
基于并列GRU分类模型的日志异常检测方法
2022-06-09 07:46周建国
南京理工大学学报 2022年2期
周建国,戴 华,2,杨 庚,2,周 倩,王 俊
(南京邮电大学1.计算机学院;2.江苏省大数据安全与智能处理重点试验室;3.现代邮政学院;4.地理与生物信息学院,江苏 南京 210023)
异常检测是维护系统安全和稳定的重要手段之一[1]。系统日志的设计目的是记录系统的实时运行状态以及系统运行时出现的关键问题,因此系统日志对于后期分析系统状态具有重要意义。基于日志数据的异常检测是指通过信息化方法分析系统运行时产生的日志数据,从而实现对系统的异常检测。随着计算机软硬件的快速发展,系统也变得愈加复杂,更容易被敌对攻击者发现并利用漏洞对系统进行攻击。因此,异常检测更加复杂,传统的检测方法逐渐不适用。除此以外,系统日志的规模也随着计算机软硬件的发展迅速增长,人工进行分析和标记变得非常困难。以Hadoop分布式文件系统(Hadoop distributed file system,HDFS)日志数据集[2]为例,此系统能够在38.7 h内产生超过1 100万条日志数据。
现有分析系统日志的方法可以被分为以下4类:基于主成分分析日志信息计数器的检测方法[2-4]、基于变量挖掘[5]捕捉日志复现模式的检测方法、基于工作流的检测方法[6]和基于深度学习的检测方法[7-11]。前三类方法仅在特定应用场景下可以使用,但并不能应用到更广泛和复杂的系统当中,因此具有很大的局限性。第四类方法虽然可以很好地解决前三类方法的局限性,但此类方法仅能对日志序列内的日志先后次序的异常特征进行检测,并没有对日志频度信息的异常特征进行检测。因此这类方法在检测准确度上依然存在提升空间,需要进一步改进和优化。
本文提出了一种并列循环门单元(Gate recurrent unit,GRU)分类模型的日志异常检测方法,其核心为通过设计并整合两个GRU神经网络模型,以实现同时对日志序列异常以及日志频度异常进行检测。首先,在模型训练阶段,利用日志模板解析器在原始日志数据集中解析日志模板集合和结构化日志集合;然后,构造并生成日志模板滑动窗口数据集和相应的日志模板频度向量集,并作为训练数据集,训练生成并列GRU分类模型。在异常检测阶段,对于被检测进程的日志序列,将其转换为与这一进程对应的日志模板滑动窗口集和日志模板频度向量集,然后输入并列GRU分类模型,通过判断当前日志模板是否属于模型的预测结果候选集以确定此日志模板序列是否存在异常。最后通过试验,将本文所提方法与现有的Deeplog方案[7]进行比较分析。
1 预备知识
1.1 日志模板解析器
在进行日志异常检测之前,需要对原始日志数据进行处理。日志模板解析器能够将系统日志记录分离成日志模板和参数向量两个部分,并且将原始日志转换为结构化日志,如图1所示。目前,国内外的研究者们提出了面向各种不同日志应用场景的日志模板解析器,例如IPLoM[12]、LogSig[13]、SHISO[14]、Spell[15]和Drain[16]等。本文将会使用日志模板解析器,对原始日志文件进行预处理,以生成训练数据或待检测数据。
1.2 GRU神经网络模型
GRU[17]是循环神经网络的一种结构模型,相较于长短期记忆神经网络模型(Long short term memory,LSTM)[18]能够有效减少参数的计算量,并且在不同的数据集上能够获得近似的甚至更好的预测准确度[19]。循环神经网络在自然语言处理领域有着广泛的应用,其最大优势是能够很好地学习句子内单词的上下文模式。由于日志行为具有明显的先后顺序关系,因此可以使用循环神经网络模型学习系统的行为模式,从而实现对后续进程行为的预测。本文将基于GRU神经网络模型构造一个并列GRU分类模型,实现对进程日志的异常检测。
2 基于并列GRU分类模型的日志异常检测
2.1 系统框架及相关定义
本文所提出的基于并列GRU分类模型的日志异常检测方法包含模型训练和异常检测两个阶段,如图2所示。在模型训练阶段,需要将正常的日志数据集进行预处理以训练并列GRU分类模型;在异常检测阶段,某一进程的日志序列将会被转换为日志模板序列,构造日志模板滑动窗口输入并列GRU分类模型并预测得到日志模板候选集,通过判断日志模板序列中的日志模板是否属于日志模板候选集以决定这个日志序列是否存在异常。具体步骤将在后续章节内详细阐述。
定义1结构化日志集合:原始日志数据集L={log1,log2,…,log n}对应的结构化日志集合记为D={d1,d2,…,d n},d i为log i对应的结构化日志三元组(k,pid,ts),其中k为日志模板k i,pid为进程标识符,ts为日志产生的时间戳。
定义2日志模板集合:在本文中,使用K={k1,k2,…,k m}表示日志模板集合,其中k i为唯一标识某一类日志的日志模板ID。为了说明简便,本文直接用k i表示某一日志模板。
定义3进程日志模板序列:对于进程p i,设其产生的日志对应的结构化日志序列为D i=〈d i,1,d i,2,…,d i,q〉,满足d i,j∈D i∧D i⊆D∧d i,j.ts<d i,j+1.ts,则D i对应的进程日志模板序列为S i=〈d i,1.k,d i,2.k,…,d i,q.k〉。
定义4日志模板滑动窗口(Log template sliding window,LTSW):设滑动窗口大小阈值为h,进程p i的进程日志模板序列为S i=〈e1,e2,…,e q〉,则对于e j∈S i而言,e j对应的滑动窗口序列LTSW记为Win(S i,e j),生成方法如下:
(1)若j≤h,则Win(S i,e j)=∅;
(2)若q>h,则Win(Si,e j)=〈e j-h,…e j-2,e j-1〉。
定义5日志模板频度向量:对于任一日志模板滑动窗口w=〈e j-h,…e j-2,e j-1〉而言,w的日志模板频度向量记为U w。此向量的维度等于K中日志模板的数量m,即U w∈R1×m,其中任一维的数值U w[i]为日志模板k i在w中出现的频次。
定义6日志模板概率分布向量:将被检测进程的某个日志模板滑动窗口w=〈e j-h,…e j-2,e j-1〉输入并列GRU分类模型,分类模型将会输出此日志模板滑动窗口所对应的日志模板概率分布向量,记为V w。此向量的维度等于K中日志模板的数量m,即V w∈R1×m,其中任一维的数值V w[i]表示e j为K中日志模板k i的概率。

