
基于注意力机制的深度循环神经网络的语音情感识别
2022-06-02 14:41蒯红权吴建华
电子器件 2022年1期
蒯红权 ,吴建华 ,吴 亮
(1.盐城市经贸高级职业学校实训处,江苏 盐城 224041;2.东南大学信息科学与工程学院,江苏 南京 210096)
情感识别是人工智能未来的研究方向之一。在许多业务场景中,利用人工智能准确地提取并利用对象的情感信息对于业务质量的提高有着重大意义。语言作为人类交流最原始,最重要的方式之一,不仅携带有语义信息,还携带着大量情感信息[1]。因此,语音情感识别问题正受到越来越广泛的关注。
近年来,伴随着硬件性能的提升带来的计算机计算资源的爆炸性增加,深度学习在许多机器学习任务上取得了巨大的成功,成为了机器学习最受关注的分支。在其他领域取得成功之后,深度学习也被应用到了语音情感识别任务中,并取得了比传统机器学习方法更好的效果。
传统的语音情感识别算法分为特征提取与特征分类两个步骤。首先需要对语音信号分帧,逐帧提取短时声学特征,例如梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient,MFCC)等,再从这些短时特征中提取长时特征,最后将长时特征输入分类器[2]。虽然深度学习技术的出现使以原始信号(或其FFT 谱)作为输入进行end-to-end(端到端)的语音情感识别得以实现[3],但实验结果表明,由于目前语音情感识别领域缺少大规模数据作为训练样本,以手动提取的传统声学特征作为模型的输入仍然比以原始数据作为输入更容易取得更好的性能[2],所以传统声学特征仍然被广泛应用于语音识别问题。
因为语音信号是一种典型的时序信号,所以专门用于处理序列数据的RNN(Ruccurent Neural Network,循环神经网络)是语音情感识别任务中最常用的一类深度学习模型。此外,CNN(Convolutional Neural Network)的应用也较为常见。自RNN 诞生以来,产生了许多变体,其中最具代表性,也最为常用的模型是LSTM(Long Short Term Memory)[4]。目前大部分序列模型中采用的都是LSTM 或其变体GRU(Gated Recurrent Unit,门控循环单元),而非传统RNN,在语音情感识别任务中也是如此。此外,相比于单向LSTM,双向LSTM 在语音情感识别任务中的应用要广泛得多。
近年来,注意力模型在机器翻译等NLP(Natrual Language Processing,自然语言处理)领域取得了巨大成功。之后,这一技术被迁移到了语音情感识别任务中。研究者将注意力机制加入了传统的CNN[5-6]和RNN[2,7],证明了注意力机制能够有效提高语音情感识别算法的性能。其中,文献[2]将注意力模型应用于双向LSTM 层的输出,在时间维度对LSTM 的输出序列进行了加权平均,得到一个特征向量,再从该向量得到最终的分类结果,该模型在IEMOCAP 数据集上取得了比传统方法高1%~2%的识别性能。
