
基于矛盾关系的评教文本反语检测算法
2022-05-27 10:01:30唐宇坤唐熙淳许梦雅
江西师范大学学报(自然科学版) 2022年1期
唐宇坤,邓 松,唐熙淳,许梦雅,郭 馨
(江西财经大学软件与物联网工程学院,江西 南昌 330013)
0 引言
学生评教文本是高校在进行教学评价活动中收集到的文本数据.评教文本不同于评教量表打分,具有较强的主观性,以及更多的信息维度.它包括学生对教师的建议、对课程的理解以及学生个人的想法等.反语是自然语言的一种修辞方法,使用和本意相反的词句表达思想.在评教文本中的反语会对评教活动带来一定的影响,这导致高校评教活动无法获取正确的教学反馈.
解释说明类反语在评教数据中较为常见,且较为隐蔽.结构上一般包含2个部分:第1部分为学生对某一事实的描述,第2部分是对第1部分的解释说明.为便于分析,列出如下3个实例:(i)“讲课水平真高,ppt用了几年?”;(ii)“上课来得真早,都快要吃晚饭了”;(iii)“上课准时,下课更准时”.从上述3个例子可以看出:解释说明类反语与在评教数据中其他类型的反语不同.
实例(i)的文本为学生的主观叙述,其中第1部分为“讲课水平真高”,第2部分为“ppt用了几年”.“讲课水平真高”表现了学生对教师上课水平的赞扬;“ppt用了几年”是学生对教师上课水平的不认可,抱怨教师过度依赖ppt以及讲课风格的一成不变.此时,在主观叙述上出现了矛盾,前后的情感倾向相反.因此,学生真正想要表达的应该是教师讲课水平有待提高.
实例(ii)的文本为学生的客观描述,其中第1部分为“上课来得真早”,第2部分为“都快吃晚饭了”.学生在第1部分“上课来得真早”中描述了一个客观事实,教师上课来得很早,这表明了一个较早的时间点;但在第2部分中,学生的表述为“都快要吃晚饭了”,这表明了一个较晚的时间点.此时,在客观的时间逻辑上出现了矛盾,前后表述的时间点相差较大.因此,学生真正想要表达的应该是教师上课来得太晚了.
实例(iii)学生直述了一个事实:教师准时上课下课.在句子中的“上课”与“下课”分别位于句子的前后2个部分,它们为并列关系,并且第2部分出现了程度副词“更”.在程度上,第2句的“下课准时”要大于第1句的“上课准时”,在程度的表示上出现了一个递进.此时,学生不是仅仅对教师准时上课下课这一行为进行陈述,而是抱怨教师对待教学工作不够认真负责.
从以上的分析可以看出:解释说明类反语与其他类型的反语存在一定区别,且隐蔽性较强.已有方法难以进行有效识别,因此需要针对解释说明类反语的特征建立评教文本解释说明类反语的检测算法.
在评教数据中的解释说明类反语主要有3种:第1种是在学生主观叙述中出现的矛盾句;第2种是在学生客观描述中出现的矛盾句;第3种是在学生对某一事实进行的叙述中情感程度出现了增强.基于以上特点可知:(i)仅使用文本情感分析方法判断反语是不够的,因为第2种和第3种类型的解释说明类反语的情感倾向不明显,文本情感分析方法难以对其进行有效分析;(ii)不能仅使用语义分析模型,因为第1种和第3种类型的解释说明类反语在语义上并没有明显的特征,现有模型难以对其进行判别.
为有效检测出在评教数据中的解释说明类反语,根据句子的特征类型、主观叙述类句子的情感倾向较强、客观描述类句子和程度递进类句子具有较为明显的语义特征,需要将情感分析与语义分析相结合进行分析.
1 相关研究
反语通常又称为“说反话”,其字面意义和所要表达的意义相反,是一种常用的带有强烈情感色彩的修辞方法.通常在表达情感时使用褒贬词来表明态度,也就使得基于情感词的褒义、贬义进行情感分析成为大部分研究的基础和重要组成部分,而影响情感分析精度的一个重要原因就是反语的使用[1].
