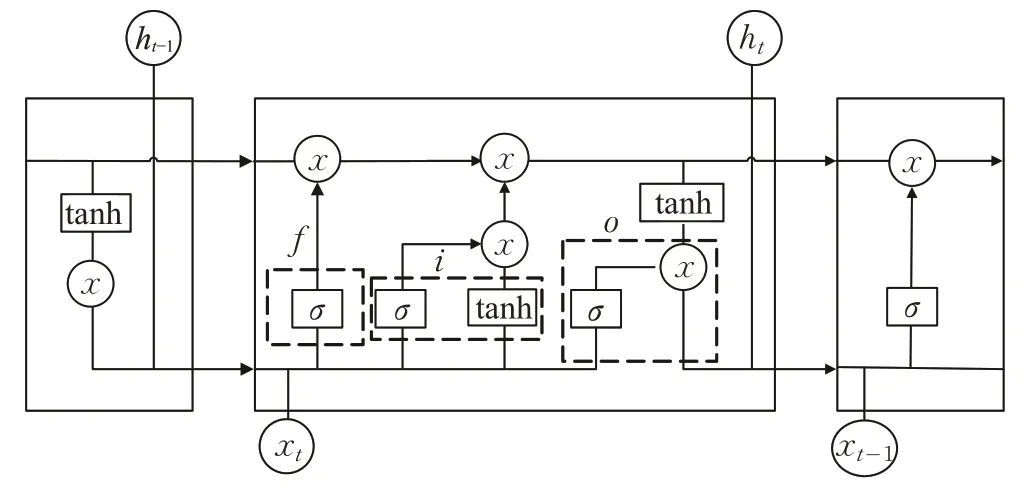
图1 LSTM模型结构Fig.1 LSTM Model structure
式(1)~(7)是它的数学表达:
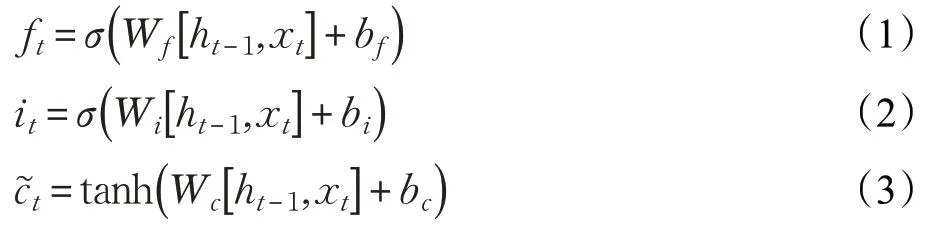

1.2 萤火虫算法
萤火虫算法由Yang等提出[14],在FA中,萤火虫的亮度I取决于它的位置X,它被认为是一个潜在的解,且群体的运动轨迹可以描述为一个搜索过程。它的实现是将空间中的每一只萤火虫视为解决问题的候选人,而发光强的萤火虫则吸引较弱的萤火虫,它们最终集中在较亮萤火虫周围,萤火虫在移动过程中完成了位置信息的更新,即完成了更新[15]。以下是它的数学表达,相对荧光亮度,如式(8):

式中,I0表示光源的光强度,γ是传播介质的光吸收系数,I与β成正比,可以描述为式(9):

其中,β0是r=0时的吸引力,βmin是最小吸引力。根据上述定义,萤火虫的运动可以描述为式(10):
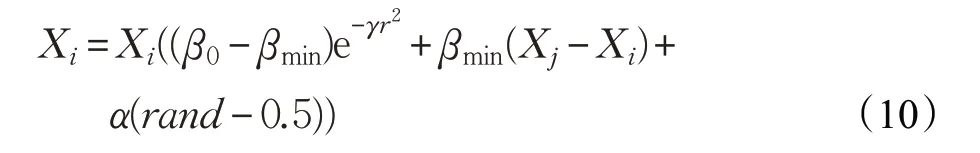
其中,α是决定随机游动大小的参数,rand是均匀分布在[0,1]上的随机数。
2 改进萤火虫算法
2.1 优化算法选取
在选取优化器时,考虑了FA、粒子群算法(particle swarm optimization,PSO)[16]以及蚁群算法(ant colony optimization,ACO)[17],分别对它们的初始参数、适用场景以及抗早熟能力进行了权衡。ACO较PSO以及FA显著差异是它的正反馈机制,这就决定它不能进行全局信息共享,且ACO对问题的维度较为敏感,所以本文在FA和PSO之间进行了选择。最终在验证实验中选取了FA,具体实验在4.4节中显示与讨论。
2.2 自适应多样性增加机制
早熟趋同被认为与个体在种群中的趋同密切相关,这对于持续搜索优化算法至关重要。多样性越大,种群越分散,越利于算法的全局搜索,反之,种群越集中,越利于算法的局部搜索。为了使FA算法有更好的处理问题能力,将遗传算法中的选择、交叉与变异算子集成到FA算法中,通过轮盘赌选择法,选择确定执行交叉变异的个体,将选择到的算子复制n次,产生新的种群个体,后使用改进的交叉变异概率在新的种群中创建新的种群个体,达到种群多样性再生的目的,避免陷入局部最优,增强算法搜索能力,找到问题的最优解。
