
基于Transformer的中英机器翻译系统的研究与开发
2022-05-30 07:37:51晁忠涛叶传奇韩雪磊朱奎源吴明利张留杰
电脑知识与技术 2022年27期
晁忠涛 叶传奇 韩雪磊 朱奎源 吴明利 张留杰
摘要:随着经济全球化和信息全球化的不断发展,翻译服务的重要性也随之提高,机器翻译相较于人工翻译,成本更低,速度更快,也因此更适应当今时代的需求。神经机器翻译技术使用深度学习方法在平行语料上进行训练并获得翻译模型,已经成为当前主流的机器翻译方法[1]。文章基于Transformer翻译模型开发了一款中英文翻译系统。结果表明,与其他翻译模型相比, 文章提出的中英机器翻译系统在语句的通顺程度和语意的准确性方面均有提升。
关键词:人工智能;机器翻译;Transformer;深度学习
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2022)27-0016-02
开放科学(资源服务)标识码(OSID):
1 概述
当今社会是经济全球化和信息全球化的社会,智能化的翻译服务成为一大研究热点。现如今社会上出现了各种各样的中英翻译软件,但是普遍存在语句不顺、语法错误及语意生硬等问题。本文针对这些问题研究并开发了以Transformer为翻译模型的中英机器翻译系统。
中英机器翻译系统主要针对的是日常生活或学生学习过程中出现的中译英问题,本系统采用的Transformer翻译模型是一种可以完成机器翻译等序列到序列学习任务的一种全新网络结构,该结构采用Self-Attention注意力机制实现序列到序列的建模。相较于其他翻译模型中广泛应用的循环神经网络,该机制具有计算复杂度小、计算并行度高和容易学习长距离依赖等优势,因此该翻译系统具有一定的开发意义和实用价值。
2 开发技术
2.1 机器翻译
机器翻译,又称自动翻译,是利用计算机程序将一种自然语言(源语言)转换为另一种自然语言(目标语言)的过程,它是人工智能的重要研究目标之一,具有非常重要的科学研究价值。同时,机器翻译又具有十分重要的实用价值,随着经济全球化以及互联网的发展,机器翻译技术在促进政治、经济和文化交流方面起着越来越重要的作用。
机器翻译主要分为预处理、翻译模型和后处理三个步骤,预处理是将输入的语言转变为机器能够理解的数据,翻译模型是将源语言转化为目标语言的过程,后处理是指将翻译后的结果进行重新拼接、排序等操作得到符合人们阅读习惯的翻译结果的过程。随着计算机计算能力的提升和多语言信息的爆发式增长,机器翻译技术逐渐走出象牙塔,开始为普通用户提供实时便捷的翻译服务[2]。
3 主要技术
3.1 Jieba+BPE分词技术
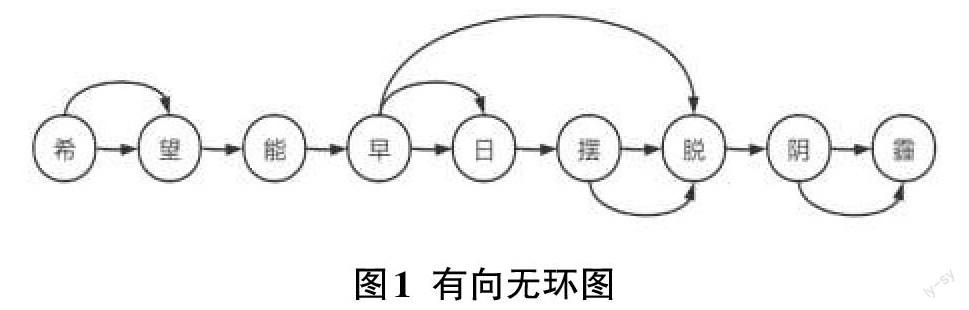
数据预处理过程中需要对中文进行Jieba+BPE分词处理,对英文进行BPE处理。Jieba分词是一款非常流行的中文开源分词包,具有高性能、准确率、可扩展性等特点。Jieba分词主要通过词典进行分词,其主要基于有向无环图的查找算法,通过动态规划,从后至前使得词的切割组合联合概率最大[3]。下面以“希望能早日摆脱阴霾”为例,假设词典如下“‘希望‘能‘早日‘摆脱‘早日摆脱‘阴霾”,则有向无环图如图1所示。
