
基于词映射构建伪查询改善低资源跨语言信息检索研究
2022-06-07 06:14李岩郭军军余正涛高盛祥
山西大学学报(自然科学版) 2022年2期
李岩 ,郭军军 *,余正涛,高盛祥
(1.昆明理工大学 信息工程与自动化学院,云南 昆明 650504;2.昆明理工大学 云南省人工智能重点实验室,云南 昆明 650504)
0 引言
跨语言信息检索(Cross-language information retrieval,CLIR),即用一种语言的查询检索出用另一种语言的相关文档信息[1-4]。跨语言检索可以有效地实现区域内国家之间的信息沟通和交互,因此具有非常重要的研究意义。目前,CLIR已经成为信息检索(Information Retrieval,IR)领域中最重要的研究课题之一。然而,由于查询和文档属于不同的语言,存在巨大的语义鸿沟,因此,如何匹配用户的查询和其他语言编写的文档成了巨大的挑战。
如何构建统一的语义空间并实现跨语言在统一语义空间中的表征,然后在公共语义空间中实现跨语言检索,是CLIR要解决的首要问题。在已有成果中,解决语言差异性最常用的方法还是查询翻译[5-6]、文档翻译[7-8]或同时使用查询文档翻译[9],然后执行单语 IR[10-15]。文献[16]基于双语词典解决歧义和多重匹配问题,实现了跨语言相似内容的检索。然而,上述基于机器翻译CLIR方法严重依赖机器翻译的质量,对于低资源语言来说,低质量机器翻译误差的累积,会对后续的检索任务产生极大的影响,甚至导致检索的失败。
为了解决低资源语言跨语言信息检索中的语义对齐问题,受文献[17]的启发,拟基于更容易获得且准确率较高的词对齐信息对跨语言语义对齐任务进行指导,我们使用预先构建的双语映射词典基于词映射生成伪查询,并且利用伪查询句来指导跨语言信息检索。从表1中可以看出,在低资源语言上,机器翻译的结果完全曲解了查询的意思,而词映射虽然丢失了部分语义,但是它可以保留查询的关键词信息,而关键词信息对于检索任务来说是非常重要的。

表1 词映射与机器翻译效果样例对比Table 1 Comparison of example of word mapping and machine translation effect
基于此,本文提出了一种基于双语交互注意力机制的伪查询句融合方法,本文方法的跨语言检索性能在文献[18]提供的公共CLIR数据集和我们构建的汉越CLIR数据集上均取得了较理想的结果。本文的主要贡献是:
1.本文首次提出一种基于词映射指导的跨语言信息检索方法,即首先利用词映射生成伪查询句来实现跨语言的语义对齐,然后利用双语交互注意力来获取查询的跨语言特征表示,进而实现跨语言检索。
2.结合查询的跨语言特征表示和文档的上下文表示构建了双语排序模块,实现了跨语言深度关联匹配。