图2 日志异常检测的系统框架图
2.2 并列GRU分类模型
为了实现异常检测,本文基于GRU神经网络模型构造了并列GRU分类模型。这一预测模型包含3层,分别为输入层、神经网络隐藏层和输出层,如图3所示。输入层负责接收由日志模板滑动窗口w=〈e j-h,…e j-2,e j-1〉和与w对应的日志模板频度向量U w构成的训练数据或检测数据。神经网络隐藏层由两个并列的GRU模块构成,其中GRU1负责处理日志模板滑动窗口数据w,GRU2负责处理与w对应的日志模板频度向量U w;GRU1和GRU2的输出结果在连接后传入输出层。输出层负责将连接后的GRU输出结果进行Softmax变换,最终输出日志模板概率分布向量V w。

图3 并列GRU分类模型结构图
在本文提出的日志异常检测方法中,首先在模型训练阶段,通过对原始日志数据进行预处理,生成日志模板滑动窗口数据集和相应的日志模板频度向量集,并将此数据集和向量集作为输入,训练并生成并列GRU分类模型;然后,在异常检测阶段,对于被检测进程的日志序列,将其转换为与这一进程对应的日志模板滑动窗口集和日志模板频度向量集,并输入并列GRU分类模型,以实现对这一进程日志的异常检测。
2.3 模型训练算法
在进行异常检测之前,首先需要完成对并列GRU分类模型的训练。本文将原始日志数据集转换为结构化日志数据集,并根据进程标识符构造进程日志模板序列;然后基于进程日志模板序列构造日志模板滑动窗口和日志模板频度向量,以形成最终的模型训练输入数据集;最后使用这个输入数据集,训练并列GRU分类模型。具体过程如算法1所示。

