
基于LSTM和新闻情感的股票价格预测方法
2022-05-27 06:56李桂城肖一凡陈丽绵
智能计算机与应用 2022年5期
许 丽,张 利,李桂城,肖一凡,陈丽绵,唐 艳
(贵州大学 大数据与信息工程学院,贵阳 550025)
0 引 言
股票市场是国家经济市场的重要组成之一。随着中国经济的腾飞和大数据的发展,一方面,关心股市问题的不再只有上市公司,越来越多的普通民众将目光转向股票投资;另一方面,影响股票价格的因素有经济、政治和公司自身的管理等,均使得股票价格走势变得难以预测。因此,众多研究者开始深入研究影响股票价格的因素,并提出了许多经典模型。
文献[1]提出了一种ARIMA和SVM的组合预测模型,首先使用ARIMA模型对华泰证券一年的股票价格进行线性预测,接着使用SVM模型对其进行非线性预测,实验表明,组合预测模型得到的综合结果精度高于单一模型。文献[2]改进了XGBoost模型,使用网格搜索算法对模型进行参数优化,基于原XGBoost、GBDT、SVM以及改进的XGBoost模型对5个短期数据集,如中国平安、中国建筑等进行预测,实验结果表明,XGBoost表现出了最优的评价指标和最好的拟合性能。文献[3]提出了一种粒子群和支持向量机的组合模型,传统的支持向量机在股票预测中取得了较好的效果,但是根据人为经验选取支持向量机的参数和核函数存在很大的弊端,而该模型利用粒子群算法可以自动更新速度和位置且各粒子之间共享信息的特性,对SVM的参数进行优化,实验结果显示,该算法在很大程度上提高了预测结果,对比原始的SVM,准确率有所提高。文献[4]提出了Bagging-SVM模型,算法的思想是利用bagging将数据集划分为若干的子训练集去训练传统的SVM,最后通过对每一个子SVM模型的预测结果进行投票,票数最多的项即为最终的预测结果。文献[5]在对输入数据进行预处理后,将其送入层数不同的LSTM和层数相同、但神经元不同的网络结构中,通过评价指标来选择合适的结果,并对苹果公司的股价进行预测分析,验证了其精度可提高30%,证明了该方法的可行性。文献[6]将LSTM网络用于股票价格预测,通过对模型进行不断调优,获得最优预测模型后将其预测结果与BP神经网络、RNN、CNN,人工神经网络的预测结果进行对比,结果表明,LSTM评价指标最优且预测值和真实值的曲线拟合得最好。