
融合标签层级结构的文本分类
2022-06-07 06:14刘瀚锴黄贤英朱小飞付朝燕
山西大学学报(自然科学版) 2022年2期
刘瀚锴,黄贤英,朱小飞,付朝燕
(重庆理工大学 计算机科学与工程学院,重庆 巴南 400054)
0 引言
文本分类是自然语言处理技术中非常重要的领域,被广泛应用于垃圾邮件过滤、新闻分类、情感分析、恶意评论检测等场景。层级文本分类(Hierarchical Text Classification,HTC)是文本分类领域中的一项特殊任务,分类结果对应标签层级结构中的一个或多个节点。如图1所示,标签被分层存储在预先定义好的树形结构中。层级文本分类可用于解决为专利申请分配分类代码[1]、网页分类[2]、表情符号推荐等任务。工业界和学术界对HTC任务都进行了广泛的研究。
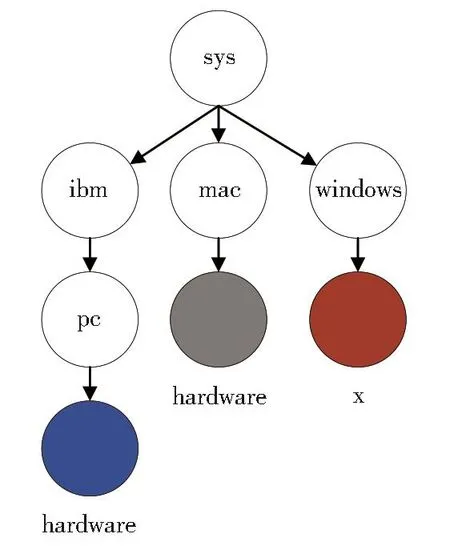
图1 预先定义好的标签层级结构Fig.1 Structure of predefined label hierarchy
Fall等[3]提出使用传统分类模型(朴素贝叶斯),将HTC问题简化为平坦的多标签分类问题,直接预测位于最后一级叶子结点的类别。这种简化方法忽略了标签的层级结构信息。为解决这个问题,Read等[4]提出对于每个二分类模型的属性空间都用0或1来拓展,代表之前所有分类器的标记相关性,从而形成分类器链。然而当第一个分类器中的一个或多个预测较差时,分类误差可能会沿链进行传播。同样,Mayne等[5]将独立的朴素贝叶斯分类器组成分层分类器,父分类器的输出概率作为额外特征传播到子分类器,每个分类器都使用二元正态分离进行单词特征选择。Shimura等[6]在学习层级信息的时候,将上层标签信息以微调卷积神经网络的方式传递到下层标签的学习中。Zhou等[7]通过引入先验层级信息和样本分布概率,使用Bi-TreeLSTM和GCN构建层次感知结构编码器来建模标签关系。然而通过样本集中标签出现次数计算得到的标签节点传递概率可能存在移植性较差的问题,在实际应用场景中,不同类别文本的数量可能随着热点的变化而变化。且该模型只考虑了标签层级结构信息,并未考虑标签语义结构信息,其在一定程度上造成了标签特征的浪费。
总之,现有的研究方法主要分为两类:(1)关注局部,倾向于构造多个层次分类模型,然后以自顶向下的方式遍历层次结构。每个分类器预测对应的类别或类别层次。(2)关注全局,将所有类别集合在一起,用单个分类器进行预测。
尽管这些方法从一定程度上引入了标签的结构信息,却忽略了标签的语义结构特征、层级结构特征以及它们与输入文本特征之间的关系。同时,大多数HTC任务标签集有多个层级,且一篇文本可能同时属于多个类别。如图1所示,语义相似度较高的标签可能隶属于同一个或不同的父级标签下。当标签数量较大、标签相似度较高时,通过人工阅读进行标注的方法构造数据集存在诸多主观因素,容易造成分类错误和分类缺失的问题。
为解决以上问题,提出了融合标签结构的层级标签文本分类模型(LHSSL)。首先通过传统编码器提取输入文本特征,连接激活函数得到预测概率分布。然后引入使用外部语料预训练好的语言模型得到标签嵌入向量,计算标签嵌入向量间的相似度得到标签的语义相关结构图。根据数据集给出的多层级类别标签,构建标签的层级结构矩阵。同时由于标签数量较少,使用单层图卷积就可以提取整个图结构的特征。因此使用共享参数的单层图卷积学习语义结构图与层级结构图的共享特征得到了两种标签嵌入。利用自注意力机制学习标签之间的关系得到新的标签嵌入向量。计算文本嵌入与标签嵌入的相似度,并且动态融合输入文本的特征。经过激活后构造标签模拟分布,将两个分布加和平均并激活后得到最终的分类结果。
本文的主要工作有:(1)通过数据标签集提取标签的语义结构信息与层级结构信息。(2)提出LHSSL文本分类模型,将标签语义结构信息、层级信息以及输入文本特征进行融合,学习标签的模拟分布作为预测的soft target。(3)在20NG、8NG_E、8NG_H、WOS11967四个数据集上验证了模型的有效性。(4)当标签数量较多且层级划分较精细时,不同的标签可能具有较强的相似性从而导致数据标签标注错误。因此引入一定噪声并验证了在数据集标签含有30%噪声时,LHSSL同样有效。