对于反语识别问题,目前已有部分学者对此展开研究.主要基于语言的自身特点以及用户的文化环境等设计了相应的识别特征体系,对于识别算法的研究则主要是直接应用在机器学习中现有的各种分类算法[2].周荣翔等[1]提出:对于评论数据的反语检测,需要结合文本特点与中文反语特性,构建语义分析、情感分析以及文本特征等多方面检测方法对反语进行识别.
1.1 基于语义分析的检测算法
语义分析方法的语义结构基于文档中的实体和共指关系连接构建.给定一个句子,首先依存解析器对所有单词对的有效依赖关系的可能性进行评分,然后使用解码器从这些评分中生成完整的解析树.
在编码步骤方面,Ji Tao等[3]基于常用的句法图网络[4-5],使用递归聚合邻节点来表示特定节点;A. Kulmizev等[6]研究了基于上下文词的嵌入对依存句法分析的影响.对于传统的非神经网络方法,基于图的方法可以进行全局最优解码,但其所使用的特征相对受限.Zhang Zhisong等[7]研究了在基于图的神经网络依存分析方法中解码阶段不同的结构约束对依存分析结果的影响;实验结果表明:使用解码结构约束确实会提升最终的依存分析精确率,但是提升程度很有限.
在评分步骤方面,M.D. Lhoneux等[8]研究了基于双向长短期记忆网络的编码对评分步骤的影响.传统的非神经网络方法一般使用基于结构的特征来计算分数[9],基于转移的方法会使用已被规约的词信息.已有研究发现:前向编码与基于结构的特征包含了相似的信息,而后向编码则与基于结构的特征包含互补的信息.
在解析步骤方面,C. Gómez-Rodríguez等[10]提出把成分句法分析任务转化为一个序列,在降低少量精确率的同时大幅降低了句法分析所需的时间.D. Vilares等[11]修改了在原方法中的标注方案以规避某些类型的错误,减轻了原方法的错误传递问题.藤少华等[12]基于构造性逻辑语句,剥离了时间属性,加速了解析流程.
现有研究对在基于语义分析的文本分类方法上取得了较大的进展,但在评教文本的语义特征方面并不明显,且存在学生刻意回避部分特征语句的现象.即学生为了说反话而说反话,使用较为隐晦的词句表达自身情感.所以,直接在评教数据中使用语义分析方法会出现精确率较低的问题.因此,需要根据评教文本的特性,加入情感因素重新设计反语检测算法.
1.2 基于情感分析的检测算法
文本情感分析是通过对带有一定情感色彩与情感倾向的文本进行分析,挖掘其内在的情感信息,并对其情感程度进行分类.情感分析方法主要包含情感词典方法、机器学习方法、深度学习方法.
情感词典方法主要通过情感词的情感极性实现对句子的划分,中文情感词典主要有How Net[13]、大连理工大学中文情感词汇本体库等,其中分别包含一定数量的褒义词与贬义词,以对文本情感极性进行分析.Cai Yi等[14]利用特定域的方法解决了情感词一词多义的问题.徐雄飞等[15]针对短文本情感,在降低资源消耗的基础上,设计了新的情感词权重特征,提升了情感分类系统的性能.
机器学习是通过给定数据训练模型,利用模型预测结果的方法.预先通过标注的语料,使用算法抽取特征,最后输出结果.李文亮等[16]利用最大池化算法和平均池化算法获取文本的情感特征,在文本情感分析任务中取得了较好的成果.
深度学习方法主要有神经网络分析方法.徐绪堪等[17]将卷积神经网络和长短期记忆网络进行融合构造,设计了一种新的情感分类组合模型,为情感分类提供了新的理论模型与方法支持.
