
基于BERT的双通道神经网络模型文本情感分析研究
2022-05-27 06:54严驰腾何利力
智能计算机与应用 2022年5期
严驰腾,何利力
(浙江理工大学 信息学院,杭州 310018)
0 引 言
随着移动互联网的高速发展,众多互联网用户积极地参与到信息的发布中,可表现为微博评论、商品评论、直播评论等带有个人情感观点的文本信息。针对这些主观性言论进行情感分析研究可以挖掘出极具价值的信息,如对社会热点新闻评论进行舆情分析,把握舆论倾向、对商品评论进行消费倾向分析,获取消费者的消费意向等。
文本情感分析是对带有情感色彩的主观性文本进行分析、推理和归纳的过程,其目的是挖掘文本信息中用户的情感信息。现有的情感分析方法主要分为传统方法、机器学习方法和深度学习方法。其中,传统的方法主要利用情感词典获取文本中情感词的情感值,再通过加权计算确定文本的整体情感倾向。这种方法严重依赖于情感词典和评判规则的质量,其优劣程度取决于人工设计与先验知识,对新词的扩展性差。基于机器学习的方法是指通过计算机对文本情感数据进行学习,提取数据特征,自主进行情感分类。常用的机器学习算法有K近邻、朴素贝叶斯、支持向量机和决策树等,与传统方法相比在分类效果上有一定的提升,但是泛化能力较差。深度学习是机器学习的分支,通过深度学习算法可以获得文本数据的连续且稠密的向量表示,再利用卷积神经网络(Convolutional Neural Networks,CNN)、循环神经网络(Recurrent Neural Network,RNN)等模型提取数据特征进行文本分类,这种方法可以更加充分地获取文本中蕴含的情感特征,分类效果更好。
1 相关工作
在文本情感分析任务中,Kaur等人使用NGram算法对文本信息进行特征提取,KNN算法对输入特征进行分类计算得到积极、消极以及中性的情感结果。Kim提出3种尺寸大小卷积核的CNN模型,在预训练好的词向量上进行特征提取,此后通过最大池化与全连接层得到分类结果,由于CNN模型只能提取文本的局部特征,因此长文本序列特征难以捕获。Bahdanau等人最早将注意力机制应用在机器翻译领域,接下来Basiri等人、Liu等人、Yang等人将注意力机制与神经网络相结合,增强了算法模型对文本中关键情感信息的感知能力,进一步提升了文本情感分析的准确率。