文献[7]提出了一种基于粒子群算法改进的LSTM模型,传统LSTM网络常常根据自身经验确定其中的重要参数,由于主观性极强无法确定最优值,粒子群算法的提出解决了这一问题,通过算法寻优构建了完善的预测模型,使得准确率大大提高且获得了普遍的适用性。文献[8]将不同的输入特征送入LSTM模型来预测股票的收入,验证了特征不同的输入对股票价格的影响。文献[9]提出了Adv-ALSTM模型,通过添加扰动来模拟价格的随机性,以此来训练模型在干扰数据下的泛化能力,实验表明,在训练模型阶段,采取对抗性网络的方式大大提高了网络性能和拟合能力。为了同时满足捕获长时间依赖关系和选择相关驱动进行预测的要求,文献[10]提出了DA-RNN网络,该网络是一个2层LSTM结构,包含解码和编码环节,将该模型应用在SML2010数据上,结果表明该网络不仅可以进行有效预测,而且具有很强的可解释性。文献[11]提出了基于TCN和文本情感分析方法的股票价格预测方法,通过爬虫的方式获取相关数据集,使用LSTM对新闻文本进行情感极性分析,并将其结果与股票数据一同输入TCN网络,改进后模型的评价指标表现良好,验证了其可行性。
本文的结构大致如下:第一节综述了股票价格预测的经典模型和算法;第二节介绍了本文使用的一些相关算法机理;第三节概述了本文算法的原理;第四节给出了本文网络在相关数据集上的评价指标和拟合曲线的实验结果;第五节总结概括了该文章,并提出该领域未来可能的发展方向。
1 相关算法
1.1 交叉验证
泛化能力是评价一个模型好坏的指标之一。因此,常常使用交叉验证来提高模型的泛化能力。常见的交叉验证有简单交叉验证、留一交叉验证以及k折交叉验证。其中,简单交叉验证仅仅需要将数据集划分为2份,选取数据量小的一份作为验证集来评价模型的好坏,该算法虽然可以用来评价模型,但是划分的比率不同会产生较大的差异。留一法,顾名思义,将个样本划分为份,进行次训练,每次只留一份为验证集,该方法在数据量小的时候可以最大限度地利用每一个样本,其弊端在于如果数据量很大时会造成欠拟合。k折交叉验证把数据集划分为份,每一份逐一作为验证集去评价模型,基于此再取平均值作为最后的评价指标。一般情况下,值越大则模型性能越好,但是有研究表明,其范围在5~10之间或能取得最佳效能,本文使用10折交叉验证对LSTM模型进行训练。