经过Jieba分词后的语句格式为“希望 能 早日 摆脱 阴霾”。
BPE分词算法是一種根据字节对进行编码的算法,主要目的是数据压缩,在一定程度上缓解了OOC的问题。BPE的算法思想是首先对大量训练语料按字符拆分进行组pair,然后对byte pair进行统计后按频率进行排名,接下来按照byte pair的频率大小对输入的语句进行分词处理,出现频率高的byte pair将会被组合到一起。Jieba和BPE结合对数据进行预处理用来为之后的翻译工作创造条件。
3.2 Transformer模型
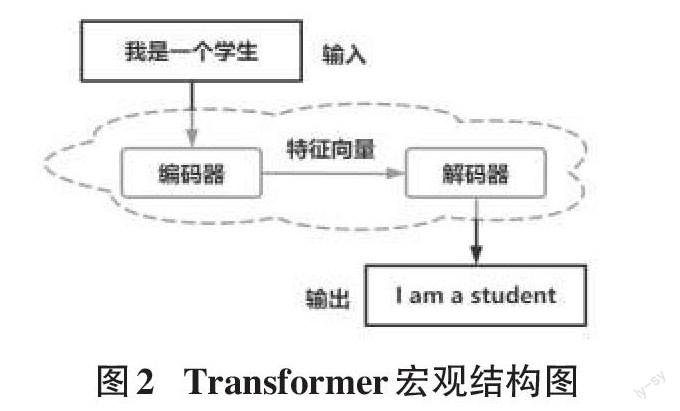
从宏观上看,Transformer像是一个黑盒,向其中输入一种语言,经过黑盒测试后会生成另一种语言。这个黑盒主要由编码器和解码器组成,输入中文语句,经过编码器得到对应的特征向量,然后再把这些特征向量作为解码器的输入,最终生成对应的英文语句。宏观结构如图2所示。
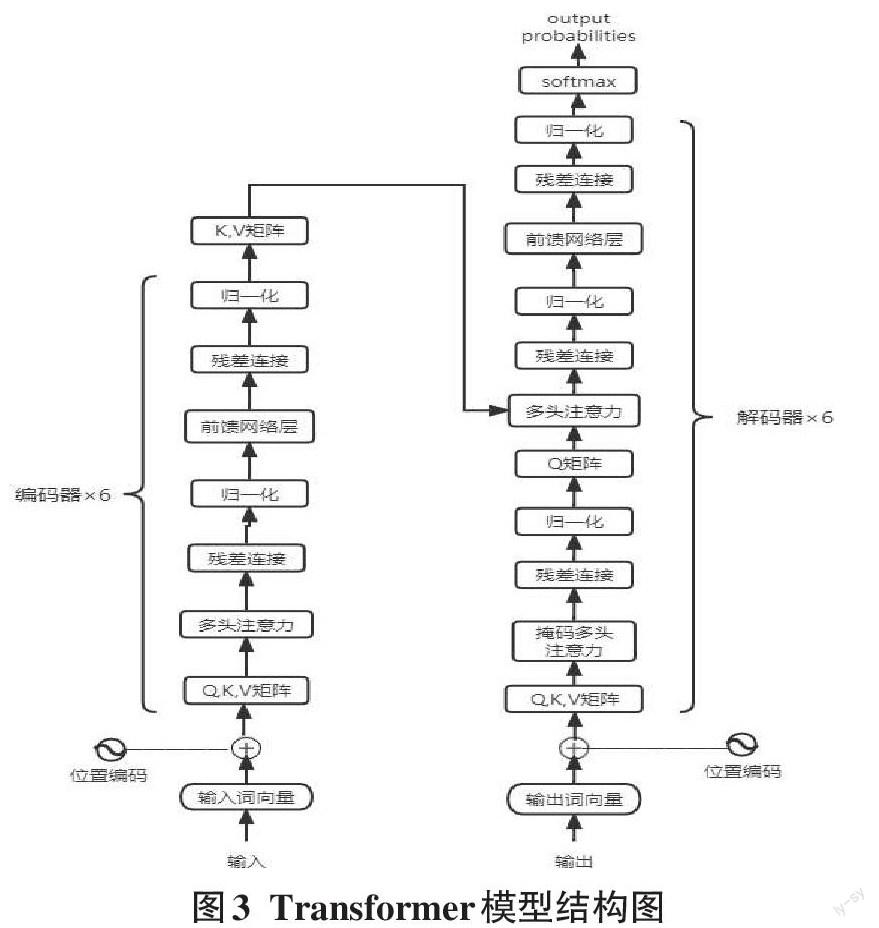
下面对Transformer模型的各个部分进行详细介绍:首先,模型需要对输入的数据进行一个词嵌入操作,词嵌入结束之后,将结果输入到编码器,其中编码器包含两层,一个自注意力层和一个前馈神经网络,并在每一层的网络后引入残差网络和归一化层来防止梯度消失或梯度爆炸,其中自注意力层采用多头注意力机制实现当前节点不仅仅只关注当前的词,从而能获取到上下文的语义,经自注意力层处理完数据后把数据送给前馈神经网络,前馈神经网络的计算可以并行,得到的输出会输入到下一个编码器。将编码器的输出经线性变换后得到的结果作为解码器中多头注意力的输入,解码器中除了包含编码器中的两层网络,还在这两层中间添加了注意力层,用来帮助当前节点获取到目前需要关注的重点内容。经解码器解码后的输出再通过线性变换和softmax得到概率最大的单词的输出向量[4]。其模型结构如图3所示。
通过对不同翻译模型的对比实验可以发现,使用Transformer模型进行翻译具有更好的技术优势。各种翻译模型效率比较如图4所示,其中BLEU值是翻译模型的评价指标,BLEU值越高说明翻译模型的精确度越高。图5是将中文采用Transformer模型翻译得到的英文。
3.3 Flask框架
Flask是一个基于Python开发的轻量级Web框架,小巧,灵活,仅凭一个脚本就可以启动一个Web项目,旨在保持核心功能的简单而易于扩展,一个纯粹的Flask框架只拥有Web框架的基本核心功能,至于其他功能就需要开发者自行扩展。与其他同类型框架相比,Flask框架具有更加灵活、轻便等优点,用户可根据自己的需求添加特定的功能,保证了核心功能简单的同时实现功能的丰富与扩展[5]。
在Web应用的开发过程中,Flask框架不仅可以对后台功能代码进行封装,而且可以通过编写html代码实现前端页面的显示。此外,Flask框架还可以非常简便地实现前端页面与后台功能的交互,既节省了开发者的大量时间和精力,同时也为用户访问后台功能提供了友好型界面。