算法1 模型训练算法输入:原始日志数据集L,滑动窗口大小阈值h;输出:训练后的并列GRU分类模型;1:初始化用于模型训练的三元组集合PL;2:以原始日志数据集L为输入,使用日志模板解析器生成日志模板集合K,然后构造结构化日志集合D;3:按照进程标识符pid对结构化日志集合D进行分组,得到分组集合DS={D1,D2,…,D u},其中D i表示进程p对应的结构化日志集合;4:FOR EACH Di∈DS DO 5: 按时间戳对Di中的结构化日志进行排序,排序结果不妨设为Di=〈d i,1,d i,2,…,d i,q〉,满足d i,j∈Di且d i,j.ts<d i,j+1.ts;6: 提取Di中的结构化日志中的日志模板ID,生成与Di相对应的进程日志模板序列S i=〈d i,1.k,d i,2.k…,d i,q.k〉;7: IF q≤h THEN 8: CONTINUE;9: END IF;10: FOR j=h+1,h+2,…,q DO 11: 生成e j对应的日志模板滑动窗口w=Win(S i e j);12: 生成日志模板滑动窗口w对应的日志模板频度向量U w;13: 构造三元组(w,U w,e j),并添加到PL中;14: END FOR;15:END FOR;16:以PL作为输入数据集训练并列GRU分类模型;17:返回训练完成的并列GRU分类模型。i,,
其中,算法1中的步骤13中的三元组(w,U w,e j)的第一个属性日志模板滑动窗口w用于训练检测日志模板序列异常的GRU1神经网络模型,而第二个属性日志模板频度向量U w用于训练负责检测日志模板频度异常的GRU2神经网络模型,而最后一个属性e j作为GRU1和GRU2的公共输入参数。
2.4 异常检测算法
在并列GRU分类模型训练完成后,此模型被用于日志异常检测。在检测过程中,首先使用日志模板解析器将待检测进程的日志序列转换为进程日志模板序列,进而构造日志模板滑动窗口集和日志模板频度向量集;然后将日志模板滑动窗口与相应的日志模板频度向量,逐一输入并列GRU分类模型,得到模型预测输出的日志模板候选集;最后,通过判断每一个日志模板滑动窗口的下一时刻的日志模板是否属于日志模板候选集,以确定这一进程日志序列是否存在异常。具体检测过程如算法2所示。

算法2 异常检测算法输入:进程pi对应的日志序列L i=〈log1,log2,…,log q〉,滑动窗口大小阈值h,预测结果候选集大小阈值g;输出:检测结果(TRUE表示正常,FALSE表示异常);1:使用日志模板解析器将L i转换为进程日志模板序列S i=〈e1,e2,…,e q〉;2:FOR j=h+1,h+2,…,q DO 3: 生成e j对应的日志模板滑动窗口w=Win(S i,e j);4: IF w=∅THEN 5: RETURN FALSE;6: END IF;7: 生成与w对应的日志模板频度向量U w;8: V w=GRUPredict(w,U w);9: 获取V w中g个最大的概率值所对应的日志模板候选集C;10: IF e j∉C THEN 11: RETURN FALSE;12: END IF;13:END FOR;14:RETURN TRUE。
在算法2的步骤8中,GRUPredict(w,U w)表示利用并列GRU分类模型对输入的日志模板滑动窗口w和日志模板频度向量U w进行预测,其输出为日志模板概率分布向量V w;步骤9中的日志模板候选集C的形成规则如下:若V w[i]是V w中g个最大概率值中的一个,则日志模板k i加入C。
3 试验
3.1 试验环境及试验数据集
本文试验基于PyTorch框架进行试验,这个框架整合了GRU神经网络模型,试验结果与同类方法Deeplog[7]进行对比。试验的操作系统为Windows 10 64 bit,开发语言为Python 3.8,深度学习框架为Pytorch 1.8,GPU采用Nvidia GTX 1660S 6GB。日志模板解析器采用Spell[15],日志模板解析器源码参考文献[20]。本文试验使用文献[21]收录标记过的HDFS日志文件[2]作为数据集。这一数据集来自于200多台亚马逊EC2节点,包含了11 175 629条日志数据,记录了575 061个block进程读写文件的行为,其中有16 838个进程被Hadoop领域的专家标记为异常。试验中的超参数设置如表1所示。