3.基于自制的汉越CLIR数据集和文献[18]中公布的三种数据集对模型进行了训练和测试。实验结果表明,该方法能改善差异性低资源语言对之间CLIR的效果,在多个CLIR数据集上取得了很好的结果。
1 相关工作
CLIR目前已经成了国内外的一个研究热点[19-21]。学者们针对如何在源语言和目标语言之间建立沟通桥梁进行了一系列研究和讨论。传统的跨语言信息检索算法大都基于机器翻译的思想,通常包括机器翻译和单语信息检索两部分[22],即首先基于机器翻译实现跨语言的语义对齐,然后在单一语义空间中完成信息检索[23-24]。根据翻译的采取方式可以进一步分为查询翻译[5-6]、文档翻译[7-8]和同时使用查询文档翻译[9]。三种基于翻译的方法通常使用双语词典、平行语料库或者机器翻译来将源语言翻译成目标语言或者将两种语言翻译成枢轴语言,然后执行单语检索。基于机器翻译CLIR方法属于一种管道式(pipeline)的方法,该方法很容易受到翻译误差的累积影响,特别是对于低资源语言对,机器翻译误差累积会为后续的检索造成较大的影响,甚至导致检索的失败。因此,对于低资源语言的跨语言检索,上述基于机器翻译的方法并不是理想的解决方案[25]。
近年来,越来越多的学者开始使用预训练的词向量进行信息检索的研究和建模。受此启发,文献[26]提出了一种生成跨语言词嵌入(CLE)的方法,首先通过随机打乱平行语料库 ,然 后 使 用 word2vec[27-28]得 到 跨 语 言 词 嵌入[29]。经过上述过程可以同时产生两种语言的单词向量表示,以此解决跨语言的语义对齐问题。基于上述跨语言的对齐方式,文献[30]提出了一个完全无监督的跨语言信息检索框架,它不需要使用任何双语数据,该框架利用共享的跨语言词嵌入空间来表示查询和文档。另外,对于低资源跨语言信息检索,文献[31]提出了一种弱监督神经模型,并在并行的机器翻译数据上进行训练。Bonab等[32]利用启发式算法预训练了一种跨语言词嵌入,并将他应用在CLIR中,使得检索精度有了一定的提高。最近,一些多语言与训练语言模型[33]将100多种语言映射到同一语义空间,这使CLIR又进一步改进。但是跨语言词嵌入需要大量的双语语料或对齐的双语词典进行预训练,与此同时,上述模型也没有对CLIR的目标进行优化[26,30]。
综上,如何实现源语言查询和目标语言文档的语义对齐,是目前CLIR研究的核心问题。但是,针对这一问题,传统的基于机器翻译的CLIR方法和基于跨语言词嵌入(CLE)的方法都存在各自的不足之处。对于低资源语言对,低质量的翻译性能直接影响了检索的准确率。而基于CLE的方法又需要大量的训练数据且很难获取。为了提高低资源的跨语言信息检索的准确率,本文提出一种基于双语交互注意力机制的伪查询句融合方法。该方法基于双语交互注意力机制融入伪查询句来生成查询的跨语言特征表示,有效地在不同语言对上缩小了语义空间之间的距离,并对CLIR的目标进行了优化。实验证明该方法相对传统的CLIR方法具有明显的优势。