文本的词向量表示是文本分类任务的基石,词嵌入方法最早使用ont-hot、bag-of-words等模型对文本进行离散表示,后来基于浅层神经网络模型的Word2Vec和GloVe等方法,可以通过语料数据训练出文本的连续且稠密的词向量表示,与早期方法相比降低了词向量维度,丰富了词向量的语义,同时能够捕捉词与词之间的相似性问题。Rhanoui等人使用Word2Vec词嵌入技术对文本数据进行向量化表示,然后通过神经网络的模型在French newpapers数据集进行情感分析,该模型中LSTM用于捕捉数据的时间序列特征,CNN对数据的局部特征进行提取,实验结果表明双通道特征提取优于单模型的数据特征提取。基于浅层神经网络模型的词嵌入方法是通过大量数据实现对词的唯一向量表示,无法解决不同语境中词语包含的语义信息,例如“小张考试得了92分,可真厉害。”、“小李考试得了32分,可真厉害!”,“厉害”在两句话中分别呈现褒义和贬义的含义。2018年,Devlin等人提出了BERT模型,该模型采用双向多层Transformer编码器结构在大型文本语料库进行预训练,通过预训练的词向量模型在下游NLP任务中对BERT模型进行微调,实现不同语义环境下词向量的动态表示,从而解决词向量的静态表征问题。谌志群等人提出基于BERT和双向LSTM的微博评论情感分析模型,该模型通过BERT生成词向量,采用双向LSTM模型进行情感分析,实验结果表明,该模型与基于Word2Vec的双向LSTM相比准确率更高。
基于上述工作,本文提出基于BERT的双通道神经网络模型的文本情感分析研究方法,该方法采用BERT(Bidirectional Encoder Representations from Transformers,BERT)模型作为词嵌入层获取文本的向量表示,构建CNN与BiGRU双通道网络模型对词向量进行局部特征和全局特征的提取,利用注意力机制提高特征矩阵中关键的情感信息权重,使得分类效果更加准确。最后本文通过对比实验证明了该方法的有效性。
2 基于BERT的CNN-BiGRU-AT情感分析模型
本文提出结合BERT的CNN-BiGRU-AT情感分析模型,模型结构如图1所示。该模型由以下部分组成。

图1 基于BERT的CNN-BiGRU-AT模型结构图Fig.1 BERT-based CNN-BiGRU-AT model structure diagram
(1)词嵌入层:本文使用BERT预训练模型获取文本序列的动态词向量表示。
(2)特征提取层:CNN能够提取文本的局部特征信息,而BiGRU能够根据文本序列的上下文语义提取到全局特征信息,因此本文通过构建CNN与BiGRU双通道模型进行特征提取。
(3)注意力层:注意力机制能够对特征提取层输出的特征矩阵进行权重分配,突出关键词在文本序列中的重要程度。本文对局部特征矩阵和全局特征矩阵分别进行注意力计算。
