
面向多元时序数据的个性化联邦异常检测方法
2022-06-09 11:57王昊天郑栋毅
计算机工程与应用 2022年11期
王昊天,郑栋毅,刘 芳,肖 侬
1.国防科技大学,长沙 410073
2.湖南大学,长沙 410006
多元时间序列数据已经广泛应用于现实世界中各个领域,例如天气数据分析和预测[1]、医疗保健[2]、金融[3]等[4-5]。异常检测是多元时间序列分析中的一类重要问题,目的是检测出不符合期望行为的序列数据,是数据挖掘关键技术之一。随着深度学习在学习复杂数据的特征表示方面表现出显著的优势[6],近年来使用深度学习方法进行异常检测受到越来越多的关注。例如,深度自动编码高斯混合模型(DAGMM)[7]综合考虑了深度自动编码器和高斯混合模型来对多维数据的密度分布进行建模;LSTM编解码器[8]利用长短期记忆网络(long short-term memory,LSTM)对时间序列中的时间相关性进行建模取得了较好的泛化能力。
但是,目前多元时序数据异常检测仍面临挑战。以飞行数据异常检测为例,飞行数据是典型的多元时序数据,有效的异常检测将提高航空系统的安全性和可靠性,并改善着陆后的维修行动组织。然而飞行数据具有高度商业机密性,造成了通用航空公司之间的数据壁垒;同时,不同类型、不同任务的飞行器生成的飞行数据具有高度不同的概率分布,使用单一的统一的检测模型不能适用于所有场景。因此,目前存在的挑战概括为以下两点:(1)由隐私安全带来的数据孤岛问题,使得一些领域内的数据难以融合,无法训练出高性能的异常检测模型。(2)由于来自不同机构的时序数据可能自发地呈现出非独立同分布的特征,例如特征分布偏斜、标签分布偏斜和概念偏移[9]等,这种统计异构性会导致严重的性能下降。
针对以上问题,本文提出了FedPAD,用于多元时序数据异常检测的个性化联邦学习框架。FedPAD可以同时解决数据孤岛和个性化问题。通过联邦学习[10]和同态加密[11],FedPAD聚合来自不同机构的数据,在云端构建高性能的深度异常检测模型,同时很好地保护了隐私数据。云模型建立后,FedPAD利用fine-tuning(微调)进一步为每个机构训练出个性化异常检测模型。