2 基于双语交互注意力机制的伪查询句融合方法
针对查询和文档之间的差异性比较大的问题,本文基于词映射构建伪查询句来指导低资源跨语言信息检索,提出了基于双语交互注意力机制的伪查询句融合方法。通过双语交互注意力机制得到查询的跨语言特征表示,最后利用双语交互排序模型去计算查询文档对的匹配分数,如图1所示。
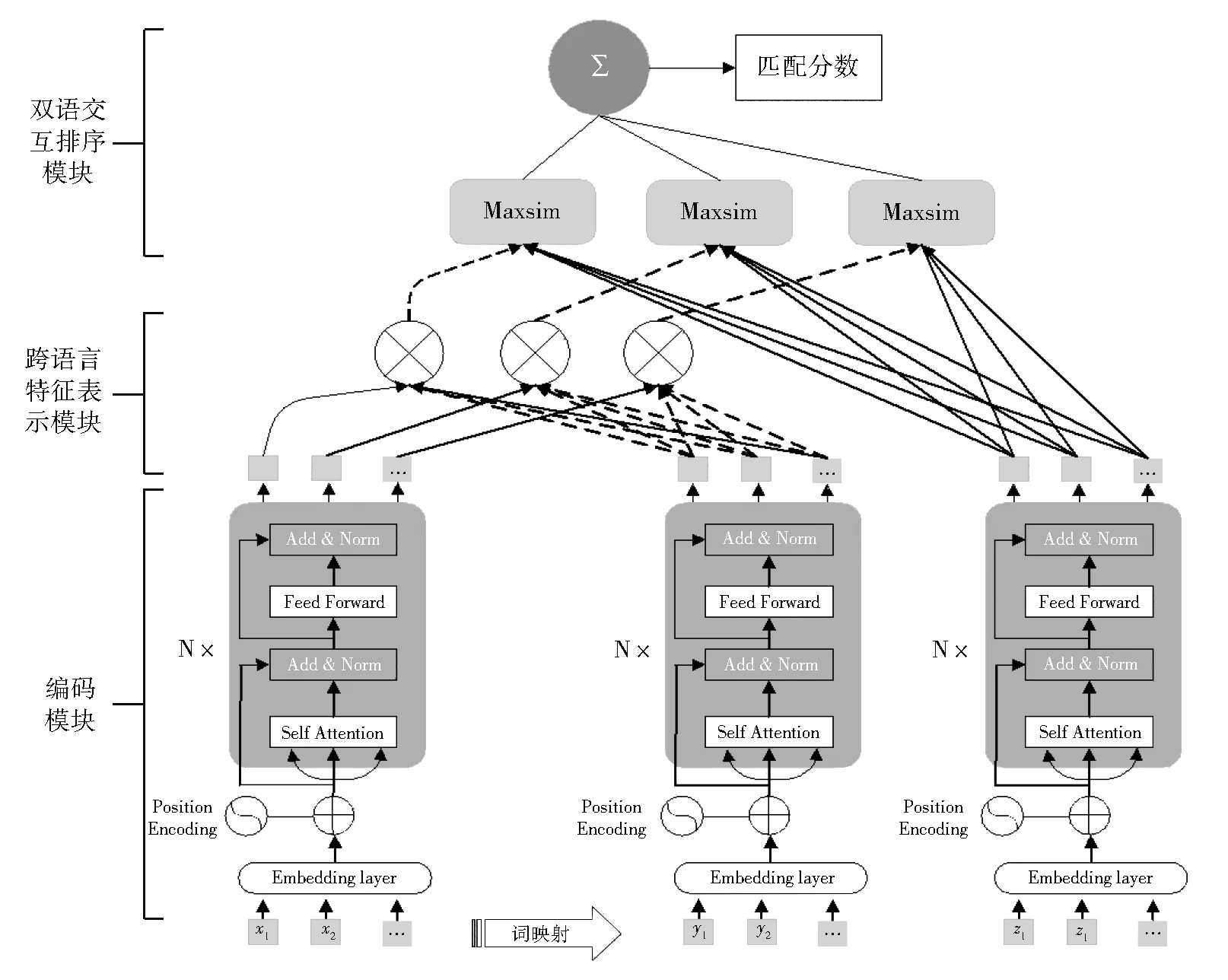
图1 跨语言深度联匹配模型结构图Fig.1 Structure of cross-language deep joint matching model
模型包括共享编码模块、跨语言特征表示模块和双语交互排序模块,其中,(a)共享编码模块:用来获取查询、伪查询和文档的上下文表示;(b)跨语言特征表示模块:基于双语交互注意力机制来获取查询的跨语言特征表示;(c)双语交互排序模块:获取查询和文档的匹配分数。
2.1 词嵌入
给 定 一 个 查 询 qzh=(x1,x2,…,x|q|)和 文 档d=(z1,z2,…,z|d|),其中,|q|和|d|表示查询和文档的长度。首先,我们利用双语映射词典生成的伪查询 qvi=(y1,y2,…,y|q|)。然后将每个句子的每个单词表示成n维词向量,如公式(1)-(3)所示:

其中,Qz∈ Rn×|q|、Qv∈ Rn×|q|和 D ∈ Rn×|q|,分别表示查询、伪查询和文档的嵌入特征表示矩阵;xi、yi和zi表示查询、伪查询及文档的第i个词;Eqz、Eqv和Ed分别表示查询、伪查询及文档的嵌入函数,它可以将每一个输入序列中的每个词转化为对应的n维词向量;“分号”表示连接操作符。
2.2 基于Transformer的共享编码模块
2.2.1 查询和文档编码
给定一个查询qzh和文档d,经过嵌入层获取到每一句查询和文档的嵌入矩阵Qz和D,我们将文献[34]的编码模块(即transformer encoder)应用到本文的共享特征提取器中。Transformer encoder由6个相同的层堆叠在一起,每一层又分为两个子层。第一个子层是一个多头的自注意力机制,第二个子层是一个简单的全连接前馈网络。在两个子层外面都添加了一个残差连接,然后进行了层归一化的操作。具体对查询和文档的编码过程如公式(4)、(5)所示。
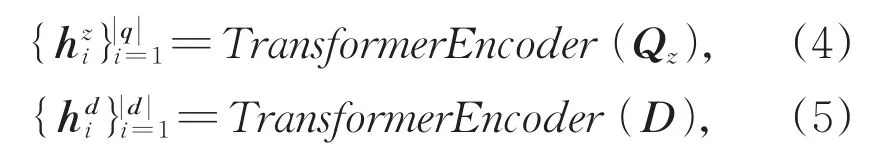
我们获取到查询和文档的上下文特征表示进行归一化,使得每个特征向量都成为等于1的L2范数,这样使得任何两个特征向量的内积等于他们的余弦相似度。
2.2.2 伪查询句编码