1 相关工作
1.1 图卷积神经网络
图结构数据含有丰富的信息,其中属性信息描述了图中节点的固有属性,结构信息描述了图中节点的关联性质。相较于卷积神经网络和循环神经网络,图卷积神经网络更适用于处理非欧几里得结构性的图数据。图卷积的目的是通过聚合节点自身以及邻居节点的信息提取拓扑图的空间特征。基于建模图卷积神经网络时关注领域不同[8],研究人员提出了如Spectral CNN[9]、GAT[10]、R-GCNs[11]、FastGCN[12]等多种变体。许多现实世界中的问题都能通过图结构进行表述,图卷积神经网络也在社交网络、推荐系统、知识图谱、生物遗传和路径规划等领域有着广泛的应用。
图卷积神经网络同样可以应用在文本分类任务中。Yao等[13]对整个语料库构图,将词与文档作为节点,词节点之间的边依据词的共现信息构建,文档节点与词节点之间的边由词频和词的文档频率构建,通过图神经网络对图进行建模从而将文本分类问题转化为节点分类问题。Liu等[14]提出TensorGCN框架用于文本分类问题,框架利用语义、句法、顺序上下文信息构造文本图张量,并执行图内传播、图间传播分别用于在单个图中聚合来自邻居节点的信息以及协调图之间的异构信息。
1.2 标签嵌入
标签嵌入学习是通过学习标签的向量表示来增强模型的分类效果。Chai等[15]提出引入外部知识生成标签的模板描述、从输入文本中抽取关键句生成标签的提取表述和通过语言模型生成输入文本的摘要得到标签的抽象描述从而得到标签的向量表示;Zhou等[6]利用不同标签在数据集中出现的次数作为先验概率来构建标签结构树对标签进行编码;Pappas等[16]提出一种连接文本向量和标签向量的方式,用来提取标签之间的非线性关系;Du等[17]通过计算单词向量与标签向量的logits来解决传统文本分类忽略字级匹配的问题。Huang等[18]使用注意力机制,让学习的文本向量与标签向量进行循环学习、交互。本文也构建了模型学习标签之间的关系从而生成含有丰富信息的标签嵌入向量。
1.3 标签平滑
标签平滑算法(label smoothing:LS)由Szegedy等[19]于2016年提出。标签平滑用于解决由使用one-hot向量表示标签带来的模型过拟合的问题,以及全概率和零概率导致样本所属类别和其他类别预测概率相差尽可能大致使模型过于自信的问题。当面对数据集标签集合中某些标签存在一定相似性以及数据集存在误标的情况下仍使用one-hot向量表示标签会一定程度上影响模型的预测能力。标签平滑通过引入超参数E作为错误率,当样本标签为0时,使用较小的E而不直接使用0作为标签进行训练,同样的,当样本标签为1时,使用1-E作为样本标签进行训练,使样本标签变得不那么极端,从一定程度上增强了模型的泛化能力。Müller等[20]指出LS除了可以提高模型的泛化能力以外还可以提高模型的校准性。He等[21]也验证了LS在图片分类任务中取得的优异表现。
1.4 标签增强
标签分布反映了数据集中每个标签与样本匹配的程度。然而大多数数据集的标签都是单一标签的集合,要获取数据真实的标签分布,需要对每条样本进行大量的标注,当标签数目较多时,会花费大量的时间与精力,标注的准确性也得不到保障。因此,Gayar等[22]、Wang 等[23]、Hou等[24]、Guo等[25]分别提出了 Fuzzy C-Means、Label Propagation、Mainifold Learning、Labe confusion learning 等标签增强的方法,利用样本集自身的特征空间构造标签分布。
2 模型设计
LHSSL的模型框架如图2所示。整个框架主要分为三个部分:预测概率分布计算、标签模拟分布构造以及损失计算。

