
基于改进近邻传播聚类挖掘算法的竞争情报研究
2022-06-09 07:46李广明张海涛
南京理工大学学报 2022年2期
李广明,于 健,张海涛
(1.天津传媒学院 图书馆,天津 300381;2.天津大学 智能与计算学部,天津 300072;3.天津师范大学 计算机与信息工程学院,天津 300387)
大数据分析技术的发展给企业竞争情报分析带来新的发展机遇[1],通过大数据技术对企业竞争情报数据进行挖掘分析,可以获得企业自身乃至于企业所在的整个行业的竞争情报内在数关联数据。企业竞争情报分析根据需求不同,可以建立不同的企业竞争分析模型,但是这些分析模型的建立需要大量统计数据支持。聚类作为大规模数据统计分析的常用方法,能够有效挖掘海量异构多维数据之间的关系,为竞争情报数据各种模型分析提供数据支持。
当前,关于竞争情报分析中的聚类应用研究较多。曹钰等[2]对企业竞争情报数据进行特征因子提取,然后采用K-means聚类进行数据情报分析,分析效果较好。张振华等[3]重点对商业竞争情报进行分析,主要数据来源为商品的在线评论数据,运用文本挖掘方法完成情报分析,有效提取相应商品的用户偏好。洪磊等[4]对公安情报数据进行了分析,数据来源为CNKI文献数据,分析了近年来公安情报数据的研究热点内容。以上文献用不同的数据采集方法获得了竞争情报样本,并进行了竞争情报分析,但是不同情报数据来源造成的情报样本异构性,为竞争情报分析带来了新的挑战。
近邻传播(Affinity propagation,AP)聚类算法作为一种较为新颖的聚类方法,与传统聚类方法相比,无需事先给定聚类数目,且具有更好的聚类性能和效率。因此,本文采用AP聚类算法应用于竞争情报分析。但是传统AP聚类算法的性能对偏向参数的依赖度较高,因此本文提出采用布谷鸟算法对AP聚类的偏向参数进行优化,以提高AP算法在竞争情报分析中的适用性。
1 基于聚类的竞争情报分析
企业竞争情报根据内外部竞争环境分析结果,制定企业发展战略,对战略进行评估后进行实施,并根据竞争环境变化检验战略的有效性。在企业竞争情报研究中,竞争情报的收集和分析最关键,前者是竞争情报样本获取的手段,通过不同渠道和手段来获取竞争情报数据;后者通过对竞争情报数据样本进行挖掘分析来获得竞争情报分析结果。
竞争情报数据样本收集的广度和维度为竞争情报分析提供了数据支持。一般而言,竞争情报数据收集流程如图1所示[5]。
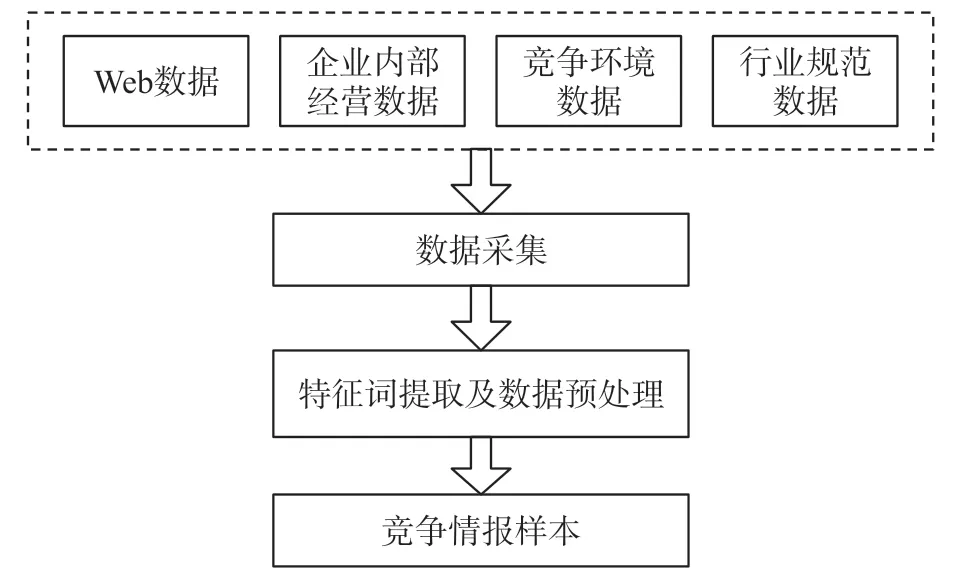
图1 竞争情报样本采集
竞争情报分析将大规模的竞争情报数据进行量化及归一化处理,然后通过大数据分析方法形成统计库,接着根据竞争情报服务需求建立相应的分析模型,除了对数据的分析之外,还需要结合行业管理及情报分析师经验协同评估分析模型结果,最后获得竞争情报分析结果,并生成竞争情报服务供需求方使用,其具体流程如图2所示。