4 中英机器翻译系统的实现
首先,通过对Transformer模型进行封装,依赖Flask框架搭建后端服务器并设计出面向用户的友好型界面,然后将前台页面和后台服务器进行连接实现前后台的交互功能,为用户提供简单便捷的翻译服务。在使用中英机器翻译系统时,用户可在前台页面输入想要进行翻译的中文文本或直接选择想要翻译
的中文txt文本文件,系统将用户输入的中文语句或文本文件读入到后台的source.ch.txt文本文件中,经过数据预处理依次得到source.ch.cut.txt文件和source.ch.BPE分词文件,之后对分词文件中的数据进行线性变 换后传入到已经训练好的模型中进行预测,预测完成后将翻译结果以文本形式返回到前台页面进行显示。到此,中英机器翻译系统完成翻译工作。工作流程如图6所示:
5 结束语
如今正是经济全球化和信息全球化的时代,翻译服务的重要性不断提高。为了适应社会发展的需求,本文提出了基于Transformer模型的翻译模型进行中英翻译。该模型可以对日常生活中或学生学习过程中遇到的中英文语句进行翻译操作。实验结果表明,基于Transformer的中英机器翻译模型与其他翻译模型相比,有效提升了单词的正确率以及语意的通顺度。此系统在中英翻译方面有着先进的技术优势和广阔的应用前景,可以有效减少中英文翻译带来的压力,对未来社会的发展和进步能够起到一定的推动作用。
参考文献:
[1] 何建树.基于深度学习的神经机器翻译技术研究[D].成都:电子科技大学,2021.
[2] 武俊,趙昌彦.机器翻译技术在外文水资源文献翻译中的应用现状及展望[J].水资源保护,2022,38(2):204-205.
[3] 石凤贵.基于jieba中文分词的中文文本语料预处理模块实现[J].电脑知识与技术,2020,16(14):248-251,257.
[4] 高巍,陈子祥,李大舟,等.预标准化Transformer在乌英机器翻译中的实现[J].小型微型计算机系统,2020,41(11):2286-2291.
[5] 王安瑾.基于Flask的金融自动化运维平台的设计与实现[D].上海:东华大学,2018.
【通联编辑:梁书】
猜你喜欢
商界(2019年12期)2019-01-03 06:59:05
IT经理世界(2018年20期)2018-10-24 02:38:24
小康(2017年16期)2017-06-07 09:00:59
考试周刊(2017年2期)2017-01-19 09:13:50
考试周刊(2017年2期)2017-01-19 09:12:54
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
智富时代(2016年12期)2016-12-01 17:03:10
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
科教导刊·电子版(2016年23期)2016-10-31 10:14:04