1.2 XGBoost
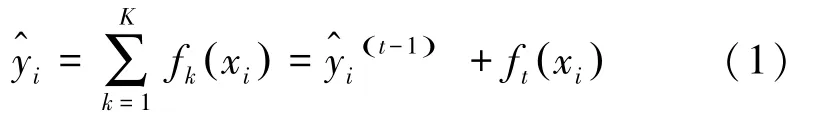
XGBoost是梯度提升决策树算法(DBDT)的改进版本。由叶节点为分类变量的决策树和叶节点为连续变量的回归树两种增强树组成。DBDT梯度提升树的表达式如(1)所示: 为了避免正则化,通过在原网络的基础上增加正则项来简化模型,XGBoost包括回归树和决策树,并且采用了blocks的存储结构,使得算法可并行,提高了运算速度。该算法的最终目标是优化函数Obj ,其中包含损失函数和表示复杂度的正则项。 网络在每一次迭代之后增加一棵树,来优化Obj 。 函数的数学定义可写为如下形式:
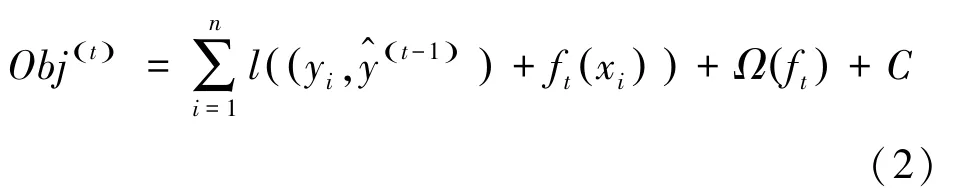
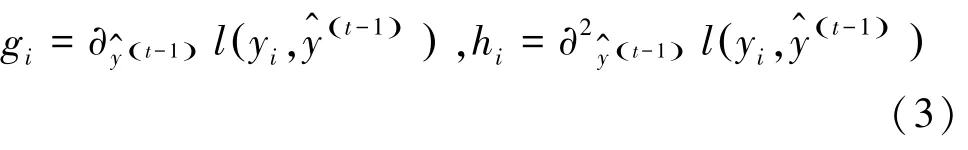
损失函数在第1次迭代时获得的预测值的一次偏导g和二次偏导h,如式(3)所示:将目标函数按泰勒二阶公式展开,消除常数项带来的影响。二阶导数使得损失函数更加精确,并将式(3)带入,得到新的目标函数如式(4)所示:
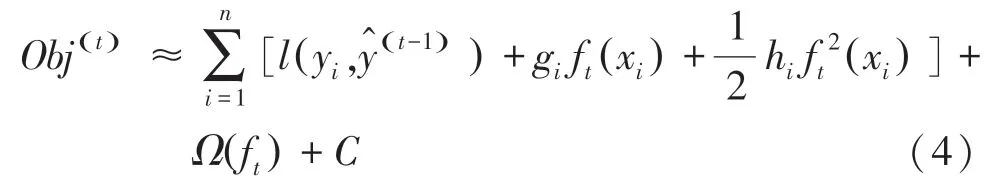
进一步地,研究中可推得:
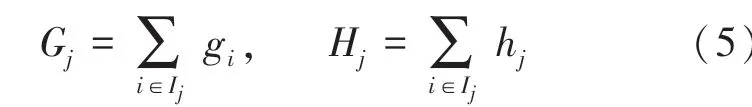
在训练目标函数时,f()=w,即把函数(树)拆分为叶子的权重向量部分和树的结构部分,目标函数可以表示为:
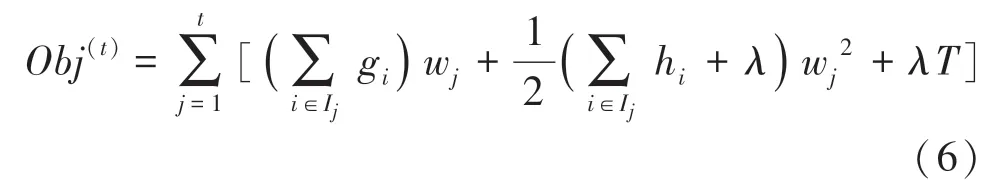
将式(5)带入式(6)合并一次项系数和二次项系数,得到最终的目标函数如式(7)所示:
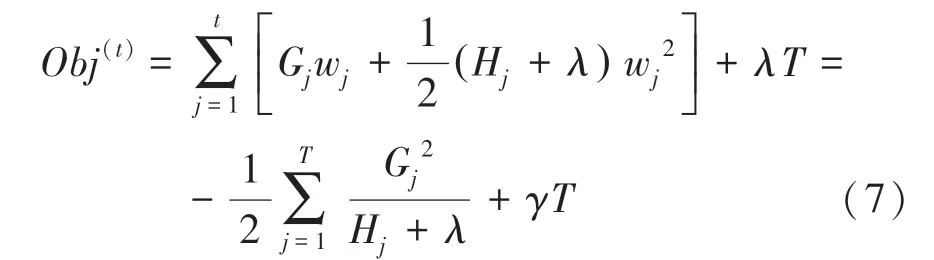
目标函数又可称作打分函数,在一定范围和条件下,目标函数的值最小,表明此时得到了最优解。总而言之,XGBoost具有很多优点。不仅可以减少过拟合并且处理正则项,也可提升运算速度、可自定义目标函数以及模型评价指标,具有高度灵敏性。除此之外,XGBoost具有自动处理数据集缺失值的功能,允许在boosting迭代中使用交叉验证。
2 算法机理及流程
2.1 SVM_LSTM模型的搭建