(4)输出层:对注意力层输出的特征向量进行融合,使用正则化防止出现过拟合现象,并通过全连接神经网络计算后,利用函数进行分类。
2.1 词嵌入层
BERT(Bidirectional Encoder Representations from Transformer)是Devlin等人于2018年提出的基于双向Transformer编码器结构进行编码的词向量预训练模型。BERT采用遮挡语言模型(Masked Language Model,MLM)和下一句预测(Next Sentence Prediction,NSP)来进行词向量训练。MLM会随机选择一定比例的词元作为预测的遮蔽词元,模型通过全局上下文来学习被遮挡的词元。尽管MLM能够编码双向上下文来表示字词,但是不能够显式地表达文本对之间的逻辑关系,而NSP可以看作是句子级别的二分类问题,通过判断后一个句子是不是前一个句子合理的下一句来挖掘句子间的逻辑关系,因此BERT模型通过结合MLM与NSP两种方法实现词向量的表示与语义特征的提取。BERT模型结构如图2所示。
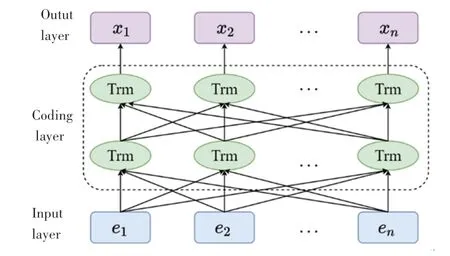
图2 BERT模型结构图Fig.2 BERT model structure diagram
图2 中,,,…,e为BERT模型的输入序列,Trm为Transformer的Encoder模型,,,…,x为BERT模型的输出词向量序列。BERT的输入序列是词元嵌入(Token Embeddings)、片段嵌入(Segment Embeddings)和位置嵌入(Positional Embeddings)信息之和,其中词元嵌入的文本序列需要使用词元<cls>作为起始标记。其输入序列模型如图3所示。

图3 BERT模型输入序列图Fig.3 BERT model input sequence diagram
2.2 双通道特征提取层
2.2.1 局部语义特征提取
卷积神经网络早期被应用于计算机视觉领域,但近年来也广泛应用到自然语言处理领域中,并取得了不错的成绩。CNN通过卷积核提取文本的局部语义特征,本文使用多尺度卷积来获取不同距离词语间的特征信息。CNN通过卷积层对文本进行特征提取后,通常会使用最大池化层对特征矩阵进行压缩,这种方法会破坏文本序列的时序性,造成特征丢失等问题。因此本文对卷积层得到的特征矩阵进行拼接,直接输入注意力层进行权重分配,模型结构如图4所示。

图4 局部特征提取模型结构图Fig.4 Local feature extraction model structure diagram