表1 试验超参数数值表
3.2 试验评价指标
(1)假阳数(False positive):在所有被检测日志序列中,被错误地判定为异常的日志序列数量,记为FP。
(2)假阴数(False negative):在所有被检测日志序列中,被错误地判定为正常的日志序列数量,记为FN。
(3)查准率(Precision):正确检测出的异常日志序列数量,占所有检测为异常的日志序列数量的比重,本文用TP表示正确检测出的异常日志序列数量,计算公式如下

(4)查全率(Recall):正确检测的异常日志序列数量,占所有确定异常的日志序列数量的比重,计算公式如下
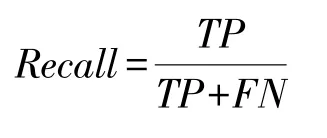
(5)调和分数(F1 score):查准率和查全率的调和均值,记为FS,计算公式如下
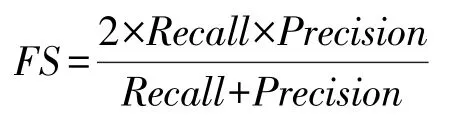
3.3 试验结果
(1)查准率、查全率及调和分数试验
为了验证本文提出的方法的各项指标表现,本试验将从查准率、查全率和调和分数3个指标上对比Deeplog和本文提出的方法。试验结果已在表2中展示。
表2的试验结果表明,本文提出的方法相较于Deeplog方案,在HDFS数据集上查全率和调和分数分别提升了13.8%和5.8%。更高的查全率表明监测算法所检测到的真正存在异常的日志模板序列的总数占比更高。而本文提出的并列GRU分类模型与Deeplog方案相比额外增加了一个GRU神经网络模型,这个GRU神经网络模型能够对待检测的日志模板序列中的日志模板频度异常进行检测,因此能够在一定程度上改善日志异常检测的性能表现。

表2 不同方法在HDFS数据集上的查准率、查全率和调和分数
(2)假阳数和假阴数试验
为了对比不同方法检测错误的次数,本试验将会从假阳数和假阴数两个指标对比Deeplog和本文提出的方法。试验结果已在表3中展示。

表3 不同方法在HDFS数据集上的假阳性和假阴性
表3的试验结果表明,本文提出的方法相较于Deeplog,能够显著降低异常检测的假阴数指标,本文提出的方法的假阴数仅为Deeplog方案的6.97%。更低的假阴性次数表示方法能够检测到更多的异常日志模板序列。更低的假阴数表明系统存在的未被检测算法所检测出来的异常日志模板序列的数量更少。而更高的假阳数表明系统内正常日志模板序列被检测算法错误地标记为异常日志模板序列的数量更多。因此,从系统安全的角度考虑,更低的假阴数比更低的假阳数更有安全意义。
4 结束语
日志异常检测是维护系统安全和稳定的重要问题之一。针对这一问题,本文提出了一种基于并列GRU分类模型的日志异常检测方法,这一方法同时考虑了日志序列上下文关系和频度的特征,利用日志模板解析器和GRU神经网络模型,构造并列GRU分类模型,实现对进程日志的异常检测。试验结果表明,与现有方案Deeplog相比,本文提出的方法在查全率、调和分数等各项评价指标上均有更好的表现。
猜你喜欢
华人时刊(2021年13期)2021-11-27
发明与创新·中学生(2021年1期)2021-01-19
诗选刊(2020年12期)2020-12-03
思维与智慧·上半月(2018年10期)2018-11-30
思维与智慧·上半月(2018年9期)2018-09-22
妇女之友(2017年3期)2017-04-20
科技资讯(2016年18期)2016-11-15
学生之友·最作文(2014年5期)2014-07-09
中学英语之友·上(2008年11期)2008-12-08