随着人们生活水平的提高,在满足日常衣食住行之余,已有很多人开始利用手中的闲钱来做投资,由于股票的低投资以及高回报性,使其成为大众的重要选择,基于此,如何选择最优股即已成为备受关注的热点话题。以往的研究者要么针对股票历史数据进行时序预测,要么采取分类网络进行文本情感分析,忽略了二者直接的内在联系。在此背景下,本文提出了SVM_LSTM网络。
在时序预测通道上,本文首先采用归一化的手段处理股票数据,对股票数据进行归一化处理可以削弱量纲带来的影响,将数据统一到一个相差不大的范围,以此来减少较大数据和较小数据的影响,本文采取的归一化公式具体如下:
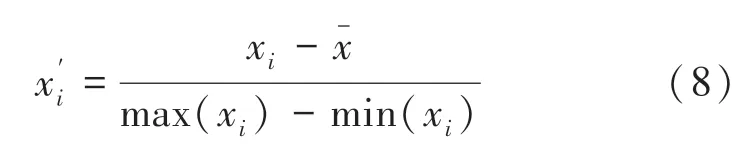
其中,x表示第个变量,x表示均值。
其次,本文使用10折交叉验证划分经过预处理的股票数据,来训练LSTM模型;最后,调用训练良好的模型预测中国银行、中国联通、浦发银行的股票数据。LSTM机理详见2.2节。
在文本预测通道上,对于中国银行股票新闻的文本数据集,本文首先在百度智能云网站注册一个AipNlp账号,这是自然语言处理的Python SDK客户端,通过调用该网站可以对本文爬取的文本数据集做一个初步的处理,由于使用该接口对新闻文本标题预测得到的结果为每一条新闻词条对应的积极的可能性和消极的可能性,本文在Python中指定当积极的可能性大于消极的可能性时,就将该新闻文本标注为1,代表利好,反之,将文本标注为0,表示利空;随后采用处理好的文本数据集训练SVM模型;最后,调用SVM预测文本新闻情感极性。SVM原理详见2.3节。
至此,研究中采用了加权的方式将SVM的预测结果与LSTM的预测结果进行融合。其算法流程如图1所示。图1中,第天的股票最终预测价格_pred的计算方法如式(9)所示:
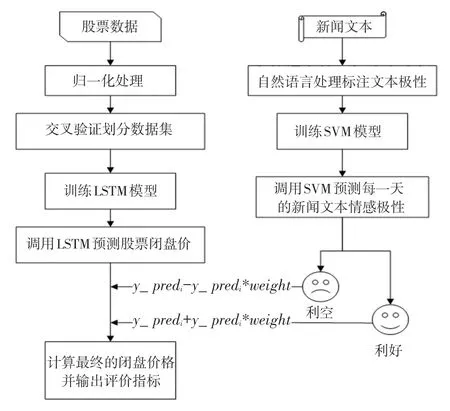
图1 算法流程图Fig.1 Algorithm flow chart
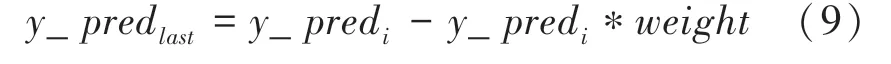
其中,_pred 表示时序预测第天的结果。在本文中,由于在时序预测阶段,真实值与预测值在整体走势上拟合得很好,只需要微小的调整就可以使得预测值更接近于真实值,故而本文将设置为001。
2.2 LSTM