图4 中,,,…,x 为文本的词嵌入向量,通过3个不同窗口大小的卷积核进行特征提取,每种卷积核的维度768、通道数256,步长设定为1。对于窗口大小为的卷积核第次卷积操作得到的局部特征c ,此处需用到的计算公式为:

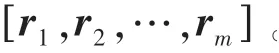
2.2.2 全局语义特征提取
门控循环单元(Gate Recurrent Unit,GRU)是长短期记忆网络(Long Short-Term Memory,LSTM)的改进模型。循环神经网络模型(Recurrent Neural Network,RNN)在处理长序列数据进行学习时会出现梯度消失现象,无法感知长时间序列的非线性关系。RNN模型的改进版LSTM通过输入门、遗忘门和输出门解决了梯度消失的问题。因为LSTM模型有参数较多,训练时间较长的问题,因此Cho等人提出了将LSTM的单元状态和隐藏状态合并,并将输入门和遗忘门合为一个更新门的GRU模型,简化了其结构,因此GRU可以使用更少的参数和时间来达到LSTM的实验效果。GRU结构如图5所示。

图5 GRU结构图Fig.5 GRU structure diagram
GRU模型向前计算公式为:
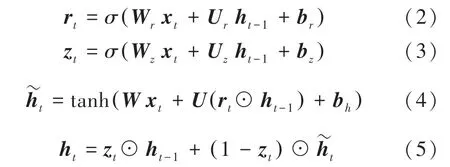
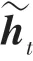
单向GRU的各时刻隐藏状态是从前向后单向传输的,这种方式忽略了文本的全局语义信息,无法推断出后文中的字词对前文的影响,因此本文采用双向门控循环单元(Bidirectional Gated Recurrent Unit,BiGRU)模型进行全局语义特征提取,可以提取正向与反向时间序列各时刻的隐藏状态,相比于单向GRU其结果更加准确,BiGRU模型结构如图6所示。
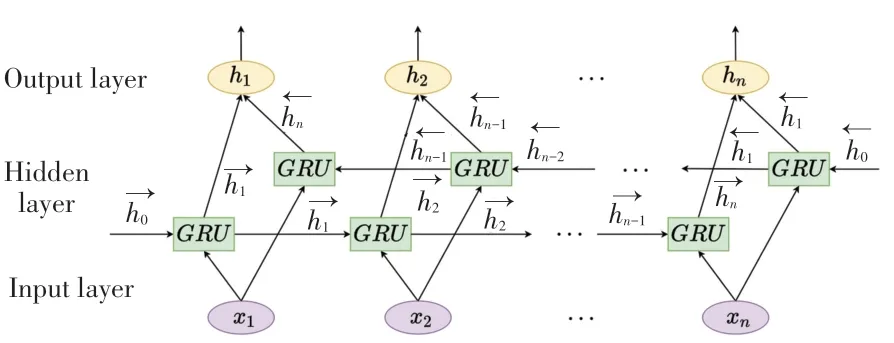
图6 BiGRU模型结构图Fig.6 BiGRU model structure diagram
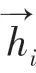
2.3 注意力层
文本信息通常会包含具有情感倾向的词汇,这些词汇往往会对文本的情感倾向产生重要影响,使用注意力机制可以捕获情感词予以分配较大的权重分值,突出其在文本序列中的重要程度。本文分别对局部特征矩阵(,,…,r 和全局特征矩阵(,,…,h )分别使用注意力机制,加强文本情感极性,研究后推得的计算公式为:
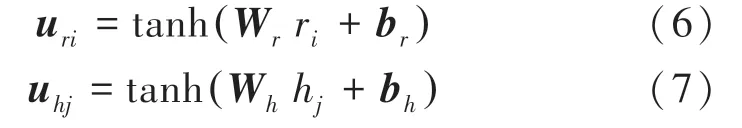