本文的主要贡献:(1)提出了一个面向多元时序数据的个性化联邦异常检测框架FedPAD,它在保护隐私安全的前提下聚合了来自不同机构的数据,并将LSTM时序预测模型与深度学习的fine-tuning技术结合,得到了相对个性化的检测模型。(2)展示了FedPAD在NASA航天探器数据集上的异常检测性能。实验表明,与基准方法相比,该方法有效提高了精确率与召回率。
1 相关工作
1.1 基于预测的多元时序异常检测模型
LSTM-NDT[12]使用长短期记忆网络来实现高性能的时序数据预测,同时保证了整个系统的可解释性。模型生成预测数据后,使用一种非参数、动态的阈值方法来评估残差。具体来说,设yi为输入序列第i时间步的信号值,为模型预测输出的序列第i时间步的信号值,那么预测误差为e i=y i-,用多个时间步的误差来计算阈值序列ε:

其中,e s是多个时间步的误差序列,μ(·)是均值,σ(·)是标准差,z是权重系数。每一个时间步的阈值εi是动态变化的,取决于之前整个阈值序列ε的最大值,计算公式如下:
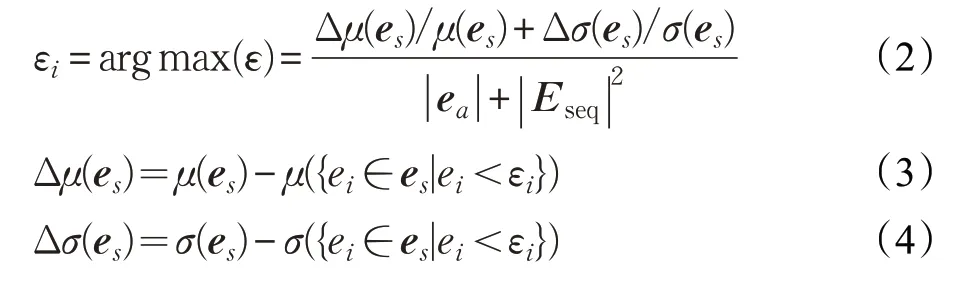
其中,e a是异常序列的误差值,Eseq是异常序列中的连续异常的误差值,表达式如下:

除此之外,还使用了剪枝方法来减少误报,将所有误差序列中的最大值emax按照降序排列得到e s,然后遍历序列计算下降百分比d i:

如果d i超过了最小百分比p,那么相关的异常序列仍为异常;如果d i和所有后续下降百分比都没有超过p,那么这些误差序列重新分类为正常序列。
1.2 联邦学习及个性化
联邦学习最早是在2016年由Google提出的[13]。其设计目标是在保证数据交换过程中的信息安全、保护个人数据隐私、确保法律合规的前提下,在多个参与者或计算节点之间进行高效学习。联邦学习能够有效地解决数据孤岛问题,在很多领域已经有了实际应用,例如,它对于移动设备上的下一个单词预测问题表现出了良好的性能和鲁棒性[14]。Bonawitz等人[15]提出一个可扩展的系统,在移动设备上实现大规模的联邦学习。Guo等人[16]在兴趣点推荐任务中使用边缘加速联邦学习框架,在保护隐私的同时,实现了高效的推荐性能。
机构参与联邦学习的主要动机是获得更好的模型,然而,对于那些拥有足够的本地数据来训练高效模型的机构来说,参与联邦学习得到的全局模型可能并不适用于其本身的检测任务。Yu等人[17]表明,对于许多任务,由于全局共享模型不如局部模型精确,所以一些参与者可能无法通过联邦学习来提高模型性能。