
基于多度量融合的微博转发行为预测方法
2022-06-07 06:14张中军张少辉张文娟
山西大学学报(自然科学版) 2022年2期
张中军 ,张少辉,张文娟
(1.周口师范学院 计算机科学与技术学院,河南 周口 466001;2.农产品质量安全追溯技术河南省工程实验室,河南 周口 466001;3.郑州大学 信息工程学院,河南 郑州 450000)
0 引言
转发微博是微博用户的主要活动,随着微博用户的增多和活跃度的提高,各类信息在微博社交网络中传播,成为重要的信息传播机制,微博用户转发行为预测主要是获得用户转发特定微博的行为发生的概率,精确掌握微博用户信息传播路径,这对于阻断网络谣言传播和舆情监测有重要作用。对社交网络的研究与分析,主要是用户在社交网络中的行为和社交网络对用户行为的影响,其中,信息转发传播就是受复杂因素影响的社交网络行为[1-2]。
用户在社交网络中的活动以浏览或发布微博为主,所以用户行为与微博内容或微博内容潜在的情感相关。Nesi等[3-5]使用离散时间方法分析不同时间段参与主题的用户数量,获得主题发展变化的趋势,动态感知热点话题;王绍卿等[6]提出联合概率模型,把用户之间的多重信任关系融入传统的贝叶斯Poisson因子分解模型,可以灵活地捕获用户之间的各种社交影响,从而预测转发行为;用户对微博的转发意味着用户对微博内容的关注,微博内容是决定用户是否转发的关键因素之一,Firdaus等[7]基于微博内容进行深层分析,挖掘微博内容相关的情感和情绪,在不同的情感层次上发现用户对不同主题的偏好,继而探讨用户的主题特定情绪对其转发决策的影响,证明了微博内容潜在的情感也是用户转发决策的一个重要因素。
用户的社交网络行为受多种复杂因素影响,用户的转发决策也不仅仅依赖于微博的内容或者情感。Chen等[8]从内容语义、用户扩散行为和网络结构三个维度生成各种特征,提出新的集成学习方法预测转发行为;Fu等[9-10]抽取影响微博转发的特征集,如用户特征、网络结构特征、互动行为、用户转发率、交互频率等,结合多种因素来度量用户历史行为模式和用户影响力对用户转发行为的影响;Zhang等[11-12]将用户社会影响力整合到转发预测模型中,共同提高预测性能;Kadhom等[13]发现用户转发行为与其他用户转发行为具有相关性,即用户之间的相关度对用户转发行为有一定的影响。Li等[14]通过分析影响微博用户转发行为的多种特征因素,建立了微博用户转发行为的预测模型,然后根据交互时间和用户关系的拓扑结构计算用户的影响,确定转发关键路径;Zou等[15]采用PCA算法对网络信息数据进行精确分析,通过对社交网络信息传播的建模和正向预测,获得网络信息传播的趋势和规律。除此之外,社交网络社区结构在用户的转发行为预测中也有重要的作用。Hoang等[16-17]发现用户所属社区结构对用户转发行为产生影响,并在转发行为预测中加以应用;Li等[18]挖掘用户潜在社区,分析外部社区驱动效应和内部社区驱动效应,采用概率图模型对转发行为进行建模,预测转发行为。Yin等[19]将用户浏览和转发的微博行为成功应用于COVID-19的舆论趋势分析,能准确预测重大新闻事件的发生。