对于一些复杂问题,由于单层RNN 难以取得足够高的性能,往往需要使用深度RNN。由于上述注意力模型的输出并非一个序列,因此其只能应用于最后一层RNN 的输出,而不能应用于多个RNN 层之间,无法与深度RNN 紧密结合。所以本文基于传统的注意力机制,提出了分段注意力机制,并将其应用于深度RNN 网络中,提出了一个基于分段注意力的新型深度RNN 模型。该模型两个LSTM 层之间加入了一个改进的注意力机制,在时间维度上将前一级LSTM 层的输出序列分割为若干区间,在每个区间内进行一个基于注意力机制的加权池化,以将该序列映射为一个较短的序列,作为下一级LSTM 层的输入。我们使用36 个短时特征作为输入,在CASIA 数据集上对该模型进行了实验,并将其与基于普通注意力机制的单层LSTM 与双层LSTM 的性能进行了对比,实验结果表明,该模型在CASIA 数据集上取得的识别性能比普通的双层LSTM 模型高出了1%~2%,比普通的单层LSTM 高出了约5%。并且训练速度比普通双层LSTM 模型高出约50%,略高于普通单层LSTM。
1 基于分段注意力机制的循环神经网络模型
RNN 是一类以序列数据作为输入的神经网络,特别适用于语音,文本等时序信息的分析。对RNN的研究始于20 世纪80—90 年代,并逐步发展为深度学习的主要模型之一。其中,目前最常见的循环神经网络结构是LSTM,是为了解决传统RNN 存在的长期依赖问题而产生的。由于其独特的结构,LSTM 擅长分析时间序列中间隔和延迟非常长的重要事件。
大多数情况下而言,序列的不同部分并非同等重要。为了更加高效地提取出有用信息,算法应该更着重于分析序列中更加重要的部分。然而,对于一般的RNN,输入序列中各个元素具有相同权重,其不具备重点关注序列中特定部分的能力。而且,除了RNN之外,CNN 等其他模型也同样具有这一不足,因此,近年来有关学者提出了注意力机制,用于帮助模型关注数据中更加重要的部分。
受到图像处理领域SIFT 算法中高斯金字塔的启发,本文提出了一种基于分段注意力机制的循环神经网络模型,其结构如图1 所示。
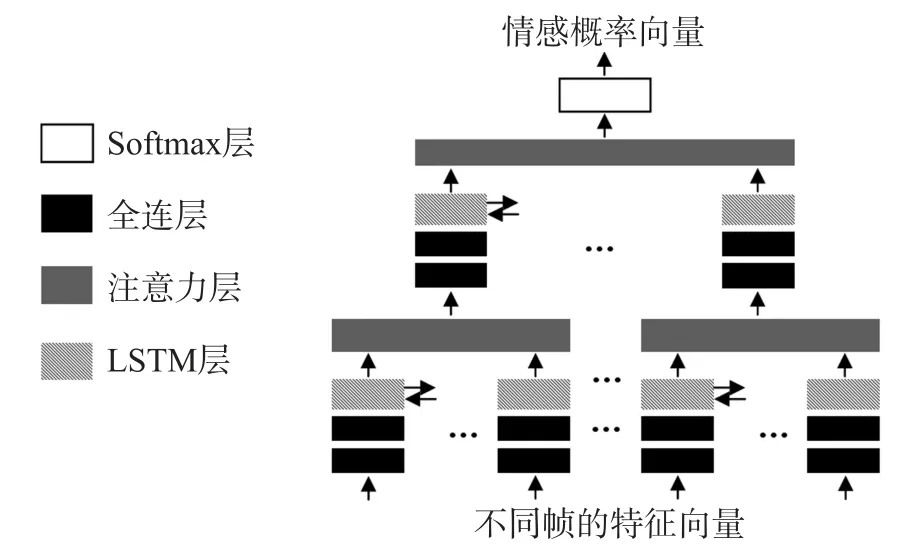
图1 基于分段注意力机制的深度RNN 模型
模型的输入为二维张量,两个维度分别为特征和时间。假设输入样本被分为T个时间片,对每一个时间片提取D维特征,则输入张量大小为D×T,各个时间片的特征向量依次存放在张量的每一列。首先,输入张量依次通过全连接层和双向LSTM 层,得到一个新的二维张量。然后,该张量从时间维度被切割为多个片段,每个片段分别通过一个注意力层,映射为一个特征向量,每个时间片的输出经过组合后又得到新的二维张量。这个操作相当于进行了一次池化,假设每个时间片的长度为L,则池化大小为1×L,输出张量大小为D×(T/L)。最后,池化结果依次通过双向LSTM 层,注意力层和Softmax 层,映射为概率向量。
该模型结构能够对时序信息进行层次化的分析,第一级LSTM 和注意力层用于对局部的特征进行提取,第二级LSTM 和注意力层用于全局特征的提取。
1.1 注意力机制