图2 模型结构Fig.2 Model structure
2.1 预测概率分布计算
计算输入文本分类预测概率分布,可以使用任何一种输入编码器,例如:CNN、RNN、LSTM、Bert等用于提取输入文本特征。连接softmax激活函数进行非线性转换得到预测的标签的概率分布。

其中fI为输入编码函数,用于将长度为n的输入文本 w=[w1,w2,…,wn]转化为长度为 n、维度为 d 的向量表示 v=[v1,v2,…,vn]。yp为预测的概率分布。
2.2 标签模拟分布构造
2.2.1 标签信息提取模块
标签信息提取模块分为两个子模块:标签语义结构特征提取和标签层级结构特征提取。
标签语义结构特征提取模块首先初始化标签嵌入向量,将包含层级结构的标签集L中的每个标签按照层级结构拆分为多个单词。如talk.politics.mideast可拆分为单词talk、politics、mideast三个单词的共同表示。通过引入使用外部语料库预训练好的语言模型,如word2vec、glove等,得到每个单词的嵌入向量。将单词嵌入向量累加后除以单词的个数得到每个层级标签的嵌入表示。

其中n(i)为第i个层级标签中的单词数量。拼接每个层级标签嵌入向量后得到标签集初始嵌入矩阵为标签层级结构叶子节点个数,即数据集标签个数。通过余弦相似度计算每个标签嵌入向量间的相似度用于构图,连接相似度大于0.8的节点对,并将节点对间的连接强度用min-max进行标准化后作为邻接矩阵Af中对应元素的值。
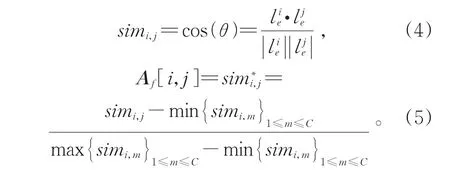
标签层级结构特征提取模块通过数据集中标签本身的层级结构构造结构关系图。图3为20NG数据集标签层级结构的一部分。其中标签talk.politics.guns和talk.politics.mideast分别由单词 talk、politics、guns和单词 talk、politics、mideast组成。其中相同的单词为talk和politics,即两个标签同属于父级标签talk下的politics中,因此具有两级的层级相关性,关系图中对应边的权重为2。基于这个规则,再次构建一个初始值为0,大小为C*C的邻接矩阵As,其中元素的值由两两标签之间的层级相关度决定。