现有的微博社交网络转发行为预测方法多数依赖于对微博正文的挖掘,以此来分析用户的兴趣或情感,通过对兴趣或情感的衡量预测转发行为,有些方法过于强调社交网络结构的影响,用网络结构紧密度来预测用户之间转发行为,都忽略了用户本身的行为习惯和用户之间的行为相关性,即用户行为对其他用户行为的影响。本文利用网络爬虫获取某时间段内的新浪微博数据并提取用户微博特征,设计了转发行为习惯度、历史微博认同度、微博内容相似度和转发行为相似度计算方法,并综合多种度量标准预测用户转发行为,避免了衡量标准的片面性和对网络结构的过度依赖。
1 转发行为预测方法
微博社交网络由用户作为网络节点、用户之间的关注关系作为网络连边,现实情况下,用户之间的关注关系具有方向性,所以,微博社交网络中的边为有向边,微博社交网络可以看成一个有向图D=<V,E>,其中V是D中的节点集,E是有向边的集合,E中的每一个元素均是序偶<u,v>。
1.1 转发行为习惯度
用户发布微博数量中转发的微博所占的比例反映用户在社交网络微博活动中更可能发生转发行为还是原创发布行为,这个比例本文称之为转发行为习惯度,转发行为习惯度越高,说明用户更习惯于转发别人的微博,否则,说明用户更习惯于发布原创微博。用户i的转发行为习惯度计算公式如下:

其中,Focusi表示用户i关注的所有用户节点的集合,nk→i表示用户i从用户k转发的微博数量,Ni表示用户i发布的微博总数,包括转发和原创微博。
1.2 历史微博认同度
用户转发其他用户微博,可以认为是对其所发布微博的观点和内容的认同。如果用户j的微博被用户i转发数量较多,那么可以合理地认为用户i对用户j的认同是稳定的,用户j再次发布的微博被用户i转发的可能性更大。所以,本文采用用户i转发用户j微博的频率Pj→i来衡量用户i对用户j历史微博的认同度,即用户j发布的微博被用户i转发的比例,计算公式如下:
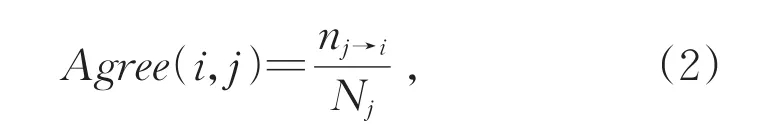
其中,nj→i表示用户 i转发用户 j的微博数量,Nj表示用户j发布的微博总数。
1.3 微博内容相似度
用户发布的微博内容能反映用户的兴趣偏好,可以分析用户近期微博内容获得该用户的兴趣偏好,根据待预测微博与该用户历史微博的相似性来衡量用户转发该微博的可能性,如果待预测微博与该用户历史微博内容高度相似,那么该用户转发行为发生概率较大。事实上,用户的兴趣偏好容易随着时间的推移发生变化,所以久远的历史微博记录只能代表用户以前的兴趣。本文只对用户近期发表的微博以及转发的微博内容进行分析,既能减少数据处理开销,也能保证用户兴趣挖掘的精确性。
文中收集用户近三个月的微博内容数据,对需要计算内容相似度的用户ui的历史微博数据和uj的待预测微博,使用NLPIR汉语分词系统对相应微博数据进行分词,得到总的词汇列表 L={t1,t2,…,tn},tk为所分析微博数据中出现的词汇,n表示总的词语数,然后对L中每个词语计算TF-IDF值,记作tdi:

其中,qi表示词语ti在总微博样本中出现的次数,n代表总词语数量,|D|表示总的微博数量,|{d∶ti∈d}|表示含有词语 ti的微博数量。对于用户ui历史微博数据和uj的待预测微博数据,根据微博词语的TF-IDF值分别用向量表示为Vui和Vuj,那么微博内容相似度可以使用其向量余弦值表示:

其中:Vui·VTuj是Vui和Vuj两者的点积,分母中分别表示Vui和Vuj的欧几里得范数。
1.4 转发行为相似度
微博内容相同或相似的用户之间具有相同的兴趣爱好,转发行为发生的可能性较大,但是,根据对微博数据的分析发现,用户转发的微博与其历史微博内容毫无相关性的现象也时常存在,这种转发行为反映出用户之间观点的相似性。本文使用用户转发行为相似性来衡量用户之间观点的相似性,如果两个用户转发第三个用户微博的比例、被第三个用户转发的比例较大,则认为两者观点高度相似,那么这类用户之间发生转发行为的可能性也较大。用户i与用户j的转发行为相似度可以通过用户i,j从所有共同关注节点的转发比例的平均值以及被所有共同粉丝节点转发的比例平均值来计算,公式如下:
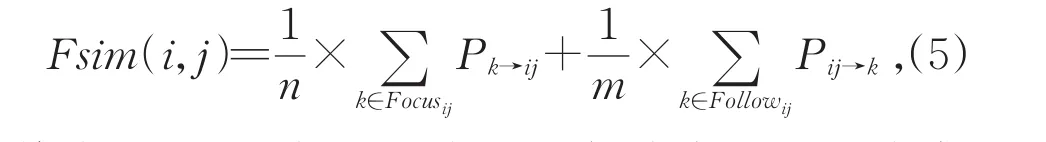
其中,Focusij表示节点i,j共同关注的节点集合;Followij表示节点i,j共同粉丝节点集合;n表示节点i,j共同关注的节点个数;m表示节点i,j共 同 粉 丝 节 点 个 数 。 pk→ij=Agree(i,k)×Agree(j,k)表示用户i和j转发k的微博比例,pij→k=Agree(k,i)×Agree(k,j)表 示 用 户 k 转 发用户i和用户j的微博比例。
1.5 用户转发行为预测
用户转发行为预测就是根据上述多个度量综合判断转发行为发生的可能性。用户i对用户j发布的微博发生转发行为的概率就是通过用户i的转发行为习惯度、用户i对用户j的历史微博认同度、用户j所发微博与用户i近期微博内容的相似度以及两者转发行为相似度综合衡量。为防止单项为0时对结果造成的影响,对各度量做简单变换,用户i对用户j发布的微博转发行为发生的概率计算公式如下:

其中,系数Eij表示在微博社交网络拓扑结构中节点i到节点j是否存在连边,存在连边为1,否则为0。节点i到节点j存在连边,说明用户i关注了用户j,用户j所发布的微博对用户i可见,可能被用户i转发,否则,不可能发生转发行为,即转发概率为零。在转发行为预测时,当满足Retweet(i,j)≥θ时,则认为会发生转发行为,否则,认为不转发。用户转发行为预测过程如图1所示。
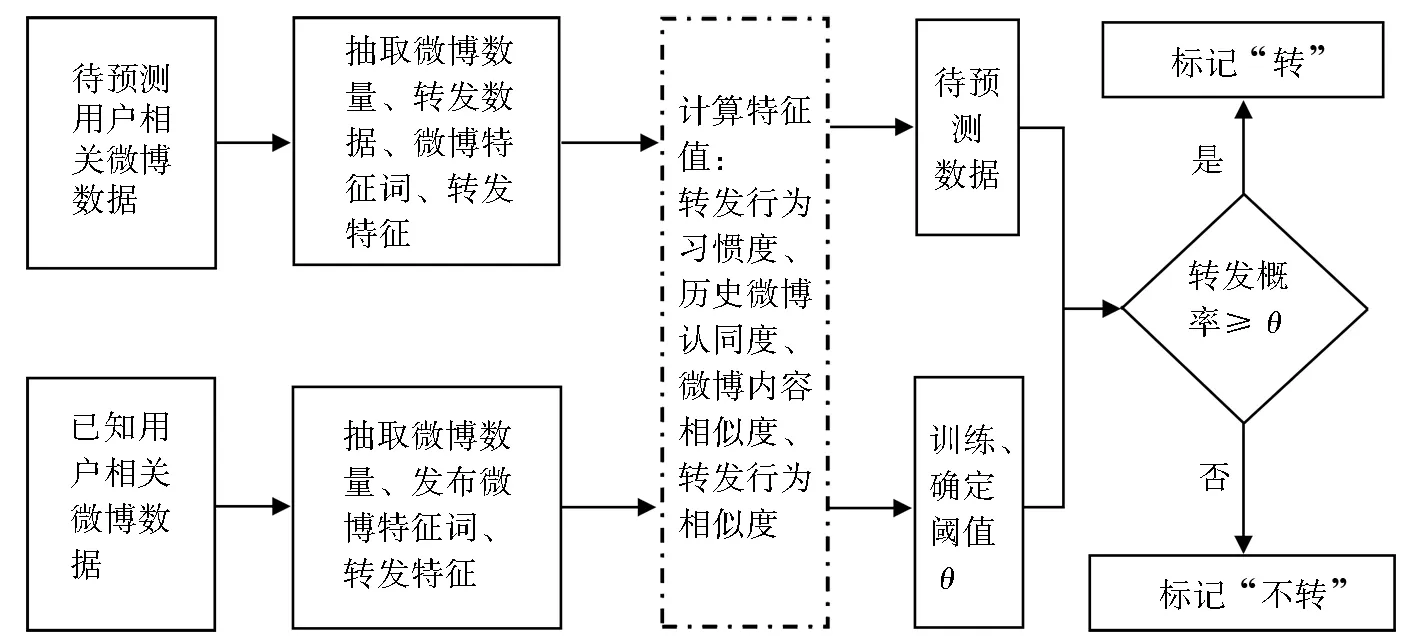
图1 用户转发行为预测过程Fig.1 Prediction process of user retweet behavior