图2 竞争情报分析流程
本文研究主要集中在分析系统的前半部分,即分析模型的统计库形成,采用聚类算法完成竞争情报数据统计。
2 改进的AP聚类
2.1 AP聚类
设S(i,j)为样本i与j之间的相似度,表示方法为[6]

根据式(1)得到待聚类的所有点的相似度矩阵,其中对角线元素称为偏向参数P,P一般设定为相同值。在实际聚类时,P值对聚类类别数影响较大,在操作时应合理设置。
r(i,j)表示吸引度函数,a(i,j)表示隶属度函数,其组成矩阵R=[r(i,j)]N×N和隶属度矩阵A=[a(i,j)]N×N,当r(i,j)+a(i,j)越大,表示点i和j的相似程度越大。
r(i,j)和a(i,j)的更新过程为[7]

r(j,j)为节点j的自吸引度。
当i=j时,a(i,j)的计算公式变为[8]
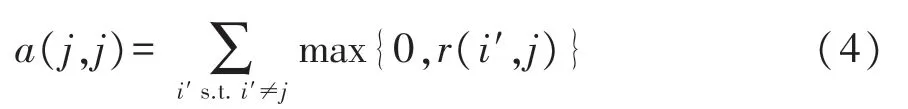
在式(2)等式两边均加上a(i,j),则有
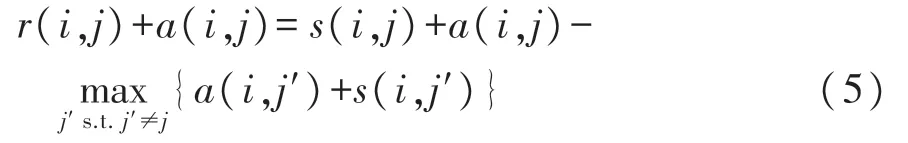
设E=[e(i,j)]N×N=[r(i,j)+a(i,j)]N×N,那么E=R+A称为决策阵,定义Γ=[τ(i,j)]N×N=[s(i,j)+a(i,j)]N×N,那么Γ=S+A为潜力阵。式(5)变为

在R和A的更新中为了防止震荡,引入阻尼ϕ(ϕ∈[0,1)),其有效平衡了震荡消除和收敛速度。T时刻的R和A分别为[9]

样本t的AP聚类轮廓(Silhouette)评价指标
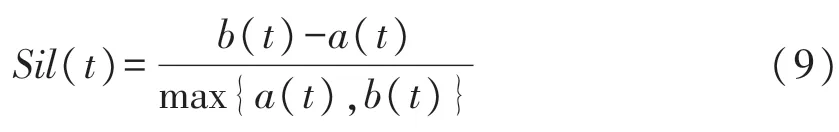
a(t)为t与同类别其他点的距离的均值,b(t)=min{d(t,C i)},Sil(t)取值[-1,1]。
2.2 布谷鸟搜索(Cuckoo Search,CS)算法
设鸟群包含N只布谷鸟,初始位置为X0=,鸟巢被宿主发现概率为Pa,设最优鸟巢和最优适应度为和。
布谷鸟飞行服从分布[10]

式中:s表示飞行步长。布谷鸟位置更新方法为[11]

式中:t=1,2,3,…,n;α为移动步长;Levy(λ)服从莱维分布[12]