已有的情感分析研究侧重于文本的情感挖掘,取得了较好的效果,同时缓解了对模型结构的依赖.解释说明类反语在情感表述上较为混乱,虽然可以使用机器学习方法对其进行有效检测,但是高校举行的评教工作的时间周期较短,反复进行语料标注在一定程度上增加了评教的工作量.因此,为减少评教工作量,并有效检出在评教文本中的解释说明类反语,需要引入语义分析算法.本文基于评教文本的主观矛盾、客观矛盾、情感程度3种特征,提出了一种基于矛盾关系的评教文本解释说明类反语的检测算法,实验结果表明:该方法在学生评教数据中具有较高的识别精确率与召回率,且在不同类型学科的评教数据中适应性较强.
2 语义矛盾分析
本文根据在评教数据中解释说明类反语的特点,设计了3个特征.首先按照主观叙述和客观描述将文本分为2类,然后分别对其进行相应的矛盾分析判别,最后对存在并列实体的文本进行情感程度计算.反语检测流程如图1所示.

图1 解释说明类反语检测流程框图
在图1中,解释说明类评教文本被分为主观叙述类和客观描述类.主观叙述是学生在个人主观立场上的叙述,感情色彩较强烈,如“老师讲课水平真高”.讲课水平的高低并没有客观的量化标准,学生从个人的角度上人认为老师的讲课水平高,此为主观叙述类文本.客观描述是学生对事物的原样进行的叙述,这类文本描述某一行为或某一事物,如“老师上课准时”.准时是一客观行为,学生没有在主观上认定教师必须在某一时刻到教室,教师根据客观的时间表准时到了教室,因此,这客观描述类文本.
由以上分析可知:主观叙述类文本的情感色彩强烈,具有较强的情感倾向;客观描述类文本建立在一种内在的逻辑基础上,情感色彩不明显.
在并列实体文本中包含2个并列的实体,如“上课准点,下课更准点”.“上课”和“下课”在此文本中为并列关系,“更”作为程度副词,它在某种意义上加强了后半句的情感.此类文本既具有一定的情感倾向,又具有一定的内在逻辑.
2.1 主观矛盾计算
主观矛盾计算是指计算在评教文本中解释说明类反语前后2个部分情感极性存在的矛盾.主要用于识别在评教数据中第1种解释说明类反语,如“讲课水平真高,ppt用了几年?”.通过对文本情感的正负面(即褒义词、贬义词)进行分析判别.
首先将文本分为前后2个部分,然后分别使用大连理工大学中文情感词汇本体库对文本情感词分数进行计算.情感分数分别记为s1和s2,其中当s1或s2大于0时文本判定为积极,当s1或s2小于0时文本判定为消极.具体流程图如图2所示.
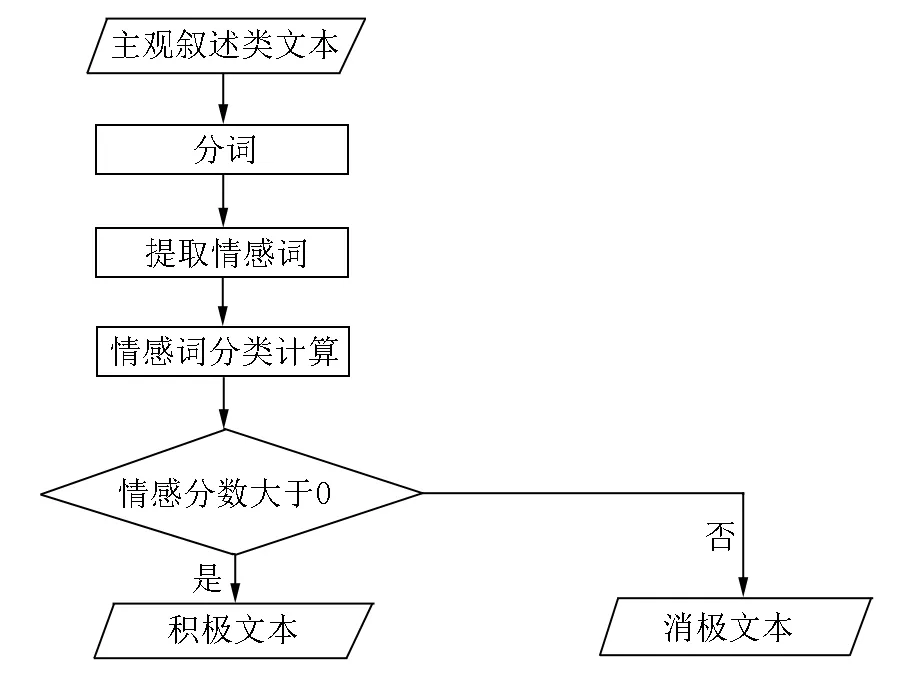
图2 情感极性分类流程