在上面的过程中,分为特征提取及相似度计算阶段、训练阶段和预测阶段。在特征提取及相似度计算阶段中,转发行为相似度的计算主要提取待预测用户发布微博的总量和其中的转发数量;历史微博认同度的计算主要提取已知用户发布微博的总量和被待预测用户转发的数量;微博内容相似度的计算主要获得已知用户所发新微博与待预测用户兴趣的契合度;转发行为相似度主要提取两者对共同关注的用户微博的转发行为和第三方对两者微博的转发行为。训练阶段主要是利用训练数据集确定阈值θ的值。转发行为预测阶段则可以看作分类问题,结果只有转发或不转发两类。本文微博转发行为预测算法MRBP-MMF(Microblog retweet behavior prediction method based on multiple metrics fusion)伪代码如下:

2 实验及结果分析
2.1 实验数据
本文所用实验数据采集于新浪微博平台,数据包括微博用户及关注关系、发布微博的时间、内容(包括原创与转发内容)、是否转发、评论及点赞等信息。由于在微博社交网络中存在大量僵尸用户等噪声数据,直接影响实验结果,所以实验前对数据进行清洗,去除在指定时间窗口内从未发布或转发过任何微博的无效用户,保留73 508个用户和1 054 563条关注关系、8 032 649条微博,其中转发微博1 296 254条、原创微博6 736 395条,形成实验数据集。后面将针对本文提出的基于多度量融合的微博转发行为预测方法(MRBP-MMF)进行反复实验,以测试算法的有效性。
2.2 评价标准
对于分类问题,衡量准确性的评价方法常选用信息检索的评价指标:查准率、查全率和F1值。微博转发预测结果只有转发或不转发,故可看作二分类问题,可用分类评价指标衡量,在微博转发预测中,查准率(precision)等于正确预测为“被转发”的数量与所有预测为“被转发”的数量的比值,查全率(recall),也称灵敏度,等于正确预测为“被转发”的数量与实际“被转发”的总量的比值。
查准率和查全率容易被极端情况影响,F1度量是可以用来同时描述查准率和查全率的一个综合指标,计算公式如下:

对于微博转发行为研究的应用,比如网络谣言传播的预测,目的是尽可能准确预测到要发生的转发行为,所以,下面实验中转发行为预测结果主要用F1值和灵敏度来衡量,灵敏度高,说明能发现更多的转发行为。
2.3 实验结果分析
针对本文提出的MRBP-MMF方法设计实验以验证算法在转发行为预测中的效果,首先进行消融实验,即转发预测模型中只保留微博内容相似度单一特征,这也是早期转发预测研究采用的方法(下文称为MRBP)。然后将本文MRBP-MMF算法与经典的朴素贝叶斯和支持向量机分类算法以及PM3[7]和RBMHDRN转发预测算法[8]进行对比实验。在实验中,采用K折交叉验证方法验证在不同规模训练数据下各算法的预测效果。K折交叉验证是数据分类中常用的测试方法,它将实验数据随机分成K份,依次将其中K-1份作为训练数据集,剩余1份作为测试数据,将K次执行的结果的平均值作为算法的执行的结果,在本文实验中,K从2到10依次取值。