FA由于其随着迭代次数的增加,种群的多样性也逐步减少,于是,FA参数完成初始化后,在种群开始进化的进程中引入多样性度量公式,计算当前多样性进化结果与上一次多样性进化结果的差值,迭代初期,收敛速度较快,连续多次的多样性计算差值较大,t-(t-1)的迭代结果为正数。迭代后期,逐渐接近最优解,t-(t-1)的迭代结果为负数。进行连续三次差值计算,若三次结果都是负数且呈现递减趋势就证明接近最优解,陷入了局部最优,此时引入自适应多样性增加机制丰富种群多样性,这即是触发多样性增加机制的条件。在计算出多样性后,判断是否满足多样性增加机制的条件,如果满足条件就将遗传算法中的选择、交叉与变异算子集成到FA中,创建新的种群,开始新一轮的迭代,同时为防止迭代到最后的局部震荡,加入了自适应游动参数,防止局部震荡的出现。本文采用任意两个个体之间的平均距离来度量种群的多样性,平均距离越大证明种群越分散,平均距离越小,证明种群越集中,|s|为种群个体个数,在种群中任取两个不同的粒子计算平均距离,如式(11)所示:
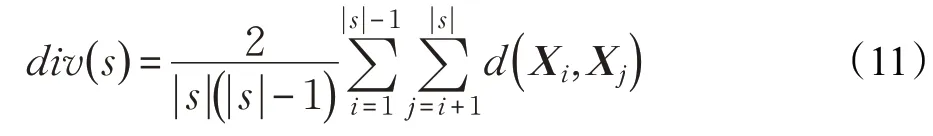
其中,d(X i,X j)为欧式距离。粒子i和j的位置向量分别为X i=[Pi1,P i2,…,Pin],X j=[Pj1,P j2,…,P jn],则其欧式距离如式(12):

FA迭代后期由于种群多样性的弥散,种群对于多样性的要求也随之降低,上述提到在识别到FA陷入局部最优时引入多样性增加机制,但是算法迭代后期不需要特别分散的种群去做全局搜索,就需要较小的多样性增加机制的概率,因此赋予多样性机制一个递减趋势的权重来平衡算法由于多样性需求降低而减缓收敛速度的要求,算法迭代前期ω值较大,后期ω值较小,更新度量多样性公式如式(13):
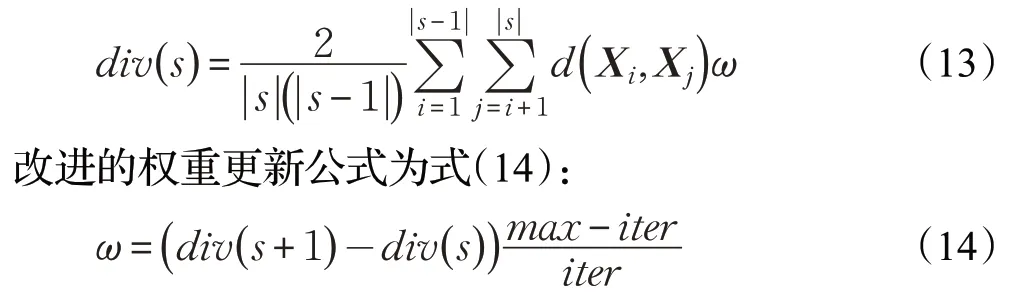
其中,max为最大迭代次数,iter为当前迭代次数。
2.2.1 选择算子
