
语音识别架构下英语口语考试辅助评分系统
2022-06-09 05:45田伟伟
自动化技术与应用 2022年5期
田伟伟
(哈尔滨医科大学大庆校区,黑龙江 大庆 163319)
1 引言
全球化经济的开放促进了不同国家和文化之间的交流,英语作为世界重要的语言之一,成为了我国学生学习外语的首选语种。当今企业招聘中,已将英语口语能力作为招聘中的硬性要求,因此英语口语考试也在各高校开始了试点实施[1-2]。但是目前高校师资力量和经费限制等问题,进行大规模的口语考试并评分不太现实,且人工评分无法避免教师自身的评分误差。苏倩等人从主观和客观两方面比较多种语音评分技术的优缺点,整合主观和客观评价,最终提出基于HMM 技术和神经网络技术的评分机制[3],但是该方法的效度值较差。朱向前介绍了AISpeech-SJTU 系统,用于Interspeech-2020英语语音识别挑战的口音识别轨道,提出了测试时间增强和嵌入融合方案,提高系统性能,但是该方法在特征提取方面不够详细[4]。针对上述问题,在已有研究的基础上,本文设计一种语音识别架构下英语口语考试辅助评分系统。
2 语音识别架构下英语口语考试辅助评分系统
2.1 硬件框架设计
在英语口语考试的辅助评分系统中,首先要根据系统具备的功能来设计硬件结构。系统中的硬件框架设计图如图1所示。
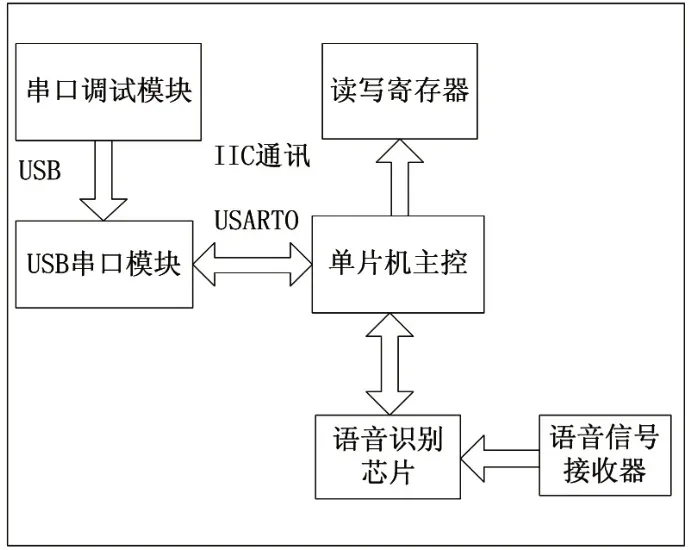
图1 系统硬件设计框图
本文选择的语音识别芯片型号为LD571,该芯片能够实现非特定人的声音识别,针对考试过程中其他学生的读、说干扰能够自动识别,仅将同一音色所产生的语音作为识别内容[5],这样能够有效提高评分的准确度。
2.2 英语口语语音识别
语音识别的过程中使用的是Sphinx-4的语音识别架构。该架构通过Java语言进行编程。本文系统架构如图2所示。
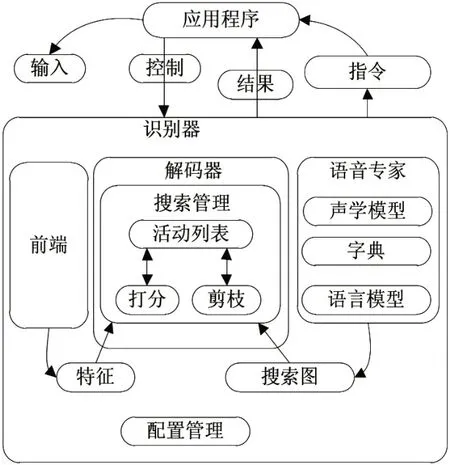
图2 Sphinx-4的语音识别架构