在图2中,分别计算文本前后2个部分的情感极性.在学生通过个人主观情感表达时,反语的产生是学生有意识的行为.为了达到反语的效果,即反语给人主观上带来的震撼,学生会主动操纵不同性质信息的反馈比例和反馈顺序,即通过“先扬后抑”或者“先抑后扬”的信息反馈顺序,使读者产生惊讶假设[18].基于此理论,此类文本的前后部分会出现一个较大的情感倾向反差.使用如下公式计算文本的情感一致性
其中S(x)表示文本前后部分的情感一致性,P和N分别表示积极和消极文本词典.x1∩P表示第1部分文本与积极文本词典的交集,x2∩N表示第2部分文本与消极文本词典的交集,x1∩N表示第1部分文本与消极文本词典的交集,x2∩P表示第2部分文本与积极文本词典的交集.当K(x)>0时,文本的前后部分情感不一致,即存在较大的情感倾向反差;此时,该评教文本为解释说明类反语.
2.2 客观矛盾计算
客观矛盾是评教文本前后部分在表面上存在较为明显的逻辑矛盾,包含时间矛盾和空间矛盾.在学生个人真正想要表达的情感角度上,存在一个严谨的内在逻辑,如“上课来得真早,都快要吃晚饭了”.此时对句子的前后2部分分别进行句法分析,结果如图3所示.

图3 客观矛盾反语的句法分析
由图3可知:句子前半部分的核心是“上课早”,后半部分的核心是“吃晚饭”,句子在时间上存在矛盾.针对文本时间信息矛盾问题,使用基于GATE的方法[19]进行时间信息抽取比对,对比过程如图4所示.

图4 GATE的中文时间信息抽取流程
根据图4对前后短句核心的时间词进行抽取,第1部分的时间信息为t1,第2部分的时间信息为t2.当t1≪t2或t1≫t2时,句子的时间在逻辑上存在矛盾.
空间矛盾是句子前后描写的空间信息出现较大偏差,使用空间映射方法计算其在物理空间中的位置映射[20],分析方法如图5所示.
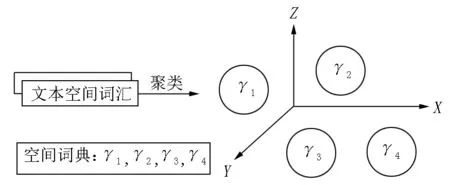
图5 中文空间信息抽取映射
在图5中,文本核心词汇中所包含的空间信息词汇被映射到3维空间坐标中.在短句中包含的空间信息在空间中的坐标为γx.若句子前后部分的空间信息|γ1-γ2|足够大,则可认为该短句为解释说明类反语.
2.3 情感程度计算
为了缩短读者情感变化的持续时间偏差与强度偏差[21],即为了让读者的情绪变化能符合学生的预期,在存在实体并列关系的文本中,学生刻意加强一部分实体情感,使读者能体会到学生真正想要表达的感情.如在“上课准时,下课更准时”句子中有2个并列的实体关系,即上下课都准时.进行语义分析图计算,结果如图6所示.