本文采用基于比例选择的轮盘赌选择法[18],依据萤火虫个体在迭代更新中个体亮度值来选择执行交叉变异的萤火虫个体,以此创建新的种群,依据式(15)对萤火虫个体进行选择:
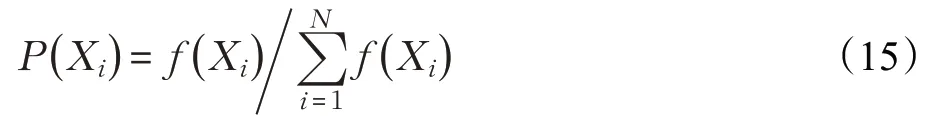
其中,f(X i)为萤火虫个体Xi的亮度值,P(X i)为个体
被选概率,同时将个体被选概率累加,后通过随机数对随机数落在的区域对应的萤火虫个体进行选取。
2.2.2 改进的交叉变异算子
在传统的遗传算法中,交叉和变异算子的值通常被确定为0.3≤Pc≤0.8和0.001≤Pm≤0.1,在实际操作中一般都选取某一固定值,这样的选取带来很多局限性。在算法进化初期,个体适应能力较弱,适应能力比平均适应能力差,需要较大的交叉概率值来进行全局搜索范围,同时选择较小的变异概率来保存染色体中的优良基因。在算法进化的后期,个体适应度超过了平均适应度值,此时需要较小的交叉概率进行局部搜索,同时需要增加变异概率来增强算法的局部搜索能力[19]。改进后的交叉与变异概率为式(16)、(17):
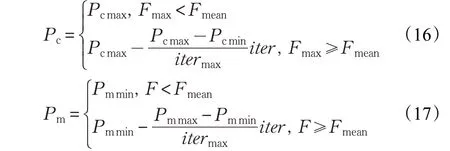
其中,Fmax为个体最大的适应度,Fmean为个体平均适应度,iter为当前迭代次数,F为父代染色体的适应度值,Fmin为个体最小适应度值。
2.2.3 自适应游动参数
从式(10)可以看出,决定随机游动大小的参数是一个固定值,使在迭代前期能较好实现全局搜索,而迭代后期由于多样性的弥散萤火虫个体围绕最优点做局部搜索,此时的α由于是一个定长值可能会使得无法收敛到最优点,所以本文采用自适应因子来自发平衡算法前后期的矛盾,迭代前期由于种群分散采用较大的游动参数进行全局搜索,迭代后期种群集中采用较小的游动参数进行局部搜索。调整如式(18):

其中,α0为初始随机游动参数,max为最大迭代次数,iter为当前迭代次数。
2.3 GAFA算法时间复杂度分析
为了分析GAFA算法的时间复杂度,给出了它的伪代码,具体如下所示:

GAFA算法在每轮迭代中首先运用式(13)计算任意两个个体间的平均距离,其时间复杂度为O(n),接着个体会向发光较亮个体移动,其时间复杂度为O(n),迭代t次,因此GAFA算法迭代一轮的时间复杂度为O(n2t)。
2.4 改进效果测试