式中:u、v分别服从u~N(0,σ2u)和v~N(0,σ2v)的分布,λ=1.5。
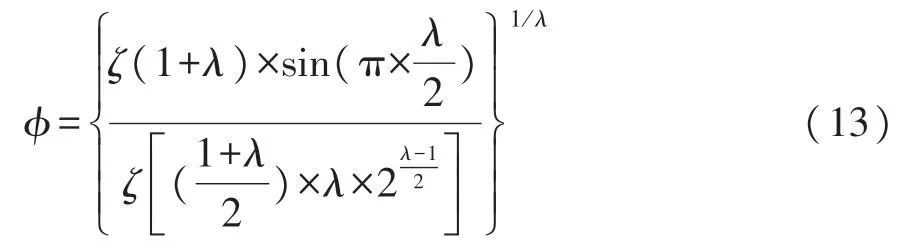
式中:ζ为Gamma函数。
设第t次飞行后适应度最优解,,其中1<t≤T。令r∈[0,1],满足r<Pa则不进行位置更新,在r>Pa的条件下继续飞行执行鸟巢位置更新[13]
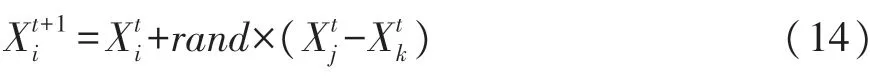
2.3 布谷鸟优化的AP聚类流程
适应度函数是群体智能优化算法寻优的统称,在面向不同问题时需进行具体设计,而本文AP聚类应用采用了轮廓指标作为适应度函数。将P作为鸟巢位置,设Sil(t)为适应度函数。首先获得待聚类的竞争情报样本,然后计算样本S(i,j)矩阵,设布谷鸟巢个数为N,最大迭代次数Tmax,初始化r(i,j)=0、a(i,j)=0,然后进行CS-AP聚类,其算法流程如图3所示。
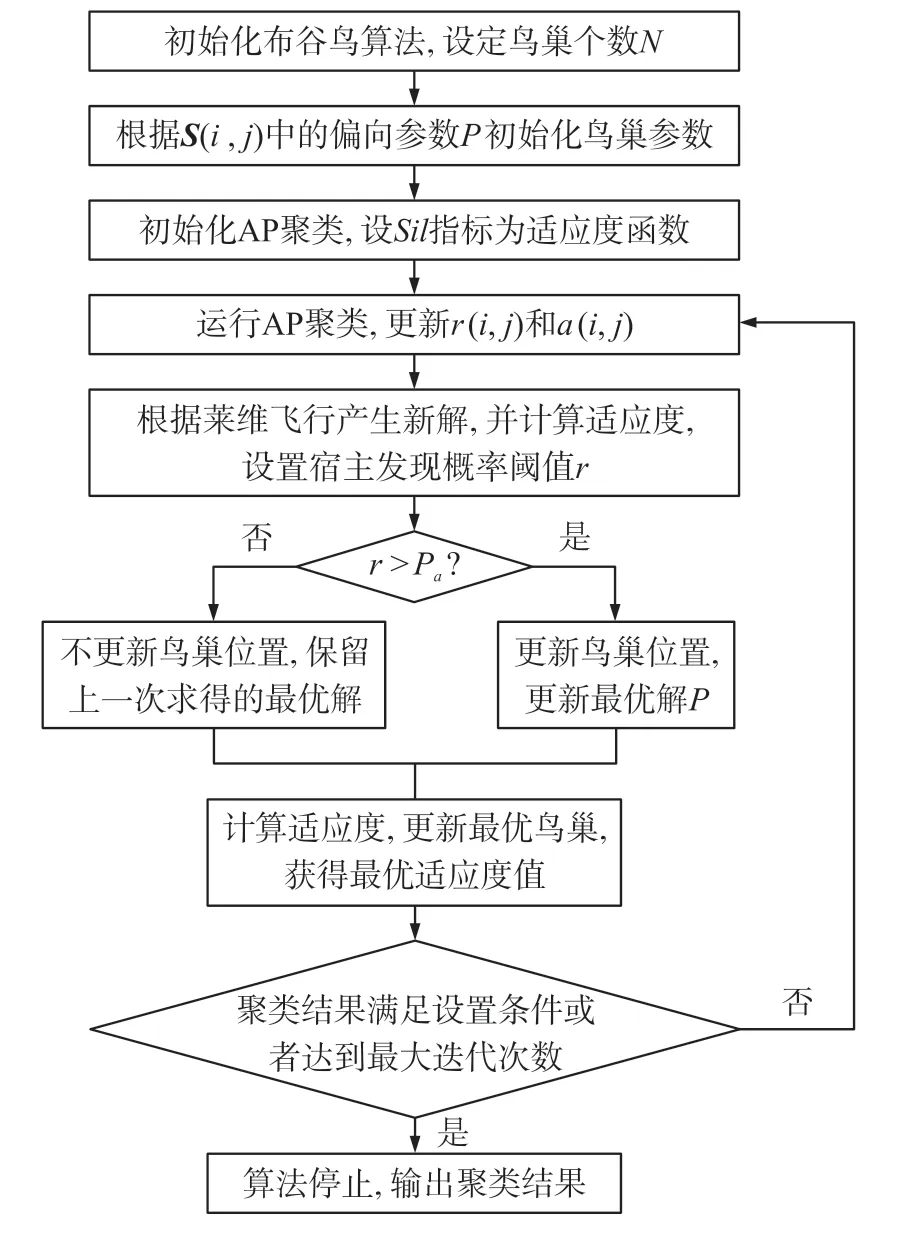
图3 CS-AP聚类算法流程图
3 实例测试结果与分析
3.1 试验环境
为了验证布谷鸟优化的AP聚类算法在竞争情报中的应用性能,进行实例测试。试验环境为台式电脑,操作系统为开源Linux系列的Ubuntu 21.04(Hirsute Hippo)正式版,CPU为英特尔I7,内存8G,显卡为GTX970,软件为MATLAB R2013b。本文数据源为中关村在线,对10个不同手机制造商的共计100款手机信息进行了爬虫抓取,对100个手机商品进行竞争情报分析,训练和测试比例为8∶2,抓取的数据特征包括手机型号、CPU、内存、摄像头特征、OS、用户评价等。首先采用布谷鸟优化的AP聚类算法对样本进行聚类,分析手机性能和用户评价聚类结果;其次分别采用AP算法和布谷鸟优化的AP算法对样本进行聚类,分析两者聚类结果的聚类样本类间距离性能;最后分别验证常用聚类算法和本文算法在分析手机竞争情报聚类中的性能。
3.2 数据的预处理
本文采用L1范数正则化来完成特征选择。首先计算L1范数评分值,并将适应度的阀值设置为0.6,以便减少数据维度。然后,通过简单快捷的均值方差归一化方法对清洗和特征选择后的样本进行归一化,具体计算公式如下