图2是MRBP-MMF方法与消融后的MRBP方法K折交叉验证结果的F1值,从图中可以看出,本文的MRBP-MMF方法的预测结果F1值整体上明显优于MRBP方法,并且随着训练数据的增多,MRBP-MMF的预测结果F1值大幅升高,整体提高了约16%,相比而言,MRBP的预测结果的F1值整体偏低,虽有提高,但增幅较小,并且在K取值为8之后,预测结果没有明显提高。图3是消融前后灵敏度对比,图中显示,MRBP-MMF灵敏度远远高于消融后的MRBP方法,并且整体来看,MRBP方法的灵敏度随着训练数据增加,并没有明显提高,甚至有下降现象。实验表明,相对于单一特征,多度量融合的方法在训练数据较少的情况下,能够取得更好的预测效果,并且随训练数据规模的逐步增大,预测效果明显提高。总体来讲,MRBP-MMF方法对用户转发行为的预测灵敏度比消融后平均高出12%。此实验结果的产生,原因在于MRBP方法采用微博内容相似度单一特征来判断用户转发行为发生的可能性,忽略了用户在微博社交网络行为中转发别人微博的习惯、对关注对象的认同等现实因素,甚至训练数据较多时却导致训练结果过度依赖微博内容,反而灵敏度下降,所以,多度量融合的MRBP-MMF方法能够取得更好的结果。

图2 消融前后预测结果F1值对比Fig.2 Comparison of F1 values before and after fusion
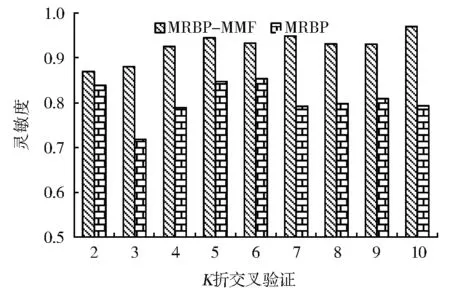
图3 消融前后灵敏度对比Fig.3 Comparison of sensitivity before and after fusion
Naive Bayes算法和SVM算法都是经典的分类算法。下面将两种分类算法用于转发行为预测,并将预测结果与MRBP-MMF方法对比。图4是三者预测结果的F1值对比,从图中可以看出,MRBP-MMF的预测结果F1值均明显高于Naive Bayes算法和SVM算法,在2折交叉验证实验时,MRBP-MMF与Naive Bayes、SVM相比,预测结果F1值相差较小,随着训练数据的增多,预测结果F1值差距逐渐增大,在10折交叉验证实验中,本文MRBP-MMF预测结果F1值相比Naive Bayes和SVM分别高出约0.09和0.12,并且两种分类算法的预测结果F1值增幅较小。图5是三者灵敏度对比,显然,MRBPMMF灵敏度高于两种分类算法,并呈上升趋势,而Naive Bayes算法和SVM算法灵敏度上升之后出现下降,整体较低。实验表明,与Naive Bayes和SVM相比,在训练数据较少的情况下,本文MRBP-MMF方法能够获得更高的预测效果,并且随训练数据规模的逐步增大,其预测效果有更大的提升。产生此实验结果的原因在于传统的Naive Bayes和SVM算法主要用于分类,特别是文本分类,虽然微博用户转发行为预测可以视为分类问题,但传统的经典分类方法并不适应于社交网络数据。MRBP-MMF方法充分考虑了用户转发行为相似度和转发习惯,所以在转发行为预测方面表现出了更好的效果。
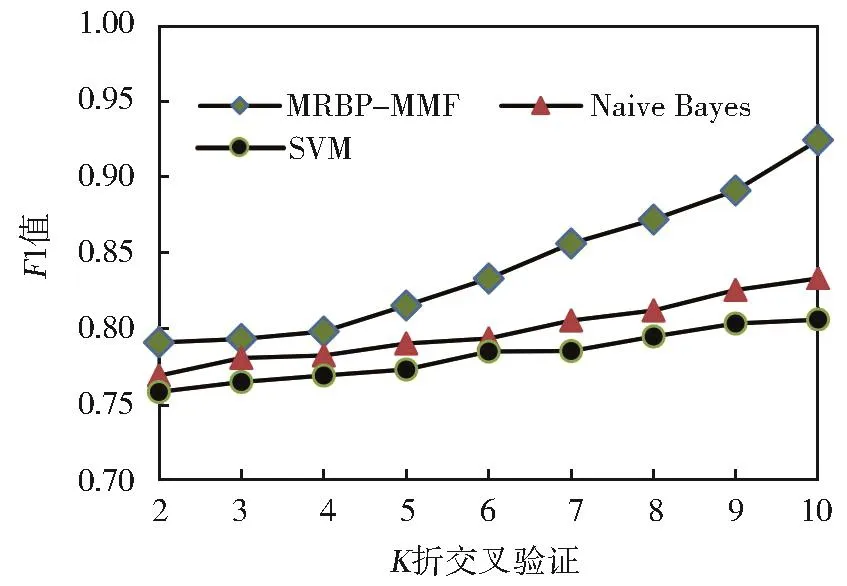
图4 与Naive Bayes和SVM预测结果F1值对比Fig.4 Comparison of F1 with Naive Bayes and SVM