Hanzely等人[18]对全局模型的性能提出了质疑,由于跨客户端的数据是非独立同分布的,这种统计异构性导致很难训练出一个对所有客户都适用的单一模型。为了解决这种异构性的挑战,规范的联邦学习方法——联邦平均法(FedAvg)被证明能够处理某些非独立同分布数据。然而,当面对高度偏斜的数据分布时,FedAvg可能会导致严重的性能下降。具体来说,一方面,非独立同分布数据会导致联邦学习过程和传统集中式训练过程之间的权重差异,FedAvg最终将得到比集中式方法性能更差的模型[19]。另一方面,FedAvg只从数据中学习粗略的特征,而无法学习特定任务数据上的细粒度特征。
为了应对统计异质性和数据的非独立同分布带来的挑战,个性化的全局模型变得十分必要。大多数个性化技术[20]通常包括两个步骤。第一步,以协作的方式训练一个全局模型。在第二步中,使用客户端的私有数据为每个客户端个性化全局模型。Arivazhagan等人[21]提出了FedPer,主张将深度学习模型视为基础+个性化层,基础层作为共享层,使用现有的联邦学习方法以协作方式进行训练,而个性化层是在本地培训的。Chen等人[22]首先通过传统的联邦学习训练一个全局模型,然后将训练好的全局模型传递回各个设备,相应地,每个设备都能够通过用其本地数据精炼全局模型来构建个性化模型。Hanzely等人[18]在传统的全局模型和本地模型之间作权衡,每个设备可以从自己的本地数据中学习本地模型,而无需任何通信。Zhang等人[23]为了实现个性化,没有像FedAvg那样计算模型参数的平均值,而是通过计算出一个客户端可以从另一个客户端的模型聚合中受益多少,得出每个客户端的最优加权模型组合。
2 本文方法
2.1 问题定义
{S1,S2,…,S N}代表来自N个不同的机构{Q1,Q2,…,Q N}的时序数据,不同机构的数据都有不同的分布。传统集中式的方法使用全局数据S=S1∪S2∪…∪S N训练一个统一的模型MALL。在本文的问题背景中,希望使用所有的数据来训练一个联邦异常检测模型MFED,在模型训练过程中,任何机构都不会相互公开自己的数据,模型训练目标是提高联邦异常检测模型MFED的性能,使得异常检测率接近或优于MALL。
2.2 框架概述