为了直接观察到GAFA与FA在寻优效果上的显著差异,本文对两者进行了改进效果的测试。具体实验细节在4.5节中显示与讨论。
3 GAFA-LSTM模型
时间序列数据预测受到多方面因素的影响,具有一定的不稳定性。本文将选用在时间序列分析与预测中表现优异的LSTM模型为基础,构建时间序列数据预测模型。首先将LSTM模型的时间窗口大小、批处理处理量和隐藏层单元数的取值范围分别作为改进萤火虫算法的初始群体,应用贪心策略思想分别取得表现最优的参数个体,进而组成一组最优参数组合,将这一参数组合作为LSTM的输入参数[20]。此外,为了进一步挖掘时间序列的时间依赖关系,本文将采用两层LSTM网络结构[21],进一步提高模型预测性能,至此GAFA-LSTM时序预测模型搭建完成。萤火虫算法广泛地应用于各种优化问题的求解,但随着种群多样性的减少,优化性能被削弱,改进后的萤火虫算法能够有效避免陷入局部最优,会使得LSTM模型能够有效确定最优超参数组合,实现高精度预测。其中,每一只萤火虫代表一种解,训练时,训练精度由平均绝对百分误差来衡量。
本文提出的改进萤火虫算法的混合优化器主要分五部分,FA的参数初始化模块、FA改进模块、LSTM结构模块、LSTM参数更新模块、LSTM训练预测模块。整个GAFA-LSTM算法的步骤如下所示,模块图如图2所示。
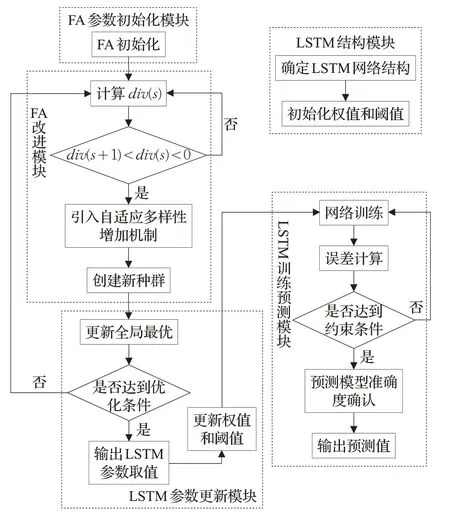
图2 改进萤火虫算法优化LSTM网络的算法流程图Fig.2 Improved firefly algorithm to optimize algorithm flow chart of LSTM network
步骤1初始化参数。
步骤2多样性计算。利用式(13)度量种群多样性,在连续迭代多次无果陷入局部最优时,引入自适应多样性增加机制,帮助跳出局部最优。
步骤3判断是否达到最优,更新最优值,如达到最优更新LSTM参数。否则返回步骤2。
步骤4保留最优参数组合,进行预测。
4 实验
4.1 数据集描述
用电负荷:该数据来自浙江某地区2020年2月至5月每隔1小时的实际用电负荷。用电负荷为实验中预测的目标值。