伪查询句的生成:由于传统的基于句子级机器翻译的方法在差异性比较大的语言对上翻译质量很差,所以没有办法基于翻译系统来进行单语检索。为此,本文首先利用Google翻译将所有查询翻译成文档端语言;然后将翻译结果回译,并基于两个翻译结果进行人工筛选将所有翻译质量差的句对剔除;最后我们利用快速对齐工具[35]实现词对齐并结合翻译从候选词对齐中人工筛选唯一词对齐,以此生成双语映射词典。基于此,根据词映射来生成伪查询句,进而保留查询中大部分关键词的准确信息,如公式(6)所示。
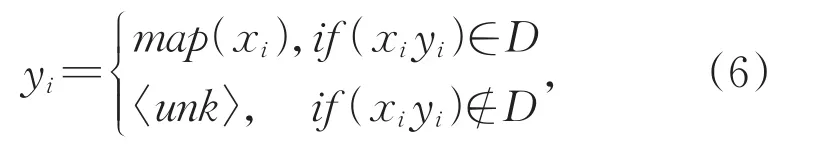
其中,D表示双语映射词典;xi表示查询中的第i个词;yi表示词映射之后伪查询句中的第i个词。
编码:伪查询句编码和查询编码是非常相似的结构。我们首先将伪查询句标记为给qvi,经过嵌入层获取每一句伪查询句的嵌入矩阵Qv,然后将伪查询句的嵌入矩阵输入到共享特征提取器中,从而获得它的上下文特征表示,如公式(7)所示:
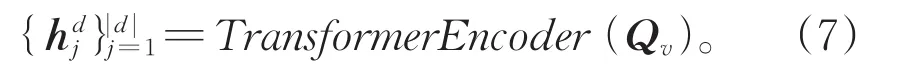
同样,本文将伪查询句的上下文表示进行归一化,使得每个特征向量都成为等于1的L2范数。
2.3 跨语言特征表示模块
2.3.1 双语交互注意层
本文借鉴神经机器翻译中注意力机制[36-37]的思想实现双语交互注意,目的是语义上对齐两个句子,使得两种语言的嵌入空间尽可能接近。具体地,我们在查询和伪查询句之间定义了一个双语交互注意力机制,该机制使得查询每一个词的特征表征通过只关注来自伪查询句的相关词的特征表征来表示,如图2所示。
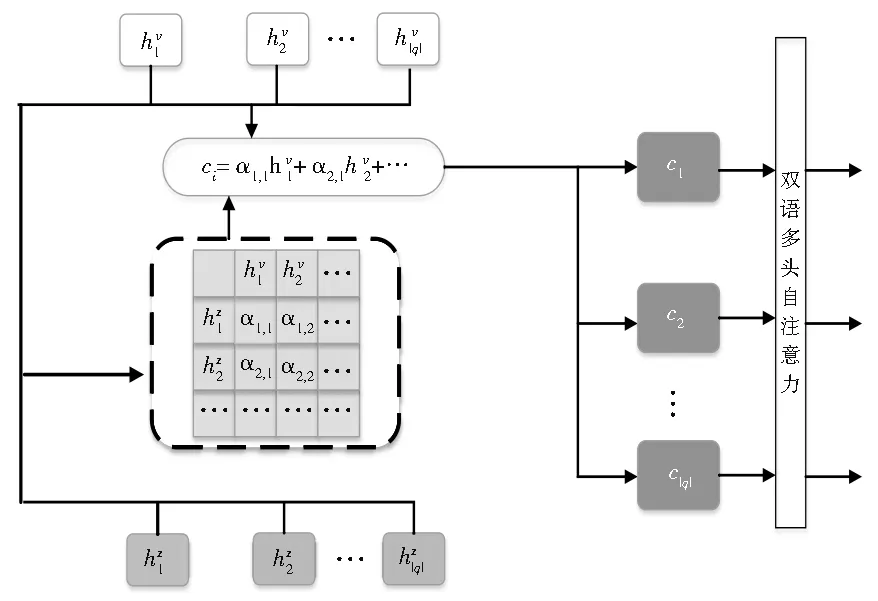
图2 双语交互注意力机制结构图Fig.2 Structure of bilingual interactive attention mechanism
根据基于transformer的共享编码模块我们可以获取到查询和伪查询句的特征表示序列。然后利用伪查询句的每一个特征表示的加权平均值来表示查询的第i个词的跨语言特征表示ci,计算如公式(8)所示:

其中,ci表示查询的第i个词的跨语言特征表示;注意力权重αi,j表示伪查询句的第j个词与查询中第i个词的注意力权重,它是通过在相应的匹配分数mi,j上计算softmax函数而获得的,如公式(9)所示:

匹配分数mi,j又是基于特征向量的双线性乘积来计算的,具体计算过程如公式(10)所示:
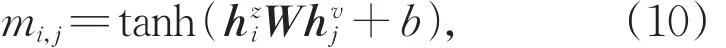
在跨语言任务中使用双语交互注意力机制,将一种语言的句子放在另一种语言的上下文嵌入中,从而得到这种语言的跨语言特征表示,以此达到语义上对齐两种语言的目的。
2.3.2 双语多头自注意力层