图3 Talk标签组层级结构图及层级结构矩阵Fig.3 “Talk”label group hierarchy chart and hierarchy matrix
标签的语义结构特征和层级结构特征并不是完全无关的。Ding等[26]在异常节点检测任务中提出通过元学习利用同领域中不同关系图提取节点的特征,并验证了其有效性。同时,数据集标签数量较少。基于这两点,提出通过共享参数矩阵的单层图卷积提取两个图数据的相关特征并得到包含共享特征的标签嵌入。
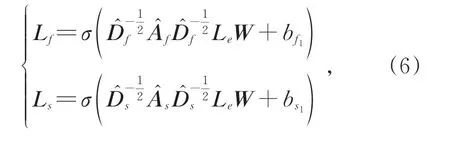

2.2.2 标签混淆模块
通过点积计算输入文本嵌入v与两种标签嵌入LAf和LAs中每个标签的相似度得到两个相似度分布随着输入文本的变化也是基于输入样本动态变化的,在只考虑标签之间相关性的基础上又增加了一定的灵活性。

其中Wf∈RC×C、Ws∈RC×C、bf∈RC、bs∈RC分别为可学习的参数矩阵和偏置项。将两个相似度概率分布相加取平均值后可得到标签分布yc:

将通过相似度计算得到的标签概率分布作为target缺乏一定的准确性与说服力。因此引入原始样本真实标签的one-hot向量yt构建标签模拟分布ys,并用超参数α控制真实标签的指导程度(标签模拟分布的流程如表1所示):

表1 标签模拟分布构造流程Table 1 Flowchart of construction of label simulation distribution

2.3 损失计算
使用KL散度作为损失函数,衡量模拟标签分布ys和预测标签分布yp的匹配程度:
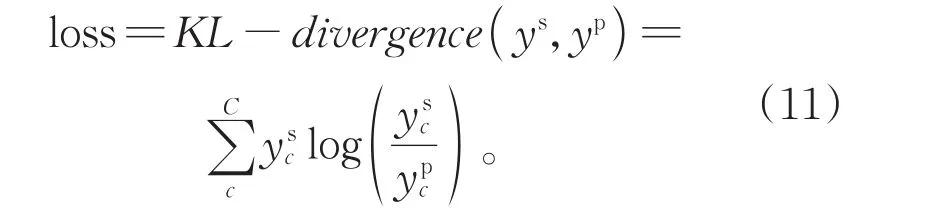
通过最小化KL散度对模型进行优化。学习的标签模拟分布使得标签的表示更加平滑,有助于使模型更好地表达容易混淆的样本。面对相似性较强的样本时,模型会将错误标签的概率按标签结构关系和语义关系分配到相似的标签上,增强了模型的泛化能力以及应对噪声的能力。
3 实验设置
3.1 数据集
本文在4个数据集上进行了实验:20NG、8NG_H、8NG_E和WOS11967。
20NG全名为20NewsGroups,是一个用于文本分类、文本挖掘和信息检索研究的新闻语料数据集。20NG数据集一共有18 821条样本,分为20个标签,属于5个标签组。从20NG数据集中选取相关性较强的8个类别和相关性较弱的8个类别的样本集合,并将他们划分为20NG的两个子数据集8NG_H和8NG_E,如表2所示。

表2 8NG_H和8NG_E数据集的标签划分Table 2 Label division of 8NG_H and 8NG_E dataset
WOS11967[27]是通过 Web of Science 论文数据库构建的文本分类数据集。WOS11967是WOS数据集的子数据集,共有35个类别标签,隶属于 Computer Science、Electrical Engineering、Psychology、Mechanical Engineering、Civil Engineering、Medical Science、biochemistry共7个大类下。每条样本包含一篇文章的标签、关键词和摘要,练集本文只选择文章的标签和摘要作为最终的数据。每个数据集中的训、验证集、测试集随机划分,训练集、验证集的样本数量占整个数据集的60%和15%,剩余的为测试集。
4个数据集的基本信息如表3所示。其中|L|是每个数据集的标签数量,Max Depth是标签层级结构最大深度,Avg(|Li|)是平均每个节点的深度。Train Size、Val Size、Test Size分别表示训练集、验证集、测试集的样本数目。