其中,W 与W 为权重参数矩阵;b 与b 为偏置项;tanh为非线性激活函数。
通过对权重向量u 与u 进行归一化处理,可得到关于局部特征r 和全局特征h 的注意力分数α与α,其计算公式为:
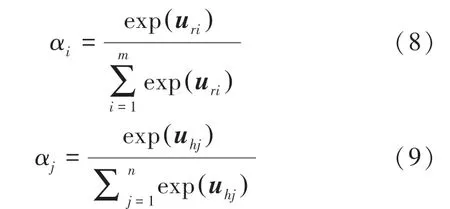
将注意力分数α与局部特征矩阵对应的子向量计算加权和,可得到经注意力机制优化后的文本局部特征向量s ,全局特征矩阵的权重优化类似,可得到文本全局特征向量s 。 具体的计算公式为:
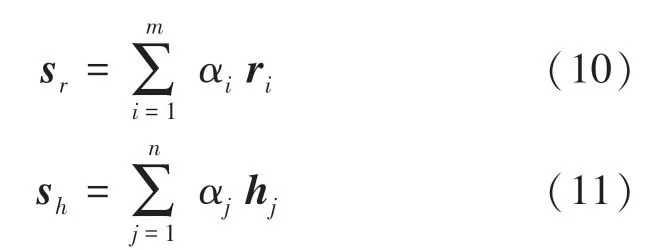
双通道注意力机制层为文本中关键情感词向量分配了相应的注意力权重,进而提高了模型情感分析的准确性。
2.4 输出层
本文模型输出层由全连接神经网络与函数构成。首先将注意力机制优化后的局部特征向量s 与全局特征向量s 融合,得到文本最终的特征表示。 相应的数学公式可表示如下:

通过在全连接神经网络层前融合方法,可以缓解模型的过拟合现象,全连接层的输出使用函数进行分类计算,该值可由如下数学公式计算得到:
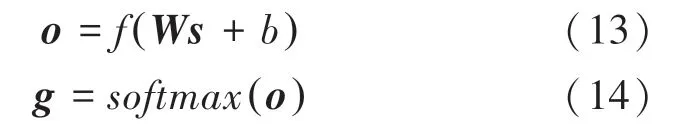
其中,为全连接层的输出向量;为权重矩阵;为偏置项;为模型的最终输出向量。
3 实验方法及结果分析
3.1 实验数据集
本文使用的是谭松波老师收集整理的酒店评论数据集,该数据集包含积极和消极评论各7 000条和3 000条。使用前对数据集进行预处理,去除掉特殊字符,调整数据集结构,其数据集示例见表1。

表1 数据集示例Tab.1 Examples of the data set
表1中,情感标签1和0分别表示积极评论和消极评论。实验数据集以4∶1比例随机划分为训练集和测试集,每个数据集以同比例划分积极和消极评论。数据集中文本长度与数量关系如图7所示,可以观察到数据集内评论以短文本居多,其中≤100的数据占比约50%,100≤200的数据占比约25%。
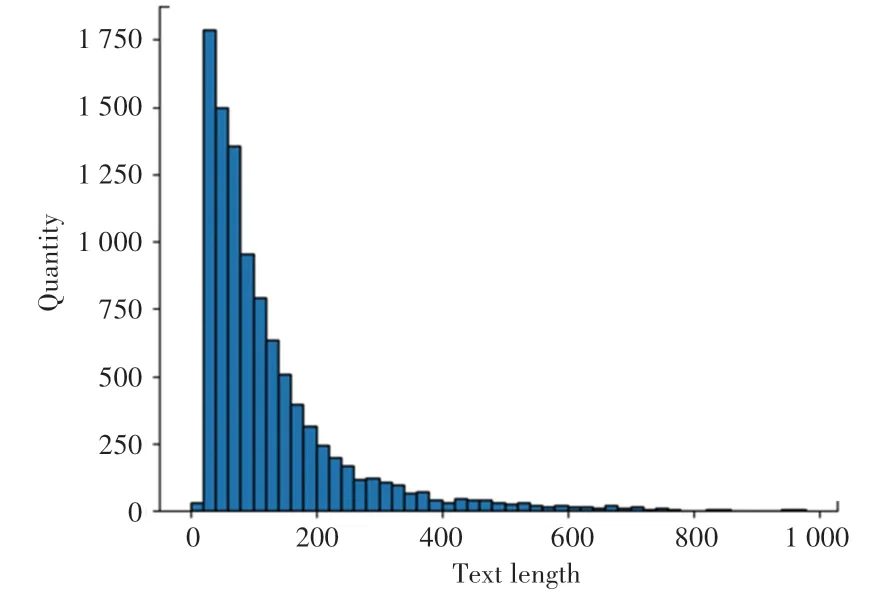
图7 文本长度与数量关系图Fig.7 The relationship between text length and quantity
3.2 模型评估指标
为验证模型在文本情感分析任务中的效果,本文采用 准确率()、查准率()、召回率()和(分值)作为评估指标,计算公式如下:

其中,(True Positive)表示样本正确分类为积极情感的数量;(False Positive)表示样本错误分类为积极情感的数量;(False Negative)表示将样本错误分类为消极情感的数量;(True Negative)表示将样本正确分类为消极情感的数量。