为了使得跨语言表征之后的查询拥有更多的句内语义信息,本文基于双语交互注意力机制得到查询句中每一个词的跨语言特征表示ci之后,并基于多头自注意力机制进行特征提取。具体如公式(11)所示。

其中,self_attention()表示多头自注意力机制的映射函数;表示查询的第i个词的跨语言上下文特征表示。
2.4 双语交互排序模块
给定查询经过双语交互注意力机制之后的表示矩阵,以及文档经过共享transformer编码之后的上下文表示矩阵,本文模型通过双语交互排序模块计算查询和文档之间的匹配关联得分,关联得分通过最大相似度(MaxSim)操作符的总和求得。
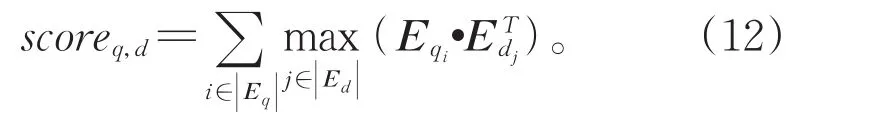
本文通过成对排名网络损失[38]最大化相关文档和不相关文档之间的分数差异来训练跨语言深度关联匹配模型。
3 实验
3.1 数据集
3.1.1 汉越CLIR数据集的构建
汉越CLIR数据集的构建过程与文献[19]构建英语-其他语言的CLIR数据集类似。首先从维基百科的每一篇英文文章中提取首句作为查询,并将链接到的越南语文档页面标注为相关。接下来我们使用Google翻译工具将查询翻译成中文。与文献[18]相似,我们将汉语查询中的主题词删除,这样做是为了防止我们的任务变成一个简单的关键字匹配问题。根据实际情况,我们将每个文档长度限制在文章的前250个词以内。经过一系列数据整理和预处理我们获得汉越CLIR数据集的三元组:(中文查询,越南文文档,相关性判断r),其中r∈{0,1}。
3.1.2 CLIR数据集的介绍
在所有实验中,我们使用了查询-文档对数据集。其中包括自制的汉语-越南语(zh-vi)数据集,以及文献[18]中提供的英语-法语(en-fr),英语-菲律宾语(en-tl),英语-斯瓦希里语(en-sw)三对公共语言对数据集。数据集规模如表2所示。
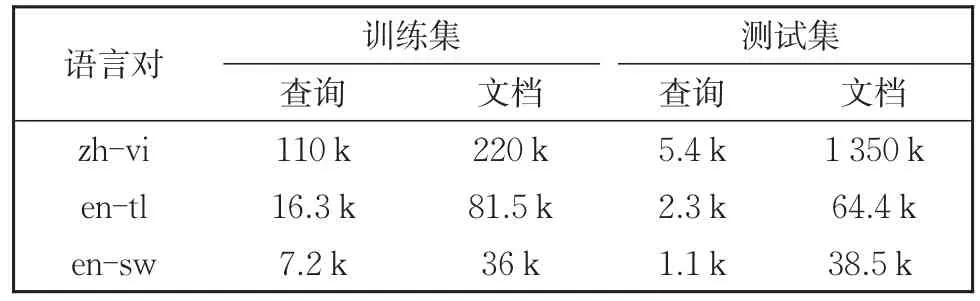
表2 CLIR数据集统计信息Table 2 Statistics of CLIR datasets
由于本文的目标之一是检验不同程度相似语言的检索性能,因此我们使用汉越这样查询和文档差异性比较大的语言对、以及文献[18]中提供的资源不同的三种语言对进行实验。
3.2 评价指标和实验设置
本文的评价指标[39]主要采用 MRR(Mean Reciprocal Rank)、P@1(Precision at 1)、R@k(Recall at k)、MAP(Mean Average Precision)以及 NDRG@k(Normalized Discounted Reciprocal Gain)。可调参数设置如下表3所示。

表3 可调参数设置Table 3 Adjustable parameters
3.3 基线模型
本文共选择了5个基准模型进行实验,如下:
(1)基于查询翻译的CLIR方法(CLIRTQ):这种方法首先使用Transformer[34]将查询翻译,然后执行单语检索,这种方法与文献[22]类似。
(2)基于文档翻译的CLIR方法(CLIRTD):这种方法首先使用 Transformer[34]将文档翻译,然后与(1)相同,执行单语检索。
(3)基于余弦模型的匹配检索方法(CLIRS-COS)[18]:此模型中使用 CNN 对查询和文档进行特征提取并利用余弦模型计算二者的匹配得分。
(4)基于深度模型的匹配检索方法(CLIRS-DEEP)[18]:此模型同样使用 CNN 对查询和文档进行特征提取。然后获得查询和文档的句子特征表示和并利用深度模型计算二者的匹配得分S,如公式(13)所示:
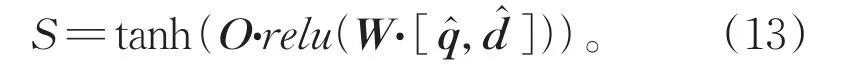
其中,O和W表示学习的参数矩阵,relu()表示非线性激活函数。深度模型根据深度分为CLIR-S-DEEP300、CLIR-S-DEEP400、CLIR-SDEEP500。整个模型的超参设置参照文献[18]。
(5)基于预训练语言模型:此方法使用多语言预训练语言模型(mBERT)来编码查询和文档,基于此计算查询和文档的余弦相似度。
3.4 实验结果及分析
在此部分,我们对本文模型的有效性进行了分析,由于汉越数据集是由本文构建,对两种语言的研究极少,所以本文只利用汉越数据集对模型结构进行选择,并得到最优模型结构。基于此,本文在两个低资源的公共数据上进行了有效性测评。
3.4.1 公共CLIR数据集分析测评
为了验证本文的基于双语交互注意力机制的伪查询句融合方法在公共数据集的有效性,本文使用文献[18]公布的公共数据集(数据集详情见表3)和性能最优的“(sh)本文模型”,与上述基准模型的性能作对比,为了使对比更加直观,本文与基准模型的来源文献[18]使用相同的评价指标,对比实验结果见表4。

表4 公共CLIR数据集实验结果Table 4 Experimental results of public CLIR data set
分析表4可知,本文模型在两种语言对上的P@1值和MAP值均超过所有对比模型。从表中可以看出,传统的基于机器翻译的基线模型都取得了不错的效果,但是与各深度学习模型还存在一定的差距。其中,与传统方法中效果比较好的查询翻译相比;在en-sw数据集上,P@1值和MAP值分别提升了11.5%和17.0%;在en-tl数据集上,P@1值和MAP值分别提升了13.1%和15.8%;这表明我们的方法相比与传统的机器翻译的方法在两个低资源数据集上有明显的改进,这也进一步证明了细粒度的方式更有利于拉近低资源语言的语义空间。