表3 数据集基本信息Table 3 Basic information of data set
3.2 实验参数设置
模型中主要超参数α、st的设置如表4-5所示。

表4 噪声为0时α和st的取值Table 4 Values ofαandstwhen the noise is 0

表5 噪声为0.3时α和st的取值Table 5 Values ofαandstwhen the noise is 0.3
除α以及st以外,构建标签语义结构图时使用的相似度阀值参数设置为0.8。词嵌入维度为768,词典大小为20 000。实验将LHSSL模型与传统的文本分类模型Bert、LSTM以及加入标签平滑后的Bert和LSTM进行对照。其中Bert中Transformer编码器隐层为2、隐层神经元数为128、多注意力头的数目为2。模型的隐层维度为64维。在训练中使用Adam优化器,学习率设置为0.000 1,训练过程中的批处理大小为512,使用Bert为基本预测模型时的迭代次数为150次,使用LSTM为基本预测模型时迭代次数为60次。为了防止过拟合,在网络的每一层加入Dropout,丢弃概率为0.5。同时,label smooth的E为0.1,图卷积的Adam优化器的学习率为0.2。
3.3 实验参数设置
观察表6-8中数据可以得到结论:无论数据集的标签中是否含有噪声,利用标签的语义关系以及层级结构关系特征,从一定程度上都能提高模型的分类性能。

表6 无噪声时测试集上的准确率Table 6 Accuracy on test set without noise
当数据真实标签中不含噪声且使用Bert作为基本预测模型时,加入标签平滑或使用LHSSL并没有明显的提升,甚至在8NG_E数据集上有了0.247 8%的轻微下降。其中8NG_E标签数量少、相关性弱、层级结构少且浅,导致加入元素基本都为0的矩阵作为标签关系信息对模型几乎起不到任何作用,这是导致出现这一结果的主要原因。同理,8NG_H由于标签层级结构较为单一,准确率提升同样不明显。而20NG、WOS11967数据集标签相对较多,标签结构相对复杂,学习到的标签相关性也更加丰富,分类的效果因此挺升得相对较多。当使用LSTM作为基本预测模型时,这一特点更加显著。因此可以得出:当数据集标签数量越多、标签关系越复杂时,LHSSL模型的提升效果越好。同时,当数据集中不存在噪音或存在少量噪音时,分类准确率提升更加显著。

表7 10%噪声时测试集上的准确率Table 7 Accuracy on test set at 10% noise

表8 30%噪声时测试集上的准确率Table 8 Accuracy on test set at 30% noise
对模型分类结果(如图4-图5)可视化后可以观察到在相似度较高的标签的样本上分类效果提升并不明显。但在对分类效果较差的类别上,增加LHSSL模块的确对准确率提高有一定作用。例如用黄框中sci.med被误分为comp.sys.mac.hardware的数量明显下降,证明在标签关系上模型学习到一些有用信息,为标签增加了一定的区分度。