从图2中可以看出,在该架构下,Sphinx-4将流程进行拆分,得到了模块化的处理过程[6]。语音识别架构主要分为应用程序和识别器。应用程序主要是接收识别器的指令和结果,输入和对识别器输入控制指令。识别器主要由前端、解码器以及语音专家组成,前端接受信号的输入并且转化为特征序列,语音专家把任何类型的标准语言模型,字典的发音信息以及一些声学模型的结构信息转换为一个搜索图,在解码器中的搜索管理负责用前端产生的特征以及语音专家生成的搜索图进行实际的解码工作,产生结果。其中在解码过程中,剪枝主要是用来提高解码速度,剪枝示意图如图3所示。
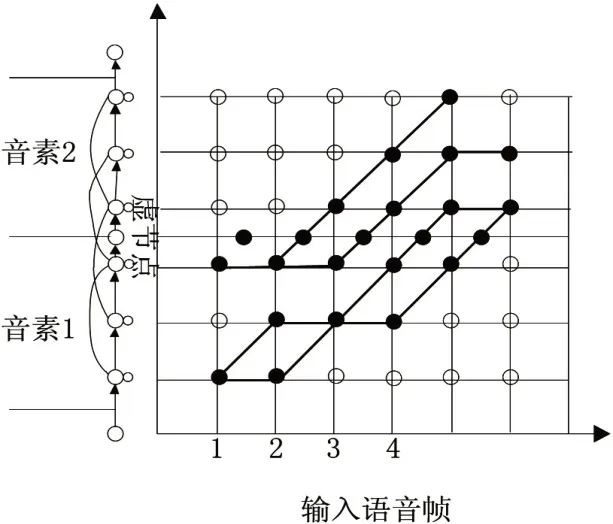
图3 剪枝策略
图3中目的空心点表示已经被剪掉的节点状态,实心点则是经过剪枝后保留下来的节点状态。但是由于一些节点在观察序列中的积累概率较小,在整个编码过程中占用搜索空间较大,将其剪掉后,能够有效地减少搜索空间,对于提高搜索效率具有重要意义[7]。
2.3 提取评分特征
在学生进行英语口语考试的过程中,得到的语音频谱中会出现一些能量比较集中的区域,这样的位置我们称为共振峰。脉冲发生器中自带一定的周期,因此激励源在此周期下进行声波和能量的发射。设置周期为W0时,得到的脉冲序列u(w)的实际波形具有声门气流脉冲的特点,并利用u(w)的传播特点,使其通过一个滤波器得到全极点模型[8]。滤波器的类型需要与声门脉冲模型相契合,因此滤波器的结构可以转化为公式:
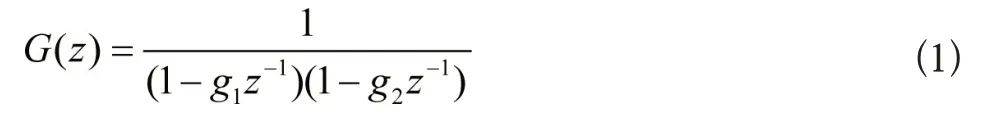
上式中,g1、g2分别表示发音样本评分结果矢量中的任意两个结果元素。在声道模型的调制影响下,能够有效将脉冲序列进行转化。声道模型的调制过程可以表示为:

上式中,ak表示调制参数,p表示调制过程中的模型变化阶数。经过转化后的脉冲序列信号需要再次经过辐射模型,才能最终转化成语音波形[9],辐射模型的辐射过程可以表示为:

在整个的变换过程中,涉及到相应的能量增益,将此时的增益包含在声道模型的调制过程中,可以得到:

上式中,A代表增益,根据上式可以求解出调制之后的语音信号变换,并与语音波形的时域相对应。根据以上计算,可以估算出模型参数,完成语音评分特征的提取。