与深度模型中效果最好的基线模型mBERT相比,在en-sw数据集上,P@1值略有下降,但是MAP提升了1.5%;在en-tl数据集上,P@1值和MAP值分别提升了4.2%和5.4%。实验结果表明在大规模训练语料上预训练好得多语言模型非常具有竞争力,因为它们已经把100多种语言之间的语义空间映射得非常接近了;另外,本文方法也体现了一定的优势,进一步证明了本文融合伪查询句的有效性。为了进一步证明本文模型在差异性不同的语言对上的优势,我们增加评价指标NDRG@k,并得到NDRG@k的结果折线图,如图3所示。
从图3中折线图中可以看出,在三种语言对的数据集上,本文方法相比于基准模型取得了更好的结果,在en-sw和en-tl两个数据集上提升比较明显。这些实验结果表明在菲律宾语等低资源语言训练数据不充足的情况下,本文方法在跨语言信息检索的任务中具有明显的优势。

图3 NDCG@k的结果折线图Fig.3 Line chart of NDCG@k results
3.4.2 融合伪查询句的有效性分析
为了证明本文提出的融合伪查询句来指导跨语言信息检索对本文模型的有效性,本文在自制的汉越CLIR数据集上进行了一组简单的消融实验,并用MRR和R@k作为评价指标[39],实验结果如表5所示,特别说明,“(-)伪查句”表示未使伪查询句来指导跨语言信息检索,使用直接建模的方式来实现。
由表5我们可以看出,在本文模型中,当我们使用伪查询句来指导跨语言信息检索时,MRR、R@3、R@5和R@10分别提升了9.45%、10.73%、10.65%、10.53%,由此证明基于词映射的伪查询句的构建和融入,在汉越这种低资源语言对上是有效的,它可以在一定程度上拉近汉越两种语言的语义空间。

表5 消融实验结果Table 5 Results of ablation experiments
3.4.3 双语交互注意力机制的有效性分析
为了得到本文模型中效果最优的双语交互策略。本文制定了三种不同的交互策略来选择最优的模型架构:
策略一(CLIR+MTL):本文利用联合多任务的思想,利用伪查询句作为辅助约束,使得查询句的语义和伪查询句的语义相似度尽可能接近,然后来辅助跨语言信息检索这个主任务。
策略二(CLIR+concat):首先将查询句和伪查询句对应位置的特征表示直接拼接,以此认为两种语言的语义空间被拉近。
策略三(CLIR+c_att):引入双语交互注意力机制,上述2.3描述方法。
针对上述的三种策略,本文利用我们构建的汉越CLIR数据集做了实验对比,实验结果如表6所示。
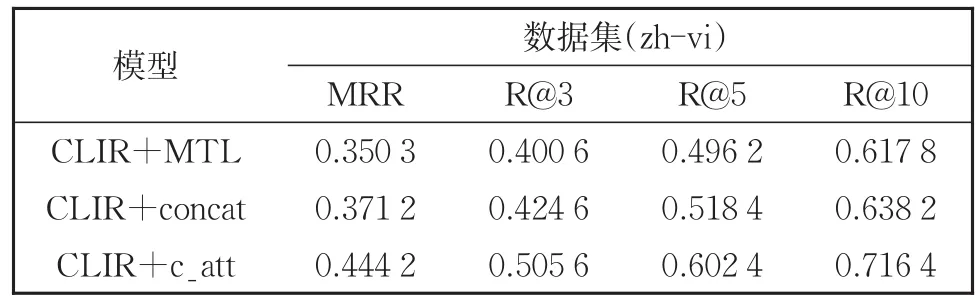
表6 双语交互注意力机制有效性分析结果Table 6 Results of effectiveness analysis of bilingual interactive attention mechanism