循环神经网络RNN能够处理时序数据,时序数据、即数据之间具有时间先后性,数据整体呈现某种趋势。循环神经网络具有跨越时间节点的自连接层,能够建立当前时刻与序列上一时刻的关系。但是随着网络层的加深,由于循环神经网络只会获取上一节点的信息,无法储存距离当前时刻较远的网络的输出,会造成梯度消失。为了解决梯度消失和梯度爆炸,最早由Zhao等人提出了LSTM网络,在此后的一段时间里,该网络被广泛地应用在时序预测邻域中。
LSTM是对RNN模型的改进,以达到解决梯度消失的效果。这一改进主要表现为:在RNN隐藏层中添加了长短期记忆单元;通过添加门控结构、引入激活函数结合RNN原有的tanh激活函数,来控制网络对历史信息的输入保存和输出;输入信息由添加的细胞状态记忆。综上所述可知,LSTM解决了短期依赖和长距离依赖问题。
LSTM的3个门控单元分别为输入层、隐藏层、输出层,共同构成了模型的输入部分。LSTM网络结构如图2所示。由图2可知,该结构中各主体组成部分的设计原理及数学表述详见如下。
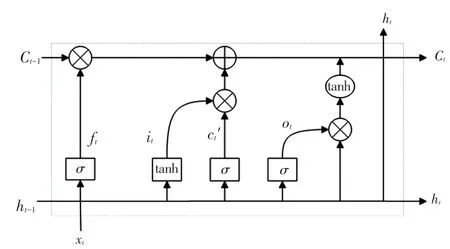
图2 LSTM网络结构Fig.2 LSTM network structure
(1)输入层。为全连接层,该网络首先对数据进行预处理,以达到输入数据格式要求。输入门的值i和输入细胞的候选状态值Ct可由如下方式计算得到:
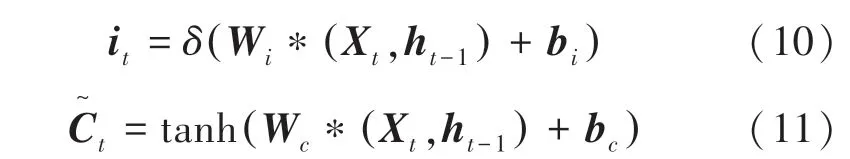
其中,和表示计算时的权重矩阵;表示偏置向量;表示激活函数。
(2)隐藏层。是包含多个LSTM神经元的循环神经网络。在该网络结构中,激活函数选取和tanh,时刻遗忘门的和当前时刻细胞的状态的更新值的数学表达式可写为:
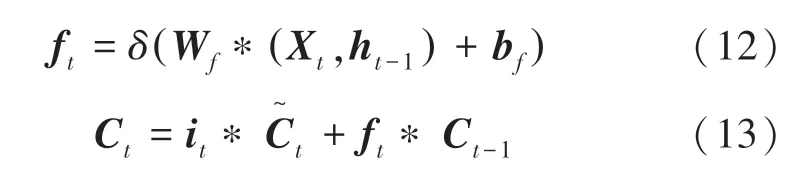
(3)输出层。将隐含层的多个输出结果映射到全连接层来获得模型的最终输出。在该层网络结构中,计算得到的最终输出结果如下:
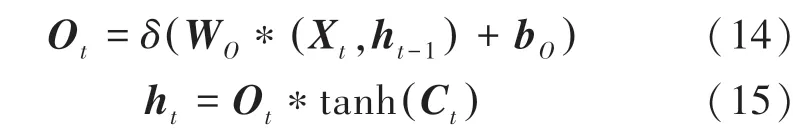
2.3 SVM

图3 SVM分类示意图Fig.3 SVM classification diagram
利用拉格朗日优化最大间隔,最终得到决策函数具体如下:
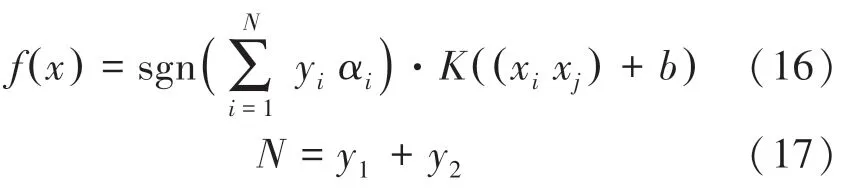
其中,表示分类总数。
二次规划问题,求解约束最优化的问题变成公式(18):
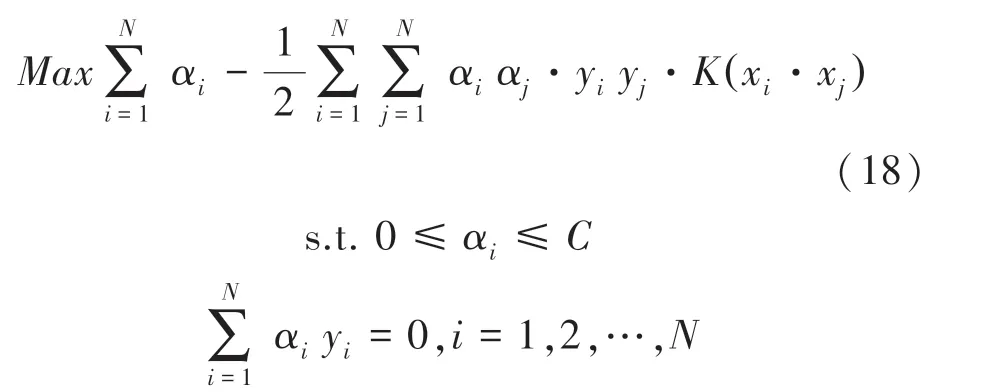
其中,为惩罚函数,该值与模型对噪声的容忍度成正比,与模型的泛化能力成反比。
常见的SVM核函数有线性核函数、多项式核函数、径向基核函数,对应的数学公式可顺次表示为:
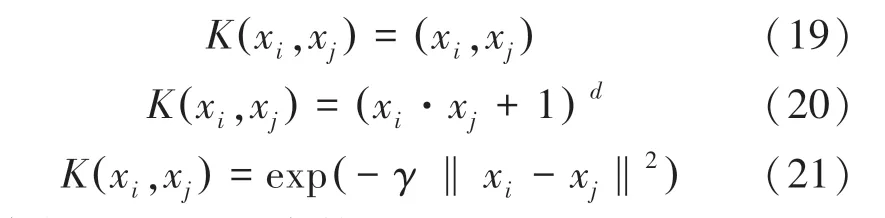
其中,和是常数项。
核函数的选择决定了模型的预测效果,通过核函数网络,SVM将输入的向量映射到高维特征的空间,将原本的非线性问题变换为高维度特征空间的线性可分问题。
3 实验
3.1 数据集介绍
本文通过baostock库爬取了中国银行、中国联通、浦发银行三只股票从2020年8月30号到2021年10月27号的相关数据,包括开盘价,收盘价,最高价以及最低价。 收盘价表示股票当天的最后成交价,一般将其作为股票价格预测中唯一的因变量。图4是中国银行的收盘价随时间的变化曲线,横坐标表示不同的日期,纵坐标表示相应日期对应的股票价格。从图4中可以看到该时序数据整体价格分布在2~4之间,某一天的闭盘价周围一段时间内不会发生太大的突变;但是,图4中黄色方框处股票急剧上升,在绿色方框处股票又突然下降。
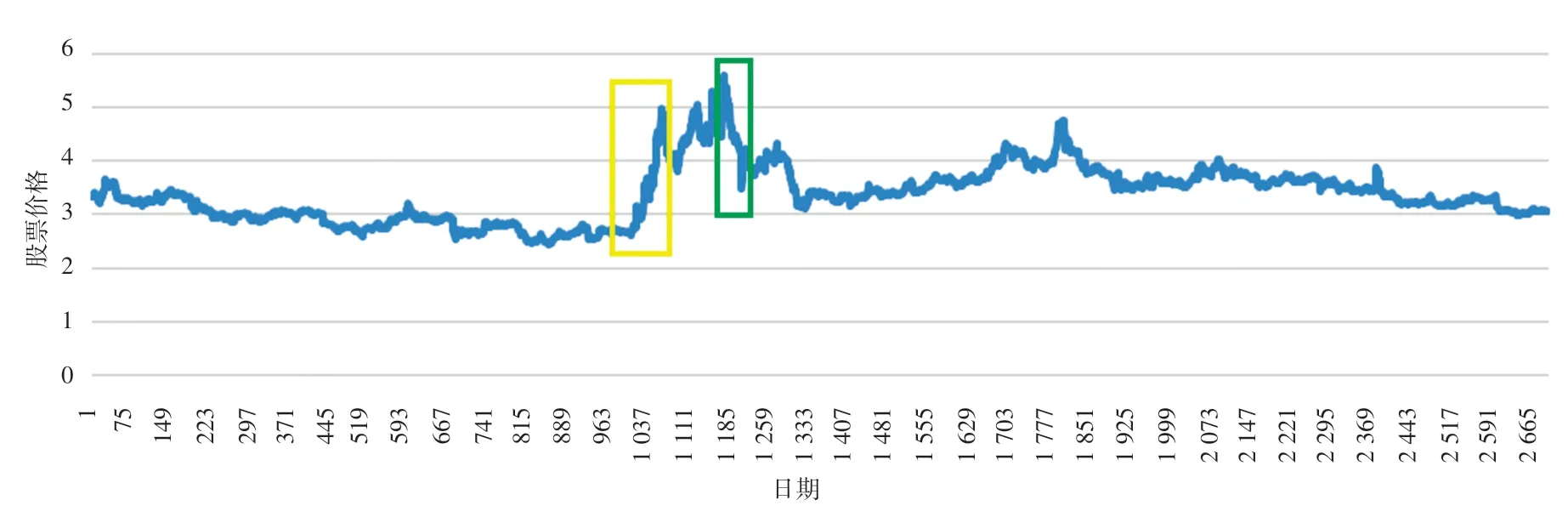
图4 中国银行股票跌涨曲线Fig.4 Stock decline and rise curve of Bank of China
对于新闻文本数据集,本文利用lxml库爬取了“新浪财经网”和“金融界”网站中有关中国银行的新闻文本。lxml是XML和HTML文件的解析器,还可以用于Web爬取。
3.2 评价指标
本文采取均方根误差()、平均绝对误差()以及均方误差()来衡量模型的性能。各指标值的数学公式可表示如下:
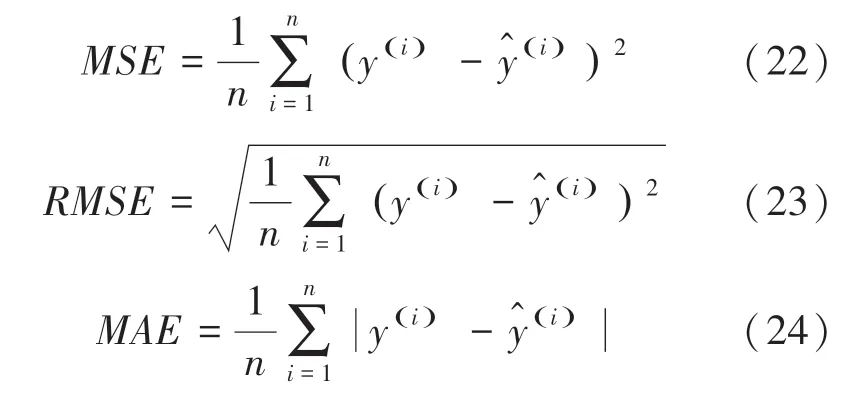
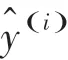
对于分类模型SVM,本文采取预测准确率()来衡量效果的好坏,研究后可推得的数学公式如下:
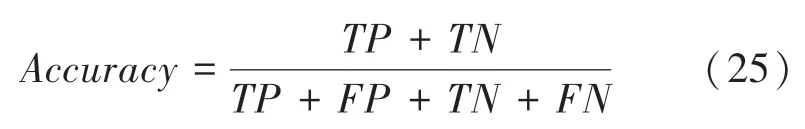