式中:min表示下界值,max表示上界值,X表示输入特征值,Xscale表示归一化后的特征值。
3.3 CS-AP聚类结果
根据抓取的手机性能参数进行CS-AP聚类计算,选取轮廓评价指标作为聚类结束条件。CS的主要参数Pa=0.25,λ=1.5,α=1,AP算法ϕ=0.7。完成聚类时,手机样本按性能优劣从高到低被分为了4类,聚类结果如表1所示。
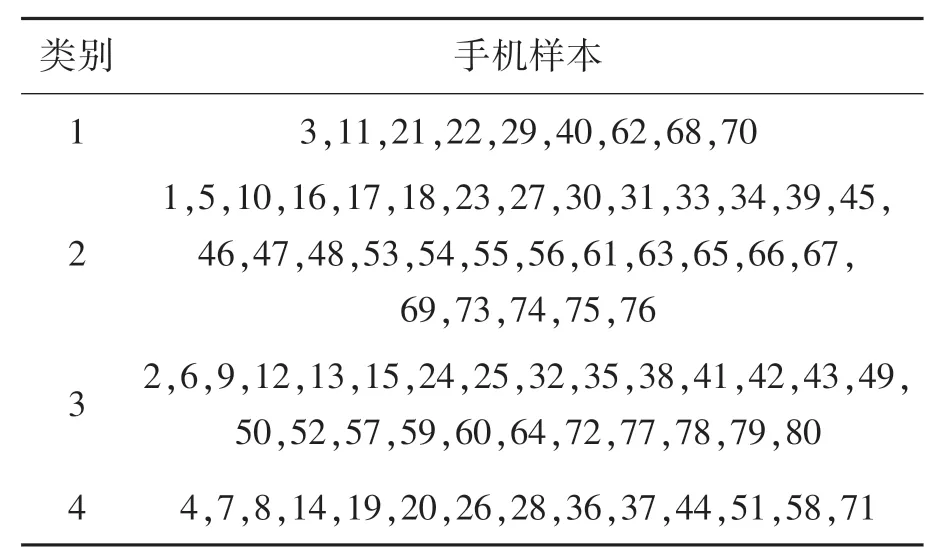
表1 手机性能聚类
下面对用户评价进行分词提取,然后采用CS-AP聚类,用户评价等级按照从高到低被分为了1~5等,聚类结果如表2所示。