股票:该数据来自网易财经提供的某公司2019年7月至2020年5月的股票数据。股票的收盘价作为预测的目标值。
用气量:该数据来自前瞻数据库提供的重庆天然气2016年1月至2018年12月的用气量。用气量为实验中预测的目标值。
Beijing PM2.5:该数据来自UCI(machine learning repository)数据集,采样时间为2010年1月1日至2014年12月31日。PM2.5浓度是在实验中预测的目标值。具体数据集信息如表1所示。
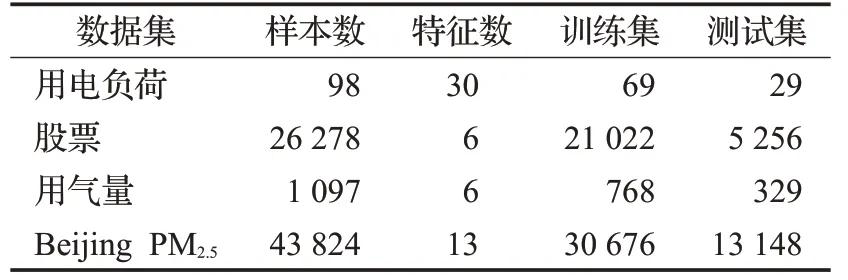
表1 数据集信息Table 1 Data set information
4.2 评价指标

4.3 实验设置
本文所有的实验均在Windows10 64位操作系统下进行,设备使用的处理器是AMD瑞龙3,显卡是gtx1080,内存大小为8.00 GB,实验环境是Python 3.6,开发工具为Spyder,后端使用tensorflow-gpu1.14。
4.4 优化算法选取分析
优化算法选取实验在FA和PSO中进行,经分析两者在初始参数阶段没有显著差异,为了找到更适用于本文场景的算法,将两者分别对LSTM的输入参数进行优化,并在Beijing PM2.5UCI数据集上进行验证对比,最终以适应度曲线形式体现算法优势[22]。实验结果如图3所示。
图3中可以看出FA在迭代前期适应度曲线呈梯度下降趋势,收敛速度优于PSO,且在迭代后期两者性能相当,在对抗早熟能力和适用场景比较分析之后决定选取FA算法对LSTM输入参数进行优化。
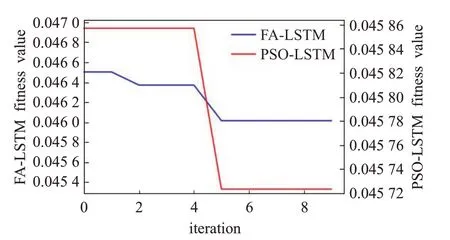
图3 FA与PSO适应度曲线图Fig.3 Fitness curve of FA and PSO
4.5 FA改进效果测试分析
在对本文所做的FA改进工作进行总结时,对其改进效果进行了测试,测试如下:将GAFA与FA分别进行寻优对比,实验中萤火虫粒子均为初始萤火虫群体。实验结果如图4所示。
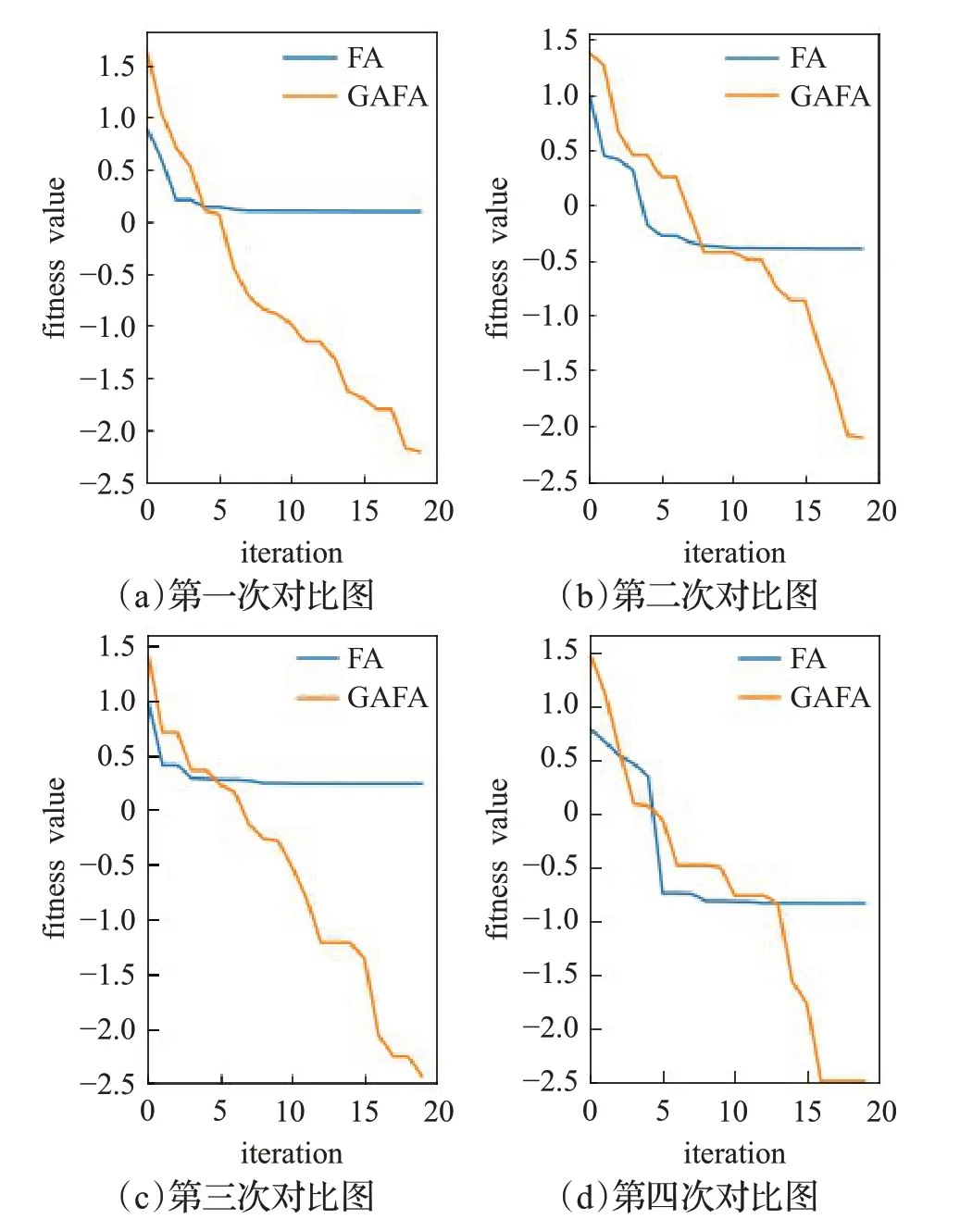
图4 寻优效果对比图Fig.4 Comparison diagram of optimization effect