图2 为本文采用的注意力机制的原理示意图。对于每一帧,我们计算LSTM 的输出yt与向量u的内积,记为pt:
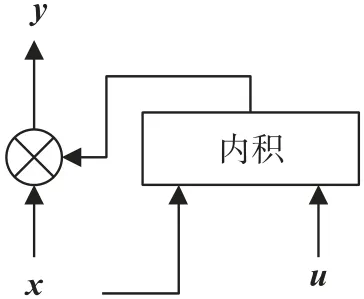
图2 注意力机制的一种实现

式中:u是一个可训练的向量。接下来,我们计算pt的Softmax 函数:

αt可理解为该帧输出相对于最终输出的权重。利用权重向量α对LSTM 的输出进行加权求和,得到最终的输出向量:
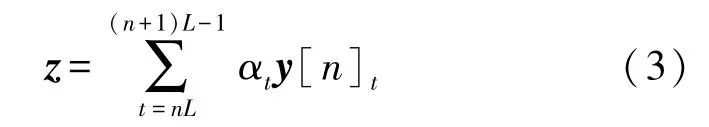
将该向量作为分类器的输入即可得到分类概率。
1.2 分段注意力机制
首先,和1.1 节类似,利用公式(1),计算LSTM每一帧的输出yt与向量u的内积pt。接下来,我们首先将LSTM 的输出分割为若干区间。假设共有N个区间,每个区间长度为L,设第n个区间为[nL,(n+1)L-1],在该区间内,我们计算pt的Softmax 函数,作为各帧的权重:

在该区间内利用该权重对LSTM 的输出进行加权求和,得到输出向量:
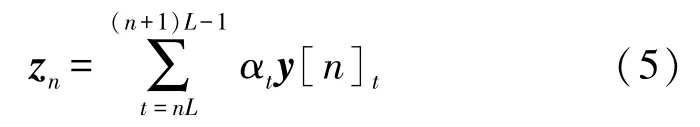
因为共有n个区间,所以分段注意力层将输出一个长度为n的序列z。当n=1 时,即退化为1.1节所述的普通注意力模型。
在我们的模型中,我们将第一层LSTM 的输出,输入分段注意力层,将分段注意力层的输出作为第二层LSTM 的输入,再将第二层LSTM 的输出,输入1.1 节所述的普通注意力层,将其输出,输入Softmax分类器,得到分类概率。
2 实验
为检验模型性能,我们在CASIA 情感数据集上进行了实验。该数据集为中科院自动化研究所建立的数据集,包括高兴,生气,悲伤,惊讶,恐惧和平静6 种情绪,每类1 200 个样本,共7 200 个样本。
首先,我们以25 ms 为帧长,10 ms 为帧移对语音进行分帧,对较短样本补0,对较长样本截去尾部,以将所有样本的长度统一为1 024 帧。接下来,我们在分帧后的语音信号中对每一帧提取36 维短时特征(包括ZCR,energy,energy entropy,spectral centroid,spectral spread,spectral entropy,spectral flux,spectral roll-off,13 阶MFCC,12 阶chroma,chroma 的标准差,harmonic ratio 和pitch),作为模型的输入。
本文采用文献[2]提出的基于注意力机制的RNN 模型作为基线。在该模型中,每帧的数据首先通过全连接层,再通过RNN 层,最后利用注意力模型对RNN 层的输出进行加权池化[2],将池化结果通过Softmax 层,得到分类概率。在本文的实验中,我们采用了2 层全连层,每层512 个神经元,激活函数为ReLU 函数;RNN 层采用的是64 个神经元的双向LSTM,为了证明深度RNN 能够取得比普通RNN 更好的性能,我们对于使用一层LSTM 和两层LSTM的情况分别进行了实验;注意力模型采用1.1 节所述模型。训练时对每层均采用0.5 的dropout 率。