图4 Bert在20NG测试集上的分类结果Fig.4 Classification results of Bert on 20NG test set

图5 Bert+LHSSL在20NG测试集上的分类结果Fig.5 Classification results of Bert+LHSSL on 20NG test set
由图6可以观察到,除了类别19,20NG数据集中每个类别的样本数目几乎不存在明显差异。而WOS11967数据集中,每个类别的样本数量逐渐减少,最多只有450条左右,最少只有53条,相差将近8倍。这可能导致模型在训练集上没有捕捉到足够的特征信息,出现在训练集上准确率高而在验证集与测试集上准确率较差的情况。因此在未来的工作中还需要针对样本数量少以及样本不均衡的问题进一步对模型进行改进。
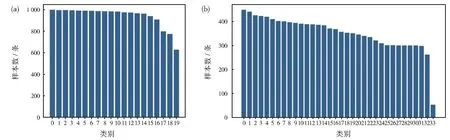
图6 20NG(a)、WOS11967(b)数据集样本分布Fig.6 Sample distribution of 20NG(a)and WOS11967(b)data sets
3.4 消融实验
为验证加入标签语义图、标签结构图以及融合两个图的特征对模型分类效果的提升作用,在 20NG、8NG_H、8NG_E、WOS11967四个数据集上进行了消融实验。观察仅通过预训练词向量生成的标签嵌入与输入文本嵌入构造模拟分布、只对标签语义图进行卷积、只对标签结构图进行卷积以及提取标签语义图和标签结构图的共享特征四种情况时,模型的分类效果。并在20NG数据集上采用T检验进行显著性验证。首先提出零假设,即各模块对模型分类效果提升没有明显差别。设立检验水准为0.05,通过计算,p值分别为0.007 89、0.006 77、0.014 40均小于检验水准,因此拒绝原假设,统计显著。
观察表9,可以得出结论,无论标签语义结构特征还是标签层级结构特征,对分类都有较好的提升作用。这表明,当面对标签没有层级结构的文本分类任务数据集时,通过构造标签语义结构并学习其特征,同样能提高模型预测的准确率。而在融合两个图的共享特征后,模型的性能有了进一步提高。大部分情况下,使用标签语义结构特征对模型的提升作用大于使用标签层级结构特征。由于8NG_H数据集中标签的层级结构较为单一,大多数标签为父级标签下一级的标签,相较于层级结构信息,标签集的语义相关信息更加复杂,因此使用语义图特征的效果提升比使用层级结构图特征更加明显,甚至在学习共享特征后,模型的准确率比起只使用语义结构特征反而降低了1.409 2%。而当使用8NG_E数据集时,使用层级结构特征比使用语义结构特征准确率更高,这是因为8NG_E中标签差异性较强而相关性较弱,因此并不能生成相较丰富的语义结构特征供模型进行学习训练。

表9 标签噪声为0时消融实验效果Table 9 Effect of ablation on test data sets with 0 noise
3.5 参数敏感性实验
模型引入超参数α用来控制真实标签的指导程度,不同的数据集α的取值不同。经过实验,发现引入标签噪声、数据集标签数量、标签层级结构的深度和复杂度等因素对α的取值都有一定影响。
实验结果表明,在20NG数据集中,数据集样本标签不含有噪声时,α设置为0.5的准确率相较于设置为3和8时更高。当对标签引入0.3的噪声时,α设置为3时模型的准确率高于α设置为0.5,因此面对包含一定噪声的数据集时,需要原始标签对模型预测指导程度更强。图7呈现的是扰动为0和0.3时WOS11967验证集的准确率。可以观察到在添加扰动时设置一个相对较大的α模型的准确率更高,而不添加扰动时设置相对较大的α效果同样较好,这可能是因为WOS11967数据集中每个标签都隶属于某个父标签,层级结构都为2,导致不同标签的层级结构信息几乎完全相似,因此需要原始标签较强的指导。

图7 在噪声为0(a)与0.3(b)的WOS11967数据集上α的敏感性实验Fig.7 Sensitivity experiment ofαon WOS11967 data set with noise of 0(a)and 0.3(b),respectively
图8呈现的是扰动为0时模型在8NG_H和8NG_E验证集上的准确率。由于8NG_E数据集标签相关性较低且几乎没有层级结构,可看作相对独立的标签,因此α的取值仍较大。8NG_H数据集存在各标签层级信息差异不明显,但其标签层级结构相较于8NG_E更加丰富,因此α取值分别为0.5、3、8时模型准确率的差异没有8NG_E大。