FedPAD旨在通过个性化联邦学习实现高性能的异常检测,同时保护隐私安全。图1给出了框架的概述,以飞行数据异常检测为例(可以扩展到其他场景),假设有三个通航公司,各有不同类型的飞行器。该框架主要包括四个流程,首先,基于公共数据集训练服务器上的云模型。然后,云模型被分发给所有机构,每个机构在云模型的基础上使用本地数据训练自己的模型。随后,将机构模型回传到云端,通过FedAvg来更新云模型。重复以上流程,直到模型收敛或达到指定训练轮数。最后,每个机构可以利用云模型和本地数据来进一步训练个性化模型。在这一步中,由于全局数据和机构的本地数据之间存在很大的分布差异,所以通过微调方法使模型更适合本地数据。在整个流程中,通过同态加密,所有参数共享过程都不会泄露用户数据。
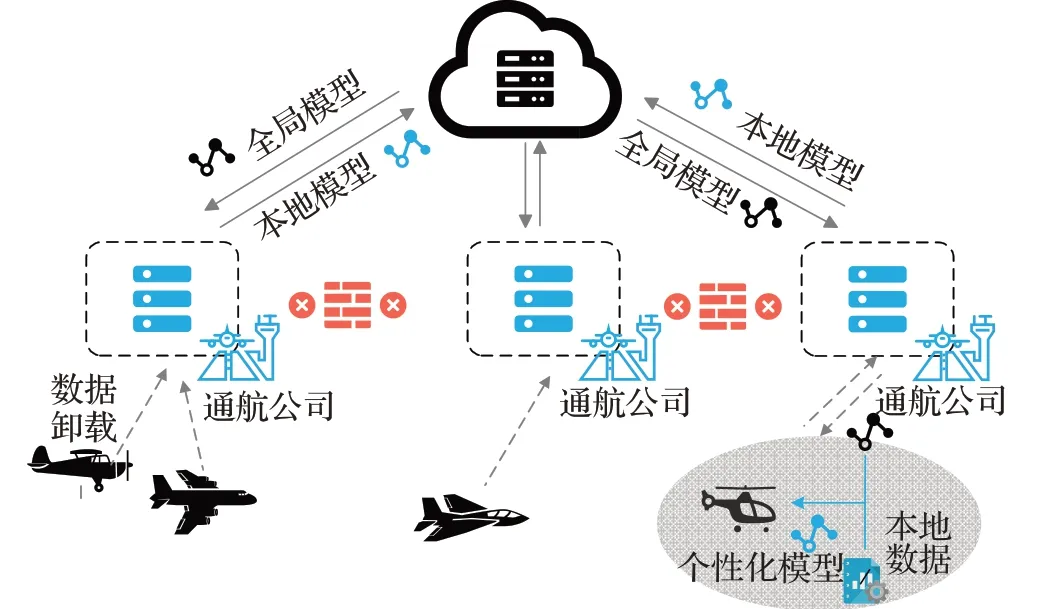
图1 FedPAD框架概述Fig.1 FedPAD framework overview
2.3 联邦学习
FedPAD采用联邦学习范式实现分布式加密模型训练和共享,解决数据隔离的问题。这一步主要由两个关键部分组成:云模型聚合和机构模型训练。在FedPAD中,采用基于LSTM时序预测的神经网络作为云端和机构模型。LSTM通过输入机构数据来进行端到端的特征学习。云端模型和机构端模型的学习目标分别如式(7)、式(8)所示:
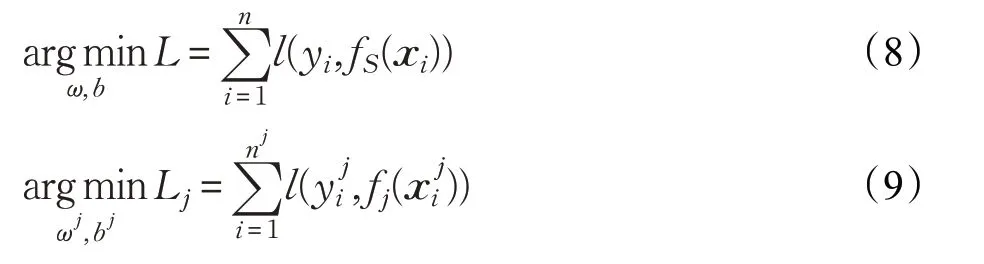
其中,ω和b表示要学习的所有参数,即权重和偏差,l(·,·)表示损失函数,j表示机构编号表示来自全局数据和第j个机构的时序数据实例,n和n j表示数据集的大小。
对所有用户模型f j进行训练后,将其上传到云端进行聚合。使用联邦平均算法[12]对齐用户模型,在每轮培训中对M个用户模型进行平均,得到平均模型:
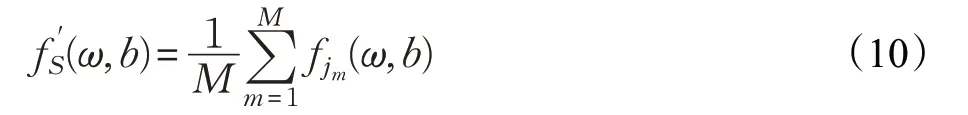
其中,(ω,b)表示神经网络参数,M表示机构数量,经过足够多轮的迭代,云端模型具有更好的泛化能力。
2.4 个性化学习
联邦学习能够解决数据孤岛问题,因此,FedPAD可以使用所有的机构数据来构建异常检测模型。此外,另一个影响性能的重要因素是数据的统计异构性。在特定机构上直接使用云模型的性能仍然很差,这是由于单一机构数据和全局数据之间的分布差异。云端的通用模型只从所有机构那里学习粗略的特征,而无法学习特定机构数据的细粒度特征。Yosinski等人[24]证明在深度神经网络中,较低层的特征是高度可迁移的,因为它们集中于学习共同的和较低层次的特征,网络中的较高层将学习任务中更具体的特征。