本文提出的模型即在上述基线模型基础上在两个LSTM 层之间加入了一个1.2 节所述的分段注意力模型,以16 帧为单位对第一层LSTM 的输出进行分段注意力池化。模型的其余参数与上述基线模型相同。
我们对每个模型都进行了多次实验,表1 列出了各模型取得的最高准确率(weighted accuracy,WA),最低准确率,以及平均准确率。因为该数据集各类别样本数是平衡的,所以UA(unweighted accuracy)和WA 是相同的。

表1 各模型的准确率
表1 中的结果表明,采用双层LSTM 的模型性能比采用单层LSTM 的模型更好。这说明深度RNN的确能够取得比单层RNN 更好的性能。在两层LSTM 之间加入了分段注意力机制后,模型识别率提高了约1.5%。
同时,我们也比较了三个模型的训练速度。实验采用的深度学习框架为Tensorflow 1.13.1,利用Nvidia RTX2070 GPU 进行加速。训练时采用的batch 大小为128,采用Adam 优化算法进行训练,初始学习率为0.001,在验证集损失函数连续10 步没有下降时将学习率降低0.5 倍。在验证集识别率连续20 步没有提高时终止训练。表2 列出了各模型的训练时间,表3列出了各模型训练过程中识别率的变化。从结果可以看出,在两个LSTM 层之间加入分段注意力机制之后,虽然模型参数变多了,但模型收敛速度却提高了约100%,甚至相比单层LSTM 也要略高。原因是分段注意力机制缩短了第二层LSTM 输入序列的长度,而RNN 训练速度主要取决于输入序列的长度。

表2 各模型收敛时间
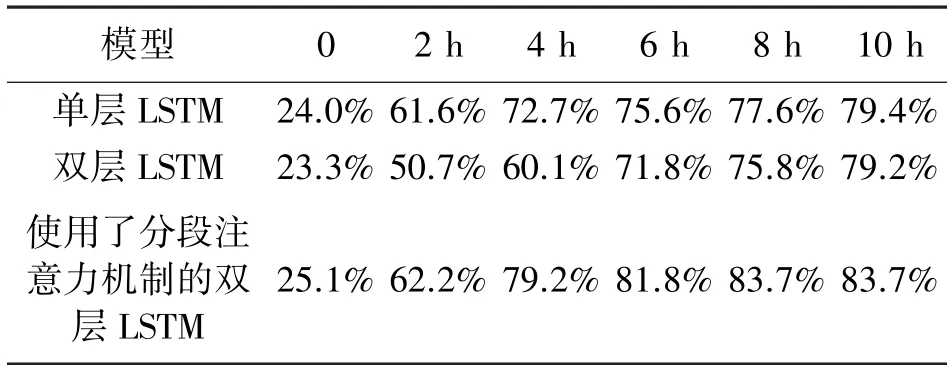
表3 各模型训练过程中识别率的变化
3 总结
为了将注意力模型与深度RNN 紧密结合,本文对传统的注意力机制进行了推广,提出了分段注意力机制,并提出了基于该机制的深度RNN 模型。该模型中,上一级RNN 层的输出序列首先被分段,对于每一段都进行注意力加权池化,以此将前级RNN输出的较长序列映射为较短的序列作为后级RNN的输入。本文在CASIA 情感数据集上进行了实验,实验结果证明,深度RNN 能够取得比单层RNN 更好的性能;在引入分段注意力机制后,模型性能获得了进一步提升,且模型的训练速度获得了大幅提高。
猜你喜欢
计算机应用(2022年9期)2022-09-25
软件导刊(2022年3期)2022-03-25
西南师范大学学报(自然科学版)(2022年1期)2022-03-02
华南师范大学学报(自然科学版)(2021年3期)2021-07-03
五邑大学学报(自然科学版)(2020年4期)2020-12-09
数学小灵通·3-4年级(2020年4期)2020-06-24
杭州电子科技大学学报(自然科学版)(2020年1期)2020-04-09
计算机技术与发展(2019年1期)2019-01-21
小学生学习指导(低年级)(2018年11期)2018-12-03
智能计算机与应用(2018年2期)2018-05-23