其中,具体参数含义见表1。

表1 预测与实际情况类型表Tab.1 Forecast vs.actual type table
3.3 XGBoost和LSTM模型的预测结果
图5(a)~图5(c)中,左侧为XGBoost模型的预测值与真实值的拟合曲线,右侧为LSTM网络的预测值与真实值拟合曲线。本文中,如果不做特殊说明,统一使用红色曲线表示预测曲线,蓝色曲线表示真实值曲线。可以看到:
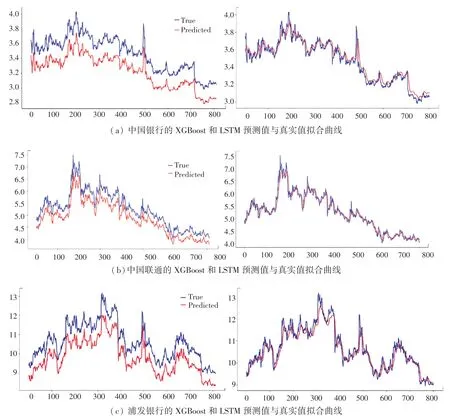
图5 XGBoost和LSTM模型的预测结果Fig.5 Prediction results of XGBoost and LSTM models
(1)XGBoost模型拟合得到的预测值与真实值相比,其涨幅趋势大致相同,并且在第天出现峰值时也能够进行较好的预测,然而预测值曲线整体处于真实值下方,说明对于数值的预测存在偏差,因此该模型性能仍存有提升空间。
(2)LSTM在保留了XGBoost优点的同时,预测值无限逼近真实值,并且与绝大部分的低谷值和峰值完全吻合,针对中国银行数据集,表2显示了LSTM的评价指标、和较XGBoost分别减少了0.234、0.173和0.011,说明了本文搭建的模型预测精度更高。
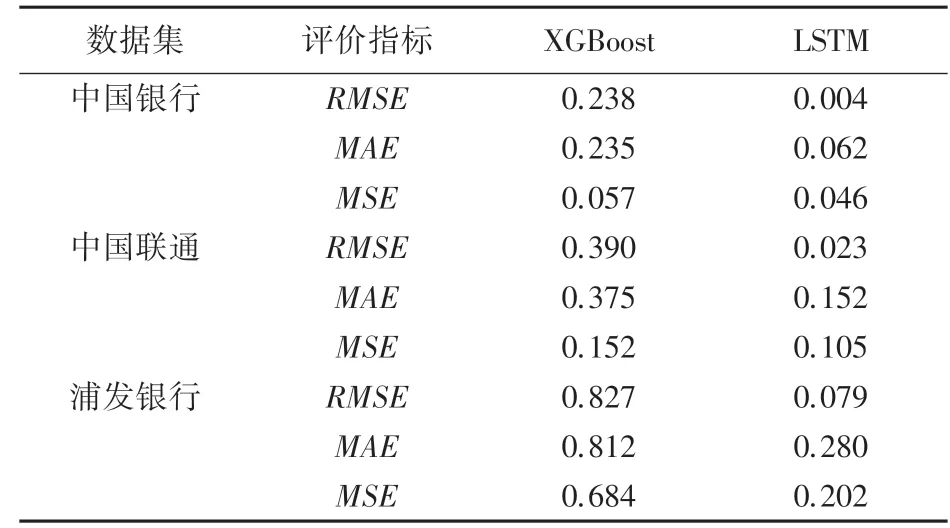
表2 XGBoost和LSTM在各数据集上的评价指标Tab.2 Evaluation indicators of XGBoost and LSTM in each dataset
(3)中国银行无论在曲线拟合程度、还是在评价指标上,均优于中国联通和浦发银行,对于LSTM网络,各评价指标之间整体没有大致的差别,表明了本文模型具有较好的泛化能力。
3.4 SVM实验结果
使用中国银行股票新闻数据集对SVM模型进行训练,该模型的准确率()达到了81%,高于文献[3]中SVM模型所达到的79.11%,说明本文模型的可行性。表3展示了自2021年9月1号到2021年10月25号的预测结果,其中1代表利好,0代表利空,分别对应了股票的上涨和下跌。表3中的新闻文本标题均为中国银行的个股资讯,由于不是每天都有相关新闻消息,表中的日期并不连续。没有日期则对应的时序预测股票价格保持不变。