图4经过20次迭代选取了四组寻优效果对比图,实验结果表明,改进后的萤火虫算法借助于种群再生的选择、交叉与变异算子,能够达到持续搜索的目的,与基础萤火虫相比,性能有了很大程度的提升。
4 .6 GAFA-LSTM模型验证
4.6.1 数据预处理
用电负荷数据集、用气量数据集和股票数据集均无缺失值,无需对缺失值进行处理,其中用电负荷数据是以一天的负荷为输出,将前n天的29个前5个用电负荷特征值作为输入[23],预测当天24时刻的负荷作为输出;对用气量数据进行处理时首先将字符型特征转化为数值,将前n个时刻的气象特征与用气量作为输入,预测当前时刻的用气量;股票数据集中将股票名称不作为特征值,输入变量为头十天内的开盘价、最低价格、最高价格。当天的收盘价作为输出;对Beijing PM2.5数据集中的离散特征数值化,即将字符型特征转化为数值,PM2.5值标准化之后均值为0,所以用0去替换缺失值,将前n个时刻的气象特征值与PM2.5值作为输入,预测当前时刻的PM2.5。然后,上述数据集中的四个输入变量都被处理为式(22),输出值按式(23)处理:

4.6.2 实验结果分析
此节采用经典LSTM模型、GA-LSTM模型、典型混合HFPSO-LSTM[15]模型,以及本文所提GAFA-LSTM这四种预测模型在四组不同领域的数据集上进行预测结果与实际结果的比对,并且通过拟合曲线图来体现不同预测模型的预测效果,如图5所示。
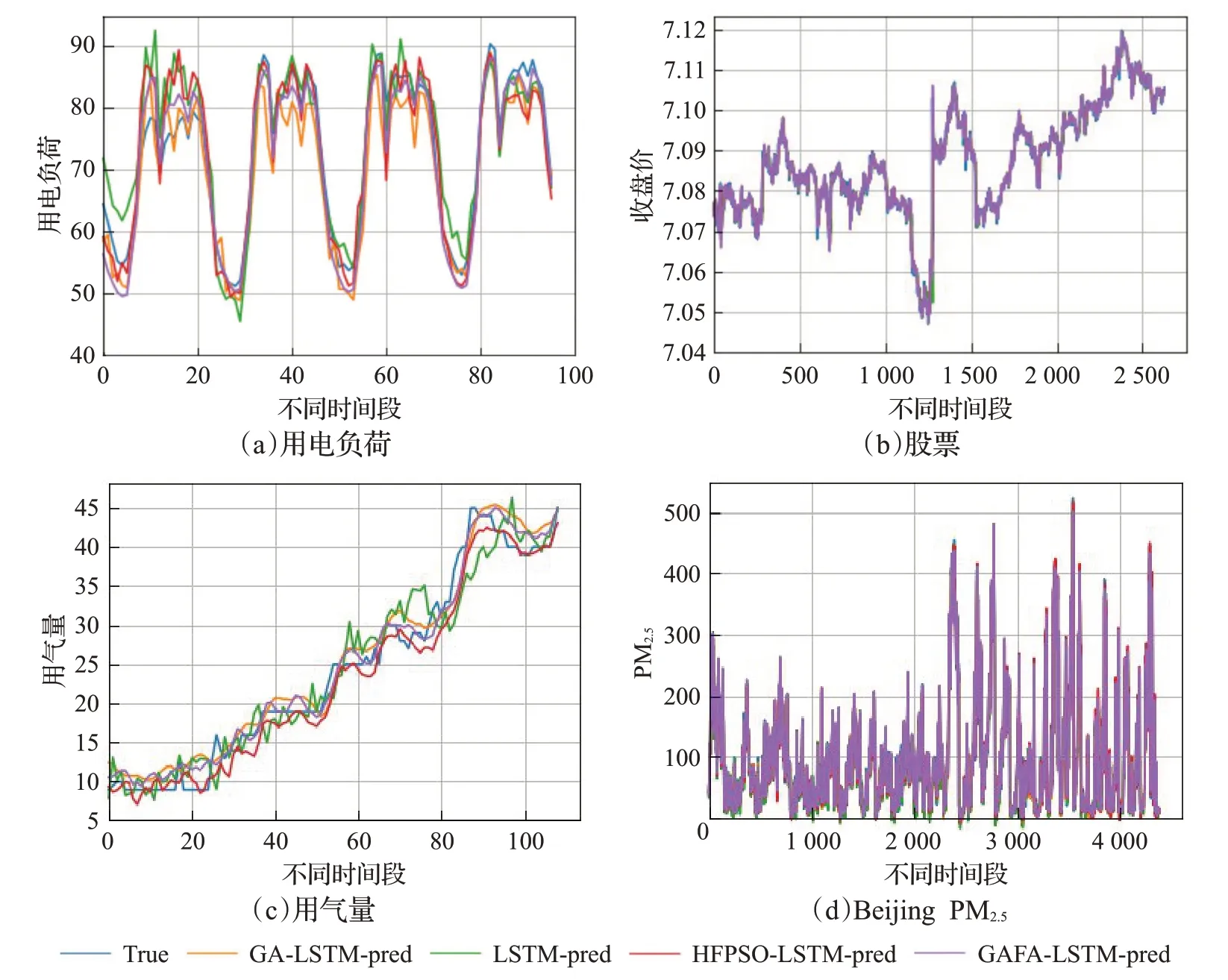
图5 不同模型预测值与真实值拟合效果图Fig.5 Fitting effect diagram of predicted value and true value of different model
图5为四种预测模型在四组不同数据集上的预测值与真实值的拟合图。其中图5(a)横坐标代表全部数据,图5(b)、(c)、(d)横坐标代表选取了10%的数据做了拟合图,所有图的纵坐标都代表实验中预测目标的值。其中四个数据集的时间跨度从3个月到4年,长度从98到43 824。从图中可以看出,四种预测模型在四组不同领域的数据集上的预测趋势与真实数据走向趋势基本吻合,但是LSTM与GA-LSTM的预测效果的拟合程度明显差于两种改进后的萤火虫算法优化模型的拟合程度,而本文所提的GAFA-LSTM的预测拟合程度又优于HFPSO-LSTM模型的预测拟合程度。这说明本文所提的GAFA-LSTM对LSTM网络模型的超参数的优化更加有效,可借鉴度更高,预测效果更加准确。