因此,在获得云模型之后,机构使用fine-tuning方法来实现个性化的机构模型,过程如图2所示。神经网络由两个LSTM层、两个Dropout层、一个Dense层和一个Linear层组成。输入是多元时序数据,输出是预测时序数据。FedPAD保持较低层(LSTM和Dropout)冻结,并调整较高层(Dense和Linear)的参数。
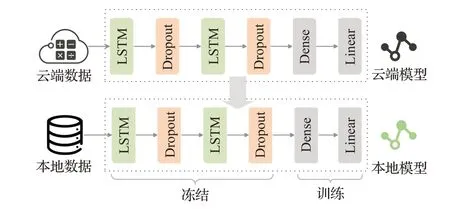
图2 FedPAD微调过程Fig.2 FedPAD fine-tuning process
2.5 算法流程
在算法1中介绍了FedPAD的模型训练流程。当机构生成新的数据时,FedPAD可以同时更新机构模型和云模型。因此,使用FedPAD的时间越长,模型性能就越好。
算法1FedPAD模型训练流程

3 实验与结果分析
3.1 数据集
NASA开源的专家标注的真实世界航天器故障数据集[11]包括火星科学实验室好奇号(mars science laboratory rover,MSL)和土壤水分主动被动探测卫星(soil moisture active passive,SMAP),共计82个通道、105个故障,数据集描述如表1所示。

表1 FedPAD模型训练流程Table 1 FedPAD model training process
3.2 评估指标
为了与LSTM-NDT[12]提出的基准进行直接比较,采用序列数据异常检测任务中常用的Point-based检测指标,即当预测异常与真实值有交集时记为true positive,预测异常与任何真实值均无交集时记为false positive,真实值与任何预测值均无交集时记为false negative,其中,精确率(Precision)、召回率(Recall)与F1值的计算均与一般的检测任务相同:

其中,TP为真阳性,FP为假阳性,TN为真阴性,FN为假阴性。
3.3 实验设置
NASA航天器数据集中,通道之间的时序数据具有相同的特征维度,但在特征分布上具有较大差异性,即统计异构性,这符合本文的问题背景。因此,将每一个通道的数据作为一个机构的数据,即在SMAP上的实验中有55个机构节点,在MSL上的实验中有27个机构节点,进行FedPAD模型训练。LSTM-NDT方法使用每一个通道数据单独训练一个模型,为了更直观的比较,使用与LSTM-NDT相同的模型架构和参数,如表2所示。