图8 在噪声为0的8NG_H(a),8NG_E(b)数据集上α的敏感性实验Fig.8 Sensitivity experiment ofαon 8NG_H(a),8NG_E(b)data sets with noise of 0,respectively
同时为了避免过拟合,获得相对较好的泛化能力,使用早停策略。即当模型在数据集上进行了st次完整的训练时,停止使用标签混淆分布而使用原始的one-hot向量和基本分类模型进行训练。图9可以观察到在加入早停策略后,模型在无噪声的WOS11967数据集上分类准确率有了明显提高,而在数据集存在噪声时提升较小,且由于标签混乱导致持续波动,模型不能很好地拟合。
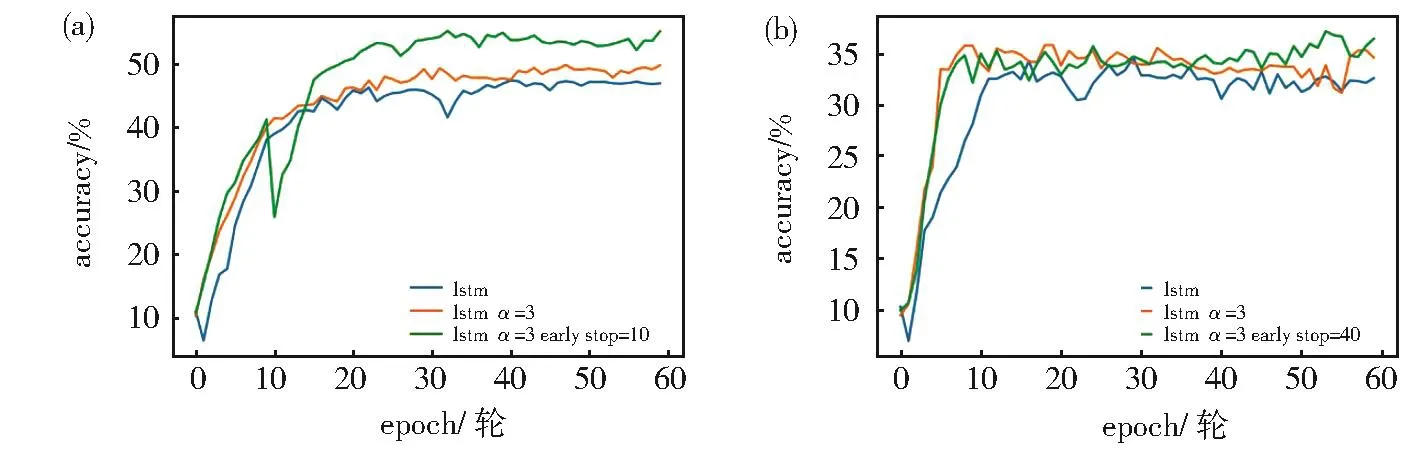
图9 在噪声为0(a)与0.3(b)的WOS11967数据集上st的敏感性实验Fig.9 Sensitivity experiment ofston WOS11967 data set with noise of 0(a)and 0.3(b),respectively
4 结论
本文通过学习标签结构特征解决层级标签文本分类任务没有充分利用标签信息的问题。首先使用基本编码器连接softmax得到标签预测分布。然后通过共享参数的图卷积神经网络学习利用标签集构造的标签语义结构图和标签层级结构图的特征,得到两种标签嵌入,并使用自注意力机制学习标签关系。计算输入文本嵌入与标签嵌入的相似度分布。引入超参数控制样本真实标签的指导程度,构造标签模拟分布。计算标签模拟分布与标签预测分布的KL散度。通过与忽视标签信息直接对输入文本分类与使用标签平滑提高模型的鲁棒性,LHSSL能进一步提升层级标签分类的准确率。该模型不改变原始分类模型的结构,并且只在训练的过程中使用,因此不会增加模型预测的时间损耗。并且标签关系越复杂,预测准确率提升越明显。
猜你喜欢
模式识别与人工智能(2022年9期)2022-10-17
北京航空航天大学学报(2022年8期)2022-08-31
中国典型病例大全(2022年13期)2022-05-10
计算机研究与发展(2022年1期)2022-01-19
中华养生保健(2021年18期)2021-02-13
航天工业管理(2020年9期)2020-12-28
廉政瞭望(2019年5期)2019-06-10
长江学术(2016年4期)2016-03-11
文苑(2015年9期)2015-09-10
长江学术(2015年1期)2015-02-27