从表2结果看出,LSTM在四组数据集上的三种误差值的表现最差,GA-LSTM的预测模型在数据集上的误差得到一定程度的降低,但是在用气量和Beijing PM2.5的数据集上MAE的指标误差超过了单一神经网络的预测误差,HFPSO-LSTM预测模型的误差较GA-LSTM预测模型的误差更小,在四个数据集上的三个误差下的表现均具有优势,这从侧面反映出混合智能优化器优化参数的效果更有优势。本文所提模型的R2在四个数据集上分别为0.934 4、0.986 0、0.976 6与0.949 8,较其他三个模型的误差都小。其他两个指标也相较于其他3个模型的预测误差均不同程度地降低,其中MAPE达0.257 6,MAE达1.467 9,这表明本文所提GAFA-LSTM预测模型会使得预测更加准确,与真实数据的偏差小,进而提高了模型的预测精度。
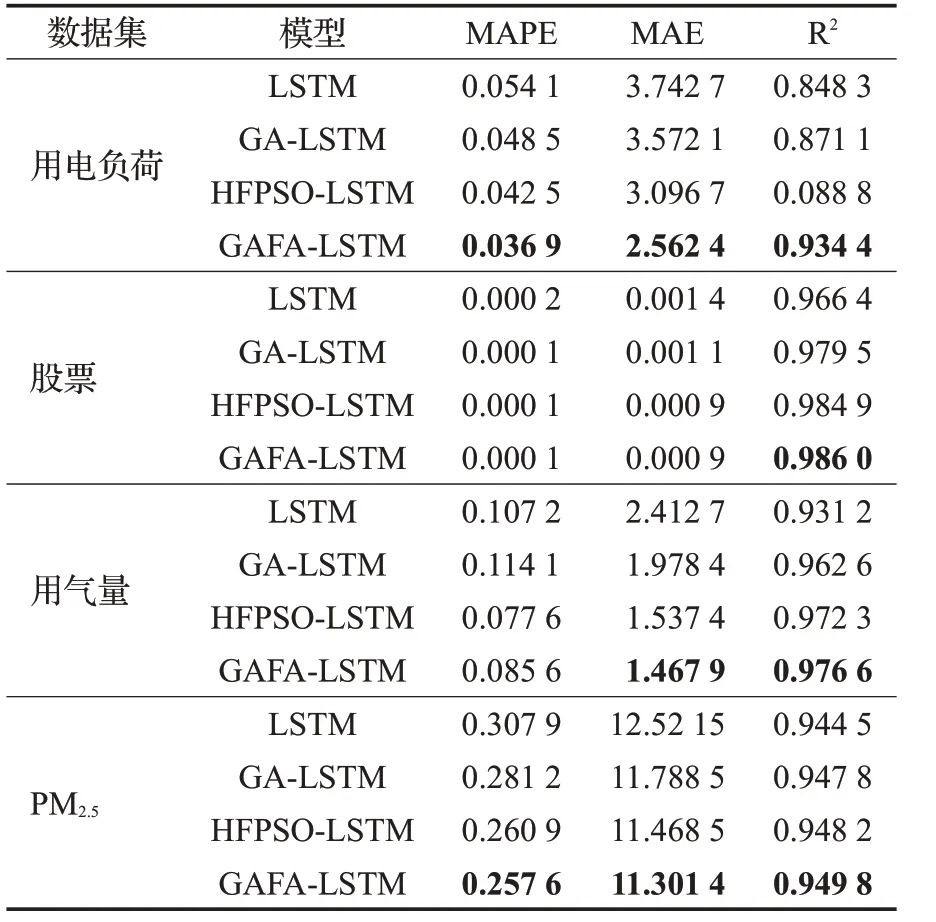
表2 四组数据集下不同模型的实验结果Table 2 Experimental results of different models under four data
根据以上两组实验可以得出,本文所提的GAFALSTM模型与实验中所提其他模型相比,拟合程度更高,在不同数据集上具有较强的泛化能力和较强的预测精度,而且在波动较大的数据集上也可以取得较好的拟合效果和较小的预测误差,是一种高效的时间序列预测模型。
4.6.3 模型性能分析
为了验证GAFA-LSTM模型的性能,将在时间复杂度和算法运行时间两个方面来对其进行性能分析。其中经过2.3节的分析,本文模型与其他3个模型的时间复杂度相同,都为O()n2,且因LSTM为单一模型所以不参与其他3个组合模型运行时间的比较。其中运行时间为运行10次的平均值。