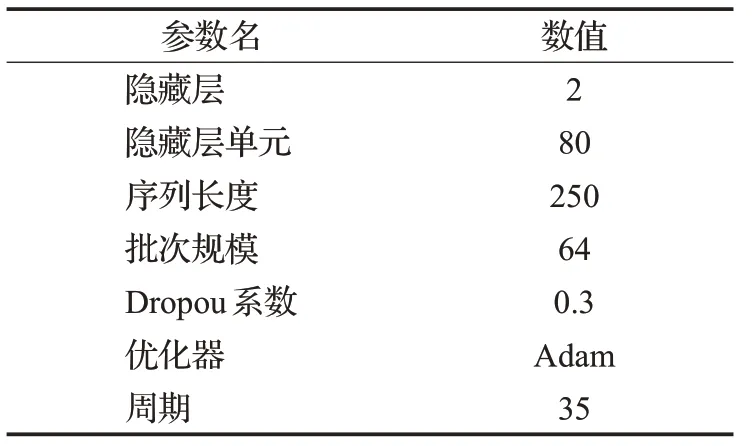
表2 模型架构及参数Table 2 Model architecture and parameters
3.4 结果分析
将FedPAD与LSTM-NDT作比较,同时记录了仅使用联邦学习(FED)的性能。
如表3所示,与LSTM-NDT相比,仅使用联邦学习进行模型训练虽然能解决数据孤岛问题,但由于数据的统计异构性,FED模型的预测性能在两个数据集上都出现了下降,整体预测误差增加了1.2个百分点。同时,FedPAD整体预测误差下降了1.6个百分点,比LSTMNDT方法表现得更好,这是因为联邦学习可以间接学习到来自多个机构的数据特征,进而训练更好的模型,并且通过微调,模型变得更加个性化,更能适应每个机构的数据特征。
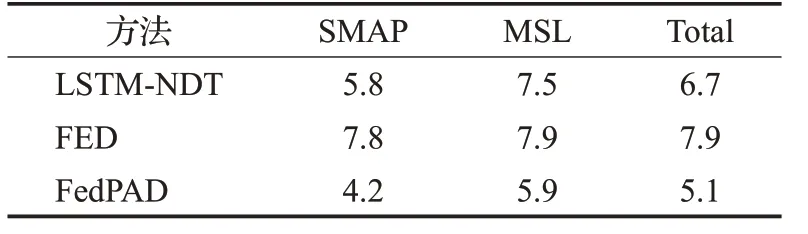
表3 遥测预测误差Table 3 Telemetry prediction error %
在LSTM-NDT方法中,剪枝参数p是控制精确率和召回率的重要参数,通过调整参数p实现精确率和召回率的权衡。在本文的实验中,将p作为控制变量,比较三种方法在两个数据集中异常检测的性能表现。如图3、4所示,在不同的参数p下,FED方法性能最不稳定,精确率和召回率无法同时达到较高水平。而Fed-PAD方法,仅在SMAP数据集中的p取较低值时性能略低于LSTM-NDT,其他情况下精确率和召回率均高于LSTM-NDT,这得益于fine-tuning提高了LSTM模型的预测性能。
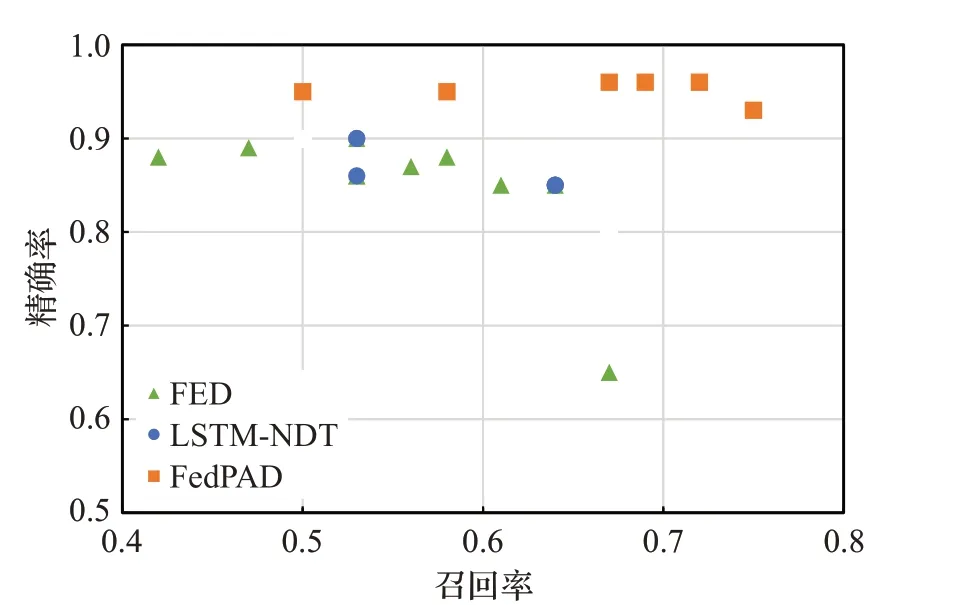
图3 三种方法在MSL数据集中的性能比较Fig.3 Performance comparison of three methods in MSL dataset
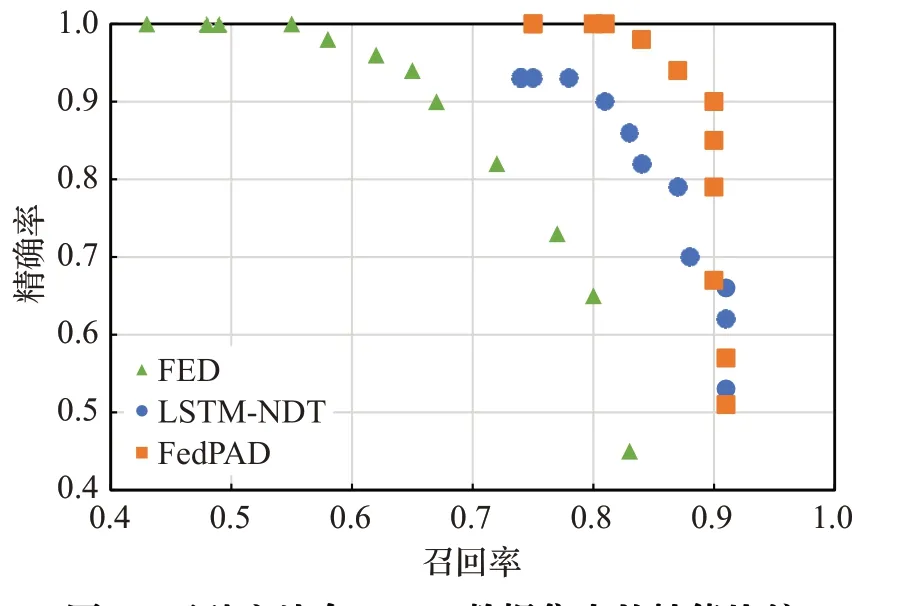
图4 三种方法在SMAP数据集中的性能比较Fig.4 Performance comparison of three methods in SMAP dataset