3.3 实验环境与超参数设定
本文模型实验环境见表2。
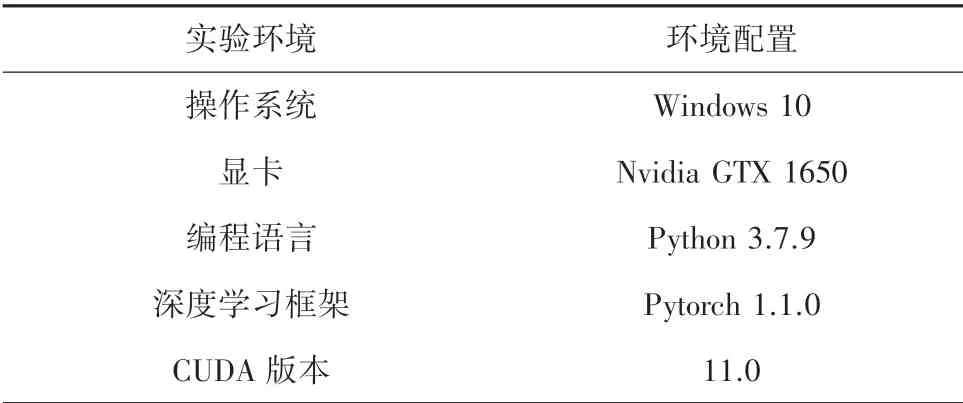
表2 实验环境Fig.2 Laboratory environment
本文词嵌入层使用Google发布的“BERT-Base Chinese”中文预训练模型,该模型采用12层Transformer,隐藏层的维度为768,激活函数为,多头注意力的参数为12,模型总参数大小为110 MB。双通道特征提取层的主要参数见表3。
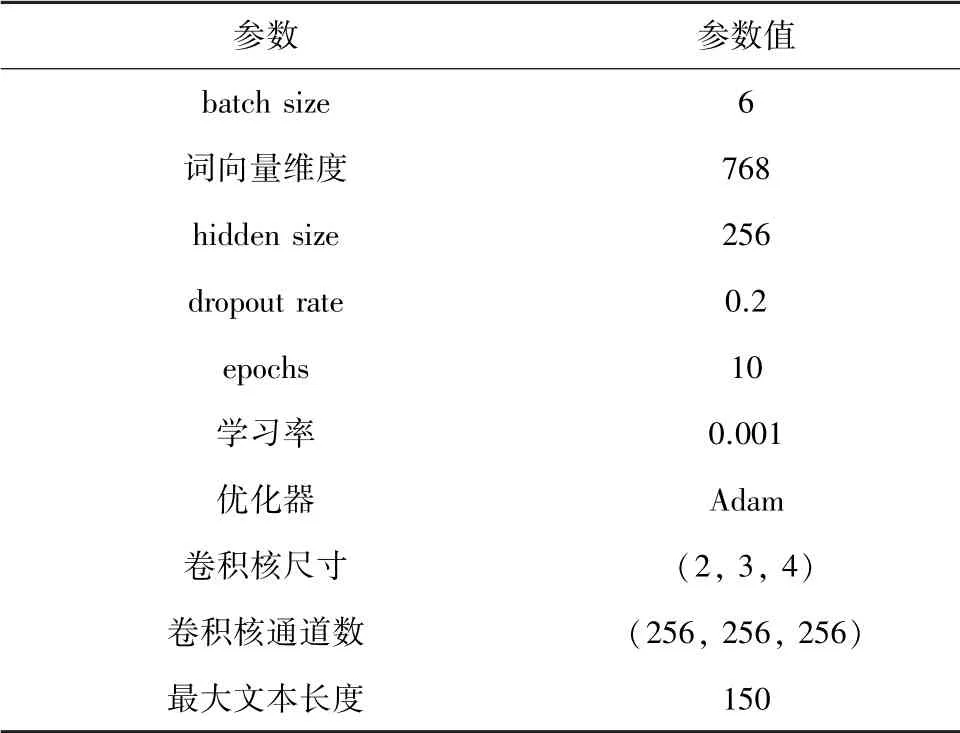
表3 特征提取层模型参数设定Tab.3 Feature extraction layer model parameters setting
3.4 对比实验与结果分析
3.4.1 BERT模型词向量化效果分析
为验证BERT预训练模型对文本向量化的表示能力,本文选取Word2Vec、ELMo与BERT进行实验对比,文本数据分别通过3个模型向量化后输入到BiGRU中进行训练。实验结果见表4。结果表明基于BiGRU的BERT词嵌入模型的准确率高达0.911 0,相比Word2Vec与ELMo准确率分别提高了4.5%与2.6%,证明了基于双向Transformer编码器的BERT模型有更出色的词向量表示能力。
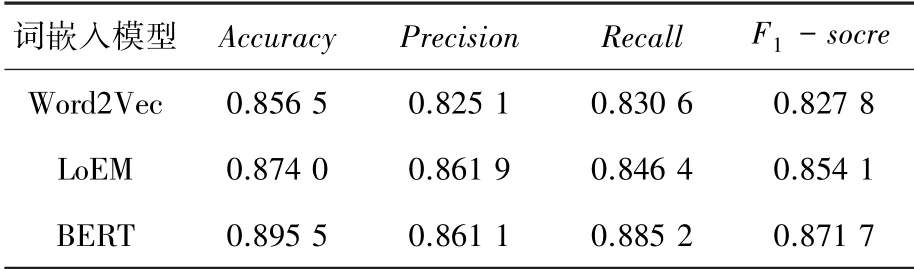
表4 词嵌入层模型试验结果对比Tab.4 Comparison of test results of word embedding layer model
3.4.2 本文模型实验对比与结果分析
为验证本文模型的有效性,使用BERT模型作为词嵌入层进行文本的向量化表示,同时为验证双通道特征提取模型与注意力机制结合的有效性,分别构建CNN-BiGRU与CNN-BiGRU-AT模型进行实验对比。在文本情感分析任务中,BiGRU、BiLSTM、TextRNN、TextCNN是情感分类中的经典模型,本文将选取上述模型进行对比实验,其模型结构如下。
(1)BiGRU:该模型为本文的全局特征提取层,对比实验中使用初始时刻与最后时刻的融合特征向量作为模型输出。
(2)BiLSTM:该模型采用双向长短期记忆网络进行特征提取,使用初始时刻与最后时刻的融合特征向量作为模型输出。
(3)TextRNN:该模型采用双向长短期记忆网络进行特征提取,与BiLSTM不同的是,使用最大池化对BiLSTM各时刻的输出特征向量进行特征提取作为模型输出。