图6 文本语义分析图
在图6中,对文本进行语义分析.前后句的“准时”为并列关系,“上课”与“下课”分别与“准时”构成一个当事关系.句子第2部分出现程度词“更”,增强了后半句的情感[22],使整个句子想要表达的情感出现了根本性的变化,即学生不是单纯描述一个事件,而是对事件的某一行为进行重点凸显.因此,在主题概率模型p=(x1,x2,…,xn)中,当主题词出现A1、A2、B1、B2、C1(其中A1、A2为构成并列关系的同一事件,B1、B2为分别与A1、A2构成当事关系的同一类型事件,C1为A1或A2的程度标记,增强了A1或A2的情感)时,句子为解释说明类反语.
3 实验分析
本文从江西财经大学教育评价系统中抽选了31 125条2018年、2019年及2020年有效的学生评教数据,标注出174条解释说明类反语文本和30 951条非反语类型的文本.
本文将对31 125条评教文本进行解释说明类反语的判别,实验结果预计为一个符合伯努利分布的数组[23].考虑到实验中算法可能出现的误检率(即算法将其他类型文本判断为解释说明类反语文本的概率),以及可能出现的漏检率(即算法未检测到解释说明类反语的概率).因此,需使用实验结果的精确率和召回率对算法进行评价.此处的精确率为Pp=TP/(TP+FP),TP为算法正确检出的解释说明类反语数量,FP为算法将其他类型文本判定为解释说明类反语文本的数量;此处的召回率为Pr=TP/(TP+FN),FN为将解释说明类反语文本判断为其他类型文本的数量.为了更好地评价检测算法的性能,进行如下定义.
T1(基于年份的检测算法精确率和召回率):在所选择的N个样本中,根据文本产生的年份(即学生提交评教文本的年份)对样本进行分类,分别计算检测算法在每一年度数据中的精确率和召回率.
T2(基于学院的检测算法精确率和召回率):根据学生所属的学院,对选择的N个样本进行分类,分别计算检测算法在每一个学院数据中的精确率和召回率.
T3(基于学生年级的检测算法精确率和召回率):在所选择的N个样本中,根据学生的年级分类,分别计算检测算法在不同年级数据中的精确率和召回率.
T4(基于学生性别的检测算法精确率和召回率):在所选择的N个样本中,依据学生性别分别计算检测算法在不同性别数据中的精确率与召回率.
先按照文本情感强度,以半监督方法将文本分为主观叙述类文本和客观描述类文本[24],然后分别对这2类文本进行主观矛盾分析和客观矛盾分析,最后提取包含并列实体关系的文本进行情感程度分析.实验首先使用本文提出的检测算法与已有算法分别对评教文本进行检测,然后比较这2种算法之间的检测效果,最后对本文算法进行评价.
3.1 基于年份的检测算法精确率和召回率
为更好地对本文算法进行评价,分别计算检测算法在数据中的精确率和召回率.为判断本文算法在不同年份数据中是否存在过拟合问题,首先按照不同年份数据分别进行检测分析.选取周荣翔等[1]提出的多要素中文反语检测算法与本文算法进行对比.因为多要素算法在复杂语境下的非平衡数据中取得了较好的效果,所以适合与本文算法进行比较分析.在不同年份下算法的精确率与召回率的实验结果分别如图7和图8所示.