如表4、5所示,记录了三种方法在不同参数p下的平均性能表现。与LSTM-NDT相比,FED在两个数据集上的F1分数分别下降了4.3%、10.9%,FedPAD在MSL数据集上的异常检测F1分数提高了10.1%,在SMAP数据集上提高了3.6%,平均F1分数提高了6.9%。这再次证明了FedPAD在提高异常检测性能上的有效性。其中的原因是,在联邦学习和微调过程中,FedPAD中每个数据机构上的异常检测模型都可以学习到其他机构的数据特征,提高了模型的推理性能。由于数据集的异构性,使用统一的联邦学习模型更容易出现误报率增加或模型鲁棒性降低的问题。FedPAD能够解决这些问题,因为它通过微调为每个数据机构构建了更加个性化的异常检测模型。
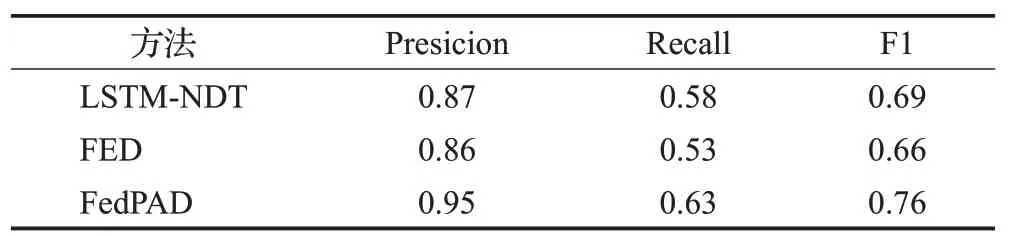
表4 MSL数据集上的平均性能对比Table 4 Average performance comparison on MSL Datasets
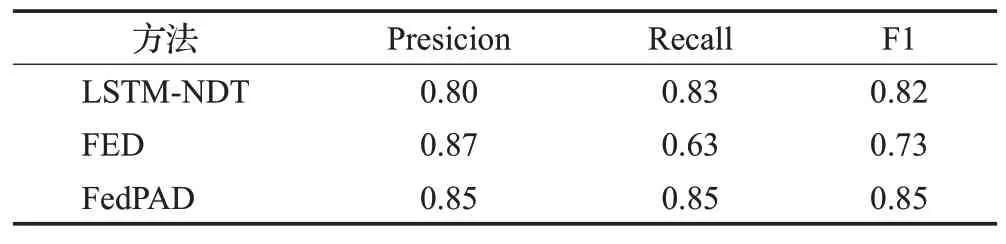
表5 SMAP数据集上的平均性能对比Table 5 Average performance comparison on SMAP datasets
4 结束语
针对多元时序数据异常检测,提出了一种基于个性化联邦学习的异常检测框架FedPAD。FedPAD基于联邦学习框架,能够在不泄露数据和隐私的情况下,学习不同机构的时序数据特征,在各自机构端使用本地数据对模型fine-tuning获得个性化检测模型。实验表明,通过检测NASA航天器数据异常,FedPAD的异常检测F1分数比基准方法平提高了6.9%。未来,计划使用更多的深度异常检测模型来验证模型的可扩展性,以及通过增量学习以实现更加灵活和个性化的异常检测。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
网络安全与数据管理(2022年1期)2022-08-29
小猕猴智力画刊(2022年3期)2022-03-28
成都信息工程大学学报(2021年3期)2021-11-22
家庭影院技术(2020年10期)2020-12-14
文苑(2020年4期)2020-05-30
铁道建筑技术(2020年11期)2020-05-22
家庭影院技术(2019年7期)2019-08-27
电子制作(2017年13期)2017-12-15
汽车与新动力(2016年6期)2017-01-04