从表3可以看出,在3个组合模型运行时间的比较中本文所提模型在股票数据集和PM2.5数据集上时间效率较高,分别为18.222 0 s与353.753 6 s,值得注意的是这两个数据集数据量都较大,股票数据集波动较大,PM2.5数据集平稳,说明本文所提模型鲁棒性和普适性都较好。
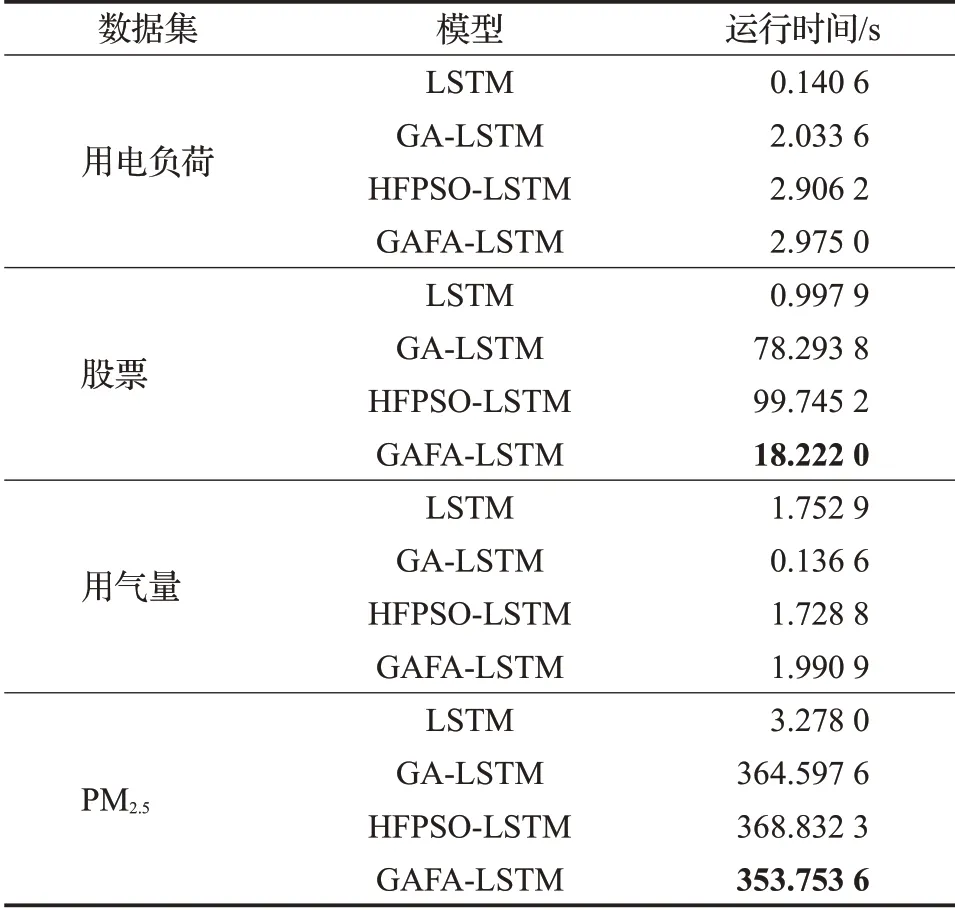
表3 不同模型性能分析结果Table 3 Performance analysis results of different models
5 结束语
为了进一步提高时间序列预测精度,本文提出了一种改进的萤火算法优化LSTM输入参数的时序预测模型。FA在寻优过程中由于多样性弥散而带来的陷入局部最优问题,提出加入自适应多样性度量机制增加多样性,来提高它的局部搜索能力,防止陷入局部最优。在迭代后期再加入自适应游动参数来避免大量萤火虫个体在最优值附近震荡的问题,同时将每个萤火虫个体看作一个超参数配置去不断优化更新LSTM模型的超参数取值从而来匹配到最优参数组合。
本文所提模型与上述实验中所提模型相比有以下两个结论。(1)首先提出一种改进的萤火虫算法,且效果在测试中表现较好。(2)其次采用改进萤火虫算法对LSTM的输入参数进行优化,搭建了一个GAFA-LSTM预测模型,解决了依据经验选取的参数而导致预测精度低的问题。本文构建的GAFA-LSTM模型较文中所提其他预测模型预测效果有较大幅度的提升。但是本文方法也存在一定的局限性。首先GAFA-LSTM可以取得良好的预测结果,但是未能进行更长时间跨度预测的输出,这将是下一步探究的方向。
猜你喜欢
今日农业(2022年15期)2022-09-20
四川大学学报(自然科学版)(2021年6期)2021-12-27
湖南电力(2021年1期)2021-04-13
计算机应用(2020年12期)2020-12-31
小天使·一年级语数英综合(2018年7期)2018-09-12
中学生物学(2018年8期)2018-03-01
小天使·一年级语数英综合(2017年6期)2017-06-07
为了孩子(孕0~3岁)(2016年1期)2016-01-16
文苑(2015年9期)2015-09-10
小天使·一年级语数英综合(2015年8期)2015-07-06