2.4 设计评分算法
在本文设计的英语口语考试辅助的评分系统中,评分方法综合了主观与客观两种评分类型,最大化地消除掉单一评分中的可能存在的误差[10]。在评分算法中,本文选择的是基于HMM 的评分算法,该算法能够优化状态序列的计算过程。评分的总体模型如图4所示。
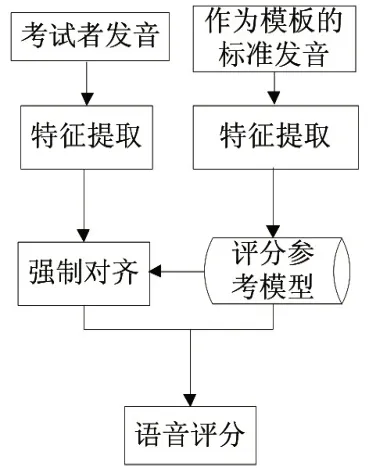
图4 评分流程
在经过特征提取之后,可以提取出待评分的考试者语音的特征序列:

通过模板标准发音得到的评分参考模型Φ中,则包含多组隐性的状态序列,可以表示为:

由于评分参考模型Φ中包含了不同状态分布下的语音特征和隐性的状态序列,因此对于待评分语音来说,可以利用后验概率作为评分的基本原则,后验概率的计算公式为:
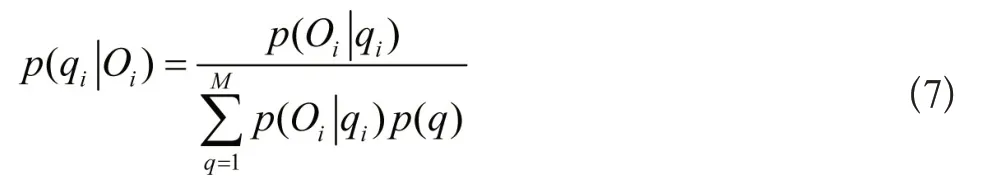
上式中,p(Qi|qi)表示最优概率,p(q)代表因素的先验概率,根据计算得到的后验概率取对数完成累加,最终得到辅助评分结果。
3 系统测试
3.1 制定英语口语考试用卷
为了验证本文设计的语音识别架构下英语口语考试辅助评分系统的有效性,需要对系统进行测试。制定的英语口语考试用卷的难易水平要适中,最终制定出一套包含四种类型题目的口语测试卷,题目结构如表1所示。
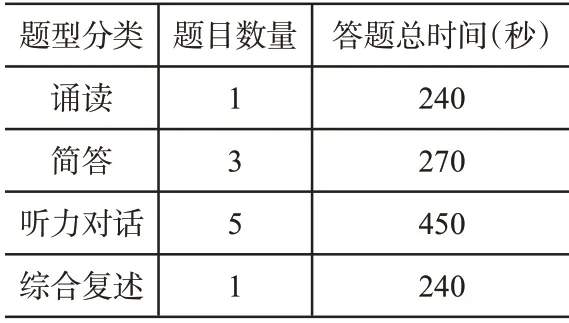
表1 英语口语考试试卷题目结构
选择某高校学生进行英语口语测试,为了保证测试结果的准确性和有效性,评分教师选择了4 名,在统一评分细则之后4名教师依靠本文设计的辅助评分系统完成独立评分。分别得到4位教师的相关性分析矩阵:
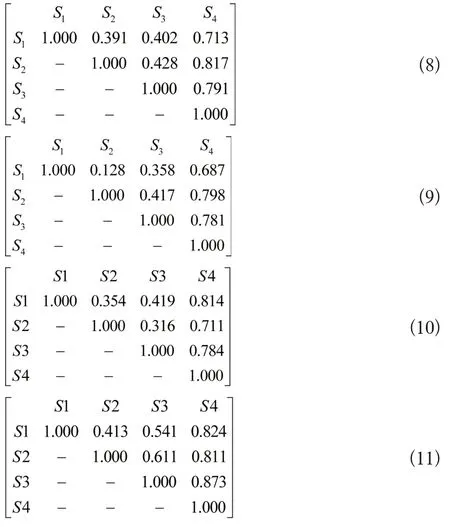
上式中,S1表示诵读题型,S2表示简答题型,S3表示听力对话题型,S4表示综合复述题型。
从以上教师评分的相关性矩阵中可以看出,大部分的题型之间的数据分析结果都能够达到0.3以上,说明选择的测试题区分度较好,能够得到比较客观的成绩。