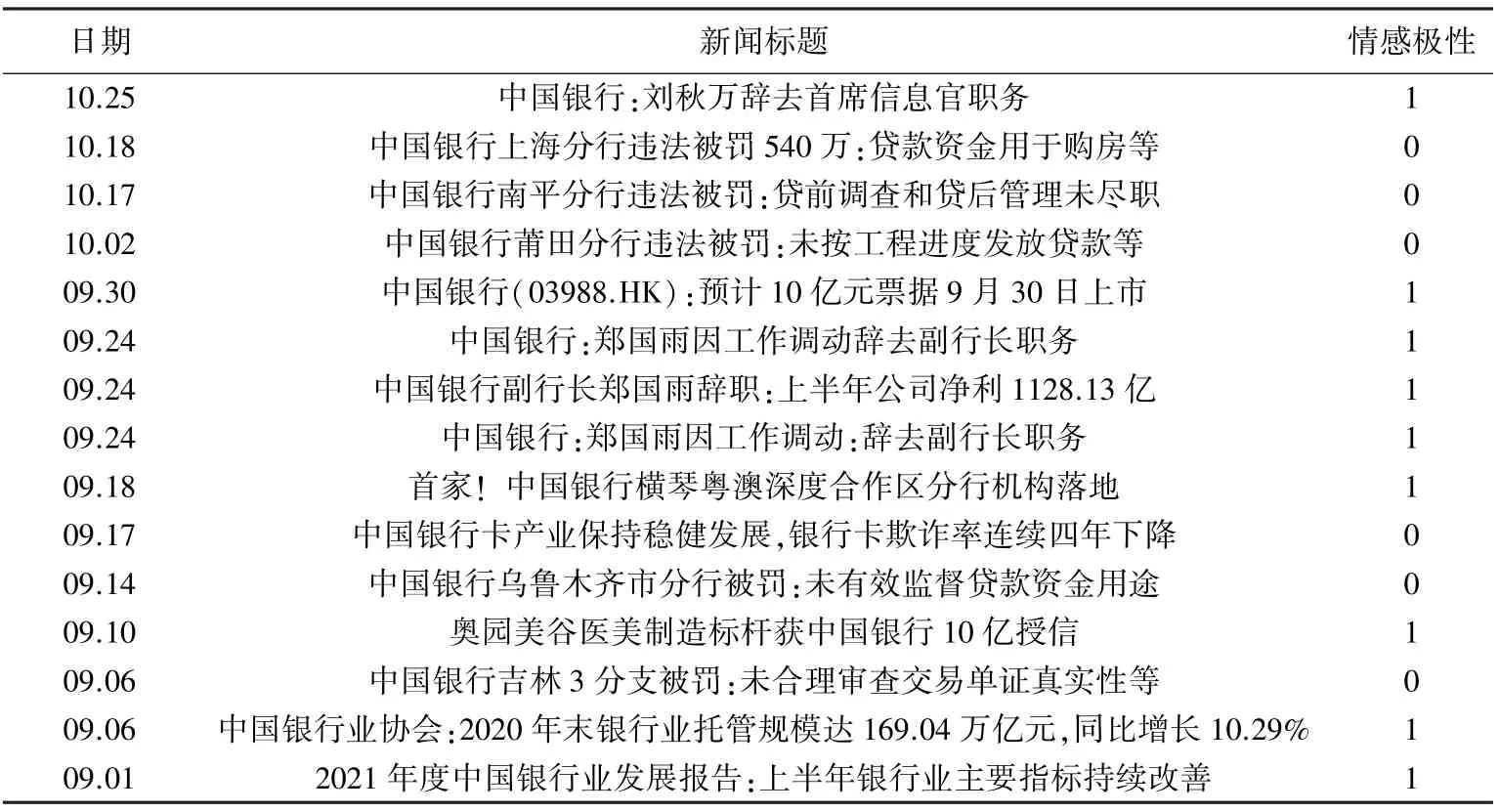
表3 SVM预测结果Tab.3 SVM prediction results
3.5 SVM_LSTM模型实验结果
本文将中国银行的预测结果按照对应日期加权(2.1节附有详细说明)到LSTM的预测结果上。经过计算,本文网络SVM_LSTM的最终结果见表4,显然,各评价指标较原LSTM均明显减少,、、分别减少了7.5%、6.4%、10.8%。

表4 SVM_LSTM评价指标Tab.4 SVM_LSTM evaluation index
4 结束语
本文综合考虑了影响股票价格的双重因素,分别是新闻文本和股票历史数据,通过SVM和LSTM对2个通道的数据进行预测,再对其预测结果进行加权融合,使得2种不同的数据类型相互补充,让最终预测股价更接近于真实价格。将本文模型应用于中国移动股票的预测上,结果表明:
(1)利用交叉验证优化的LSTM虽然比XGBoost模型具有更高的预测精度,曲线拟合程度也更优,但是模型预测值和真实值之间仍然存在一定的差距。
(2)SVM模型预测准确率虽然达到了81%,能够给投资者提供大致的股票跌涨讯息,可是却不能够获取实际闭盘价格。
(3)本文采取加权融合的方式将SVM以及LSTM的预测结果融合,使得评价指标、、在原LSTM的基础上分别减少了7.5%、6.4%、10.8%,证明了SVM_LSTM网络的实用性,能够给投资者带来一定的参考价值。
下一步工作将考虑使用爬虫获取更多与股票相关的数据和文本讯息,进行多维度、深层次的分析,同时考虑分别优化时序和文本预测网络,采取更科学的举措归并两者的预测结果。
猜你喜欢
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·高二版(2022年4期)2022-05-09
阅读与作文(英语初中版)(2019年8期)2019-08-27
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
时代金融(2016年29期)2016-12-05
时代金融(2016年29期)2016-12-05
商(2016年33期)2016-11-24
商(2016年27期)2016-10-17