(4)TextCNN:该模型采用多尺度卷积对输入向量进行特征提取,不同尺度的卷积核获取到不同长度词语的特征信息,最后使用最大池化对特征向量进行计算作为模型输出。
(5)CNN-BiGRU:该模型为未使用注意力机制的双通道特征提取模型,主要与本文BERT-CNNBiGRU-AT模型进行对比,验证注意力机制的有效性。
所有模型对比实验结果见如表5。
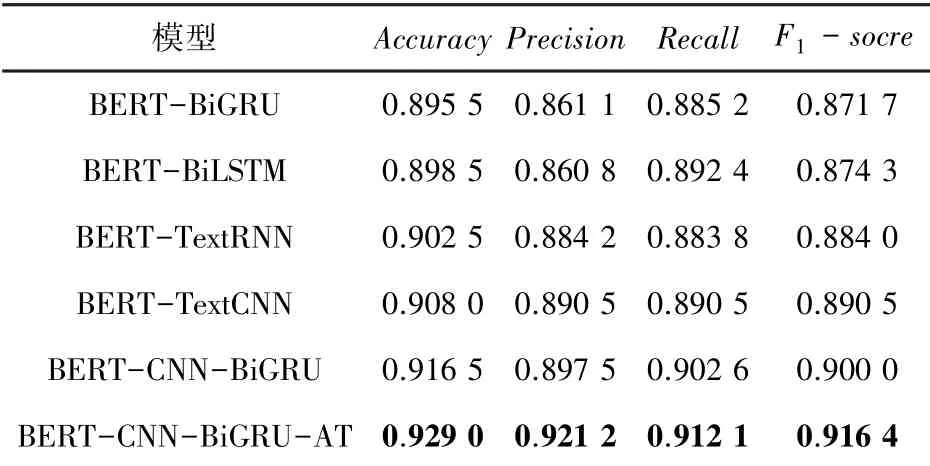
表5 不同模型的实验对比结果Tab.5 Experimental comparison results of different models
实验结果评估指标以与为主,根据表5可知,本文模型BERT-CNN-BiGRUAT的准确率达到了92.90%,分数达到了91.64%,均高于其他模型。其中,BERT-BiGRU与BERT-BiLSTM的模型评分相差不多,因为二者具有相同的模型结构。TextCNN模型在本文数据集中的实验效果均好于循环神经网络模型,在酒店评论数据集中,短文本数据占比约为75%,TextCNN通过多尺度卷积可以更好地获取到短文本序列词组之间的特征信息,而循环神经网络擅长捕获较长文本的时间序列特征。通过BERT-CNN-BiGRU与BERTCNN-BiGRU-AT对比可知,使用了注意力机制后,准确率提高了约1.4%,分数提高了约1.8%,说明注意力机制可以有效提高模型的准确率。综上所述,本文所提出的基于BERT的CNN-BiGRU-AT模型在中文文本情感分析任务上具有很好的效果,证明了本文模型的有效性。
4 结束语
本文提出基于BERT的双通道神经网络模型的文本情感分类方法,首先采用BERT模型进行文本向量化表示,结合CNN和BiGRU构建双通道模型提取文本中蕴含的局部与全局情感特征,通过建立注意力权重分配机制,融合加权求和后的特征向量,经过输出层计算后,得出文本的情感倾向信息,在酒店评论数据集中表现出了较高的准确率。但是依然有不足之处,表现为模型训练时间过久,其原因是BERT模型具有大量参数,且模型深度较深,在对下游任务进行微调的过程中,需要反向传播更新大量参数,消耗较多时间。针对此问题拟在后续研究中加以改进。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
电机与控制学报(2018年9期)2018-05-14
中国新通信(2017年9期)2017-05-27
计算机应用(2016年10期)2017-05-12
电脑爱好者(2015年22期)2015-09-10
分析化学(2015年8期)2015-08-13