图5 与Naive Bayes和SVM灵敏度对比Fig.5 Comparison of sensitivity with Naive Bayes and SVM
PM3算法和RBMHDRN算法均与传统分类方法不同,PM3算法是针对社交网络转发行为预测而设计的一种强调用户情感因素的方法,重点研究内容包含情感和情绪对转发决策的影响,而RBMHDRN算法与本文MRBP-MMF方法类似,集成多种特征实现转发预测,但抽取的特征有所不同。
图6是MRBP-MMF方法与PM3算法、RBMHDRN算法预测结果的F1值对比,图中显示,MRBP-MMF的预测结果F1值均高于PM3算法,针对不同规模的训练数据实验,多数预测结果的F1值略高于RBMHDRN算法,偶尔略低于RBMHDRN算法,但差距不大,并且训练数据量少的情况下,MRBP-MMF方法较优。图7是三者灵敏度对比,MRBP-MMF的灵敏度明显高于PM3算法,与RBMHDRN算法相比,MRBP-MMF灵敏度多数情况下略高,偶尔略低,整体相差不大,在训练数据增多的情况下,RBMHDRN算法灵敏度较优。总体来讲,MRBP-MMF方法转发行为预测灵敏度分别比PM3和RBMHDRN平均高出4%和0.7%。

图6 转发行为预测算法预测结果F1值对比Fig.6 Comparison of F1 with other algorithms

图7 转发行为预测算法灵敏度对比Fig.7 Comparison of sensitivity of MRBP-MMF with that of PM3 and RBMHDRN
实验表明,在训练数据较少的情况下,本文提出的MRBP-MMF方法能够获得更高的准确性和灵敏度,并且随训练数据规模的逐步增大,均有所提高,同样,PM3算法预测结果F1值也有提升,说明对用户情感和情绪的挖掘有助于转发行为的预测。实际上,情感词所反映的用户情感是多样的,比如,“哭”可能代表伤心,也可能代表开心或恐惧,所以,转发行为预测不能完全依赖于用户情感,MRBP-MMF方法综合多种衡量标准,更能取得稳定的预测结果。
3 结论
本文提出一种基于多度量融合的微博转发行为预测方法,综合考虑了用户转发习惯度、内容相似度、转发行为相似度等多种度量标准,实验证明本文算法取得了较好的预测结果。但是,预测方法还需要进一步的研究探讨,比如,转发时间的预测,能进一步确定用户在什么时间转发微博将有更重要的意义。下一步工作的重点是深入分析用户转发时间规律,结合最新技术,设计转发时间预测模型,进一步细化用户转发行为预测结果。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
矿业安全与环保(2022年2期)2022-05-20
中学生数理化·高二版(2022年4期)2022-05-09
意林彩版(2022年2期)2022-05-03
北京航空航天大学学报(2021年4期)2021-11-24
好日子(2021年8期)2021-11-04
第一财经(2020年4期)2020-04-14
文苑(2018年17期)2018-11-09