从表6可知,三种不同的融合策略会直接导致不同的检索性能。其中,与策略一(CLIR+MTL)相比,使用本文的双语交互注意力机制时,MRR值、R@3值、R@5值和R@10值分别提升了9.39%、10.50%、10.62%、9.86%;与策略二(CLIR+concat)相比,双语交互注意力机制分别提升了7.30%、8.10%、8.40%、7.82%。由此可见,双语交互注意力机制是本文模型的重要一环,它可以利用伪查询句的指导作用来拉近两种语言的嵌入空间,进而有效地改善模型跨语言信息检索的性能。
3.4.4 双语交互排序模型的有效性分析
为了给本文模型选择最优的排序方式,我们使用双语交互排序模型与基线模型中的排序方式来作对比。其中,第一种方式是利用平均池化的方式得到查询和文档的句子向量,直接利用句子向量计算余弦相似度得到排序分数(CLIR-sent_cos)。第二种方式是本文使用的双语交互排序方式。对比实验结果如表7所示。
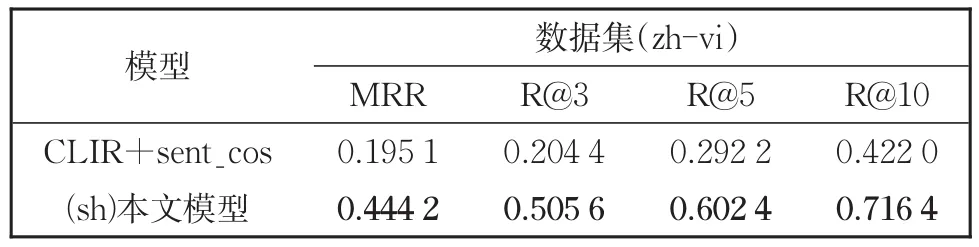
表7 双语交互排序模型有效性分析结果Table 7 Results of the effectiveness analysis of the bilingual interactive ranking model
从表7可知,本文提出的双语交互排序模型与传统方法相比具有很明显的优势。由此可见,不一样的排序方式也会直接影响检索的准确率。由于查询和文档的长度差距比较大,文档句子又过长,直接利用句子的表征去计算匹配得分会大大的丢失关键语义信息,从而导致准确率的下降。而本文的双语交互排序模型可以从词级粒度出发,更为全面的计算短查询和长文档的相似性,所以本文排序模型具有明显优势。
4 结论
本文研究旨在提升差异性比较大的低资源语言对跨语言信息检索的准确率。针对不同语言之间存在语义鸿沟等原因导致检索准确率低这一问题,我们利用双语映射词典构建伪查询句,提出了一种基于双语交互注意力机制的伪查询句融合方法。本文模型在自制的汉越数据集和CLIR公共数据集上均取得了显著的效果。当前,针对低资源语言得跨语言信息检索是检索领域的研究热点和难点,在未来工作中,我们将针对低资源跨语言信息检索展开进一步的研究。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
电脑爱好者(2021年9期)2021-05-12
电脑爱好者(2017年7期)2017-05-06
湖北函授大学学报(2016年13期)2017-01-03
科技视界(2016年12期)2016-05-25
新晨(2013年7期)2014-09-29
新晨(2013年5期)2014-09-29
新晨(2013年10期)2014-09-29
图书馆界(2013年5期)2013-03-11