在以上的实验环境下,分别可以得到不同系统下各个题型的SPSS分析数据,计算效度。效度的计算公式为:

3.2 实验结果对比与分析
随机选取100 份成绩进行两系统评分模式下的差异分析。在结果分析中设定,当两系统得到的评分结果与全人工评分结果相同时,判定为完全一致,得到的结果与全人工评分结果相差一个评分等级时,则判定为可接受差异,其余情况为不可接受差异。差异分析结果如表2所示。
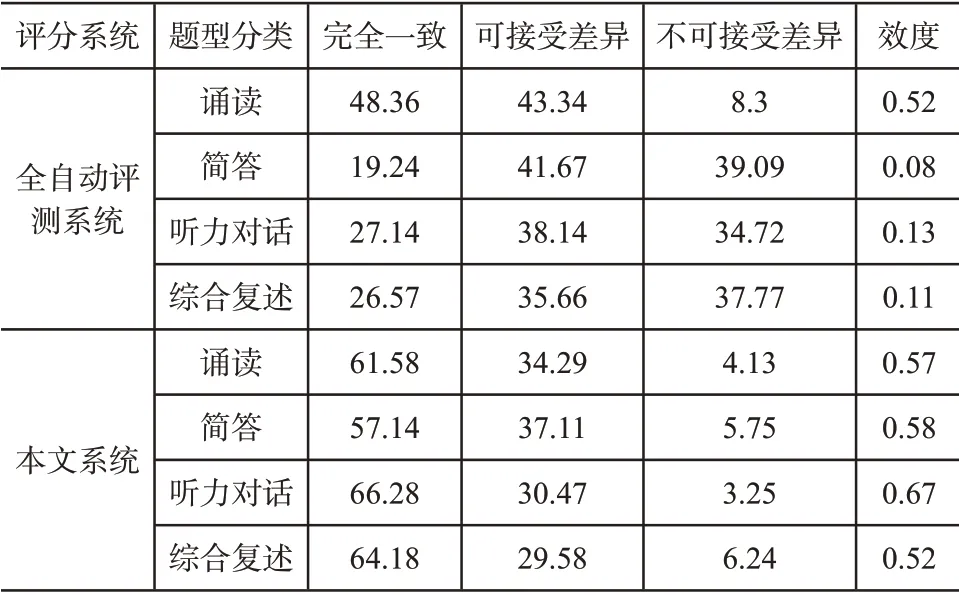
表2 两系统与全人工评分结果差异分析
从上表结果可知,在全自动评测系统中,仅有诵读类题目的不可接受差异的结果低于10%,其他类型的题目均达到30%以上,且计算得到的效度中,仅有诵读题型达到了效度的最优区间0.5-0.7;在本文系统得到的评分结果中,四种题型的不可接受差异均能控制在10%以下,且效度值均在最优区间内。验证了本文设计的语音识别架构下英语口语考试辅助评分系统具有一定的可靠性。
4 结束语
本文设计的语音识别架构下英语口语考试辅助评分系统避免了全自动评分系统中的缺陷,又弥补了人工评分的效率问题,对于我国英语口语教学来说意义重大。但是本文设计的系统由于技术等方面的限制,使用的评分算法和识别技术都处于初级研究阶段,在未来的工作与发展中,可以向人工智能以及语料库的扩充建设方面来深入研究。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
中学生数理化(高中版.高二数学)(2022年5期)2022-06-01
求学·理科版(2022年3期)2022-02-25
中学生数理化(高中版.高二数学)(2021年5期)2021-07-21
汽车工程(2021年12期)2021-03-08
甘肃教育(2020年8期)2020-06-11
当代陕西(2019年16期)2019-09-25
活力(2019年15期)2019-09-25
中学生数理化·高一版(2017年2期)2017-04-25
互联网天地(2016年1期)2016-05-04