表2 手机用户评价聚类
对比表1和表2,可以获取多种手机的行业竞争情报数据,比如手机性能优劣与用户评价等级并没有直接联系,高配性能手机样本共有9个,但是高配中用户评价为优秀的只有29个样本,原因可能是用户觉得这款手机性价比不高,或者高配的性能并没有得到用户的认可,这就可以为这款手机制造商的产品性能改进和产品定价提供帮助。同时根据表1和表2数据,可以具体分析出手机的哪些性能因素是用户最关心最在意的,这样也方便手机行业进行调整设计及生产战略,优化制造成本优化。
3.4 AP和CS-AP聚类性能对比
为了进一步验证布谷鸟算法在AP聚类中的优化性能,分别采用AP算法和CS-AP算法对手机样本进行聚类测试,计算各手机样本到各自聚类中心的欧式距离,结果如图4所示。
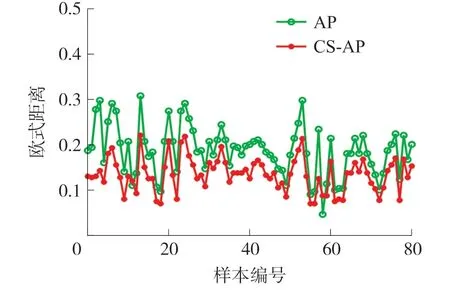
图4 AP和CS-AP算法的欧式距离
从图4可以看出,AP算法的各样本点至类别中心点的距离基本在0.2左右波动,而CS-AP算法的欧式距离基本在0.13左右波动,CS-AP优于AP。另一方面,AP算法的距离波动幅度更大,而CS-AP算法的距离波动偏小,这表明CS-AP算法的类间距离更小,聚类的中心点选择更优。原因是采用CS算法对偏置参数P进行优化后,聚类类别数和聚类中心点数选择更加合理,AP算法能够获得更好的聚类效果。
采用AP和CS-AP算法对80个样本的轮廓性能进行测试,计算方法参照式(9),结果如表3所示。

表3 AP和CS-AP算法的轮廓性能
从表3可知,CS-AP的80个样本的平均值为0.829 5,明显优于AP算法的0.731 6,而且标准差更优。这表明经过CS优化后,聚类效果得到了明显改善,样本的类间分布更紧密、更靠近聚类中心,下面对两者的收敛性能进行测试。
从图5可以看出,经过AP迭代,两种算法的Sil值标准差快速减小直至稳定,但是对比发现,AP算法在迭代过程中出现多次标准差局部收敛的假象,在迭代次数为[18,22]、[37,39]等阶段,标准差几乎没发生变化,而CS-AP算法的标准差一直在减小。在迭代50次后,CS-AP算法达到稳定,收敛于0.25左右,而AP算法迭代80次后才收敛于0.5,因此CS-AP算法的收敛性能更优。经过CS优化后,AP算法能够获得更优的偏置参数P,这为后续的聚类迭代运算节省了时间,且取得了更优的标准差值。

图5 AP和CS-AP算法的收敛性
3.5 不同聚类算法的轮廓性能
下面对常用竞争情报聚类算法进行聚类测试,比较其在手机行业竞争情报中的性能,分别采用均值聚类算法[14]、层次聚类算法[15]、改进的Kmeans算法[16]和CS-AP算法方法对80个手机样本进行测试。测试结果见图6。
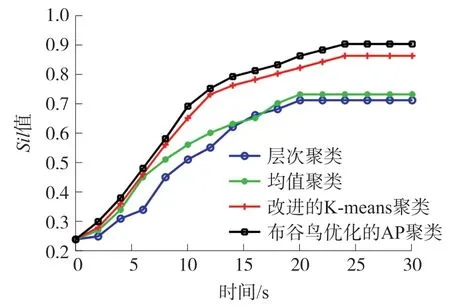
图6 不同聚类算法的轮廓性能
图6展示了4种算法的聚类过程中,所有手机样本Sil均值的变化情况。Sil值越高,表明各聚类类别簇内的节点集中度更高,聚类效果更好。从图6可知,CS-AP算法的轮廓性能最优,稳定时的值为0.9,改进的K-means次之,层次聚类最差约为0.7;从聚类时间来看,层次和均值聚类最好,在20 s内获得了稳定的聚类结果,改进的K-means和CS-AP算法均需要24 s才能收敛,这是因为K-means和CS-AP的聚类过程均需多次迭代。
4 结束语
为了提高竞争情报分析的有效性,采用AP聚类算法对竞争情报数据进行分析,并通过布谷鸟对AP算法的偏置参数进行优化。试验结果表明,通过合理设置布谷鸟和AP算法参数,对情报数据采集得到的数据源进行聚类能够获得较好的聚类效果,以满足竞争情报分析的需要。下一步的研究将继续优化CS算法和AP算法参数,以提高竞争情报分析中的聚类效率,从而增强大规模竞争情报数据分析的适用度。
猜你喜欢
现代装饰(2022年5期)2022-10-13
北京航空航天大学学报(2022年8期)2022-08-31
现代装饰(2022年3期)2022-07-05
现代装饰(2022年2期)2022-05-23
南京理工大学学报(2022年1期)2022-03-17
汽车实用技术(2022年4期)2022-03-07
红蜻蜓(2021年12期)2021-12-19
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
剑南文学(2016年14期)2016-08-22
小天使·一年级语数英综合(2015年10期)2015-10-14