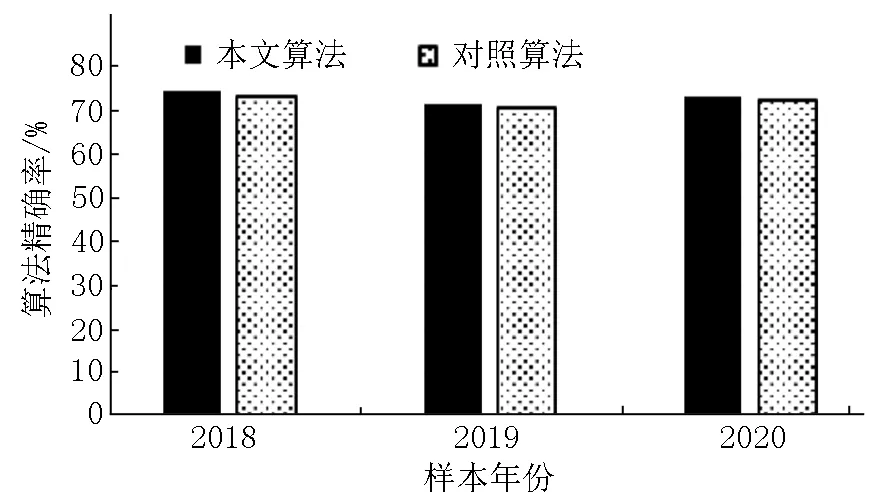
图7 基于年份的算法精确率比较

图8 基于年份的算法召回率比较
从图7可以看出:在不同年份的评教数据中,本文算法与对照算法均取得了较高的精确率.图8显示了本文算法的召回率较高且比对照算法具有较为明显的优势,对照算法的召回率与原文实验[1]相比出现了一定的下降.原因在于本文根据学生评教的动机重新对反语进行了定义.本文在常规反语定义的基础上增加了并列实体情感增强的反语,同时对常规的反语定义进行了一定的拓展.由于对照算法难以对本文拓展定义的反语进行检测,因此对照算法的召回率出现了下降.
由于本文根据评教文本反语的拓展定义重新设计了反语检测算法,该算法从学生的评教动机出发,以情感动机和逻辑信息2个角度对评教文本进行判别,因此本算法具有较高的精确率与召回率.从本实验可以看出:本文算法在不同年份的数据中均具有较好的效果.
3.2 基于学院的检测算法精确率和召回率
不同学院在教学方式与风格上存在一定的区别,同时不同学院学生的思考方式也各不相同.为了显示算法能否在不同学院中保持稳定效果,进行如下实验,分别计算该算法在不同学院数据中的精确率与召回率,实验结果分别如图9和图10所示.
从图9和图10可以看出:本文算法在不同学院的数据中均保持了较高的精确率与召回率,且召回率优于常规的算法.同时还可以发现:算法的精确率和召回率在不同学院中出现了一定的波动.原因可能在于:在不同学院中不同思维方式的学生产生反语的动机存在一定的区别,算法无法在不同的学院数据中保持绝对的稳定性.

图9 基于学院的算法精确率比较
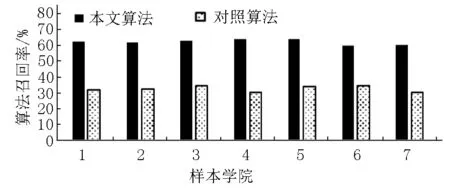
图10 基于学院的算法召回率比较
3.3 基于学生年级的检测算法精确率和召回率
随着本科教学的深入,不同年级学生的思维方式与行动逻辑会逐渐出现区别,为了比较算法在不同年级学生的数据中的效果进行如下实验,分别计算该算法在不同年级学生数据中的精确率与召回率,实验结果分别如图11和图12所示.
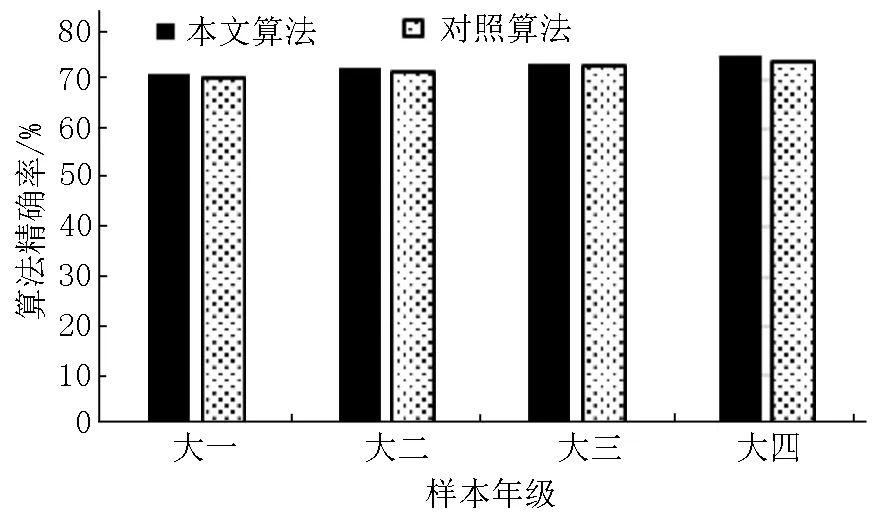
图11 基于年级的算法精确率比较
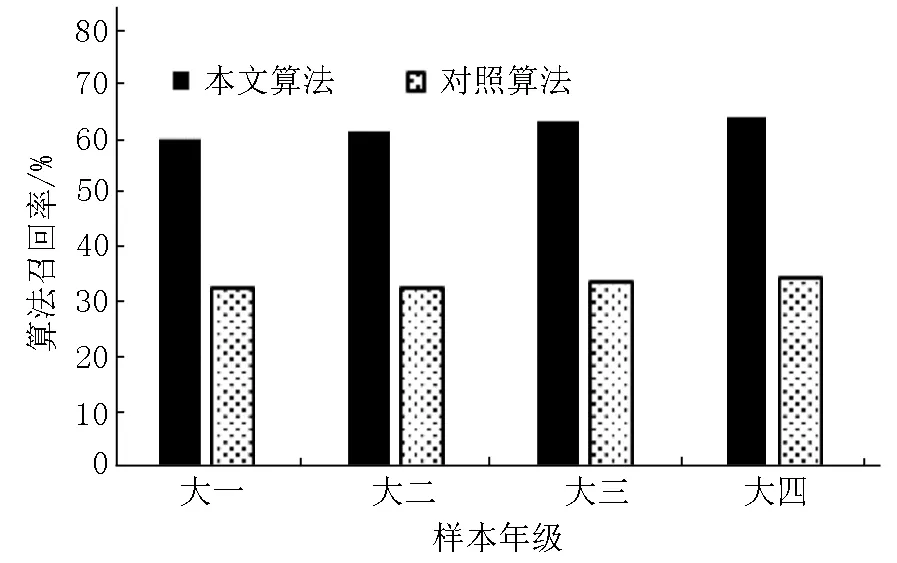
图12 基于年级的算法召回率比较
从图11和图12可以看出:本文的算法在不同年级的样本数据中均保持了较高的精确率与召回率,且随年级的提高有个缓慢的上升趋势.原因可能在于:学生在高校学习的过程中的逻辑思维能力和情感表现能力也在逐年提高.由于随着年级的提升因此产生的解释说明类反语会越来越具有逻辑性且情感反差也越来越大,所以算法的性能也随着年级的提升而逐步提高.
3.4 基于学生性别的检测算法精确率和召回率
性别的不同会导致逻辑辩证思维能力以及情感表现倾向也存在差异.为了测试算法在其中是否也会出现较大差异,设计如下实验,分别对不同性别学生的数据进行检测.实验结果如图13和图14所示.
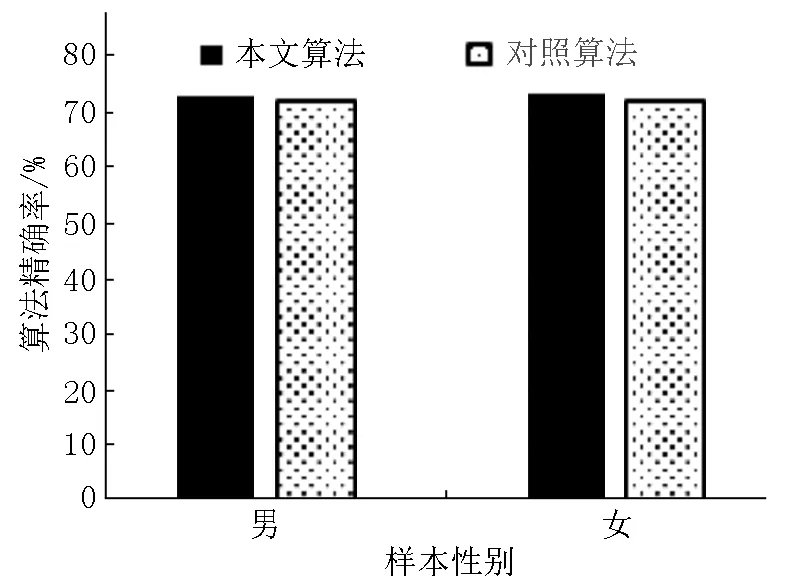
图13 基于性别的算法精确率比较
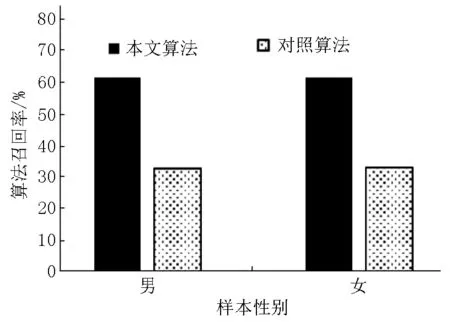
图14 基于性别的算法召回率比较
从图13和图14可知:学生性别因素对算法的影响较小,准确率与召回率在不同性别数据中的差距极小.可以认为算法在不同性别数据中保持了较高性能,同时稳定性也较高,不易受到性别因素的干扰.所以算法在不同性别的数据中均可得到较好的应用.
3.5 实验总结
本文从学生的评教动机出发,针对在评教文本中解释说明类反语的特点,设计了主观矛盾、客观矛盾、情感程度3种特征,通过客观的内在逻辑与主观的情感发泄2个方面完成对解释说明类反语的判别,计算公式为

其中T(X)表示文本的矛盾关系,S(x)表示文本的主观矛盾关系,O(x)表示文本的客观矛盾关系,E(x)表示文本的情感程度关系.当S(x)=1时,文本存在主观矛盾;当O(x)=1时文本存在客观矛盾;当E(x)=1时,文本存在情感程度差异.当T(X)=1时,文本中存在矛盾关系,即文本为解释说明类反语.
本文从年份、学院、年级、性别共4个角度设计实验检测算法性能,实验结果表明该算法在不同角度下均保持了良好的效果,且比传统算法具有一定的提升.其原因是本文重新定义了解释说明类反语,从逻辑与情感角度对其原定义进行拓展的同时,针对评教工作的特点引入了新的解释说明类反语特征.传统算法在评教环境下的解释说明类反语数据中出现了性能下降的现象.
4 结语
为了推进评教工作的开展,本文从学生的评教动机出发,设计了一种基于矛盾关系的评教文本解释说明类反语检测算法.从学生的内在逻辑和情感表达2个方面设计了主观矛盾、客观矛盾、情感程度3种特征,通过不同的特征对解释说明类反语进行判别,完成在评教工作中反语的标记任务.
随着语言的发展,语言逻辑性与情感表现性也会逐步提高.在未来的工作中,将进一步对解释说明类反语的特点进行挖掘,以更好地完成高等院校的评教工作.
猜你喜欢
科教导刊(2023年2期)2023-02-23 14:30:12
中共云南省委党校学报(2022年1期)2022-04-26 13:55:44
小学生优秀作文(低年级)(2020年4期)2020-07-24 08:31:16
法律方法(2018年2期)2018-07-13 03:22:06
外国语文(2017年3期)2017-03-11 15:11:53
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01 04:07:06
广州大学学报(社会科学版)(2016年7期)2016-03-09 09:22:39
大庆师范学院学报(2015年3期)2015-12-24 07:35:45
河南教育·基教版(2015年5期)2015-06-05 07:00:04
福州大学学报(哲学社会科学版)(2013年4期)2013-04-18 08:33:55
